1. 大模型的选择详细分析
@
目录
- [1. 大模型的选择详细分析](#1. 大模型的选择详细分析)
- 最后:
介绍
Spring AI 是一个面向人工智能工程的应用框架。解决了 AI 集成的基本挑战:将企业数据和API与AI 模型连接起来。
特性:
提示词工厂
可以说是大模型应用中最简单也是最核心的一个技术。他是我们更大模型交互的媒介,提示词给的好大模型才能按你想要的方式响应。
对话拦截
面向切面的思想对对模型对话和响应进行增强。
对话记忆
plain
@Autowired
ChatMemoryRepository chatMemoryRepository;通过一个bean组件就可以让大模型拥有对话记忆功能,可谓是做到了开箱即用
tools
让大模型可以跟企业业务API进行互联 ,这一块实现起来也是非常的优雅
plain
class DateTimeTools {
@Tool(description = "Get the current date and time in the user's timezone")
String getCurrentDateTime() {
return LocalDateTime.now().atZone(LocaleContextHolder.getTimeZone().toZoneId()).toString();
}
}RAG技术下的 ETL
让大模型可以跟企业业务数据进行互联(包括读取文件、分隔文件、向量化) 向量数据库支持 目前支持20+种向量数据库的集成 这块我到时候也会详细去讲
MCP
让tools外部化,形成公共工具让外部开箱即用。 原来MCP协议的JAVA SDK就是spring ai团队提供的 提供了MCP 客户端、服务端、以及MCP认证授权方案 ,还有目前正在孵化的Spring MCP Agent 开源项目:
模型的评估
可以测试大模型的幻觉反应(在系列课详细讲解)
可观察性
它把AI运行时的大量关键指标暴露出来, 可以提供Spring Boot actuctor进行观测
agent应用
springai 提供了5种agent模式的示例
-
Evaluator Optimizer -- The model analyzes its own responses and refines them through a structured process of self-evaluation.
-
Routing -- This pattern enables intelligent routing of inputs to specialized handlers based on classification of the user request and context.
-
Orchestrator Workers -- This pattern is a flexible approach for handling complex tasks that require dynamic task decomposition and specialized processing
-
Chaining -- The pattern decomposes complex tasks into a sequence of steps, where each LLM call processes the output of the previous one.
-
Parallelization -- The pattern is useful for scenarios requiring parallel execution of LLM calls with automated output aggregation.
学完这5种你会对对模型下的agent应用有一个完整认识
langchain4j vs springAI
| 生态 | 不依赖Spring,需要单独集成Spring | Spring官方,和Spring无缝集成 |
| 诞生 | 更早,中国团队,受 LangChain 启发 | 稍晚,但是明显后来居上 |
| jdk | v0.35.0 前的版本支持jdk8 ,后支持jdk17 | 全版本jdk17 |
| 功能 | 没有mcp server, 官方建议使用quarkus-mcp-server | 早期落后langchain4j, 现在功能全面,并且生态活跃,开源贡献者众多 |
| 易用性 | 尚可,中文文档 | 易用,api优雅 |
| 最终 | 公司不用 Spring AI 就选择它 | 无脑选! |
大模型选型
- 自研(算法 c++ python 深度学习 机器学习 神经网络 视觉处理 952 211研究生 )AI算法岗位
- 云端大模型 比如:云端我们在线使用的 DeepSeek,豆包,通义千问等等, 占用算力 token计费 功能完善成熟
- 开源的大模型(本地部署)Ollama 购买算力 好处:采用开源大模型本地部署,可以将我们的资料信息私有化,因为你要知道,我们向云端大模型的每次提问,都是被其公司记录了的。存在隐私安全性。
- 选型
- 自己构建选型-->评估流程
- 业务确定:( 电商、医疗、教育 )
- 样本准备:数据集样本 选择题
- 任务定制:问答 (利用多个大模型)
- 评估: 人工评估
- 通用能力毕竟好的
- 2月份 deepseek 6710亿 671b = 算力 显存 H20 96G 140万 ; 比 openai gpt4节省了40/1 成本。
- 3月份 阿里 qwq-32b(不带深度思考) 32b=320亿 媲美deepseek-r1 32G 比deepseek-r1节省20/1
- 4月份 阿里 qwen3 (深度思考) 2350亿=235b 赶超了deepseek-r1 比deepseek-r1节省2-3倍 选择(qwen3-30b)
- 5月 deepseek-r1-0528 6710亿 671b 性能都要要
从证明的比较我们可以看出,目前大模型的基本上可以说是有一定的定型了,基本上都是通过提高硬件设置参数,算力,提高大模型的性能。而想要通过算法设计的方式,提高大模型有点困难了。
- 对成本有要求: 选择(qwen3-30b)
- 不差钱 deepseek-r1-0528 满血版本
大模型的选择,需要根据自身的业务以及财力进行综合的选择。
1. 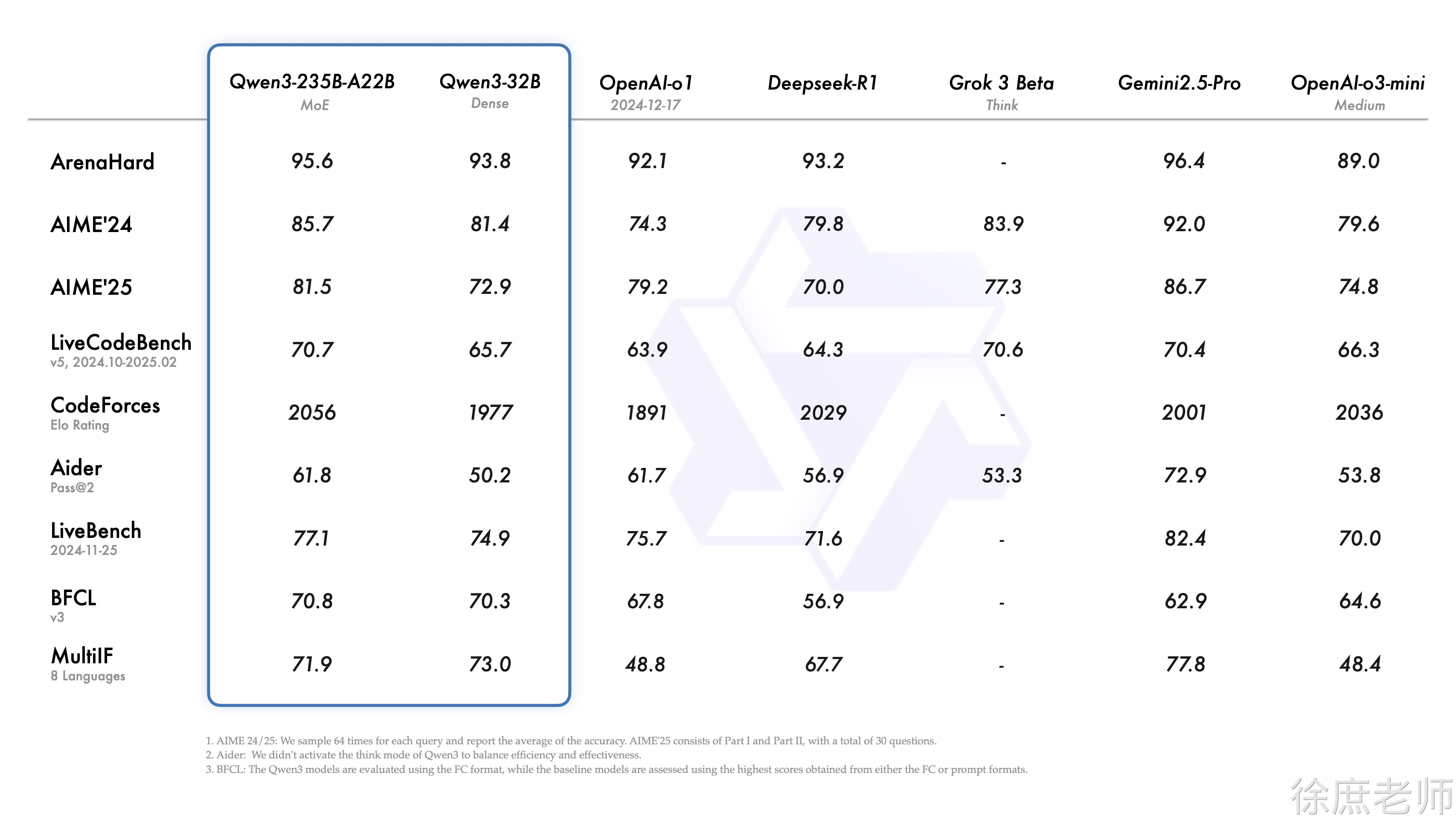https://github.com/jeinlee1991/chinese-llm-benchmark#-排行榜
大模型的诊断平台:https://nonelinear.com/static/eval.html,可以通过它,帮助我们进行以一个初步大模型的选择。
最后:
"在这个最后的篇章中,我要表达我对每一位读者的感激之情。你们的关注和回复是我创作的动力源泉,我从你们身上吸取了无尽的灵感与勇气。我会将你们的鼓励留在心底,继续在其他的领域奋斗。感谢你们,我们总会在某个时刻再次相遇。"