第一步:DNS 解析 ------ 把名字变成地址
当你在浏览器地址栏输入 https://example.com 并按下回车,计算机需要先将其转换成它能理解的 IP 地址(如 93.184.216.34)。因此,第一步是 DNS(Domain Name System)解析。
浏览器不会立刻联网,而是先查缓存:
-
浏览器 DNS 缓存
Chrome、Firefox 等现代浏览器会缓存近期解析过的域名(可通过
chrome://net-internals/#dns查看)。 -
系统 hosts 文件
操作系统会检查本地
hosts文件(如 Windows 的C:\Windows\System32\drivers\etc\hosts),这是手动映射域名到 IP 的方式。 -
操作系统 DNS 缓存
若前两步未命中,系统会查询自己的 DNS 缓存(Windows 用
ipconfig /displaydns,macOS 用sudo dscacheutil -cachedump)。 -
向 DNS 服务器发起查询
若仍无结果,操作系统会向配置的 DNS 服务器(如 8.8.8.8 或 ISP 提供的 DNS)发起请求。
上面提到的 8.8.8.8 是公共 DNS 服务器。如果你连接的是公司的网络,公司也有配置的内部 DNS 服务器地址,这样你就可以访问到公司内部的网站。
📌 ISP 是什么? ISP = Internet Service Provider中文叫:互联网服务提供商 简单说,ISP 就是给你家、你公司、你手机提供"上网服务"的公司。
💡 注意:DNS 缓存只保存"域名 → IP"的映射,不缓存网页内容。
DNS 查询如何工作?
- 你(浏览器)发起的是"递归查询" :只需问一次本地 DNS 服务器,就期待拿到最终答案。
- 本地 DNS 服务器内部用"迭代查询" :它依次问根服务器 → 顶级域(.com)服务器 → 权威 DNS 服务器,每一步只告诉你"下一个该问谁"。
在 DNS 查询流程中提到的 "本地 DNS 服务器"(Local DNS Server) ,是一个网络术语。
🧩 类比理解
想象你要查一个陌生公司的电话:
- 你 = 浏览器/你的电脑
- 114 查号台 = "本地 DNS 服务器"(比如 8.8.8.8)
- 工商注册系统、行业目录等 = 根服务器、.com 服务器、权威 DNS
你只打一次 114(递归查询),说:"请帮我查 example.com 的电话"。
114 自己去翻各种资料(迭代查询),最后告诉你结果。
你不需要知道 114 背后怎么查的。
整个过程通常在几十毫秒内完成,但在弱网或跨洋场景下可能显著延迟。
第二步:安全检查 ------ 防止你误入陷阱
在导航流程早期(甚至在 DNS 解析开始前 ),现代浏览器(如 Chrome)就会启动 Safe Browsing 安全检查:
- 浏览器将用户输入的域名或完整 URL 的加密哈希值,与本地缓存的恶意站点黑名单进行比对。
- 若本地无法确认,会通过隐私保护机制(如私有集合交集)向 Google 等服务发起查询。
- 该检查完全基于域名或 URL 路径,不依赖 IP 地址。这意味着即使恶意网站托管在合法 IP 上,只要其域名可疑,仍会被拦截。
为提升性能,此步骤通常与 DNS 解析并行执行,而非串行等待。
Google 提供了一个专门用于触发 Safe Browsing 警告的测试网址:
这个页面由 Google 维护,包含多个模拟的恶意链接,例如:
- 模拟恶意软件站点
- 模拟钓鱼网站
- 模拟不安全的下载
操作步骤:
-
打开 Chrome(或其他支持 Safe Browsing 的浏览器)
-
点击任意一个"Malware "或"Phishing"链接
-
正常情况下,浏览器会拦截页面并显示红色警告,例如:
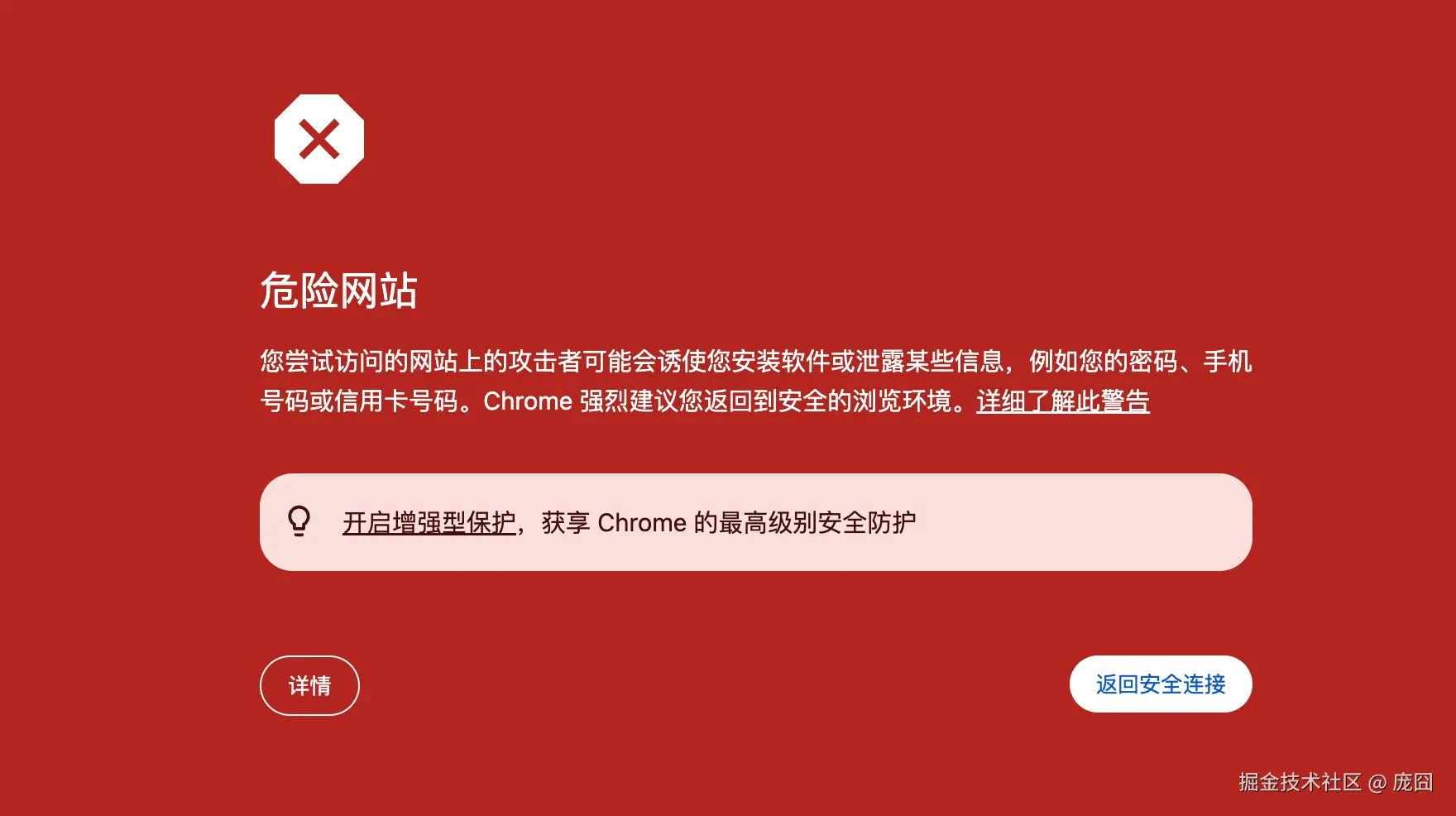 ✅ 如果看到警告,说明 Safe Browsing 已启用并正常工作。
✅ 如果看到警告,说明 Safe Browsing 已启用并正常工作。
⚠️ 注意:请勿绕过警告!这些是测试页面,但行为模拟真实攻击。
第三步:建立 TCP 连接 ------ "三次握手"
浏览器会通过操作系统,向目标服务器的 IP 地址发起 TCP 连接请求。因为 HTTP/HTTPS 依赖 TCP 作为底层传输协议,必须先建立可靠的连接通道。
🔄 TCP 三次握手过程:
- 客户端 → 服务器 :发送
SYN(同步序列号),表示"我想连接你"。 - 服务器 → 客户端 :回复
SYN-ACK(同步+确认),表示"我收到了,我也准备好了"。 - 客户端 → 服务器 :发送
ACK(确认),表示"好的,我们开始通信吧"。
至此,TCP 连接建立成功,双方可以可靠地收发数据。
💡 注意:如果是访问
https://example.com,这一步连接的是 目标服务器的 443 端口(HTTPS 默认端口)。
第四步:TLS 握手(仅 HTTPS)------ 加密你的通信
因为访问的是 https://,还需进行 TLS(Transport Layer Security)握手 ,确保通信不被窃听、篡改或冒充。
以现代常用的 TLS 1.3 为例,简化流程如下:
- Client Hello:浏览器发送支持的加密协议、密钥交换算法等。
- Server Hello + 证书:服务器选定协议,返回数字证书(含公钥)。
- 证书验证:浏览器检查证书是否由可信机构(CA)签发、域名是否匹配、是否过期。
- 密钥协商 :双方通过 ECDHE 等算法,各自计算出相同的会话密钥(密钥从未在网络上传输!)。
- 加密通信开始:后续所有 HTTP 数据均用该密钥加密。
TLS 1.3 将握手压缩到 1 个往返(1-RTT) ,甚至支持 0-RTT(对已访问过的站点),极大提升速度。
🔐 TLS 握手只发生在 HTTPS 连接中:
- HTTP(如
http://example.com)
→ 使用 明文传输 ,直接在 TCP 连接建立后发送 HTTP 请求,没有 TLS 握手 。
→ 数据(包括 Cookie、密码、URL 参数等)在网络中可被窃听或篡改。 - HTTPS(如
https://example.com)
→ 在 TCP 连接建立后,必须先完成 TLS 握手,协商加密密钥、验证服务器身份,之后才发送加密的 HTTP 请求。
第五步:发送 HTTP 请求 ------ 要 HTML!
浏览器通过已建立的 TLS 连接,发送一个 HTTP/1.1 或 HTTP/2 请求(具体取决于服务器支持),例如:
html
GET / HTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0 ...
Accept: text/html
Connection: keep-alive🔐 这个请求在发送前会被 TLS 层加密,网络上的中间人只能看到加密数据,无法得知你请求的是
/还是/passwords.txt。
服务器返回加密的 HTTP 响应
服务器收到请求后,生成 HTML 内容,并通过 TLS 通道返回:
http
HTTP/1.1 200 OK
Content-Type: text/html; charset=UTF-8
Content-Length: 1256
...
<!DOCTYPE html>
<html>
<head><title>Example Domain</title></head>
<body>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples...</p>
</body>
</html>🔐 整个响应体(包括 HTML 内容)同样被加密传输。
HTTP/1.1和 HTTP/2 的区别
✅ 1. HTTP/1.1:复用同一个 TCP + TLS 连接(通过 Keep-Alive)
- 在 HTTP/1.1 中,默认启用
Connection: keep-alive。 - 浏览器在获取 HTML 后,会复用已有的 TCP + TLS 连接去请求 CSS、JS、图片等资源。
- 只要服务器支持,同一个连接可以连续发送多个请求(串行或有限并发)。
⚠️ 但 HTTP/1.1 有"队头阻塞"问题:多个资源需排队传输,效率不高。
✅ 2. HTTP/2:强烈推荐复用连接(且必须基于 TLS)
- HTTP/2 强制要求 TLS(浏览器只在 HTTPS 下启用 HTTP/2)。
- 它支持 多路复用(Multiplexing) :
→ 在同一个 TLS 连接上,并行传输 HTML、CSS、JS、图片等所有资源。 - 完全避免了重复握手开销,极大提升加载速度。
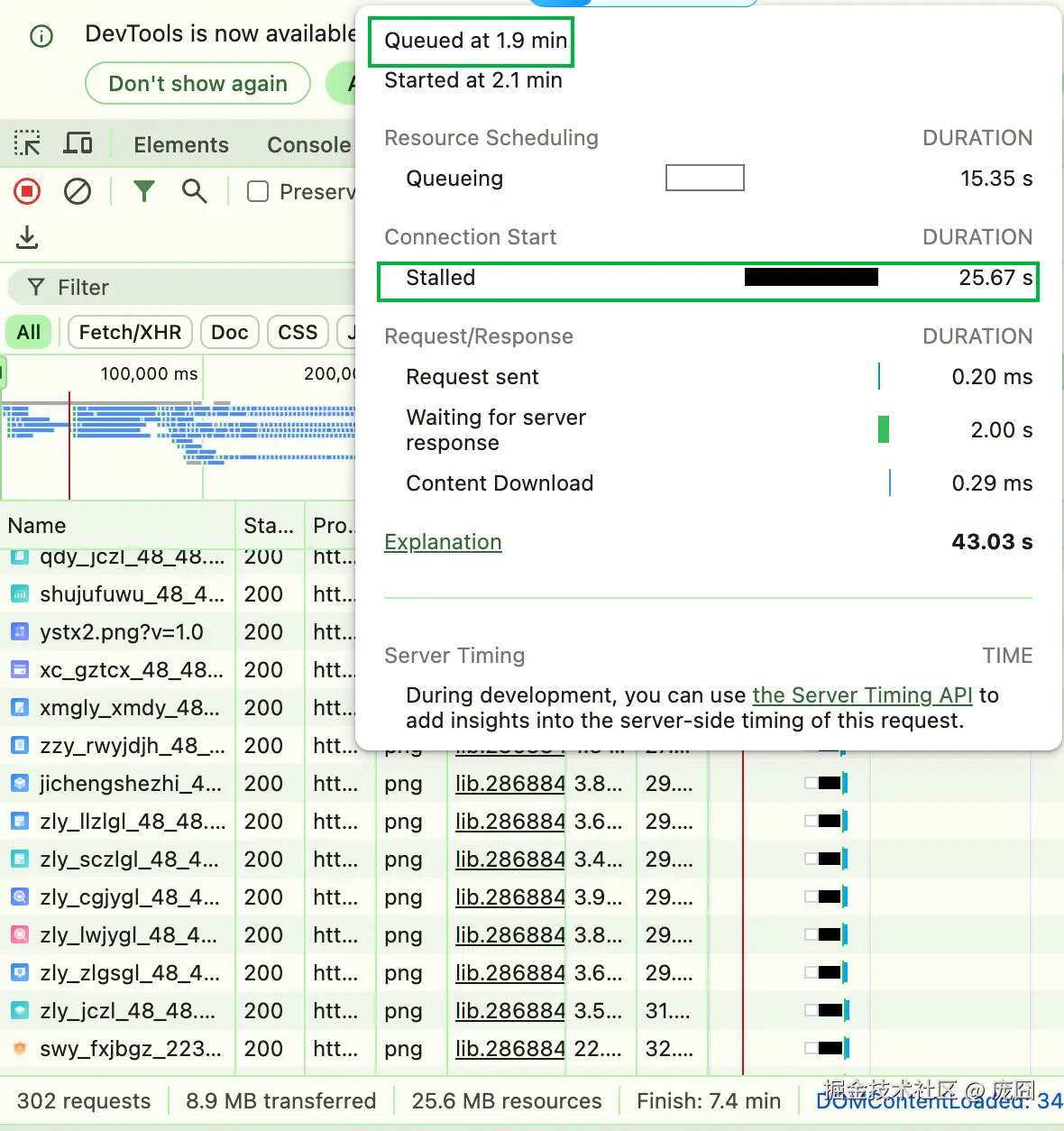
举个例子:
-
在 Chrome DevTools → Network
-
启用 Throttling (模拟 3G):
→ 点击 "No throttling" → 选 "Slow 3G"
-
分别访问:
- 一个 HTTP/2 站点
- 一个 HTTP/1.1 站点
-
观察 Waterfall(瀑布图) :
- HTTP/1.1:资源呈"阶梯状",大量排队(Stalled/Queueing)
- HTTP/2:资源密集并行,Stalled 时间短
例如我访问的这个使用 HTTP/1 的大型网站,可以看到有很多排队和 Stalled 的时间:
第六步:解析与渲染 ------ 把代码变成画面
这一步内容比较多,我单独写在一个文章里了,传送门如何解析 HTML:
补充 1:四次挥手
什么是"四次挥手"?
TCP 是面向连接的协议,断开连接时需双方确认,过程称为 四次挥手(Four-Way Handshake) :
- 客户端 → 服务器 :
FIN(我想关闭连接) - 服务器 → 客户端 :
ACK(收到你的关闭请求) - 服务器 → 客户端 :
FIN(我也准备好了,可以关闭) - 客户端 → 服务器 :
ACK(确认,连接关闭)
📌 注意:如果一方还有数据要发,可以延迟发送自己的
FIN,所以有时看起来像"三次"(合并 ACK+FIN),但逻辑上仍是四步。
关掉浏览器页面会触发四次挥手吗?
不一定立刻触发,原因如下:
情况一:页面关闭 ≠ 立即关闭 TCP 连接
- 浏览器可能复用连接 给其他标签页(比如你同时开着
github.com和example.com,它们共用连接池)。 - 即使关闭标签页,浏览器也可能保持连接一段时间 (称为 连接保活 / keep-alive timeout),以便后续请求复用,减少握手开销。
情况二:浏览器主动关闭连接
-
如果该连接没有被其他页面使用 ,且浏览器决定不再复用,它会主动发起
FIN,启动四次挥手。 -
这通常发生在:
- 页面完全关闭
- 一段时间无活动(如 30--120 秒)
- 浏览器内存压力大,主动清理连接
情况三:服务器先关闭
- 服务器也有超时机制(如 Nginx 默认
keepalive_timeout 75s)。 - 如果客户端长时间不发请求,服务器会先发
FIN,浏览器回应,完成挥手。
补充 2:强缓存与协商缓存
浏览器缓存主要分为两类:强缓存(也称强制缓存) 和 协商缓存(也称对比缓存) 。它们通常协同工作,共同决定资源是否需要重新从服务器获取。
强缓存(Strong Cache)
强缓存由服务端通过响应头中的 Cache-Control 字段控制。一旦命中强缓存,浏览器会直接从本地缓存读取资源,不会向服务器发起任何请求。
💡 历史补充 :
早期 HTTP/1.0 使用
Expires字段(如Expires: Wed, 21 Oct 2025 07:28:00 GMT)控制缓存过期时间。HTTP/1.1 引入了更灵活的
Cache-Control,优先级高于Expires。若两者同时存在,浏览器以Cache-Control为准。
常见的 Cache-Control 指令
max-age=<seconds> |
资源在客户端可被缓存的最大时间(单位:秒)。例如max-age=31536000表示缓存一年。 |
no-cache |
并非禁止缓存!而是要求每次使用缓存前必须向服务器验证资源是否更新(即走协商缓存流程)。 |
no-store |
禁止任何形式的缓存,客户端和中间代理(如 CDN)都不能存储该响应。适用于敏感数据。 |
如何判断是否命中强缓存?
在浏览器开发者工具的 Network 面板中:
- 若请求的 Size 列显示
(memory cache)或(disk cache),且 没有发起网络请求(Status 为 200 但无 Timing 数据),说明命中了强缓存。 - 此时请求不会出现在 Network 列表中(除非勾选"Disable cache")。
💡 小知识 :
浏览器会根据资源大小、访问频率等因素,决定将缓存存入内存 (速度快,关闭即失)还是磁盘(持久,速度稍慢)。
协商缓存(Revalidation Cache)
当强缓存失效(或被跳过)时,浏览器会发起请求,但会携带缓存验证头,询问服务器:"我本地有这个资源,它还有效吗?" 这就是协商缓存。
工作流程:
-
首次请求 :
服务器返回资源,并在响应头中附带缓存标识,如:
ETag: "abc123"(基于内容生成的唯一标识)Last-Modified: Wed, 21 Oct 2024 07:28:00 GMT(资源最后修改时间)
-
后续请求 :
浏览器在请求头中带上验证字段:
If-None-Match: "abc123"(对应ETag)If-Modified-Since: Wed, 21 Oct 2024 07:28:00 GMT(对应Last-Modified)
-
服务器判断:
- 若资源未变 → 返回
304 Not Modified,浏览器使用本地缓存。 - 若资源已变 → 返回
200 OK+ 新资源,并更新缓存标识。
- 若资源未变 → 返回
ETag vs Last-Modified
-
优先使用
ETag,原因如下:Last-Modified精确到秒级,无法识别一秒内的多次修改。- 文件内容未变但修改时间变了(如重新部署),
ETag(通常基于内容哈希)仍能识别为"未变",而Last-Modified会误判为"已更新"。
强缓存与协商缓存的配合策略
在实际应用中,两者通常组合使用:
- 静态资源(JS/CSS/图片) :设置长期强缓存(如
max-age=31536000),并通过文件名哈希(如app.a1b2c3.js)解决更新问题。 - HTML 文件 :通常设置
no-cache,确保每次加载最新入口,再由 HTML 引用带哈希的静态资源。
浏览器不同操作对缓存的影响:
| 用户操作 | 强缓存 | 协商缓存 |
|---|---|---|
| 页面跳转 / 前进后退 | ✅ 生效 | 不触发(直接读缓存) |
| 普通刷新(F5) | ❌ 跳过 | ✅ 触发(发送验证请求) |
| 强制刷新(Ctrl+F5 或 Cmd+Shift+R) | ❌ 跳过 | ❌ 跳过(全新请求) |
🛠️ 开发调试技巧 :
在 Chrome DevTools 的 Network 面板中勾选 "Disable cache" ,可临时禁用所有缓存,方便调试最新资源。
为什么需要缓存?
- 网络请求的延迟和带宽成本远高于本地读取。
- 静态资源(如 JS、CSS、图片)通常不频繁变动,非常适合缓存。
- 合理的缓存策略可显著提升首屏加载速度、降低服务器负载。
前端与缓存的关系
在现代前端工程化中,我们常通过构建工具(如 Webpack)为静态资源添加内容哈希:
html
<!-- 构建前 -->
<script src="./app.js"></script>
<!-- 构建后 -->
<script src="./app.a1b2c3.js"></script>原理:文件内容变化 → 哈希值变化 → 文件名变化 → 浏览器视为新资源 → 绕过旧缓存。
但在开发模式下,构建通常不设置强缓存,甚至协商缓存也是禁用的,为了方便我们改代码后立刻看到对应的效果。
如果在生产环境中,会自动有个时间较短的强缓存时间,并且协商缓存能默认存在。
🔧 为什么协商缓存能"默认存在"?
因为:
ETag可以基于文件 inode + 修改时间 + 大小 自动生成;Last-Modified就是文件系统的修改时间;- 这些信息服务器天然拥有,所以默认就返回了。
对于强缓存这个 max-age 是平台决定的,作为前端无法修改(除非平台支持自定义头)。
不过在一些部署平台上,我们可以配置响应头(比如:Vercel、Netlify、Nginx、Express、Cloudflare Pages):
http
# 对带 hash 的静态资源(.js, .css, .png...)
Cache-Control: public, max-age=31536000, immutable
# 对 index.html
Cache-Control: no-cache这时:
- 带 hash 的资源 → 强缓存生效 ✅
- HTML → 每次验证(协商缓存或 no-cache)✅