
- [1. ReplicaSet(RS)](#1. ReplicaSet(RS))
- [2. Deployment](#2. Deployment)
- [3. Deployment资源配置](#3. Deployment资源配置)
- 总结
在上一章节中,介绍了pod,以及介绍了如何使用命令行来创建一个pod。那么问题来了,一般来说,我们部署微服务不可能只部署一个噻,肯定是部署多个,但是我们总不可能说,写一个for循环,启动多个pod,并且如果pod挂了,我们又不能说实时观察,肯定是希望pod能够自动创建重启。那么这些如何做到呢?这便是今天我们介绍的Deployment的功能了。
1. ReplicaSet(RS)
在介绍Deployment之前,首先需要介绍一下RS。RS,顾名思义,就是副本集,本质上就是一个资源对象,它定义了pod副本的数量,如何创建新pod,以及通过标签识别pod,目的就是确保集群中始终运行指定数量的pod副本。他的作用很简单:
- Pod 挂了 → 自动重建
- Pod 被删了 → 自动补上
- Pod 数量 ≠ 期望值 → 调整到期望值
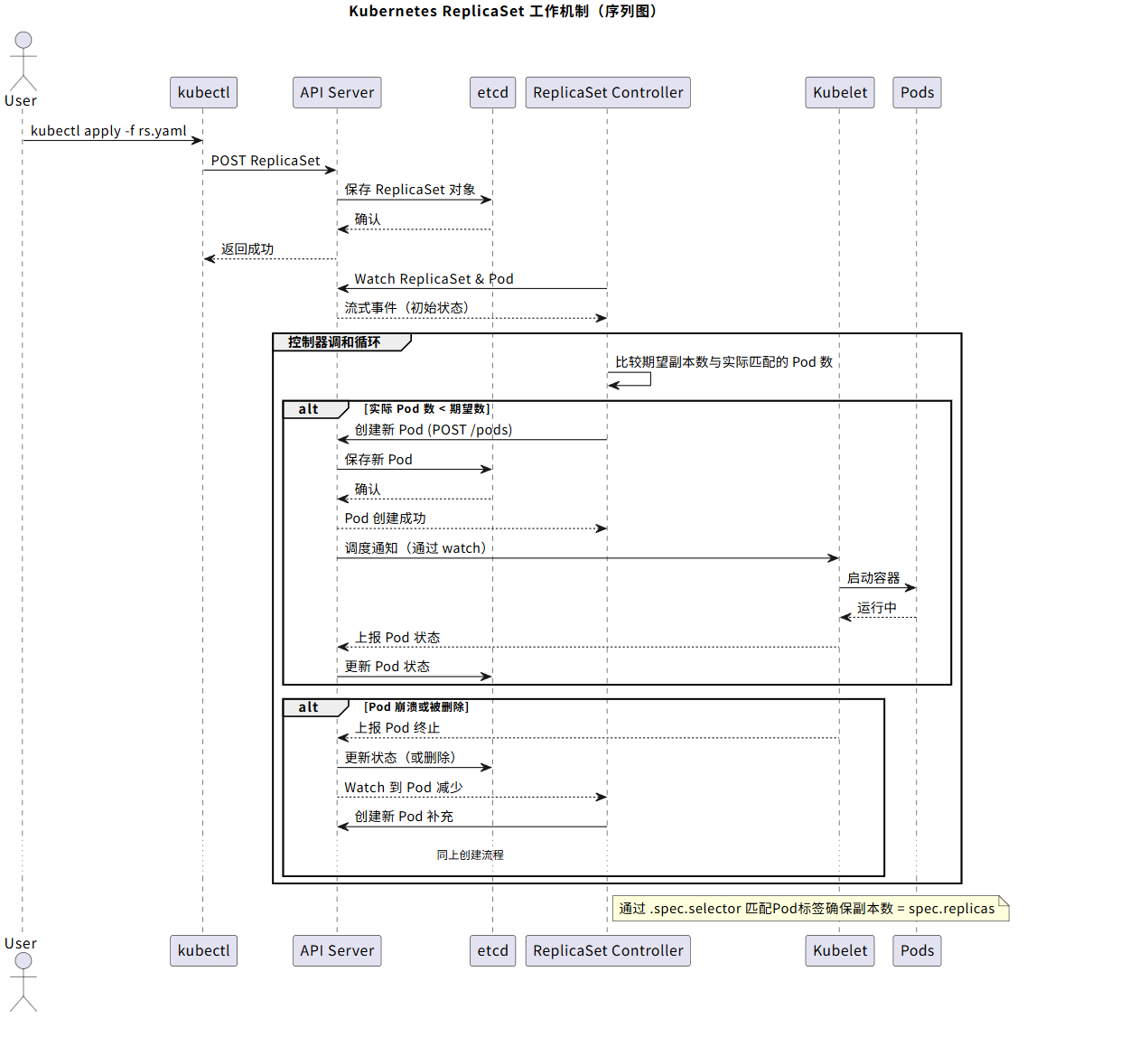
看到上面这些问题,是不是似曾相似,这不就是之前在k8s基础概念 \^1提到的kube-controller-manager吗?YES,sir!是的,kube-controller-manager运行着多个控制器(controller,负责管理对应的资源对象),其中有一个就是Replication Controller,当我们创建一个ReplicaSet的时候,kube-controller-manager就是监听RS这个资源对象,然后检查。
例如,如下yaml定义便是创建一个RS,在yaml定义中,我们会定义rs管理的标签,也就是nginx和prob ,同时我们也会定义pod的创建模板,在模板中我们定义了pod的标签也为nginx和prob。 这样,RS在管理的时候,就是将对应标签的pod纳入到管理中。当他发现少了pod,则会创建,多了,则会删除。
yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-rs
spec:
replicas: 3
selector: # ← 标签,这就是"认亲规则"
matchLabels:
app: nginx
env: prod
template: # 创建pod的规则
metadata:
labels:
app: nginx # ← 必须满足 selector!
env: prod
spec:
containers:
- name: nginx
image: nginx:latest 下面是RS的工作原理图,可以结合前面章节的内容进行参考:
2. Deployment
在上面小节中,详细的介绍了ReplicaSet相关的作用以及工作流程,RS通过定义pod的数量相关资源对象,来确保集群中pod数量。那么有了这个,为什么我们还需要Deployment呢?
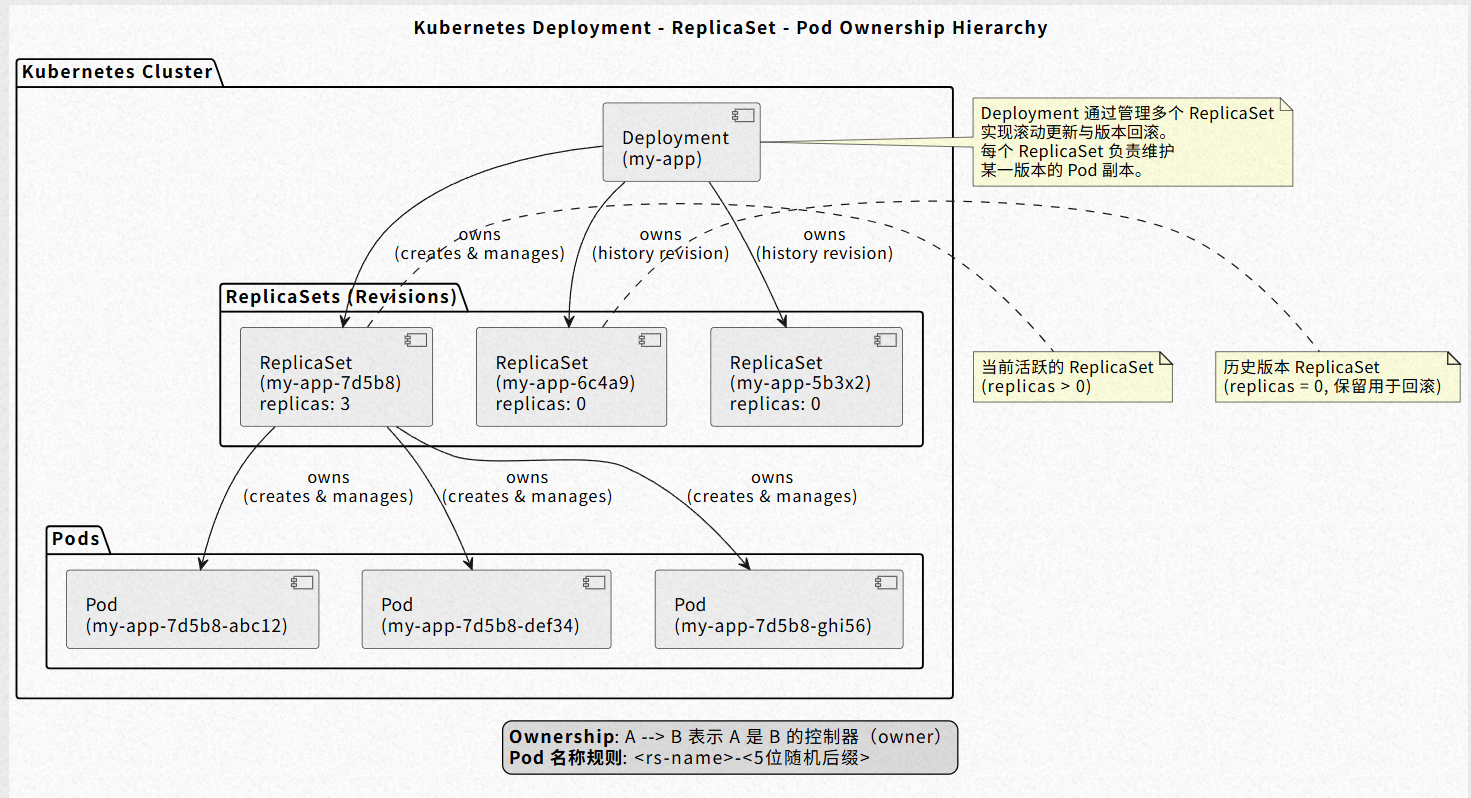
Deployment提供了对pod和ReplicatSet的管理方式,从名字上我们就能看出,Deployment对应了的集群中的一次部署。当我们创建一个Deployment资源对象的时候,Deployment控制器就会自动创建一个RS资源对象。然后RS控制器又会根据RS里面定义的规则,最终创建对应数量的pod。看起来,似乎Deployment的功能和RS类似,但是相比于RS,deployment提供了更多的功能。
让我们想想,RS有什么局限性?在实际的开发生产中,我们的应用需要更新或者在必要时进行回滚。那么就需要进行如下操作:
- 升级应用镜像版本:比如说nginx从1.0→2.0
- 滚动更新(逐步替换旧pod)
- 更新失败自动回滚到上一版本
- 更新速度控制(例如一次只更新一个pod)
- 灰度发布
那么问题来了,RS能提供这些功能吗?答案是不能。如果我们需要更新镜像版本,那么必须要先创建新的RS,等新的pod启动后,再删除老的pod。但是却没法控制更新速度,以及进行自动归滚。当然,你要是说,我手动模拟这个过程,那确实也行,不过这样的,风险就太高了,毕竟手动操作怎么比得上程序自动操作的有序性和精准性。
如下便是一个deployment的定义:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80运行之后,则会生成3个pod:

同时也生成了1个rs:

如果我此时更新deployment对应的镜像,我们可以看到,k8s自动生成了新的rs,并且保留了之前版本的历史记录:

3. Deployment资源配置
在Docker中,我们可以配置容器的计算资源,比如说CPU内存,当然在k8s中,我们也当然可以进行相关的配置。
yaml
apiVersion: apps/v1
kind: Deployment
meta
name: my-app
spec:
replicas: 2
selector:
matchLabels:
app: my-app
template:
meta
labels:
app: my-app
spec:
containers:
- name: app-container
image: nginx:1.25
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m" k8s调度器会根据 requests 值选择有足够资源的节点,表示容器至少需要 这么多资源才能正常运行。limits则表示容器最多可以使用的上线,如果内存超过limit,则会OOMKilled,如果cpu超过limit,则会被节流。CPU的单位有点奇葩,是m,其中1000m=1核。
requests和limit主要有以下用途:
- 平时 :Pod 按
requests保证最低资源(用于调度和资源预留)。 - 高峰期 :如果节点有空闲资源,Pod 可以 临时使用更多资源 (最多到
limits),实现"爆发"。 - 资源紧张时 :Kubernetes 会优先保障
requests,并可能限制或驱逐低 QoS 的 Pod。
学过操作系统的我们知道,在Linux系统中,会实现某些调度器(比如CFS)来将cpu的时间分配给某些进程。因此,在k8s中配置pod的cpu资源大小,本质上就是在配置cpu的调度时间。具体的可以参考linux的cgroup是如何分配CPU资源。
但是在使用中,我们需要注意,尽量让内存的requests和limits大小尽量不要偏差太大。因为cpu从limits大小的资源变成requests,无非就是算的慢一点。但是如果是内存从大变小,便可能会出现OOMKilled问题(因为本来程序占用了4G的内存资源,现在变成了1G,能不OOM吗?)。
4. 总结
在 Kubernetes 中,Pod 是调度和运行的最小单元 ,但由于其缺乏自愈和管理能力,生产环境中绝不应直接部署裸 Pod 。对于无状态应用 (如 Web 服务、微服务),Deployment 是事实上的标准部署单元。它通过管理 ReplicaSet 实现副本保障、滚动更新和版本回滚,是云原生应用发布的基石。