1.暴力破解
暴力破解是一种最直接、最笨拙的攻击方式,见名知意,就是攻击者通过穷举所有可能的密钥、口令或输入组合,直到找到正确答案为止。
这种攻击方式看起来很low,但在现实中却屡见不鲜,因为许多用户仍然习惯使用过于简单的弱口令,比如像什么123456,或者是password或是生日、手机号等。
极易猜测的信息,一旦系统没有设置登录尝试次数限制,攻击者就可以借助自动化工具快速完成大规模的密码测试。
常见的暴力破解目标:
密码 ,像登录口令、Wi-Fi密码、数据库口令之类的。加密密钥 ,如对称加密中的密钥。验证码/Token,如短信验证码、验证码图片等。
暴力破解的分类
1. 纯暴力破解 从所有可能的字符组合开始尝试,例如: 尝试 "a"、"b"、"c" ... 然后 "aa"、"ab"、"ac" ...
2. 字典攻击,这个也比较常用 使用常见密码字典,比如 123456、password、qwerty 等进行尝试。 比纯暴力破解快,因为大部分用户喜欢用弱口令。
3. 混合攻击 字典 + 规则,例如: 在字典词后加数字password123 首字母大写Qwerty
2.随机森林
森林中的每个树就是决策树。
使用决策树的组合,可以提升其性能和准确率。随机森林是一种基于决策树的集成学习方法,它通过构建多个决策树模型,然后使用投票的方式进行预测,来减少过拟合的风险。
在实现随机森林时,需要对决策树的构建、特征选择、模型训练和预测等方面进行优化。
森林中的每一棵树都有很多叶子,在计算机中可以理解为很多节点,比如什么二叉树。
在决策树的每个节点,算法需要选择一个特征来进行分割,目的是最大化节点的纯度,即减少子节点中类别的不确定性。
举个例子来说:
首先要下载matplotlib,Scikit-learn和pandas
bash
import pandas as pd
# 创建一个包含年龄和类别标签的Data
data = {
'Age': [25, 30, 35, 40, 45, 50, 55, 60, 65, 70],
'Category': ['A', 'A', 'B', 'B', 'B', 'C', 'C', 'A', 'B', 'C']
}
df = pd.DataFrame(data)
# 显示原始数据
df这是一一对应的,比如说25对应A, 35对应B
现在我们去自定义一个分类:
bash
# 根据年龄是否大于30来分割数据 gini = 0.2
df['Age_GreaterThan_30'] = df['Age'] > 30
# 根据年龄是否大于20来分割数据 gini = 0.1
# 显示分割后的数据
df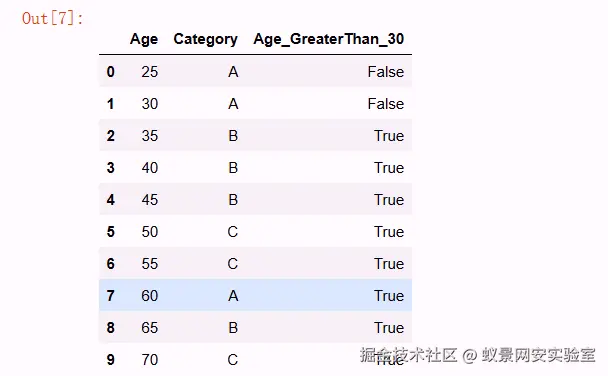
这样数据就可以分成小于30就是false,大于30就是true,这样就是把叶子做了一个特征分类。
所以当有这么一棵树的时候,有数据进来,就可以以此判断它的类别是什么。
那么随机森林就是很多棵决策树,但是每棵树略有不同,比如说取的数据不同。
比如说100个数据,使用10棵树,10棵树产生的分类也有所不同,这样就可以避免产生过拟合。
3.使用随机森林识别暴力破解
注意:这里的代码有些没有完全展示,因为太长了,只截取重要部分。
这里使用的数据是一些检测函数调用和攻击最后的结果之间的对应关系,用这些数据做特征。
ini
...
x1,y1 = load_adfa_training_files("./data/ADFA-LD/Training_Data_Master/")
x2,y2 = load_adfa_hydra_ftp_files("./data/ADFA-LD/Attack_Data_Master/")先去加载数据,把数据分成两份,训练数据和攻击数据。
这里选择的就是hydra_ftp,暴力破解数据。
hydra是渗透过程中常用工具,这里就不展开解释了 hydra
然后对训练数据和攻击数据都打上标签,也就是x1,y1 x2,y2
把x1,x2加起来进行一个拼接,y1和y2也是一样。
然后需要拿去做一个向量化,因为读取的数据都是字符串。
ini
x1,y1 = load_data.x1,load_data.y1
x2,y2 = load_data.x2,load_data.y2
x = x1+x2
y = y1+y2
vectorizer = CountVectorizer(min_df=1)
x = vectorizer.fit_transform(x)
x = x.toarray()
print(type(x))
print(y)
# [1,2,3]
np.savetxt("../model/data_x.csv", x, delimiter=",")
np.savetxt("../model/data_y.csv", y, delimiter=",")用CountVectorizer将读取的数据转换为numpy格式,转换完成就可以使用np.savetxt方式把x和y的数据导入到csv文件。
数据处理完之后,接下来就是模型,直接简短代码就行。
ini
rf = RandomForestClassifier(n_estimators=model_param.rf_params["n_estimators"],
max_depth=model_param.rf_params["max_depth"],
min_samples_split=model_param.rf_params["min_samples_split"],
random_state=model_param.rf_params["random_state"])使用随机森林模型
n_estimators: 这个参数指定了要构建的决策树的数量。
max_depth: 这个参数定义了树的最大深度,太小了容易欠拟合,不限制又容易过拟合。
min_samples_split: 这个参数指定了在树的节点上进行分裂所需的最小样本数,最少都需要两个,增加这个值可
以使树更加保守,减少过拟合的风险,但可能降低模型的复杂度和准确性。
这样模型就构建好了,接下来就是训练了。
ini
x = np.genfromtxt("data_x.csv",delimiter=",")
y = np.genfromtxt("data_y.csv",delimiter=",")
x_train, x_test , y_train, y_test = train_test_split(x, y, test_size = 0.3)
save_model = model_struct.rf.fit(x_train, y_train)
# 模型的保存
with open('rf.pickle','wb') as f:
pickle.dump(save_model,f) #将训练好的模型clf存储在变量f中,且保存到本地把刚才导出来x,y导入,将其分成测试集和训练集,将模型保存下来,用于接下的测试。
首先是得分测试:
scss
with open('../rf.pickle', 'rb') as f:
clf_load = pickle.load(f) # 将模型存储在变量clf_load中
x = np.genfromtxt("../data_x.csv",delimiter=",")
y = np.genfromtxt("../data_y.csv",delimiter=",")
# 交叉验证
scores = cross_val_score(clf_load, x, y, cv=10, scoring='accuracy')
# 11111
# 00001
print(scores.mean())
plt.bar(np.arange(10),scores,facecolor='yellow',edgecolor='white') # +表示向上显示
for x,y in zip(np.arange(10),scores):
plt.text(x,y+0.05, '%.2f' % y,ha='center',va= 'bottom') # '%.2f' % y 保留y的两位小数 ha='center' 居中对齐 va= 'bottom' 表示向下对齐 top向上对齐
plt.ylim(0,1.1)
plt.show()用十字交叉验证去做一个验证,去跑一下模型:
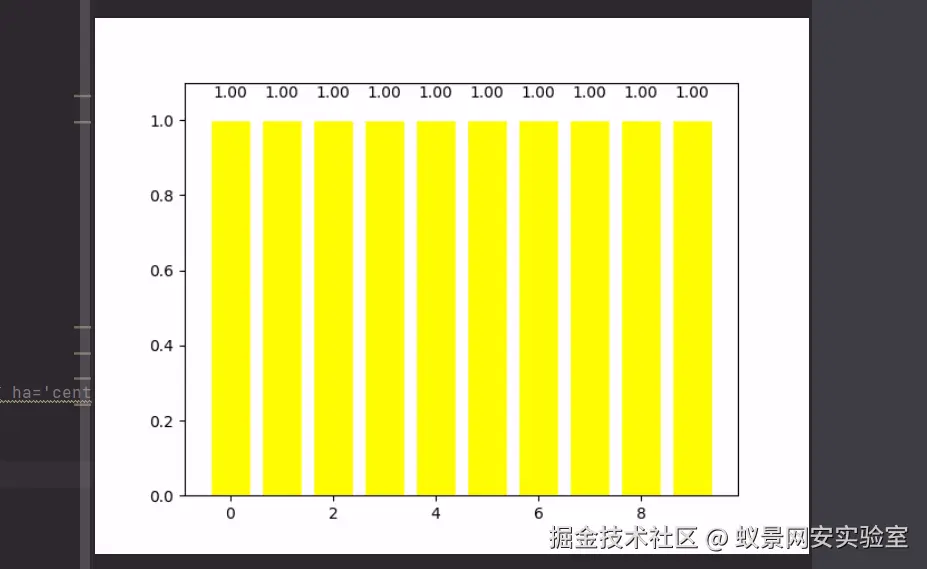
10次跑分的成绩
然后是使用的测试:
ini
sys.path.append(config.syspath)
import config
import pickle
import numpy as np
def load_data(filename):
with open(filename, 'r') as f:
first_line = f.readline().strip('\n')
features = [float(feature) for feature in first_line.split()]
return np.array(features) # 确保返回的是一维数组
if __name__ == '__main__':
# 加载数据
data = load_data(config.syspath + "/model/model_test/UAD-Hydra-FTP-1-1613.txt")
# 获取实际特征数量
actual_features = data.shape[0]
# 模型期望的特征数量
expected_features = 142
# 根据特征数量决定如何处理
if actual_features < expected_features:
# 填充缺失的特征
padding = np.zeros(expected_features - actual_features)
data_padded = np.hstack([data, padding]).reshape(1, expected_features)
elif actual_features > expected_features:
# 截断多余的特征
data_padded = data[:expected_features].reshape(1, expected_features)
else:
# 特征数量匹配,无需修改
data_padded = data.reshape(1, expected_features)
# 加载模型
with open('../rf.pickle', 'rb') as f:
clf_load = pickle.load(f)
# 使用模型进行预测
prediction = clf_load.predict(data_padded)
print("预测结果:", prediction)注意,这里模型是一个支持固定长度的特征输入,但是实战中经常会遇到各种不同长度特征的输入。
可以根据特征数量去进行一个处理,比如说这个特征是一个连续的特征,这里用到的数据都是函数的调用序列。
不管它们在什么位置,它们所代表的实际含义都是一样的,都是这个函数在哪个位置被调用了。
erlang
6 63 6 5 221 141 141 6 5 221 6 ....比如说上述一部分数据,第一次调用了6号函数,第二次调用了63号函数,以此类推。
也就是特征和特征之间都是统一的内容,也就是连续的而不是离散的,那么就可以使用上述代码进行一个处理。
接下来去跑测试模式就可以了。
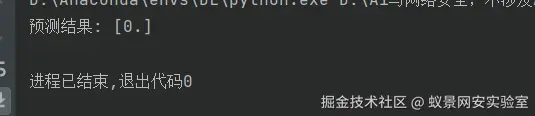
如果预测结果不太准确,那么就需要在模型参数那里进行一个调整,当然每一次调整参数都需要把原先的模式删除。
python
rf_params = {
'n_estimators':10,
'max_depth':None,
'min_samples_split':2,
'random_state':0
}总之,使用随机森林去识别暴力破解,就是导入一些安全产品记录了一些时间段某些函数的调用的数据。
把数据进行一个预处理,就是把函数名称做一个排序,然后对应到序号上,生成上述的那一部分数字。
接下来就可以重复刚刚的步骤,转换,构建,训练,测试。
这个数据是函数调用序列,可能比较抽象,或者用网络数据包数据或许会更好,但是模型构建的方法是一样的。