你是否曾想过,AI 是否能像人类一样,通过"思考"来学习一款全新游戏?传统的人工智能系统,如 AlphaGo 或 OpenAI Five,虽然能在围棋或 Dota 2 中击败人类冠军,但它们的学习过程依赖海量数据和"黑箱"神经网络,既不透明也难以理解。近年来,大型语言模型的崛起为我们提供了新的可能:能否让 AI 通过自然语言进行推理 (reasoning) 和规划 (planning),从而更高效、更可解释地学习?

-
论文:Cogito, Ergo Ludo: An Agent that Learns to Play by Reasoning and Planning
腾讯与武汉大学联合发表的论文《Cogito, Ergo Ludo》(拉丁语意为"我思,故我玩")正是对这一问题的精彩回应。研究者提出了一种名为 CEL 的新型Agent架构,它不依赖预设游戏相关知识,而是从零开始,从完全不知道游戏赢输规则,开始通过与环境的交互和反思,自主构建世界模型,提升对游戏规则和策略的理解,进而掌握游戏。这项研究不仅在技术上实现了"学习如何学习"的突破,也为构建透明、可信的 AI 系统开辟了新路径。
🔍 研究动机:为什么需要"通过推理学习"的智能体?
传统深度强化学习 (Deep RL) 方法虽然在游戏AI中取得巨大成功,但其"蛮力学习"模式存在明显短板:它们需要数百万次交互才能掌握任务,且学到的策略隐藏在神经网络参数中,难以解释。
另一方面,尽管大型语言模型具备强大的推理能力,但现有 LLM 智能体多停留在"零样本" (zero-shot) 或"记忆检索" (memory retrieval) 阶段,缺乏持续学习和自我改进的机制。它们无法像人类一样,从失败中总结经验,逐步完善对世界的认知。
因此,CEL 的提出正是为了填补这一空白:它不仅要让智能体"会玩",还要让它"懂玩"------通过显式推理构建可解释的世界模型,并在每一局游戏后反思进步。
🧩 CEL 方法详解:如何实现"思考式学习"?
整体架构与两阶段循环
CEL 的核心是一个由 LLM 驱动的两阶段循环:回合内决策 与 回合后反思。这一设计灵感来源于人类的学习方式:先行动,再总结。

上图清晰地对比了三种智能体范式:传统 RL 更新策略权重,零样本推理使用静态 LLM,而 CEL 则在 RL 训练的同时,构建并传递一个持续演进的知识库(游戏规则与策略手册)。
语言世界模型:预测与规划的基础
CEL 使用 LLM 作为"语言世界模型" (Language-based World Model),用于预测假如执行某个动作后环境会如何变化。具体来说,给定当前状态
和候选动作
,LLM 会输出预测的下一个状态
和奖励
。这个过程用公式表示为:
-
:LLM 的推理过程(思维链)
-
和
:预测的状态和奖励(以自然语言描述) -
:当前对环境规则的认知
为什么重要? 这使得智能体能进行规划 (Planning),在"脑海中"模拟不同动作的后果,从而做出更明智的决策,类似于人类在下棋前先"推演几步"。
规则归纳:从交互中总结环境规律
每完成一局游戏,CEL 会回顾整个轨迹
,并更新其对环境规则的理解
。轨迹定义为:
规则更新过程表示为:
-
初始时
为空,智能体完全不清楚游戏规则 -
通过分析成功与失败的轨迹,LLM 逐步提炼出准确、完整的规则集
策略总结:提炼可执行的攻略与经验
在规则归纳的同时,CEL 也会更新其攻略手册
,总结哪些行为容易成功、哪些会导致失败。更新公式为:
-
:游戏结果(如胜利/失败)
-
包含从具体攻略(如"约束传播")到高级原则(如"安全探索")的多层次策略
与传统 RL 的对比:传统方法将策略编码在神经网络中,调整缓慢且不透明;而 CEL 的策略以明文纯自然语言形式存在,可即时更新、易于理解。
语言价值函数:评估状态的长期潜力
CEL 还使用 LLM 作为"语言价值函数" (Language-based Value Function),对当前状态的长期价值进行定性评估:
-
不是具体数值,而是如"高战略价值"之类的描述
-
结合游戏规则与攻略手册,使评估更具上下文感知能力
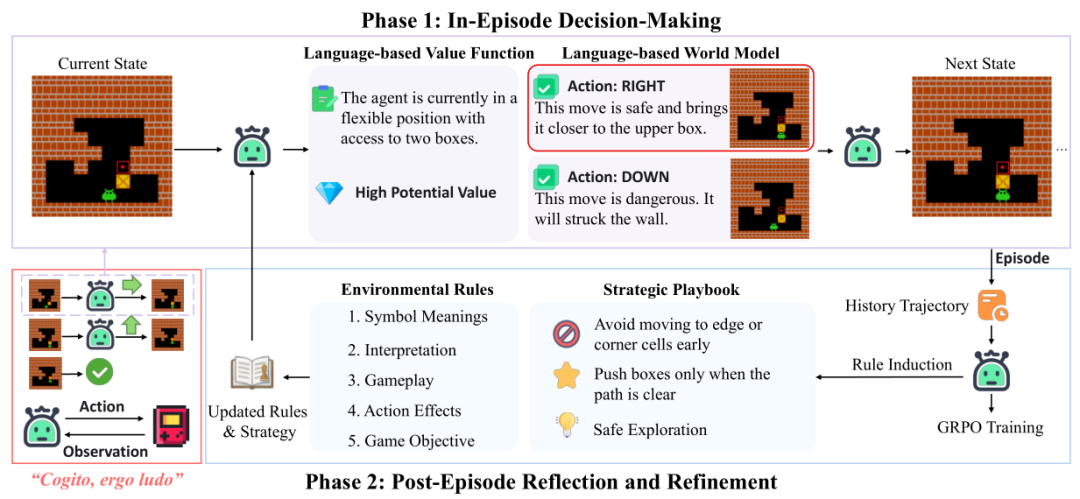
上图展示了 CEL 智能体的完整生命周期:Phase 1 中它基于世界模型和价值函数规划及决策;Phase 2 中它反思并更新规则与攻略手册,形成自我改进的闭环。
🧪 实验验证:CEL 在三个小游戏中表现如何?
实验环境与设置
研究选用了三个经典网格世界 (grid world) 游戏作为实验平台:
-
扫雷 (Minesweeper):逻辑推理类,需根据数字推断地雷位置
-
冰冻湖 (Frozen Lake):导航类,需从起点走到终点并避开陷阱
-
推箱子 (Sokoban):规划类,需推动箱子到目标位置且避免死锁
所有环境均设置为稀疏奖励 :只有成功时才奖励 +1,失败为 0。智能体不被告知任何游戏规则,只能通过与环境交互自行探索。
性能结果:学习曲线与成功率
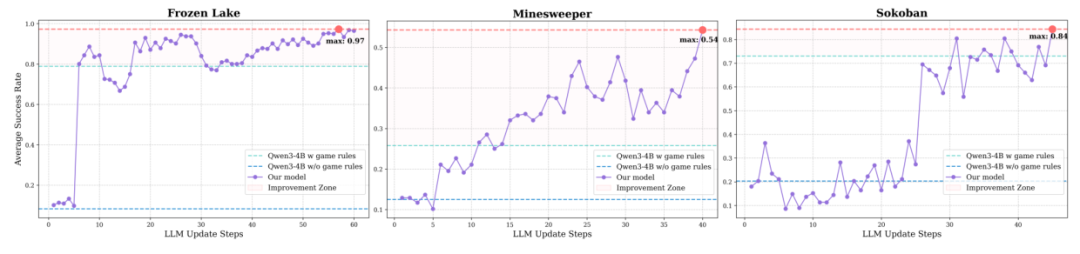
从学习曲线可见,CEL 在三个游戏中均表现出持续进步:
-
扫雷:成功率稳步上升至 54%,显著高于已知规则零样本基线的 26%
-
推箱子:初期探索后实现"突破",成功率跃升至 84%
-
冰冻湖:学习速度极快,10 局内达到 97% 成功率
这表明 CEL 能自主掌握从逻辑推理到规划的多样任务。
消融研究:迭代规则归纳的关键性
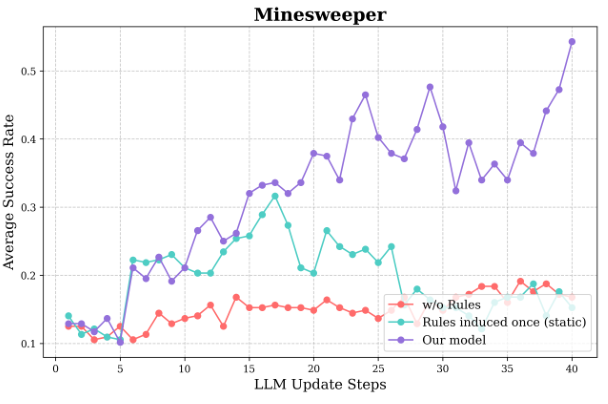
研究者进行了消融实现,移除了规则归纳机制进行对比:
-
无规则:性能停滞在低水平
-
仅一次规则归纳:初期进步后迅速退化
-
完整 CEL:持续改进,显著优于前两者
结论:迭代式规则更新是 CEL 成功的关键,静态或缺失规则都会严重限制学习能力。
案例研究:决策过程、规则与策略的可视化
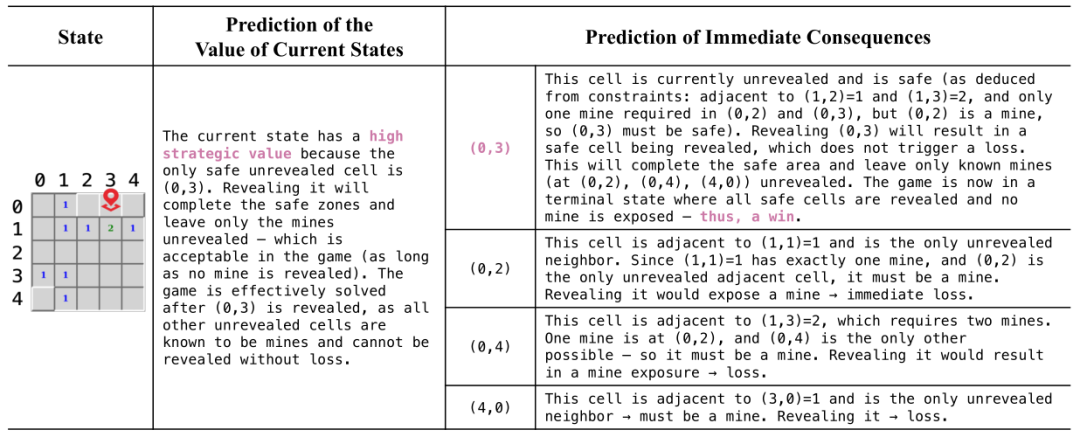
上图展示了智能体在游戏中的实时决策过程:它先评估当前状态价值(Language-based Value),再对每个候选动作进行结果预测 (Language-based World Model),并进行Planning,最终选择最优动作。

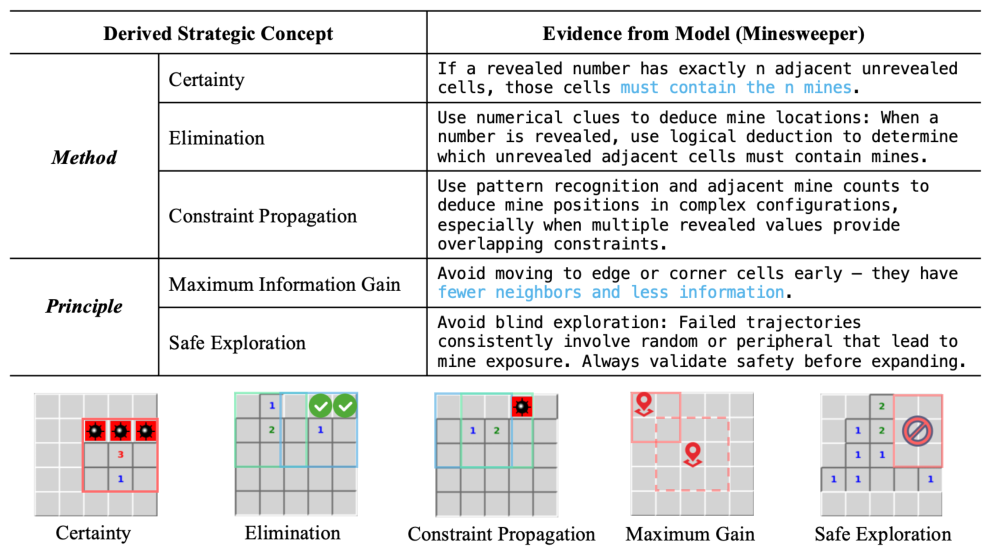
这两个图分别展示了智能体自主学到的扫雷游戏规则手册与攻略手册。游戏规则手册覆盖了符号含义、游戏目标等全部关键信息;攻略手册则提炼出"约束传播"、"安全探索"等专家级启发式方法。
泛化能力:跨游戏与跨布局的测试
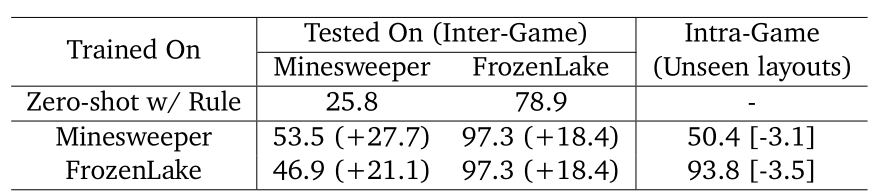
表1总结了 CEL 在两类泛化测试中的表现:
-
游戏内泛化:在未见过的地图布局 (Layout) 上,性能仅轻微下降(如扫雷从 53.5% 降至 50.4%),说明它学的是通用原理而非记忆地图
-
游戏间泛化:将在 A 游戏训练的模型直接用于 B 游戏,仍能有效学习(如扫雷训练后玩冰冻湖成功率 97.3%),表明它迁移的是"推理与规划能力"而非具体知识
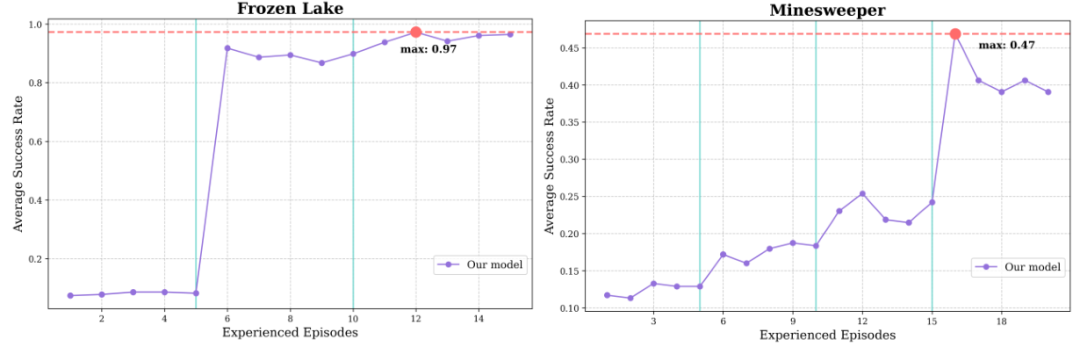
上图进一步展示了跨游戏泛化的学习曲线,把模型权重冻结,在与新游戏交互过程中,仅靠更新规则与策略手册也能持续进步,实现了Learning to learn。
💡 讨论与分析:CEL 的优势与启示
可解释性是 CEL 最突出的优势。所有决策依据、规则理解和策略思考都以自然语言形式呈现,用户可随时知道智能体"在想什么";通过推理与规划实现的策略则大大地增加了智能体的环境泛化性,它不再像传统RL时代一样只会过拟合单一训练过的环境。
与相关工作的对比:
-
相比于 MuZero、Dreamer 等隐式 (Latent) 世界模型,CEL 的世界模型是显式、以自然语言表达的、可读的
-
相比于Zero-shot LLM 智能体,CEL 具备持续学习能力
-
相比于传统 RL,CEL 样本效率更高、策略更透明
局限与未来:
-
当前实验限于网格世界,需扩展至更复杂环境
-
语言模型的推理速度与成本是实际部署的挑战
-
未来可探索与符号推理、神经模型混合的架构
✅ 结论
《Cogito, Ergo Ludo》提出了一种革命性的智能体学习范式:通过推理与规划,从零开始构建可解释的世界模型与策略。CEL 不仅在扫雷、冰冻湖、推箱子等任务中表现出色,还展现出强大的泛化能力与透明决策过程。这项研究标志着 AI 正从"黑箱蛮力"迈向"白箱思考",为构建更通用、可信的人工智能奠定了坚实基础。

