目录
- 引言
- [一、为什么列表类型是 Redis 的 "有序数据利器"?](#一、为什么列表类型是 Redis 的 “有序数据利器”?)
- [二、Redis 列表类型的核心特性:基于双向链表的 "有序与高效"](#二、Redis 列表类型的核心特性:基于双向链表的 “有序与高效”)
-
- [2.1 底层实现:双向链表的 "优与劣"](#2.1 底层实现:双向链表的 “优与劣”)
- [2.2 存储特性:有序、可重复、字符串专属](#2.2 存储特性:有序、可重复、字符串专属)
- [2.3 与其他类型的差异:明确适用边界](#2.3 与其他类型的差异:明确适用边界)
- [三、列表类型核心命令实操:7 大类命令全掌握](#三、列表类型核心命令实操:7 大类命令全掌握)
-
- [3.1 两端增删元素:LPUSH、RPUSH、LPOP、RPOP(核心高频命令)](#3.1 两端增删元素:LPUSH、RPUSH、LPOP、RPOP(核心高频命令))
- [3.2 统计元素个数:LLEN(高效计数)](#3.2 统计元素个数:LLEN(高效计数))
- [3.3 获取列表片段:LRANGE(有序查询)](#3.3 获取列表片段:LRANGE(有序查询))
- [3.4 删除指定值元素:LREM(按值清理)](#3.4 删除指定值元素:LREM(按值清理))
- [3.5 索引操作:LINDEX、LSET(定位与修改)](#3.5 索引操作:LINDEX、LSET(定位与修改))
- [3.6 保留指定片段:LTRIM(截取与瘦身)](#3.6 保留指定片段:LTRIM(截取与瘦身))
- [四、列表类型典型业务场景:适配 "有序 + 高频两端操作" 需求](#四、列表类型典型业务场景:适配 “有序 + 高频两端操作” 需求)
- [五、列表类型避坑指南:新手常犯的 4 个错误](#五、列表类型避坑指南:新手常犯的 4 个错误)
-
- [5.1 坑 1:频繁通过索引操作中间元素,导致性能低下](#5.1 坑 1:频繁通过索引操作中间元素,导致性能低下)
- [5.2 坑 2:误解`LPUSH`的元素插入顺序,导致列表顺序混乱](#5.2 坑 2:误解
LPUSH的元素插入顺序,导致列表顺序混乱) - [5.3 坑 3:用`LREM`删除元素时忽略`count`参数的正负,导致删除方向错误](#5.3 坑 3:用
LREM删除元素时忽略count参数的正负,导致删除方向错误) - [5.4 坑 4:列表元素过大导致内存膨胀与性能下降](#5.4 坑 4:列表元素过大导致内存膨胀与性能下降)
- 六、总结:列表类型的学习与进阶建议
引言
在 Redis 的 6 种核心数据类型中,列表类型(list)是专为 "有序时序数据" 设计的利器。它基于双向链表实现,能高效处理 "从两端增删元素" 的场景,无论是存储新鲜事、评论列表,还是模拟队列、栈,都能轻松胜任。本文从核心特性、命令实操、场景落地到避坑指南,全方位拆解 Redis 列表类型,帮你掌握其在 "有序 + 高频两端操作" 场景中的高效用法。
一、为什么列表类型是 Redis 的 "有序数据利器"?
列表类型(list)是 Redis 中用于存储 "有序字符串列表" 的数据类型,其底层基于双向链表(double linked list)实现 ------ 这种结构赋予了它独特的优势:向列表两端(头部 / 尾部)添加或删除元素时,时间复杂度仅为 O(1),无论列表包含 10 个元素还是 100 万个元素,操作速度几乎无差异。
列表类型的核心价值体现在三个方面:
-
解决关系数据库痛点:传统关系数据库存储时序数据(如日志)时,若需频繁在数据两端操作(如新增日志到末尾、删除过期日志从头部),需频繁调整表结构或全表扫描,性能低下;而 Redis 列表的两端操作效率不受数据量影响,完美适配这类场景。
-
支持多种数据结构模拟:通过组合不同命令,列表可模拟栈(先进后出)、队列(先进先出)等经典数据结构,无需额外开发,降低编码复杂度。
-
有序且灵活:元素按插入顺序排列,支持正向、反向遍历,同时允许存储重复元素(如列表中可包含多个 "redis" 字符串),比集合类型(set)更灵活,比有序集合类型(zset)更轻量。
对于新手而言,理解列表类型的双向链表特性是关键 ------ 它决定了列表的 "优势场景"(两端操作)与 "劣势场景"(中间索引访问),直接影响后续命令选择与业务适配。
二、Redis 列表类型的核心特性:基于双向链表的 "有序与高效"
要用好列表类型,首先需深入理解其底层特性,避免因误解结构导致使用场景偏差。列表类型的核心特性可拆解为三点:
2.1 底层实现:双向链表的 "优与劣"
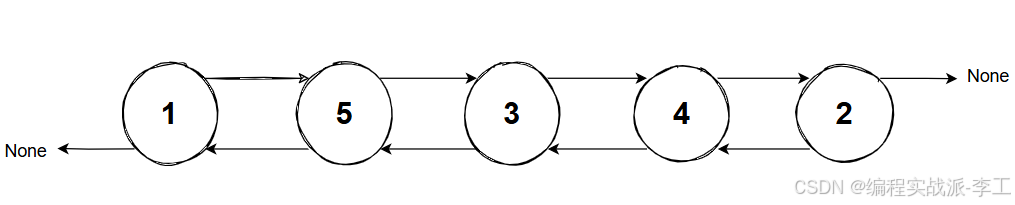
Redis 列表的底层是双向链表,这种结构就像现实中的 "排队队伍":
-
优势(两端操作快) :无论是在队伍头部(最前面)加人,还是在尾部(最后面)加人,都能瞬间完成,无需移动其他元素 ------ 对应列表的
LPUSH(头部添加)、RPUSH(尾部添加)、LPOP(头部删除)、RPOP(尾部删除)命令,时间复杂度均为 O(1)。 -
劣势(中间访问慢) :若想找到队伍中间的第 N 个人(对应列表的
LINDEX命令),必须从队伍头部或尾部逐个计数,数据量越大耗时越长,时间复杂度为 O(n)。比如华为旗舰店为了感谢大家的排队支持,决定奖励排在第521位的顾客一部免费手机,为了找到该顾客,工作人员需要一个一个地数到第521个人。效率远低于找首尾的人。
2.2 存储特性:有序、可重复、字符串专属
-
有序性 :元素严格按插入顺序排列,不会自动排序(与有序集合类型的 "分数排序" 区分)。例如执行
RPUSH list a b c,列表顺序固定为[a,b,c],执行LPUSH list x y,列表顺序变为[y,x,a,b,c]。 -
可重复性 :允许存储重复元素,如
RPUSH list redis redis,列表会包含两个 "redis" 字符串,这与集合类型(set)的 "元素唯一" 形成鲜明对比。 -
字符串专属:列表中的每个元素仅支持字符串类型,不允许嵌套其他数据类型(如列表中不能包含哈希、集合)。若需存储复杂数据,需先将其序列化为字符串(如 JSON 格式)再存入。
2.3 与其他类型的差异:明确适用边界
为避免场景错位,需清晰区分列表类型与集合、有序集合类型的差异,:
| 对比维度 | 列表类型(list) | 集合类型(set) | 有序集合类型(zset) |
|---|---|---|---|
| 有序性 | 插入顺序有序,不自动排序 | 完全无序 | 按分数自动排序,元素有序 |
| 元素唯一性 | 允许重复元素 | 元素唯一,不允许重复 | 元素唯一,分数可重复 |
| 核心操作效率 | 两端增删 O(1),中间访问 O(n) | 增删查 O(1),无有序操作 | 增删查 O(logn),支持分数排序 |
| 适用场景 | 时序数据(日志、新鲜事)、队列 | 去重集合(标签、好友列表) | 带权重排序(排行榜、计分板) |
简单来说:需要 "按时间顺序存储、高频操作两端" 选列表;需要 "去重、无顺序要求" 选集合;需要 "按分数排序、元素唯一" 选有序集合。
三、列表类型核心命令实操:7 大类命令全掌握
列表类型的 7 大类核心命令,涵盖两端操作、计数、查询、删除等全场景需求。下面逐一拆解命令用法与注意事项。
3.1 两端增删元素:LPUSH、RPUSH、LPOP、RPOP(核心高频命令)
这组命令是列表类型最基础的 "写入 - 删除" 工具,直接利用双向链表的两端高效特性,是日常开发中使用频率最高的命令。
(1)命令格式与功能
| 命令 | 功能描述 |
|---|---|
LPUSH key value... |
向列表头部添加 1 个或多个元素,返回添加后列表长度(元素逆序插入) |
RPUSH key value... |
向列表尾部添加 1 个或多个元素,返回添加后列表长度(元素正序插入) |
LPOP key |
从列表头部 弹出 1 个元素(删除并返回),列表为空返回nil |
RPOP key |
从列表尾部 弹出 1 个元素,列表为空返回nil |
(2)实操案例
shell
# 1. 向头部添加元素(LPUSH:逆序插入)
127.0.0.1:6379> LPUSH numbers 3 # 首次添加,列表:[3]
(integer) 1
127.0.0.1:6379> LPUSH numbers 5 1 # 先加5→列表[5,3],再加1→列表[1,5,3]
(integer) 3
# 2. 向尾部添加元素(RPUSH:正序插入)
127.0.0.1:6379> RPUSH numbers 4 2 # 加4→列表[1,5,3,4],加2→列表[1,5,3,4,2]
(integer) 5
# 3. 从头部弹出元素(LPOP)
127.0.0.1:6379> LPOP numbers
"1" # 弹出后列表:[5,3,4,2]
# 4. 从尾部弹出元素(RPOP)
127.0.0.1:6379> RPOP numbers
"2" # 弹出后列表:[5,3,4](3)数据结构模拟
利用这组命令可轻松模拟栈和队列:
-
栈(先进后出) :搭配
LPUSH(入栈)+LPOP(出栈),或RPUSH(入栈)+RPOP(出栈)。例如LPUSH stack a b c→LPOP stack,先弹出c(最后入栈的元素)。 -
队列(先进先出) :搭配
LPUSH(入队)+RPOP(出队),或RPUSH(入队)+LPOP(出队)。例如RPUSH queue a b c→LPOP queue,先弹出a(最先入队的元素)。
3.2 统计元素个数:LLEN(高效计数)
LLEN命令用于统计列表中的元素总数,时间复杂度为 O(1)------Redis 内部维护了元素计数器,无需遍历列表,性能远超关系数据库的COUNT(*)(需遍历表)。
(1)命令格式与返回值
-
格式:
LLEN key -
返回值:列表元素个数,列表不存在返回
0。
(2)实操案例
shell
# 统计存在的列表元素数(当前列表[5,3,4])
127.0.0.1:6379> LLEN numbers
(integer) 3
# 统计不存在的列表
127.0.0.1:6379> LLEN empty:list
(integer) 0(3)使用场景
-
监控列表长度(如日志列表是否超过最大限制);
-
分页计算(如知道列表总长为 100,可分 10 页,每页 10 个元素)。
3.3 获取列表片段:LRANGE(有序查询)
LRANGE命令用于获取列表中指定索引范围的元素,是列表类型最常用的 "读取" 命令,支持正向与反向索引,灵活适配分页、片段查看场景。
(1)命令格式与规则
-
格式:
LRANGE key start stop -
核心规则:
-
索引从
0开始(正向索引),-1表示最后一个元素(反向索引),-2表示倒数第二个,以此类推; -
包含两端元素(如
LRANGE list 0 2返回索引 0、1、2 的元素); -
若
start > stop,返回空列表(如LRANGE list 2 1); -
若
stop超出实际索引范围,返回至列表末尾(如LRANGE list 1 999,返回从索引 1 到末尾的元素)。
-
(2)实操案例
shell
# 列表当前状态:[5,3,4]
127.0.0.1:6379> LRANGE numbers 0 2 # 获取所有元素(0到2索引)
1) "5"
2) "3"
3) "4"
# 负索引查询(获取最后2个元素)
127.0.0.1:6379> LRANGE numbers -2 -1
1) "3"
2) "4"
# 超出索引范围查询(stop=999超出实际范围)
127.0.0.1:6379> LRANGE numbers 1 999
1) "3"
2) "4"(3)与slice()的差异
LRANGE与 JavaScript 等语言的slice(start, stop)不同:LRANGE包含stop索引元素,而slice()不包含。例如LRANGE list 0 2返回 3 个元素(0、1、2),slice(0,2)仅返回 2 个元素(0、1)。
3.4 删除指定值元素:LREM(按值清理)
当需要删除列表中 "值为指定内容" 的元素时,LREM命令是核心工具,它支持按 "数量" 和 "方向" 删除,灵活适配不同清理场景。
(1)命令格式与count规则
-
格式:
LREM key count value -
count参数规则(文档重点强调):-
count > 0:从列表头部 开始,删除前count个值为value的元素; -
count < 0:从列表尾部 开始,删除前count个值为value的元素(如count=-1删除尾部第一个匹配元素); -
count = 0:删除列表中所有值为value的元素。
-
(2)实操案例
shell
# 先向列表添加元素,当前列表:[5,3,4,2,5]
127.0.0.1:6379> RPUSH numbers 2 5
# 从尾部删除1个值为5的元素(count=-1)
127.0.0.1:6379> LREM numbers -1 5
(integer) 1 # 成功删除1个,列表变为[5,3,4,2]
# 删除所有值为3的元素(count=0)
127.0.0.1:6379> LREM numbers 0 3
(integer) 1 # 列表变为[5,4,2](3)注意事项
-
LREM的返回值是 "实际删除的元素个数",而非 "匹配的元素个数"(若部分元素不存在,不计数); -
删除后建议用
LRANGE验证结果,避免因count参数错误导致删除方向或数量偏差。
3.5 索引操作:LINDEX、LSET(定位与修改)
LINDEX和LSET是列表类型中少数涉及 "中间索引" 的命令,分别用于 "获取指定索引元素" 和 "修改指定索引元素",需注意性能风险。
(1)命令格式与功能
| 命令 | 功能描述 |
|---|---|
LINDEX key index |
获取指定索引的元素值,支持负索引,列表为空或索引不存在返回nil |
LSET key index value |
将指定索引的元素值改为value,索引不存在返回错误(如(error) ERR index out of range) |
(2)实操案例
shell
# 列表当前状态:[5,4,2]
127.0.0.1:6379> LINDEX numbers 0 # 获取头部元素(索引0)
"5"
127.0.0.1:6379> LINDEX numbers -1 # 获取尾部元素(索引-1)
"2"
# 修改索引1的元素值为7
127.0.0.1:6379> LSET numbers 1 7
OK
127.0.0.1:6379> LINDEX numbers 1
"7" # 列表变为[5,7,2]
# 修改不存在的索引(索引10)
127.0.0.1:6379> LSET numbers 10 9
(error) ERR index out of range(3)性能提示
LINDEX和LSET的时间复杂度为 O(n),索引越靠近列表中间,执行速度越慢。例如对 10 万元素的列表执行LINDEX list 50000,需遍历 5 万个元素,耗时明显;而执行LINDEX list 0(头部)或LINDEX list -1(尾部),则瞬间完成。因此,应避免频繁操作中间索引元素。
3.6 保留指定片段:LTRIM(截取与瘦身)
LTRIM命令用于 "裁剪" 列表,仅保留指定索引范围的元素,删除其他所有元素,类似 "截取列表的子列表",适合日志裁剪、数据瘦身场景。
(1)命令格式与差异
-
格式:
LTRIM key start stop -
与
LRANGE的差异:LRANGE仅查询片段不修改原列表,LTRIM会直接删除无关元素,永久修改原列表。
(2)实操案例
shell
# 列表当前状态:[5,7,4,2](先通过RPUSH添加4、2)
127.0.0.1:6379> LRANGE numbers 0 -1
# 仅保留索引1到2的元素(即7、4)
127.0.0.1:6379> LTRIM numbers 1 2
OK
# 查看修剪后的列表
127.0.0.1:6379> LRANGE numbers 0 -1
1) "7"
2) "4"(3)适用场景
-
日志裁剪:保留最近 100 条日志,执行
LTRIM log:list 0 99; -
数据瘦身:删除列表中过期或无效的片段,减少内存占用。
四、列表类型典型业务场景:适配 "有序 + 高频两端操作" 需求
列表类型的典型应用场景主要有三类,均围绕 "有序时序数据" 或 "两端操作" 展开。
4.1 存储文章 ID 列表(实现分页与排序)
博客、资讯类平台的核心需求之一是 "按发布时间排序展示文章",并支持分页加载 ------ 列表类型的 "有序性" 和 "片段查询" 特性能完美适配。
(1)实现方案
-
键名设计:
posts:list(存储所有文章 ID 的列表,按发布时间排序); -
发布文章:用
LPUSH posts:list 文章ID(头部插入,最新文章 ID 在列表最前,实现 "最新文章优先显示"); -
删除文章:用
LREM posts:list 0 文章ID(删除所有匹配的文章 ID,避免重复); -
分页显示:用
LRANGE实现分页,如首页显示前 10 篇(LRANGE posts:list 0 9)、第二页显示 11-20 篇(LRANGE posts:list 10 19)。若需 "最旧文章优先",可在客户端将LRANGE结果反转后显示。
(2)实操示例
shell
# 发布3篇文章,ID分别为1001(最早)、1002、1003(最新)
127.0.0.1:6379> LPUSH posts:list 1001 1002 1003
(integer) 3 # 列表:[1003,1002,1001](最新1003在最前)
# 首页显示前2篇(1003、1002)
127.0.0.1:6379> LRANGE posts:list 0 1
1) "1003"
2) "1002"
# 删除过期文章1002
127.0.0.1:6379> LREM posts:list 0 1002
(integer) 1 # 列表变为[1003,1001]4.2 存储文章评论列表(时序化管理)
每篇文章的评论需按发布时间排序,且通常无需修改已有评论,仅需 "新增评论" 和 "加载所有评论"------ 列表类型的 "尾部 / 头部插入" 与 "全量查询" 特性恰好适配。
(1)实现方案
-
键名设计:
post:文章ID:comments(如post:1003:comments存储文章 1003 的评论); -
发布评论:将评论信息(评论者、时间、内容)序列化为字符串(如 "张三 | 2025-09-18 | 很棒的文章!"),用
LPUSH(最新评论在最前)或RPUSH(最新评论在最后)加入列表; -
加载评论:用
LRANGE post:1003:comments 0 -1获取所有评论,客户端反序列化后按顺序显示。
(2)实操示例
shell
# 发布2条评论到文章1003(LPUSH:最新评论在最前)
127.0.0.1:6379> LPUSH post:1003:comments "张三|2025-09-18|很棒的文章!"
(integer) 1
127.0.0.1:6379> LPUSH post:1003:comments "李四|2025-09-19|学习了!"
(integer) 2 # 列表:[李四的评论, 张三的评论]
# 加载所有评论,客户端反序列化后显示
127.0.0.1:6379> LRANGE post:1003:comments 0 -1
1) "李四|2025-09-19|学习了!"
2) "张三|2025-09-18|很棒的文章!"4.3 模拟队列(任务调度场景)
后台任务调度系统(如邮件发送、数据同步)需按 "先进先出"(FIFO)顺序处理任务,避免任务积压或顺序错乱 ------ 列表类型的RPUSH(入队)+LPOP(出队)组合能轻松实现队列功能。
(1)实现方案
-
键名设计:
task:queue(任务队列,存储待处理的任务 ID); -
任务入队:用
RPUSH task:queue 任务ID(尾部插入,符合 "先进先出" 顺序); -
任务出队:用
LPOP task:queue(头部弹出,先入队的任务先处理); -
队列监控:用
LLEN task:queue统计待处理任务数,超过阈值时触发告警。
(2)实操示例
shell
# 3个任务入队(task1→task2→task3,task1最先入队)
127.0.0.1:6379> RPUSH task:queue task1 task2 task3
(integer) 3 # 列表:[task1, task2, task3]
# 任务出队(先处理task1)
127.0.0.1:6379> LPOP task:queue
"task1"
127.0.0.1:6379> LPOP task:queue
"task2" # 剩余待处理任务:[task3]
# 监控队列长度
127.0.0.1:6379> LLEN task:queue
(integer) 1五、列表类型避坑指南:新手常犯的 4 个错误
即使掌握了命令格式,新手仍可能因忽视细节或误解特性导致问题。以下是 4 个高频坑点及解决方案。
5.1 坑 1:频繁通过索引操作中间元素,导致性能低下
现象 :对包含 10 万元素的列表执行LINDEX list 50000,命令执行耗时超过 1 秒,阻塞 Redis 服务,影响其他业务。
原因:中间索引访问需遍历列表,时间复杂度 O(n),元素越多耗时越长,违背列表 "两端快、中间慢" 的设计初衷。
解决方案:
-
避免中间索引操作:若需随机访问数据(如通过 ID 获取详情),改用字符串类型(键名含 ID)或哈希类型,时间复杂度 O(1);
-
优先操作两端:必须使用列表时,仅操作靠近头部或尾部的索引(如前 100 或后 100 个元素),减少遍历次数。
5.2 坑 2:误解LPUSH的元素插入顺序,导致列表顺序混乱
现象 :执行LPUSH list a b c后,预期列表为[a,b,c],实际通过LRANGE查看为[c,b,a],导致数据展示顺序错误。
原因 :LPUSH向列表头部插入元素,多个元素按 "最后输入的先插入头部" 的顺序排列 ------ 先插a→列表[a],再插b→列表[b,a],最后插c→列表[c,b,a]。
解决方案:
-
需正序排列用
RPUSH:执行RPUSH list a b c,元素按输入顺序插入尾部,列表为[a,b,c]; -
明确
LPUSH的逆序特性:将其用于 "最新元素优先" 场景(如新鲜事、日志),避免在需正序的场景中误用。
5.3 坑 3:用LREM删除元素时忽略count参数的正负,导致删除方向错误
现象 :想删除列表尾部第一个值为 "redis" 的元素,执行LREM list 1 redis后,却发现头部第一个 "redis" 被删除,尾部元素未变化。
原因 :count=1表示 "从头部开始删除前 1 个匹配元素",count=-1才表示 "从尾部开始删除前 1 个匹配元素",参数正负决定删除方向。
解决方案:
-
明确删除方向与
count的对应关系:头部删除用count>0,尾部删除用count<0,删除所有用count=0; -
执行后验证:删除完成后用
LRANGE查看列表,确认目标元素已删除,避免因参数错误导致漏删或误删。
5.4 坑 4:列表元素过大导致内存膨胀与性能下降
现象 :将 10MB 的 JSON 字符串(如完整的文章内容)存入列表,导致列表内存占用超过 1GB,LPUSH/RPOP操作速度变慢,网络传输耗时增加。
原因:列表的设计初衷是存储 "小数据时序集合"(如 ID、短字符串),大体积元素会增加内存存储与网络传输成本,违背其轻量化定位。
解决方案:
-
拆分大元素:大体积数据(如文章内容、大 JSON)优先存储在对象存储服务(如 OSS),列表仅存储数据的 URL 或 ID(如
post:1003); -
控制元素大小:单个列表元素大小建议控制在 1KB 以内,避免因元素过大影响列表操作性能。
六、总结:列表类型的学习与进阶建议
列表类型是 Redis 中适配 "有序时序数据" 的核心类型,掌握它不仅能解决高频两端操作的性能问题,还能灵活模拟栈、队列等数据结构。给新手以下学习建议:
-
先吃透核心特性:牢记 "双向链表" 是列表类型的底层基础,明确 "两端增删快、中间访问慢" 的操作规律,避免在不适合的场景中误用(如用列表做随机访问)。
-
熟练高频命令 :重点掌握
LPUSH/RPUSH/LPOP/RPOP(两端操作)、LRANGE(片段查询)、LLEN(计数)这 6 个命令,通过redis-cli反复实操,理解命令间的组合逻辑(如LPUSH+RPOP模拟队列)。 -
明确场景选型:根据业务需求选择数据类型 ------ 时序数据(日志、新鲜事)、两端操作场景(队列、栈)选列表;去重场景选集合;带分数排序场景选有序集合,避免 "一刀切" 用列表存储所有数据。
-
关注进阶方向:后续可深入学习:
-
阻塞式弹出命令:
BLPOP/BRPOP(列表为空时阻塞等待,适合分布式队列); -
列表内存优化:通过
LTRIM控制列表长度,避免无限增长导致内存泄漏; -
持久化配置:结合 RDB/AOF 持久化,确保列表数据在 Redis 重启后不丢失。
-
Redis 列表类型的核心价值在于 "用合适的结构解决合适的问题",从今天开始,尝试用列表类型重构你的时序数据存储逻辑,你会发现它在 "有序 + 高频两端操作" 场景中的高效与灵活。