从零开始实现简易版Netty(七) MyNetty 实现Normal规格的池化内存分配
1. Netty池化内存分配介绍
在上一篇博客中,lab6版本的MyNetty中实现了一个简易的非池化ByteBuf容器,池化内存分配是netty中非常核心也非常复杂的一个功能,没法在一次迭代中完整的实现,MyNetty打算分为4个迭代逐步的将其实现。
按照计划,lab7版本的MyNetty需要实现Normal规格的内存分配。
由于本文属于系列博客,读者需要对之前的博客内容有所了解才能更好地理解本文内容。
- lab1版本博客:从零开始实现简易版Netty(一) MyNetty Reactor模式
- lab2版本博客:从零开始实现简易版Netty(二) MyNetty pipeline流水线
- lab3版本博客:从零开始实现简易版Netty(三) MyNetty 高效的数据读取实现
- lab4版本博客:从零开始实现简易版Netty(四) MyNetty 高效的数据写出实现
- lab5版本博客:从零开始实现简易版Netty(五) MyNetty FastThreadLocal实现
- lab6版本博客:从零开始实现简易版Netty(六) MyNetty ByteBuf实现
在上一篇博客中我们提到,Netty的ByteBuf容器相比jdk的ByteBuffer的最大的一个优势就是实现了池化功能。通过对ByteBuf容器的池化,大幅提高了需要大量创建并回收ByteBuf容器的场景下的性能。
在Netty中对于ByteBuf的池化分为两部分,一个是ByteBuf对象本身的池化 ,另一个则是对ByteBuf背后底层数组所使用内存的池化 。
对于ByteBuf对象的池化,Netty中实现了一个简单的对象池(Recycler类)以支持并发的对象创建与回收,相对简单。而对ByteBuf底层数组使用内存的池化设计则很大程度上参考了jemalloc这一适用于多处理器操作系统内核的内存分配器。
关于jemalloc的工作原理,官方有两篇经典论文,分别是写于2006年的A Scalable Concurrent malloc(3) Implementation for FreeBSD与2011年的scalable-memory-allocation-using-jemalloc。
其中2011年的论文中提到,相比起2006年最初版本的jemalloc,新版本的jemalloc做了进一步的优化,大幅提升了jemalloc的性能与易用性。强烈建议读者在开始着手研究Netty池化内存的工作原理细节之前,先阅读这两篇高屋建瓴的关于jemalloc的论文。掌握了核心的设计理念后,再去看细节能起到事半功倍的作用。
在后续介绍Netty的实现细节时,我也会结合这两篇论文中的内容来进行讲解,个人认为背后的设计理念与实现的细节同样重要,应该争取做到知其然而知其所以然。
2. ByteBuf对象池的实现解析
2.1 池化的ByteBuf分配器(PooledByteBufAllocator)
为了能够让使用者灵活的控制所创建的ByteBuf是否需要池化,Netty抽象出了ByteBufAllocator这一接口。使用者可以通过其对应的接口来创建ByteBuf,而不用特别关心其底层的实现。
MyNetty池化的ByteBuf分配器实现
- 从下面展示的MyPooledByteBufAllocator的源码中可以看到,用于分配池化ByteBuf的功能主要集中在子类的newHeapBuffer方法中。
该方法中为当前线程分配一个固定的PoolArena,再通过选中的PoolArena去进行实际的分配。 - 熟悉前面提到的jemalloc论文的读者可以看到,Netty中的PoolArena其实就对应着jemalloc中反复提到的Arena的概念。
"Application threads are assigned arenas in round-robin fashion upon first allocating a small/large object. Arenas are completely independent of each other. They maintain their own chunks, from which they carve page runs for small/large objects."
"应用线程在首次分配small或large对象时,使用round-robin轮训为其分配一个arena。不同的Arena彼此之间完全独立。Arena维护独属于它自己的Chunk集合,从中切割出连续的页段用于分配small或large对象。" - Netty参考jemalloc也实现了Arena与线程的绑定关系,并且通过FastThreadLocal实现了ByteBuf线程缓存的能力。
因为Arena与线程是一对多的关系,通过Arena来分配池化内存,必然会因为要变更Arena的内部元数据(trace metadata)而需要加锁防并发。通过线程级别的池化能力,可以以略微增加内存碎片为代价,减少同步竞争而大幅增加池化内存分配的吞吐量。
"The main goal of thread caches is to reduce the volume of synchronization events."
"引入线程缓存的主要目的是减少同步事件的量。" - MyNetty中分为3个迭代来完成池化ByteBuf的功能,线程缓存的功能被放在了最后一个迭代,也就是lab9中去实现。
在本篇博客(lab7),MyNetty聚焦于PoolArena的内部实现,所以直接简单的设置所有线程共用同一个PoolArena。并且与lab6一致,简单起见只实现了HeapByteBuf相关的池化,不考虑DirectByteBuf相关的功能。
java
public abstract class MyAbstractByteBufAllocator implements MyByteBufAllocator{
// 。。。 已省略无关逻辑
static final int DEFAULT_INIT_CAPACITY = 256;
static final int DEFAULT_MAX_CAPACITY = Integer.MAX_VALUE;
static final int CALCULATE_THRESHOLD = 1048576 * 4; // 4 MiB page
@Override
public MyByteBuf heapBuffer() {
// 以默认参数值创建一个heapBuffer
return newHeapBuffer(DEFAULT_INIT_CAPACITY,DEFAULT_MAX_CAPACITY);
}
@Override
public MyByteBuf heapBuffer(int initialCapacity) {
return heapBuffer(initialCapacity,DEFAULT_MAX_CAPACITY);
}
@Override
public MyByteBuf heapBuffer(int initialCapacity, int maxCapacity) {
// 简单起见,不实现netty里空buf优化
// capacity参数校验
validate(initialCapacity, maxCapacity);
return newHeapBuffer(initialCapacity,maxCapacity);
}
}
java
public class MyPooledByteBufAllocator extends MyAbstractByteBufAllocator{
private final MyPoolArena<byte[]>[] heapArenas;
public MyPooledByteBufAllocator() {
// 简单起见,Arena数量写死为1方便测试,后续支持与线程绑定后再拓展为与处理器数量挂钩
int arenasNum = 1;
// 初始化好heapArena数组
heapArenas = new MyPoolArena.HeapArena[arenasNum];
for (int i = 0; i < heapArenas.length; i ++) {
MyPoolArena.HeapArena arena = new MyPoolArena.HeapArena(this);
heapArenas[i] = arena;
}
}
@Override
protected MyByteBuf newHeapBuffer(int initialCapacity, int maxCapacity) {
// 简单起见,Arena数量写死为1方便测试,后续支持与线程绑定后再拓展为与处理器数量挂钩
MyPoolArena<byte[]> targetArena = heapArenas[0];
return targetArena.allocate(initialCapacity, maxCapacity);
}
}2.2 从对象池中获取ByteBuf对象
- PoolArena中生成可用PooledByteBuf的方法中,只做了两件事情。
首先是从ByteBuf的对象池中获得一个ByteBuf对象,然后再为这个对象的底层数组分配相匹配的内存。本小节,我们主要探讨前一个操作。 - 获取ByteBuf对象逻辑是在PooledHeapByteBuf.newInstance方法中,通过一个全局的ObjectPool对象池来获得(RECYCLER.get())。
获取到一个可用的ByteBuf对象后,通过PooledHeapByteBuf的reuse方法,将自身内部的读写指针等内部属性重新初始化一遍,避免被之前的数据污染。
java
public class MyPoolArena{
// 。。。 已省略无关逻辑
/**
* 从当前PoolArena中申请分配内存,并将其包装成一个PooledByteBuf返回
* */
MyPooledByteBuf<T> allocate(int reqCapacity, int maxCapacity) {
// 从对象池中获取缓存的PooledByteBuf对象
MyPooledByteBuf<T> buf = newByteBuf(maxCapacity);
// 为其分配底层数组对应的内存
allocate(buf, reqCapacity);
return buf;
}
public static final class HeapArena extends MyPoolArena<byte[]>{
@Override
protected MyPooledByteBuf<byte[]> newByteBuf(int maxCapacity) {
return MyPooledHeapByteBuf.newInstance(maxCapacity);
}
}
}
java
public class MyPooledHeapByteBuf extends MyPooledByteBuf<byte[]>{
// 。。。 已省略无关逻辑
private static final MyObjectPool<MyPooledHeapByteBuf> RECYCLER = MyObjectPool.newPool(
new MyObjectPool.ObjectCreator<MyPooledHeapByteBuf>() {
@Override
public MyPooledHeapByteBuf newObject(MyObjectPool.Handle<MyPooledHeapByteBuf> handle) {
return new MyPooledHeapByteBuf(handle, 0);
}
});
MyPooledHeapByteBuf(MyObjectPool.Handle<? extends MyPooledHeapByteBuf> recyclerHandle, int maxCapacity) {
super(recyclerHandle, maxCapacity);
}
public static MyPooledHeapByteBuf newInstance(int maxCapacity) {
MyPooledHeapByteBuf buf = RECYCLER.get();
buf.reuse(maxCapacity);
return buf;
}
}
java
public abstract class MyPooledByteBuf<T> extends MyAbstractReferenceCountedByteBuf {
// 。。。 已省略无关逻辑
/**
* 一个PooledByteBuf在回归对象池后,再重新被拿出来作为一个新的ByteBuf使用。需要进行一系列的重置操作
* */
final void reuse(int maxCapacity) {
// 设置新的maxCapacity
maxCapacity(maxCapacity);
// 释放后,再重新被复用,refCnt重置为1
setRefCnt(1);
// 读指针,写指针,以及对应的marks指针都设置为0
this.readerIndex(0);
this.writerIndex(0);
discardMarks();
}
}2.3 ByteBuf简易对象池内部实现解析
下面我们来分析ByteBuf对象池的内部工作原理。作为一个对象池,我们主要关注获取对象与归还对象两部分的逻辑。
获取对象
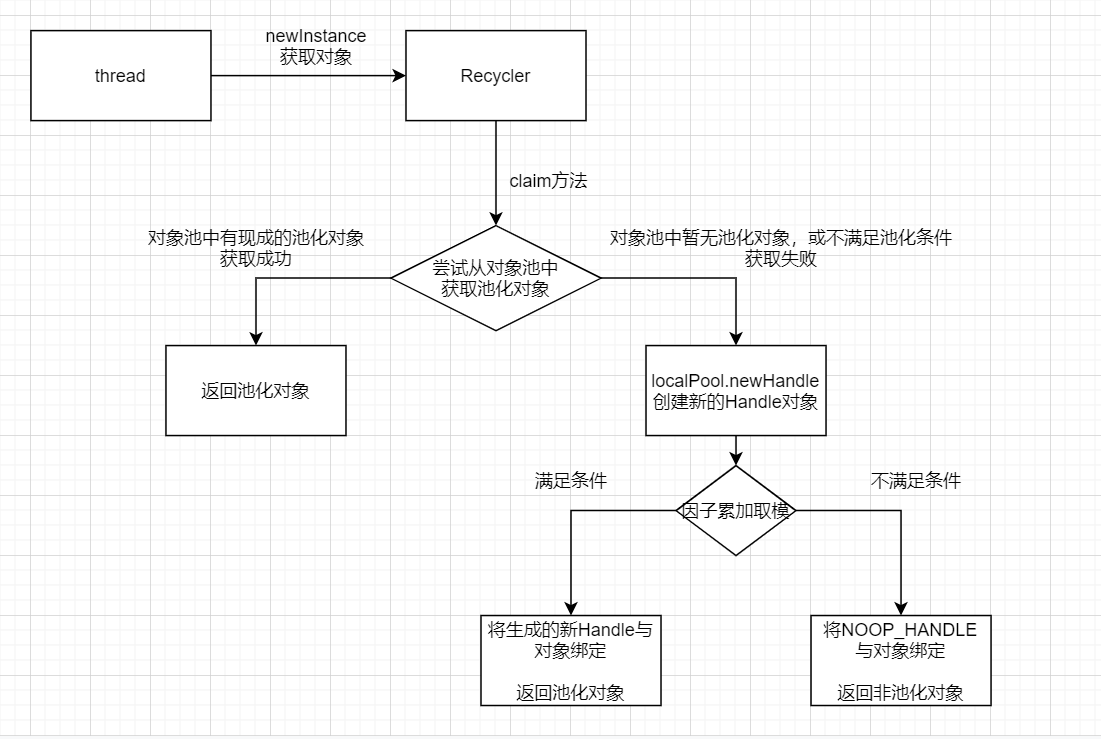
- 获取对象的逻辑入口在Recycler类的get方法。jemalloc的论文中提到,线程本地缓存在减少同步竞争的同时,也会增加内存碎片,因此netty中不允许线程不加节制的缓存ByteBuf对象。
netty允许通过系统参数io.netty.recycler.maxCapacityPerThread来配置每个线程所能缓存的最大ByteBuf对象数量。特别的,当其为0时则代表ByteBuf不使用线程缓存,每次获取都创建一个新的对象。 - 每个线程的本地缓存存储在FastThreadLocal类型的LocalPool中,LocalPool内部持有了一个MessagePassingQueue队列来存放池化对象。
MessagePassingQueue是一个线程安全的队列,特别适合于多写单读 的场景。因为每个线程都只通过独属于线程自己的LocalPool获取池化对象,但最终释放并归还池化对象的线程可以是任意线程,因此使用MessagePassingQueue是性能最佳的。
这一点与jemalloc获取与释放池化内存的逻辑是一致的。"Freed memory is always returned to the arena from which it came, regardless of which thread performs the deallocation." - 通过线程缓存维护池化对象是一种用于提升吞吐量的机制,其并非万能药。在对性能要求不高的场景中,无脑的进行线程缓存会浪费内存。
因此,netty中默认只有FastThreadLocalThread这种netty中独有的线程类型才进行缓存,但也可以通过配置系统参数(io.netty.recycler.batchFastThreadLocalOnly=false)允许所有类型的线程都进行缓存。 - 获取对象时,LocalPool可能为空,不一定能获取到可用的池化对象。这时便需要new一个新的池化对象出来。
netty中引入了一个分配因子,在所有的new新对象的申请中,默认只有一小部分(1/8)的请求会生成池化对象,而大部分情况下生成的都是无需池化,即释放时不归还到对象池中的普通对象(NOOP_HANDLE)。
这样做的目的是希望在分配对象的吞吐量与内存碎片之间获得一个平衡,让空间与时间的取舍达到相对的平衡。
归还对象
- 生成池化对象时,会将一个Handle对象通过构造函数注入给池化对象(比如PooledByteBuf),而后在池化对象被释放时(比如PooledByteBuf的deallocate方法),通过Handle的recycle方法将该对象归还到所属的对象池中。
获取池化对象流程图
java
/**
* 参考自Netty 4.1.118的Recycler类,但做了一定的简化
* */
public abstract class MyRecycler<T> {
/**
* 每个线程最多可以池化缓存的对象数量。因为内存是有限的,不能无限制的池化。所以需要用户基于开启的线程数和所池化缓存对象的平均内存大小来设置
* maxCapacityPerThread也可以被设置为0,来标识不进行池化
*
* netty里可以基于构造函数指定,但一般基于系统参数io.netty.recycler.maxCapacityPerThread来控制,简单起见直接写死
* */
private final int maxCapacityPerThread = 4096;
/**
* netty里可以基于构造函数指定,但一般基于系统参数io.netty.recycler.ratio控制,简单起见直接写死
* */
private final int interval = 8;
/**
* netty里可以基于构造函数指定,但一般基于系统参数io.netty.recycler.chunkSize控制,简单起见直接写死
* */
private final int chunkSize = 32;
/**
* 是否只有FastThreadLocal类型的线程才进行byteBuf的池化
* */
private static final boolean BATCH_FAST_TL_ONLY = true;
private final MyFastThreadLocal<LocalPool<T>> threadLocal = new MyFastThreadLocal<LocalPool<T>>() {
@Override
protected LocalPool<T> initialValue() {
return new LocalPool<T>(maxCapacityPerThread, interval, chunkSize);
}
@Override
protected void onRemoval(LocalPool<T> value) throws Exception {
super.onRemoval(value);
MessagePassingQueue<DefaultHandle<T>> handles = value.pooledHandles;
value.pooledHandles = null;
value.owner = null;
handles.clear();
}
};
protected abstract T newObject(Handle<T> handle);
/**
* 获取池化对象
* 1. 优先从线程本地对象池LocalPool获取
* 对象池本身内部很复杂,获取池化对象时一般都要加同步锁防止并发。引入LocalPool的目的是为了尽可能的无锁化,提高效率
* 2. 每个线程能池化的对象个数是有限的(maxCapacityPerThread控制)
* 3. 不是所有类型的线程都能持有池化对象(默认配置只有netty的FastThreadLocalThread才行)
*
* 第2和3设计的目的都是为了避免过多的池化对象导致占用过多的内存
* */
public final T get() {
if (maxCapacityPerThread == 0) {
// netty中maxCapacityPerThread是可以动态配置的。如果每个线程池化的个数为0,就不需要进行池化,返回一个持有NOOP_HANDLE的对象做降级兼容(逻辑上是非池化的)。NOOP_HANDLE在回收时recycle方法里什么也不做
return newObject((Handle<T>) NOOP_HANDLE);
}
// 获得当前线程自己独有的threadLocal本地对象池
LocalPool<T> localPool = threadLocal.get();
// 从本地对象池中尝试获取一个可用的对象出来
DefaultHandle<T> handle = localPool.claim();
T obj;
if (handle == null) {
// 为null说明线程本地对象池中拿不出来可用的池化对象
// 调用newHandle尝试创建一个handle
handle = localPool.newHandle();
if (handle != null) {
// 获取handle句柄成功,由子类实现newObject方法创建需要池化的对象(比如new一个PooledHeapByteBuf对象)
obj = newObject(handle);
// 将handle句柄与创建出来的池化对象进行绑定
handle.set(obj);
} else {
// 创建handle句柄失败,返回一个逻辑上非池化的对象(newHandle里控制了创建需要池化的对象的比例)
obj = newObject((Handle<T>) NOOP_HANDLE);
}
} else {
// 线程本地对象池中可以拿出来一个可用的对象,直接返回
obj = handle.get();
}
return obj;
}
private static final class LocalPool<T> implements MessagePassingQueue.Consumer<DefaultHandle<T>>{
/**
* 当前LocalPool中队列所缓存的最大handle个数(有batch和pooledHandles两个队列,有并发时好像会略高于这个值)
* */
private final int chunkSize;
private final ArrayDeque<DefaultHandle<T>> batch;
private volatile Thread owner;
private volatile MessagePassingQueue<DefaultHandle<T>> pooledHandles;
/**
* 创建池化对象的比例(默认是8)
* */
private final int ratioInterval;
/**
* 配合ratioInterval比例功能的计数器,在newHandle方法中有用到
* */
private int ratioCounter;
@SuppressWarnings("unchecked")
LocalPool(int maxCapacity, int ratioInterval, int chunkSize) {
this.ratioInterval = ratioInterval;
this.chunkSize = chunkSize;
batch = new ArrayDeque<>(chunkSize);
Thread currentThread = Thread.currentThread();
// owner = !BATCH_FAST_TL_ONLY || currentThread instanceof MyFastThreadLocalThread ? currentThread : null;
if(!BATCH_FAST_TL_ONLY){
// 配置中指定了不只有FastThreadLocal类型的线程才能池化,说明所有类型的线程都能池化
owner = currentThread;
}else{
// 配置了只有FastThreadLocal类型的线程才能池化,判断一下currentThread的类型
if(currentThread instanceof MyFastThreadLocalThread){
owner = currentThread;
}else{
// 非FastThreadLocalThread类型的线程不能池化
owner = null;
}
}
// netty这里有多种配置来设置不同类型的队列,这里简单起见直接写死一种
// Mpsc即MultiProducerSingleConsumer,多写一读的队列
// 别的线程在将handle释放时,将其写入该队列中。而owner线程则负责消费读取该队列,将别的线程释放的对象往batch里存
pooledHandles = (MessagePassingQueue<DefaultHandle<T>>) new MpscChunkedArrayQueue<T>(chunkSize, maxCapacity);
// 初始化时令ratioCounter = ratioInterval。确保第一次newHandle被调用时,创建的是可被回收的池化对象
ratioCounter = ratioInterval; // Start at interval so the first one will be recycled.
}
/**
* 从本地对象池中尝试获取一个可池化对象的handle句柄
* */
DefaultHandle<T> claim() {
MessagePassingQueue<DefaultHandle<T>> handles = pooledHandles;
if (handles == null) {
// pooledHandles为空,说明持有该LocalPool的线程已经被关闭了,所以被设置为了null(release方法里的逻辑)
// 没法去缓存池化对象了,返回null
return null;
}
if (batch.isEmpty()) {
// 本地缓存的对象为空,从handles里面尝试获取一批可池化对象,放到batch队列里(chunkSize控制个数)
handles.drain(this, chunkSize);
}
// 从本地缓存的对象池里获取一个handle句柄
DefaultHandle<T> handle = batch.pollLast();
if (null != handle) {
handle.toClaimed();
}
return handle;
}
/**
* 池化对象回收时,尝试将其放回本地对象池中
* */
void release(DefaultHandle<T> handle) {
// 回收时进行状态的判断,避免重复回收,提前发现bug
handle.toAvailable();
// owner线程是持有当前localPool对象池的线程
Thread owner = this.owner;
if (owner != null && Thread.currentThread() == owner && batch.size() < chunkSize) {
// 如果是当前线程用完了进行回收,并且batch队列里缓存的池化对象数量小于chunkSize,则将其放回到LocalPool里
accept(handle);
} else if (owner != null && isTerminated(owner)) {
// 如果持有LocalPool的线程已经被杀掉了(isTerminated),清空当前LocalPool的pooledHandles
// 防止claim方法里继续去获取池化对象
this.owner = null;
pooledHandles = null;
} else {
// 释放对象的线程不是持有LocalPool的线程,通过pooledHandles内存队列将其异步的放回到该LocalPool里去
MessagePassingQueue<DefaultHandle<T>> handles = pooledHandles;
if (handles != null) {
handles.relaxedOffer(handle);
}
}
}
private static boolean isTerminated(Thread owner) {
// Do not use `Thread.getState()` in J9 JVM because it's known to have a performance issue.
// See: https://github.com/netty/netty/issues/13347#issuecomment-1518537895
// return PlatformDependent.isJ9Jvm() ? !owner.isAlive() : owner.getState() == Thread.State.TERMINATED;
// 用的java8,简单起见直接判断状态
return owner.getState() == Thread.State.TERMINATED;
}
DefaultHandle<T> newHandle() {
if (++ratioCounter >= ratioInterval) {
// 基于ratioInterval创建可回收的池化对象
ratioCounter = 0; // 重置计数器,实现按比例生成可回收的池化对象
return new DefaultHandle<>(this);
}
// 生成的是不回收的对象(get方法里调用的地方做了判断)
return null;
}
@Override
public void accept(DefaultHandle<T> tDefaultHandle) {
// 将可池化的对象handle,放到本地缓存的batch队列里
batch.addLast(tDefaultHandle);
}
}
private static final class DefaultHandle<T> implements Handle<T> {
private static final int STATE_CLAIMED = 0;
private static final int STATE_AVAILABLE = 1;
private static final AtomicIntegerFieldUpdater<DefaultHandle<?>> STATE_UPDATER;
private volatile int state;
private final LocalPool<T> localPool;
private T value;
static {
AtomicIntegerFieldUpdater<?> updater = AtomicIntegerFieldUpdater.newUpdater(DefaultHandle.class, "state");
// noinspection unchecked
STATE_UPDATER = (AtomicIntegerFieldUpdater<DefaultHandle<?>>) updater;
}
DefaultHandle(LocalPool<T> localPool) {
this.localPool = localPool;
}
@Override
public void recycle(Object object) {
if (object != this.value) {
throw new IllegalArgumentException("object does not belong to handle");
} else {
// handle句柄被释放时,将其放回到本地缓存LocalPool中
this.localPool.release(this);
}
}
void toClaimed() {
assert state == STATE_AVAILABLE;
STATE_UPDATER.lazySet(this, STATE_CLAIMED);
}
T get() {
return this.value;
}
void set(T value) {
this.value = value;
}
void toAvailable() {
int prev = STATE_UPDATER.getAndSet(this, 1);
if (prev == 1) {
throw new IllegalStateException("Object has been recycled already.");
}
}
}
/**
* 为什么弄了个子interface?我的理解是类的内部引用起来更方便,也可以在未来进行进一步的拓展(基于4.1.80),更高版本的弄了个EnhancedHandle
* */
public interface Handle<T> extends MyObjectPool.Handle<T> { }
private static final Handle<?> NOOP_HANDLE = new Handle<Object>() {
@Override
public void recycle(Object object) {
// NOOP
}
@Override
public String toString() {
return "NOOP_HANDLE";
}
};
}
java
/**
* 基本copy自netty的ObjectPool类
*
* 一个轻量级的对象池
* */
public abstract class MyObjectPool<T> {
/**
* 从对象池中获取一个对象
* 如果对象池中没有一个可以被重用的池化对象,也许会通过newObject(Handle)方法来创建一个对象
*/
public abstract T get();
/**
* 用于通知对象池可以再次重用的句柄(handle)
*/
public interface Handle<T> {
/**
* 如果可能的话,将对象回收并且使其能准备好被复用
*/
void recycle(T self);
}
/**
* 创建一个新的对象,该对象引用了给定的handle句柄对象.
* 其一旦可以被重用时,调用Handle#recycle(Object)方法
*/
public interface ObjectCreator<T> {
/**
* Creates an returns a new {@link Object} that can be used and later recycled via
* {@link Handle#recycle(Object)}.
*
* @param handle can NOT be null.
*/
T newObject(Handle<T> handle);
}
/**
* 使用给定的ObjectCreator,创建一个新的对象池(ObjectPool)
* 该对象池创建的对象应该被池化
*/
public static <T> MyObjectPool<T> newPool(final ObjectCreator<T> creator) {
if (creator == null) {
throw new NullPointerException("creator");
}
return new RecyclerObjectPool<>(creator);
}
private static final class RecyclerObjectPool<T> extends MyObjectPool<T> {
private final MyRecycler<T> recycler;
RecyclerObjectPool(final ObjectCreator<T> creator) {
recycler = new MyRecycler<T>() {
@Override
protected T newObject(Handle<T> handle) {
return creator.newObject(handle);
}
};
}
@Override
public T get() {
return recycler.get();
}
}
}3. Normal规格的ByteBuf池化实现解析
下面我们开始分析池化内存中最关键的部分,即PooledByteBuf底层数组内存的池化机制。具体的入口在PoolArena的allocate方法中。
java
/**
* 参考自netty的PoolArena,但做了大幅简化
* */
public abstract class MyPoolArena<T>{
// 。。。 已省略无关逻辑
final MySizeClasses mySizeClasses;
private void allocate(MyPooledByteBuf<T> buf, final int reqCapacity) {
final MySizeClassesMetadataItem sizeClassesMetadataItem = mySizeClasses.size2SizeIdx(reqCapacity);
switch (sizeClassesMetadataItem.getSizeClassEnum()){
case SMALL:
// 暂不支持
throw new RuntimeException("not support small size allocate! reqCapacity=" + reqCapacity);
// tcacheAllocateSmall(buf, reqCapacity, sizeIdx);
case NORMAL:
tcacheAllocateNormal(buf, reqCapacity, sizeClassesMetadataItem);
return;
case HUGE:
// 超过了PoolChunk大小的内存分配就是Huge级别的申请,每次分配使用单独的非池化的新PoolChunk来承载
allocateHuge(buf, reqCapacity);
}
}
}
java
public class MySizeClassesMetadataItem {
private int size;
private SizeClassEnum sizeClassEnum;
public MySizeClassesMetadataItem(int size, SizeClassEnum sizeClassEnum) {
this.size = size;
this.sizeClassEnum = sizeClassEnum;
}
public int getSize() {
return size;
}
public SizeClassEnum getSizeClassEnum() {
return sizeClassEnum;
}
}
java
public enum SizeClassEnum {
SMALL,
NORMAL,
HUGE,
;
}SizeClasses工作原理解析
从上面的MyNetty的源码实现中可以看到,netty在进行实际的分配前,先基于参数reqCapacity计算出实际应该分配的大小以及规格级别,然后再基于规格级别去执行不同机制的分配操作。
在jemalloc的论文中提到,jemalloc默认情况将SizeClass规格分为了以下三大类。
- Small: 8, 16, 32, 48, ..., 128, 192, 256, 320, ..., 512, 768, 1024, 1280, ..., 3840
- Large: 4 KiB, 8 KiB, 12 KiB, ..., 4072 KiB
- Huge: 4 MiB, 8 MiB, 12 MiB, ...
而netty参考了jemalloc,同样将规格分为了对应的三类,即Small、Normal和Huge。默认情况下,Small与Normal的分界线不是4KB,而是8KB。
- Huge类型分配:默认情况下大于4MB的PooledByteBuf分配,视为Huge规格。因为其占用空间过大,且实际使用场景很少,所以对于Huge类型的申请,netty不进行内存池化,而是每次都临时的申请新的内存来满足需求,以减少内存碎片。
- Normal类型分配:默认情况下8KB,4MB大小区间内的PooledByteBuf分配,视为Normal规格。netty参考linux内核的伙伴算法,通过管理以页(默认1页8KB)为最小单位的连续内存页段(run)的方式进行空闲内存的追踪与维护。
- Small类型分配:默认情况下小于8KB的PooledByteBuf分配,被视为Small规格。netty参考linux内核的slab内存分配算法,通过管理一系列固定大小的内存对象槽集合的方式,管理待分配的池化内存。
为什么linux内核和netty都要基于实际申请的内存大小划分规格,并区别对待呢?我们留到下一篇博客介绍完small类型分配工作原理后统一进行分析。
下面我们基于MyNetty的SizeClasses实现源码来分析一下netty是如何进行规格划分的。
Netty的SizeClasses主要做了两件事,一个是计算出所申请内存的规格级别(Small、Normal还是Huge),另一个则是规范化所申请的内存大小。
怎么理解规范化呢?无论是伙伴算法,还是slab算法,出于减少内存碎片的考虑,无法为任意字节大小的内存申请都预先池化恰好等于所申请大小的规格。
举个例子,假如用户要申请14kb大小的内存,又要申请11kb大小的内存,要想恰好满足用户的需求,则需要预留N个14kb的内存块和M个11kb的内存块。
而用户实际会申请的内存大小的可能性是几乎不可枚举的,所以只能对其申请的内存大小进行规范化。比如申请11和14kb都统一将其规范化为满足其大小前提下最小的规格,比如16;而如果要申请的内存为28kb,则规范化为32等等。
netty和jemalloc一样,都以2的倍数为基础设计了一系列的规格,用以规范化内存申请大小。总的来说,规格越小,则规格的排布就越密集,比如16,32,48,64,每个间隔仅为16;而到了512时则是640,768,896,1024,每个间隔扩大到了128。
jemalloc的论文中提到之所以这样设计,是为了平衡内部碎片与外部碎片,当申请14kb而实际分配规范化后的16kb池化内存时,就有2kb的内部碎片无法使用;而对应规格的池化内存如果因为使用率较低的话,则会产生大量外部碎片。
绝大多数的应用在申请内存时,较小的内存大小的申请是远多于大内存的。假如512的大小下,依然以16为间隔进行划分,那么恰好申请512-528字节的可能性相对16-32字节区间就低太多了。这样即使在处理540字节的申请时,并实际分配640字节而造成100字节的内部碎片,所带来的总内存碎片量依然低得多。
Carefully choose size classes (somewhat inspired by Vam). If size classes are spaced far apart, objects will tend to have excessive unusable trailing space (internal fragmentation).
As the size class count increases, there will tend to be a corresponding increase in unused memory dedicated to object sizes that are currently underutilized (external fragmentation).
精心设计规格等级(部分灵感来自于Vam)。如果不同规格等级之间差距过大,对象尾部将会产生过多的不可使用的空间(内部碎片)。
而随着规格等级数量的增加,又会导致专门服务于某一使用率较低的规格大小的内存空间闲置(外部碎片)。
MySizeClasses源码实现
java
/**
* 功能与Netty的SizeClasses类似,
* netty里支持动态配置pageSize和chunkSize来调优,并能够得到合理的伸缩比例,所以实现的比较复杂
* MySizeClasses这里size的规格全部写死为netty的默认值,简化复杂度
* */
public class MySizeClasses {
/**
* 页大小直接写死,8K
* */
private final int pageSize = 8192;
/**
* 页大小的log2对数
* log2(8192) = 13
* */
private final int pageShifts = 13;
/**
* 一共有多个个Page类型的规格(所有的规格,恰好是pageSize的倍数的就是Page类型的规格,比如8K,16K,24K以此类推)
* */
private final int nPageSizes;
/**
* chunk大小直接写死,4M
* */
private final int chunkSize = 1024 * 1024 * 4;
/**
* size低于该值的直接通过16的倍数索引数组(size2idxTab)来快速匹配
* */
private final int lookupMaxSize = 4096;
/**
* QUANTUM是量子的意思,即最小的规格 是16
* LOG2_QUANTUM = (log2(16) = 4)
* */
private final int LOG2_QUANTUM = 4;
/**
* 每一个规格组的大小固定为4,组内每一个size规格的间距是固定的
* */
private static final int LOG2_SIZE_CLASS_GROUP = 2;
private final MySizeClassesMetadataItem[] sizeTable;
private final MySizeClassesMetadataItem[] size2idxTab;
private final MySizeClassesMetadataItem[] pageIdx2sizeTab;
public MySizeClasses() {
int sizeNum = 69;
sizeTable = new MySizeClassesMetadataItem[sizeNum];
// 简单起见,写死size表规格
// 规格跨度逐渐增加。绝大多数情况下,越小的内存规格,被申请的次数越多,因此更为精确的小规格配合slab分配可以显著减少内部内存碎片
// 对于较大的规格(比如normal级别的),如果还是按照几十的间距来设置规格(1k-2k之间就有几十个不同的规格),就会导致过多的元数据需要维护,产生过多的外部碎片而浪费内存。
// normal级别的内存通过伙伴算法进行分配,可以在内部内存碎片和外部内存碎片的取舍上得到一个不错的空间效率
sizeTable[0] = new MySizeClassesMetadataItem(16, SizeClassEnum.SMALL);
sizeTable[1] = new MySizeClassesMetadataItem(32, SizeClassEnum.SMALL);
sizeTable[2] = new MySizeClassesMetadataItem(48, SizeClassEnum.SMALL);
sizeTable[3] = new MySizeClassesMetadataItem(64, SizeClassEnum.SMALL);//组内固定间距16(2^4)
sizeTable[4] = new MySizeClassesMetadataItem(80, SizeClassEnum.SMALL);
sizeTable[5] = new MySizeClassesMetadataItem(96, SizeClassEnum.SMALL);
sizeTable[6] = new MySizeClassesMetadataItem(112, SizeClassEnum.SMALL);
sizeTable[7] = new MySizeClassesMetadataItem(128, SizeClassEnum.SMALL);//组内固定间距16(2^4)
sizeTable[8] = new MySizeClassesMetadataItem(160, SizeClassEnum.SMALL);
sizeTable[9] = new MySizeClassesMetadataItem(192, SizeClassEnum.SMALL);
sizeTable[10] = new MySizeClassesMetadataItem(224, SizeClassEnum.SMALL);
sizeTable[11] = new MySizeClassesMetadataItem(256, SizeClassEnum.SMALL);//组内固定间距32(2^5)
sizeTable[12] = new MySizeClassesMetadataItem(320, SizeClassEnum.SMALL);
sizeTable[13] = new MySizeClassesMetadataItem(384, SizeClassEnum.SMALL);
sizeTable[14] = new MySizeClassesMetadataItem(448, SizeClassEnum.SMALL);
sizeTable[15] = new MySizeClassesMetadataItem(512, SizeClassEnum.SMALL);//组内固定间距64(2^6)
sizeTable[16] = new MySizeClassesMetadataItem(640, SizeClassEnum.SMALL);
sizeTable[17] = new MySizeClassesMetadataItem(768, SizeClassEnum.SMALL);
sizeTable[18] = new MySizeClassesMetadataItem(896, SizeClassEnum.SMALL);
sizeTable[19] = new MySizeClassesMetadataItem(1024, SizeClassEnum.SMALL);//组内固定间距128(2^7)
sizeTable[20] = new MySizeClassesMetadataItem(1280, SizeClassEnum.SMALL);
sizeTable[21] = new MySizeClassesMetadataItem(1536, SizeClassEnum.SMALL);
sizeTable[22] = new MySizeClassesMetadataItem(1792, SizeClassEnum.SMALL);
sizeTable[23] = new MySizeClassesMetadataItem(1024 * 2, SizeClassEnum.SMALL);//组内固定间距256(2^8)
sizeTable[24] = new MySizeClassesMetadataItem((int) (1024 * 2.5), SizeClassEnum.SMALL);
sizeTable[25] = new MySizeClassesMetadataItem(1024 * 3, SizeClassEnum.SMALL);
sizeTable[26] = new MySizeClassesMetadataItem((int) (1024 * 3.5), SizeClassEnum.SMALL);
sizeTable[27] = new MySizeClassesMetadataItem(1024 * 4, SizeClassEnum.SMALL);//组内固定间距512(2^9)
sizeTable[28] = new MySizeClassesMetadataItem(1024 * 5, SizeClassEnum.SMALL);
sizeTable[29] = new MySizeClassesMetadataItem(1024 * 6, SizeClassEnum.SMALL);
sizeTable[30] = new MySizeClassesMetadataItem(1024 * 7, SizeClassEnum.SMALL);
sizeTable[31] = new MySizeClassesMetadataItem(1024 * 8, SizeClassEnum.NORMAL);//组内固定间距1024(2^10) 大于等于PageSize的都是Normal级别
sizeTable[32] = new MySizeClassesMetadataItem(1024 * 10, SizeClassEnum.NORMAL);
sizeTable[33] = new MySizeClassesMetadataItem(1024 * 12, SizeClassEnum.NORMAL);
sizeTable[34] = new MySizeClassesMetadataItem(1024 * 14, SizeClassEnum.NORMAL);
sizeTable[35] = new MySizeClassesMetadataItem(1024 * 16, SizeClassEnum.NORMAL);//组内固定间距2048(2^11)
sizeTable[36] = new MySizeClassesMetadataItem(1024 * 20, SizeClassEnum.NORMAL);
sizeTable[37] = new MySizeClassesMetadataItem(1024 * 24, SizeClassEnum.NORMAL);
sizeTable[38] = new MySizeClassesMetadataItem(1024 * 28, SizeClassEnum.NORMAL);
sizeTable[39] = new MySizeClassesMetadataItem(1024 * 32, SizeClassEnum.NORMAL);//组内固定间距4096(2^12)
sizeTable[40] = new MySizeClassesMetadataItem(1024 * 40, SizeClassEnum.NORMAL);
sizeTable[41] = new MySizeClassesMetadataItem(1024 * 48, SizeClassEnum.NORMAL);
sizeTable[42] = new MySizeClassesMetadataItem(1024 * 56, SizeClassEnum.NORMAL);
sizeTable[43] = new MySizeClassesMetadataItem(1024 * 64, SizeClassEnum.NORMAL);//组内固定间距8192(2^13)
sizeTable[44] = new MySizeClassesMetadataItem(1024 * 80, SizeClassEnum.NORMAL);
sizeTable[45] = new MySizeClassesMetadataItem(1024 * 96, SizeClassEnum.NORMAL);
sizeTable[46] = new MySizeClassesMetadataItem(1024 * 112, SizeClassEnum.NORMAL);
sizeTable[47] = new MySizeClassesMetadataItem(1024 * 128, SizeClassEnum.NORMAL);//组内固定间距16384(2^14)
sizeTable[48] = new MySizeClassesMetadataItem(1024 * 160, SizeClassEnum.NORMAL);
sizeTable[49] = new MySizeClassesMetadataItem(1024 * 192, SizeClassEnum.NORMAL);
sizeTable[50] = new MySizeClassesMetadataItem(1024 * 224, SizeClassEnum.NORMAL);
sizeTable[51] = new MySizeClassesMetadataItem(1024 * 256, SizeClassEnum.NORMAL);//组内固定间距32768(2^15)
sizeTable[52] = new MySizeClassesMetadataItem(1024 * 320, SizeClassEnum.NORMAL);
sizeTable[53] = new MySizeClassesMetadataItem(1024 * 384, SizeClassEnum.NORMAL);
sizeTable[54] = new MySizeClassesMetadataItem(1024 * 448, SizeClassEnum.NORMAL);
sizeTable[55] = new MySizeClassesMetadataItem(1024 * 512, SizeClassEnum.NORMAL);//组内固定间距65536(2^16)
sizeTable[56] = new MySizeClassesMetadataItem(1024 * 640, SizeClassEnum.NORMAL);
sizeTable[57] = new MySizeClassesMetadataItem(1024 * 768, SizeClassEnum.NORMAL);
sizeTable[58] = new MySizeClassesMetadataItem(1024 * 896, SizeClassEnum.NORMAL);
sizeTable[59] = new MySizeClassesMetadataItem(1024 * 1024, SizeClassEnum.NORMAL);//组内固定间距131072(2^17)
sizeTable[60] = new MySizeClassesMetadataItem((int) (1024 * 1024 * 1.25), SizeClassEnum.NORMAL);
sizeTable[61] = new MySizeClassesMetadataItem((int) (1024 * 1024 * 1.5), SizeClassEnum.NORMAL);
sizeTable[62] = new MySizeClassesMetadataItem((int) (1024 * 1024 * 1.75), SizeClassEnum.NORMAL);
sizeTable[63] = new MySizeClassesMetadataItem(1024 * 1024 * 2, SizeClassEnum.NORMAL);//组内固定间距262144(2^18)
sizeTable[64] = new MySizeClassesMetadataItem((int) (1024 * 1024 * 2.5), SizeClassEnum.NORMAL);
sizeTable[65] = new MySizeClassesMetadataItem(1024 * 1024 * 3, SizeClassEnum.NORMAL);
sizeTable[66] = new MySizeClassesMetadataItem((int) (1024 * 1024 * 3.5), SizeClassEnum.NORMAL);
sizeTable[67] = new MySizeClassesMetadataItem(1024 * 1024 * 4, SizeClassEnum.NORMAL);//组内固定间距524288(2^19)
// 一个chunk就是4M,超过chunk级别的规格就是Huge类型了,这个是MyNetty额外加的一项
sizeTable[68] = new MySizeClassesMetadataItem(0, SizeClassEnum.HUGE);
// 计算一共有多个个Page类型的规格(所有的规格,恰好是pageSize的倍数的就是Page类型的规格,比如8K,16K,24K以此类推)
int nPageSizes = 0;
for (MySizeClassesMetadataItem item : sizeTable) {
int size = item.getSize();
if (size >= pageSize & size % pageSize == 0) {
nPageSizes++;
}
}
this.nPageSizes = nPageSizes;
// 构建lookupMaxSize以下规格的快速查找索引表
this.size2idxTab = buildSize2idxTab(lookupMaxSize,sizeTable);
this.pageIdx2sizeTab = newPageIdx2sizeTab(sizeTable, sizeTable.length-1, this.nPageSizes);
}
private MySizeClassesMetadataItem[] buildSize2idxTab(int lookupMaxSize, MySizeClassesMetadataItem[] sizeTable) {
MySizeClassesMetadataItem[] size2idxTab = new MySizeClassesMetadataItem[lookupMaxSize >> LOG2_QUANTUM];
int size2idxTabIndex = 0;
int lastQuantumBaseSize = 0;
for(int i=0; i<sizeTable.length; i++){
MySizeClassesMetadataItem item = sizeTable[i];
// 量子基数(size都是QUANTUM(16)的倍数,比如size=16,那就是1;size=32,那就是2 依此类推)
int quantumBaseSize = item.getSize() >> LOG2_QUANTUM;
for(int j=lastQuantumBaseSize; j<quantumBaseSize; j++){
if(size2idxTabIndex < size2idxTab.length){
size2idxTab[size2idxTabIndex] = item;
size2idxTabIndex++;
}
}
lastQuantumBaseSize = quantumBaseSize;
}
return size2idxTab;
}
private MySizeClassesMetadataItem[] newPageIdx2sizeTab(MySizeClassesMetadataItem[] sizeTable, int nSizes, int nPSizes) {
MySizeClassesMetadataItem[] pageIdx2sizeTab = new MySizeClassesMetadataItem[nPSizes];
int pageIdx = 0;
for (int i = 0; i < nSizes; i++) {
MySizeClassesMetadataItem item = sizeTable[i];
int size = item.getSize();
if (size >= pageSize && size % pageSize == 0) {
pageIdx2sizeTab[pageIdx] = item;
pageIdx++;
}
}
return pageIdx2sizeTab;
}
public MySizeClassesMetadataItem size2SizeIdx(int size) {
if (size == 0) {
return sizeTable[0];
}
if (size > chunkSize) {
// 申请的是huge级别的内存规格
return sizeTable[sizeTable.length-1];
}
// 简单起见,不支持配置内存对齐(directMemoryCacheAlignment)
if (size <= lookupMaxSize) {
// 小于4096的size规格,可以通过以16为基数的索引表,以O(1)的时间复杂度直接找到对应的规格
// size-1 / MIN_TINY
return size2idxTab[size - 1 >> LOG2_QUANTUM];
}
// 申请规格对应的向上取整的2次幂(比如15,sizeToClosestLog2就是4,代表距离最近的二次幂规格是16)
int sizeToClosestLog2 = MathUtil.log2((size << 1) - 1);
// size所在内存规格组编号,每一个组内包含4个规格(LOG2_SIZE_CLASS_GROUP=2),每个组内第4个也是最后一个规格是64的倍数(2^6)
// 第一个组最后一个规格为64,第二组最后一个规格为64*2=128,第三组最后一个规格为64*4=128*2=256,依次类推,每一组的最后一个规格都是前一组最后一个规格的2倍
// 所以size在二次幂向上对其后,除以64就能得到其所属的组的编号(log2对数就是直接减6(2+4))
// lookupMaxSize很大,所以sizeGroupShift肯定大于0
int sizeGroupShift = sizeToClosestLog2 - (LOG2_SIZE_CLASS_GROUP + LOG2_QUANTUM);;
// 每个组内有4个规格,所以sizeGroupShift*4后获得对应的组的起始规格下标号
int groupFirstIndex = sizeGroupShift << LOG2_SIZE_CLASS_GROUP;
// 组内规格之间固定的间隔(每一组内部有4个规格,而相邻两组之间规格相差2倍,所以除以8就能得到组内的固定间隔)
int log2Delta = sizeToClosestLog2 - LOG2_SIZE_CLASS_GROUP - 1;
// size最贴近组内哪一个规格
// (size - 1 >> log2Delta)得到当前size具体是几倍的log2Delta
// 组内共(1 << LOG2_SIZE_CLASS_GROUP)=4个规格,因此对4求余数(x为二次幂可以通过&(x-1)的方式优化),就能得到组内具体的规格项下标
int mod = size - 1 >> log2Delta & (1 << LOG2_SIZE_CLASS_GROUP) - 1;
// 最终确定实际对应内存规格的下标
int finallySizeIndex = groupFirstIndex + mod;
// 返回最终所匹配到的规格信息
return sizeTable[finallySizeIndex];
}
public MySizeClassesMetadataItem sizeIdx2size(int sizeIdx) {
return sizeTable[sizeIdx];
}
/**
* 申请pages个连续页时,向上规格化后所对应的规格
* */
public int pages2pageIdx(int pages) {
return pages2pageIdxCompute(pages, false);
}
/**
* 申请pages个连续页时,向下规格化后所对应的规格
* */
public int pages2pageIdxFloor(int pages) {
return pages2pageIdxCompute(pages, true);
}
public int getPageSize() {
return pageSize;
}
public int getNPageSizes() {
return nPageSizes;
}
public int getPageShifts() {
return pageShifts;
}
public int getChunkSize() {
return chunkSize;
}
/**
* 和size2SizeIdx逻辑几乎一样,也是基于有规律的pageIdx2sizeTab表来快速定位对应规格
* */
private int pages2pageIdxCompute(int pages, boolean floor) {
// 将申请的总页数 乘以 页大小 得到总共需要申请的size之和
int pageSize = pages << pageShifts;
if (pageSize > chunkSize) {
// 申请的是huge级别的内存规格
return this.pageIdx2sizeTab.length;
}
// 申请规格对应的向上取整的2次幂(比如8100,sizeToClosestLog2就是13,代表距离最近的二次幂规格是8192)
int sizeToClosestLog2 = MathUtil.log2((pageSize << 1) - 1);
// pageSize所在内存规格组编号,每一个组内包含4个规格(LOG2_SIZE_CLASS_GROUP=2),单位起步是页级别(PAGE_SHIFTS)
int sizeGroupShift;
if(sizeToClosestLog2 < LOG2_SIZE_CLASS_GROUP + pageShifts){
// 说明是第一组内的规格
sizeGroupShift = 0;
}else{
sizeGroupShift = sizeToClosestLog2 - (LOG2_SIZE_CLASS_GROUP + pageShifts);
}
// 每个组内有4个规格,所以sizeGroupShift*4后获得对应的组的起始规格下标号
int groupFirstIndex = sizeGroupShift << LOG2_SIZE_CLASS_GROUP;
// 组内规格之间固定的间隔(每一组内部有4个规格)
int log2Delta;
if(sizeToClosestLog2 < LOG2_SIZE_CLASS_GROUP + pageShifts + 1){
// 前两个group的组内间隔都是8K
log2Delta = pageShifts;
}else{
// 后面每个组的组内间隔,相比前一个组都大两倍
log2Delta = sizeToClosestLog2 - LOG2_SIZE_CLASS_GROUP - 1;
}
// pageSize最贴近组内哪一个规格
// (pageSize - 1 & deltaInverseMask)得到当前pageSize具体是几倍的log2Delta
// 组内共(1 << LOG2_SIZE_CLASS_GROUP)=4个规格,因此对4求余数(x为二次幂可以通过&(x-1)的方式优化),就能得到组内具体的规格项下标
int deltaInverseMask = -1 << log2Delta;
int mod = (pageSize - 1 & deltaInverseMask) >> log2Delta & (1 << LOG2_SIZE_CLASS_GROUP) - 1;
int pageIdx = groupFirstIndex + mod;
if (floor && pageIdx2sizeTab[pageIdx].getSize() > pages << pageShifts) {
// 默认都是向上取整的,如果floor=true,且当前向上取整的size规格确实大于pages对应的size,则返回前一个规格
return pageIdx-1;
}else{
return pageIdx;
}
}
}Netty中为了支持动态的设置Normal页单位的大小,实现了一套复杂的算法来计算每一个规格区间动态的生成sizeIdx2sizeTab等规格表。而MyNetty的实现中,简单起见直接以默认的页大小(8Kb)在构造函数中直接写死了sizeTable数组中每个规范化的规格大小和对应级别,方便读者理解。
下面我们重点关注size2SizeIdx方法,这个方法传入实际申请的大小,返回规范化后的规格和对应的级别(比如540规范化为640(small),10001规范化为10240(Normal)等等)。
如果没有看过Netty的实际实现,读者可能会觉得规范化的功能其内部是通过二分查找来实现的(对数时间复杂度)。但netty认为内存分配操作是一个高频操作,对数的时间复杂度还不够快。通过精心设计的规格间距,使得能够以常数时间复杂度完成规范化计算。
- 首先,默认情况下对于小于lookupMaxSize规格(默认4096)的大小申请,netty单独设计了一个索引表size2idxTab,为范围内每一个2次幂(除以4)对应的规范化规格进行了索引。所以通过位运算可以直接定位到对应的规格(size2idxTabsize - 1 \>\> LOG2_QUANTUM)。
- 随着规格越来越大,如果继续使用size2idxTab来生成索引其耗费的空间会指数级增加,因此对于大小超过lookupMaxSize的申请则通过巧妙的规格分组结合位运算来进行规范化计算。
简单来说,netty将规格进行分组,每个分组内共4个规格,组内的规格间距相同;相邻组之间的间隔(即更小组中的最大项与更大组中的最小项)则随着组别的增加,有规律的扩大。
在上述MySizeClasses的构造方法中,结合注释可以很清楚的看到这一规律。这使得netty可以通过一系列巧妙的运算,在不使用索引表的情况下,仍然可以用常数的时间复杂度完成规范化计算。 - 对于小于lookupMaxSize大小的申请,一次简单的位操作可以直接完成计算,索引表浪费空间但能节约时间。而对于大于lookupMaxSize小于ChunkSize的申请,通过几次运算后也能在常数复杂度内完成,时间复杂度大O相同但小O更大。
考虑到小于lookupMaxSize的小内存申请数通常远多于超过lookupMaxSize的大内存申请数。可以说,netty在规范化计算的实现上,很好的平衡了时间与空间。
看到这里,读者应该可以理解为什么Netty的SizeClasses的构造方法中要实现的那么复杂了吧(里面各种group分组和logXXX的变量)。
其最主要的目的就是实现常数复杂度的内存申请规范化计算并支持动态的页大小,同时尽量减少其中各种元数据所占用的内存。
PoolChunkList工作原理解析
PoolChunk是Netty中分配内存的基本单元,Chunk就是一大块内存的意思,在使用时会按照需求有机切割为一些不同大小的连续内存段以供使用。默认情况下,ChunkSize为4MB。
Normal和Small类型的内存申请的空间通常远小于Chunk的大小,因此一个新的PoolChunk在进行一次内存分配后,必然会空余大量的内存空间。要减少内存碎片,就必须尽可能的让PoolChunk中的内存空间被充分利用,尽可能用更少的PoolChunk数来满足更多的内存分配申请。
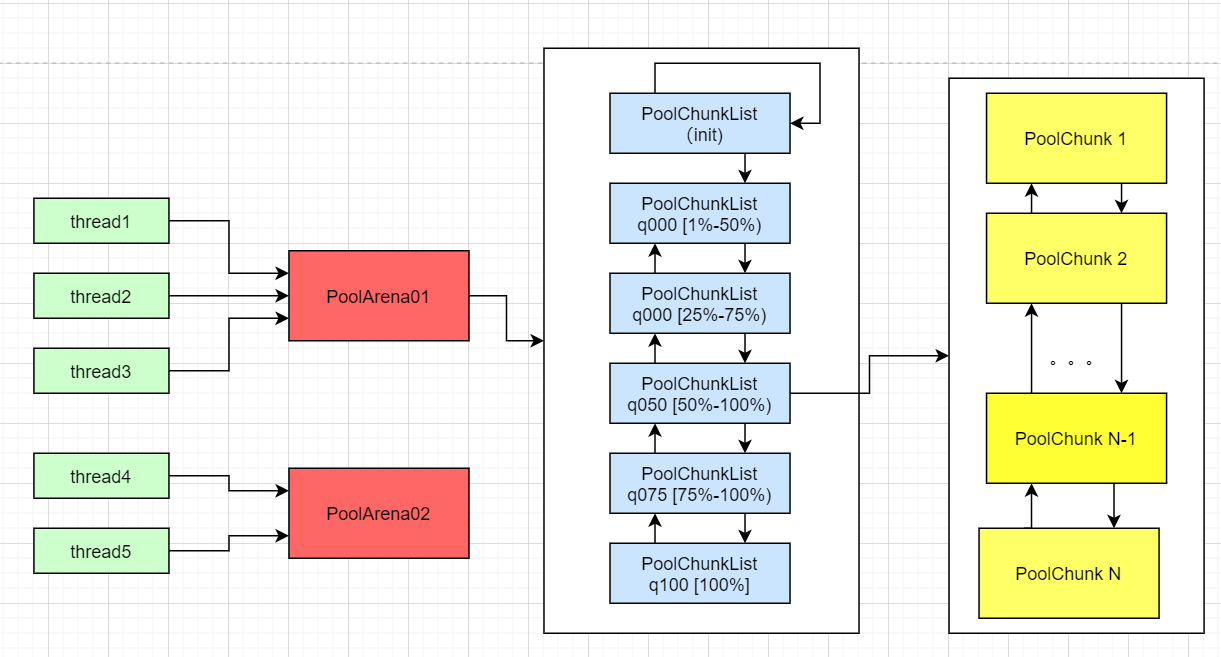
Netty参考jemalloc将PoolChunk按照内部的空间利用率有机的组织起来,按照使用率的阈值范围进行分组,每一组PoolChunk以双向链表的形式构成一个PoolChunkList。
PoolChunkList结构图
下面我们结合源码看看Netty是如何进行Normal类型的内存分配的。
- PoolArena按照内存使用率区间划分了6个PoolChunkList,分别是qInit、q000[1%-50%)、q025[25%-75%)、q050[50%-100%)、q075[75%-100%)、q100(100%)。
按照使用率的大小,以双向链表的形式组织了起来,刚被创建的PoolChunk会被放入qInit,随着后续内存的分配与回收,如果PoolChunk的使用率超过了所在PoolChunkList的上限或下限,则会被移动到满足其使用率范围的最临近的那个PoolChunkList中。
可以注意到,不同的PoolChunkList的使用率区间是存在重合的,q000中的PoolChunk如果内存使用率从10%变为了40%,并不会被立即移动到q025中。
这样设计的目的是为了避免位于区间临界点的PoolChunk因为频繁的分配和回收,而反复的在不同PoolChunkList中迁移,以提高效率。 - 出于减少内存碎片的考虑,PoolArena与线程的关系是1对N的,所以访问PoolArena是可能出现并发的。为了保护分配时元数据的变更,实际分配前使用当前PoolArena专属的互斥锁执行加锁操作(tcacheAllocateNormal方法)。
- 在allocateNormal方法中,可以看到按照顺序依次尝试从q050、q025、q000、qInit和q075这些使用率不满100%的PoolChunkList中进行分配,如果分配成功则会提前返回。
如果所有的PoolChunkList都无法满足当前的分配请求,则会新创建一个空的PoolChunk进行分配,并将这个新的PoolChunk放入qInit中。
这种尝试顺序可以在确保足够分配成功率的前提下,尽量让每一个PoolChunk都保持较高的空间使用率。
java
/**
* 参考自netty的PoolArena,但做了大幅简化
* */
public abstract class MyPoolArena<T> {
// 。。。 已省略无关逻辑
final MyPooledByteBufAllocator parent;
final MySizeClasses mySizeClasses;
private final MyPoolChunkList<T> q050;
private final MyPoolChunkList<T> q025;
private final MyPoolChunkList<T> q000;
private final MyPoolChunkList<T> qInit;
private final MyPoolChunkList<T> q075;
private final MyPoolChunkList<T> q100;
private final ReentrantLock lock = new ReentrantLock();
public MyPoolArena(MyPooledByteBufAllocator parent) {
this.parent = parent;
this.mySizeClasses = new MySizeClasses();
int chunkSize = this.mySizeClasses.getChunkSize();
// 从小到大,使用率区间相近的PoolChunkList进行关联,组成双向链表(使用率区间有重合,论文中提到是设置磁滞效应,避免使用率小幅波动时反复移动位置,以提高性能)
// qInit <=> q000(1%-50%) <=> q025(25%-75%) <=> q050(50%-100%) <=> q075(75%-100%) <=> q100(100%)
this.q100 = new MyPoolChunkList<T>(this, null, 100, Integer.MAX_VALUE, chunkSize);
this.q075 = new MyPoolChunkList<T>(this, q100, 75, 100, chunkSize);
this.q050 = new MyPoolChunkList<T>(this, q075, 50, 100, chunkSize);
this.q025 = new MyPoolChunkList<T>(this, q050, 25, 75, chunkSize);
this.q000 = new MyPoolChunkList<T>(this, q025, 1, 50, chunkSize);
this.qInit = new MyPoolChunkList<T>(this, q000, Integer.MIN_VALUE, 25, chunkSize);
this.q100.setPrevList(q075);
this.q075.setPrevList(q050);
this.q050.setPrevList(q025);
this.q025.setPrevList(q000);
this.q000.setPrevList(null);
this.qInit.setPrevList(qInit);
// 简单起见,PoolChunkListMetric暂不实现
}
/**
* 从当前PoolArena中申请分配内存,并将其包装成一个PooledByteBuf返回
* */
MyPooledByteBuf<T> allocate(int reqCapacity, int maxCapacity) {
// 从对象池中获取缓存的PooledByteBuf对象
MyPooledByteBuf<T> buf = newByteBuf(maxCapacity);
// 为其分配底层数组对应的内存
allocate(buf, reqCapacity);
return buf;
}
private void allocate(MyPooledByteBuf<T> buf, final int reqCapacity) {
final MySizeClassesMetadataItem sizeClassesMetadataItem = mySizeClasses.size2SizeIdx(reqCapacity);
switch (sizeClassesMetadataItem.getSizeClassEnum()){
case SMALL:
// 暂不支持
throw new RuntimeException("not support small size allocate! reqCapacity=" + reqCapacity);
// tcacheAllocateSmall(buf, reqCapacity, sizeIdx);
case NORMAL:
tcacheAllocateNormal(buf, reqCapacity, sizeClassesMetadataItem);
return;
case HUGE:
// 超过了PoolChunk大小的内存分配就是Huge级别的申请,每次分配使用单独的非池化的新PoolChunk来承载
allocateHuge(buf, reqCapacity);
}
}
private void tcacheAllocateNormal(MyPooledByteBuf<T> buf, final int reqCapacity, final MySizeClassesMetadataItem sizeClassesMetadataItem) {
lock();
try {
// 加锁处理,防止并发修改元数据
allocateNormal(buf, reqCapacity, sizeClassesMetadataItem);
} finally {
unlock();
}
}
private void allocateHuge(MyPooledByteBuf<T> buf, int reqCapacity) {
MyPoolChunk<T> chunk = newUnpooledChunk(reqCapacity);
buf.initUnPooled(chunk, reqCapacity);
}
private void allocateNormal(MyPooledByteBuf<T> buf, int reqCapacity, MySizeClassesMetadataItem sizeIdx) {
// 优先从050的PoolChunkList开始尝试分配,尽可能的复用已经使用较充分的PoolChunk。如果分配失败,就尝试另一个区间内的PoolChunk
// 分配成功则直接return快速返回
if (q050.allocate(buf, reqCapacity, sizeIdx)){
return;
}
if (q025.allocate(buf, reqCapacity, sizeIdx)){
return;
}
if (q000.allocate(buf, reqCapacity, sizeIdx)){
return;
}
if (qInit.allocate(buf, reqCapacity, sizeIdx)){
return;
}
if (q075.allocate(buf, reqCapacity, sizeIdx)){
return;
}
// 所有的PoolChunkList都尝试过了一遍,都没能分配成功,说明已经被创建出来的,所有有剩余空间的PoolChunk空间都不够了(或者最初阶段还没有创建任何一个PoolChunk)
// MyNetty对sizeClass做了简化,里面的规格都是写死的,所以直接从sizeClass里取
int pageSize = this.mySizeClasses.getPageSize();
int nPSizes = this.mySizeClasses.getNPageSizes();
int pageShifts = this.mySizeClasses.getPageShifts();
int chunkSize = this.mySizeClasses.getChunkSize();
// 创建一个新的PoolChunk,用来进行本次内存分配
MyPoolChunk<T> c = newChunk(pageSize, nPSizes, pageShifts, chunkSize);
c.allocate(buf, reqCapacity, sizeIdx);
// 新创建的PoolChunk首先加入qInit(可能使用率较高,add方法里会去移动到合适的PoolChunkList中(nextList.add))
qInit.add(c);
}
}PoolChunkList内部将PoolChunk以双向链表的形式组织起来。allocate方法中从头结点开始依次遍历所有的PoolChunk,调用PoolChunk的allocate方法看其是否能满足本次分配(PoolChunk在下一小节解析)。
如果能满足需求,则返回true,并且判断分配完成后,当前PoolChunk的使用率是否超过了当前PoolChunkList的上限,如果超过了,则将其移动到后面使用率更高的PoolChunkList中去。
如果不能满足需求,则返回false,意味着当前PoolChunkList内的所有Chunk都无法满足本次分配(也可能是一个PoolChunk都没有)。
java
/**
* 参考Netty的PoolChunkList
*/
public class MyPoolChunkList<T> {
// 。。。 已省略无关逻辑
/**
* 当前chunkList所归属的Arena
* */
private final MyPoolArena<T> arena;
/**
* 最小空间使用率(百分比)
* */
private final int minUsage;
/**
* 最大空间使用率(百分比)
* */
private final int maxUsage;
/**
* 最大可用空间
* */
private final int maxCapacity;
/**
* PoolChunkList本质上是一个PoolChunk的链表,将同样使用率区间的PoolChunk给管理起来
* head就是这个PoolChunk链表的头节点
* */
private MyPoolChunk<T> head;
/**
* 最小空闲阈值(单位:字节)
* 如果当前ChunkList内所维护的PoolChunk的实际空闲字节低于了这个最小空闲阈值,就要将其移动下一个更充实的ChunkList中去(next)
* (比如从(25-75%)的利用率list => (50-100%)的那个list里去)
* */
private final int freeMinThreshold;
/**
* 最大空闲阈值(单位:字节)
* 如果当前ChunkList内所维护的PoolChunk的实际空闲字节高于了这个最大空闲阈值,就要将其移动上一个更空旷的ChunkList中去(prev)
* (比如从(25-75%)的利用率list => (1-50%)的那个list里去)
* */
private final int freeMaxThreshold;
/**
* 当前chunkList的后继list节点
* */
private final MyPoolChunkList<T> nextList;
/**
* 当前chunkList的前驱list节点
* 前驱节点仅在PoolArena的构造函数中进行更新,本质上也可以看作时final的(因为构造对象时必须按照顺序创建,无法同时指定一个节点的前驱和后继)
* */
private MyPoolChunkList<T> prevList;
MyPoolChunkList(MyPoolArena<T> arena, MyPoolChunkList<T> nextList, int minUsage, int maxUsage, int chunkSize) {
this.arena = arena;
this.nextList = nextList;
this.minUsage = minUsage;
this.maxUsage = maxUsage;
// 计算出最大可用空间,方便下面计算空闲空间阈值上下限
maxCapacity = calculateMaxCapacity(minUsage, chunkSize);
// 基于最大使用率maxUsage,计算出最小的剩余空间阈值
freeMinThreshold = (maxUsage == 100) ? 0 : (int) (chunkSize * (100.0 - maxUsage + 0.99999999) / 100L);
// 基于最小使用率minUsage,计算出最大的剩余空间阈值
freeMaxThreshold = (minUsage == 100) ? 0 : (int) (chunkSize * (100.0 - minUsage + 0.99999999) / 100L);
}
/**
* 基于最小使用率和chunkSize计算出当前chunkList中所包含的PoolChunk最大可用空间
*/
private static int calculateMaxCapacity(int minUsage, int chunkSize) {
minUsage = minUsage0(minUsage);
if (minUsage == 100) {
// If the minUsage is 100 we can not allocate anything out of this list.
// 如果最小使用率都是100%了,那就没有额外空间可以继续分配了
return 0;
}
// Calculate the maximum amount of bytes that can be allocated from a PoolChunk in this PoolChunkList.
//
// As an example:
// - If a PoolChunkList has minUsage == 25 we are allowed to allocate at most 75% of the chunkSize because
// this is the maximum amount available in any PoolChunk in this PoolChunkList.
return (int) (chunkSize * (100L - minUsage) / 100L);
}
private static int minUsage0(int value) {
return max(1, value);
}
void setPrevList(MyPoolChunkList<T> prevList) {
this.prevList = prevList;
}
/**
* 向当前PoolChunkList申请分配内存
* @return true 分配成功
* false 分配失败
* */
boolean allocate(MyPooledByteBuf<T> buf, int reqCapacity, MySizeClassesMetadataItem sizeClassesMetadataItem) {
if (sizeClassesMetadataItem.getSize() > maxCapacity) {
// 所申请的内存超过了当前ChunkList中Chunk单元的最大空间,无法分配返回false
return false;
}
for (MyPoolChunk<T> currentChunk = head; currentChunk != null; currentChunk = currentChunk.next) {
// 从head节点开始遍历当前Chunk链表,尝试进行分配
if (currentChunk.allocate(buf, reqCapacity, sizeClassesMetadataItem)) {
// 当前迭代的Chunk分配内存成功,空闲空间减少
// 判断一下分配后的空闲空间是否低于当前最小阈值
if (currentChunk.freeBytes <= freeMinThreshold) {
// 分配后确实低于了当前ChunkList的最小阈值,将当前Chunk从原有的ChunkList链表中摘除
// 尝试将其放入后面内存使用率更高的ChunkList里(不一定就能放入直接后继,如果一次分配了很多,可能会放到更后面的ChunkList里)
remove(currentChunk);
nextList.add(currentChunk);
}
// 分配成功,返回true
return true;
}
}
// 遍历了当前ChunkList中的所有节点,没有任何一个Chunk单元能够进行分配,返回false
return false;
}
private boolean move0(MyPoolChunk<T> chunk) {
if (prevList == null) {
// q000这个ChunkList是相对特殊的,prevList为null。在这个ChunkList中的Chunk如果低于了阈值,说明Chunk已经完全空闲了,返回false,在上层将Chunk直接销毁
return false;
}else{
// 将当前Chunk移动到空间使用率更低的ChunkList中(prev)
return prevList.move(chunk);
}
}
private boolean move(MyPoolChunk<T> chunk) {
// 如果当前chunk的空闲空间大于当前PoolChunkList的最大空闲空间阈值
if (chunk.freeBytes > freeMaxThreshold) {
// 尝试着将其往空间使用率更低的PoolChunkList里放
return move0(chunk);
}
// 当前chunk的空间使用率与当前PoolChunkList匹配,可以将其插入
add0(chunk);
return true;
}
void add(MyPoolChunk<T> chunk) {
// 如果当前chunk的空闲空间少于当前PoolChunkList的最小空闲空间阈值
if (chunk.freeBytes <= freeMinThreshold) {
// 尝试着将其往空间使用率更高的PoolChunkList里放
nextList.add(chunk);
return;
}
// 当前chunk的空间使用率与当前PoolChunkList匹配,可以将其插入
add0(chunk);
}
/**
* 将chunk节点插入到当前双向链表的头部
* */
void add0(MyPoolChunk<T> chunk) {
chunk.parent = this;
if (head == null) {
// 如果当前链表为空,则新插入的这个chunk自己当头结点
head = chunk;
chunk.prev = null;
chunk.next = null;
} else {
// 当前插入的chunk作为新的head头节点
chunk.prev = null;
chunk.next = head;
head.prev = chunk;
head = chunk;
}
}
/**
* 将当前节点从其所属的双向链表中移除
* */
private void remove(MyPoolChunk<T> currentNode) {
if (currentNode == head) {
// 如果需要摘除的是头结点,则令其next节点为新的head节点
head = currentNode.next;
if (head != null) {
// 如果链表不为空(老head节点存在next),将老的head节点彻底从其next节点中摘除
head.prev = null;
}
} else {
// 是双向链表的非头结点,将其prev与next直接进行关联
MyPoolChunk<T> next = currentNode.next;
currentNode.prev.next = next;
if (next != null) {
next.prev = currentNode.prev;
}
}
}
}PoolChunk工作原理解析
现在来分析Normal级别内存分配中最核心的组件,即PoolChunk。PoolChunk是一个完整的连续内存块,但却要同时满足不同大小的内存分配,因此如何高效的标识和追踪块中哪部分的内存已被分配,哪部分的内存空闲可供分配便是PoolChunk的重中之重。
PoolChunk中将页(Page)作为内存分配的最小单元,对于Normal级别的内存分配,本质就是分配1个或多个连续的Page页(run)。对于PoolChunk来说,分配时通过修改其元数据,将被分配出去的Page页标明为已分配;而内存被释放时,则将对应的Page页由已分配改为空闲、待分配的状态即可。
同时出于性能的考虑,一次内存分配所划分出去的多个Page页内存必须是连续的,因此PoolChunk的元数据除了要追踪分配出去的页面的数量,也必须明确的追踪到各个页之间的连续性。
handle
Netty中使用handle作为元数据,标识一段连续内存段。
- handle是一个long类型的64位的变量,在逻辑上按照位数被划分为了5个不同的字段属性。
// a handle is a long number, the bit layout of a run looks like:(一个handle是一个long类型的数字,其bit位布局如下所述)
// oooooooo ooooooos ssssssss ssssssue bbbbbbbb bbbbbbbb bbbbbbbb bbbbbbbb
// o: runOffset (page offset in the chunk), 15bit(前15位offset)
// s: size (number of pages) of this run, 15bit(接着15位是run的大小(该run内存段一共多少个page))
// u: isUsed?, 1bit(接着1位标识着是否已被使用)
// e: isSubpage?, 1bit(接着1位标识着该run内存段是否为用于small类型分配的subPage)
// b: bitmapIdx of subpage, zero if it's not subpage, 32bit(最后32位标识着subPage是否使用的位图,如果isSubpage=0,则则全为0)
在lab7中,我们暂时只实现了Normal级别的内存分配,而subpage是用于Small级别内存分配的,因此先重点关注前面4个字段属性即可。读写handle的对应字段时,均采用位运算进行操作。 - 一个PoolChunk在被创建时,基于Chunk大小和Page页大小被划分为了M个相同大小的Page页(类似电影院的座位,每个座位就是一个Page页)。
第一个属性是runOffset,即当前内存段的起始位置在第几个Page页。
第二个属性是size,即handle所标识的连续内存段有多长,一共几个Page页大小(类似一家人买了个连号,都挨着坐一起)。
第三个属性是isUsed,是否使用。一个handle被分配出去了,isUsed=1;未被分配出去则isUsed=0。
第四个属性是isSubPage,是否是SubPage类型的内存段,用于Small级别的分配。在lab7中,所有的handle的isSubPage值都为0。 - 在PoolChunk刚被创建时,整个Chunk被视为一个未被使用的、完整的连续内存段,所以在构造方法中,构造了一个initHandle来标识这一整个内存段。
runsAvail
在了解了handle的机制后,接下来要思考一个问题。每次Normal级别的分配可能是分配1个Page,也可能是分配2个、3个或者10个Page。那么如何才能以最快的速度找到isUsed=0且大小足够的handle内存段,并尽可能的减少内存碎片呢?
- PoolChunk中另一个关键的数据结构便是runsAvail数组,其内部存储的是LongPriorityQueue类型的对象。
runsAvail中的每一项都对应一种特定大小的内存段,其中每一项的大小与SizeClasses中构建的pageIdx2sizeTab一一对应(因为最终申请的都是规范化后的大小),比如第0项存放大小为1页的连续内存段,第1项存放大小为2页的连续内存段,依次类推,第31项存放的是大小为512页的连续内存段。
PoolChunk被创建初始化时,initHandle作为规格最大的连续内存段(如果PoolChunk有512页,则initHandle对应的连续内存段大小也为512),被放在了runAvail数组的最后一项对应的LongPriorityQueue中。 - 当需要分配内存时(runFirstBestFit方法),会从最小的能满足当前申请大小的项开始遍历runsAvail,比如要申请3*8KB(3页)时,就从第2项开始从小到大的查找。
如果当前项对应的LongPriorityQueue不为空,说明存在对应规格的空闲内存段可供分配。如果当前项LongPriorityQueue为空,则一直往后查找。
特别的,如果遍历完整个runAvail数组,都没有发现不为空的LongPriorityQueue项,说明当前PoolChunk无法满足当前内存申请的分配,分配失败,allocate方法返回false。 - 使用LongPriorityQueue而不是普通的Long类型集合(比如List)来存储空闲handle的原因在于尽可能的减少内存碎片,让被分配的内存段之间的空隙更少。
在有多个相同大小的run可供使用时,统一优先分配runOffset偏移值更小的run能够让实际分配出去的内存段更加有序,排布更加紧凑,减少空间足够但空闲内存段之间不连续而导致分配失败的场景。
Normal级别内存申请分配
- allocateRun方法先通过runsAvailLock对runAvail进行加锁防止并发更新,然后通过runFirstBestFit方法找到最小的,能进行分配的连续内存段。
runFirstBestFit返回-1,则直接返回,代表分配失败。 - runFirstBestFit成功找到可用的连续内存段,则将该内存段对应的handle先从runAvail数组中摘除。然后计算分配完成后,对应空闲run剩余的可用页数量。
如果恰好分配完成,则仅需将对应的run的isUsed设置为1即可。但大多数时候并不会正好分完,而是会剩余一部分。
此时,基于原handle中得偏移量和大小,以及当前分配出去得内存页大小,可以计算出来剩余的空闲内存段的对应偏移量以及剩余大小,生成一个对应的新handle后将其加入到对应规格的runAvail中去。 - runAvail中存储的handle的实际大小与对应下标规格并不是总是完全相等的,而是可能大于。比如一个新的PoolChunk在完成一个8KB(1页)大小的分配后,空闲的run会从第31项转移到第30项中。第31项代表规格为512页,而第30项代表规格为448页,而空闲run的大小实际为511页。
但由于所有的内存申请都是经过SizeClasses规范化处理的,所申请的大小要么是512页,要么是448页,而不会出现介于其中的比如498页这样的请求。
因此位于第30项的空闲runAvail能满足448页以及更小规格的申请,同时也能正确的拒绝掉512页大小的内存申请(可用内存不足)。 - allocateRun如果分配成功,最终会返回被分配出去的那段连续内存段的handle,并且在initBuf中将其与PooledByteBuf对象进行绑定。
PooledByteBuf对象初始化时,底层数组就是PoolChunk中所维护那块内存,并且在读写时通过计算出来的偏移量进行转换,确保最终实际读写的指针位置与PoolChunk中所分配出去的那块连续内存地址相匹配。
Normal级别内存释放归还
PooledByteBuf的deallocate中,通过调用对应PoolArena的free方法进行池化内存的释放。其中PoolChunk的free方法,基本上是进行分配时操作的逆向操作。
- 首先,将之前分配出去的handle中的isUsed设置为0,允许其被分配给其它PooledByteBuf。
- 其次,通过collapseRuns方法,尝试将当前内存段与其前后直接相邻的内存段进行合并。如果其前面,或者后面直接相邻的空闲内存段存在,则将其和直接相邻的空闲内存段合并为一个更大的空闲连续内存段。合并之后的内存段能够满足更大规格的内存分配请求。
- PoolChunk中维护了一个runsAvailMap ,其起到了一个索引的作用。在一个handle被加入到runsAvail数组时,也会将其头、尾页偏移量放入runsAvailMap(一个handler对应两项(insertAvailRun0两次))。
有了runsAvailMap后,便能够在尝试合并相邻内存段时,以O(1)的时间复杂度查找到相邻的空闲内存段是否存在,而不用去遍历整个runAvail数组。
MyNetty PoolChunk实现源码
java
/**
* 内存分配chunk
* */
public class MyPoolChunk<T> {
private static final int SIZE_BIT_LENGTH = 15;
private static final int INUSED_BIT_LENGTH = 1;
private static final int SUBPAGE_BIT_LENGTH = 1;
private static final int BITMAP_IDX_BIT_LENGTH = 32;
static final int IS_SUBPAGE_SHIFT = BITMAP_IDX_BIT_LENGTH;
static final int IS_USED_SHIFT = SUBPAGE_BIT_LENGTH + IS_SUBPAGE_SHIFT;
static final int SIZE_SHIFT = INUSED_BIT_LENGTH + IS_USED_SHIFT;
static final int RUN_OFFSET_SHIFT = SIZE_BIT_LENGTH + SIZE_SHIFT;
/**
* 当前chunk属于哪个arena
*/
final MyPoolArena<T> arena;
/**
* directByteBuffer的os内存基地址
*/
final Object base;
/**
* 所管理的内存对象
*/
final T memory;
/**
* chunk中page页的大小,page是chunk中最小的分配单元
*/
final int pageSize;
/**
* pageSize的二次对数值
* log2(pageSize) = pageShifts
*/
final int pageShifts;
/**
* chunk的大小,也就是本PoolChunk可以分配的总内存大小
*/
final int chunkSize;
/**
* 最多有多少种PageSize的规格
*/
int maxPageIdx;
/**
* 当前chunk还未分配的空闲内存大小
*/
int freeBytes;
/**
* 当前chunk所属的chunkList
*/
MyPoolChunkList<T> parent;
/**
* 当前chunk在chunkList双向链表中的前驱节点
*/
MyPoolChunk<T> prev;
/**
* 当前chunk在chunkList双向链表中的后继节点
*/
MyPoolChunk<T> next;
final boolean unpooled;
/**
* manage all avail runs
* 每一种page规格都通过一个优先级队列(IntPriorityQueue)进行维护
*/
private final LongPriorityQueue[] runsAvail;
/**
* store the first page and last page of each avail run
*/
private final LongLongHashMap runsAvailMap;
/**
* 分配与释放内存时,防止并发操作runsAvail的互斥锁
*/
private final ReentrantLock runsAvailLock;
private final AtomicLong pinnedBytes = new AtomicLong();
/**
* 用于small和normal类型分配的构造函数 unpooled为false,需要池化
* */
public MyPoolChunk(MyPoolArena<T> arena, Object base, T memory, int pageSize, int pageShifts, int chunkSize, int maxPageIdx) {
this.unpooled = false;
this.arena = arena;
this.base = base;
this.memory = memory;
this.pageSize = pageSize;
this.pageShifts = pageShifts;
this.chunkSize = chunkSize;
this.maxPageIdx = maxPageIdx;
// 初始化时,所有的内存都还没有分配过,所以freeBytes就等于chunkSize
this.freeBytes = chunkSize;
// 每一种page规格都通过一个优先级队列(IntPriorityQueue)进行维护
// 优先级队列中维护的int类型数据被称为handle,本质上是一段连续内存段(被称为run)的元数据。
this.runsAvail = newRunsAvailQueueArray(maxPageIdx);
// 分配与释放内存时,防止并发操作runsAvail的互斥锁
runsAvailLock = new ReentrantLock();
this.runsAvailMap = new LongLongHashMap(-1);
// todo PoolSubpage用于small级别的分配,等后面再实现
// subpages = new PoolSubpage[chunkSize >> pageShifts];
// 一个chunk一共有多少个Page单元
int pages = chunkSize >> pageShifts;
// a handle is a long number, the bit layout of a run looks like:(一个handle是一个long类型的数字,其bit位布局如下所述)
// oooooooo ooooooos ssssssss ssssssue bbbbbbbb bbbbbbbb bbbbbbbb bbbbbbbb
// o: runOffset (page offset in the chunk), 15bit(前15位offset)
// s: size (number of pages) of this run, 15bit(接着15位是run的大小(该run内存段一共多少个page))
// u: isUsed?, 1bit(接着1位标识着是否已被使用)
// e: isSubpage?, 1bit(接着1位标识着该run内存段是否为用于small类型分配的subPage)
// b: bitmapIdx of subpage, zero if it's not subpage, 32bit(最后32位标识着subPage是否使用的位图,如果isSubpage=0,则则全为0)
// initHandle = 000000000000000 000001000000000 0 0 0000 0000 0000 0000 0000 0000 0000 0000
// 偏移量为0,标识一整个run的pages总数为512,u=0未被使用,e=0不是用于subpage
long initHandle = (long) pages << SIZE_SHIFT;
// 将当前初始化好的handle插入到runsAvail中(空的PoolChunk里面就只有一个run,起始的offset=0,尾部的offset=511,总长度正好是PoolChunk的总页数512)
insertAvailRun(0, pages, initHandle);
// cachedNioBuffers相关逻辑暂不实现
// cachedNioBuffers = new ArrayDeque<ByteBuffer>(8);
}
/**
* 用于huge类型分配的构造函数 unpooled为true,不需要池化
* */
MyPoolChunk(MyPoolArena<T> arena, Object base, T memory, int size) {
unpooled = true;
this.arena = arena;
this.base = base;
this.memory = memory;
pageSize = 0;
pageShifts = 0;
runsAvailMap = null;
runsAvail = null;
runsAvailLock = null;
// subpages = null;
chunkSize = size;
}
private void insertAvailRun(int runOffset, int pages, long handle) {
// 获得当前申请page个数的最终分配规格
int pageIdxFloor = arena.getMySizeClasses().pages2pageIdxFloor(pages);
// 找到对应规格的handle优先级队列,将对应的handle放进去
LongPriorityQueue queue = runsAvail[pageIdxFloor];
queue.offer(handle);
// 写入handle的起始runOffset的索引
insertAvailRun0(runOffset, handle);
if (pages > 1) {
// 计算出当前handle的最后一个page的offset(offset + pages - 1)
int lastPage = lastPage(runOffset, pages);
// 写入handle的末尾runOffset的索引
insertAvailRun0(lastPage, handle);
}
}
private void insertAvailRun0(int runOffset, long handle) {
runsAvailMap.put(runOffset, handle);
}
private static int lastPage(int runOffset, int pages) {
return runOffset + pages - 1;
}
private static LongPriorityQueue[] newRunsAvailQueueArray(int size) {
LongPriorityQueue[] queueArray = new LongPriorityQueue[size];
for (int i = 0; i < queueArray.length; i++) {
queueArray[i] = new LongPriorityQueue();
}
return queueArray;
}
boolean allocate(MyPooledByteBuf<T> buf, int reqCapacity, MySizeClassesMetadataItem mySizeClassesMetadataItem) {
long handle;
if (mySizeClassesMetadataItem.getSizeClassEnum() == SizeClassEnum.SMALL) {
// todo small分配待实现
handle = -1;
} else {
// 除了Small就只可能是Normal,huge的不去池化,进不来
// runSize must be multiple of pageSize(normal类型分配的连续内存段的大小必须是pageSize的整数倍)
int runSize = mySizeClassesMetadataItem.getSize();
handle = allocateRun(runSize);
if (handle < 0) {
return false;
}
}
// 分配成功,将这个空的buf对象进行初始化
initBuf(buf,null,handle,reqCapacity);
return true;
}
void initBuf(MyPooledByteBuf<T> buf, ByteBuffer nioBuffer, long handle, int reqCapacity) {
// if (isSubpage(handle)) {
// initBufWithSubpage(buf, nioBuffer, handle, reqCapacity, threadCache);
// } else {
int maxLength = runSize(pageShifts, handle);
buf.init(this, nioBuffer, handle, runOffset(handle) << pageShifts,
reqCapacity, maxLength);
// }
}
public void incrementPinnedMemory(int delta) {
pinnedBytes.addAndGet(delta);
}
public void decrementPinnedMemory(int delta) {
pinnedBytes.addAndGet(-delta);
}
public T getMemory() {
return memory;
}
public MyPoolArena<T> getArena() {
return arena;
}
public boolean isUnpooled() {
return unpooled;
}
/**
* 分配一个大小等于runSize的连续内存段
* @return >=0 分配成功,返回对应的handle描述符
* <0 分配失败
* */
private long allocateRun(int runSize) {
// 一共要申请多少页
int pages = runSize >> pageShifts;
// 页数对应的规格
int pageIdx = arena.getMySizeClasses().pages2pageIdx(pages);
// 加锁防并发
runsAvailLock.lock();
try {
// 伙伴系统,从小到大查找,找到最合适的可分配内存段规格(在满足大小的情况下,尽可能的小)
int queueIdx = runFirstBestFit(pageIdx);
if (queueIdx == -1) {
// 没有找到可用的内存段,分配失败,返回负数
return -1;
}
LongPriorityQueue queue = runsAvail[queueIdx];
// 在存储内存段的优先级队列中,poll返回的是offset最小的run
long unUsedHandle = queue.poll();
// 将待分配的handle对应的内存段从queue中先摘出来
removeAvailRun(queue, unUsedHandle);
// 一个大的run,在分配了一部分内存出去后,需要进行拆分
long allocatedRunHandle = splitLargeRun(unUsedHandle, pages);
// 获得所分配handle的总大小
int pinnedSize = runSize(pageShifts, allocatedRunHandle);
// 分配成功后,当前Chunk空闲大小减去本次被分配的大小
freeBytes -= pinnedSize;
// 返回当前分配出去的内存段对应的handle
return allocatedRunHandle;
} finally {
// 操作完毕,释放互斥锁
runsAvailLock.unlock();
}
}
/**
* 从handle中获得对应内存段的总大小
* */
static int runSize(int pageShifts, long handle) {
// 一共多少页
int runPages = runPages(handle);
// 页数 * 页大小 = 总大小
return runPages << pageShifts;
}
/**
* 基于偏移量,从handle中获得pages属性
* */
static int runPages(long handle) {
return (int) (handle >> SIZE_SHIFT & 0x7fff);
}
/**
* 基于偏移量,从handle中获得offset属性
* */
static int runOffset(long handle) {
return (int) (handle >> RUN_OFFSET_SHIFT);
}
/**
* 伙伴系统,从小到大查找,找到最合适的可分配内存段规格(在满足大小的情况下,尽可能的小)
* */
private int runFirstBestFit(int pageIdx) {
int nPSizes = arena.getMySizeClasses().getNPageSizes();
if (freeBytes == chunkSize) {
// 特殊情况,说明整个PoolChunk只有一个最大的完整的run,直接返回最后一个
return nPSizes - 1;
}
// 伙伴系统,从pageIdx对应的规格开始从小往大查找,直到从对应的LongPriorityQueue中找到一个可以用来分配的内存段规格
for (int i = pageIdx; i < nPSizes; i++) {
LongPriorityQueue queue = runsAvail[i];
if (queue != null && !queue.isEmpty()) {
// 找到了一个不为空的队列,说明内部存在对应的可供分配的run,返回runsAvail下标
return i;
}
}
// 遍历了一遍,发现无法分配
return -1;
}
private void removeAvailRun(LongPriorityQueue queue, long handle) {
// 将handle从当前LongPriorityQueue中移除
queue.remove(handle);
// 将handle在runsAvailMap中的索引也一并移除
int runOffset = runOffset(handle);
int pages = runPages(handle);
// remove first page of run
runsAvailMap.remove(runOffset);
if (pages > 1) {
// remove last page of run
runsAvailMap.remove(lastPage(runOffset, pages));
}
}
private void removeAvailRun(long handle) {
int pageIdxFloor = arena.getMySizeClasses().pages2pageIdxFloor(runPages(handle));
LongPriorityQueue queue = runsAvail[pageIdxFloor];
removeAvailRun(queue, handle);
}
private long splitLargeRun(long handle, int needPages) {
// 计算出待分配的当前handle一共多少页
int totalPages = runPages(handle);
// 分配完成后剩余多少页
int remPages = totalPages - needPages;
if (remPages > 0) {
// 当前handle内存段在分配后还有空余,需要进行拆分
// 获得当前待拆分handle的偏移
int runOffset = runOffset(handle);
// 将待拆分的handle前面这部分分配出去,计算出剩余的那段内存的偏移量
int availOffset = runOffset + needPages;
// 剩余的那段内存段转换为一个新的handle放入当前Chunk中(inUsed=0 未使用)
long availRun = toRunHandle(availOffset, remPages, 0);
insertAvailRun(availOffset, remPages, availRun);
// 返回分配出去的那段run的handle(inUsed=1 已使用)
return toRunHandle(runOffset, needPages, 1);
}else{
// 当前handle内存段被完整的分配掉了,直接整体标记为已使用即可
handle |= 1L << IS_USED_SHIFT;
return handle;
}
}
/**
* 基于runOffset、runPages和inUsed 构建一个long类型的handle结构
* */
private static long toRunHandle(int runOffset, int runPages, int inUsed) {
return (long) runOffset << RUN_OFFSET_SHIFT
| (long) runPages << SIZE_SHIFT
| (long) inUsed << IS_USED_SHIFT;
}
/**
* 释放之前分配出去的内存
* @param handle 之前分配出去的内存段handle
* */
void free(long handle, int normCapacity) {
// 获得所释放内存段的大小
int runSize = runSize(pageShifts, handle);
// todo subPage free 下个版本再实现
// 开始释放内存,加锁防并发
runsAvailLock.lock();
try {
// 伙伴算法,在回收时,如果对应的内存段前后存在同样空闲的内存段,将其合并为一个更大的空闲内存段
long finalRun = collapseRuns(handle);
// 整个内存段设置为未使用(可能合并了,也可能就只是回收了当前内存段)
finalRun &= ~(1L << IS_USED_SHIFT);
// // if it is a subpage, set it to run
// finalRun &= ~(1L << IS_SUBPAGE_SHIFT);
// 将空闲的内存段插入到PoolChunk中
insertAvailRun(runOffset(finalRun), runPages(finalRun), finalRun);
// 回收后,空闲字节数增加对应的值
freeBytes += runSize;
} finally {
runsAvailLock.unlock();
}
}
/**
* 尝试合并与handle头尾相邻的内存段
* */
private long collapseRuns(long handle) {
// 先尝试和handle内存段头部相邻的内存段合并
long afterCollapsePast = collapsePast(handle);
// 再尝试和尾部相邻的内存段合并
return collapseNext(afterCollapsePast);
}
private long collapsePast(long currentHandle) {
for (;;) {
int runOffset = runOffset(currentHandle);
int runPages = runPages(currentHandle);
// 从索引中尝试获得当前handle头部相邻的内存段(与头部直接相邻,就是比当前内存段的runOffset恰好少1)
long pastRun = getAvailRunByOffset(runOffset - 1);
if (pastRun == -1) {
// 返回-1,说明与当前内存段头部相邻的内存段不存在(已经被分配出去了或者当前内存段的起始达到了左边界) 合并结束,直接返回
return currentHandle;
}
int pastOffset = runOffset(pastRun);
int pastPages = runPages(pastRun);
if (pastRun != currentHandle && pastOffset + pastPages == runOffset) {
// 发现可以进行合并,将前面的handle内存与当前handle合并成一个更大的内存段run
// 先从Chunk中摘掉之前的run
removeAvailRun(pastRun);
// 合并成一个新的,更大的内存段(offset以前一段内存的offset为准,大小为两个run的和,inUsed=0代表未分配)
currentHandle = toRunHandle(pastOffset, pastPages + runPages, 0);
// 这个过程可以循环往复多次,反复合并,所以是循环处理(什么时候会反复合并?没想通)
} else {
// 无法再继续合并了
return currentHandle;
}
}
}
private long collapseNext(long handle) {
for (;;) {
int runOffset = runOffset(handle);
int runPages = runPages(handle);
// 从索引中尝试获得当前handle尾部相邻的内存段(与尾部直接相邻,就是其起始的offset等于当前内存段的runOffset+页数pages)
long nextRun = getAvailRunByOffset(runOffset + runPages);
if (nextRun == -1) {
// 返回-1,说明与当前内存段尾部相邻的内存段不存在(已经被分配出去了或者当前内存段的末尾达到了右边界) 合并结束,直接返回
return handle;
}
int nextOffset = runOffset(nextRun);
int nextPages = runPages(nextRun);
if (nextRun != handle && runOffset + runPages == nextOffset) {
// 发现可以进行合并,将尾部的handle内存与当前handle合并成一个更大的内存段run
// 先从Chunk中摘掉之前的run
removeAvailRun(nextRun);
// 合并成一个新的,更大的内存段(offset以前当前offset为准,大小为两个run的和,inUsed=0代表未分配)
handle = toRunHandle(runOffset, runPages + nextPages, 0);
// 这个过程和collapsePast一样,同样可以循环往复多次,反复合并,所以是循环处理(什么时候会反复合并?没想通)
} else {
return handle;
}
}
}
private long getAvailRunByOffset(int runOffset) {
return runsAvailMap.get(runOffset);
}
}总结
- 在MyNetty的lab7中,实现了PooledByteBuf对象的池化功能,以及Normal规格的池化内存功能。并结合jemalloc的论文,解析其背后的设计原理。
PooledByteBuf对象的池化功能基于一个轻量级的对象池实现,核心是本地线程缓存的LocalPool和多写单读的MessagePassingQueue。
Normal规格的内存池化由SizeClasses、PoolArena、PoolChunkList和PoolChunk这几个组件合作完成。其中核心是SizeClasses中的规范化和PoolChunk中通过handle追踪连续内存段,以及连续内存段的拆分和合并逻辑。 - lab7是MyNetty实现完整池化ByteBuf容器功能的第一个迭代,为后续实现Small规格内存池化以及池化内存的本地线程缓存打下了基础。相信在理解了MyNetty中简易版的池化内存实现后,能帮助读者后续更好的理解Netty中更为复杂,细节更多的池化内存功能。
- 最后强烈推荐一下大佬的技术博客:bin的技术小屋 谈一谈Netty的内存管理------且看Netty如何实现Java版的Jemalloc,里面的内容全面且图文并茂,在我研究Netty池化内存原理的过程中给予了我非常大的帮助。
博客中展示的完整代码在我的github上:https://github.com/1399852153/MyNetty (release/lab7_normal_allocate 分支),内容如有错误,还请多多指教。