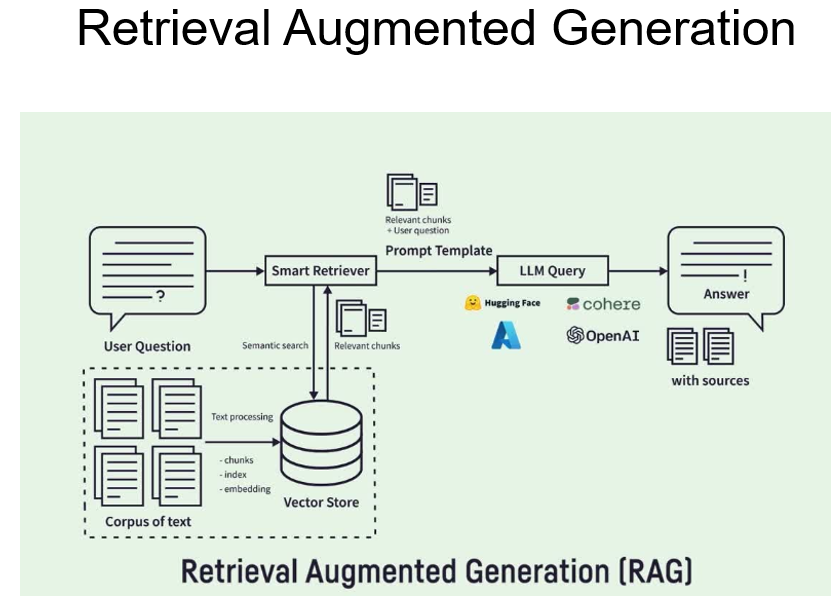
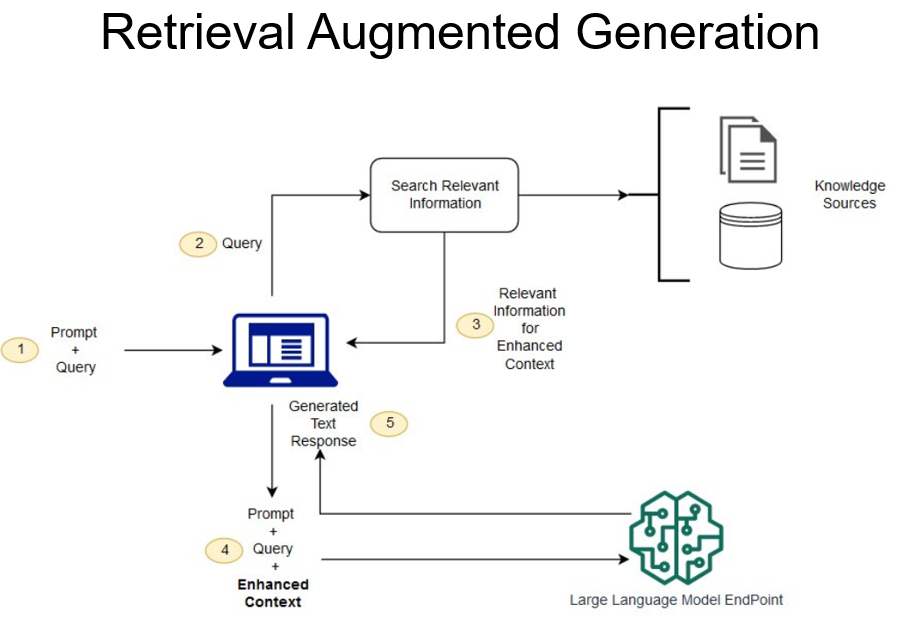
RAG
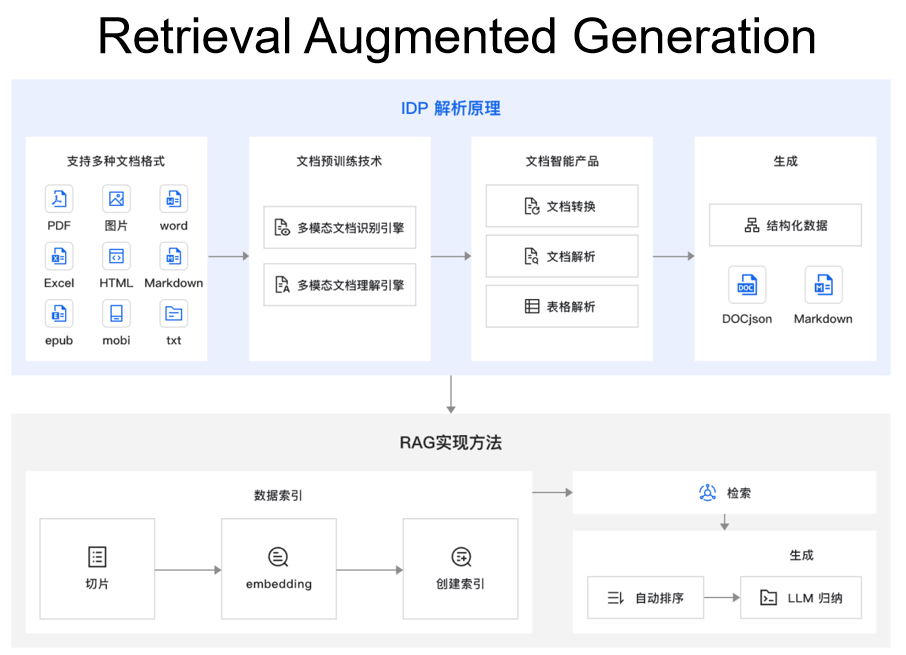
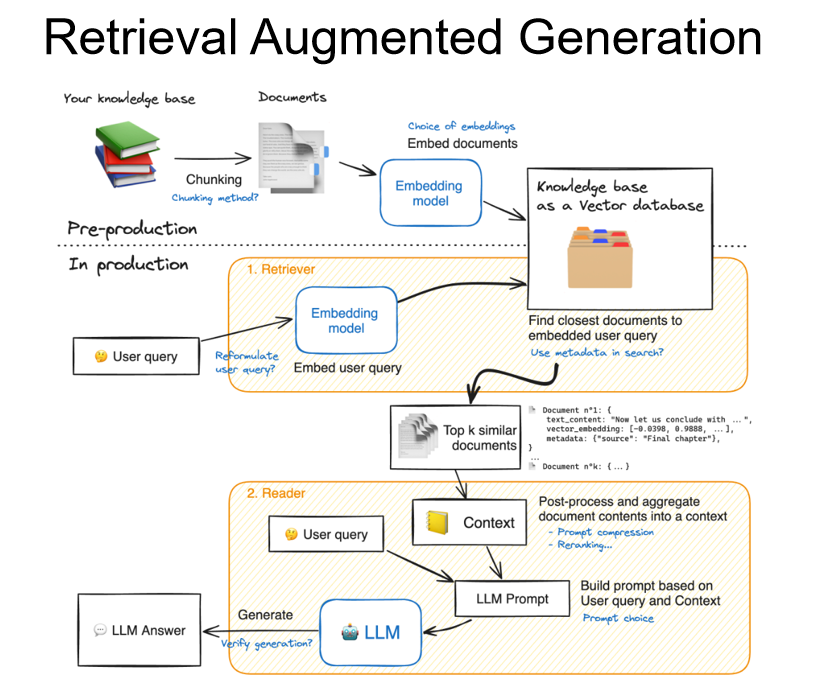
RAG优势
(1)可扩展性:减少模型大小和训练成本,并能够快速扩展知识。
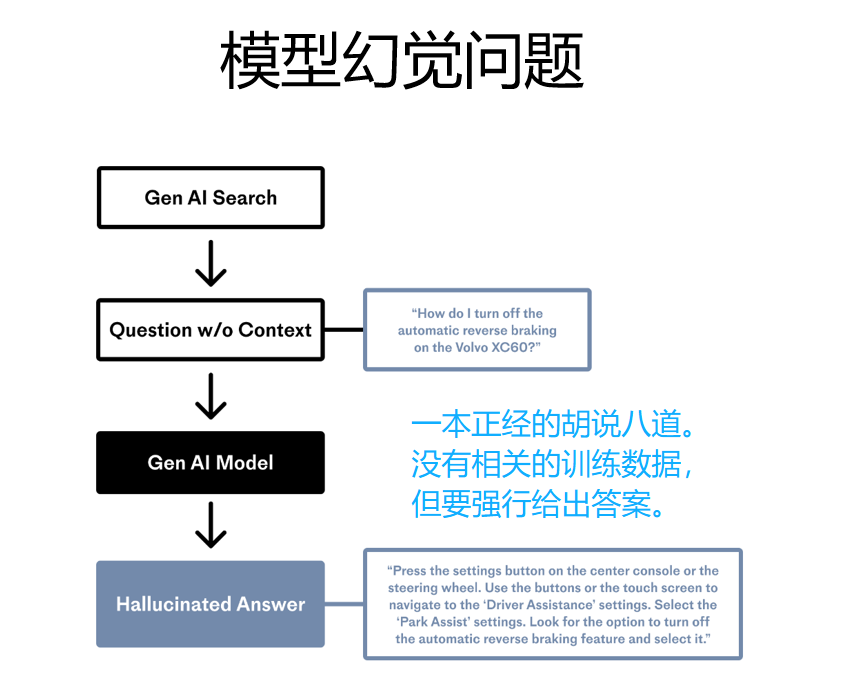
(2)准确性:模型基于事实进行回答,减少幻觉的发生。
(3)可控性:允许更新和定制知识。
(4)可解释性:检索到的相关信息作为模型预测中来源的参考。
(5)多功能性:RAG能够针对多种任务进行微调和定制,如QA、Summary、Dialogue等。
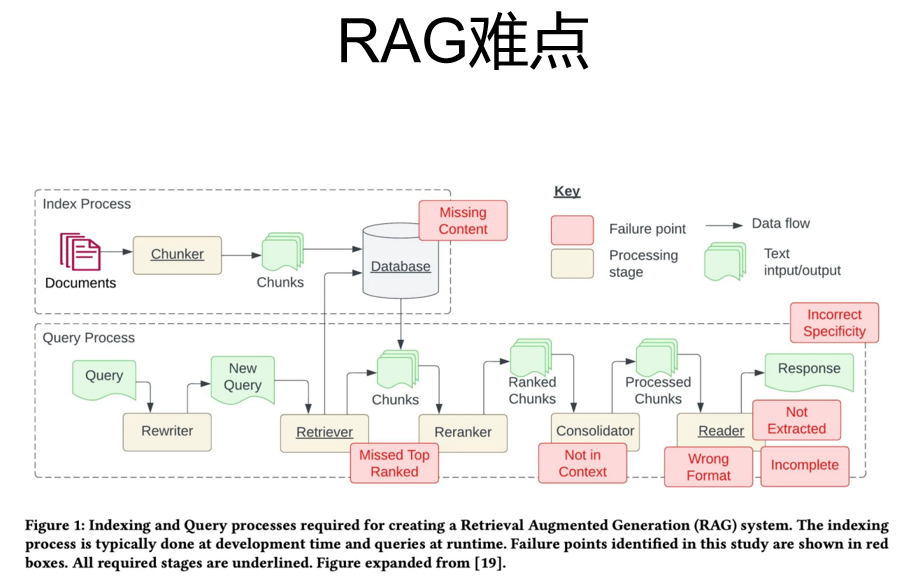
RAG难点及解决
数据清洗及常见数据格式

-
文本类(.txt/.md)
特点:
纯文本内容,可能包含标题、段落、列表等简单结构(如 Markdown 的# 标题、- 列表项)。
预处理步骤:
按自然段落分割(避免过长文本影响检索精度);
保留标题与内容的关联(如用 "标题:内容" 格式标记);
去除空行、冗余符号(如连续换行、特殊字符)。
-
文档类(.docx/.pdf)
特点:
可能包含复杂格式(如多栏布局、表格、图片、公式),文本可能分散在不同页面或区域。
预处理步骤:
文本提取:
用工具(如 Python 的python-docx提取 docx,PyPDF2/pdfplumber提取 PDF)提取纯文本,忽略格式标记(如字体、颜色);
处理多页文档时,记录页码(便于后续溯源)。
结构整理:
合并跨页断裂的段落;
表格内容转换为 "行 + 列" 文本(如 "表头 1:值 1;表头 2:值 2");
图片 / 公式:若无法提取文本,用描述性文字标记(如 "图片:模型架构图""公式:注意力计算公式")。
-
表格类(.xlsx/.csv)
特点:
结构化数据,以行和列组织信息(如产品信息表、用户信息表)。
预处理步骤:
按 "行" 或 "行 + 列" 分割(避免整表作为一个文本块,导致检索粒度太粗);
保留表头与内容的关联(用表头作为"键",行内容作为"值");
处理空值:用 "无数据" 标记,避免遗漏信息。
-
网页类(.html/ 网页链接)
特点:
包含大量 HTML 标签(如div/p/a)、广告、导航栏等冗余内容,核心文本可能嵌套在标签中。
预处理步骤:
标签清洗:用工具(如BeautifulSoup)提取p/h1-h6等标签内的核心文本,去除广告、导航、脚本等无关内容;
结构保留:保留标题(h1)、副标题(h2)与正文的层级关系;
链接处理:对内部链接(如 "详见 xxx 页面"),若能访问则合并内容,否则标记链接地址(如 "链接:https://xxx 详细说明")。
-
邮件类(.eml/.msg)
特点:
包含发件人、收件人、主题、正文、附件等信息,正文可能有签名、回复历史等冗余内容。
预处理步骤:
提取核心字段:主题、发件人、发送时间、正文;
清洗正文:去除 "回复:""转发:" 等前缀、签名档、重复的历史对话;
附件处理:若附件为文档 / 表格,按对应格式预处理后,关联到邮件主题(如 "附件内容 主题:xxx 正文:xxx")。
文档切分方案

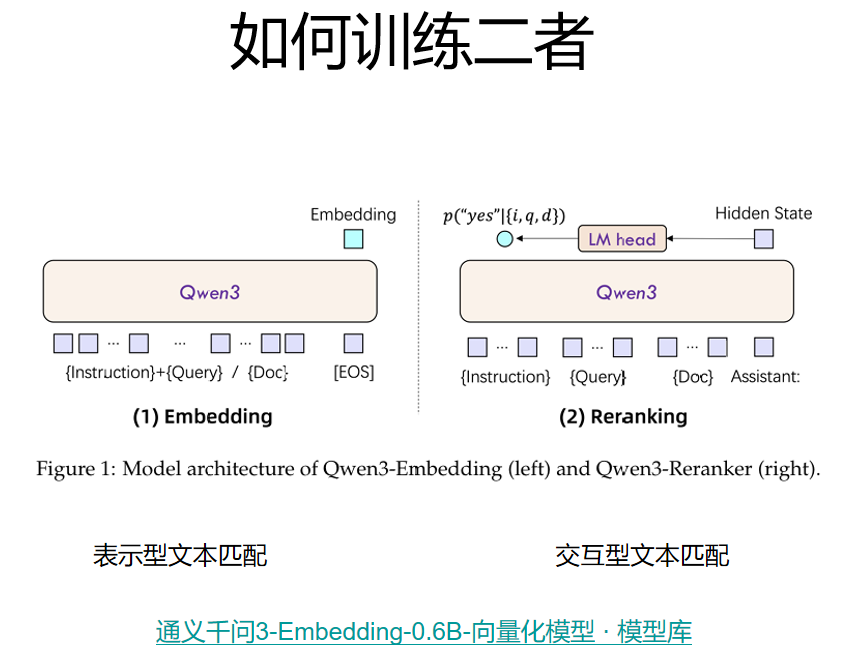
检索模型
Embedding Model
嵌入模型
-
核心作用:
将文本(如用户问题、文档片段)转换为低维稠密向量(Embedding),通过向量间的相似度(如余弦相似度)衡量文本语义相关性,实现快速的初步检索。
-
原理:
模型通过预训练学习到文本的语义表示,语义相近的文本会被映射到向量空间中距离较近的位置。
例如,"猫喜欢吃鱼" 和 "猫咪爱吃鱼" 的向量会非常接近,而与 "狗喜欢啃骨头" 的向量距离较远。
-
常见模型:
OpenAI 的text-embedding-ada-002、BGE 系列、Sentence-BERT、qwen3-embedding等。
-
示例流程:

Reranker Model重排序模型
-
核心作用:
对嵌入模型召回的 Top N 文档进行二次精细排序,修正初步检索的误差,提升最终结果的相关性。
-
原理:
与嵌入模型的 "单文本独立编码" 不同,重排序模型会同时输入问题和文档,通过交叉注意力机制捕捉两者的细粒度语义关联。
例如,嵌入模型可能因字面相似性召回 "RAG 的训练方法",但重排序模型会发现该文档与 "RAG 如何检索" 的问题关联度更低。
-
常见模型:
轻量模型:cross-encoder/ms-marco-MiniLM-L-6-v2(适用于实时场景)。
高精度模型:cross-encoder/ms-marco-TinyBERT-L-2-v2、BAAI/bge-reranker-large。
-
示例流程:

二者关系

结合搜索引擎的RAG
RAG与搜索引擎结合是一种高效的知识获取方案,它既能利用搜索引擎的实时性和广度,又能通过 RAG 的生成能力提供结构化、个性化的回答。应用方式可以分为两种:
-
搜索引擎作为 RAG 的外部知识库
流程:
当用户提问时,系统先调用搜索引擎获取相关网页结果,对结果进行预处理(提取核心文本、去重、分块),再通过 RAG 的嵌入模型和重排序模型筛选优质片段,最后结合大语言模型生成回答。
示例:
用户问 "2024 年人工智能领域的重大突破",系统调用搜索引擎获取 2024 年的最新资讯,提取其中关于 GPT-5、多模态模型等内容,经 RAG 处理后生成结构化总结。
-
RAG 优化搜索引擎的结果展示
流程:
搜索引擎返回的原始结果(如 10 条网页链接)经 RAG 处理后,转换为 "问题 - 答案" 形式的摘要,或按语义聚类(如按 "技术突破""产业应用" 分类),提升用户获取信息的效率。
示例:
搜索 "如何预防流感" 时,RAG 从搜索结果中提取权威医学建议,整理为 "症状识别""预防措施""治疗方法" 三个板块的自然语言回答,而非单纯的链接列表。
搜索引擎RAG注意事项
- 1.网页内容质量把控
优先选择权威来源(如.gov、.edu 域名,或领域内知名网站);
用 RAG 的重排序模型过滤重复内容和与问题无关的片段;
对时效性强的问题(如 "最新政策"),强制筛选近 3 个月的结果。 - 2.性能与效果平衡
合理设置每次检索的关键词(避免过于宽泛导致结果冗余);
对高频重复问题,缓存 RAG 处理后的结果,减少 API 调用;
对热门问题预生成回答,减少实时计算量。 - 3.合规与标注来源
对敏感查询,采用匿名化处理后再调用搜索引擎;
明确告知用户信息来源和数据使用范围,遵守当地数据保护法规;
RAG应用场景







RAG的延伸
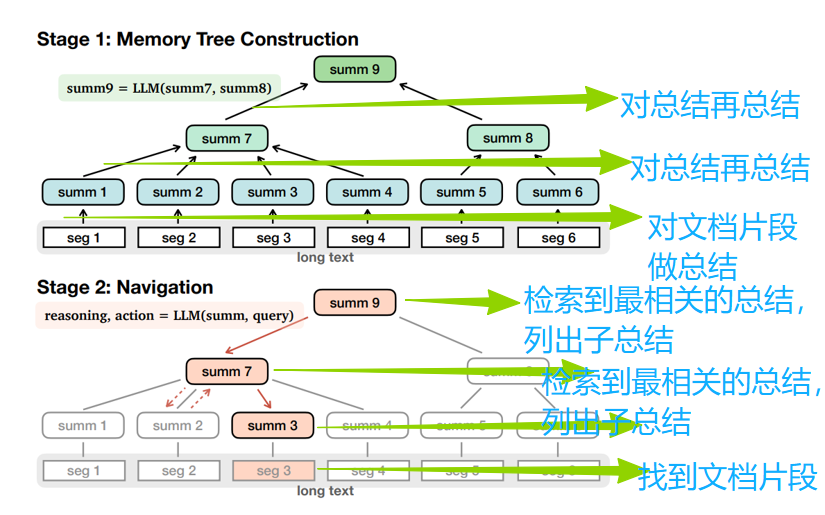
MemWalker
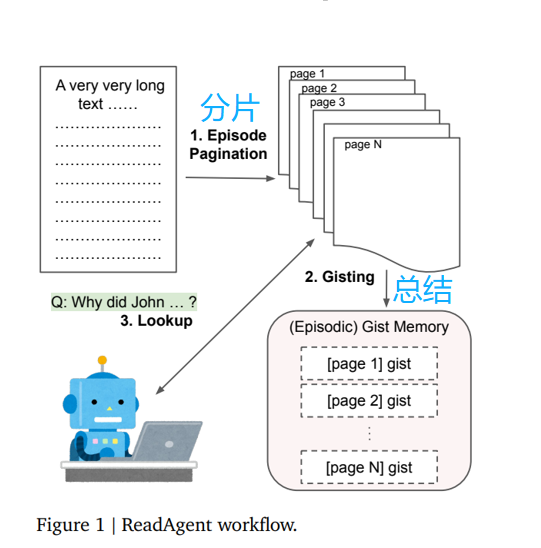
Read Agent
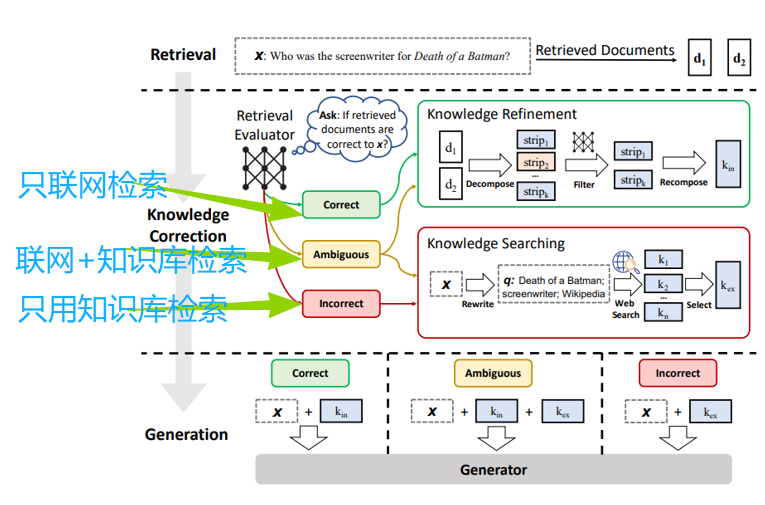
Corrective RAG
self RAG

<bm25.py>
python
import math
from typing import Dict, List
class BM25:
EPSILON = 0.25
PARAM_K1 = 1.5 # BM25算法中超参数
PARAM_B = 0.6 # BM25算法中超参数
def __init__(self, corpus: Dict):
"""
初始化BM25模型
:param corpus: 文档集, 文档集合应该是字典形式,key为文档的唯一标识,val对应其文本内容,文本内容需要分词成列表
"""
self.corpus_size = 0 # 文档数量
self.wordNumsOfAllDoc = 0 # 用于计算文档集合中平均每篇文档的词数 -> wordNumsOfAllDoc / corpus_size
self.doc_freqs = {} # 记录每篇文档中查询词的词频
self.idf = {} # 记录查询词的 IDF
self.doc_len = {} # 记录每篇文档的单词数
self.docContainedWord = {} # 包含单词 word 的文档集合
self._initialize(corpus)
def _initialize(self, corpus: Dict):
"""
根据语料库构建倒排索引
"""
# nd = {} # word -> number of documents containing the word
for index, document in corpus.items():
self.corpus_size += 1
self.doc_len[index] = len(document) # 文档的单词数
self.wordNumsOfAllDoc += len(document)
frequencies = {} # 一篇文档中单词出现的频率
for word in document:
if word not in frequencies:
frequencies[word] = 0
frequencies[word] += 1
self.doc_freqs[index] = frequencies
# 构建词到文档的倒排索引,将包含单词的和文档和包含关系进行反向映射
for word in frequencies.keys():
if word not in self.docContainedWord:
self.docContainedWord[word] = set()
self.docContainedWord[word].add(index)
# 计算 idf
idf_sum = 0 # collect idf sum to calculate an average idf for epsilon value
negative_idfs = []
for word in self.docContainedWord.keys():
doc_nums_contained_word = len(self.docContainedWord[word])
idf = math.log(self.corpus_size - doc_nums_contained_word +
0.5) - math.log(doc_nums_contained_word + 0.5)
self.idf[word] = idf
idf_sum += idf
if idf < 0:
negative_idfs.append(word)
average_idf = float(idf_sum) / len(self.idf)
eps = BM25.EPSILON * average_idf
for word in negative_idfs:
self.idf[word] = eps
@property
def avgdl(self):# 平均每篇文档的长度
return float(self.wordNumsOfAllDoc) / self.corpus_size
def get_score(self, query: List, doc_index):
"""
计算查询 q 和文档 d 的相关性分数
:param query: 查询词列表
:param doc_index: 为语料库中某篇文档对应的索引
"""
k1 = BM25.PARAM_K1
b = BM25.PARAM_B
score = 0
doc_freqs = self.doc_freqs[doc_index]
for word in query:
if word not in doc_freqs:
continue
score += self.idf[word] * doc_freqs[word] * (k1 + 1) / (
doc_freqs[word] + k1 * (1 - b + b * self.doc_len[doc_index] / self.avgdl))
return [doc_index, score]
def get_scores(self, query):
scores = [self.get_score(query, index) for index in self.doc_len.keys()]
return scores<bm25_rag.py>
python
import os
import jieba
from zai import ZhipuAiClient
from bm25 import BM25
'''
基于RAG来介绍Dota2英雄故事和技能
用bm25做召回
同样以智谱的api作为我们的大模型
https://docs.bigmodel.cn/cn/guide/start/model-overview
'''
#智谱的api作为我们的大模型
def call_large_model(prompt):
client = ZhipuAiClient(api_key=os.environ.get("zhipuApiKey")) # 填写您自己的APIKey
response = client.chat.completions.create(
model="glm-4.5", # 填写需要调用的模型名称
messages=[
{"role": "user", "content": prompt},
],
)
response_text = response.choices[0].message.content
return response_text
class SimpleRAG:
def __init__(self, folder_path="Heroes"):
self.load_hero_data(folder_path)
def load_hero_data(self, folder_path):
self.hero_data = {}
for file_name in os.listdir(folder_path):
if file_name.endswith(".txt"):
with open(os.path.join(folder_path, file_name), "r", encoding="utf-8") as file:
intro = file.read()
hero = file_name.split(".")[0]
self.hero_data[hero] = intro
corpus = {}
for hero, intro in self.hero_data.items():
corpus[hero] = jieba.lcut(intro)
self.bm25_model = BM25(corpus)
return
def retrive(self, user_query):
scores = self.bm25_model.get_scores(jieba.lcut(user_query))
sorted_scores = sorted(scores, key=lambda x: x[1], reverse=True)
hero = sorted_scores[0][0]
text = self.hero_data[hero]
return text
def query(self, user_query):
print("user_query:", user_query)
print("=======================")
retrive_text = self.retrive(user_query)
print("retrive_text:", retrive_text)
print("=======================")
prompt = f"请根据以下从数据库中获得的英雄故事和技能介绍,回答用户问题:\n\n英雄故事及技能介绍:\n{retrive_text}\n\n用户问题:{user_query}"
response_text = call_large_model(prompt)
print("模型回答:", response_text)
print("=======================")
if __name__ == "__main__":
rag = SimpleRAG()
user_query = "高射火炮是谁的技能"
rag.query(user_query)
print("----------------")
print("No RAG (直接请求大模型回答):")
print(call_large_model(user_query))<国外开放搜索引擎接口 web_search.py>
python
import os
from exa_py import Exa
#一个国外的搜索引擎接口
#https://dashboard.exa.ai/home
#pip install exa-py
exa = Exa(api_key = os.getenv("EXA_API_KEY"))
result = exa.search_and_contents(
"blog post about AI",
text = True,
type = "auto"
)
print(result.autoprompt_string)FuctionCall和MCP
Function Call
简单来说,Function Call 是 LLM 调用外部工具(如 API、数据库、计算器等)的能力。当 LLM 遇到自身无法直接解决的问题(如实时数据查询、复杂计算、操作硬件等)时,会生成结构化指令(如 JSON 格式),调用对应的函数工具完成任务,再将工具返回的结果整理成自然语言回答。
核心特点:LLM 作为 "决策者",决定何时调用、调用哪个工具,工具负责执行具体操作,两者形成 "决策 - 执行" 闭环。
问题:各家function定义方式不统一
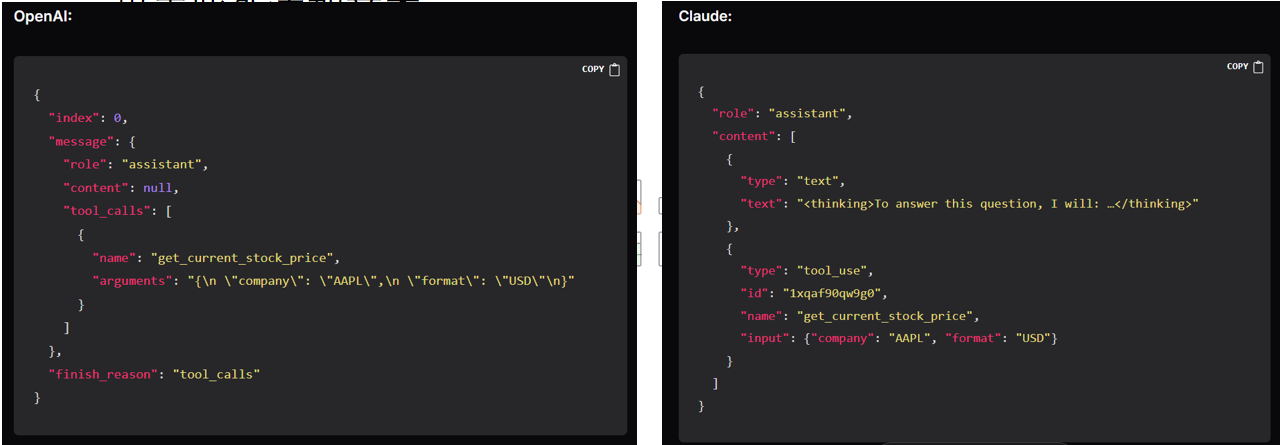
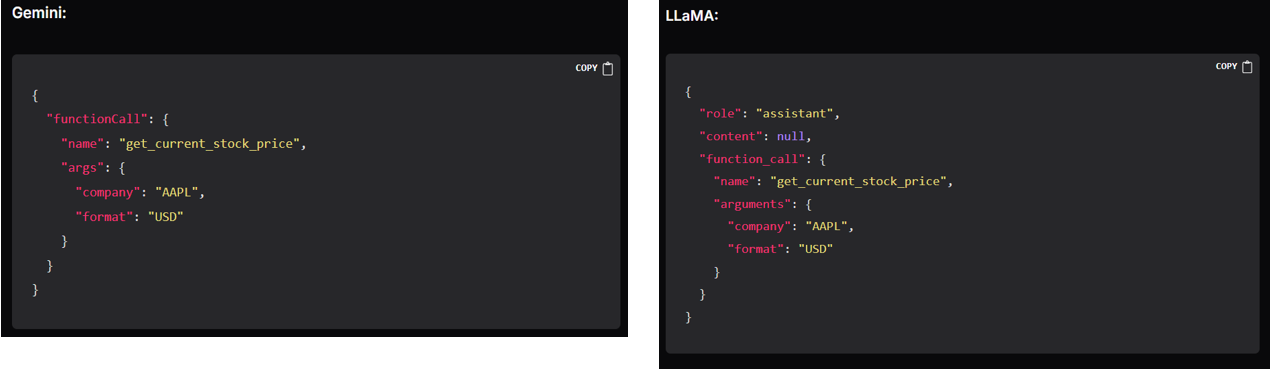
MCP:Model Context Protocol
一套用于function call标准协议
它标准化了应用程序如何向 LLM 提供上下文。将 MCP 想象成用于 AI 应用程序的 USB-C 端口。
正如 USB-C 提供了一种将设备连接到各种外围设备和配件的标准化方式一样,MCP 也提供了一种将 AI 模型连接到不同数据源和工具的标准化方式。
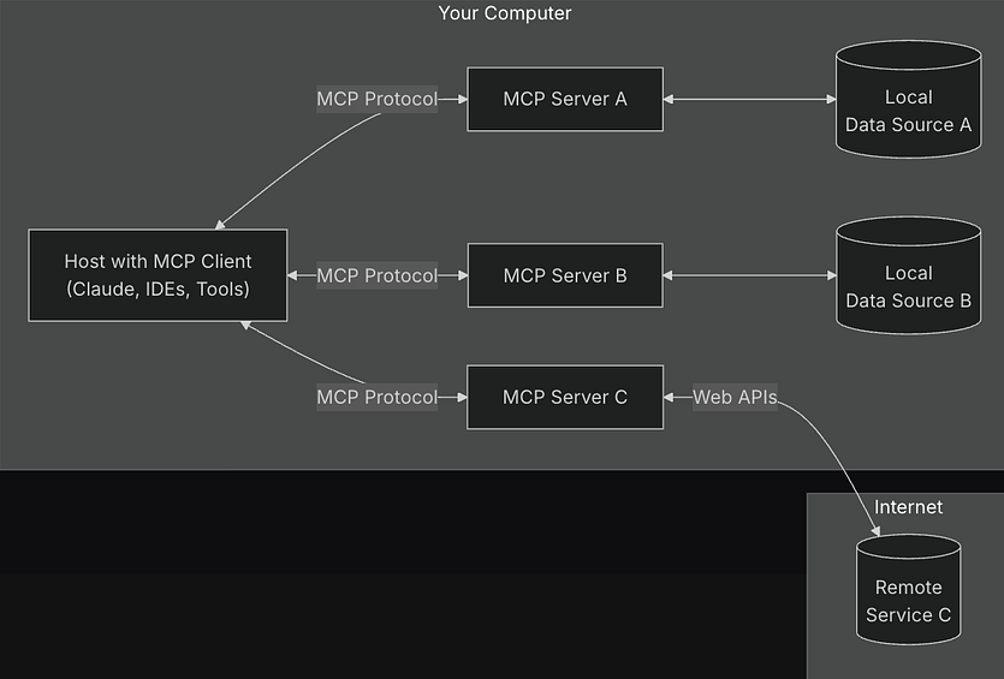
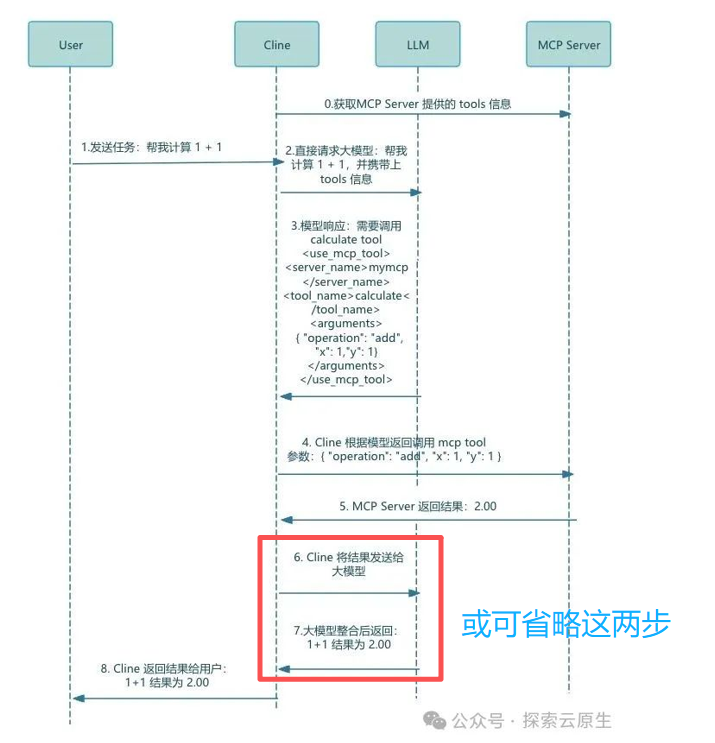
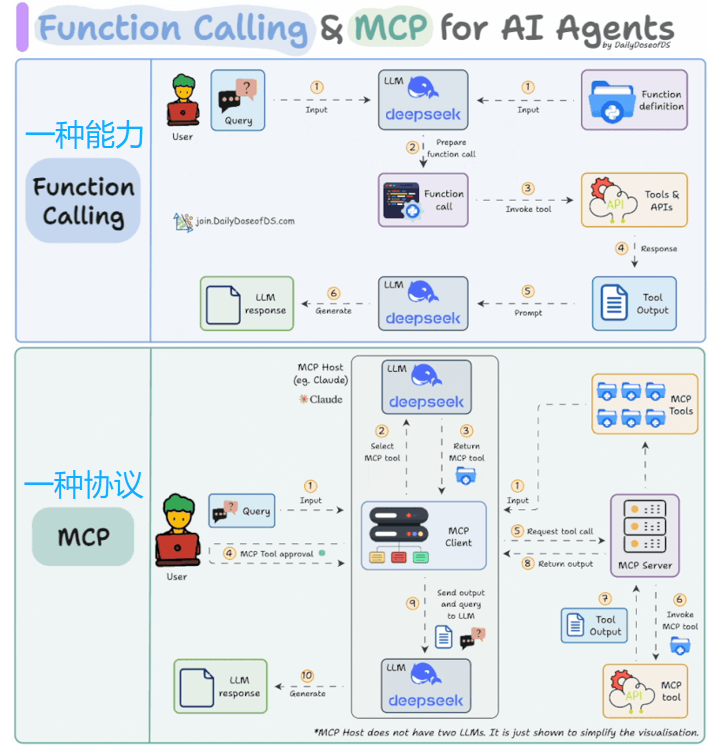
应用
如果不需要使用别人提供的function,那就不需要用mcp协议,自己在内部做function call就可以。
Mcp的价值主要在于与其他人(企业等)对接,共同开发
本质上都是利用LLM的理解能力来使用工具
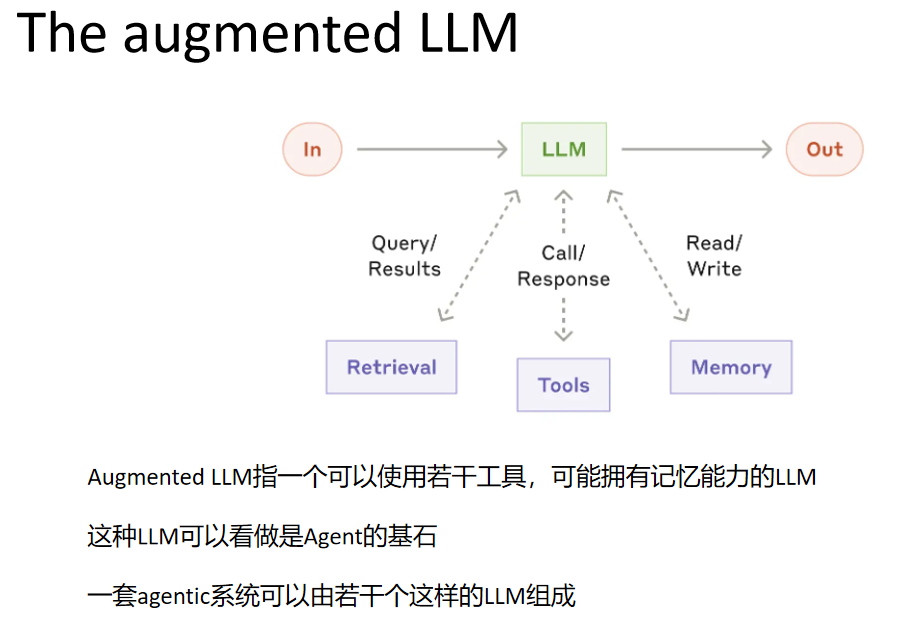
Agent
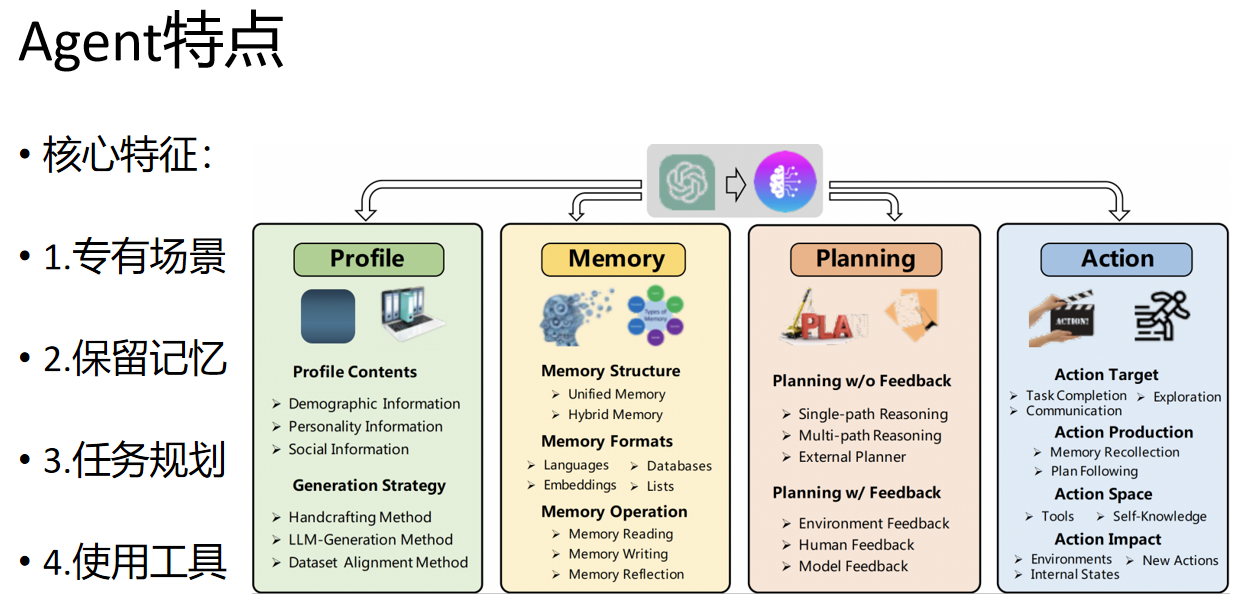
Agent与Workflow
参考文献
Workflow
工作流是通过事先写好的代码路径,编排好的 LLM 和工具的系统
Agent
由LLM动态选择自己的工作流程和工具使用,完成任务的路径不完全是事先写定的。
多个Agent可以组成一套agentic系统
实际上,在目前国内,基于LLM的workflow通常也被称为Agent
- 何时需要agent
使用 LLM 构建应用程序时,我们建议找到尽可能简单的解决方案,并且仅在需要时增加复杂性。
这可能意味着绝大多数情况,根本不需要Agent。
当任务足够复杂,人为设计完成任务的路径变的困难,或工作量极大,则可以设计Agent类系统。
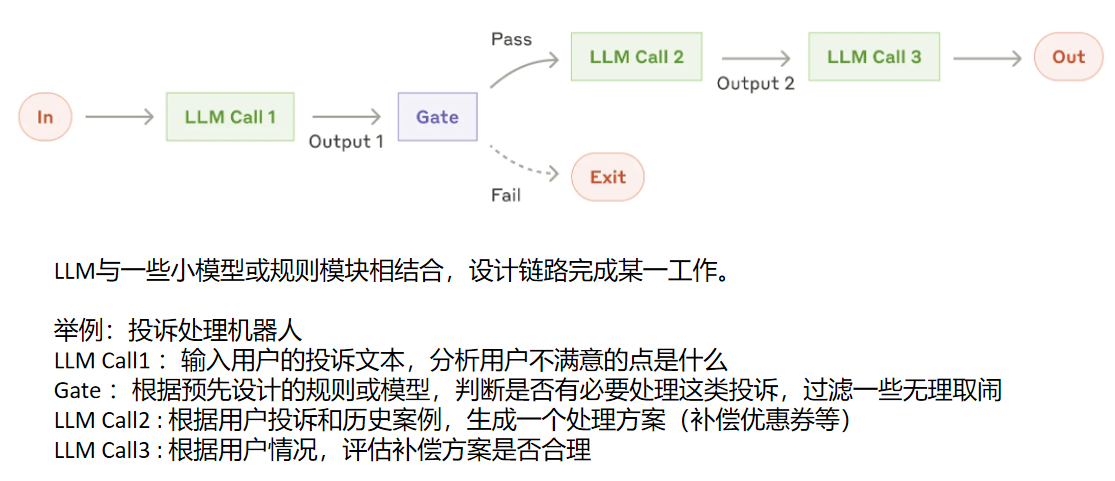
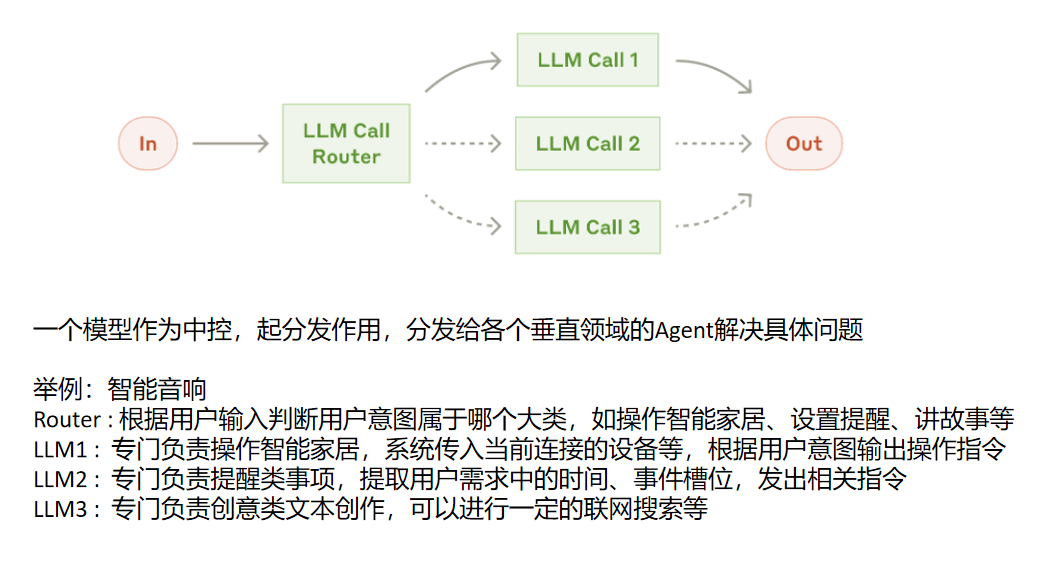
常见Agent系统设计
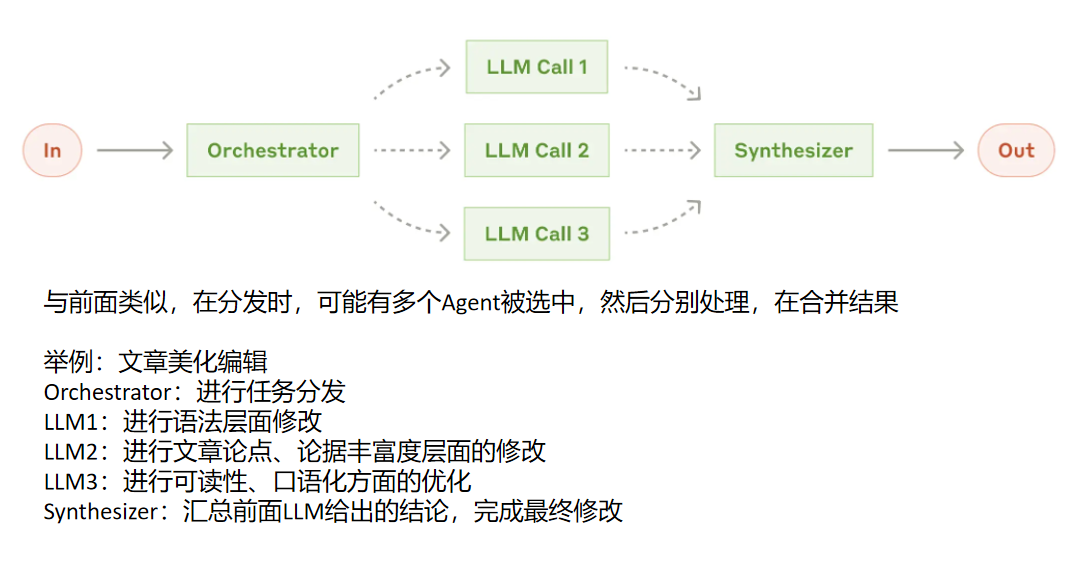
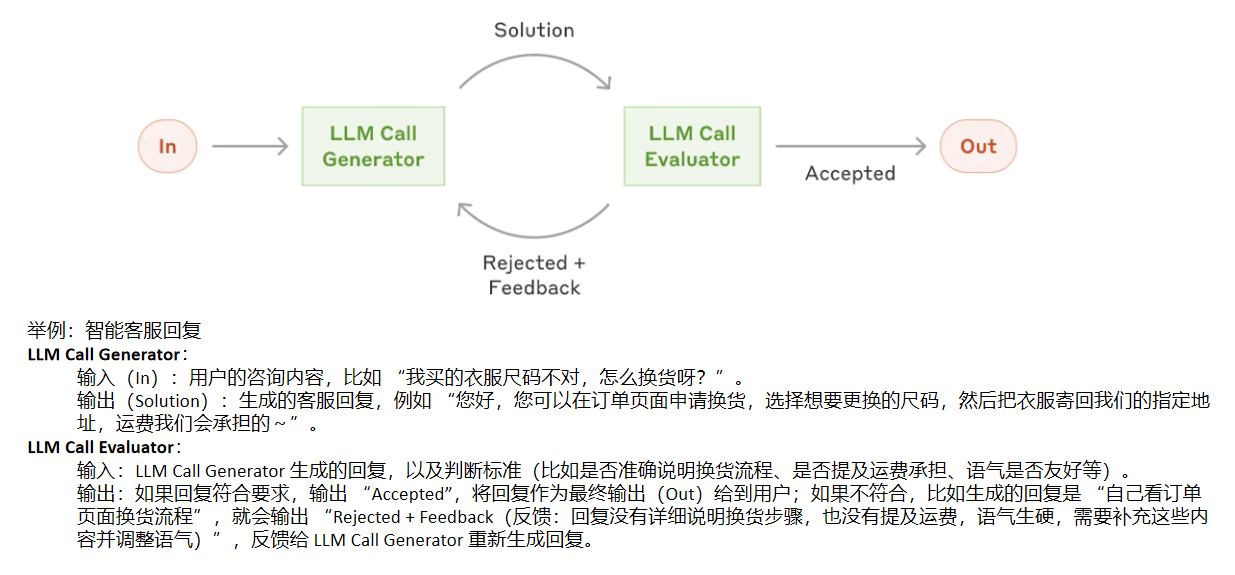
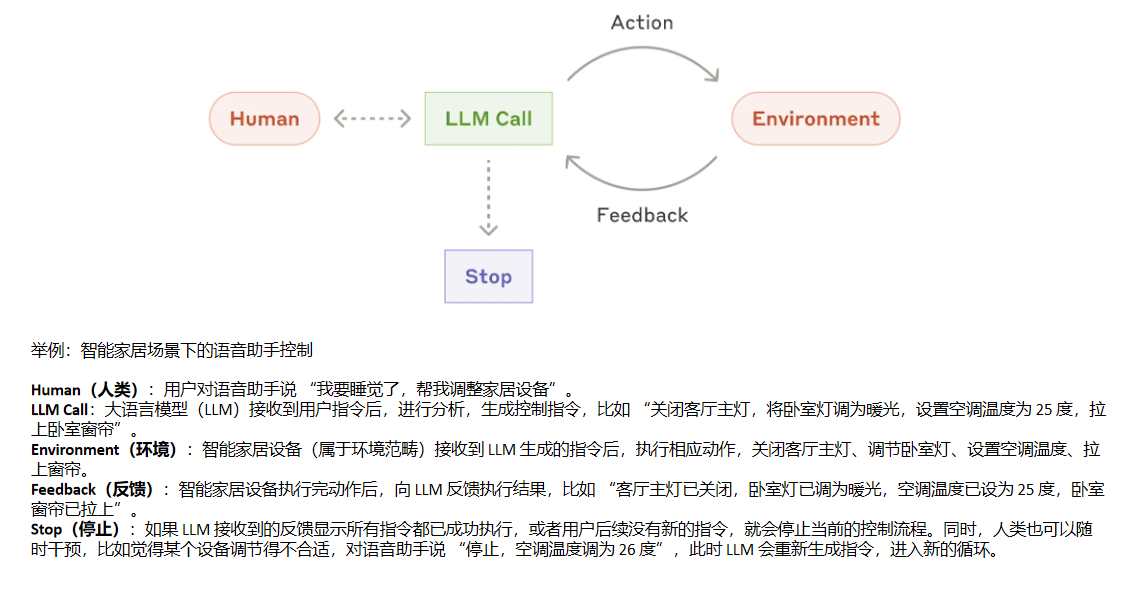
- 举例:AI 编程辅助工具自动生成并优化代码
Human(人类):程序员向工具提出需求,比如 "帮我生成一段 Python 代码,实现从 CSV 文件中读取数据,筛选出年龄大于 30 岁的记录,并计算这些记录的平均薪资"。
LLM Call:大语言模型(LLM)接收到需求后,进行分析,生成对应的 Python 代码,例如:
python
import pandas as pd
""" 读取 CSV 文件"""
df = pd.read_csv('data.csv')
"""筛选年龄大于 30 岁的记录"""
filtered_df = df[df['age'] > 30]
"""计算平均薪资"""
average_salary = filtered_df['salary'].mean()
print(average_salary)-
Environment(环境):代码运行环境(如本地 Python 解释器、在线编程平台等)接收到 LLM 生成的代码后,执行这段代码。
-
Feedback(反馈):代码运行环境向 LLM 反馈运行结果。如果代码运行成功,输出计算得到的平均薪资数值;如果代码存在错误,比如 CSV 文件路径错误、列名写错等,反馈错误信息,如 "FileNotFoundError: Errno 2 No such file or directory: 'data.csv'"。
-
Stop(停止):如果 LLM 接收到的反馈显示代码运行成功,得到了正确的平均薪资结果,或者程序员对生成的代码满意,就会停止当前的代码生成与优化流程。如果反馈显示代码有错误,LLM 会根据错误信息重新生成修正后的代码,进入新的循环;同时,程序员也可以手动干预,比如指出代码的其他优化方向,让 LLM 进一步调整代码。
-
示例:
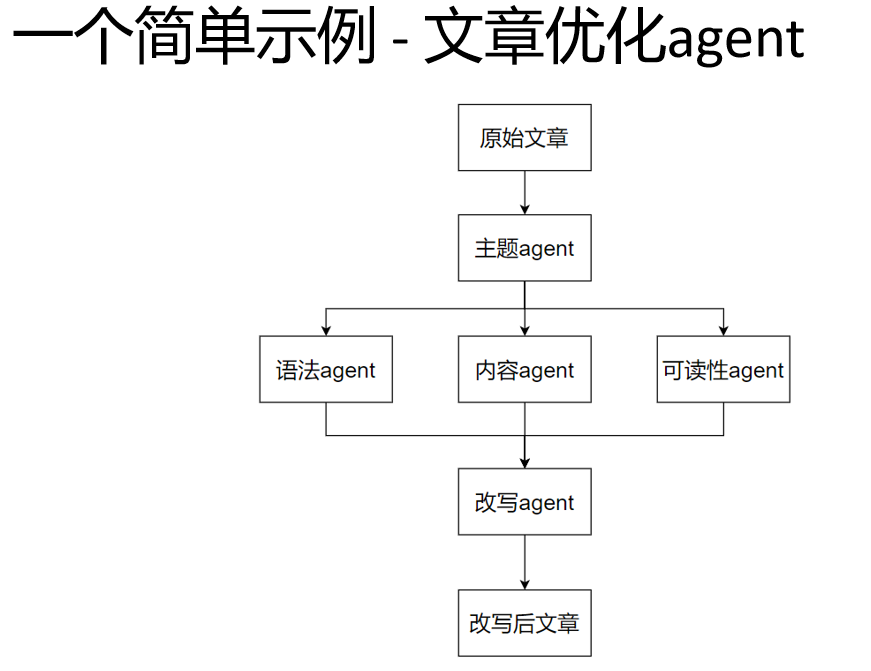
python
#coding:utf-8
import json
from zai import ZhipuAiClient
'''
利用agent思想优化文章
'''
#pip install zhipuai
#https://open.bigmodel.cn/ 注册获取APIKey
def call_large_model(prompt):
client = ZhipuAiClient(api_key=os.environ.get("zhipuApiKey")) #key填入环境变量
response = client.chat.completions.create(
model="glm-3-turbo", # 填写需要调用的模型名称
messages=[
{"role": "user", "content": prompt},
],
)
response_text = response.choices[0].message.content
return response_text
def theme_analysis_agent(article_text):
# 向大模型提问进行文章分析
prompt_analysis = f"请分析并输出以下文章的主题:{article_text}"
# 调用大模型接口,假设返回的结果是一个字典,包含结构和主题信息
theme_analysis_result = call_large_model(prompt_analysis)
return theme_analysis_result
def language_optimization_agent(article_text, theme_analysis_result):
# 根据文章分析结果构建提示词
prompt_language = f"请检查下面这篇文章中的语法错误和用词不当之处,并提出优化建议。建议要尽量简练,不超过100字。\n\n文章主题:{theme_analysis_result}\n\n文章内容:{article_text}"
language_optimization_suggestions = call_large_model(prompt_language)
return language_optimization_suggestions
def content_enrichment_agent(article_text, theme_analysis_result):
# 根据文章分析结果构建提示词
prompt_content = f"请阅读下面这篇文章,根据主题为该文章提出可以进一步扩展和丰富的内容点或改进建议,比如添加案例、引用数据等。建议要尽量简练,不超过100字。\n\n文章主题:{theme_analysis_result}\n\n文章内容:{article_text}"
content_enrichment_suggestions = call_large_model(prompt_content)
return content_enrichment_suggestions
def readability_evaluation_agent(article_text, theme_analysis_result):
# 根据文章分析结果构建提示词
prompt_readability = f"请阅读下面这篇文章,根据主题评估该文章的可读性,包括段落长度、句子复杂度等,提出一些有助于文章传播的改进建议。建议要尽量简练,不超过100字。\n\n文章主题:{theme_analysis_result}\n\n文章内容:{article_text}"
readability_evaluation_result = call_large_model(prompt_readability)
return readability_evaluation_result
def comprehensive_optimization_agent(article, theme_analysis_result, language_optimization_suggestions, content_enrichment_suggestions, readability_evaluation_result):
# 合并结果的逻辑可以是将各个部分的建议整理成一个结构化的文档
final_optimization_plan = f"请阅读下面这篇文章,以及若干个负责专项优化的agent给出的改进建议,重写这篇文章,提升文章的整体质量。\n\n文章原文:{article}\n\n文章主题分析:{theme_analysis_result}\n\n语言优化建议:{language_optimization_suggestions}\n\n内容丰富建议:{content_enrichment_suggestions}\n\n可读改进建议:{readability_evaluation_result}。\n\n优化后文章:"
final_optimization_result = call_large_model(final_optimization_plan)
return final_optimization_result
article = """
2024年8月20日,国产游戏《黑神话:悟空》正式上线,迅速引发了全网的热议与追捧,其火爆程度令人惊叹。黑悟空之所以能如此之火,原因是多方面的。
从文化内涵来看,《黑神话:悟空》深深扎根于中国传统文化。《西游记》作为中国文学的经典之作,孙悟空更是家喻户晓的英雄形象,承载着无数国人的童年回忆和文化情感。该游戏以孙悟空为主角,让玩家能够在游戏中亲身扮演齐天大圣,体验其神通广大与英勇无畏,这种文化认同感和情感共鸣是黑悟空火爆的重要基础。它不仅仅是一款游戏,更像是一场文化的回归与盛宴,让玩家在游戏的世界里重新领略中国神话的魅力,使得传统文化以一种全新的、生动的方式呈现在大众面前。
在视觉呈现方面,黑悟空堪称一场视觉盛宴。制作团队不惜投入大量的时间和精力,运用先进的游戏制作技术,精心打造了美轮美奂的游戏画面。从细腻逼真的环境场景,到栩栩如生的角色形象,再到炫酷华丽的技能特效,每一个细节都展现出了极高的制作水准。无论是神秘奇幻的山林洞穴,还是气势恢宏的天庭宫殿,都仿佛让玩家身临其境,沉浸在一个充满想象力的神话世界之中。这种极致的视觉体验,极大地满足了玩家对于游戏画面品质的追求,也是吸引众多玩家的关键因素之一。
游戏品质上,黑悟空也达到了相当高的水平。它拥有丰富多样且极具挑战性的关卡设计,玩家需要运用智慧和技巧,不断探索、战斗,才能逐步推进游戏进程。角色的技能系统丰富且独特,玩家可以通过不同的技能组合,发挥出孙悟空的各种强大能力,增加了游戏的可玩性和策略性。同时,游戏的剧情紧凑且富有深度,在遵循原著故事框架的基础上,进行了大胆的创新和拓展,为玩家呈现了一个既熟悉又充满新鲜感的西游世界,让玩家在享受游戏乐趣的同时,也能感受到一个精彩绝伦的故事。
再者,宣传推广策略也为黑悟空的火爆添了一把柴。从 2020 年开始,制作方每年 8 月 20 日都会公开最新的实机视频,这些视频在网络上广泛传播,引发了大量关注和讨论,成功地为游戏上线预热造势。在社交媒体上,关于黑悟空的话题热度持续攀升,玩家们纷纷自发地宣传分享,形成了强大的传播效应。此外,针对海外市场,黑悟空也积极开展宣传活动,通过号召海外网友参与视频投稿、与博主合作推广等方式,有效地扩大了游戏在国际上的影响力。
《黑神话:悟空》的火爆并非偶然,而是其在文化内涵、视觉呈现、游戏品质以及宣传推广等多个方面共同发力的结果。它的成功,不仅为国产游戏树立了新的标杆,也证明了中国游戏产业在技术和创意上的巨大潜力。相信在黑悟空的带动下,未来会有更多优秀的国产游戏涌现,推动中国游戏产业不断向前发展,让中国的游戏文化在全球舞台上绽放更加耀眼的光芒。同时,黑悟空也为传统文化的传承与创新提供了新的思路和途径,让传统文化在现代社会中焕发出新的活力与生机。它不仅仅是一款游戏的成功,更是中国文化与现代科技融合发展的一个精彩范例,其影响力必将深远而持久。
"""
theme_analysis_result = theme_analysis_agent(article)
language_optimization_suggestions = language_optimization_agent(article, theme_analysis_result)
content_enrichment_suggestions = content_enrichment_agent(article, theme_analysis_result)
readability_evaluation_result = readability_evaluation_agent(article, theme_analysis_result)
final_optimization_plan = comprehensive_optimization_agent(article, theme_analysis_result, language_optimization_suggestions, content_enrichment_suggestions, readability_evaluation_result)
results = {"主题分析结果": theme_analysis_result, "语言优化建议": language_optimization_suggestions, "内容丰富建议": content_enrichment_suggestions, "可读性评价结果": readability_evaluation_result, "最终优化方案": final_optimization_plan}
#存储json文件
with open('results.json', 'w', encoding='utf-8') as f:
json.dump(results, f, ensure_ascii=False, indent=4)
print(f"最终优化方案:{final_optimization_plan}")Agent应用
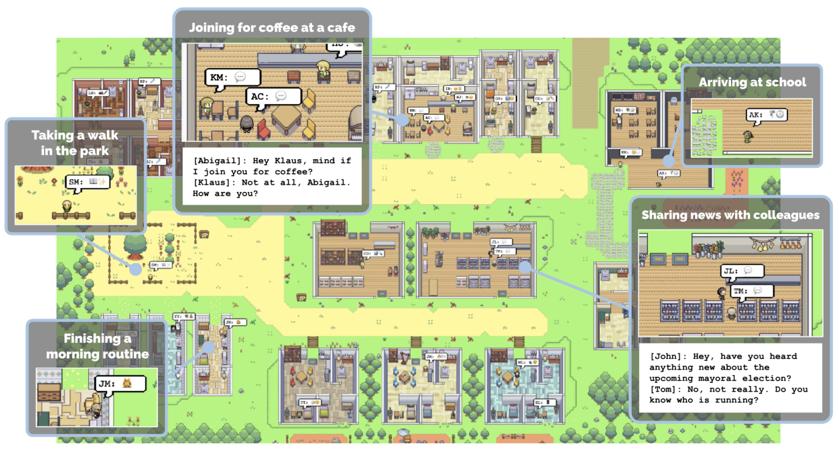
Generative Agents
Agents模仿人类社群
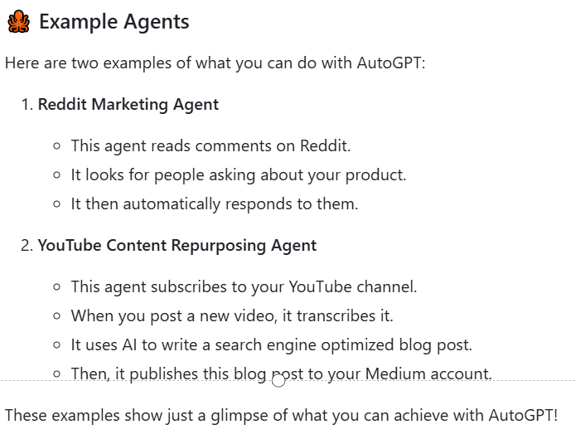
AutoGPT
帮你在线完成任务
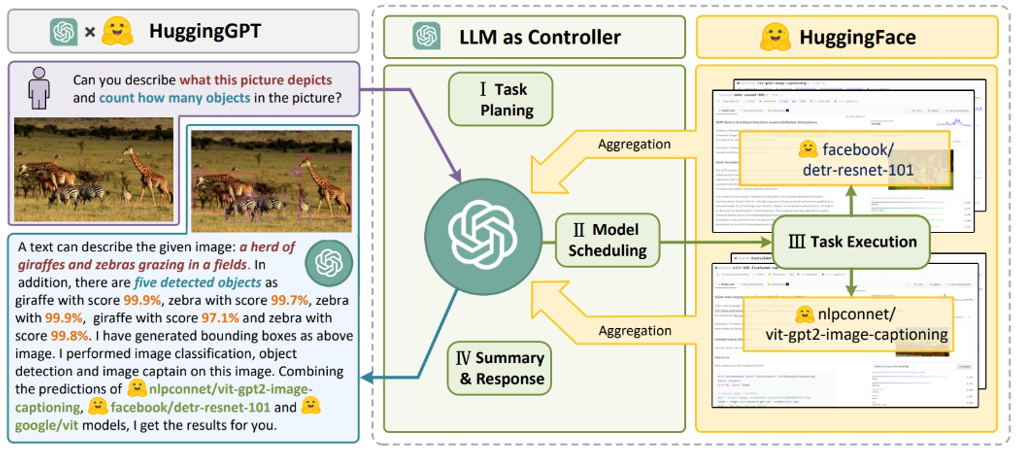
HuggingGPT
由agent根据任务决定去HuggingFace上用哪个模型

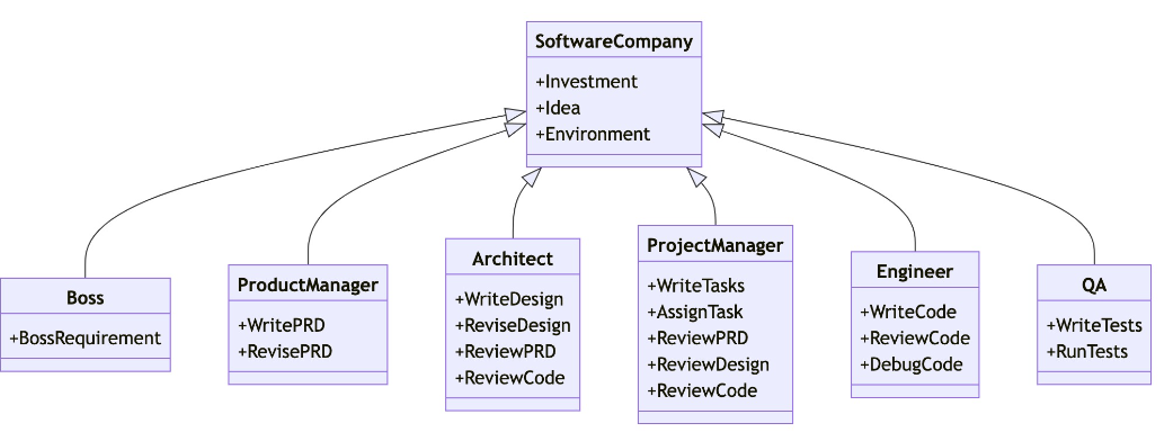
MetaGPT
多agent协作代码开发
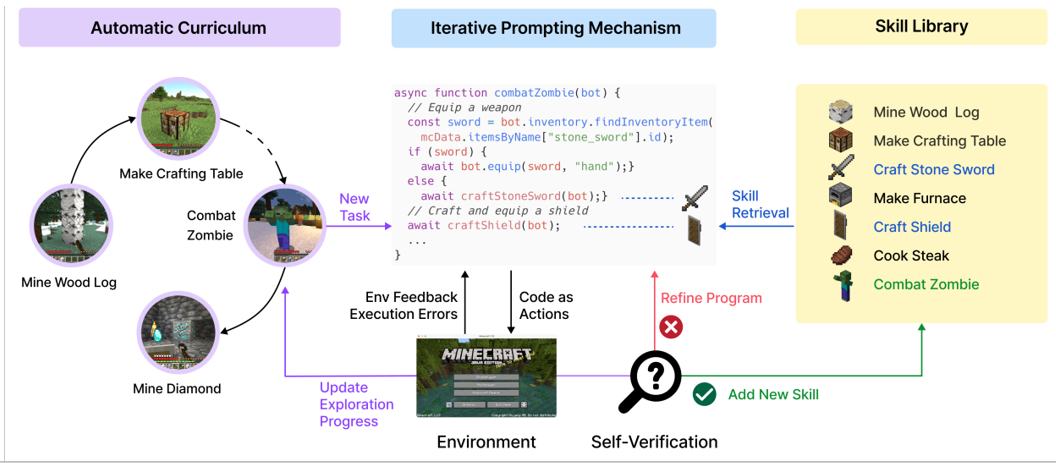
Voyager
用agent学习玩Minecraft游戏
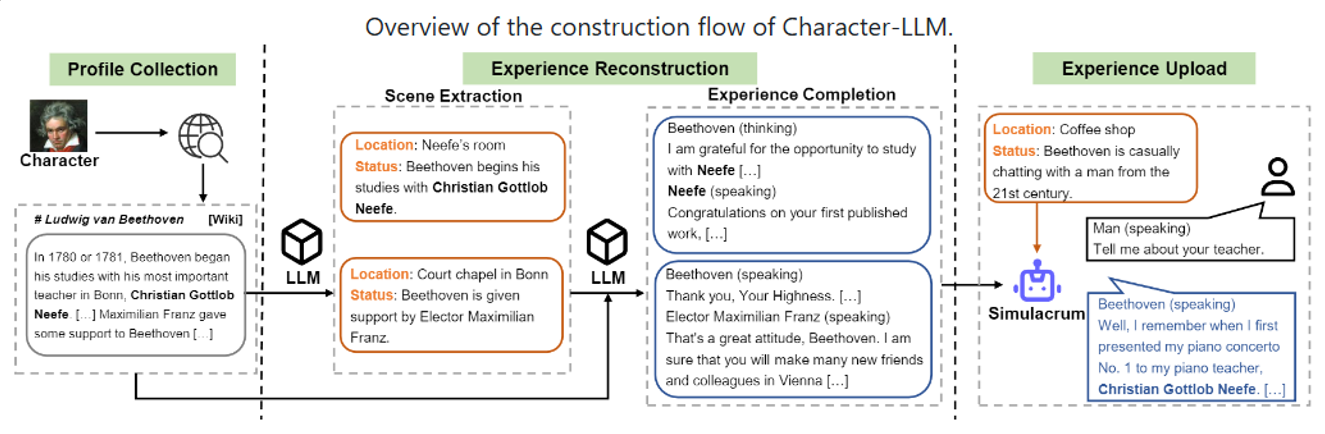
Character-LLM
agent做角色扮演
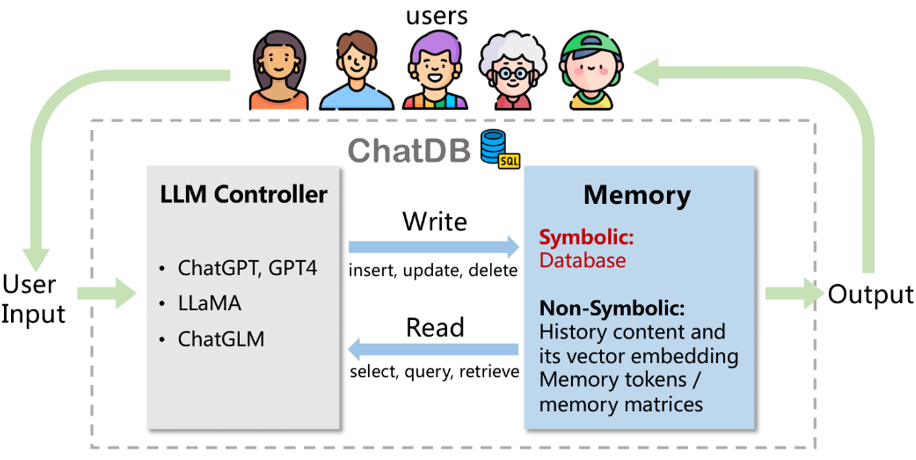
ChatDB
Agent与数据库交互