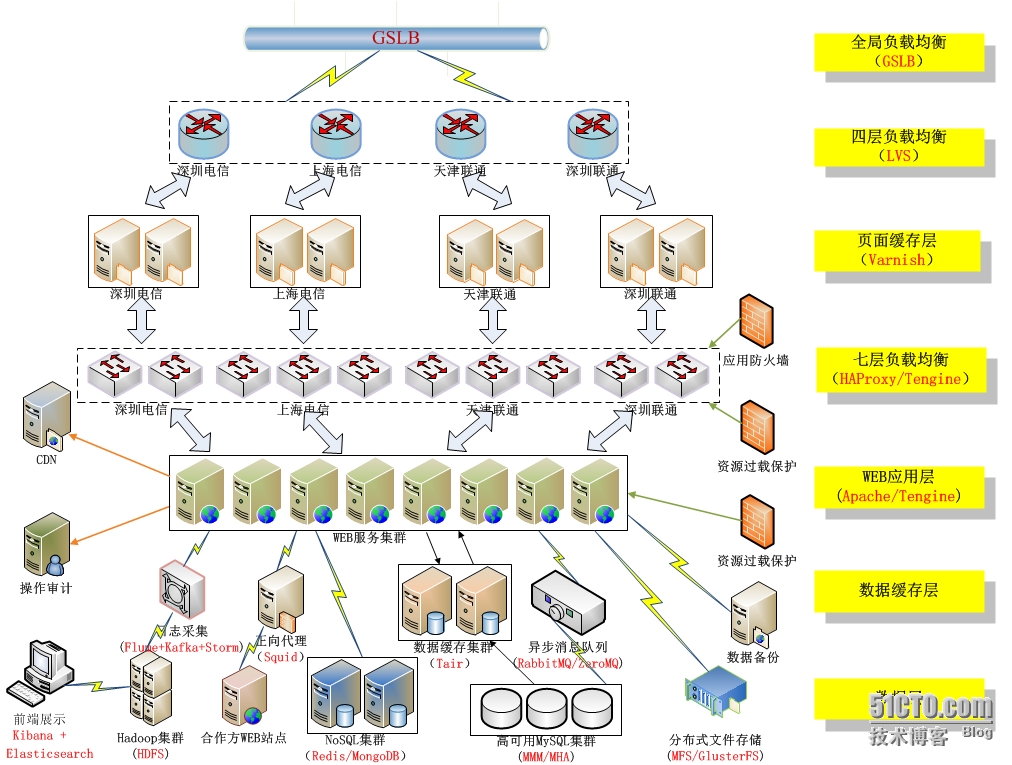
文章目录
- [负载均衡-Nginx 全解析](#负载均衡-Nginx 全解析)
- [HAProxy 负载均衡全解析:从基础部署、负载策略到会话保持及性能优化指南](#HAProxy 负载均衡全解析:从基础部署、负载策略到会话保持及性能优化指南)
-
- [HAProxy 介绍](#HAProxy 介绍)
- [HAProxy 调度算法](#HAProxy 调度算法)
- [HAProxy 实践](#HAProxy 实践)
- [HAProxy 配置说明](#HAProxy 配置说明)
- [HAProxy 使用总结](#HAProxy 使用总结)
- [负载均衡-LVS 全解析](#负载均衡-LVS 全解析)
- 总结
负载均衡-Nginx 全解析
Nginx 介绍
反向代理服务可以缓存资源以改善网站性能。在部署位置上,反向代理服务器处于Web服务器前面,缓存Web响应,加速访问。这个位置也正好是负载均衡服务器的位置,所以大多数反向代理服务器同时提供负载均衡的功能,管理一组Web服务器,将请求根据负载均衡算法转发到不同的Web服务器上。
Web服务器处理完成的响应也需要通过反向代理服务器返回给用户。由于web服务器不直接对外提供访问,因此Web服务器不需要使用外部ip地址,而反向代理服务器则需要配置双网卡和内部外部两套IP地址。
常见的 Nginx 版本有:
- 官方版 (Nginx Official) :由 Nginx 官方发布的版本,这是最常见和最基础的版本。官方版专注于提供核心的 Nginx 功能,定期更新并提供安全补丁和性能优化。它适用于大多数使用场景,是企业和个人用户的首选。
- Nginx Plus:这是 Nginx 官方的商业版本,提供了更多高级功能和企业级支持,例如会话保持(Sticky Sessions)、应用程序负载均衡、动态 DNS 解析、活动健康检查以及更高级的监控和管理功能。Nginx Plus 适合需要企业级支持和额外功能的用户。
- OpenResty:基于 Nginx 的一个高性能 Web 平台,集成了 LuaJIT 和大量的 Lua 模块,使用户可以用 Lua 编写 Nginx 的扩展模块和逻辑,适用于需要高度可定制和高性能 Web 服务的场景。OpenResty 常用于需要动态内容生成或更复杂请求处理的应用中。
- Tengine:由阿里巴巴开发和维护的 Nginx 分支,特别为大型网站和互联网企业优化。Tengine 在 Nginx 的基础上添加了许多新特性和增强功能,如动态模块加载、更高效的处理请求能力和性能优化,是中国互联网企业广泛使用的版本。
Nginx 实践
本实验通过 nginx 代理方式访问 web 集群。
实验环境前提:
- 关闭 SELinux
- 关闭防火墙
网络拓扑
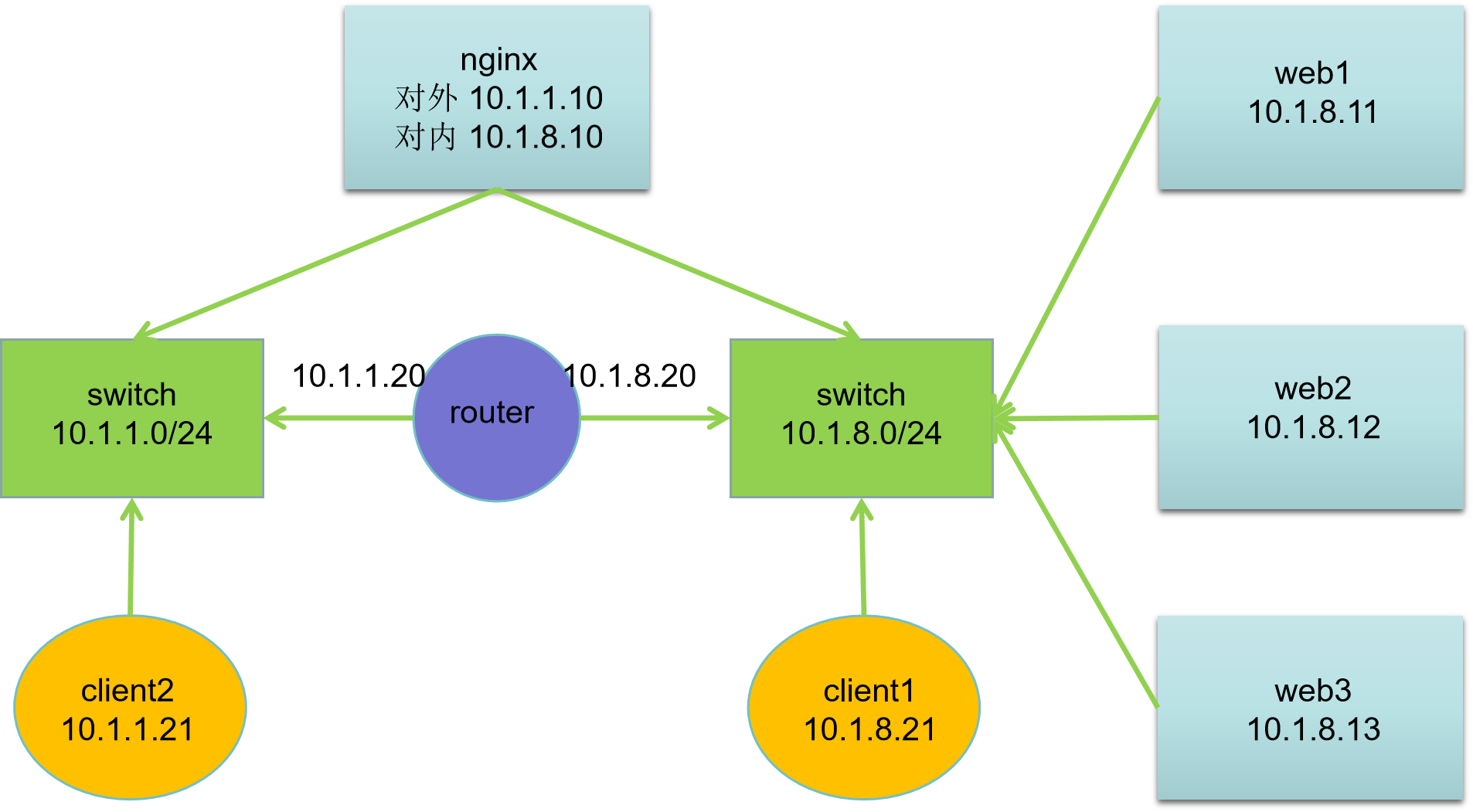
| 主机名 | IP地址 | 服务器角色 |
|---|---|---|
| client2.ghl.cloud | 10.1.1.21 | 客户端 |
| client1.ghl.cloud | 10.1.8.21 | 客户端 |
| router.ghl.cloud | 10.1.1.20, 10.1.8.20 | 路由器 |
| nginx.ghl.cloud | 10.1.1.10, 10.1.8.10 | 代理服务器 |
| web1.ghl.cloud | 10.1.8.11 | Web 服务器 |
| web2.ghl.cloud | 10.1.8.12 | Web 服务器 |
| web3.ghl.cloud | 10.1.8.13 | Web 服务器 |
网络说明:
- 所有主机:第一块网卡名为 ens33,第二块网卡名为 ens192
- 默认第一块网卡模式为nat,第二块网卡模式为hostonly
- 网关设置:10.1.1.0/24 网段网关为10.1.1.20,10.1.8.0/24 网段网关为10.1.8.20
基础配置
-
主机名
-
IP 地址
-
网关
bash# 网关配置命令参考 # 10.1.1.0/24 网段网关为10.1.1.20 [root@router ~ 09:20:04]# nmcli connection modify ens33 ipv4.gateway 10.1.8.20 [root@router ~ 09:27:33]# nmcli connection up ens33 # 10.1.8.0/24 网段网关为10.1.8.20 [root@router ~ 09:29:05]# nmcli connection modify ens33 ipv4.gateway 10.1.1.20 [root@router ~ 09:29:05]# nmcli connection up ens33
配置 router
bash
# 开启路由
[root@router ~ 09:33:52]# echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf
# 或者
# [root@router ~ 09:33:52]# sed -i "s/ip_forward=0/ip_forward=1/g" /etc/sysctl.conf
[root@router ~ 09:29:57]# sysctl -p
# 设置防火墙
systemctl enable firewalld.service --now
firewall-cmd --set-default-zone=trusted
firewall-cmd --add-masquerade
firewall-cmd --add-masquerade --permanent
# 配置免密登录
[root@router ~ 09:29:49]# sshpass -p 123 ssh-copy-id web3
[root@router ~ 09:29:57]# sshpass -p 123 ssh-copy-id nginx配置 web
bash
# 部署 web
[root@web3 ~ 09:34:10]# yum install -y nginx
[root@web3 ~ 09:40:09]# echo Welcome to $(hostname) > /usr/share/nginx/html/index.html
[root@web3 ~ 09:40:09]# systemctl enable nginx.service --now
# 访问后端 nginx
[root@router ~ 09:42:54]# curl 10.1.8.13
Welcome to web3.ghl.cloud配置 Nginx 代理
bash
# 配置代理
[root@ngnix ~ 09:37:02]# yum install -y nginx
# 配置nginx
[root@ngnix ~ 09:45:57]# vim /etc/nginx/conf.d/proxy.conf
upstream web {
server 10.1.8.11:80;
server 10.1.8.12:80;
server 10.1.8.13:80;
}
# 前段监听
server {
server_name www.ghl.cloud;
root /usr/share/nginx/html;
include /etc/nginx/default.d/*.conf;
location / {
# 添加如下语句
proxy_pass http://web;
}
}
# 启动服务
[root@ngnix ~ 09:50:52]# systemctl start nginx.service访问验证
bash
[root@client1 ~ 09:17:19]# echo "10.1.8.10 www.ghl.cloud www" >> /etc/hosts
[root@client1 ~ 09:52:24]# for i in {1..90};do curl -s www.ghl.cloud;done|sort|uniq -c
30 Welcome to web1.ghl.cloud
30 Welcome to web2.ghl.cloud
30 Welcome to web3.ghl.cloud
# 或者
[root@client1 ~ 09:54:42]# while true;do curl -s http://10.1.1.10;sleep 1;done
Welcome to web3.ghl.cloud
Welcome to web1.ghl.cloud
Welcome to web2.ghl.cloud
Welcome to web3.ghl.cloud
Welcome to web1.ghl.cloud
......结论:后端服务器轮询处理客户端请求。
Nginx 负载均衡算法
Nginx 的 upstream 模块声明一组可以被 proxy_pass 和 fastcgi_pass 引用的服务器。这些服务器既可以使用不同的端口,也可以使用Unix Socket。这些服务器可被赋予了不同的权重、不同的类型甚至可以基于维护等原因被标记为 down。
upstream 语法:
upstream name {
....
}例如:
json
upstream backend {
server backend1.example.com weight=5 down backup;
server 127.0.0.1:8080 max_fails=3 fail_timeout=30s;
server unix:/tmp/backend2;
}upstream 模块常用的指令有:
-
keepalive,每个 worker 进程为发送到 upstream 服务器的连接所缓存的个数。
-
server,定义一个upstream服务器的地址,还可包括一系列可选参数。
-
weight:权重,默认值为1;
-
max_fails:最大失败连接次数,失败连接的超时时长由fail_timeout指定;
-
fail_timeout:等待请求的目标服务器发送响应的时长;
-
backup:用于 fallback 的目的,所有服务均故障时才启动此服务器;
-
down:手动标记其不再处理任何请求;
-
示例:
json
upstream web {
keepalive 32;
server 10.1.8.11:80 max_fails=3 fail_timeout=30s weight=2;
server 10.1.8.12:80 max_fails=3 fail_timeout=30s backup;
server 10.1.8.13:80 max_fails=3 fail_timeout=30s down;
}upstream 模块调度算法一般分为两类:
-
静态调度算法,即负载均衡器根据自身设定的规则进行分配,不需要考虑后端节点服务器的情况。例如:rr、ip_hash 等都属于静态调度算法。
-
动态调度算法,即负载均衡器会根据后端节点的当前状态来决定是否分发请求, 例如:连接数少(least_conn)的服务器优先获得请求,响应时间短(least_time)的服务器优先获得请求。
轮询(round-robin)
nginx 默认的调度算法,按客户端请求顺序把客户端的请求逐一分配到不同的后端节点服务器。如果后端节点服务器宕机(默认情况下Nginx只检测80端口),宕机的服务器会被自动从节点服务器池中剔除,以使客户端的用户访问不受影响。新的请求会分配给正常的服务器。
示例:
json
upstream web {
server 10.1.8.11:80;
server 10.1.8.12:80;
server 10.1.8.13:80;
}测试结果
bash
[root@client1 ~ 09:52:24]# for i in {1..90};do curl -s www.ghl.cloud;done|sort|uniq -c
30 Welcome to web1.ghl.cloud
30 Welcome to web2.ghl.cloud
30 Welcome to web3.ghl.cloud**还可以在 rr 轮询算法的基础上为服务器加上权重。**权重和用户访问成正比,权重值越大,被转发的请求也就越多。 可以根据服务器的配置和性能指定权重值大小,有效解决新旧服务器性能不均带来的请求分配问题。在配置的server后面加个weight=number,number值越高,分配的概率越大。
示例:
json
upstream web {
server 10.1.8.11:80 weight=10;
server 10.1.8.12:80 weight=20;
server 10.1.8.13:80 weight=30;
}测试
bash
[root@client2 ~ 14:39:48]# for i in {1..60};do curl -s 10.1.1.10 ;done |sort|uniq -c
10 Welcome to web1.ghl.cloud
20 Welcome to web2.ghl.cloud
30 Welcome to web3.ghl.cloudIP哈希(ip_hash)
**每个请求按客户端IP的 hash 结果分配。**当新的请求到达时,先将其客户端IP通过哈希算法哈希出一个值,在随后的客户端请求中,客户IP的哈希值只要相同,就会被分配至同一台服务器。
该调度算法可以解决动态网页的 session 共享问题,但有时会导致请求分配不均,即无法保证1:1的负载均衡,因为在国内大多数公司都是NAT上网模式,多个客户端会对应一个外部IP,所以这些客户端都会被分配到同一节点服务器,从而导致请求分配不均。
LVS负载均衡的-p参数、Keepalived配置里的per-sistence_timeout 50参数都类似这个Nginx里的ip_hash参数,其功能都可以解决动态网页的session共享问题。
示例:
json
[root@ngnix ~ 10:25:39]# vim /etc/nginx/conf.d/proxy.conf
upstream web {
#
ip_hash;
server 10.1.8.11:80;
server 10.1.8.12:80;
server 10.1.8.13:80;
}测试结果
bash
[root@client2 ~ 10:26:44]# for n in {1..90}; do curl http://10.1.8.10 -s; done | sort |uniq -c
90 Welcome to web2.ghl.cloud通用哈希(generic Hash)
请求发送到的服务器由用户定义的键确定,该键可以是文本字符串、变量或组合。例如,密钥可以是配对的源 IP 地址和端口,或者是 URI。
在upstream中加入hash语句,server语句中不能写入weight等其他的参数,hash_method使用的是hash算法。url_hash按访问URL的hash结果来分配请求,使每个URL定向到同一个后端服务器,可以进一步提高后端缓存服务器的效率命中率。
Nginx本身是不支持url_hash的,如果需要使用这种调度算法,必须安装Nginx的hash模块软件包。
示例:
json
upstream web {
hash $request_uri;
server 10.1.8.11:80;
server 10.1.8.12:80;
server 10.1.8.13:80;
}准备工作
bash
[root@web3 ~ 09:40:41]# mkdir /usr/share/nginx/html/test
[root@web3 ~ 10:28:44]# echo test from $(hostname -s) > \
> /usr/share/nginx/html/test/index.html测试结果
bash
[root@web3 ~ 10:29:30]# for n in {1..90}; do curl http://10.1.8.10 -s; done | sort |uniq -c
90 Welcome to web3.ghl.cloudHAProxy 负载均衡全解析:从基础部署、负载策略到会话保持及性能优化指南
文档 https://www.haproxy.org/#docs
下载 https://www.haproxy.org/#down
HAProxy 介绍
HAProxy 是一款提供高可用性、负载均衡以及基于TCP(第四层)和HTTP(第七层)应用的代理软件,支持虚拟主机。它是免费、快速并且可靠的一种解决方案。 HAProxy 特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。HAProxy 运行在时下的硬件上,完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架构中, 同时可以保护你的web服务器不被暴露到网络上。
**HAProxy 实现了一种事件驱动、单一进程模型,此模型支持非常大的并发连接数。**多进程或多线程模型受内存限制 、系统调度器限制以及无处不在的锁限制,很少能处理数千并发连接。事件驱动模型因为在有更好的资源和时间管理的用户端(User-Space) 实现所有这些任务。此模型的弊端是,在多核系统上,这些程序通常扩展性较差。这就是为什么他们必须进行优化以 使每个CPU时间片(Cycle)做更多的工作。
性能
HAProxy借助于OS上几种常见的技术来实现性能的最大化。
1,单进程、事件驱动模型显著降低了上下文切换的开销及内存占用。
2,O(1)事件检查器(event checker)允许其在高并发连接中对任何连接的任何事件实现即时探测。
3,在任何可用的情况下,单缓冲(single buffering)机制能以不复制任何数据的方式完成读写操作,这会节约大量的CPU时钟周期及内存带宽;
4,借助于Linux 2.6 (>= 2.6.27.19)上的splice()系统调用,HAProxy可以实现零复制转发(Zero-copy forwarding),在Linux 3.5及以上的OS中还可以实现零复制启动(zero-starting);
5,内存分配器在固定大小的内存池中可实现即时内存分配,能够显著减少创建一个会话的时长;
6,树型存储:侧重于使用作者多年前开发的弹性二叉树,实现了以O(log(N))的低开销来保持计时器命令、保持运行队列命令及管理轮询及最少连接队列;
7,优化的HTTP首部分析:优化的首部分析功能避免了在HTTP首部分析过程中重读任何内存区域;
8,精心地降低了昂贵的系统调用,大部分工作都在用户空间完成,如时间读取、缓冲聚合及文件描述符的启用和禁用等;
所有的这些细微之处的优化实现了在中等规模负载之上依然有着相当低的CPU负载,甚至于在非常高的负载场景中,5%的用户空间占用率和95%的系统空间占用率也是非常普遍的现象,这意味着HAProxy进程消耗比系统空间消耗低20倍以上。因此,对OS进行性能调优是非常重要的。即使用户空间的占用率提高一倍,其CPU占用率也仅为10%,这也解释了为何7层处理对性能影响有限这一现象。由此,在高端系统上HAProxy的7层性能可轻易超过硬件负载均衡设备。
在生产环境中,在7层处理上使用HAProxy作为昂贵的高端硬件负载均衡设备故障故障时的紧急解决方案也时长可见。硬件负载均衡设备在"报文"级别处理请求,这在支持跨报文请求(request across multiple packets)有着较高的难度,并且它们不缓冲任何数据,因此有着较长的响应时间。对应地,软件负载均衡设备使用TCP缓冲,可建立极长的请求,且有着较大的响应时间。
HAProxy 调度算法
Haproxy有8种负载均衡算法(balance),分别如下:
-
roundrobin(rr),动态加权轮询,支持权重,
-
static-rr,静态轮询 不支持权重。
-
leastconn,最小连接优先处理。
-
source,源地址哈希算法。
-
uri,根据URI做哈希算法。
-
url_param,根据请求的URl参数'balance url_param' requires an URL parameter name做哈希。
-
hdr(name) ,根据HTTP请求头来锁定每一次HTTP请求。
-
rdp-cookie(name) ,根据据cookie(name)来锁定并哈希每一次TCP请求。
HAProxy 实践
通过HAProxy实现4层和7层负载均衡。
基础配置
网络拓扑
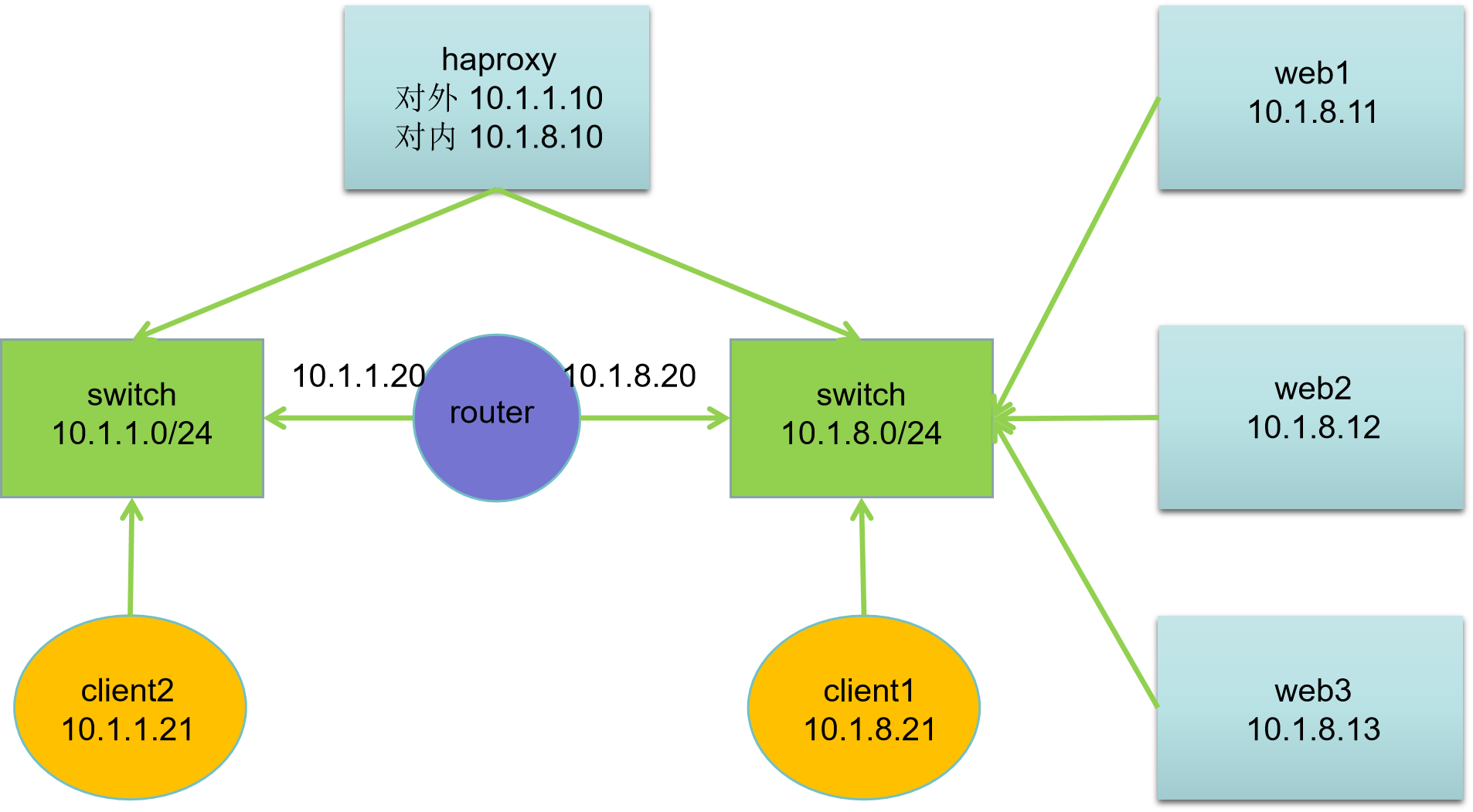
| 主机名 | IP地址 | 服务器角色 |
|---|---|---|
| client2.ghl.cloud | 10.1.1.21 | 客户端 |
| client1.ghl.cloud | 10.1.8.21 | 客户端 |
| router.ghl.cloud | 10.1.8.20 10.1.1.20 | 路由器 |
| haproxy.ghl.cloud | 10.1.8.10 10.1.1.10 | 代理服务器 |
| web1.ghl.cloud | 10.1.8.11 | Web 和 SSH 服务器 |
| web2.ghl.cloud | 10.1.8.12 | Web 和 SSH 服务器 |
| web3.ghl.cloud | 10.1.8.13 | Web 和 SSH 服务器 |
网络说明:
- 所有主机:第一块网卡名为 ens33,第二块网卡名为 ens192
- 默认第一块网卡模式为nat,第二块网卡模式为hostonly
- 网关设置:10.1.1.0/24 网段网关为10.1.1.20,10.1.8.0/24 网段网关为10.1.8.20
基础配置
-
主机名
-
IP 地址
-
网关
bash# 网关配置命令参考 # 10.1.1.0/24 网段网关为10.1.1.20 nmcli connection modify ens33 ipv4.gateway 10.1.1.20 nmcli connection up ens33 # 10.1.8.0/24 网段网关为10.1.8.20(可以不改) nmcli connection modify ens33 ipv4.gateway 10.1.8.20 nmcli connection up ens33
配置 router
bash
# 开启路由
echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf
sysctl -p
# 设置防火墙
systemctl enable firewalld.service --now
firewall-cmd --set-default-zone=trusted
firewall-cmd --add-masquerade --permanent简单配置 haproxy
bash
# 安装 haproxy
[root@haproxy ~ 10:36:49]# yum install -y haproxy
# 备份 haproxy 配置文件
[root@haproxy ~ 10:37:37]# cp /etc/haproxy/haproxy.cfg{,.ori}
# 修改 haproxy 配置文件,最后添加以下内容
[root@haproxy ~ 10:42:23]# vim /etc/haproxy/haproxy.cfg
frontend front_web *:80
use_backend backend_web
backend backend_web
balance roundrobin
server web1 10.1.8.11:80
server web2 10.1.8.12:80
server web3 10.1.8.13:80
[root@haproxy ~ 10:43:23]# systemctl start haproxy.service
# 测试
[root@client1 ~ 10:27:15]# for n in {1..90}; do curl http://10.1.1.10 -s; done | sort |uniq -c
30 Welcome to web1.ghl.cloud
30 Welcome to web2.ghl.cloud
30 Welcome to web3.ghl.cloudhttp 模式
配置 web
bash
# web1、2、3相同操作
[root@web1 ~ 11:31:05]# cat > /etc/nginx/conf.d/vhost-test.conf <<'EOF'
> server {
> listen 81;
> root /test;
> }
> EOF
[root@web1 ~ 11:31:37]# systemctl restart nginx
[root@web1 ~ 11:31:43]# mkdir /test
[root@web1 ~ 11:31:49]# echo hello txt from $(hostname -s) > /test/index.txt
[root@web1 ~ 11:32:01]# echo hello html from $(hostname -s) > /test/index.html
# 测试
[root@client1 ~ 11:45:46]# curl http://web1:81/
hello html from web1
[root@client1 ~ 11:54:32]# curl http://web2:81/
hello html from web2
[root@client1 ~ 11:45:43]# curl http://web3:81/
hello html from web3配置 haproxy
bash
[root@haproxy ~ 11:28:05]# vim /etc/haproxy/haproxy.cfg
######### web 代理 ###########
frontend front_web
bind *:80
default_backend back_web
acl test url_reg -i \.txt$
# acl 是固定的关键字
# test 规则名,可自定义
# url_reg 匹配方式
# -i 忽略大小写
# \.txt$ 匹配.txt结尾
# 如果ac规则 test匹配,则使用后端 back_test
use_backend back_test if test
backend back_web
# 采用轮询方式负载
balance roundrobin
server web1 10.1.8.11:80 check
# server 是关键字,代表后端主机
# web1 是后端主机名,可自定义,建议与主机名保持一致
# 10.1.8.11:80 是后端服务实际地址和端口
# check haproxy检查后端服务是否正常
server web2 10.1.8.12:80 check
server web3 10.1.8.13:80 check
backend back_test
balance roundrobin
server test1 10.1.8.11:81 check
server test2 10.1.8.12:81 check
server test3 10.1.8.13:81 check
[root@haproxy ~ 11:18:38]# systemctl restart haproxy.service测试
bash
[root@client1 ~ 10:27:15]# for n in {1..90}; do curl http://10.1.1.10 -s; done | sort |uniq -c
30 Welcome to web1.ghl.cloud
30 Welcome to web2.ghl.cloud
30 Welcome to web3.ghl.cloud
# 测试 txt结尾的acl规则
[root@client1 ~ 11:36:09]# while true;do curl -s http://10.1.8.10/index.txt;sleep 1;done
hello txt from web2
hello txt from web3
hello txt from web1tcp 模式
配置 haproxy
bash
# 修改 haproxy 配置文件,最后添加以下内容
[root@haproxy ~ 11:11:45]# systemctl restart haproxy.service
[root@haproxy ~ 11:11:50]# echo '
> ######### ssh 代理 ###########
> listen ssh
> mode tcp
> bind *:1022
> balance roundrobin
> server web1 10.1.8.11:22 check
> server web2 10.1.8.12:22 check
> server web3 10.1.8.13:22 check
> ' >> /etc/haproxy/haproxy.cfg
# 重启服务
[root@haproxy ~ 11:15:49]# systemctl restart haproxy.service测试
bash
[root@client1 ~ 11:25:23]# while true;do curl -s http://10.1.8.10/index.txt;sleep 1;done
hello txt from web3
hello txt from web2
hello txt from web3HAProxy 配置说明
haproxy 的配置文件由两部分组成:全局设定(global settings)和对代理的设定(proxies)
- global settings:主要用于定义haproxy进程管理安全及性能相关的参数
- proxies 共分为4段:
- defaults:为其它配置段提供默认参数,默认配置参数可由下一个"defaults"重新设定。
- frontend:定义一系列监听的套接字,这些套接字可接受客户端请求并与之建立连接。
- backend:定义"后端"服务器,前端代理服务器将会把客户端的请求调度至这些服务器。
- listen:定义监听的套接字和后端的服务器。类似于将frontend和backend段放在一起,通常配置TCP流量,也就是4层代理。
所有代理的名称只能使用大写字母、小写字母、数字、-(中线)、_(下划线)、.(点号)和:(冒号)。此外,ACL名称会区分字母大小写。
HAProxy 使用总结
HAProxy 是高性能开源负载均衡器,支持 TCP 四层与 HTTP 七层代理,核心功能含负载策略(轮询、加权、IP 哈希等)、后端服务器健康检查(主动 / 被动)及会话保持。通过 frontend/backend/listen 配置块定义转发规则,可实现 SSL 终止、请求过滤与流量控制。轻量且高并发,常用于 Web 服务、数据库等场景的高可用架构,搭配日志监控与故障转移配置,能有效提升服务稳定性与资源利用率。
负载均衡-LVS 全解析
LVS 介绍
Linux 虚拟服务器(LVS,Linux Virtual Servers) ,使用负载均衡技术将多台服务器组成一个虚拟服务器。它为适应快速增长的网络访问需求提供了一个负载能力易于扩展,而价格低廉的解决方案。
LVS是 章文嵩博士 于1998年创建的一款开源负载均衡软件。LVS工作在内核空间中,能够根据请求报文的目标IP和目标 PORT 将请求调度转发至后端服务器集群中的某节点。
LVS 术语
-
调度器,负载均衡器,Director,Virtual Server(VS)
-
后端服务器,真实服务器,Real Server(RS),Backend Server
-
调度器一般配两个IP地址:VIP ,向外提供服务的IP地址;DIP,与后端RS通信的IP地址。
-
RIP :RS 的 IP,CIP:客户端的IP。
LVS由 ipvsadm 和 ipvs 组成:
- ipvsadm:用户空间命令行工具,用于在Director上定义集群服务和添加集群上的 Real Servers。
- ipvs:工作于内核上 netfilter 中 INPUT 钩子上的程序代码。
要想将某台主机配置为 Director,首选确保当前内核支持 ipvs 并安装 ipvsadm。另外,由于 Director 要调度转发所有客户端的请求,负载压力较大,生产环境中Director 不要使用虚拟机。
工作原理
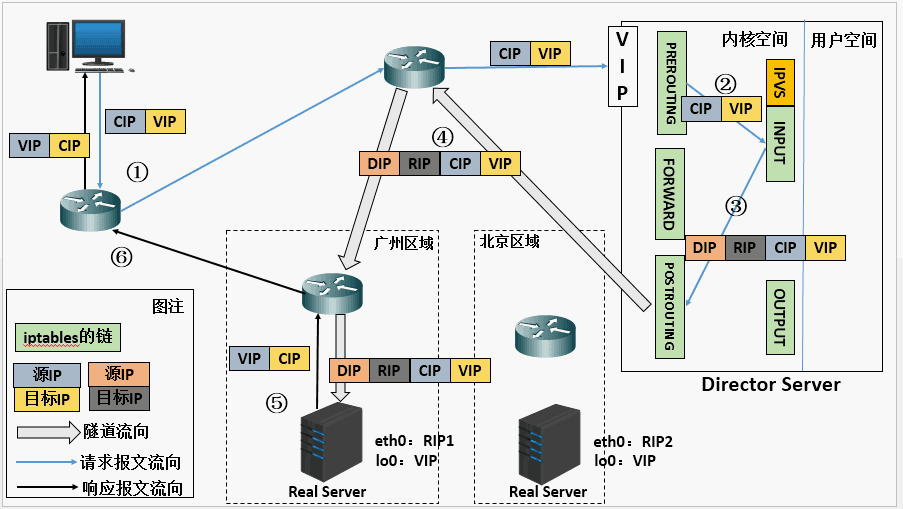
ipvs使用内核netfilter子系统处理进入本机器的数据包:
- 当用户向负载均衡调度器(Director Server)发起请求,调度器将请求发往至内核空间。
- PREROUTING 链首先会接收到用户请求,判断目标IP确定是本机IP,将数据包发往INPUT 链。
- IPVS 是工作在 INPUT 链上的代码块。当用户请求到达 INPUT 时,IPVS 会将用户请求和自己已定义好的集群服务进行比对,如果用户请求的就是定义的集群服务,那么此时IPVS会强行修改数据包里的目标IP地址及端口,并将新的数据包发往 POSTROUTING 链。
- POSTROUTING 链接收数据包后发现目标IP地址刚好是自己的后端服务器,那么此时通过选路,将数据包最终发送给后端的服务器。
工作模式
LVS 的常用工作模式有四种,分别是:
- lvs-nat
- lvs-dr
- lvs-tun
- lvs-fullnet
NAT 模式
工作方式
通过将请求报文的目标地址和目标端口修改为某RS的IP和PORT来实现报文转发。
原报文:
| 源IP | 源MAC | 目标IP | 目标MAC |
|---|---|---|---|
| Client IP | Client MAC | Director VIP | Director MAC |
更改为:
| 源IP | 源MAC | 目标IP | 目标MAC |
|---|---|---|---|
| Client IP | Client MAC | RS IP | RS MAC |
工作原理
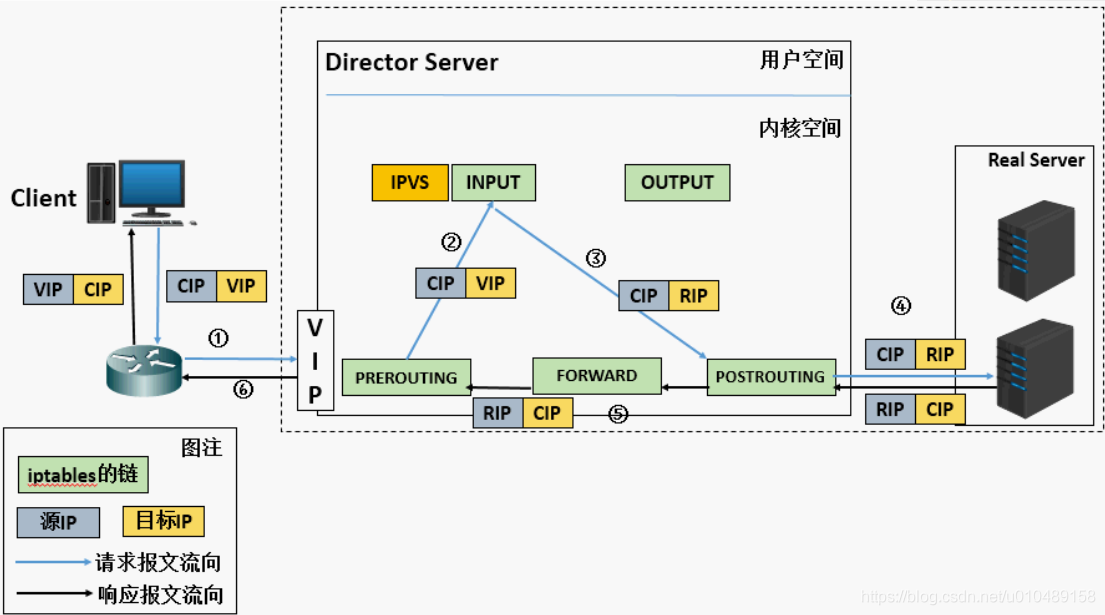
-
当用户请求到达Director Server,此时请求的数据报文会先到内核空间的PREROUTING链。 此时报文的源IP为CIP,目标IP为VIP。
-
PREROUTING检查发现数据包的目标IP是本机,将数据包送至INPUT链。
-
IPVS比对数据包请求的服务是否为集群服务,若是,修改数据包的目标IP地址为后端服务器IP,后将数据包发至POSTROUTING链。 此时报文的源IP为CIP,目标IP为RIP。
-
POSTROUTING链通过选路,将数据包发送给Real Server。
-
Real Server比对发现目标为自己的IP,开始构建响应报文发回给Director Server。 此时报文的源IP为RIP,目标IP为CIP。
-
Director Server在响应客户端前,此时会将源IP地址修改为自己的VIP地址,然后响应给客户端。 此时报文的源IP为VIP,目标IP为CIP。
特点
- RS应该和DIP应该使用私网地址,且RS的网关要指向DIP;
- 请求和响应报文都要经由director转发;极高负载的场景中,director可能会成为系统瓶颈;
- 支持端口映射;
- RS可以使用任意OS;
- RS的RIP和Director的DIP必须在同一IP网络;
缺陷:对Director Server压力会比较大,请求和响应都需经过director server,director往往会成为系统的性能瓶颈
DR 模式
工作方式
通过为请求报文重新封装一个MAC首部进行报文转发;新Mac首部的源MAC是DIP所在网卡的MAC,目标MAC为某RS所在接口的MAC;整个过程源报文的IP首部不会发生变化(源IP为CIP,目标IP始终为VIP);
原报文:
| 源IP | 源MAC | 目标IP | 目标MAC |
|---|---|---|---|
| Client IP | Client MAC | Director VIP | Director MAC |
更改为:
| 源IP | 源MAC | 目标IP | 目标MAC |
|---|---|---|---|
| Client IP | Director DIP对应的MAC | Director VIP | RS MAC |
工作原理
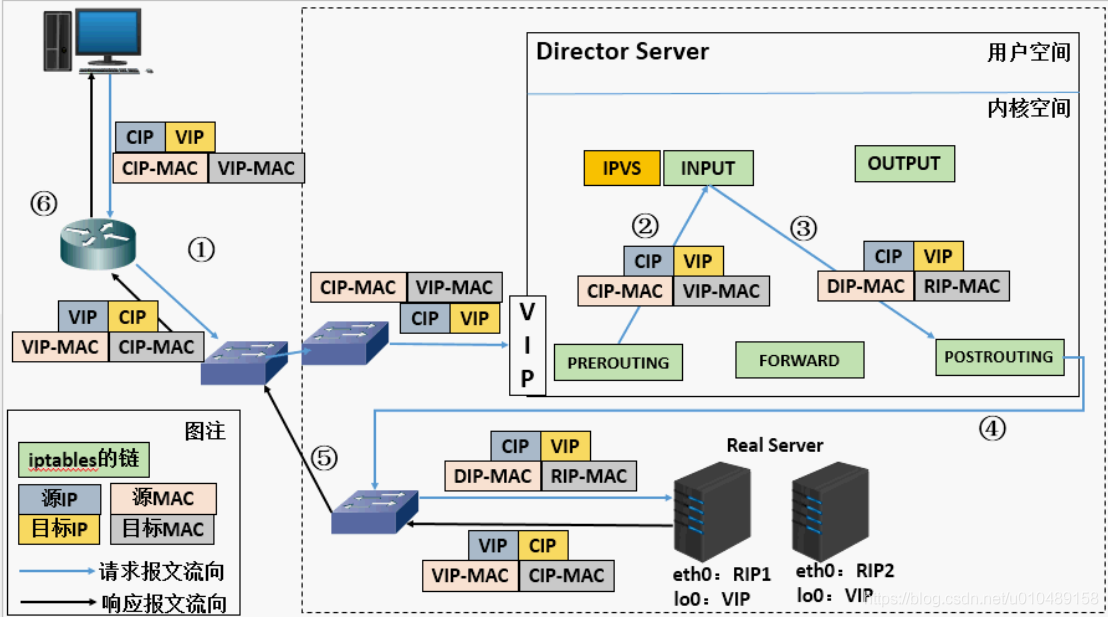
- 当用户请求到达Director Server,此时请求的数据报文会先到内核空间的PREROUTING链。 此时报文的源IP为CIP,目标IP为VIP
- PREROUTING检查发现数据包的目标IP是本机,将数据包送至INPUT链
- IPVS比对数据包请求的服务是否为集群服务,若是,将请求报文中的源MAC地址修改为DIP的MAC地址,将目标MAC地址修改RIP的MAC地址,然后将数据包发至POSTROUTING链。 此时的源IP和目的IP均未修改,仅修改了源MAC地址为DIP的MAC地址,目标MAC地址为RIP的MAC地址
- 由于DS和RS在同一个网络中,所以是通过二层来传输。POSTROUTING链检查目标MAC地址为RIP的MAC地址,那么此时数据包将会发至Real Server。
- RS发现请求报文的MAC地址是自己的MAC地址,就接收此报文。处理完成之后,将响应报文通过lo接口传送给eth0网卡然后向外发出。 此时的源IP地址为VIP,目标IP为CIP
- 响应报文最终送达至客户端
特点
-
RS的lo网卡配置一个IP地址(地址为VIP)。
-
确保路由器只会把目标IP为VIP的请求报文发往Director,即会忽略RS上的VIP;
实现方案如下:
-
路由器静态绑定Director的VIP和MAC地址
-
禁止RS响应VIP的ARP请求;
(a) arptables;
(b) 修改各RS的内核参数,并把VIP配置在特定的接口上实现禁止其响应;
-
-
RS的RIP跟Director的DIP必须在同一物理网络中;RS的网关不能指向DIP
-
RS的RIP可以使用私有地址,也可以使用公网地址;
-
请求报文必须由Director调度,但响应报文不经过Director,RS直接用VIP作为源IP发送响应报文;
-
不支持端口映射;
缺陷:RS和DS必须在同一机房中,因为它是由二层进行转发的根据MAC地址来进行匹配
TUN 模式
工作模式
不修改请求报文的IP首部(源IP仍为CIP,目标IP仍为VIP),而是在原有的IP首部之外再封装一个IP首部(源IP为DIP,目标IP为RIP);
原报文:
| 源IP | 源MAC | 目标IP | 目标MAC |
|---|---|---|---|
| Client IP | Client MAC | Director VIP | Director MAC |
更改为:
| 封装源IP | 封装目标IP | 源IP | 源MAC | 目标IP | 目标MAC |
|---|---|---|---|---|---|
| DIP | RIP | Client IP | Client MAC | Director VIP | Director MAC |
工作原理
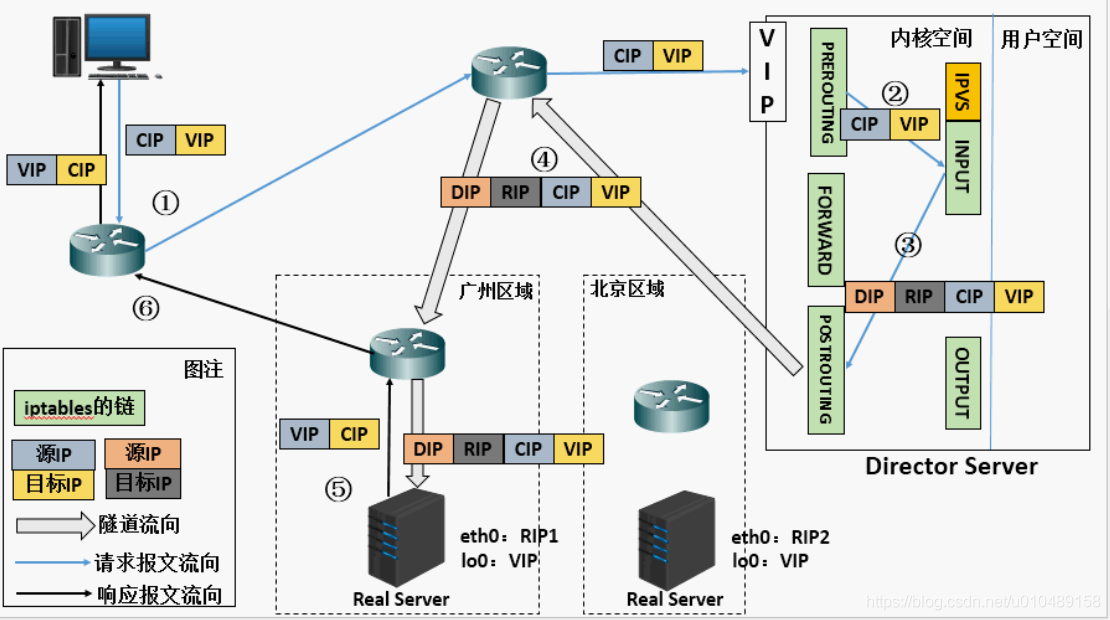
- 当用户请求到达Director Server,此时请求的数据报文会先到内核空间的PREROUTING链。 此时报文的源IP为CIP,目标IP为VIP 。
- PREROUTING检查发现数据包的目标IP是本机,将数据包送至INPUT链
- IPVS比对数据包请求的服务是否为集群服务,若是,在请求报文的首部再次封装一层IP报文,封装源IP为为DIP,目标IP为RIP。然后发至POSTROUTING链。 此时源IP为DIP,目标IP为RIP
- POSTROUTING链根据最新封装的IP报文,将数据包发至RS(因为在外层封装多了一层IP首部,所以可以理解为此时通过隧道传输)。 此时源IP为DIP,目标IP为RIP
- RS接收到报文后发现是自己的IP地址,就将报文接收下来,拆除掉最外层的IP后,会发现里面还有一层IP首部,而且目标是自己的lo接口VIP,那么此时RS开始处理此请求,处理完成之后,通过lo接口送给eth0网卡,然后向外传递。 此时的源IP地址为VIP,目标IP为CIP
- 响应报文最终送达至客户端
特点
- RIP,DIP,VIP必须都是公网地址;
- RS的网关不能,也不可能指向DIP;
- 请求报文经由Director调度,但响应报文将直接发给CIP;
- 不支持端口映射;
- RS的OS必须支持IP隧道功能;
调度算法
LVS的调度算法分为静态与动态两类。
静态算法
根据算法进行调度,不考虑后端服务器的实际连接情况和负载情况。
-
RR:轮叫调度(Round Robin)
调度器通过"轮叫"调度算法将外部请求按顺序轮流分配到集群中的真实服务器上,它均等地对待每一台服务器,而不管服务器上实际的连接数和系统负载。
-
WRR:加权轮叫(Weight RR)
调度器通过"加权轮叫"调度算法根据真实服务器的不同处理能力来调度访问请求。这样可以保证处理能力强的服务器处理更多的访问流量。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。
-
DH:目标地址散列调度(Destination Hash )
根据请求的目标IP地址,作为散列键(HashKey)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。
-
SH:源地址 hash(Source Hash)
源地址散列"调度算法根据请求的源IP地址,作为散列键(HashKey)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。
动态算法
前端的调度器会根据后端真实服务器的实际连接情况来分配请求。
-
LC:最少链接(Least Connections)
调度器通过"最少连接"调度算法动态地将网络请求调度到已建立的链接数最少的服务器上。如果集群系统的真实服务器具有相近的系统性能,采用"最小连接"调度算法可以较好地均衡负载。
-
WLC:加权最少连接(默认采用的就是这种)(Weighted Least Connections)
在集群系统中的服务器性能差异较大的情况下,调度器采用"加权最少链接"调度算法优化负载均衡性能,具有较高权值的服务器将承受较大比例的活动连接负载。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。
-
SED:最短延迟调度(Shortest Expected Delay )
在WLC基础上改进,Overhead = (ACTIVE+1)*256/加权,不再考虑非活动状态,把当前处于活动状态的数目+1来实现,数目最小的,接受下次请求,+1的目的是为了考虑加权的时候,非活动连接过多缺陷:当权限过大的时候,会倒置空闲服务器一直处于无连接状态。
-
NQ永不排队/最少队列调度(Never Queue Scheduling NQ)
无需队列。如果有台 realserver的连接数=0就直接分配过去,不需要再进行sed运算,保证不会有一个主机很空间。在SED基础上无论+几,第二次一定给下一个,保证不会有一个主机不会很空闲着,不考虑非活动连接,才用NQ,SED要考虑活动状态连接,对于DNS的UDP不需要考虑非活动连接,而httpd的处于保持状态的服务就需要考虑非活动连接给服务器的压力。
-
LBLC:基于局部性的最少链接(locality-Based Least Connections)
基于局部性的最少链接"调度算法是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。该算法根据请求的目标IP地址找出该目标IP地址最近使用的服务器,若该服务器是可用的且没有超载,将请求发送到该服务器;若服务器不存在,或者该服务器超载且有服务器处于一半的工作负载,则用"最少链接"的原则选出一个可用的服务器,将请求发送到该服务器。
-
LBLCR:带复制的基于局部性最少连接(Locality-Based Least Connections with Replication)
带复制的基于局部性最少链接"调度算法也是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。它与LBLC算法的不同之处是它要维护从一个目标IP地址到一组服务器的映射,而LBLC算法维护从一个目标IP地址到一台服务器的映射。该算法根据请求的目标IP地址找出该目标IP地址对应的服务器组,按"最小连接"原则从服务器组中选出一台服务器,若服务器没有超载,将请求发送到该服务器;若服务器超载,则按"最小连接"原则从这个集群中选出一台服务器,将该服务器加入到服务器组中,将请求发送到该服务器。同时,当该服务器组有一段时间没有被修改,将最忙的服务器从服务器组中删除,以降低复制的程度。
LVS 实践
通过LVS实现httpd负载均衡。
基本配置
-
主机名
-
网络
-
/etc/hosts
bash127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 ###### lvs 代理集群 ######## # lvs 主机记录一定要设置为 VIP 地址 # 如果 lvs主机解析为 10.1.8.10,则会导致ipvs规则的VIP变为10.1.8.10 10.1.1.10 lvs lvs.ghl.cloud 10.1.8.11 web1 web1.ghl.cloud 10.1.8.12 web2 web2.ghl.cloud 10.1.8.13 web3 web3.ghl.cloud 10.1.8.20 router router.ghl.cloud 10.1.8.21 client1 client1.ghl.cloud 10.1.1.21 client2 client2.ghl.cloud -
web 服务器
bash[root@web1-3 ~]# yum install -y nginx systemctl enable nginx --now echo Welcome to $(hostname) > /usr/share/nginx/html/index.html -
lvs 服务器
bash[root@lvs ~]# yum install -y ipvsadm # systemctl enable ipvsadm # 等ipvs规则配置完成后再启动ipvsadm服务
ipvsadm 命令
bash
## 定义集群服务
ipvsadm -A|E -t|u|f service-address [-s scheduler]
[-p [timeout]] [-M netmask]
-A: 表示添加一个新的集群服务
-E: 编辑一个集群服务
-t: 表示tcp协议
-u: 表示udp协议
-f: 表示firewall-Mark,防火墙标记
service-address: 集群服务的IP地址,即VIP
-s 指定调度算法
-p 持久连接时长,如#ipvsadm -Lcn ,查看持久连接状态
-M 定义掩码
# 删除一个集群服务
ipvsadm -D -t|u|f service-address
# 清空所有的规则
ipvsadm -C
# 重新载入规则
ipvsadm -R
# 保存规则
ipvsadm -S [-n]
## 管理集群服务中RealServer
ipvsadm -a|e -t|u|f service-address -r server-address
[-g|i|m] [-w weight]
-a 添加一个新的realserver规则
-e 编辑realserver规则
-t tcp协议
-u udp协议
-f firewall-Mark,防火墙标记
service-address realserver的IP地址
-g 表示定八义为LVS-DR模型
-i 表示定义为LVS-TUN模型
-m 表示定义为LVS-NAT模型
-w 定义权重,后面跟具体的权值
# 删除一个realserver
ipvsadm -d -t|u|f service-address -r server-address
# 查看定义的规则
ipvsadm -L|l [options]
ipvsadm -L -n
# 清空计数器
ipvsadm -Z [-t|u|f service-address]NAT 模式
网络拓扑
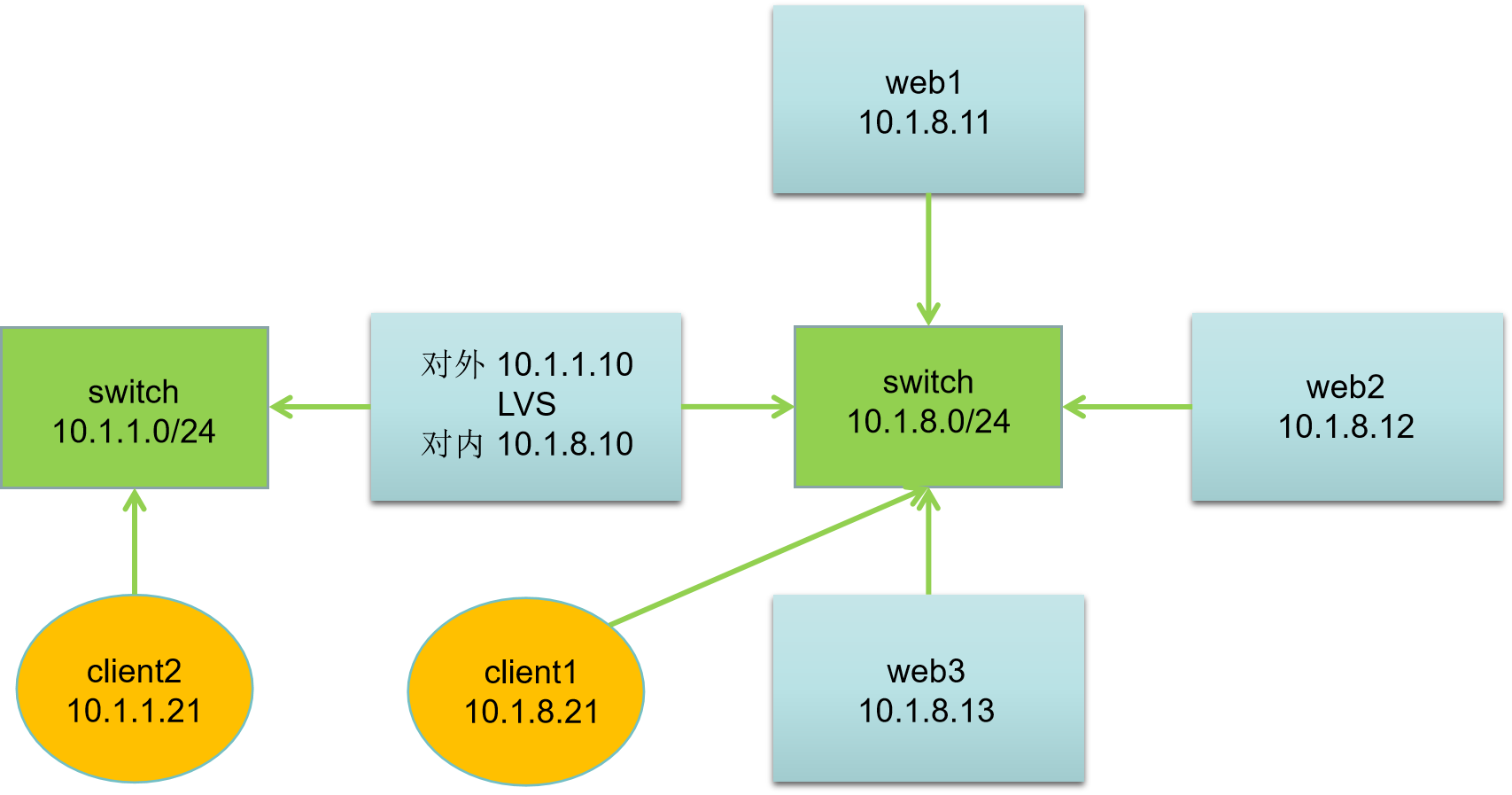
| 主机名 | IP地址 | 服务器角色 |
|---|---|---|
| client2.ghl.cloud | 10.1.1.21 | 客户端 |
| client1.ghl.cloud | 10.1.8.21 | 客户端 |
| router.ghl.cloud | 10.1.1.20, 10.1.8.20 | 路由器 |
| lvs.ghl.cloud | 10.1.1.10, 10.1.8.10 | LVS 服务器 |
| web1.ghl.cloud | 10.1.8.11 | Web 服务器 |
| web2.ghl.cloud | 10.1.8.12 | Web 服务器 |
| web3.ghl.cloud | 10.1.8.13 | Web 服务器 |
网络说明:
- 所有主机:第一块网卡名为 ens33,第二块网卡名为 ens192
- 默认第一块网卡模式为nat,第二块网卡模式为hostonly
- 网关设置:10.1.1.0/24 网段网关为10.1.1.10,10.1.8.0/24 网段网关为10.1.8.10
注意:本次实验的网关指向 LVS 服务器。
配置 LVS
准备工作
bash
[root@haproxy ~ 13:36:47]# systemctl disable haproxy --now
[root@client2 ~ 14:11:20]# nmcli connection modify ens33 ipv4.gateway 10.1.1.10
[root@client2 ~ 14:11:59]# nmcli connection up ens33
# 该脚本用于批量维护远端主机
# 第一个参数是cmd,则用于在远端主机上执行命令
# 第一个参数是scp,则用于将本地文件复制到远端主机
[root@router ~ 13:47:42]# vim /usr/local/bin/weihu
#!/bin/bash
case $1 in
cmd)
shift
for host in lvs web{1..3} client1 client2
do
ssh root@$host "$*"
done
;;
scp)
shift
for host in lvs web{1..3} client1 client2
do
scp $1 root@$host:$1
done
;;
*)
echo "Usage: $0 cmd command"
echo "Usage: $0 scp /path/to/file"
exit
;;
esac
# 用于修改网关
[root@router ~ 14:01:23]# vim /usr/local/bin/weihu
#!/bin/bash
#HOSTLIST="lvs web{1..3} client1 client2"
HOSTLIST="web1 web2 web3 client1"
case $1 in
cmd)
shift
for host in $HOSTLIST
do
ssh root@$host "$*"
done
;;
scp)
shift
for host in $HOSTLIST
do
scp $1 root@$host:$1
done
;;
*)
echo "Usage: $0 cmd command"
echo "Usage: $0 scp /path/to/file"
exit
;;
esac
[root@router ~ 14:00:50]# weihu cmd nmcli connection modify ens33 ipv4.gateway 10.1.8.10
[root@router ~ 14:01:16]# weihu cmd nmcli connection up ens33
bash
# 开启路由
[root@lvs ~ 13:57:26]# echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf
# 或者
# sed -i "s/ip_forward=0/ip_forward=1/g" /etc/sysctl.conf
[root@lvs ~ 14:08:04]# sysctl -p
# 设置防火墙
[root@lvs ~ 14:09:04]# systemctl enable firewalld.service --now
[root@lvs ~ 14:09:29]# firewall-cmd --set-default-zone=trusted
[root@lvs ~ 14:09:30]# firewall-cmd --add-masquerade --permanent
[root@lvs ~ 14:09:30]# firewall-cmd --add-masquerade
# 安装 ipvsadm
[root@lvs ~ 14:10:21]# yum install -y ipvsadm
# ipvsadm 服务启动依赖该文件,否则无法启动服务
[root@lvs ~ 14:13:11]# touch /etc/sysconfig/ipvsadm
[root@lvs ~ 14:14:59]# systemctl enable ipvsadm --now
# 创建轮询负载
# 增减一个tcp模式虚拟IP,调度模式:轮询
# -A,增加,-t,tcp,-s,设置调度模式
[root@lvs ~ 14:15:24]# ipvsadm -A -t 10.1.1.10:80 -s rr
[root@lvs ~ 14:20:55]# ipvsadm -a -t 10.1.1.10:80 -r 10.1.8.11 -m
[root@lvs ~ 14:21:20]# ipvsadm -a -t 10.1.1.10:80 -r 10.1.8.12 -m
[root@lvs ~ 14:21:20]# ipvsadm -a -t 10.1.1.10:80 -r 10.1.8.13 -m
[root@lvs ~ 14:21:24]# ipvsadm-save -n > /etc/sysconfig/ipvsadm
# 测试,只能在client2做,client2为外部主机
[root@client2 ~ 14:12:21]# curl http://10.1.1.10
Welcome to web3.ghl.cloud
[root@client2 ~ 14:22:29]# curl http://10.1.1.10
Welcome to web2.ghl.cloud
[root@client2 ~ 14:22:36]# curl http://10.1.1.10
Welcome to web1.ghl.cloud负载均衡模式更改为加权轮询。
bash
# 修改 调度模式为:带权重的轮询
[root@lvs ~ 14:21:50]# ipvsadm -E -t 10.1.1.10:80 -s wrr
# 设置权重为2
[root@lvs ~ 14:39:10]# ipvsadm -e -t 10.1.1.10:80 -r 10.1.8.12 -m -w 2
# 设置权重为3
[root@lvs ~ 14:39:16]# ipvsadm -e -t 10.1.1.10:80 -r 10.1.8.13 -m -w 3
# 核实配置是否生效
[root@lvs ~ 14:39:17]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.1.1.10:80 wrr
-> 10.1.8.11:80 Masq 1 0 2
-> 10.1.8.12:80 Masq 2 0 3
-> 10.1.8.13:80 Masq 3 0 5
# 测试
[root@client2 ~ 14:39:48]# for i in {1..60};do curl -s 10.1.1.10 ;done |sort|uniq -c
10 Welcome to web1.ghl.cloud
20 Welcome to web2.ghl.cloud
30 Welcome to web3.ghl.cloud思考
-
此时client1是否可以通过10.1.1.10访问后端服务器?具体原因是什么?
答案:不能访问。因为client1发出去的数据包是经过LVS的ipvs模块处理的,而后端web服务器收到数据包后根据来源地址10.1.8.21进行回复,也就是直接返回给client1,导致数据包没有返回给LVS处理。
-
如果不能,需要如何配置才能实现访问?
bash
[root@web1-3 ~]# nmcli connection modify ens33 ipv4.routes '10.1.8.21 255.255.255.255 10.1.8.10'
[root@web1-3 ~]# nmcli connection up ens33不建议这样配置,内部网络直接访问主机,不通过外网
DR 模式
网络拓扑
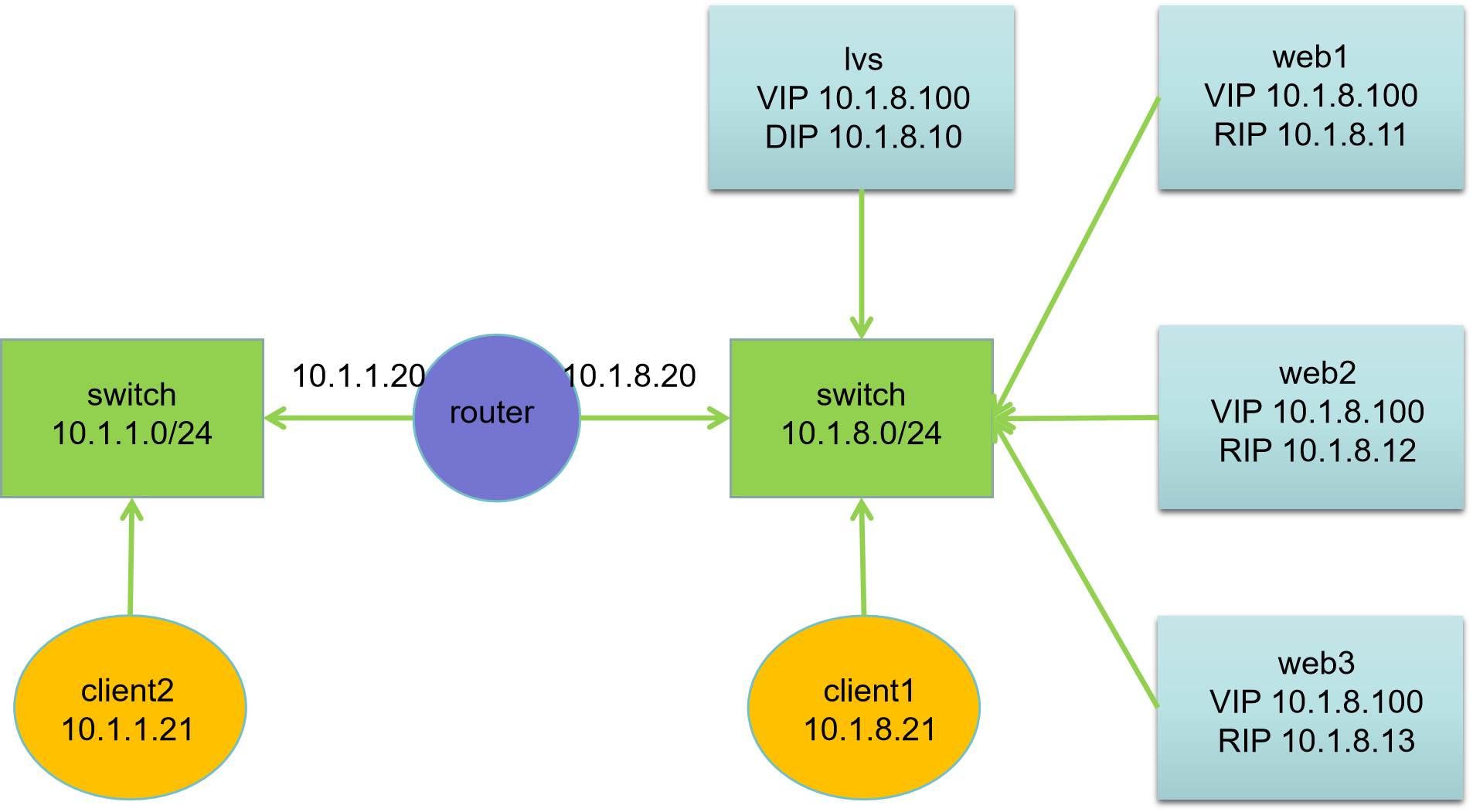
| 主机名 | IP地址 | 服务器角色 |
|---|---|---|
| client2.ghl.cloud | 10.1.1.21 | 客户端 |
| client1.ghl.cloud | 10.1.8.21 | 客户端 |
| router.ghl.cloud | 10.1.1.20, 10.1.8.20 | 路由器 |
| lvs.ghl.cloud | 10.1.8.10 | LVS 服务器 |
| web1.ghl.cloud | 10.1.8.11 | Web 服务器 |
| web2.ghl.cloud | 10.1.8.12 | Web 服务器 |
| web3.ghl.cloud | 10.1.8.13 | Web 服务器 |
网络说明:
- 所有主机:第一块网卡名为 ens33,第二块网卡名为 ens192
- 默认第一块网卡模式为 nat,第二块网卡模式为 hostonly
- 网关设置:10.1.1.0/24 网段网关为10.1.1.20,10.1.8.0/24 网段网关为10.1.8.20
基础配置
-
主机名
-
IP 地址
-
网关
bash# 网关配置命令参考 # 10.1.8.0/24 网段网关为10.1.8.20 nmcli connection modify ens33 ipv4.gateway 10.1.8.20 nmcli connection up ens33 # 10.1.1.0/24 网段网关为10.1.1.20 nmcli connection modify ens33 ipv4.gateway 10.1.1.20 nmcli connection up ens33
web、router部署同上
配置 LVS-RS
所有后端主机都要做相同配置。
bash
# 移除lvs主机的第二个网卡
# web1、2、3相同操作
[root@web1 ~ 13:41:23]# nmcli connection add type dummy ifname dummy con-name dummy ipv4.method manual ipv4.addresses 10.1.8.100/32
[root@web1 ~ 15:05:49]# nmcli connection up dummy
[root@web1 ~ 15:05:50]# cat >> /etc/sysctl.conf << EOF
> net.ipv4.conf.all.arp_ignore = 1
> net.ipv4.conf.all.arp_announce = 2
> net.ipv4.conf.dummy.arp_ignore = 1
> net.ipv4.conf.dummy.arp_announce = 2
> EOF
[root@web1 ~ 15:07:17]# sysctl -p内核参数:net.ipv4.conf.all.arp_ignore
作用:控制主机收到 ARP 请求时,是否回复 ARP 响应(即是否告知对方 "该 IP 对应的 MAC 地址是我")。
参数值及含义:
参数值 行为说明 0(默认) 只要本机有该 IP 地址(无论哪个网卡),就回复 ARP 响应。 问题:多网卡场景下,可能导致 "ARP 漂移"(例如网卡 A 的 IP 被网卡 B 响应)。 1 仅当 ARP 请求的目标 IP 与接收请求的网卡上的主 IP 完全匹配时,才回复响应。 (主 IP 指网卡配置的第一个 IP 地址) 2 仅当 ARP 请求的目标 IP 与接收请求的网卡上的任一 IP(包括 secondary IP)匹配时,才回复响应。 3 不回复 ARP 请求(除非是本地环回地址)。 4-7 更复杂的策略(如忽略来自非本网络的请求),较少使用。 典型场景:
- 服务器有多个网卡(如
eth0、eth1),分别属于不同子网,需避免跨网卡响应 ARP 请求。- 配置虚拟 IP(如 Keepalived 高可用集群的 VIP)时,防止非主节点响应 VIP 的 ARP 请求。
内核参数:net.ipv4.conf.all.arp_announce
作用 :控制主机发送 ARP 通告(主动告知 "我的 IP 对应的 MAC 地址")时,如何选择源 IP 地址。
参数值及含义:
参数值 行为说明 0(默认) 允许使用任意本地 IP 作为 ARP 通告的源 IP(可能选择与目标网络无关的 IP)。 问题:跨子网通信时,可能导致其他主机学习到错误的 IP-MAC 映射。 1 尽量使用与目标 IP 同子网的本地 IP 作为源 IP;若没有,则使用接收接口的 IP。 2(推荐) 严格选择与目标 IP 同子网的本地 IP 作为源 IP;若没有,则不发送 ARP 通告(或使用环回地址)。 典型场景:
- 多网卡服务器访问外部网络时,确保 ARP 通告的源 IP 属于目标网络所在的子网,避免其他主机误将 IP 关联到错误的网卡 MAC。
- 负载均衡或高可用集群中,防止虚拟 IP 被错误的物理网卡 MAC 通告。
配置 LVS-DS
bash
# 配置虚拟网卡
[root@lvs ~ 15:08:18]# nmcli connection add type dummy ifname dummy con-name dummy ipv4.method manual ipv4.addresses 10.1.8.100/32
[root@lvs ~ 15:10:03]# nmcli connection up dummy
# 安装 ipvsadm
yum install -y ipvsadm
touch /etc/sysconfig/ipvsadm
systemctl enable ipvsadm --now
# 清除
[root@lvs ~ 15:10:07]# ipvsadm -C
# 创建轮询负载
[root@lvs ~ 15:11:55]# ipvsadm -A -t 10.1.8.100:80 -s rr
[root@lvs ~ 15:12:12]# ipvsadm -a -t 10.1.8.100:80 -r 10.1.8.11:80
[root@lvs ~ 15:12:12]# ipvsadm -a -t 10.1.8.100:80 -r 10.1.8.12:80
[root@lvs ~ 15:12:12]# ipvsadm -a -t 10.1.8.100:80 -r 10.1.8.13:80
[root@lvs ~ 15:12:12]# ipvsadm-save -n > /etc/sysconfig/ipvsadm
# 核实配置是否生效
[root@lvs ~ 15:12:20]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.1.8.100:80 rr
-> 10.1.8.11:80 Route 1 0 0
-> 10.1.8.12:80 Route 1 0 0
-> 10.1.8.13:80 Route 1 0 0
# Forward 值为 Route,代表当前模式为 DR总结
nginx
优点
- Nginx工作在网络的7层之上,可以针对http应用做一些分流的策略,比如针对域名、目录结构。**它的正则规则比 HAProxy 更为强大和灵活,这也是它目前广泛流行的主要原因之一。**location 使用灵活,应用场合广泛。
- Nginx对网络稳定性的依赖非常小,理论上能ping通就就能进行负载功能,这个也是它的优势之一;相反LVS对网络稳定性依赖比较大。
- Nginx安装和配置比较简单,测试起来比较方便,它基本能把错误用日志打印出来。LVS的配置、测试需要比较长的时间了。
- Nginx可以通过端口检测到服务器内部的故障,比如根据服务器处理网页返回的状态码、超时等等,并且会把返回错误的请求重新提交到另一个节点。比如用户正在上传一个文件,而处理该上传的节点刚好在上传过程中出现故障,Nginx会把上传切到另一台服务器重新处理,而LVS就直接断掉了,如果是上传一个很大的文件或者很重要的文件的话,用户可能会因此而不满。
- Nginx不仅仅是一款优秀的负载均衡器/反向代理软件,它同时也是功能强大的Web应用服务器。LNMP也是近几年非常流行的web架构,在高流量的环境中稳定性也很好。
- Nginx现在作为Web反向加速缓存越来越成熟了,速度比传统的Squid服务器更快,可以考虑用其作为反向代理加速器。
- Nginx可作为中层反向代理使用,这一层面Nginx基本上无对手,唯一可以对比Nginx的就只有lighttpd了,不过lighttpd目前还没有做到Nginx完全的功能,配置也不那么清晰易读,社区资料也远远没Nginx活跃。
- Nginx也可作为静态网页和图片服务器,这方面的性能也无对手。还有Nginx社区非常活跃,第三方模块也很多。
缺点
- Nginx仅支持http、https和Email协议,这样就在适用范围上面小些,这个是它的缺点。
- 对后端服务器的健康检查,只支持通过端口来检测,不支持通过 url 来检测。
- 不支持 Session 的直接保持,但能通过 ip_hash 来解决。
haproxy
优点
-
HAProxy 支持虚拟主机。
-
HAProxy 的优点能够补充Nginx的一些缺点,比如支持Session的保持,Cookie的引导;同时支持通过获取指定的 url 来检测后端服务器的状态。
-
HAProxy跟LVS类似,本身就只是一款负载均衡软件;单纯从效率上来讲HAProxy会比Nginx有更出色的负载均衡速度,在并发处理上也是优于Nginx的。
-
HAProxy支持TCP协议的负载均衡转发,例如对后端的MySQL节点进行检测和负载均衡,大家可以用LVS+Keepalived对MySQL主从做负载均衡。
-
HAProxy 负载均衡策略非常多。
缺点
- 对http分流,弱与nginx。
lvs
LVS:使用Linux内核集群实现一个高性能、高可用的负载均衡服务器,它具有很好的可伸缩性(Scalability)、可靠性(Reliability)和可管理性(Manageability)。
优点
-
工作在4层,仅作分发之用,没有流量的产生,这个特点也决定了它在负载均衡软件里的性能最强的,对内存和cpu资源消耗比较低。
-
配置性比较低,这是一个缺点也是一个优点,因为没有可太多配置的东西,所以并不需要太多接触,大大减少了人为出错的几率。
-
工作稳定,自身有完整的双机热备方案,如LVS+Keepalived。不过我们在项目实施中用得最多的还是LVS/DR+Keepalived。
-
应用范围比较广,因为LVS工作在4层,所以它几乎可以对所有应用做负载均衡,包括http、数据库、在线聊天室等等。
缺点
- 软件本身不支持正则表达式处理,不能做动静分离;而现在许多网站在这方面都有较强的需求,这个是 Nginx/HAProxy+Keepalived 的优势所在。
- 如果是网站应用比较庞大的话,LVS/DR+Keepalived实施起来就比较复杂了,特别后面有Windows Server的机器的话,实施、配置、维护过程就比较复杂了,相对而言Nginx/HAProxy + Keepalived就简单多了。
四层和七层负载
四层负载均衡通过报文中的目标IP地址和端口,七层负载均衡通过报文中的应用层信息(URL、HTTP头部等信息),选择到达目的的内部服务器。
四层负载均衡在解包上的消耗更少,可以达到更高的性能。而七层负载算法可以通过更多的应用层信息分发请求,功能性上更强大。
七层负载均衡软件可以通过URL、Cookie和HTTP head等信息,而不仅仅是IP端口分发流量,还可以修改客户端的请求和服务器的响应(例如HTTP请求中的Header的重写),极大提升了应用系统在网络层的灵活性。
在网络中常见的SYN Flood攻击中,黑客会对同一目标大量发送SYN报文,耗尽服务器上的相关资源,以达到Denial of Service(DoS)的目的。四层模式下这些SYN攻击都会被转发到后端的服务器上;而在七层模式下这些SYN攻击在负载均衡设备上就截止,不会影响后台服务器的正常运营。另外负载均衡设备可以在七层层面设定多种策略,过滤SQL Injection等应用层面的特定攻击手段,进一步提高系统整体安全。
从性能上比较,LVS>HAProxy>Nginx;
从功能性和便利性上比较,Nginx>HAProxy>LVS。
实际应用
对于一个大型后台系统来说,LVS、HAProxy和Nginx常常可以配合使用在不同的层级:
- LVS用在接入层的最前端,承担最大规模的流量分发;
- 页面缓存用在四层和七层之间,提供缓存,加速访问;
- HAProxy负责按域名分流;
- Nginx只需要作为Web服务器负责单机内多实例的负载均衡,或负责目录结构分流和静态资源缓存等需求。
- 后台数据库采用主主、主从、一主多从读写分离架构。
下图转载 https://blog.51cto.com/sofar/1369762