郑重声明: 本文所有安全知识与技术,仅用于探讨、研究及学习,严禁用于违反国家法律法规的非法活动。对于因不当使用相关内容造成的任何损失或法律责任,本人不承担任何责任。 如需转载,请注明出处且不得用于商业盈利。
💥👉点赞❤️ 关注🔔 收藏⭐️ 评论💬💥
更多文章戳👉 Whoami!-CSDN博客🚀

𖤐 嘿,经过前面的预热,我们正式打开这扇门,来吧 !
𖤐 𝓗𝓮𝔂, 𝓪𝓯𝓽𝓮𝓻 𝔀𝓪𝓻𝓶-𝓾𝓹,𝔀𝓮'𝓻𝓮 𝓷𝓸𝔀 𝓸𝓯𝓯𝓲𝓬𝓲𝓪𝓵𝓵𝔂 𝓸𝓹𝓮𝓷𝓲𝓷𝓰 𝓽𝓱𝓲𝓼 𝓭𝓸𝓸𝓻,𝓒𝓸𝓶𝓮 𝓸𝓷 !
→ 信息收集**▸WEB应用攻击▸Web应用枚举A-----我们在这儿~** 🔥🔥🔥
→ 漏洞检测
→ 初始立足点
→ 权限提升
→ 横向移动
→ 报告/分析
→ 教训/修复
目录
[1.1 浏览器"开发者工具"枚举法](#1.1 浏览器"开发者工具"枚举法)
[1.1.1 通过URL扩展名分析](#1.1.1 通过URL扩展名分析)
[1.1.2 使用浏览器"开发者工具"分析](#1.1.2 使用浏览器“开发者工具”分析)
[1. Debugger(调试器)工具](#1. Debugger(调试器)工具)
[2. Inspector(检查器)工具](#2. Inspector(检查器)工具)
[1.2 HTTP响应头与站点地图枚举](#1.2 HTTP响应头与站点地图枚举)
[1.2.1 http头部与Cookie检查](#1.2.1 http头部与Cookie检查)
[1.2.2 站点地图与robots.txt文件](#1.2.2 站点地图与robots.txt文件)
[3.站点地图 vs robots.txt 对比](#3.站点地图 vs robots.txt 对比)
[1.3 其他WEB应用枚举简介](#1.3 其他WEB应用枚举简介)
[1.3.1 被动信息收集 (Passive Reconnaissance)](#1.3.1 被动信息收集 (Passive Reconnaissance))
[1.3.2 主动枚举与交互式分析 (Active Enumeration)](#1.3.2 主动枚举与交互式分析 (Active Enumeration))
[1.3.3 特定技术与框架枚举](#1.3.3 特定技术与框架枚举)
[💥创作不易💥求一波暴击👉点赞❤️ 关注🔔 收藏⭐️ 评论💬](#💥创作不易💥求一波暴击👉点赞❤️ 关注🔔 收藏⭐️ 评论💬)
1.Web应用枚举
Web应用程序枚举是渗透测试中的关键阶段,核心目标是深入理解目标应用的构成 ,主要目的是识别和映射 目标应用的各个组件,为后续精准攻击奠定基础。在对Web应用进行任何攻击之前,必须先发现其使用的技术栈,这通常包括四个核心层级:
| 层级 | 说明 | 常见示例 |
|---|---|---|
| 🖥️ 操作系统 | 托管Web服务器的基础系统 | Linux, Windows Server |
| 🌐 Web服务器 | 处理HTTP请求的软件 | Apache, Nginx, IIS |
| 💾 数据库 | 存储应用数据的系统 | MySQL, PostgreSQL, MongoDB |
| 👨💻 编程语言 | 服务器端/客户端语言 | PHP, Python, Java, JavaScript |
1.1 浏览器"开发者工具"枚举法
通过浏览器自带的**"开发者工具"**来获取网站的技术栈详细信息。
1.1.1 通过URL扩展名分析
URL中的文件扩展名可以提供技术栈线索:
-
.php→ PHP -
.jsp或.do→ Java -
.aspx→ ASP.NET -
.html/.htm→ 静态页面或Java框架
⚠️ 局限性 :现代Web框架普遍使用路由技术,URL中不再显示文件扩展名,此方法效力有限。
1.1.2 使用浏览器"开发者工具"分析
1. Debugger(调试器)工具
Debugger工具用于分析JavaScript代码,可发现:
-
🔍 JavaScript框架(jQuery, React, Vue等)
-
🕵️ 隐藏的API端点
-
💬 开发者注释
-
🔒 客户端逻辑和控制
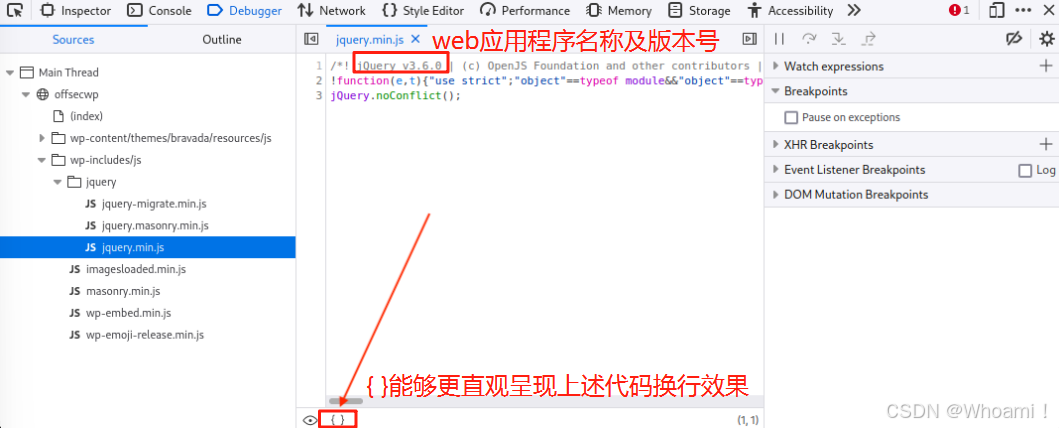
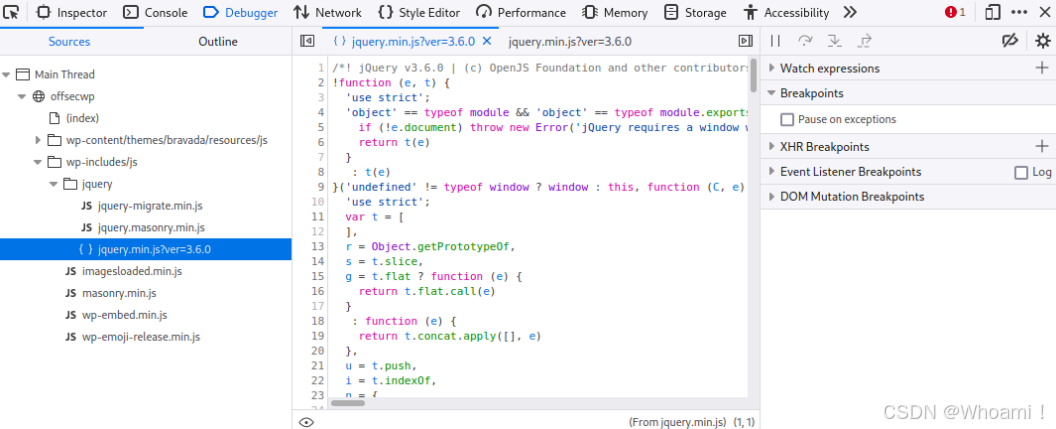
点击**{ } 图标**后,Firefox将以更易于阅读和跟踪的格式显示代码:
2. Inspector(检查器)工具
Inspector工具用于分析页面HTML结构,特别适合发现:
-
👁️ 隐藏表单字段 (如
<input type="hidden">) -
🍪 Cookie信息
-
🔍 敏感注释
-
⚙️ 客户端验证逻辑
使用方法 :右键点击页面元素 → 选择"检查Inspector"。
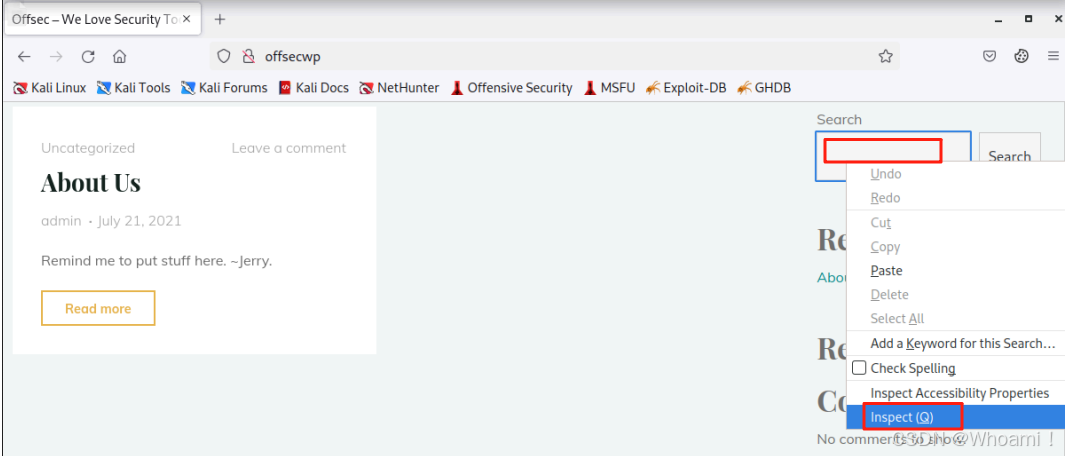
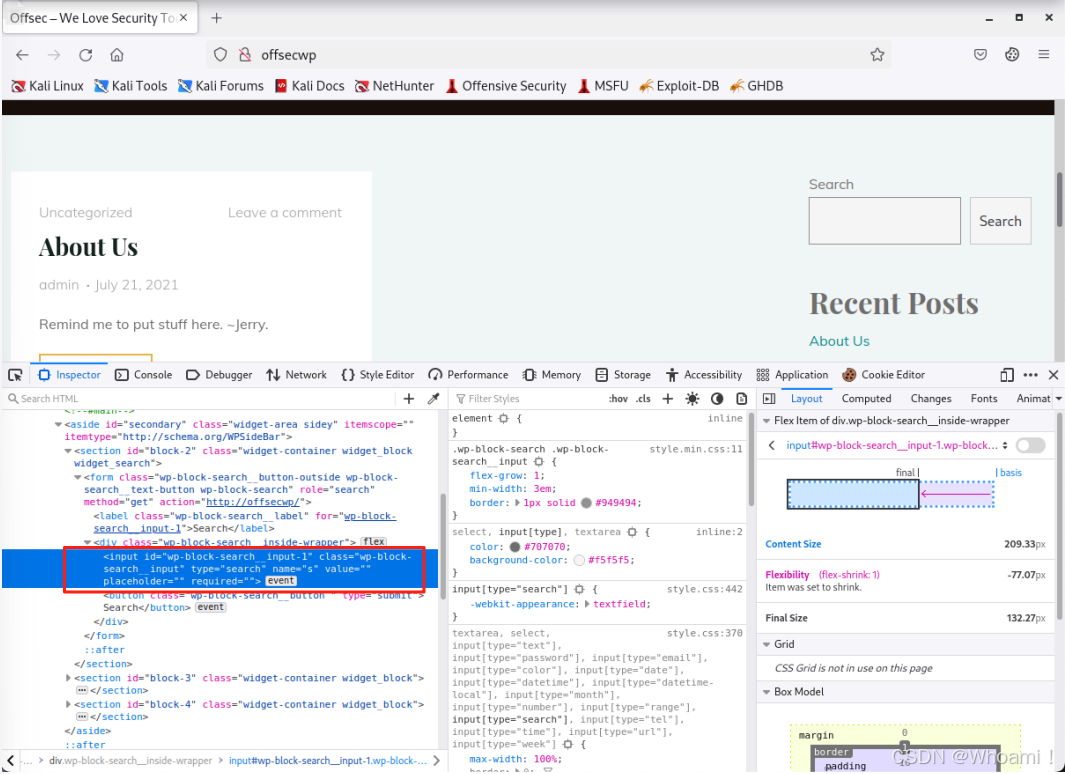
打开**检查器("Inspector")**工具,并突出显示右键单击的元素的HTML代码:
1.2 HTTP响应头与站点地图枚举
分析工具类型
① 代理工具
如Burp Suite等专业工具,能够拦截并分析客户端与服务器之间的所有HTTP请求和响应。
② 浏览器内置工具
现代浏览器(如Firefox、Chrome)提供的Network面板,直接查看网络请求与响应的详细信息。
1.2.1 http头部与Cookie检查
操作步骤:
-
打开浏览器开发者工具(F12)
-
切换到Network标签页
-
刷新页面捕获网络请求
-
点击任意请求查看详细信息
-
检查Response Headers部分
点击一个请求获取更多关于它的详细信息。检查响应头,响应头是作为对HTTP请求的响应发送的HTTP头的子集。
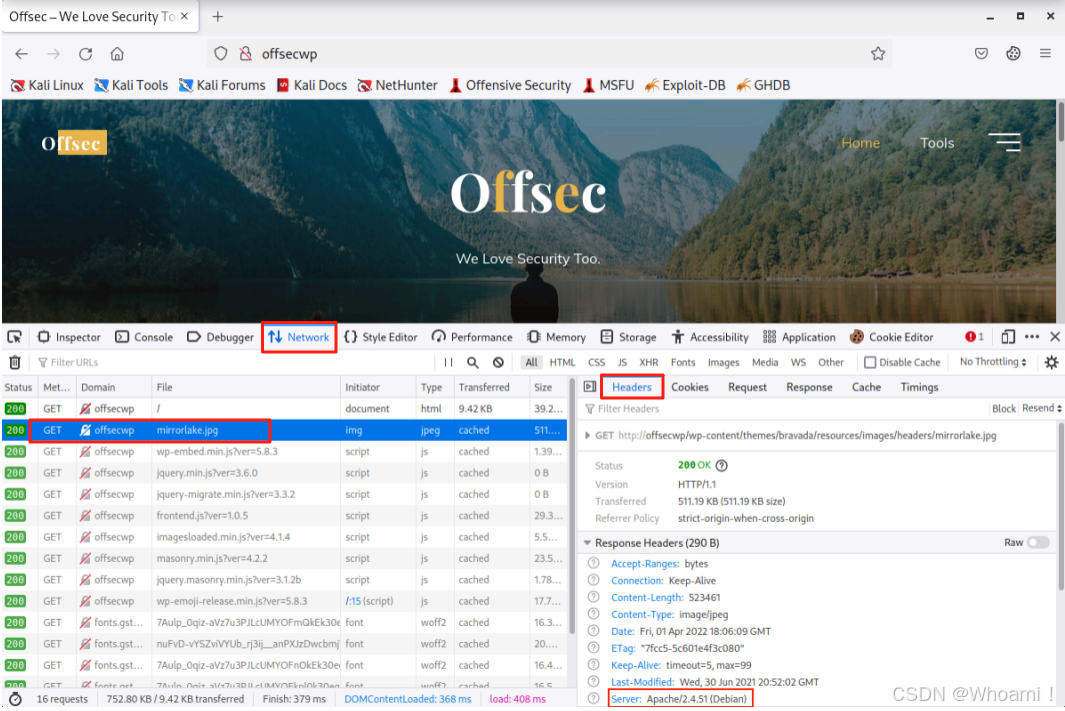
关键信息字段
| 响应头字段 | 说明 | 示例值 |
|---|---|---|
| Server | Web服务器软件及版本 | Apache/2.4.51 (Debian) |
| X-Powered-By | 应用使用的技术 | PHP/8.0.10 |
| X-AspNet-Version | ASP.NET版本 | 4.0.30319 |
| x-amz-cf-id | Amazon CloudFront标识 | x-amz-cf-id: abc123... |
| X-Forwarded-For | 客户端原始IP | 192.168.1.1 |
重要发现
-
🔍 服务器标识:Server头部通常明确显示Web服务器软件和版本号
-
⚠️ 信息泄露风险:过多详细信息可能暴露攻击面
-
📝 自定义头部 :以
X-开头的头部常包含技术栈信息
技术栈识别示例:
Web服务器:Apache、Nginx、IIS等
编程语言:PHP、ASP.NET、Python等
框架:Express、Django、Ruby on Rails等
云服务:AWS CloudFront、Azure、Google Cloud等
代理/CDN:Cloudflare、Akamai等
注意:
HTTP头部并不总是仅由Web服务器生成。例如,Web代理会主动插入X-For warded-For头部,以向Web服务器传递原始客户端IP地址的信息。从历史上看,以"X-"开头的头部被称为非标准HTTP头部。 然而,RFC6648现在不推荐使用"X-",而是采用更清晰的命名约定。
1.2.2 站点地图与robots.txt文件
在Web应用侦察阶段,站点地图文件 (sitemap.xml)和robots.txt文件是宝贵的信息来源,它们可以帮助安全研究人员和搜索引擎更好地了解网站结构和敏感区域。
1.站点地图文件分析(包含URL)
站点地图 (sitemap.xml,Sitemaps文件被放在网站的根目录下)是一种标准化的XML文件格式,遵循Sitemaps协议,主要功能是:
-
🔍 引导搜索引擎:指明哪些页面可以被抓取
-
📊 提供元数据:包含页面更新频率和优先级信息
-
🗂️ 揭示网站结构:展示完整的URL层次结构
站点地图示例结构
XML
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://example.com/</loc>
<lastmod>2023-10-15</lastmod>
<changefreq>daily</changefreq>
<priority>1.0</priority>
</url>
<url>
<loc>https://example.com/about</loc>
<lastmod>2023-09-20</lastmod>
<changefreq>monthly</changefreq>
<priority>0.8</priority>
</url>
</urlset>站点地图关键元素:
| 元素 | 描述 | 安全意义 |
|---|---|---|
| <loc> | 页面URL | 发现所有可访问路径 |
| <lastmod> | 最后修改时间 | 识别活跃更新区域 |
| <changefreq> | 变更频率 | 找出频繁更新的敏感区域 |
| <priority> | 优先级 | 识别重要页面 |
2.robots.txt文件分析(排除URL)
robots.txt 文件位于网站根目录 ,用于指示网络爬虫哪些区域不应被访问:
-
🚫 排除指令:使用Disallow指令限制抓取
-
✅ 允许指令:使用Allow指令特例允许
-
⚠️ 安全风险:常暴露敏感目录和页面
robots.txt示例
XML
User-agent: *
Disallow: /admin/
Disallow: /config/
Disallow: /backup/
Allow: /public/常见敏感路径
-
/admin/,/administrator/- 管理后台 -
/wp-admin/- WordPress管理 -
/config/,/includes/- 配置文件目录 -
/backup/,/bak/- 备份文件目录 -
/phpmyadmin/- 数据库管理
3.站点地图 vs robots.txt 对比
| 特性 | 站点地图(sitemap.xml) | robots.txt |
|---|---|---|
| 主要目的 | 包含URL( inclusivity ) | 排除URL( exclusivity ) |
| 协议类型 | Sitemaps协议 | Robots排除协议 |
| 文件格式 | XML格式 | 文本格式 |
| 安全性 | 显示公开内容 | 常暴露敏感路径 |
| 搜索引擎 | 指导抓取重要页面 | 限制抓取敏感区域 |
1.3 其他WEB应用枚举简介
1.3.1 被动信息收集 (Passive Reconnaissance)
在不与目标服务器直接交互的情况下,从第三方来源获取信息。
-
搜索引擎技巧 (Google Dorking / OSINT):
-
使用特定的搜索语法在Google、Bing等搜索引擎中查找敏感信息。
-
示例:
-
site:example.com(搜索指定站点的所有收录页面) -
site:example.com ext:pdf(查找该站点上的PDF文件) -
site:example.com intitle:"login"(查找标题中含"login"的页面) -
site:example.com inurl:/admin/(查找URL中含"/admin"的页面) -
site:pastebin.com example.com(在代码分享网站中搜索目标相关信息)
-
-
-
第三方数据库与服务:
-
DNS记录查询 :使用
dig,nslookup,whois命令或在线服务(如ViewDNS.info)获取DNS信息,如A记录、MX记录、TXT记录等,可能发现子域名或内部服务器信息。 -
证书透明度日志 :证书在签发时会被记录在公共日志中。使用 Censys 或 crt.sh 等网站,通过证书查找关联的子域名。
-
历史数据与归档 :Wayback Machine (archive.org) 存档了网站的历史快照,可以查看已删除的页面、旧的源代码和不再活跃的端点。
-
子域名枚举 :使用专门工具如 Amass , Subfinder , Sublist3r 等,它们会聚合多种数据源(搜索引擎、证书日志、DNS等)来发现目标的子域名。
-
1.3.2 主动枚举与交互式分析 (Active Enumeration)
直接与目标应用交互,分析其响应。
-
自动化爬虫与扫描器 (Automated Scanners):
-
Burp Suite / OWASP ZAP :这些是交互式安全测试工具 (IAST),不仅代理流量,其 爬虫 (Spider) 功能可以自动遍历网站链接,扫描器 (Scanner) 能自动测试常见漏洞。它们的 目标站点地图 (Target Site Map) 会自动生成一张所有已发现目录和文件的树状图。
-
Nikto:一款经典的Web服务器扫描器,专门用于快速检查数千个危险文件、过时的服务器软件和错误配置。
-
Dirb / Dirbuster / FFuf:这些是更专业的目录暴力破解工具,通常比Gobuster有更多自定义选项和字典。
-
-
人工深度分析:
-
源代码分析:在浏览器中查看页面源代码,寻找隐藏的链接、注释、JS文件路径和API密钥。
-
JavaScript文件分析:
-
使用浏览器开发者工具中的"Network"标签页,刷新页面以查看所有加载的JS文件。
-
手动检查或使用工具(如 LinkFinder)自动分析JS文件,从中提取隐藏的端点、API路径和子域名。
-
-
参数发现 :手动或使用工具(如 Arjun)来发现GET/POST参数,这些参数可能对应未文档化的功能点。工具会使用庞大的参数名字典进行模糊测试。
-
1.3.3 特定技术与框架枚举
针对已知的技术栈进行针对性枚举。
-
内容管理系统枚举 (CMS Enumeration):
-
如果目标使用WordPress、Joomla!、Drupal等CMS,有专门的黑客工具。
-
示例 :对于WordPress,可以使用 WPScan,它能枚举用户名、插件、主题,并检查其已知漏洞。
-
-
框架与特定技术:
- 识别出框架(如Laravel、Ruby on Rails、Django)后,可以查找其默认的管理后台路径、调试模式端点(如
/console之于Flask)等。
- 识别出框架(如Laravel、Ruby on Rails、Django)后,可以查找其默认的管理后台路径、调试模式端点(如
-
API深度枚举:(后续文章详细说明)
-
如果发现API端点(如
/api/v1/),可以尝试:-
寻找 Swagger/OpenAPI 文档(如
/api-docs,/swagger.json)。 -
测试不同的HTTP方法(GET, POST, PUT, DELETE, PATCH, HEAD, OPTIONS)。
-
测试HTTP方法覆盖 (如通过
X-HTTP-Method-Override头)。 -
测试身份验证绕过和权限提升。
-
对GraphQL端点使用专用工具(如InQL)。
-
-
总结与对比
| 方法类型 | 优点 | 缺点 | 常用工具 |
|---|---|---|---|
| 被动收集 | 隐蔽,无法被目标察觉 | 信息可能过时或不完整 | Google, crt.sh, whois, Amass |
| 主动枚举 | 信息准确、实时 | 会产生大量日志,易触发告警 | Burp Suite, ZAP, Nikto, FFuf |
| 人工分析 | 深度挖掘,能发现逻辑漏洞 | 耗时,依赖经验 | 浏览器开发者工具 |
| 技术栈特定 | 高度精准,效率极高 | 必须先识别出技术栈 | WPScan, 各种Scanner |
最佳实践是混合使用多种方法:
通常从被动信息收集 开始,绘制目标大致轮廓;然后使用自动化工具 进行初步的主动枚举;最后对关键区域进行深度人工分析,从而构建一个完整且深入的Web应用攻击面地图。
💥创作不易💥求一波暴击👉点赞❤️ 关注🔔 收藏⭐️ 评论💬
您的支持是我创作最大的动力!
