原文:nolanlawson.com/2025/08/31/...
翻译:安东尼
前端周刊进群:flowus.cn/48d73381-69...
运行 bun install 很快,是真的很快。平均而言,它比 npm 快约 7 倍,比 pnpm 快约 4 倍,比 yarn 快约 17 倍。在大型代码库里差异尤其明显------原本要花几分钟的事,现在只要(毫)秒。
这并不是挑选有利数据的"cherry pick"。Bun 之所以快,是因为它把"安装依赖"当成系统编程 问题,而不是 JavaScript 问题。
这篇文章我们就来展开说说:从尽量减少系统调用、把清单缓存成二进制、优化 tar 包解压、利用操作系统原生的文件复制能力,到把工作扩展到多核 CPU。
但在理解"为什么这很重要"之前,我们先小小回到过去。
现在是 2009 年。你从一个 .zip 文件安装 jQuery,你的 iPhone 3GS 只有 256MB 内存。GitHub 诞生才一年,256GB 的 SSD 要价 700 美元。你的笔记本配置着 5400RPM 机械硬盘,极限 100MB/s,"宽带"意味着 10Mbps(还是运气不错时)。

更重要的是: **Node.js 刚刚发布!**Ryan Dahl 登台解释为什么服务器的大部分时间都耗在"等待"上。
在 2009 年,一次典型的磁盘寻道需要 10ms,一次数据库查询 50--200ms,向外部 API 发起一个 HTTP 请求要 300ms+。在这些事务期间,传统服务器会......一直等着。你的服务器开始读一个文件,然后就卡住了 10ms。
现在把这个过程乘以"成千上万的并发连接",每个连接都在做多次 I/O。服务器大约 95% 的时间都在等 I/O。
Node.js 发现 JavaScript 的事件循环(最初为浏览器事件而设计)非常适合服务器 I/O。当代码发起一个异步请求时,I/O 会在后台进行,而主线程立刻继续做下一件事。完成后,对应的回调被排入队列执行。
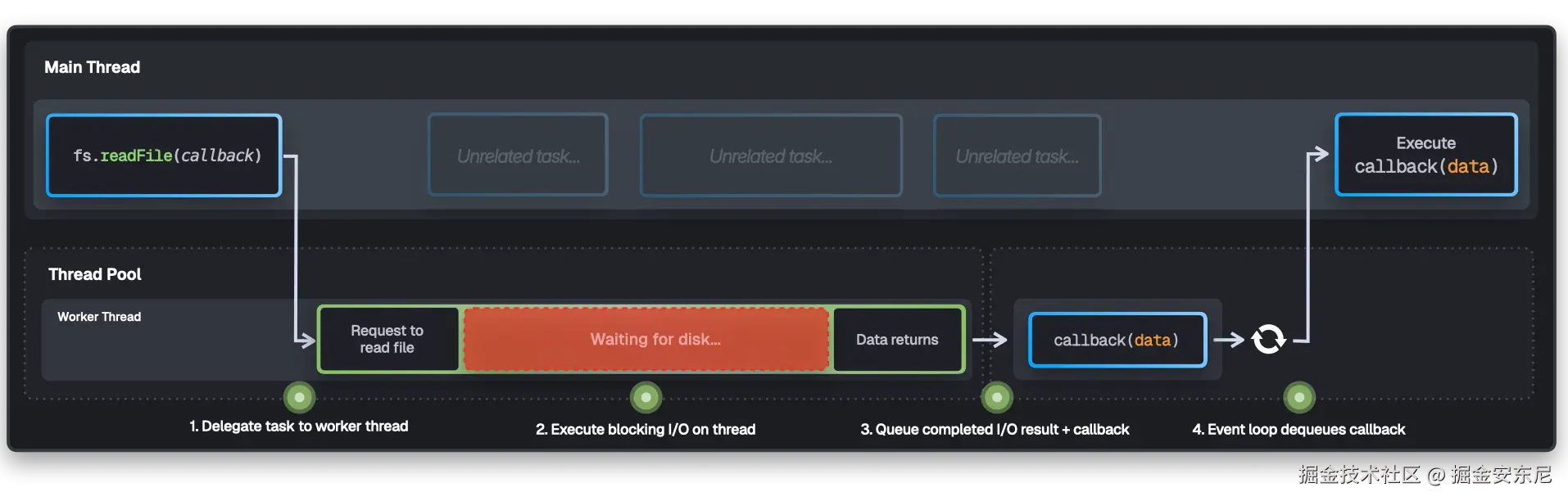
下面是 Node.js 处理
fs.readFile的事件循环 + 线程池的简化示意。为简洁起见省略了其他异步来源与实现细节。
JavaScript 的事件循环在那个"等待数据才是主要瓶颈"的世界里是一剂良方。
随后 15 年里,Node 的架构塑造了我们的工具构建方式。包管理器继承了 Node 的线程池、事件循环、异步范式------在磁盘寻道 10ms 的时代非常合理的优化。
但硬件变了。现在不是 2009 年了,而是 16 年后(难以置信吧)。我正在用的这台 M4 Max MacBook,在 2009 年能排进全球最快超级计算机的前 50。如今的 NVMe 能跑到 7000MB/s,比 Node 设计时的世界快 70× !慢吞吞的机械硬盘离场,网络可以流畅看 4K,连入门级手机的内存都比 2009 年的高端服务器更多。
然而今天的包管理器仍在优化"上个十年"的问题。在 2025 年,真正的瓶颈不再是 I/O,而是系统调用。
系统调用的问题(The Problem with System Calls)
每当你的程序需要操作系统做点事(读文件、开网络连接、分配内存),它就要发起一个系统调用。每次系统调用,CPU 都得做一次"模式切换"。
CPU 有两种运行模式:
● 用户态(user mode) :你的应用代码在这里运行,不能直接访问硬件和物理地址。这种隔离防止程序互相干扰或把系统搞崩。
● 内核态(kernel mode):操作系统内核在这里运行,负责调度、内存、磁盘/网络等硬件。只有内核和驱动能在内核态运行。
当你在程序里想打开一个文件(比如 fs.readFile())时,CPU 在用户态下不能直接读磁盘。它得先切到内核态。
在这次切换中,CPU 停下执行你的程序 → 保存状态 → 切换到内核态 → 执行操作 → 再切回用户态。
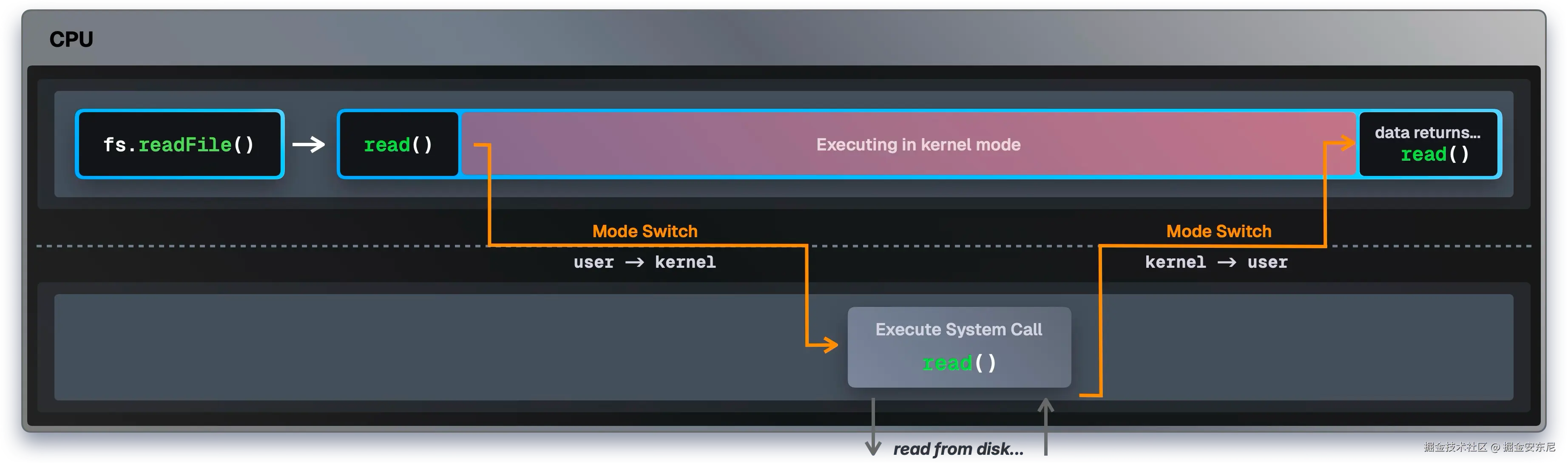
但是,这个模式切换很贵! 光是切换本身就要消耗 1000--1500 个 CPU 周期的纯开销,真正的工作还没开始呢。
CPU 以 GHz 计时。3GHz 的处理器每秒完成 30 亿个周期;每个周期能执行加法、数据搬移、比较等指令。一个周期是 0.33ns。
在 3GHz 下,1000--1500 个周期约等于 500ns。听起来微不足道,但现代 SSD 每秒能处理上百万次操作。如果每次都要系统调用,你光模式切换就烧掉每秒 15 亿个周期!
安装依赖会触发成千上万次系统调用。装个 React 加依赖可能就有 5 万+ 次系统调用:光模式切换就烧掉数秒的 CPU 时间!不是在读文件、也不是在装包,就是在用户态和内核态之间来回切。
这就是为什么 Bun 把安装依赖当系统编程问题来做。它通过减少系统调用并充分利用操作系统的优化来获得速度。
当我们跟踪各包管器的实际系统调用时,差异一目了然:
plain
Benchmark 1: strace -c -f npm install
Time (mean ± σ): 37.245 s ± 2.134 s [User: 8.432 s, System: 4.821 s]
Range (min ... max): 34.891 s ... 41.203 s 10 runs
System calls: 996,978 total (108,775 errors)
Top syscalls: futex (663,158), write (109,412), epoll_pwait (54,496)
Benchmark 2: strace -c -f bun install
Time (mean ± σ): 5.612 s ± 0.287 s [User: 2.134 s, System: 1.892 s]
Range (min ... max): 5.238 s ... 6.102 s 10 runs
System calls: 165,743 total (3,131 errors)
Top syscalls: openat(45,348), futex (762), epoll_pwait2 (298)
Benchmark 3: strace -c -f yarn install
Time (mean ± σ): 94.156 s ± 3.821 s [User: 12.734 s, System: 7.234 s]
Range (min ... max): 89.432 s ... 98.912 s 10 runs
System calls: 4,046,507 total (420,131 errors)
Top syscalls: futex (2,499,660), epoll_pwait (326,351), write (287,543)
Benchmark 4: strace -c -f pnpm install
Time (mean ± σ): 24.521 s ± 1.287 s [User: 5.821 s, System: 3.912 s]
Range (min ... max): 22.834 s ... 26.743 s 10 runs
System calls: 456,930 total (32,351 errors)
Top syscalls: futex (116,577), openat(89,234), epoll_pwait (12,705)
Summary
'strace -c -f bun install' ran
4.37 ± 0.28 times faster than 'strace -c -f pnpm install'
6.64 ± 0.51 times faster than 'strace -c -f npm install'
16.78 ± 1.12 times faster than 'strace -c -f yarn install'
System Call Efficiency:
- bun: 165,743 syscalls (29.5k syscalls/s)
- pnpm: 456,930 syscalls (18.6k syscalls/s)
- npm: 996,978 syscalls (26.8k syscalls/s)
- yarn: 4,046,507 syscalls (43.0k syscalls/s)可以看到,Bun 不仅装得更快,系统调用也更少 。一次普通安装里,yarn 超 400 万次,npm 近 100 万,pnpm 接近 50 万,Bun 只有 16.5 万。
以每次 1000--1500 周期计,yarn 的 400 万次调用意味着它光模式切换就消耗了数十亿 CPU 周期------在 3GHz 处理器上就是几秒纯开销!
不仅如此,看看那些 futex 调用!Bun 只有 762 次(总调用的 0.46%),npm 有 663,158 次(66.51%),yarn 2,499,660 次(61.76%),pnpm 116,577 次(25.51%)。
futex(fast userspace mutex)是 Linux 的线程同步系统调用。线程大多在用户态用原子操作协调,不需要切内核态,很高效。但如果抢到的是"已被占用"的锁,就要 futex 进内核让线程睡眠,直到锁可用。大量 futex 通常意味着线程彼此等待严重,造成延迟。
Bun 到底做了什么不一样?
消灭 JavaScript 运行时开销(Eliminating JavaScript overhead)
npm、pnpm、yarn 都是用 Node.js 写的。在 Node 里,系统调用不是直达的:你在 JS 里调用 fs.readFile(),到真正触达 OS 之前要经过好几层。
Node 使用 C 库 libuv 抽象平台差异,并通过线程池管理异步 I/O。
结果就是,哪怕只读一个文件,也要走这套复杂流水线。以 fs.readFile('package.json', ...) 为例:
- JS 先校验参数并把 UTF-16 的字符串转成 libuv C API 需要的 UTF-8(在 I/O 开始前就会短暂阻塞主线程)。
- libuv 把请求排到 4 个工作线程的队列里;线程都忙的话就排队等。
- 工作线程取到任务,打开文件描述符,执行真正的
read()系统调用。 - 内核切到内核态、从磁盘取数据、把数据返回给工作线程。
- 工作线程通过事件循环把数据推回主线程,最终调度并执行你的回调。
每一次 fs.readFile() 都要这么走。安装依赖要读成千上万份 package.json,还要扫目录、处理元数据......每次线程协调(比如访问任务队列或回传事件)都可能涉及 futex 上锁/等待。
当系统调用成千上万次时,这些"开销"本身就可能比真实的数据搬运更费时。
Bun 走的是另一条路。Bun 用 Zig 写成,编译为原生代码,可以直接发起系统调用:
plain
// 直接系统调用,没有 JS 开销
var file = bun.sys.File.from(try bun.sys.openatA(
bun.FD.cwd(),
abs,
bun.O.RDONLY,
0,
).unwrap());当 Bun 读文件:
- Zig 代码直接调用(如
openat()) - 内核立刻执行系统调用并返回数据
就这样。没有 JS 引擎、没有线程池、没有事件循环、没有跨层编解码。原生代码直接对内核说话。
性能差异不言自明:
plain
Runtime Version Files/Second Performance
Bun v1.2.20 146,057
Node.js v24.5.0 66,576 2.2× slower
Node.js v22.18.0 64,631 2.3× slower这个基准里,Bun 每秒处理 146,057 个 package.json,Node v24.5.0 是 66,576,v22.18.0 是 64,631------超过 2× 。
Bun 的 0.019ms/文件 代表"直接系统调用下的真实 I/O 成本",Node 同样操作要 0.065ms 。用 Node 写的包管理器"被迫"接受 Node 的抽象:有没有必要都要走线程池,每一次文件操作都要付这笔税。
Bun 的包管理器更像一个"懂 JS 包格式的原生应用",而不是一个"用 JS 做系统编程的应用"。
即便 Bun 不是用 Node 写的,你仍然可以在任何 Node 项目里用 bun install,无需更换运行时。Bun 会尊重你现有的 Node 生态和工具链,你只会得到更快的安装速度!
不过到这里,我们还没真正"装包"。接下来看看 Bun 在"安装阶段"做了哪些优化。
当你敲下 bun install,Bun 先解析你的意图:读取传入的 flags,找到 package.json 并解析依赖。
异步 DNS 解析(Async DNS Resolution)
⚠️ 仅在 macOS 上的优化
处理依赖就意味着要发网络请求,而网络请求要先 DNS 将 registry.npmjs.org 这样的域名解析为 IP。
当 Bun 解析 package.json 的同时,就预取 DNS 解析。也就是说,在依赖解析还没结束之前,网络解析已经在路上了。
用 Node 写包管理器时,一个办法是 dns.lookup()。从 JS 看像异步,但底层是阻塞式的 getaddrinfo(),只是放到了 libuv 线程池里,不占主线程而已。
Bun 在 macOS 上用的是苹果的"隐藏"异步 DNS API(getaddrinfo_async_start()),不属于 POSIX 标准,但能通过 mach port (苹果的进程间通信系统)把 DNS 做成"系统级的真正异步"。
DNS 在后台解析时,Bun 可以继续做文件 I/O、网络、依赖分析等工作。等它需要下载 React 时,DNS 很可能已经好了。
这是一个小优化(未单独跑基准),但能看出 Bun 的理念:每一层都要抠细节。
二进制清单缓存(Binary Manifest Caching)
建立和 npm Registry 的连接后,接下来要拿包清单 (manifest)。
清单是 JSON,包含每个包的所有版本、依赖、元数据。热门包(如 React)经常有 100+ 个版本,清单动辄数 MB。
典型清单如下(节选):
json
{
"name": "lodash",
"versions": {
"4.17.20": {
"name": "lodash",
"version": "4.17.20",
"description": "Lodash modular utilities.",
"license": "MIT",
"repository": { "type": "git", "url": "git+https://github.com/lodash/lodash.git" },
"homepage": "https://lodash.com/"
},
"4.17.21": {
"name": "lodash",
"version": "4.17.21",
"description": "Lodash modular utilities.",
"license": "MIT",
"repository": { "type": "git", "url": "git+https://github.com/lodash/lodash.git" },
"homepage": "https://lodash.com/"
}
// ... 100+ 几乎相同的版本
}
}大多数包管器把清单作为 JSON 缓存。下次 npm install 会从缓存读,但每次仍要解析 JSON :语法校验、建对象树、GC......这都是开销。
还不止解析:看 lodash,"Lodash modular utilities." 在每个版本里都重复;"MIT" 重复 100+ 次;仓库 URL、主页 URL 也重复......字符串海量重复 。
在内存里,JS 为每个字符串创建独立对象,既浪费内存,又让比较变慢。比如检查两个包是否用相同 postcss 版本时,你在比较两个不同的字符串对象,而不是复用同一份驻留字符串。
Bun 把清单存成二进制格式。****下载到包信息后,它只解析一次 JSON,然后存为二进制文件( ~/.bun/install/cache/*.npm)。这些二进制文件把包的版本、依赖、校验和等数据都放在****固定的字节偏移 上。
当 Bun 访问 lodash 的 name 时,就是指针算术:string_buffer + offset。没有分配、没有解析、没有对象遍历,只是按位读。
伪代码示意:
plain
// 所有字符串只存一份
string_buffer = "lodash\0MIT\0Lodash modular utilities.\0git+https://github.com/lodash/lodash.git\0https://lodash.com/\04.17.20\04.17.21\0..."
^0 ^7 ^11 ^37 ^79 ^99 ^107
// 固定大小的版本条目
versions = [
{ name_offset: 0, name_len: 6, version_offset: 99, version_len: 7, desc_offset: 11, desc_len: 26, license_offset: 7, license_len: 3, ... }, // 4.17.20
{ name_offset: 0, name_len: 6, version_offset: 107, version_len: 7, desc_offset: 11, desc_len: 26, license_offset: 7, license_len: 3, ... }, // 4.17.21
// ... 100+ 个版本
]为了检查是否有更新,Bun 还存了 ETag,并用 If-None-Match 请求头;npm 返回 304 就知道缓存仍新鲜,连一个字节都不用解析。
基准如下:
plain
Benchmark 1: bun install # fresh
Time (mean ± σ): 230.2 ms ± 685.5 ms [User: 145.1 ms, System: 161.9 ms]
Range (min ... max): 9.0 ms ... 2181.0 ms 10 runs
Benchmark 2: bun install # cached
Time (mean ± σ): 9.1 ms ± 0.3 ms [User: 8.5 ms, System: 5.9 ms]
Range (min ... max): 8.7 ms ... 11.5 ms 10 runs
Benchmark 3: npm install # fresh
Time (mean ± σ): 1.786 s ± 4.407 s [User: 0.975 s, System: 0.484 s]
Range (min ... max): 0.348 s ... 14.328 s 10 runs
Benchmark 4: npm install # cached
Time (mean ± σ): 363.1 ms ± 21.6 ms [User: 276.3 ms, System: 63.0 ms]
Range (min ... max): 344.7 ms ... 412.0 ms 10 runs
Summary
bun install # cached ran
25.30 ± 75.33 times faster than bun install # fresh
39.90 ± 2.37 times faster than npm install # cached
196.26 ± 484.29 times faster than npm install # fresh你会发现,npm 的"缓存安装"居然比 Bun 的"新鲜安装"还慢。这就是解析缓存 JSON(及其他因素)带来的额外负担。
优化 tar 包解压(Optimized Tarball Extraction)
拿到清单后,就要去 Registry 下载并解压 tarball(压缩归档,包含源码与文件)。
大多数包管器以流式方式边收边解压。面对"未知大小"的流,典型写法是这样的:
javascript
let buffer = Buffer.alloc(64 * 1024); // 64KB 起步
let offset = 0;
function onData(chunk) {
while (moreDataToCome) {
if (offset + chunk.length > buffer.length) {
// 不够就扩容
const newBuffer = Buffer.alloc(buffer.length * 2);
buffer.copy(newBuffer, 0, 0, offset); // 复制旧数据
buffer = newBuffer;
}
chunk.copy(buffer, offset);
offset += chunk.length;
}
// ... 从 buffer 解压 ...
}看似合理,但每次扩容都要复制一遍已有数据 ,对性能是个坑。
比如 1MB 包,从 64KB 开始:64→128→256→512→1MB,每步都要拷贝,最终你多拷了 960KB------每个包都这样。

Bun 选择先把整个 tarball 缓存到内存,再解压。
你可能会想:"内存不浪费吗?"------对于像 TypeScript 这种 50MB 压缩包,大概是;但绝大多数 npm 包都很小(<1MB)。在常见场景里,这样能彻底避免重复拷贝。对于大包,现代机器上这点瞬时内存峰值也可接受,且少 5--6 次拷贝往往值得。
把 tarball 全部读入内存后,Bun 会去读 gzip 格式的最后 4 字节 ------里面存的正是解压后的准确大小 。它就可以预分配刚刚好的内存,彻底避免"边长边拷"的增量扩容:
plain
// gzip 最后 4 字节就是未压缩大小
if (tgz_bytes.len > 16) {
const last_4_bytes: u32 = @bitCast(tgz_bytes[tgz_bytes.len - 4 ..][0..4].*);
if (last_4_bytes > 16 and last_4_bytes < 64 * 1024 * 1024) {
esimated_output_size = last_4_bytes;
if (zlib_pool.data.list.capacity == 0) {
zlib_pool.data.list.ensureTotalCapacityPrecise(zlib_pool.data.allocator, last_4_bytes) catch {};
} else {
zlib_pool.data.ensureUnusedCapacity(last_4_bytes) catch {};
}
}
}解压本身,Bun 用 libdeflate,比大多数包管器用的 zlib 更快,针对现代 CPU 的 SIMD 做了优化。

在 Node 里要实现这种优化很麻烦:你得为流另起读流 → seek 到末尾 → 读 4 字节 → 解析 → 关流 → 再重新开始解压。Node 的 API 天性就不适合这种模式。
Zig 就很直接:seek 到尾部,读 4 个字节,搞定。
接下来还有一个挑战:高效存放并访问成千上万个(且相互依赖的)包。
友好的缓存布局(Cache-Friendly Data Layout)
安装过程中,包管器要遍历依赖图:检查版本、解决冲突、决定装谁,还要做 hoist(把依赖"抬"到上层,让多个包共享)。
但依赖图如何布局会显著影响性能。传统包管器大致像这样存:
javascript
const packages = {
next: {
name: "next",
version: "15.5.0",
dependencies: {
"@swc/helpers": "0.5.15",
"postcss": "8.4.31",
"styled-jsx": "5.1.6",
},
},
postcss: {
name: "postcss",
version: "8.4.31",
dependencies: {
nanoid: "^3.3.6",
picocolors: "^1.0.0",
},
},
};这对写 JS 很友好,但对现代 CPU 来说并不好。
JS 对象分配在堆上,packages["next"] 存的是个指针,指到 Next 的数据,再从里面指到它的 dependencies,再指到哈希表里的字符串,层层指针"跳转"。
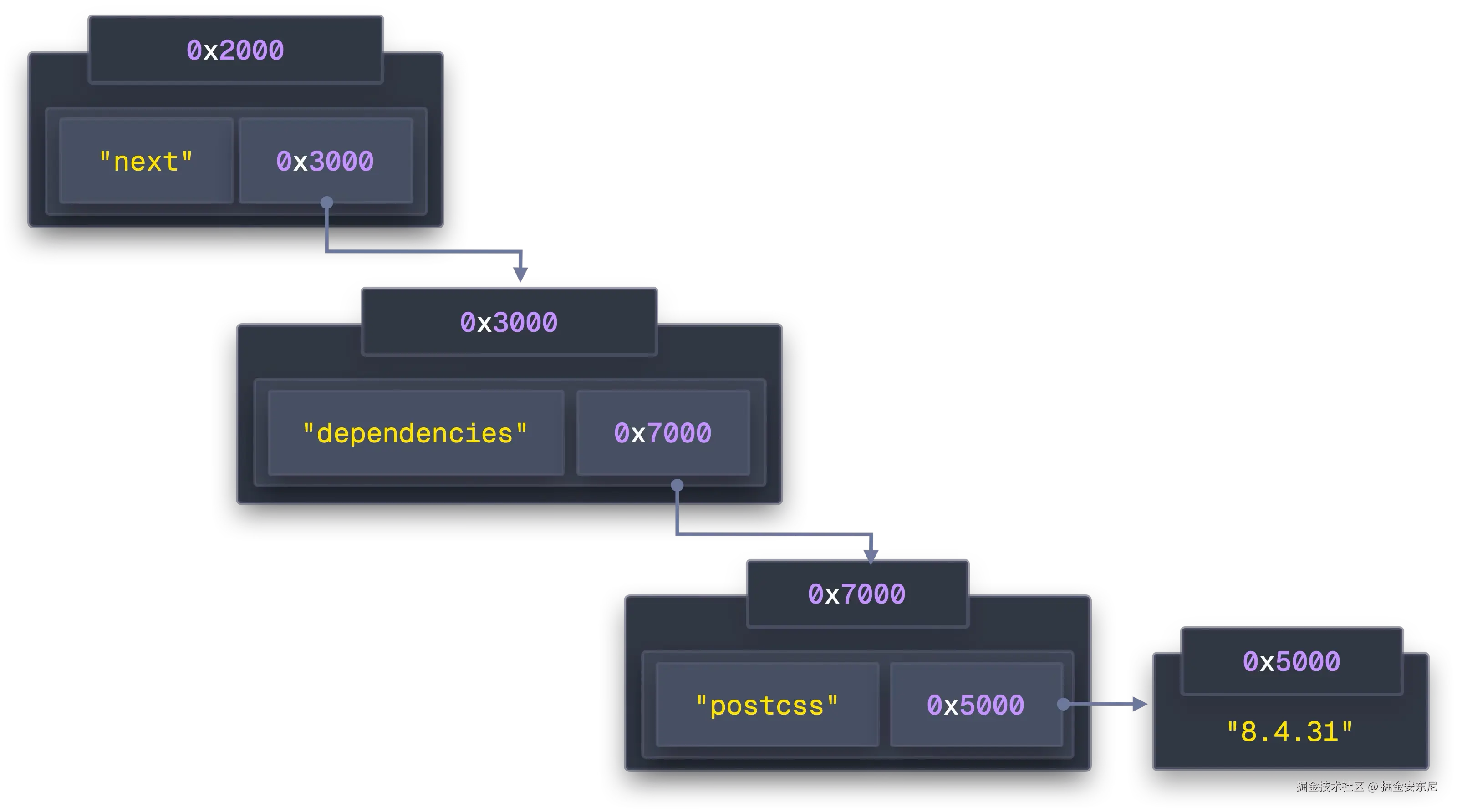
更糟的是,对象的分配地址几乎随机(什么时候创建就占用哪块空闲内存):
javascript
packages["react"] = {/*...*/} // 0x1000
packages["next"] = {/*...*/} // 0x2000
packages["postcss"]= {/*...*/} // 0x8000
// ... 还会有几百个CPU 为了弥补"计算比取数快太多"的差距,有多级缓存(L1/L2/L3),而且以 64 字节 cache line 为单位加载。你的数据如果不连续 ,一次载入的 64 字节多数都浪费了。访问 0x2000 后下一次要 0x8000,就是另一个 cache line;L1 很快被无关数据挤爆,命中率雪崩,每次访问都从 RAM 拉,一次 300 个周期。

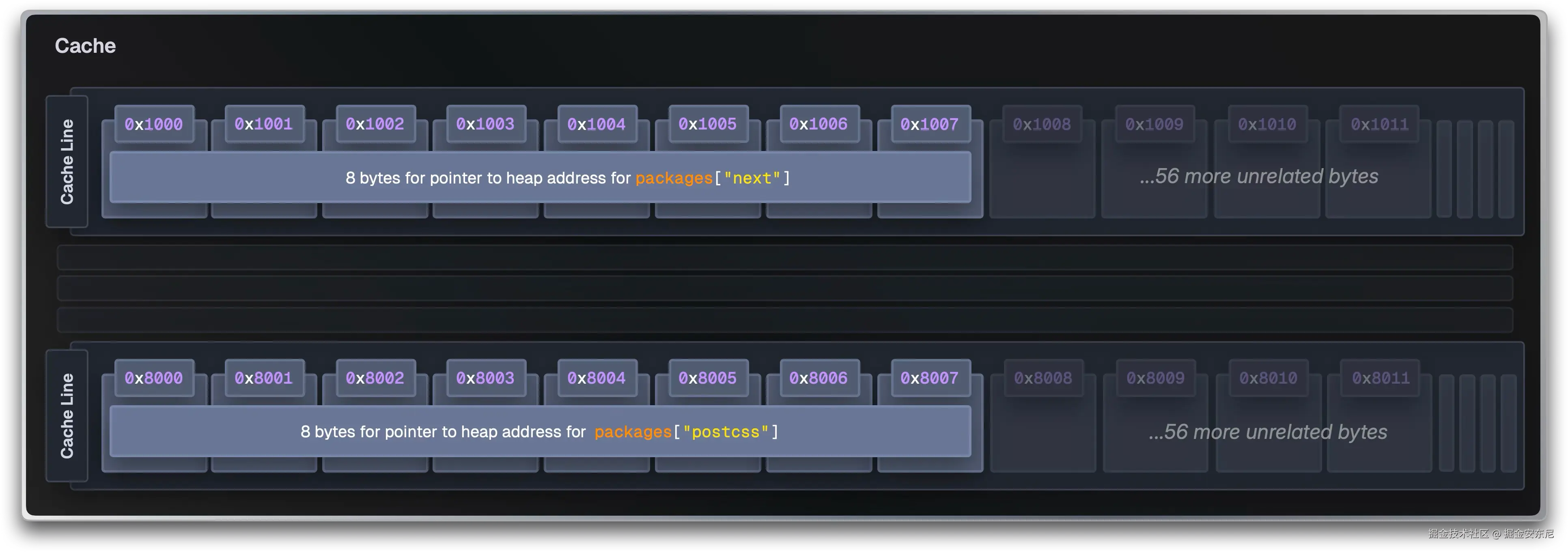
而且"指针追逐(pointer chasing)"会让 CPU 无法预取:它必须等上一跳加载完成,才能知道下一跳去哪。
Bun 则采用 SoA(Structure of Arrays,数组的结构)。不是每个包都维护自己的依赖数组,而是把"所有包的某个字段"集中到一块连续内存里:
javascript
// ❌ 传统 AoS:指针横飞
packages = {
next: { dependencies: { "@swc/helpers": "0.5.15", "postcss": "8.4.31" } },
};
// ✅ Bun 的 SoA:缓存友好
packages = [
{
name: { off: 0, len: 4 },
version: { off: 5, len: 6 },
deps: { off: 0, len: 2 },
}, // next
];
dependencies = [
{ name: { off: 12, len: 13 }, version: { off: 26, len: 7 } }, // @swc/helpers@0.5.15
{ name: { off: 34, len: 7 }, version: { off: 42, len: 6 } }, // postcss@8.4.31
];
string_buffer = "next\015.5.0\0@swc/helpers\00.5.15\0postcss\08.4.31\0";核心思想是:
● packages 里只存轻量的"偏移 + 长度"结构体
● dependencies 集中存所有依赖关系
● string_buffer 把所有文本顺序拼接在一个大字符串里
● versions 把语义化版本压成紧凑结构
访问 Next 的依赖就是简单的 "下标 + 偏移"算术。更妙的是,访问 packages[0] 时,CPU 会把一个 64B 的 cache line 一口气把 packages[0..7] 都带进来,于是你顺序访问时的局部性极好。
最终效果是:无论你有多少包,**只需要 ****~**6 次大块分配,而不是成百上千个小对象的随机分配,缓存命中率直线上升。
优化的锁文件格式(Optimized Lockfile Format)
Bun 把 SoA 的思路也用在 bun.lock 上。
bun install 需要解析锁文件看看哪些已装、哪些要更新。大多数包管器把锁写成嵌套 JSON(npm)或 YAML(pnpm/yarn)。例如 npm 的 package-lock.json:
json
{
"dependencies": {
"next": {
"version": "15.5.0",
"requires": {
"@swc/helpers": "0.5.15",
"postcss": "8.4.31"
}
},
"postcss": {
"version": "8.4.31",
"requires": {
"nanoid": "^3.3.6",
"picocolors": "^1.0.0"
}
}
}
}每个包都是独立对象 + 嵌套对象树。解析 JSON 要分配大量对象,再次引入"指针追逐"。
Bun 的 bun.lock 用 SoA 思路写成人类可读的格式:
json
{
"lockfileVersion": 0,
"packages": {
"next": [
"next@npm:15.5.0",
{ "@swc/helpers": "0.5.15", "postcss": "8.4.31" },
"hash123"
],
"postcss": [
"postcss@npm:8.4.31",
{ "nanoid": "^3.3.6", "picocolors": "^1.0.0" },
"hash456"
]
}
}这样既能去重字符串 ,又能按依赖顺序 存放,方便顺序读取,避免在对象树之间乱跳。Bun 还会根据锁文件大小预分配内存 ,就像解压时那样,避免一遍遍"扩容 + 拷贝"。
顺便提一句:Bun 早期用过二进制锁文件(bun.lockb)来彻底避免 JSON 解析,但二进制难以在 PR 里审阅,也不利于冲突合并。
文件复制(File copying)
把包装进缓存 ~/.bun/install/cache/ 后,接下来要把文件放进 node_modules。这一步对 Bun 的总体性能影响最大。
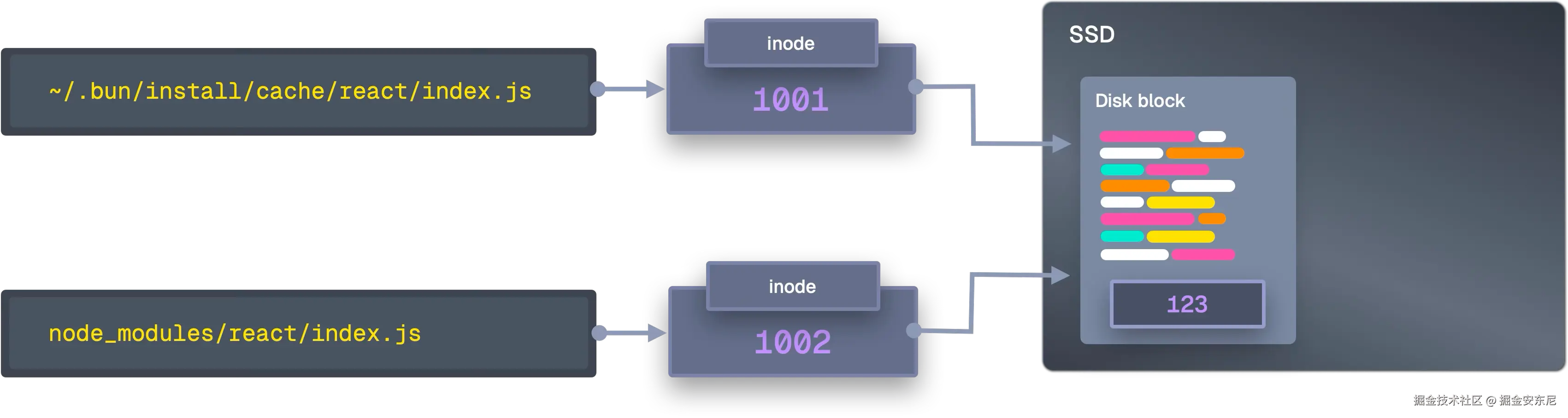
传统复制会遍历目录,一个个文件地复制:
- 打开源文件(
open()) - 创建/打开目标文件(
open()) - 循环
read()/write()直到写完 - 关闭两个文件(
close())
每一个步骤都是系统调用,要模式切换。对一个普通 React 应用的大量文件来说,就是几十万到上百万个系统调用------这正是本文最开始说的"系统编程问题"。
Bun 会根据操作系统/文件系统使用不同策略,尽可能利用本地最强的路径:
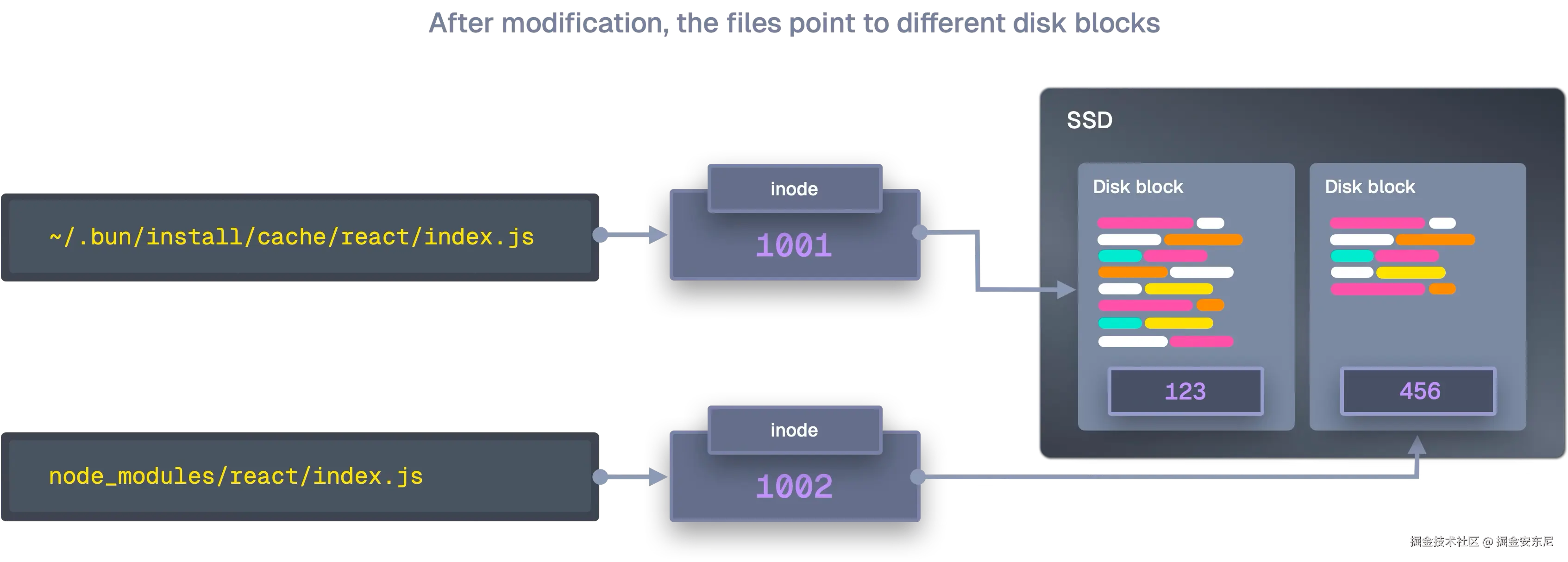
在 macOS 上
Bun 使用苹果的 clonefile()(写时复制 )系统调用。
clonefile 能在一个系统调用 里克隆整个目录树:它不会写入新数据,而是让新文件的元数据指向同一组物理磁盘块。
c
// 传统:数以百万计的系统调用
for (each file) {
copy_file_traditionally(src, dst); // 每个文件 50+ 次系统调用
}
// Bun:一次系统调用
clonefile("/cache/react", "/node_modules/react", 0);写时复制(CoW)意味着只有在修改时才会真正复制数据。安装后 node_modules 基本只读,很少被改动,所以这是接近 O(1) 的操作。
基准:
plain
bun install --backend=copyfile
2.955 s ± 0.101 s
bun install --backend=clonefile
1.274 s ± 0.052 s
=> clonefile 约快 2.32×若文件系统不支持,Bun 退化到逐目录的 clonefile_each_dir;再不行才用传统 copyfile。
在 Linux 上
Linux 没有 clonefile(),但有更古老也更强的硬链接(hardlink)。Bun 的回退链如下(从最优到最差):
- 硬链接 :
link("/cache/react/index.js", "/node_modules/react/index.js")。创建的是"另一个名字",指向同一个 inode(同一份数据)。无需数据搬运,一个系统调用,微秒级完成,且节省磁盘空间。限制是不能跨文件系统、某些 FS/权限不支持等。 ioctl_ficlone:在 Btrfs/XFS 开启写时复制,类似 macOS 的效果,但生成的是独立文件,数据块共享,修改时才分裂。copy_file_range:若没有 CoW,至少让复制留在内核态 。传统复制要先读到内核缓冲区 → 拷到用户态 → 再写回内核缓冲区 → 落盘;而copy_file_range直接在内核里源→目的,少两次拷贝与上下文切换。sendfile:更老、更广泛支持的 API,原为网络设计,但也可用于磁盘到磁盘复制,同样不进用户态。copyfile:最终兜底,传统读写循环,系统调用最多,效率最低,但兼容性最好。
基准:
plain
copyfile : 325.0 ms ± 7.7 ms
hardlink : 109.4 ms ± 5.1 ms
=> hardlink 约快 2.97×这些优化直击主要瓶颈:系统调用开销 。Bun 不用"一刀切",而是因地制宜选择最优的复制后端。
多核并行(Multi-Core Parallelism)
上面所有优化主要是在单核 视角下减少工作量。但现代笔电有 8、16、甚至 24 核!
Node 虽然有线程池,但真正的决策工作(解析依赖图、版本约束求解、决定装谁)仍在一个线程上完成。npm 跑在你的 M3 Max 上时,常见的情况是一个核心忙得要死,其他 15 个闲着。
Bun 走的是**无锁 + "工作窃取"**线程池架构。
工作窃取(work-stealing):空闲线程会去"偷"繁忙线程队列里的任务。线程先看自己本地队列,再看全局队列,最后去其他线程偷,尽量不让任何线程闲着。
传统多线程经常被锁拖慢(上文 npm 大量 futex 就是线程频繁等待)。每次改共享队列都要加锁,其他线程就阻塞:
c
// 传统:有锁
mutex.lock();
queue.push(task);
mutex.unlock();
// 其他线程在等锁Bun 使用无锁数据结构:依赖 CPU 的原子操作保证安全修改共享数据,无需锁:
plain
pub fn push(self: *Queue, batch: Batch) void {
// 原子 CAS,瞬时完成
_ = @cmpxchgStrong(usize, &self.state, state, new_state, .seq_cst, .seq_cst);
}还记得前面那个"每秒处理 146,057 份 package.json vs Node 的 66,576"吗?这就是把所有核心都拉上 的效果。
Bun 的网络也不同:传统包管器常会"边等边下",CPU 在等网络时空转。Bun 维护 64 路并发 HTTP 连接 (BUN_CONFIG_MAX_HTTP_REQUESTS 可调),由独立网络线程 跑事件循环,负责下载;CPU 线程负责解压与处理,互不等待。
此外,Bun 给每个线程 分配独立的内存池,避免所有线程争用同一个分配器造成的内存分配竞争。
结语(Conclusion)
这些被我们拿来做基准的包管器并没有"写错",它们都是在当时的约束下 做出的优秀解法:
npm 奠定了地基;yarn 让 workspace 更顺手;pnpm 用硬链接巧妙地省空间、提速度。它们都认真解决了当时开发者真正在遇到 的问题。
但那个世界已经变了:SSD 快了 70× ,CPU 有几十核,内存很便宜。真正的瓶颈从硬件速度,挪到了软件抽象。
Bun 的方法不是什么"革命",而是直面 2025 年的真实瓶颈 :
当 SSD 每秒能做百万次操作,为什么还要接受线程池的额外成本?
当你读了第一百次的包清单,为什么还要再解析一次 JSON?
当文件系统支持写时复制,为什么还要真的复制上 GB 的数据?
决定下一个十年开发者生产力的工具,现在正在被那些理解"存储变快、内存变廉价后瓶颈如何迁移"的团队重写。他们不是在"微调旧物",而是在重想可能性 。
把安装速度做到 25× 并不是"魔法"------这只是针对当下硬件认真做工程后的自然结果。