最近在爬取acm会议的论文时,遇到了传说中的cloudflare 5s盾,经过一系列的不懈努力,最终完美解决了这个问题,这里来给大家分享一下我的反反爬方法。
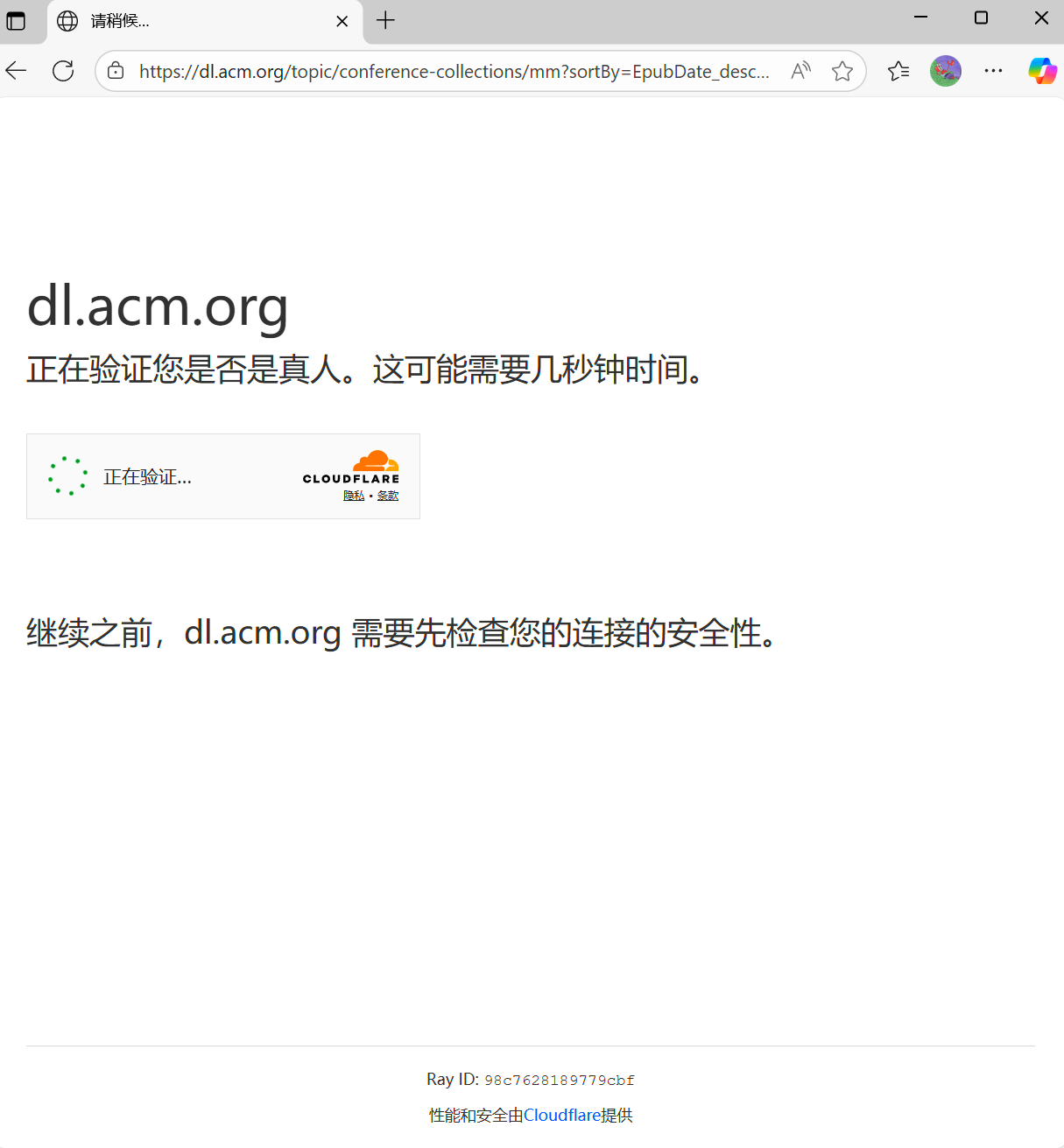
首先,这里我向acm的url发送了一个请求,携带了完整的headers与cookie,但却无济于事,返回内容是非常经典的Just a moment。

那么,发送请求这条路基本就走不通了,除非硬着头皮逆向,补环境。但是,太累了!
selenium自动化初次尝试
爬取该网页内容并不复杂,照正常操作逻辑很快就可以写好完整代码,考虑到反爬机制也是添加了许多消除自动化痕迹的argument,但最后还是无济于事,但凡切换页数超过3页数也就被检测到。
以下是完整代码,用来爬取指定会议在指定年份内的所有论文标题与下载链接
python
#acm会议论文爬取
import os
import time
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from selenium.common import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def parse_html(html):
soup=BeautifulSoup(html,'html.parser')
titles=[title.text.replace('\n','') for title in soup.find_all(class_='issue-item__title')]
link_containers=[href.find('a') for href in soup.find_all(class_='hlFld-Title')]
if link_containers:
download_Links=['https://dl.acm.org/doi/pdf'+href.get('href').replace('/doi','') for href in link_containers]
return titles,download_Links
def crawl(start:str,end:str,conference:str):
pages=1
url=f'https://dl.acm.org/topic/conference-collections/{conference}?sortBy=EpubDate_desc&AfterYear={start}&BeforeYear={end}&queryID=undefined&pageSize=50'
options=Options()
options.page_load_strategy='eager'
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_argument('--ignore-ssl-errosr')
options.add_argument('--ignore-certificate-errors')
options.add_experimental_option('excludeSwitches',['enable-automation'])
options.add_argument('--enable-parallel-downloading')
edge=webdriver.Edge(options=options)
edge.get(url)
soup=BeautifulSoup(edge.page_source,'html.parser')
total=int(soup.find(class_='hitsLength').text.replace(',',''))
pages=total//50+1 if total>50 else 1
Titles=[title.text.replace('\n','') for title in soup.find_all(class_='issue-item__title')]
Link_containers=[href.find('a') for href in soup.find_all(class_='hlFld-Title')]
if Link_containers:
Download_Links=['https://dl.acm.org/doi/pdf'+href.get('href').replace('/doi','') for href in Link_containers]
if pages>1:
for i in range(1,pages):
url=f'https://dl.acm.org/topic/conference-collections/{conference}?sortBy=EpubDate_desc&AfterYear={start}&BeforeYear={end}&queryID=undefined&startPage={i}&pageSize=50'
edge.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument',js_scripts)
edge.get(url)
titles,download_Links=parse_html(edge.page_source)
Titles.extend(titles)
Download_Links.extend(download_Links)
time.sleep(2)
edge.quit()
return Titles,Download_Links
titles,links=crawl(start='2024',end='2024',conference='mm')
print(titles)
print(links)运行效果

共计要爬取1455个内容,每页50个内容,要切换30多页,运行程序后,只是过了一会儿便弹出了验证提示,程序直接报错。
这说明我们的selenium痕迹消除的不是很彻底。仍需要进一步改善,但是,到目前为止所有可以用来消除痕迹的argument基本都用上了,如果想要彻底消除,那我们还需要来了解一下cloudflare的反爬机制。
cloudflare反爬机制
cloudflare最核心的反爬机制就是基于浏览器指纹和行为验证,说白了就是必须使用浏览器访问这个网页,使用requests发送请求被拒就卡在这一步。
当我们使用浏览器访问一个托管在cloudflare服务器上的网站时,cloudflare主要经历了这几个校验步骤:
-
JavaScript 验证
-
工作原理:当 Cloudflare 怀疑一个请求是机器人时,不会直接返回页面内容,而是返回一段复杂的 JavaScript 代码。浏览器必须成功执行这段代码,才能得到一个有效的令牌,并用这个令牌重新请求才能获取真实页面。
-
目的 :简单的爬虫(如
requests、urllib)无法执行 JS,会立刻被拦截。这能过滤掉绝大部分初级爬虫。
-
-
浏览器完整性检查
- 检测一些已知的恶意工具和垃圾邮件来源的指纹。
-
Canvas 指纹识别:通过浏览器渲染隐藏的 Canvas 图像来收集硬件和浏览器的独特特征。
-
WebGL 指纹识别:与 Canvas 类似,但通过 WebGL 渲染器来获取指纹。
-
字体列表检测:检测用户系统上安装的字体列表。
-
用户行为分析:监测鼠标移动、点击、滚动、键盘事件的速度、轨迹和模式。人类的操作是带有随机性和微小延迟的,而机器人则非常规律和迅速。
当然,Canvas指纹识别,WebGL字体列表检测这些都好说,但凡我们自动操作webdriver都可以避免这些问题。
而用户行为分析这一步取决于网站使用的cloudflare防护程度,一般而言普通的cloudflare反爬服务还不会涉及到这个level,即使有这一项,随便添加一些细微的鼠标移动就ok了。
浏览器 VS webdriver
cloudflare真正能够识别出webdriver的秘密其实还是藏在浏览器环境中,毕竟webdriver和真实浏览器还是有些差别的,他们中的大部分通过在options中添加arguments可以去除掉,但是有些痕迹相当于是永久的伤疤,无法完全去除掉,这个痕迹就是:
分别在浏览器与edgedriver的控制台中运行该代码:
javascript
const webdriverPattern = /^([a-z]){3}_.*_(Array|Promise|Symbol|JSON|Object|Proxy)$/;
const windowProperties = Object.getOwnPropertyNames(window);
const suspiciousProperties = windowProperties.filter(prop => webdriverPattern.test(prop));
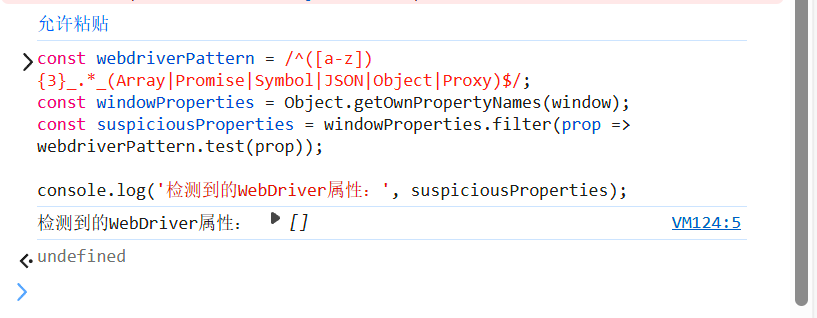
console.log('检测到的WebDriver属性:', suspiciousProperties);正常浏览器环境输出:
python
检测到的WebDriver属性:[]edgedriver环境输出:
python
检测到的WebDriver属性:
[ 'cdc_adoQpoasnfa76pfcZLmcfl_Array',
'cdc_adoQpoasnfa76pfcZLmcfl_Object',
'cdc_adoQpoasnfa76pfcZLmcfl_Promise',
'cdc_adoQpoasnfa76pfcZLmcfl_Proxy',
'cdc_adoQpoasnfa76pfcZLmcfl_Symbol',
'cdc_adoQpoasnfa76pfcZLmcfl_JSON']这些以**cdc_**前缀开头的属性是EdgeDriver在运行时注入的内部对象,使用常规方法根本无法消除,所以这也成为了cloudflare识别自动化环境的一个关键指纹。只要我们能够将这些属性去除掉,那么基本上这个问题就解决了。
消除cdc前缀
消除的思路很简单,在使用get方法向url发起请求前,让webdriver运行js代码将这些特征删除。
js代码
python
js_scripts={
'source': '''
//删除所有可能的WebDriver属性
const propertiesToDelete = [
'cdc_adoQpoasnfa76pfcZLmcfl_Array',
'cdc_adoQpoasnfa76pfcZLmcfl_Object',
'cdc_adoQpoasnfa76pfcZLmcfl_Promise',
'cdc_adoQpoasnfa76pfcZLmcfl_Proxy',
'cdc_adoQpoasnfa76pfcZLmcfl_Symbol',
'cdc_adoQpoasnfa76pfcZLmcfl_JSON',
'cdc_adoQpoasnfa76pfcZLmcfl_Array',
'cdc_adoQpoasnfa76pfcZLmcfl_Window'
];
propertiesToDelete.forEach(prop => {
try {
delete window[prop];
} catch (e) {}
});
// 隐藏navigator.webdriver
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined,
configurable: true
});
if (window.chrome) {
delete window.chrome.runtime;
Object.defineProperty(window, 'chrome', {
get: () => undefined,
configurable: true
});
}
'''
}添加到selenium中
python
#acm会议论文爬取
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from selenium.common import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
#completely消除webdriver
js_scripts={
'source': '''
//删除所有可能的WebDriver属性
const propertiesToDelete = [
'cdc_adoQpoasnfa76pfcZLmcfl_Array',
'cdc_adoQpoasnfa76pfcZLmcfl_Object',
'cdc_adoQpoasnfa76pfcZLmcfl_Promise',
'cdc_adoQpoasnfa76pfcZLmcfl_Proxy',
'cdc_adoQpoasnfa76pfcZLmcfl_Symbol',
'cdc_adoQpoasnfa76pfcZLmcfl_JSON',
'cdc_adoQpoasnfa76pfcZLmcfl_Array',
'cdc_adoQpoasnfa76pfcZLmcfl_Window'
];
propertiesToDelete.forEach(prop => {
try {
delete window[prop];
} catch (e) {}
});
// 隐藏navigator.webdriver
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined,
configurable: true
});
if (window.chrome) {
delete window.chrome.runtime;
Object.defineProperty(window, 'chrome', {
get: () => undefined,
configurable: true
});
}
'''
}
def crawl(start:str,end:str,conference:str):
pages=1
url=f'https://dl.acm.org/topic/conference-collections/{conference}?sortBy=EpubDate_desc&AfterYear={start}&BeforeYear={end}&queryID=undefined&pageSize=50'
options=Options()
options.page_load_strategy='eager'
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_argument('--ignore-ssl-errosr')
options.add_argument('--ignore-certificate-errors')
options.add_experimental_option('excludeSwitches',['enable-automation'])
options.add_argument('--enable-parallel-downloading')
edge=webdriver.Edge(options=options)
edge.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument',js_scripts)
edge.get(url)
将上述js_scripts代码通过execute_cdp_cmd函数传入到webdriver对象运行后便可以彻底删除前边说到的cdc前缀。注意,execute_cdp_cmd函数一定要在get方法前!
测试效果
运行代码,edgedriver启动后,打开控制台将检测代码粘贴运行,发现所有的cfc前缀特征已被彻底删除。