00 开篇词 为什么你要学习etcd
开门见山,今天我想和你聊聊为什么要学习etcd。随着Kubernetes成为容器编排领域霸主,etcd也越来越火热,越来越多的软件工程师使用etcd去解决各类业务场景中遇到的痛点。你知道吗?etcd的GitHub star数已超过34.2K,它的应用场景相当广泛,从服务发现到分布式锁,从配置存储到分布式协调等等。可以说,etcd已经成为了云原生和分布式系统的存储基石。
另外,etcd作为最热门的云原生存储之一,在腾讯、阿里、Google、AWS、美团、字节跳动、拼多多、Shopee、明源云等公司都有大量的应用,覆盖的业务可不仅仅是Kubernetes相关的各类容器产品,更有视频、推荐、安全、游戏、存储、集群调度等核心业务。
我想为你解决哪些问题?
在工作和参与etcd社区贡献的过程中,我经常会收到各类问题咨询,同时自己也经历了各种问题。我相信你在使用Kubernetes、etcd的过程中,很可能也会遇到下面这些典型问题:
- etcd Watch机制能保证事件不丢吗?(原理类)
- 哪些因素会导致你的集群Leader发生切换? (稳定性类)
- 为什么基于Raft实现的etcd还可能会出现数据不一致?(一致性类)
- 为什么你删除了大量数据,db大小不减少?为何etcd社区建议db大小不要超过8G?(db大小类)
- 为什么集群各节点磁盘I/O延时很低,写请求也会超时?(延时类)
- 为什么你只存储了1个几百KB的key/value, etcd进程却可能耗费数G内存? (内存类)
- 当你在一个namespace下创建了数万个Pod/CRD资源时,同时频繁通过标签去查询指定Pod/CRD资源时,APIServer和etcd为什么扛不住?(最佳实践类)
当然,你在学习和使用etcd、Kubernetes过程中遇到的问题肯定远远不止这些,下面我用思维导图给你总结了更多类似问题,你可以对照自身的经历去看一下。
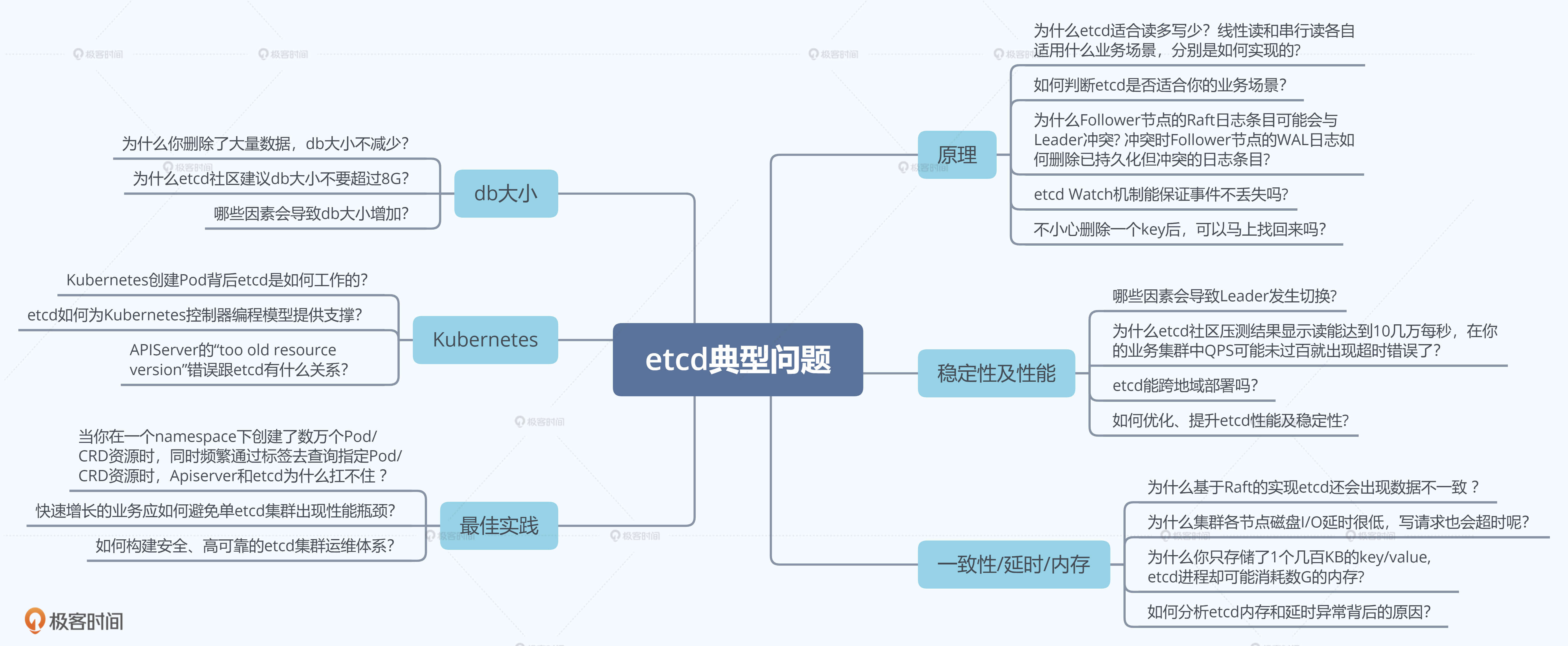
这门课就是为了帮助你解决这些问题而生。不过你可能会想,你能把这些东西都讲明白么?我先和你聊聊我的个人etcd经历,你就知道我为什么有自信能带你学好etcd了。
我和etcd的那些事
本科毕业后,我通过校招加入了腾讯。不到一年的时间,我就主导完成了一个亿级用户的业务核心存储平滑迁移任务。
在2015到2017的这两年时间里,为了满足业务大量的Redis诉求,我基于Redis/Codis构建了大规模的排行榜和Redis集群平台服务,支撑了公司的多个重要业务。在这期间,我积累了大量的NoSQL数据库知识与经验,为后面工作转岗到To B,负责Kubernetes的元数据存储etcd奠定了良好的基础。
2017年后,我就开始接触Docker和Kubernetes,并通过Kubernetes来解决大规模Redis集群的治理问题,提升服务的可用性、降低运维成本。
2018年,我转岗到了腾讯云,负责Kubernetes集群存储etcd治理工作。我主导构建的云原生etcd平台,支持自动化的集群管理、调度、迁移、监控、巡检、备份,成功解决了集群大规模增长过程中的各类etcd稳定性问题,支撑了万级的Kubernetes和etcd集群。
etcd平台从解决Kubernetes etcd稳定性问题,到为各类云原生产品提供etcd基础服务,再到保障开箱即用的腾讯云etcd产品化服务,它发挥着重要作用。在这个过程中,我也见证了越来越多的软件工程师加入etcd的阵营,越来越多的产品使用etcd。目前,etcd作为腾讯众多产品的基础设施,服务用户已达数亿。
同时,我也遇到了很多问题,从内存泄露到数据不一致,从节点crash到性能慢,再到死锁、OOM等稳定性问题等等。最令我记忆犹新的是,我和小伙伴王超凡通过混沌工程发现并修复了多个数据不一致Bug,其中一个Bug已经存在近3年之久,而且很严重,重启就可能会触发数据不一致。
从解决类似上面的棘手Bug到提交稳定性、性能优化PR,从提交QoS特性设计方案、POC到给新的contributor review PR,通过一点点的积累,大量周末、凌晨时间的付出,我成为了2020年etcd社区的全球Top3活跃贡献者,与Google、AWS、阿里巴巴的小伙伴们,一起推动etcd项目越来越好,服务于全球开发者。
总结来说的话,过去几年我一直在与Redis、etcd打交道,一线的经历、解决的问题都让我收获良多,所以我也非常有自信能把这些经验都交付给你。
在业务实践方面,我成功解决过众多大规模业务增长过程中,遇到的存储稳定性、可扩展性等痛点,积累了丰富的理论知识、大规模集群的实战、治理经验,能直接帮助到你今后的工作。
另外,在etcd开源项目方面,我深度参与etcd开源项目的贡献经历,让我可以从开发者的视角,为你分析问题、梳理最佳实践、解读特性设计方案、阐述社区未来演进方向等等,帮助你深度理解etcd以及分布式服务。
你应该怎么学etcd?
在我看来,etcd学习其实可以分为大中小三个目标。最大的目标我当然是希望你能够用最低的学习成本,掌握etcd核心原理与最佳实践,让etcd为你所用,帮助你解决业务过程中的各类痛点,在工作中少踩坑、少交学费,多升职、多涨薪。
但是这个大的目标怎么实现呢?
我的答案是使用拆解法。下面我给你提出了学习这个专栏的一些中等大小目标,希望你能带着这些目标进行学习,每过一段时间,回过头来看看,这些目标实现了多少?
首先,你能知道什么是etcd,了解它的基本读写原理、核心特性和能解决什么问题。
然后,在使用etcd解决各类业务场景需求时,能独立判断etcd是否适合你的业务场景,并能设计出良好的存储结构,避免expensive request。
其次,在使用Kubernetes的过程中,你能清晰地知道你的每个操作背后的etcd是如何工作的,并遵循Kubernetes/etcd最佳实践,让你的Kubernetes集群跑得更快更稳。
接着,在运维etcd集群的时候,你能知道etcd集群核心监控指标,了解常见的坑,制定良好的巡检、监控策略,及时发现、规避问题,避免事故的产生。
最后,当你遇到etcd问题时,能自己分析为什么会出现这样的错误,并知道如何解决,甚至给社区提PR优化,做到知其然知其所以然。
做到以上五个目标其实也并不容易,别着急,我们接着往下拆分。为了让你实现以上五个目标,我把专栏分为了基础和实践两大主线。每个主线里都有一个一个的小目标,我们逐个攻破就容易多了。
基础篇主线是为了帮助你建立起对etcd的整体认知,搞懂读写请求、各个核心特性背后的原理,为我们后面的实践篇打下基础。
基础篇的学习也是一个中小型分布式存储系统从0到1的实现案例解读,学习它你收获的不仅仅是etcd,更是如何构建分布式存储系统的理论知识。
我把基础篇分为了以下的学习小目标:
- etcd基础架构。通过为你梳理etcd前世今生、分析etcd读写流程,帮助你建立起对etcd的整体认知,了解一个分布式存储系统的基本模型、设计思想。
- Raft算法。通过为你介绍Raft算法在etcd中是如何工作的,帮助你了解etcd高可用、高可靠背后的核心原理。
- 鉴权模块。通过介绍etcd的鉴权、授权体系,带你了解etcd是如何保护你的数据安全,以及各个鉴权机制的优缺点。
- 租约模块。介绍etcd租约特性的实现,帮助你搞懂如何检测一个进程的存活性,为什么它可以用于Leader选举中。
- MVCC/Watch模块。通过这两个模块帮助你搞懂Kubernetes控制器编程模型背后的原理。
在介绍etcd原理的过程中,我也会从更上层的角度,为你解读分布式系统存储系统的核心技术难点是什么,常见的解决方案有哪些,以及为什么etcd要这样设计、实现。让你对整个分布式系统有更深层次的理解,明白不同存储系统只是在面对各自的业务场景的时候,选择了合适的技术方案,让你从本质上去理解分布式存储系统要解决的核心问题基本是一致的。
当然基础篇讲的远不止这些,关于基础篇的更多内容,你可以参考下面的etcd基础篇思维导图:
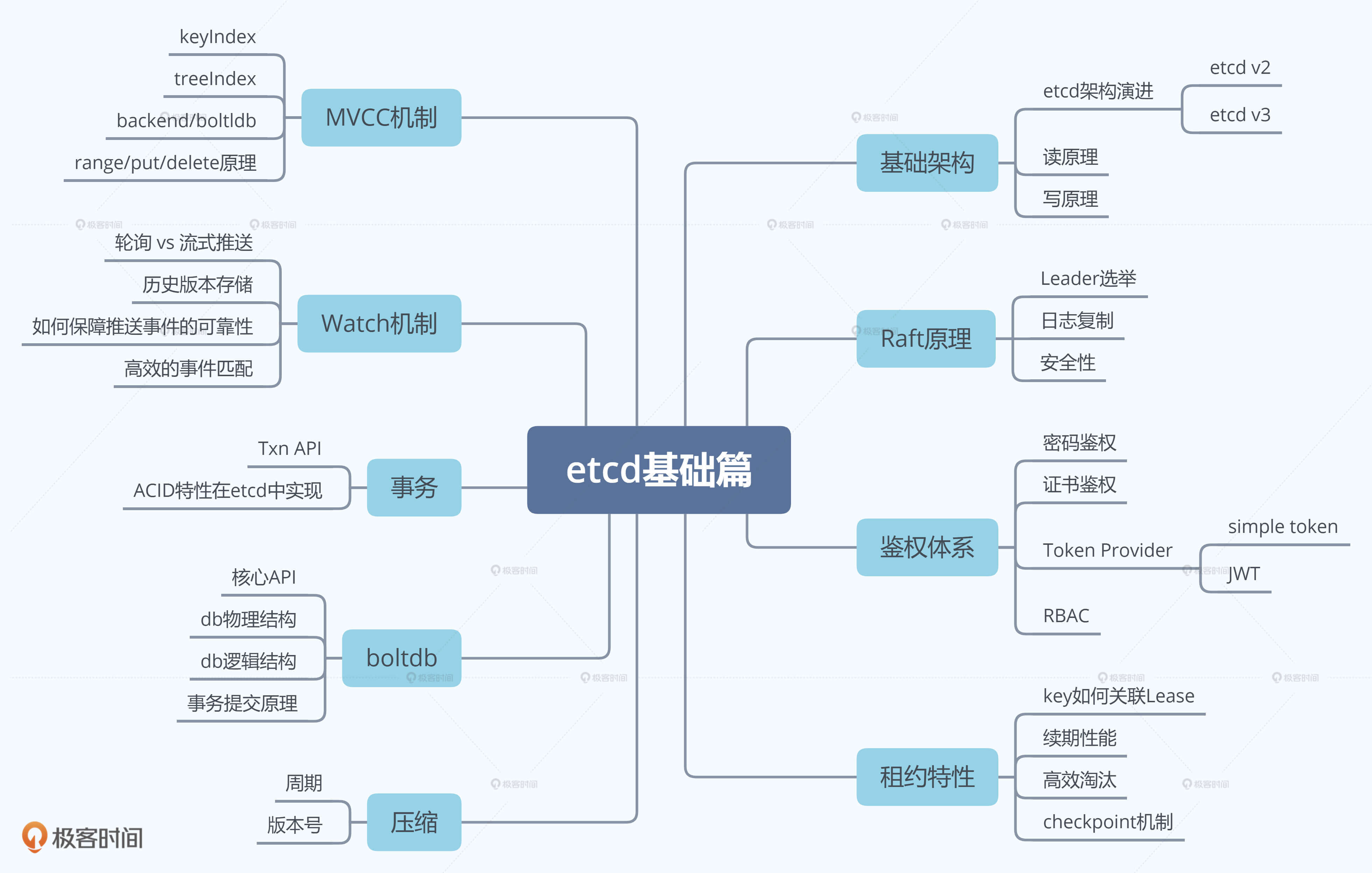
通过基础篇掌握好etcd核心模块原理后,实践篇我将为你解读实际使用etcd时,可能会遇到的各种问题,帮助你提前避坑、遇到类似问题时能独立分析、解决。
我把实践篇分为以下的学习小目标:
- 问题篇。为你分析etcd使用过程中的各类典型问题,和你细聊各种异常现象背后的原理、最佳实践。
- 性能优化篇。通过读写链路的分析,为你梳理可能影响etcd性能的每一个瓶颈。
- 实战篇。带你从0到1亲手参与构建一个简易的分布式KV数据库,进一步提升你对分布式存储系统的认知。
- Kubernetes实践篇。为你分析etcd在Kubernetes中的应用,让你对Kubernetes原理有更深层次的理解。
- etcd应用篇。介绍etcd在分布式锁、配置系统、服务发现场景中的应用。
更多实践篇内容你可以参考下面的思维导图:
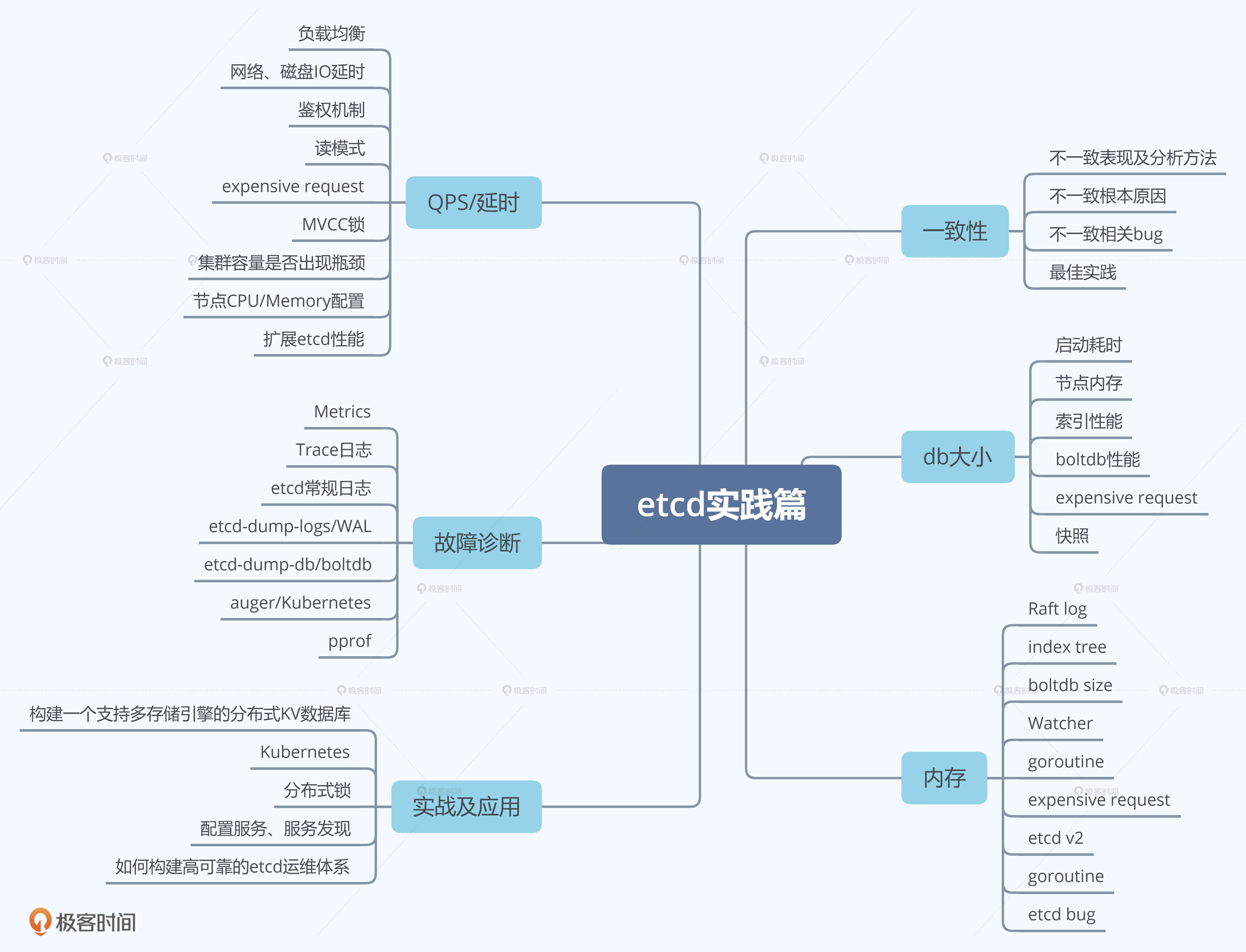
这样一来,我们的学习目标就比较明确了。最终目标是让etcd为你所用,少踩坑、多升职加薪;而为了实现这个目标,我们需要从多方面提升自己对etcd的掌控能力,也就是实现中等目标;但进阶的难度还是比较大的,所以我们需要把一个个小目标当作基石(也就是每一节课的知识点学习),来达成个人能力的提升。
现在我们不妨就带着这些目标,共同开启etcd的学习之旅吧!
01 etcd的前世今生:为什么Kubernetes使用etcd?
让我们一起穿越回2013年,看看etcd最初是在什么业务场景下被设计出来的?
2013年,有一个叫CoreOS的创业团队,他们构建了一个产品,Container Linux,它是一个开源、轻量级的操作系统,侧重自动化、快速部署应用服务,并要求应用程序都在容器中运行,同时提供集群化的管理方案,用户管理服务就像单机一样方便。
他们希望在重启任意一节点的时候,用户的服务不会因此而宕机,导致无法提供服务,因此需要运行多个副本。但是多个副本之间如何协调,如何避免变更的时候所有副本不可用呢?
为了解决这个问题,CoreOS团队需要一个协调服务来存储服务配置信息、提供分布式锁等能力。怎么办呢?当然是分析业务场景、痛点、核心目标,然后是基于目标进行方案选型,评估是选择社区开源方案还是自己造轮子。这其实就是我们遇到棘手问题时的通用解决思路,CoreOS团队同样如此。
假设你是CoreOS团队成员,你认为在这样的业务场景下,理想中的解决方案应满足哪些目标呢?
如果你有过一些开发经验,应该能想到一些关键点了,我根据自己的经验来总结一下,一个协调服务,理想状态下大概需要满足以下五个目标:
- 可用性角度:高可用。协调服务作为集群的控制面存储,它保存了各个服务的部署、运行信息。若它故障,可能会导致集群无法变更、服务副本数无法协调。业务服务若此时出现故障,无法创建新的副本,可能会影响用户数据面。
- 数据一致性角度:提供读取"最新"数据的机制。既然协调服务必须具备高可用的目标,就必然不能存在单点故障(single point of failure),而多节点又引入了新的问题,即多个节点之间的数据一致性如何保障?比如一个集群3个节点A、B、C,从节点A、B获取服务镜像版本是新的,但节点C因为磁盘 I/O异常导致数据更新缓慢,若控制端通过C节点获取数据,那么可能会导致读取到过期数据,服务镜像无法及时更新。
- **容量角度:低容量、仅存储关键元数据配置。**协调服务保存的仅仅是服务、节点的配置信息(属于控制面配置),而不是与用户相关的数据。所以存储上不需要考虑数据分片,无需过度设计。
- 功能:增删改查,监听数据变化的机制。协调服务保存了服务的状态信息,若服务有变更或异常,相比控制端定时去轮询检查一个个服务状态,若能快速推送变更事件给控制端,则可提升服务可用性、减少协调服务不必要的性能开销。
- **运维复杂度:可维护性。**在分布式系统中往往会遇到硬件Bug、软件Bug、人为操作错误导致节点宕机,以及新增、替换节点等运维场景,都需要对协调服务成员进行变更。若能提供API实现平滑地变更成员节点信息,就可以大大降低运维复杂度,减少运维成本,同时可避免因人工变更不规范可能导致的服务异常。
了解完理想中的解决方案目标,我们再来看CoreOS团队当时为什么选择了从0到1开发一个新的协调服务呢?
如果使用开源软件,当时其实是有ZooKeeper的,但是他们为什么不用ZooKeeper呢?我们来分析一下。
从高可用性、数据一致性、功能这三个角度来说,ZooKeeper是满足CoreOS诉求的。然而当时的ZooKeeper不支持通过API安全地变更成员,需要人工修改一个个节点的配置,并重启进程。
若变更姿势不正确,则有可能出现脑裂等严重故障。适配云环境、可平滑调整集群规模、在线变更运行时配置是CoreOS的期望目标,而ZooKeeper在这块的可维护成本相对较高。
其次ZooKeeper是用 Java 编写的,部署较繁琐,占用较多的内存资源,同时ZooKeeper RPC的序列化机制用的是Jute,自己实现的RPC API。无法使用curl之类的常用工具与之互动,CoreOS期望使用比较简单的HTTP + JSON。
因此,CoreOS决定自己造轮子,那CoreOS团队是如何根据系统目标进行技术方案选型的呢?
etcd v1和v2诞生
首先我们来看服务高可用及数据一致性。前面我们提到单副本存在单点故障,而多副本又引入数据一致性问题。
因此为了解决数据一致性问题,需要引入一个共识算法,确保各节点数据一致性,并可容忍一定节点故障。常见的共识算法有Paxos、ZAB、Raft等。CoreOS团队选择了易理解实现的Raft算法,它将复杂的一致性问题分解成Leader选举、日志同步、安全性三个相对独立的子问题,只要集群一半以上节点存活就可提供服务,具备良好的可用性。
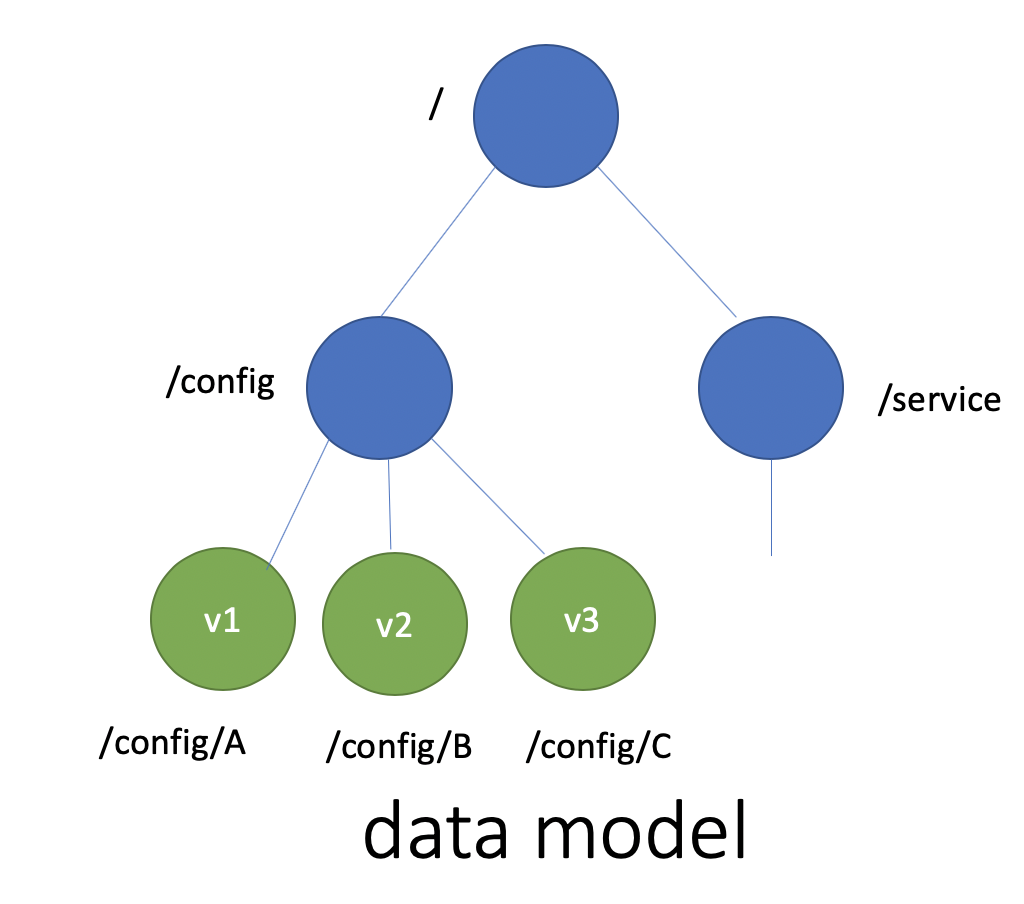
其次我们再来看数据模型(Data Model)和API。数据模型参考了ZooKeeper,使用的是基于目录的层次模式。API相比ZooKeeper来说,使用了简单、易用的REST API,提供了常用的Get/Set/Delete/Watch等API,实现对key-value数据的查询、更新、删除、监听等操作。
key-value存储引擎上,ZooKeeper使用的是Concurrent HashMap,而etcd使用的是则是简单内存树,它的节点数据结构精简后如下,含节点路径、值、孩子节点信息。这是一个典型的低容量设计,数据全放在内存,无需考虑数据分片,只能保存key的最新版本,简单易实现。
c
type node struct {
Path string //节点路径
Parent *node //关联父亲节点
Value string //key的value值
ExpireTime time.Time //过期时间
Children map[string]*node //此节点的孩子节点
}最后我们再来看可维护性。Raft算法提供了成员变更算法,可基于此实现成员在线、安全变更,同时此协调服务使用Go语言编写,无依赖,部署简单。
基于以上技术方案和架构图,CoreOS团队在2013年8月对外发布了第一个测试版本v0.1,API v1版本,命名为etcd。
那么etcd这个名字是怎么来的呢?其实它源于两个方面,unix的"/etc"文件夹和分布式系统("D"istribute system)的D,组合在一起表示etcd是用于存储分布式配置的信息存储服务。
v0.1版本实现了简单的HTTP Get/Set/Delete/Watch API,但读数据一致性无法保证。v0.2版本,支持通过指定consistent模式,从Leader读取数据,并将Test And Set机制修正为CAS(Compare And Swap),解决原子更新的问题,同时发布了新的API版本v2,这就是大家熟悉的etcd v2版本,第一个非stable版本。
下面,我用一幅时间轴图,给你总结一下etcd v1/v2关键特性。
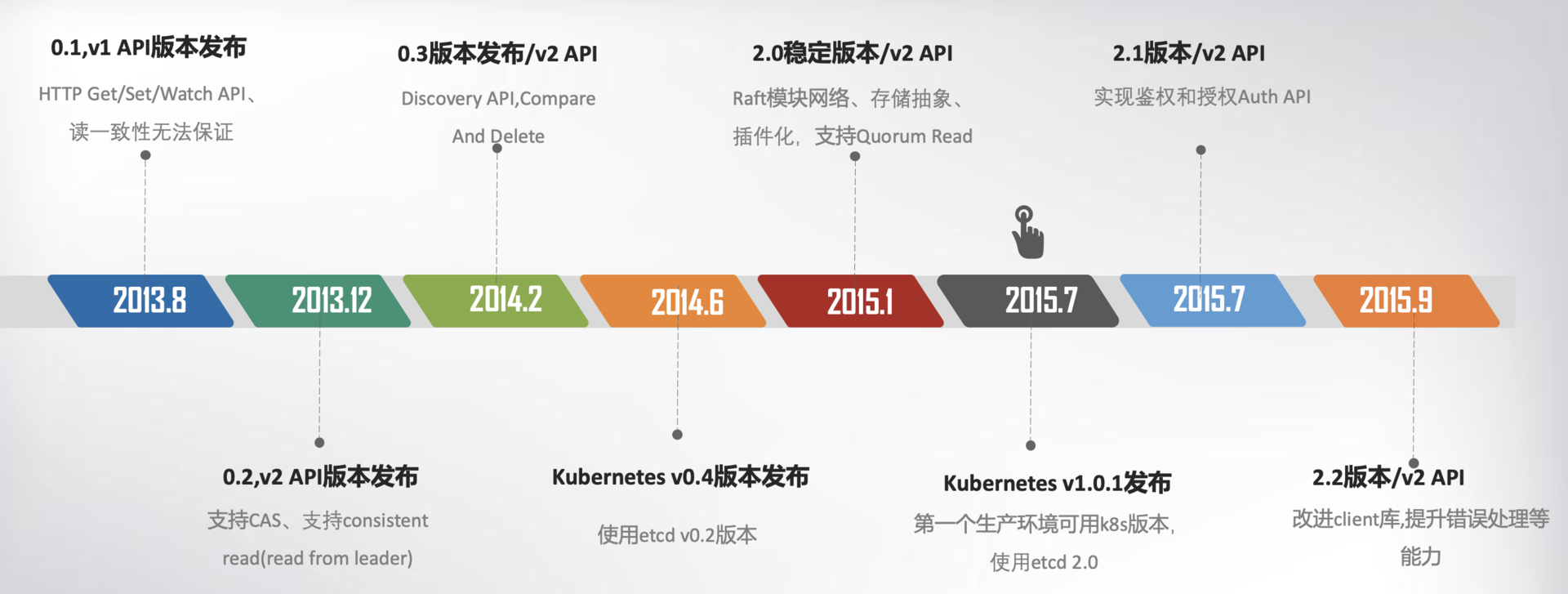
为什么Kubernetes使用etcd?
这张图里,我特别标注出了Kubernetes的发布时间点,这个非常关键。我们必须先来说说这个事儿,也就是Kubernetes和etcd的故事。
2014年6月,Google的Kubernetes项目诞生了,我们前面所讨论到Go语言编写、etcd高可用、Watch机制、CAS、TTL等特性正是Kubernetes所需要的,它早期的0.4版本,使用的正是etcd v0.2版本。
Kubernetes是如何使用etcd v2这些特性的呢?举几个简单小例子。
当你使用Kubernetes声明式API部署服务的时候,Kubernetes的控制器通过etcd Watch机制,会实时监听资源变化事件,对比实际状态与期望状态是否一致,并采取协调动作使其一致。Kubernetes更新数据的时候,通过CAS机制保证并发场景下的原子更新,并通过对key设置TTL来存储Event事件,提升Kubernetes集群的可观测性,基于TTL特性,Event事件key到期后可自动删除。
Kubernetes项目使用etcd,除了技术因素也与当时的商业竞争有关。CoreOS是Kubernetes容器生态圈的核心成员之一。
当时Docker容器浪潮正席卷整个开源技术社区,CoreOS也将容器集成到自家产品中。一开始与Docker公司还是合作伙伴,然而Docker公司不断强化Docker的PaaS平台能力,强势控制Docker社区,这与CoreOS核心商业战略出现了冲突,也损害了Google、RedHat等厂商的利益。
最终CoreOS与Docker分道扬镳,并推出了rkt项目来对抗Docker,然而此时Docker已深入人心,CoreOS被Docker全面压制。
以Google、RedHat为首的阵营,基于Google多年的大规模容器管理系统Borg经验,结合社区的建议和实践,构建以Kubernetes为核心的容器生态圈。相比Docker的垄断、独裁,Kubernetes社区推行的是民主、开放原则,Kubernetes每一层都可以通过插件化扩展,在Google、RedHat的带领下不断发展壮大,etcd也进入了快速发展期。
在2015年1月,CoreOS发布了etcd第一个稳定版本2.0,支持了quorum read,提供了严格的线性一致性读能力。7月,基于etcd 2.0的Kubernetes第一个生产环境可用版本v1.0.1发布了,Kubernetes开始了新的里程碑的发展。
etcd v2在社区获得了广泛关注,GitHub star数在2015年6月就高达6000+,超过500个项目使用,被广泛应用于配置存储、服务发现、主备选举等场景。
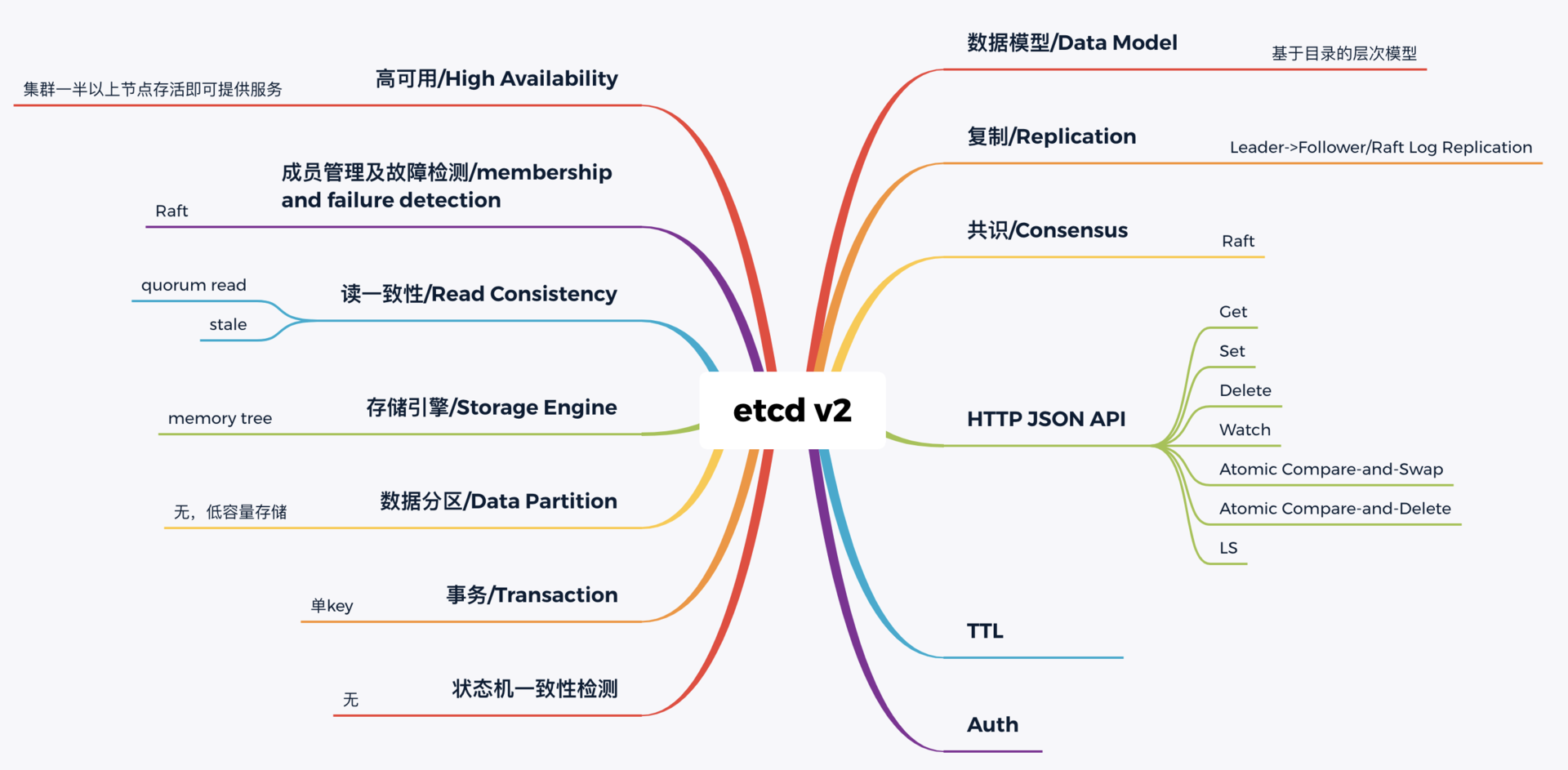
下图我从构建分布式系统的核心要素角度,给你总结了etcd v2核心技术点。无论是NoSQL存储还是SQL存储、文档存储,其实大家要解决的问题都是类似的,基本就是图中总结的数据模型、复制、共识算法、API、事务、一致性、成员故障检测等方面。
希望通过此图帮助你了解从0到1如何构建、学习一个分布式系统,要解决哪些技术点,在心中有个初步认识,后面的课程中我会再深入介绍。
etcd v3诞生
然而随着Kubernetes项目不断发展,v2版本的瓶颈和缺陷逐渐暴露,遇到了若干性能和稳定性问题,Kubernetes社区呼吁支持新的存储、批评etcd不可靠的声音开始不断出现。
具体有哪些问题呢?我给你总结了如下图:
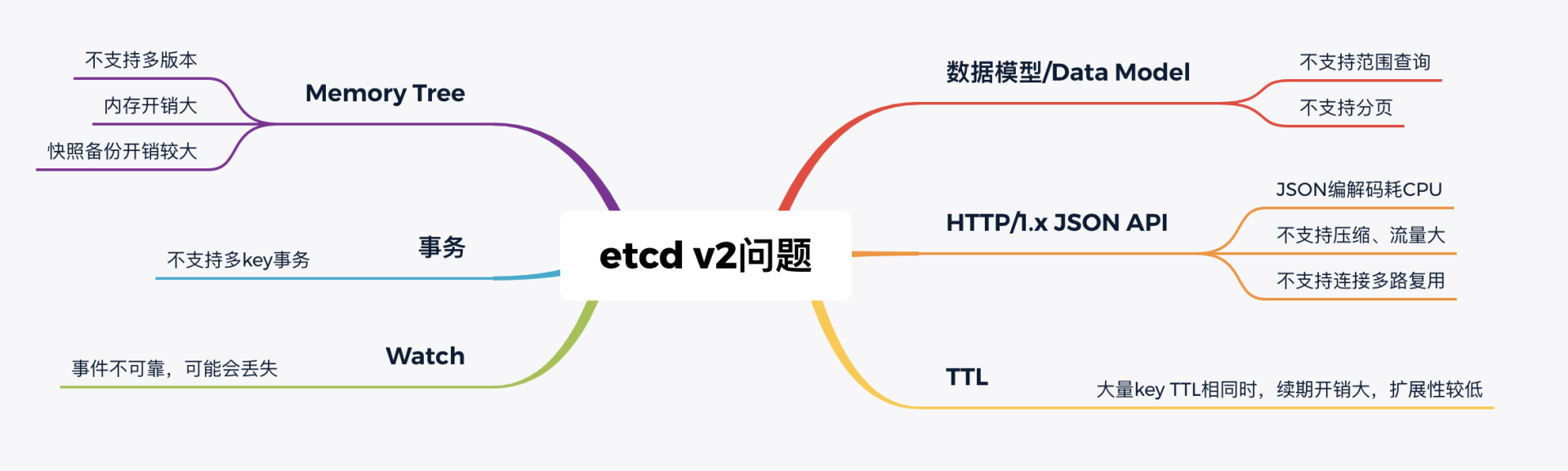
下面我分别从功能局限性、Watch事件的可靠性、性能、内存开销来分别给你剖析etcd v2的问题。
首先是**功能局限性问题。**它主要是指etcd v2不支持范围和分页查询、不支持多key事务。
第一,etcd v2不支持范围查询和分页。分页对于数据较多的场景是必不可少的。在Kubernetes中,在集群规模增大后,Pod、Event等资源可能会出现数千个以上,但是etcd v2不支持分页,不支持范围查询,大包等expensive request会导致严重的性能乃至雪崩问题。
第二,etcd v2不支持多key事务。在实际转账等业务场景中,往往我们需要在一个事务中同时更新多个key。
然后是Watch机制可靠性问题。Kubernetes项目严重依赖etcd Watch机制,然而etcd v2是内存型、不支持保存key历史版本的数据库,只在内存中使用滑动窗口保存了最近的1000条变更事件,当etcd server写请求较多、网络波动时等场景,很容易出现事件丢失问题,进而又触发client数据全量拉取,产生大量expensive request,甚至导致etcd雪崩。
其次是性能瓶颈问题。etcd v2早期使用了简单、易调试的HTTP/1.x API,但是随着Kubernetes支撑的集群规模越来越大,HTTP/1.x协议的瓶颈逐渐暴露出来。比如集群规模大时,由于HTTP/1.x协议没有压缩机制,批量拉取较多Pod时容易导致APIServer和etcd出现CPU高负载、OOM、丢包等问题。
另一方面,etcd v2 client会通过HTTP长连接轮询Watch事件,当watcher较多的时候,因HTTP/1.x不支持多路复用,会创建大量的连接,消耗server端过多的socket和内存资源。
同时etcd v2支持为每个key设置TTL过期时间,client为了防止key的TTL过期后被删除,需要周期性刷新key的TTL。
实际业务中很有可能若干key拥有相同的TTL,可是在etcd v2中,即使大量key TTL一样,你也需要分别为每个key发起续期操作,当key较多的时候,这会显著增加集群负载、导致集群性能显著下降。
最后是**内存开销问题。**etcd v2在内存维护了一颗树来保存所有节点key及value。在数据量场景略大的场景,如配置项较多、存储了大量Kubernetes Events, 它会导致较大的内存开销,同时etcd需要定时把全量内存树持久化到磁盘。这会消耗大量的CPU和磁盘 I/O资源,对系统的稳定性造成一定影响。
为什么etcd v2有以上若干问题,Consul等其他竞品依然没有被Kubernetes支持呢?
一方面当时包括Consul在内,没有一个开源项目是十全十美完全满足Kubernetes需求。而CoreOS团队一直在聆听社区的声音并积极改进,解决社区的痛点。用户吐槽etcd不稳定,他们就设计实现自动化的测试方案,模拟、注入各类故障场景,及时发现修复Bug,以提升etcd稳定性。
另一方面,用户吐槽性能问题,针对etcd v2各种先天性缺陷问题,他们从2015年就开始设计、实现新一代etcd v3方案去解决以上痛点,并积极参与Kubernetes项目,负责etcd v2到v3的存储引擎切换,推动Kubernetes项目的前进。同时,设计开发通用压测工具、输出Consul、ZooKeeper、etcd性能测试报告,证明etcd的优越性。
etcd v3就是为了解决以上稳定性、扩展性、性能问题而诞生的。
在内存开销、Watch事件可靠性、功能局限上,它通过引入B-tree、boltdb实现一个MVCC数据库,数据模型从层次型目录结构改成扁平的key-value,提供稳定可靠的事件通知,实现了事务,支持多key原子更新,同时基于boltdb的持久化存储,显著降低了etcd的内存占用、避免了etcd v2定期生成快照时的昂贵的资源开销。
性能上,首先etcd v3使用了gRPC API,使用protobuf定义消息,消息编解码性能相比JSON超过2倍以上,并通过HTTP/2.0多路复用机制,减少了大量watcher等场景下的连接数。
其次使用Lease优化TTL机制,每个Lease具有一个TTL,相同的TTL的key关联一个Lease,Lease过期的时候自动删除相关联的所有key,不再需要为每个key单独续期。
最后是etcd v3支持范围、分页查询,可避免大包等expensive request。
2016年6月,etcd 3.0诞生,随后Kubernetes 1.6发布,默认启用etcd v3,助力Kubernetes支撑5000节点集群规模。
下面的时间轴图,我给你总结了etcd3重要特性及版本发布时间。从图中你可以看出,从3.0到未来的3.5,更稳、更快是etcd的追求目标。
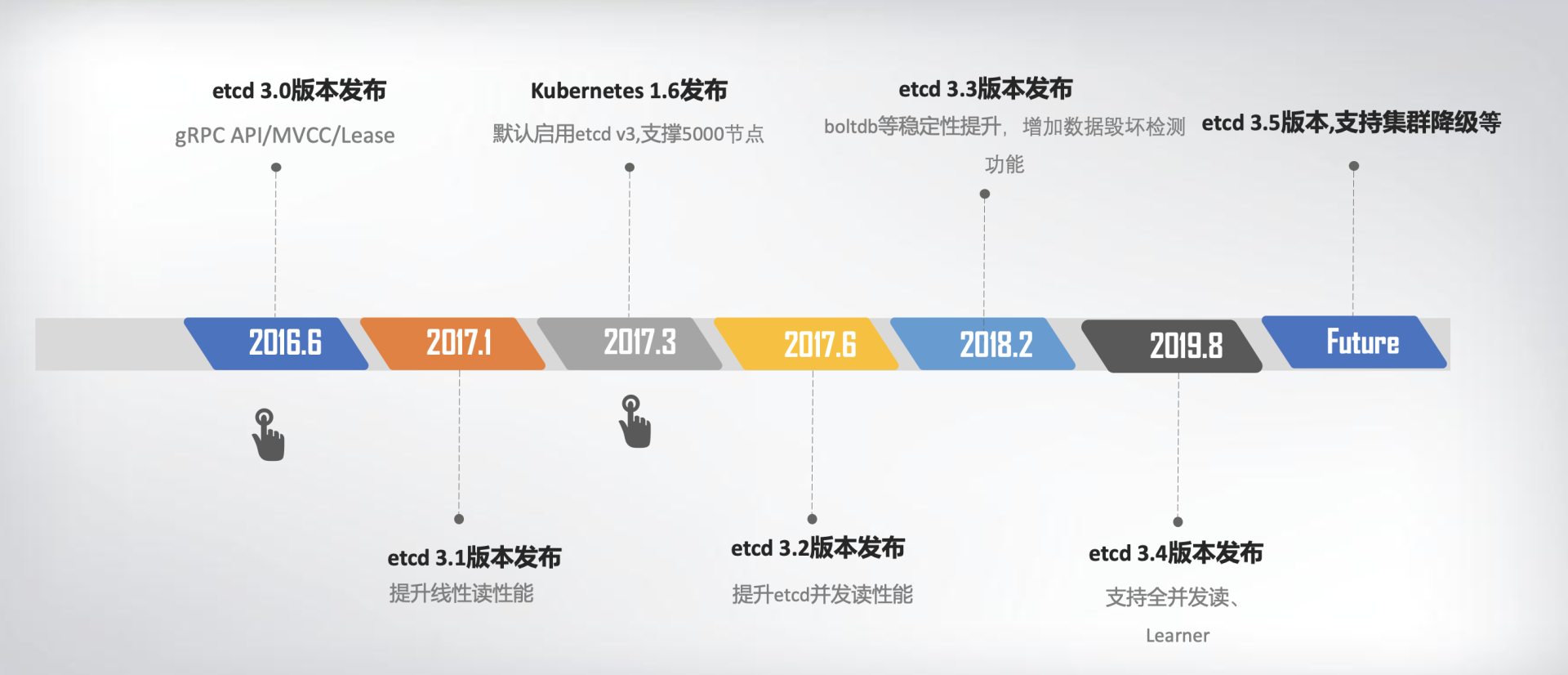
从2013年发布第一个版本v0.1到今天的3.5.0-pre,从v2到v3,etcd走过了7年的历程,etcd的稳定性、扩展性、性能不断提升。
发展到今天,在GitHub上star数超过34K。在Kubernetes的业务场景磨炼下它不断成长,走向稳定和成熟,成为技术圈众所周知的开源产品,而v3方案的发布,也标志着etcd进入了技术成熟期,成为云原生时代的首选元数据存储产品。
小结
最后我们来小结下今天的内容,我们从如下几个方面介绍了etcd的前世今生,并在过程中详细解读了为什么Kubernetes使用etcd:
- etcd诞生背景, etcd v2源自CoreOS团队遇到的服务协调问题。
- etcd目标,我们通过实际业务场景分析,得到理想中的协调服务核心目标:高可用、数据一致性、Watch、良好的可维护性等。而在CoreOS团队看来,高可用、可维护性、适配云、简单的API、良好的性能对他们而言是非常重要的,ZooKeeper无法满足所有诉求,因此决定自己构建一个分布式存储服务。
- 介绍了v2基于目录的层级数据模型和API,并从分布式系统的角度给你详细总结了etcd v2技术点。etcd的高可用、Watch机制与Kubernetes期望中的元数据存储是匹配的。etcd v2在Kubernetes的带动下,获得了广泛的应用,但也出现若干性能和稳定性、功能不足问题,无法满足Kubernetes项目发展的需求。
- CoreOS团队未雨绸缪,从问题萌芽时期就开始构建下一代etcd v3存储模型,分别从性能、稳定性、功能上等成功解决了Kubernetes发展过程中遇到的瓶颈,也捍卫住了作为Kubernetes存储组件的地位。
希望通过今天的介绍, 让你对etcd为什么有v2和v3两个大版本,etcd如何从HTTP/1.x API到gRPC API、单版本数据库到多版本数据库、内存树到boltdb、TTL到Lease、单key原子更新到支持多key事务的演进过程有个清晰了解。希望你能有所收获,在后续的课程中我会和你深入讨论各个模块的细节。
思考题
最后,我给你留了一个思考题。分享一下在你的项目中,你主要使用的是哪个etcd版本来解决什么问题呢?使用的etcd v2 API还是v3 API呢?在这过程中是否遇到过什么问题?
02 基础架构:etcd一个读请求是如何执行的?
在上一讲中,我和你分享了etcd的前世今生,同时也为你重点介绍了etcd v2的不足之处,以及我们现在广泛使用etcd v3的原因。
今天,我想跟你介绍一下etcd v3的基础架构,让你从整体上对etcd有一个初步的了解,心中能构筑起一幅etcd模块全景图。这样,在你遇到诸如"Kubernetes在执行kubectl get pod时,etcd如何获取到最新的数据返回给APIServer?"等流程架构问题时,就能知道各个模块由上至下是如何紧密协作的。
即便是遇到请求报错,你也能通过顶层的模块全景图,推测出请求流程究竟在什么模块出现了问题。
基础架构
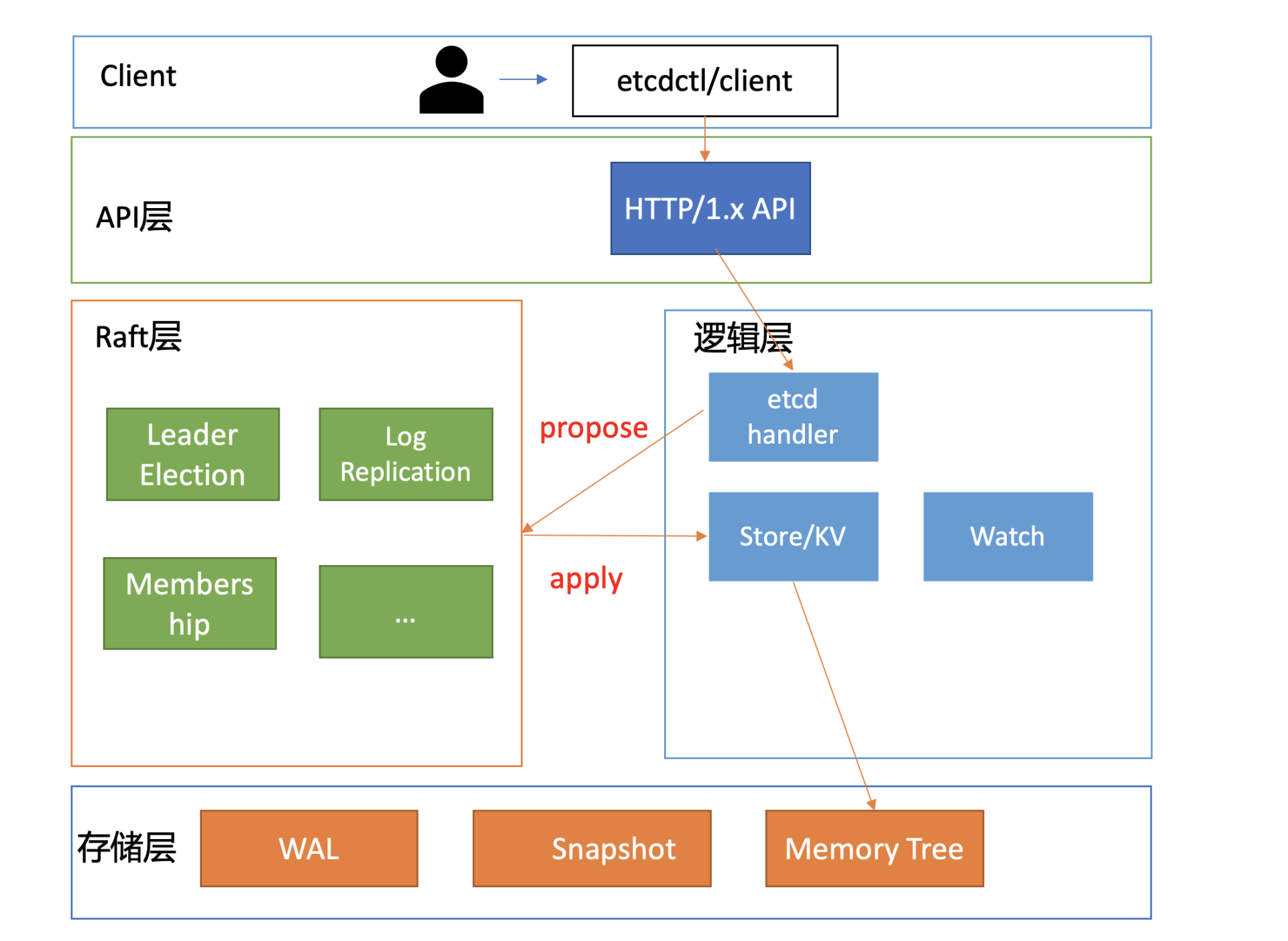
下面是一张etcd的简要基础架构图,我们先从宏观上了解一下etcd都有哪些功能模块。
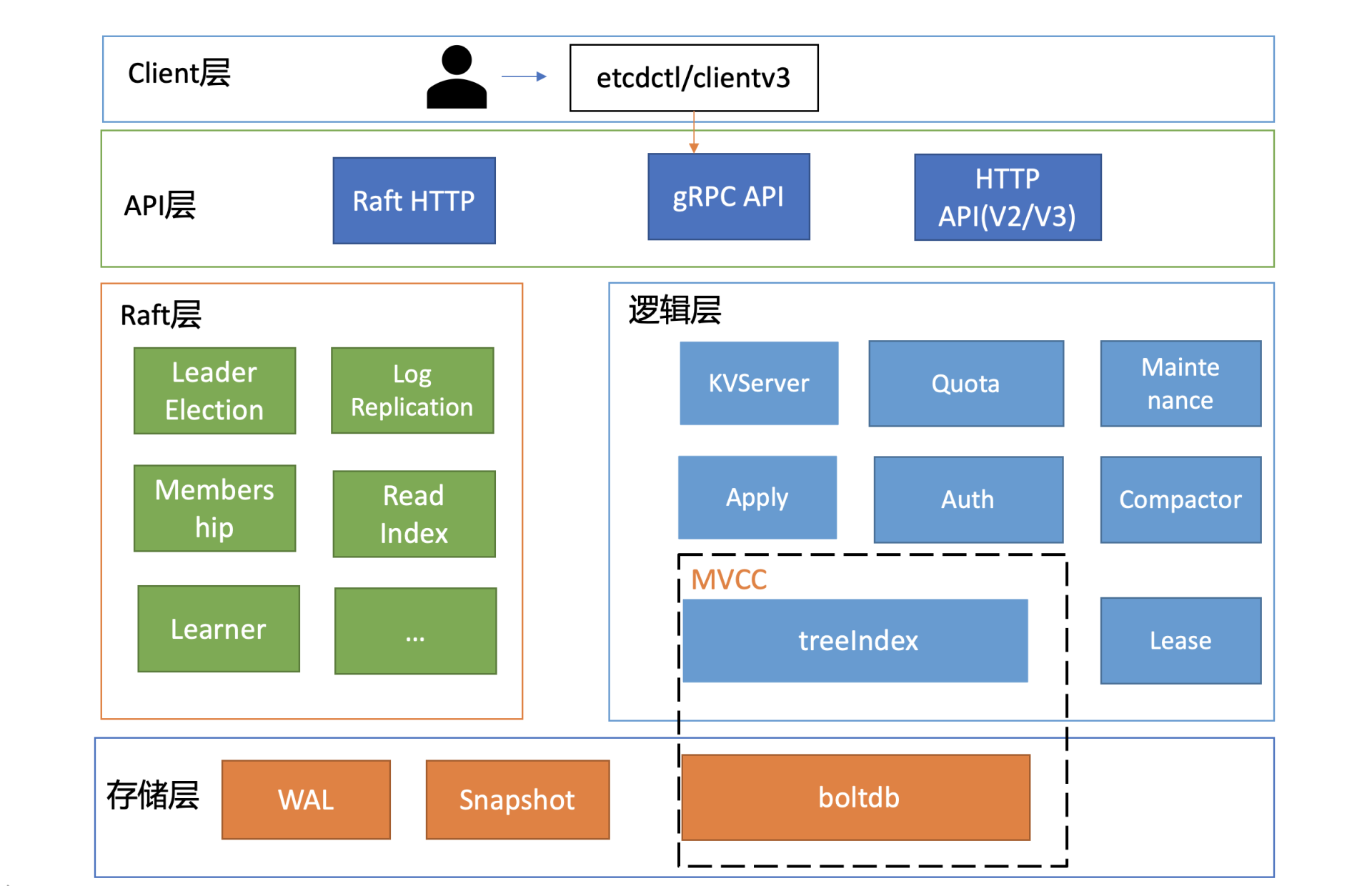
你可以看到,按照分层模型,etcd可分为Client层、API网络层、Raft算法层、逻辑层和存储层。这些层的功能如下:
- Client层:Client层包括client v2和v3两个大版本API客户端库,提供了简洁易用的API,同时支持负载均衡、节点间故障自动转移,可极大降低业务使用etcd复杂度,提升开发效率、服务可用性。
- API网络层:API网络层主要包括client访问server和server节点之间的通信协议。一方面,client访问etcd server的API分为v2和v3两个大版本。v2 API使用HTTP/1.x协议,v3 API使用gRPC协议。同时v3通过etcd grpc-gateway组件也支持HTTP/1.x协议,便于各种语言的服务调用。另一方面,server之间通信协议,是指节点间通过Raft算法实现数据复制和Leader选举等功能时使用的HTTP协议。
- Raft算法层:Raft算法层实现了Leader选举、日志复制、ReadIndex等核心算法特性,用于保障etcd多个节点间的数据一致性、提升服务可用性等,是etcd的基石和亮点。
- 功能逻辑层:etcd核心特性实现层,如典型的KVServer模块、MVCC模块、Auth鉴权模块、Lease租约模块、Compactor压缩模块等,其中MVCC模块主要由treeIndex模块和boltdb模块组成。
- 存储层:存储层包含预写日志(WAL)模块、快照(Snapshot)模块、boltdb模块。其中WAL可保障etcd crash后数据不丢失,boltdb则保存了集群元数据和用户写入的数据。
etcd是典型的读多写少存储,在我们实际业务场景中,读一般占据2/3以上的请求。为了让你对etcd有一个深入的理解,接下来我会分析一个读请求是如何执行的,带你了解etcd的核心模块,进而由点及线、由线到面地帮助你构建etcd的全景知识脉络。
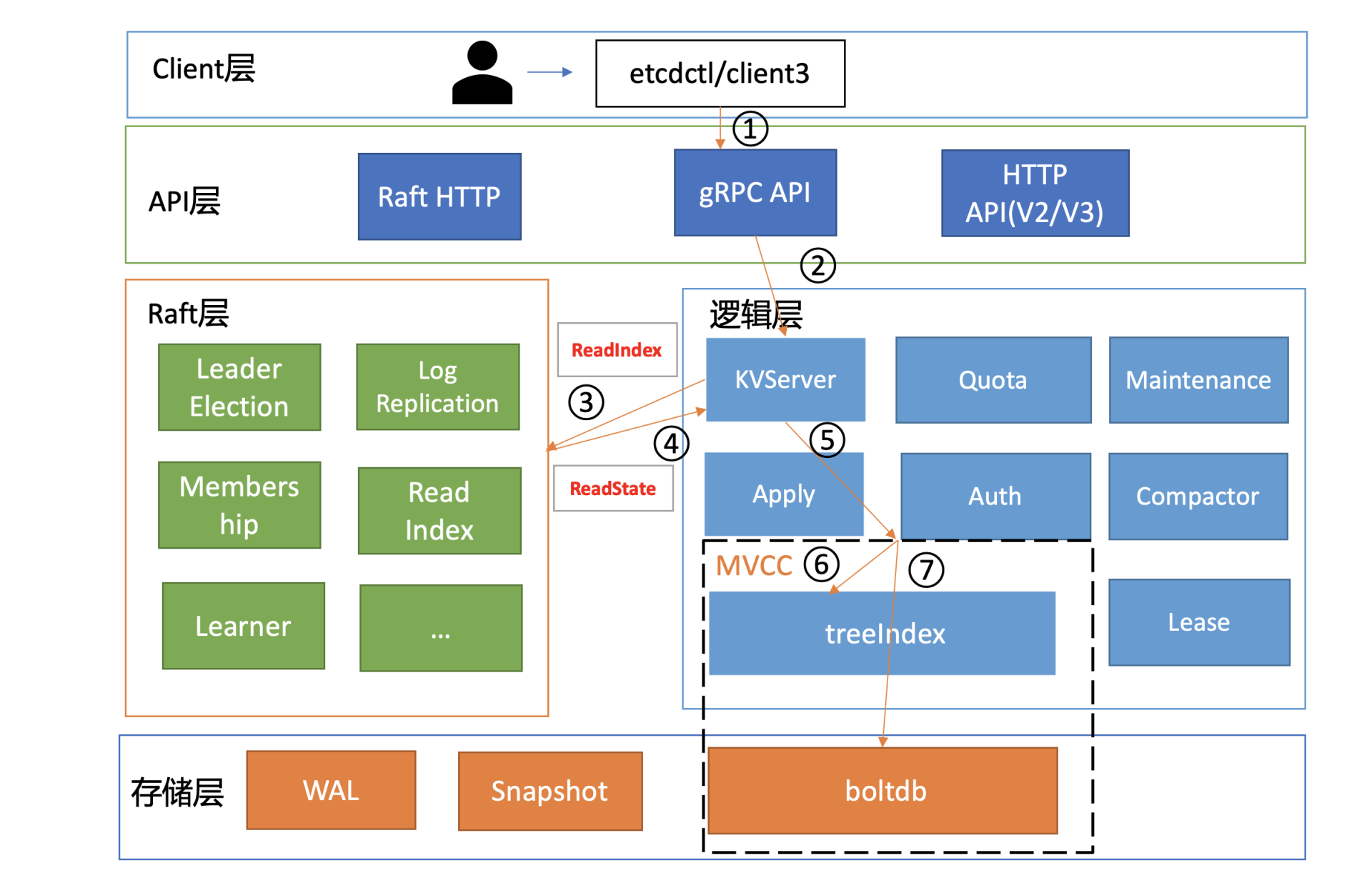
在下面这张架构图中,我用序号标识了etcd默认读模式(线性读)的执行流程,接下来,我们就按照这个执行流程从头开始说。
环境准备
首先介绍一个好用的进程管理工具goreman,基于它,我们可快速创建、停止本地的多节点etcd集群。
你可以通过如下go get命令快速安装goreman,然后从etcd release页下载etcd v3.4.9二进制文件,再从etcd源码中下载goreman Procfile文件,它描述了etcd进程名、节点数、参数等信息。最后通过goreman -f Procfile start命令就可以快速启动一个3节点的本地集群了。
bash
go get github.com/mattn/goremanclient
启动完etcd集群后,当你用etcd的客户端工具etcdctl执行一个get hello命令(如下)时,对应到图中流程一,etcdctl是如何工作的呢?
bash
etcdctl get hello --endpoints http://127.0.0.1:2379
hello
world 首先,etcdctl会对命令中的参数进行解析。我们来看下这些参数的含义,其中,参数"get"是请求的方法,它是KVServer模块的API;"hello"是我们查询的key名;"endpoints"是我们后端的etcd地址,通常,生产环境下中需要配置多个endpoints,这样在etcd节点出现故障后,client就可以自动重连到其它正常的节点,从而保证请求的正常执行。
在etcd v3.4.9版本中,etcdctl是通过clientv3库来访问etcd server的,clientv3库基于gRPC client API封装了操作etcd KVServer、Cluster、Auth、Lease、Watch等模块的API,同时还包含了负载均衡、健康探测和故障切换等特性。
在解析完请求中的参数后,etcdctl会创建一个clientv3库对象,使用KVServer模块的API来访问etcd server。
接下来,就需要为这个get hello请求选择一个合适的etcd server节点了,这里得用到负载均衡算法。在etcd 3.4中,clientv3库采用的负载均衡算法为Round-robin。针对每一个请求,Round-robin算法通过轮询的方式依次从endpoint列表中选择一个endpoint访问(长连接),使etcd server负载尽量均衡。
关于负载均衡算法,你需要特别注意以下两点。
- 如果你的client 版本<= 3.3,那么当你配置多个endpoint时,负载均衡算法仅会从中选择一个IP并创建一个连接(Pinned endpoint),这样可以节省服务器总连接数。但在这我要给你一个小提醒,在heavy usage场景,这可能会造成server负载不均衡。
- 在client 3.4之前的版本中,负载均衡算法有一个严重的Bug:如果第一个节点异常了,可能会导致你的client访问etcd server异常,特别是在Kubernetes场景中会导致APIServer不可用。不过,该Bug已在 Kubernetes 1.16版本后被修复。
为请求选择好etcd server节点,client就可调用etcd server的KVServer模块的Range RPC方法,把请求发送给etcd server。
这里我说明一点,client和server之间的通信,使用的是基于HTTP/2的gRPC协议。相比etcd v2的HTTP/1.x,HTTP/2是基于二进制而不是文本、支持多路复用而不再有序且阻塞、支持数据压缩以减少包大小、支持server push等特性。因此,基于HTTP/2的gRPC协议具有低延迟、高性能的特点,有效解决了我们在上一讲中提到的etcd v2中HTTP/1.x 性能问题。
KVServer
client发送Range RPC请求到了server后,就开始进入我们架构图中的流程二,也就是KVServer模块了。
etcd提供了丰富的metrics、日志、请求行为检查等机制,可记录所有请求的执行耗时及错误码、来源IP等,也可控制请求是否允许通过,比如etcd Learner节点只允许指定接口和参数的访问,帮助大家定位问题、提高服务可观测性等,而这些特性是怎么非侵入式的实现呢?
答案就是拦截器。
拦截器
etcd server定义了如下的Service KV和Range方法,启动的时候它会将实现KV各方法的对象注册到gRPC Server,并在其上注册对应的拦截器。下面的代码中的Range接口就是负责读取etcd key-value的的RPC接口。
cpp
service KV {
// Range gets the keys in the range from the key-value store.
rpc Range(RangeRequest) returns (RangeResponse) {
option (google.api.http) = {
post: "/v3/kv/range"
body: "*"
};
}
....
} 拦截器提供了在执行一个请求前后的hook能力,除了我们上面提到的debug日志、metrics统计、对etcd Learner节点请求接口和参数限制等能力,etcd还基于它实现了以下特性:
- 要求执行一个操作前集群必须有Leader;
- 请求延时超过指定阈值的,打印包含来源IP的慢查询日志(3.5版本)。
server收到client的Range RPC请求后,根据ServiceName和RPC Method将请求转发到对应的handler实现,handler首先会将上面描述的一系列拦截器串联成一个执行,在拦截器逻辑中,通过调用KVServer模块的Range接口获取数据。
串行读与线性读
进入KVServer模块后,我们就进入核心的读流程了,对应架构图中的流程三和四。我们知道etcd为了保证服务高可用,生产环境一般部署多个节点,那各个节点数据在任意时间点读出来都是一致的吗?什么情况下会读到旧数据呢?
这里为了帮助你更好的理解读流程,我先简单提下写流程。如下图所示,当client发起一个更新hello为world请求后,若Leader收到写请求,它会将此请求持久化到WAL日志,并广播给各个节点,若一半以上节点持久化成功,则该请求对应的日志条目被标识为已提交,etcdserver模块异步从Raft模块获取已提交的日志条目,应用到状态机(boltdb等)。
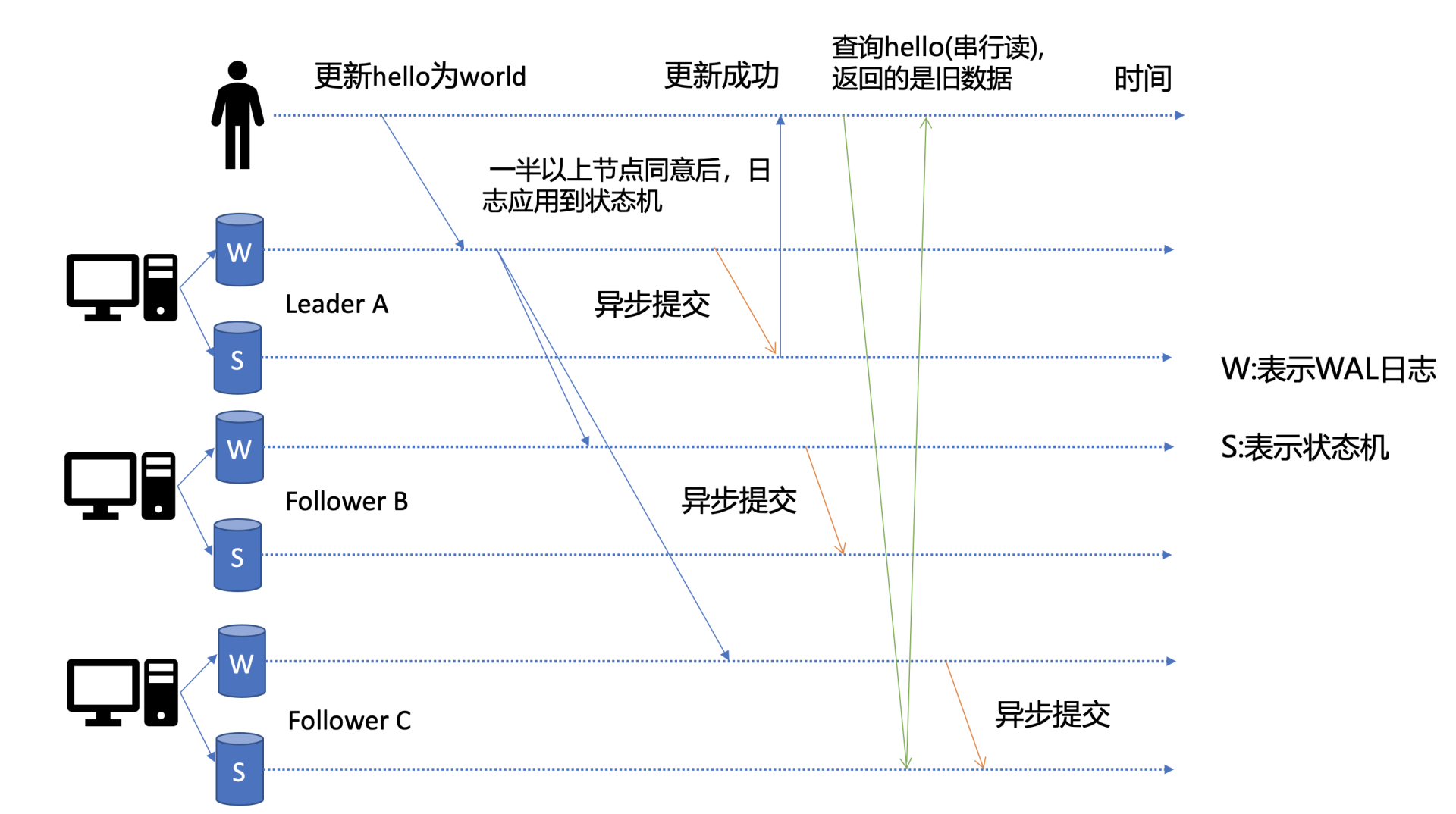
此时若client发起一个读取hello的请求,假设此请求直接从状态机中读取, 如果连接到的是C节点,若C节点磁盘I/O出现波动,可能导致它应用已提交的日志条目很慢,则会出现更新hello为world的写命令,在client读hello的时候还未被提交到状态机,因此就可能读取到旧数据,如上图查询hello流程所示。
从以上介绍我们可以看出,在多节点etcd集群中,各个节点的状态机数据一致性存在差异。而我们不同业务场景的读请求对数据是否最新的容忍度是不一样的,有的场景它可以容忍数据落后几秒甚至几分钟,有的场景要求必须读到反映集群共识的最新数据。
我们首先来看一个对数据敏感度较低的场景。
假如老板让你做一个旁路数据统计服务,希望你每分钟统计下etcd里的服务、配置信息等,这种场景其实对数据时效性要求并不高,读请求可直接从节点的状态机获取数据。即便数据落后一点,也不影响业务,毕竟这是一个定时统计的旁路服务而已。
这种直接读状态机数据返回、无需通过Raft协议与集群进行交互的模式,在etcd里叫做串行(Serializable)读,它具有低延时、高吞吐量的特点,适合对数据一致性要求不高的场景。
我们再看一个对数据敏感性高的场景。
当你发布服务,更新服务的镜像的时候,提交的时候显示更新成功,结果你一刷新页面,发现显示的镜像的还是旧的,再刷新又是新的,这就会导致混乱。再比如说一个转账场景,Alice给Bob转账成功,钱被正常扣出,一刷新页面发现钱又回来了,这也是令人不可接受的。
以上的业务场景就对数据准确性要求极高了,在etcd里面,提供了一种线性读模式来解决对数据一致性要求高的场景。
什么是线性读呢?
你可以理解一旦一个值更新成功,随后任何通过线性读的client都能及时访问到。虽然集群中有多个节点,但client通过线性读就如访问一个节点一样。etcd默认读模式是线性读,因为它需要经过Raft协议模块,反应的是集群共识,因此在延时和吞吐量上相比串行读略差一点,适用于对数据一致性要求高的场景。
如果你的etcd读请求显示指定了是串行读,就不会经过架构图流程中的流程三、四。默认是线性读,因此接下来我们看看读请求进入线性读模块,它是如何工作的。
线性读之ReadIndex
前面我们聊到串行读时提到,它之所以能读到旧数据,主要原因是Follower节点收到Leader节点同步的写请求后,应用日志条目到状态机是个异步过程,那么我们能否有一种机制在读取的时候,确保最新的数据已经应用到状态机中?
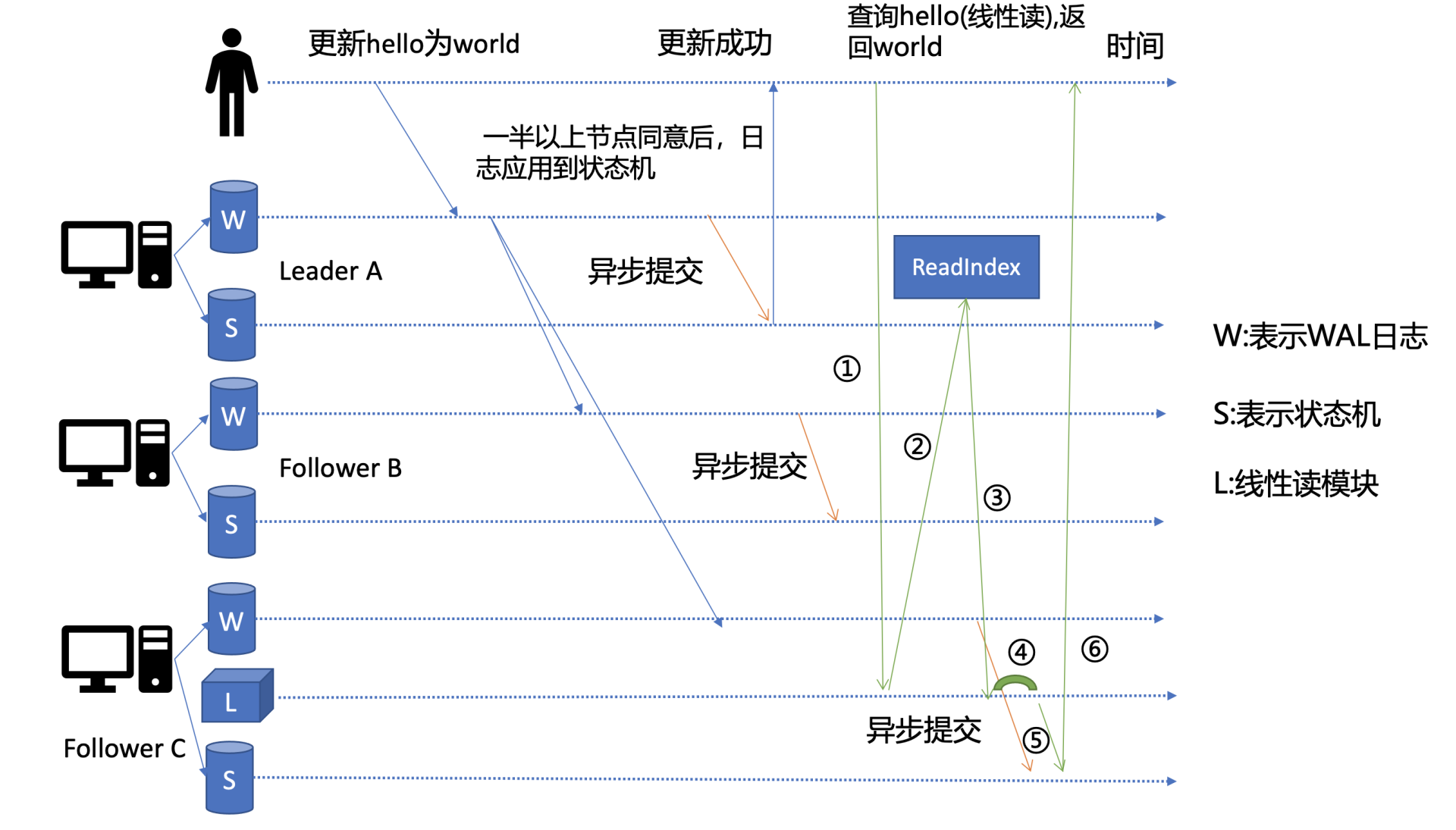
其实这个机制就是叫ReadIndex,它是在etcd 3.1中引入的,我把简化后的原理图放在了上面。当收到一个线性读请求时,它首先会从Leader获取集群最新的已提交的日志索引(committed index),如上图中的流程二所示。
Leader收到ReadIndex请求时,为防止脑裂等异常场景,会向Follower节点发送心跳确认,一半以上节点确认Leader身份后才能将已提交的索引(committed index)返回给节点C(上图中的流程三)。
C节点则会等待,直到状态机已应用索引(applied index)大于等于Leader的已提交索引时(committed Index)(上图中的流程四),然后去通知读请求,数据已赶上Leader,你可以去状态机中访问数据了(上图中的流程五)。
以上就是线性读通过ReadIndex机制保证数据一致性原理, 当然还有其它机制也能实现线性读,如在早期etcd 3.0中读请求通过走一遍Raft协议保证一致性, 这种Raft log read机制依赖磁盘IO, 性能相比ReadIndex较差。
总体而言,KVServer模块收到线性读请求后,通过架构图中流程三向Raft模块发起ReadIndex请求,Raft模块将Leader最新的已提交日志索引封装在流程四的ReadState结构体,通过channel层层返回给线性读模块,线性读模块等待本节点状态机追赶上Leader进度,追赶完成后,就通知KVServer模块,进行架构图中流程五,与状态机中的MVCC模块进行进行交互了。
MVCC
流程五中的多版本并发控制(Multiversion concurrency control)模块是为了解决上一讲我们提到etcd v2不支持保存key的历史版本、不支持多key事务等问题而产生的。
它核心由内存树形索引模块(treeIndex)和嵌入式的KV持久化存储库boltdb组成。
首先我们需要简单了解下boltdb,它是个基于B+ tree实现的key-value键值库,支持事务,提供Get/Put等简易API给etcd操作。
那么etcd如何基于boltdb保存一个key的多个历史版本呢?
比如我们现在有以下方案:方案1是一个key保存多个历史版本的值;方案2每次修改操作,生成一个新的版本号(revision),以版本号为key, value为用户key-value等信息组成的结构体。
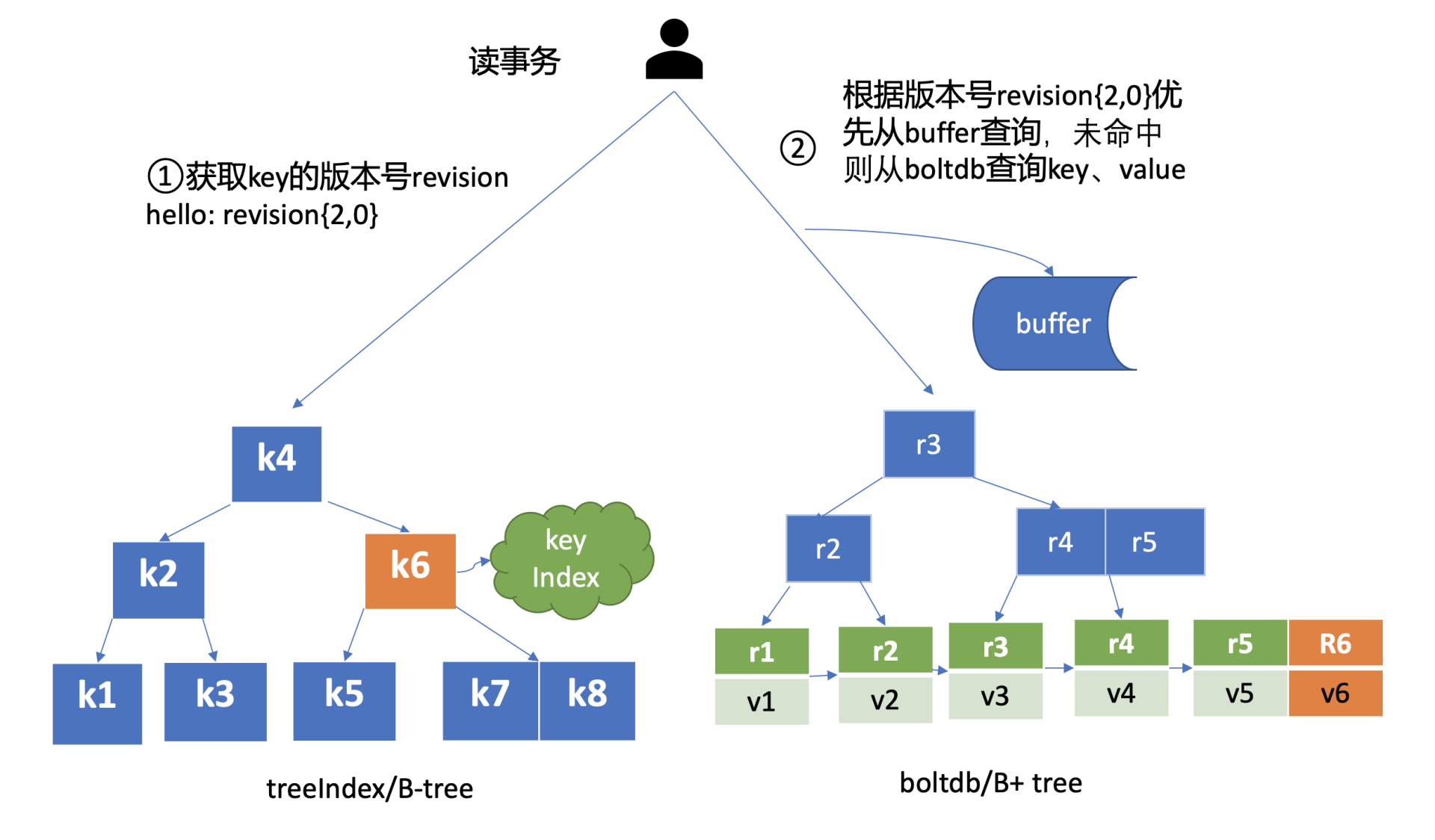
很显然方案1会导致value较大,存在明显读写放大、并发冲突等问题,而方案2正是etcd所采用的。boltdb的key是全局递增的版本号(revision),value是用户key、value等字段组合成的结构体,然后通过treeIndex模块来保存用户key和版本号的映射关系。
treeIndex与boltdb关系如下面的读事务流程图所示,从treeIndex中获取key hello的版本号,再以版本号作为boltdb的key,从boltdb中获取其value信息。
treeIndex
treeIndex模块是基于Google开源的内存版btree库实现的,为什么etcd选择上图中的B-tree数据结构保存用户key与版本号之间的映射关系,而不是哈希表、二叉树呢?在后面的课程中我会再和你介绍。
treeIndex模块只会保存用户的key和相关版本号信息,用户key的value数据存储在boltdb里面,相比ZooKeeper和etcd v2全内存存储,etcd v3对内存要求更低。
简单介绍了etcd如何保存key的历史版本后,架构图中流程六也就非常容易理解了, 它需要从treeIndex模块中获取hello这个key对应的版本号信息。treeIndex模块基于B-tree快速查找此key,返回此key对应的索引项keyIndex即可。索引项中包含版本号等信息。
buffer
在获取到版本号信息后,就可从boltdb模块中获取用户的key-value数据了。不过有一点你要注意,并不是所有请求都一定要从boltdb获取数据。
etcd出于数据一致性、性能等考虑,在访问boltdb前,首先会从一个内存读事务buffer中,二分查找你要访问key是否在buffer里面,若命中则直接返回。
boltdb
若buffer未命中,此时就真正需要向boltdb模块查询数据了,进入了流程七。
我们知道MySQL通过table实现不同数据逻辑隔离,那么在boltdb是如何隔离集群元数据与用户数据的呢?答案是bucket。boltdb里每个bucket类似对应MySQL一个表,用户的key数据存放的bucket名字的是key,etcd MVCC元数据存放的bucket是meta。
因boltdb使用B+ tree来组织用户的key-value数据,获取bucket key对象后,通过boltdb的游标Cursor可快速在B+ tree找到key hello对应的value数据,返回给client。
到这里,一个读请求之路执行完成。
小结
最后我们来小结一下,一个读请求从client通过Round-robin负载均衡算法,选择一个etcd server节点,发出gRPC请求,经过etcd server的KVServer模块、线性读模块、MVCC的treeIndex和boltdb模块紧密协作,完成了一个读请求。
通过一个读请求,我带你初步了解了etcd的基础架构以及各个模块之间是如何协作的。
在这过程中,我想和你特别总结下client的节点故障自动转移和线性读。
一方面, client的通过负载均衡、错误处理等机制实现了etcd节点之间的故障的自动转移,它可助你的业务实现服务高可用,建议使用etcd 3.4分支的client版本。
另一方面,我详细解释了etcd提供的两种读机制(串行读和线性读)原理和应用场景。通过线性读,对业务而言,访问多个节点的etcd集群就如访问一个节点一样简单,能简洁、快速的获取到集群最新共识数据。
早期etcd线性读使用的Raft log read,也就是说把读请求像写请求一样走一遍Raft的协议,基于Raft的日志的有序性,实现线性读。但此方案读涉及磁盘IO开销,性能较差,后来实现了ReadIndex读机制来提升读性能,满足了Kubernetes等业务的诉求。
思考题
etcd在执行读请求过程中涉及磁盘IO吗?如果涉及,是什么模块在什么场景下会触发呢?如果不涉及,又是什么原因呢?
03 基础架构:etcd一个写请求是如何执行的?
在上一节课里,我通过分析etcd的一个读请求执行流程,给你介绍了etcd的基础架构,让你初步了解了在etcd的读请求流程中,各个模块是如何紧密协作,执行查询语句,返回数据给client。
那么etcd一个写请求执行流程又是怎样的呢?在执行写请求过程中,如果进程crash了,如何保证数据不丢、命令不重复执行呢?
今天我就和你聊聊etcd写过程中是如何解决这些问题的。希望通过这节课,让你了解一个key-value写入的原理,对etcd的基础架构中涉及写请求相关的模块有一定的理解,同时能触类旁通,当你在软件项目开发过程中遇到类似数据安全、幂等性等问题时,能设计出良好的方案解决它。
整体架构
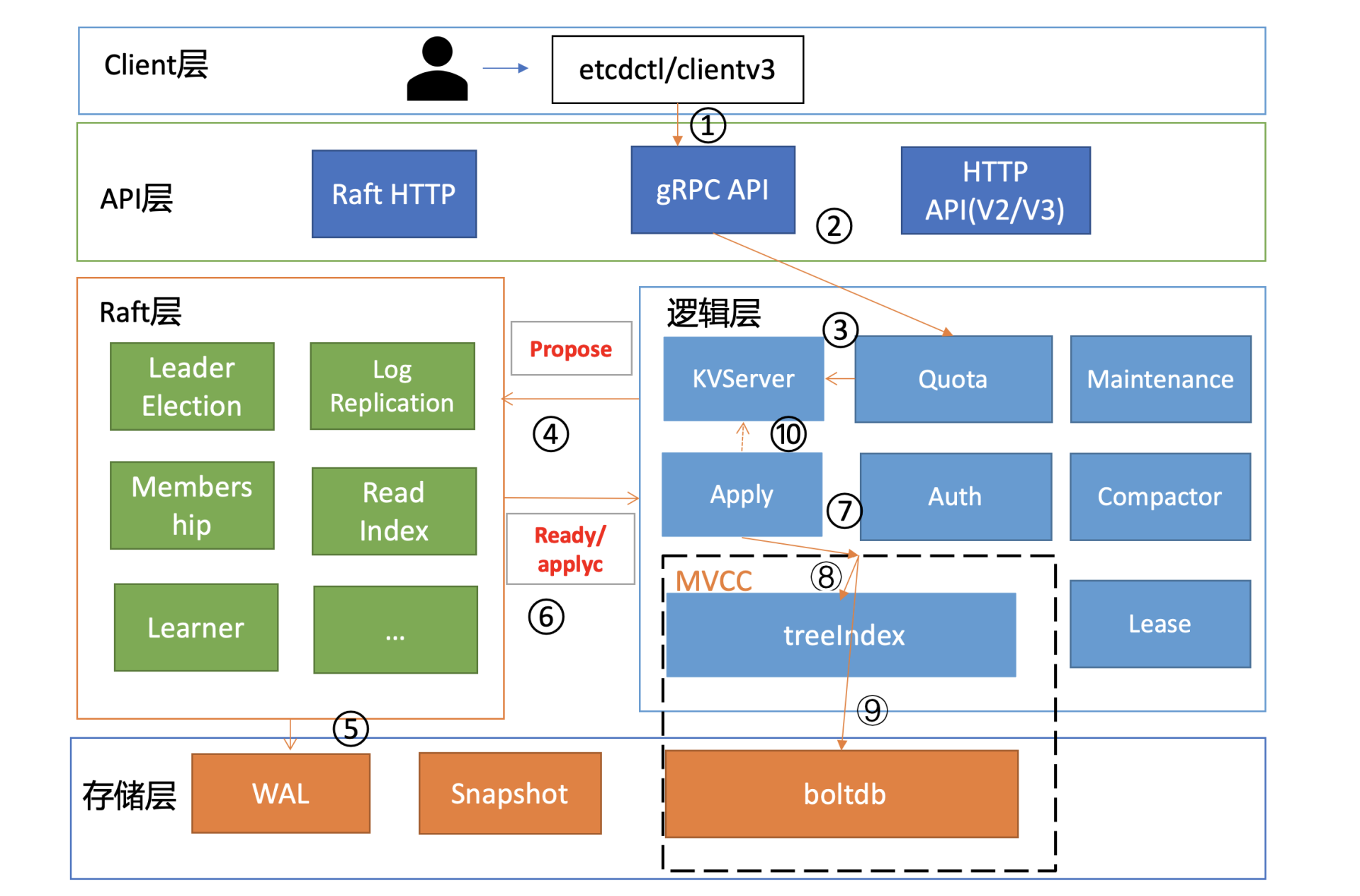
为了让你能够更直观地理解etcd的写请求流程,我在如上的架构图中,用序号标识了下面的一个put hello为world的写请求的简要执行流程,帮助你从整体上快速了解一个写请求的全貌。
cpp
etcdctl put hello world --endpoints http://127.0.0.1:2379
OK首先client端通过负载均衡算法选择一个etcd节点,发起gRPC调用。然后etcd节点收到请求后经过gRPC拦截器、Quota模块后,进入KVServer模块,KVServer模块向Raft模块提交一个提案,提案内容为"大家好,请使用put方法执行一个key为hello,value为world的命令"。
随后此提案通过RaftHTTP网络模块转发、经过集群多数节点持久化后,状态会变成已提交,etcdserver从Raft模块获取已提交的日志条目,传递给Apply模块,Apply模块通过MVCC模块执行提案内容,更新状态机。
与读流程不一样的是写流程还涉及Quota、WAL、Apply三个模块。crash-safe及幂等性也正是基于WAL和Apply流程的consistent index等实现的,因此今天我会重点和你介绍这三个模块。
下面就让我们沿着写请求执行流程图,从0到1分析一个key-value是如何安全、幂等地持久化到磁盘的。
Quota模块
首先是流程一client端发起gRPC调用到etcd节点,和读请求不一样的是,写请求需要经过流程二db配额(Quota)模块,它有什么功能呢?
我们先从此模块的一个常见错误说起,你在使用etcd过程中是否遇到过"etcdserver: mvcc: database space exceeded"错误呢?
我相信只要你使用过etcd或者Kubernetes,大概率见过这个错误。它是指当前etcd db文件大小超过了配额,当出现此错误后,你的整个集群将不可写入,只读,对业务的影响非常大。
哪些情况会触发这个错误呢?
一方面默认db配额仅为2G,当你的业务数据、写入QPS、Kubernetes集群规模增大后,你的etcd db大小就可能会超过2G。
另一方面我们知道etcd v3是个MVCC数据库,保存了key的历史版本,当你未配置压缩策略的时候,随着数据不断写入,db大小会不断增大,导致超限。
最后你要特别注意的是,如果你使用的是etcd 3.2.10之前的旧版本,请注意备份可能会触发boltdb的一个Bug,它会导致db大小不断上涨,最终达到配额限制。
了解完触发Quota限制的原因后,我们再详细了解下Quota模块它是如何工作的。
当etcd server收到put/txn等写请求的时候,会首先检查下当前etcd db大小加上你请求的key-value大小之和是否超过了配额(quota-backend-bytes)。
如果超过了配额,它会产生一个告警(Alarm)请求,告警类型是NO SPACE,并通过Raft日志同步给其它节点,告知db无空间了,并将告警持久化存储到db中。
最终,无论是API层gRPC模块还是负责将Raft侧已提交的日志条目应用到状态机的Apply模块,都拒绝写入,集群只读。
那遇到这个错误时应该如何解决呢?
首先当然是调大配额。具体多大合适呢?etcd社区建议不超过8G。遇到过这个错误的你是否还记得,为什么当你把配额(quota-backend-bytes)调大后,集群依然拒绝写入呢?
原因就是我们前面提到的NO SPACE告警。Apply模块在执行每个命令的时候,都会去检查当前是否存在NO SPACE告警,如果有则拒绝写入。所以还需要你额外发送一个取消告警(etcdctl alarm disarm)的命令,以消除所有告警。
其次你需要检查etcd的压缩(compact)配置是否开启、配置是否合理。etcd保存了一个key所有变更历史版本,如果没有一个机制去回收旧的版本,那么内存和db大小就会一直膨胀,在etcd里面,压缩模块负责回收旧版本的工作。
压缩模块支持按多种方式回收旧版本,比如保留最近一段时间内的历史版本。不过你要注意,它仅仅是将旧版本占用的空间打个空闲(Free)标记,后续新的数据写入的时候可复用这块空间,而无需申请新的空间。
如果你需要回收空间,减少db大小,得使用碎片整理(defrag), 它会遍历旧的db文件数据,写入到一个新的db文件。但是它对服务性能有较大影响,不建议你在生产集群频繁使用。
最后你需要注意配额(quota-backend-bytes)的行为,默认'0'就是使用etcd默认的2GB大小,你需要根据你的业务场景适当调优。如果你填的是个小于0的数,就会禁用配额功能,这可能会让你的db大小处于失控,导致性能下降,不建议你禁用配额。
KVServer模块
通过流程二的配额检查后,请求就从API层转发到了流程三的KVServer模块的put方法,我们知道etcd是基于Raft算法实现节点间数据复制的,因此它需要将put写请求内容打包成一个提案消息,提交给Raft模块。不过KVServer模块在提交提案前,还有如下的一系列检查和限速。
Preflight Check
为了保证集群稳定性,避免雪崩,任何提交到Raft模块的请求,都会做一些简单的限速判断。如下面的流程图所示,首先,如果Raft模块已提交的日志索引(committed index)比已应用到状态机的日志索引(applied index)超过了5000,那么它就返回一个"etcdserver: too many requests"错误给client。
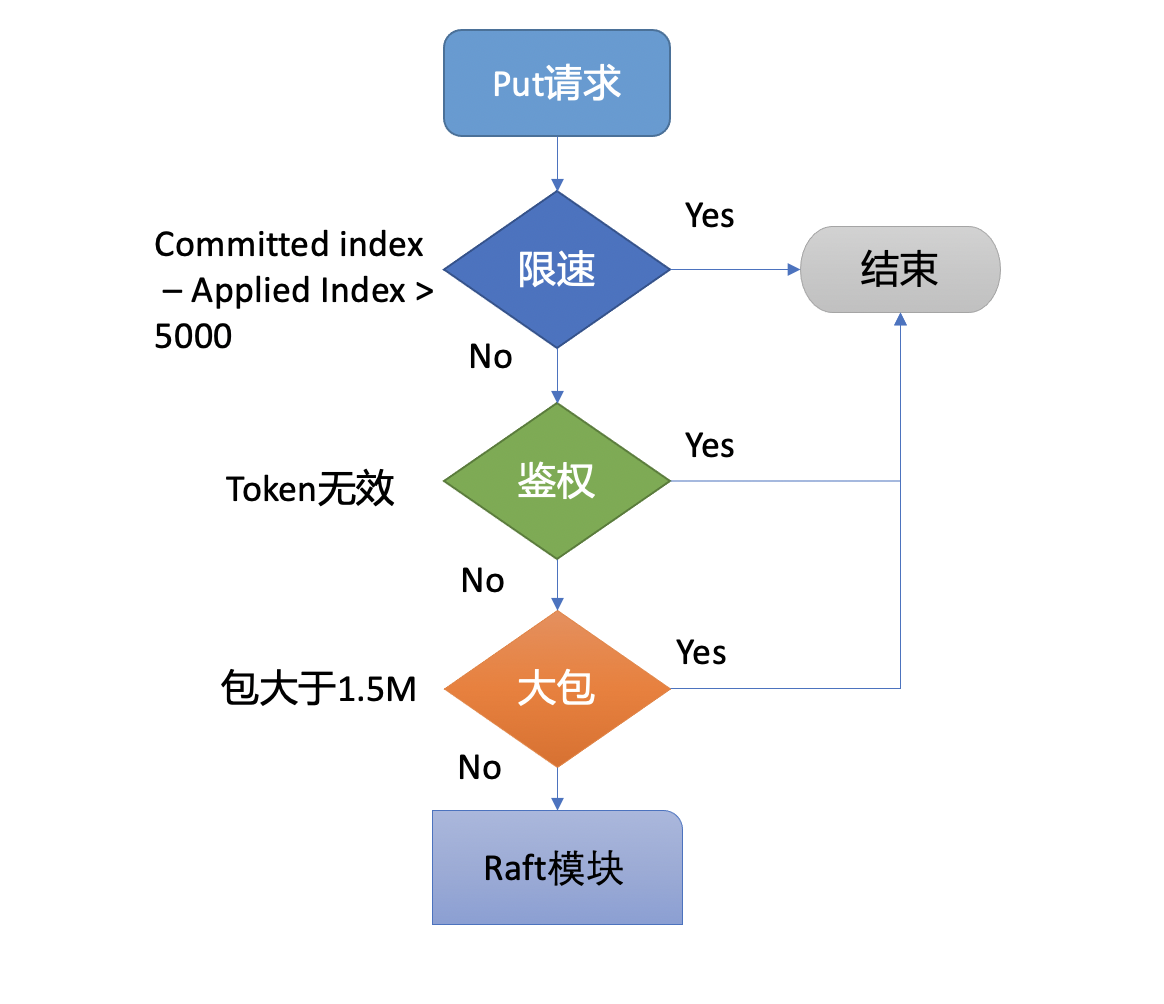
然后它会尝试去获取请求中的鉴权信息,若使用了密码鉴权、请求中携带了token,如果token无效,则返回"auth: invalid auth token"错误给client。
其次它会检查你写入的包大小是否超过默认的1.5MB, 如果超过了会返回"etcdserver: request is too large"错误给给client。
Propose
最后通过一系列检查之后,会生成一个唯一的ID,将此请求关联到一个对应的消息通知channel,然后向Raft模块发起(Propose)一个提案(Proposal),提案内容为"大家好,请使用put方法执行一个key为hello,value为world的命令",也就是整体架构图里的流程四。
向Raft模块发起提案后,KVServer模块会等待此put请求,等待写入结果通过消息通知channel返回或者超时。etcd默认超时时间是7秒(5秒磁盘IO延时+2*1秒竞选超时时间),如果一个请求超时未返回结果,则可能会出现你熟悉的etcdserver: request timed out错误。
WAL模块
Raft模块收到提案后,如果当前节点是Follower,它会转发给Leader,只有Leader才能处理写请求。Leader收到提案后,通过Raft模块输出待转发给Follower节点的消息和待持久化的日志条目,日志条目则封装了我们上面所说的put hello提案内容。
etcdserver从Raft模块获取到以上消息和日志条目后,作为Leader,它会将put提案消息广播给集群各个节点,同时需要把集群Leader任期号、投票信息、已提交索引、提案内容持久化到一个WAL(Write Ahead Log)日志文件中,用于保证集群的一致性、可恢复性,也就是我们图中的流程五模块。
WAL日志结构是怎样的呢?
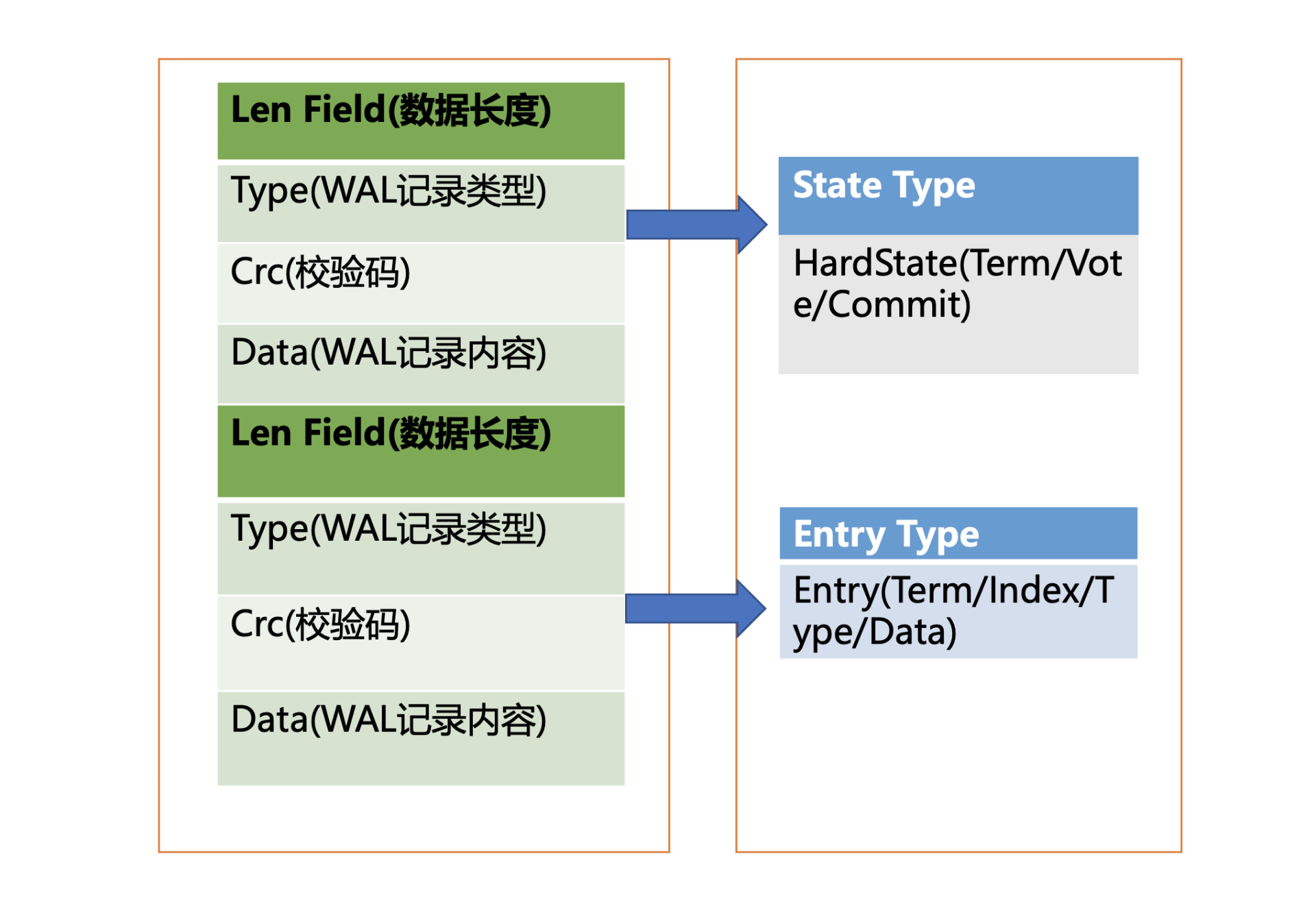
上图是WAL结构,它由多种类型的WAL记录顺序追加写入组成,每个记录由类型、数据、循环冗余校验码组成。不同类型的记录通过Type字段区分,Data为对应记录内容,CRC为循环校验码信息。
WAL记录类型目前支持5种,分别是文件元数据记录、日志条目记录、状态信息记录、CRC记录、快照记录:
- 文件元数据记录包含节点ID、集群ID信息,它在WAL文件创建的时候写入;
- 日志条目记录包含Raft日志信息,如put提案内容;
- 状态信息记录,包含集群的任期号、节点投票信息等,一个日志文件中会有多条,以最后的记录为准;
- CRC记录包含上一个WAL文件的最后的CRC(循环冗余校验码)信息, 在创建、切割WAL文件时,作为第一条记录写入到新的WAL文件, 用于校验数据文件的完整性、准确性等;
- 快照记录包含快照的任期号、日志索引信息,用于检查快照文件的准确性。
WAL模块又是如何持久化一个put提案的日志条目类型记录呢?
首先我们来看看put写请求如何封装在Raft日志条目里面。下面是Raft日志条目的数据结构信息,它由以下字段组成:
- Term是Leader任期号,随着Leader选举增加;
- Index是日志条目的索引,单调递增增加;
- Type是日志类型,比如是普通的命令日志(EntryNormal)还是集群配置变更日志(EntryConfChange);
- Data保存我们上面描述的put提案内容。
csharp
type Entry struct {
Term uint64 `protobuf:"varint,2,opt,name=Term" json:"Term"`
Index uint64 `protobuf:"varint,3,opt,name=Index" json:"Index"`
Type EntryType `protobuf:"varint,1,opt,name=Type,enum=Raftpb.EntryType" json:"Type"`
Data []byte `protobuf:"bytes,4,opt,name=Data" json:"Data,omitempty"`
}了解完Raft日志条目数据结构后,我们再看WAL模块如何持久化Raft日志条目。它首先先将Raft日志条目内容(含任期号、索引、提案内容)序列化后保存到WAL记录的Data字段, 然后计算Data的CRC值,设置Type为Entry Type, 以上信息就组成了一个完整的WAL记录。
最后计算WAL记录的长度,顺序先写入WAL长度(Len Field),然后写入记录内容,调用fsync持久化到磁盘,完成将日志条目保存到持久化存储中。
当一半以上节点持久化此日志条目后, Raft模块就会通过channel告知etcdserver模块,put提案已经被集群多数节点确认,提案状态为已提交,你可以执行此提案内容了。
于是进入流程六,etcdserver模块从channel取出提案内容,添加到先进先出(FIFO)调度队列,随后通过Apply模块按入队顺序,异步、依次执行提案内容。
Apply模块
执行put提案内容对应我们架构图中的流程七,其细节图如下。那么Apply模块是如何执行put请求的呢?若put请求提案在执行流程七的时候etcd突然crash了, 重启恢复的时候,etcd是如何找回异常提案,再次执行的呢?
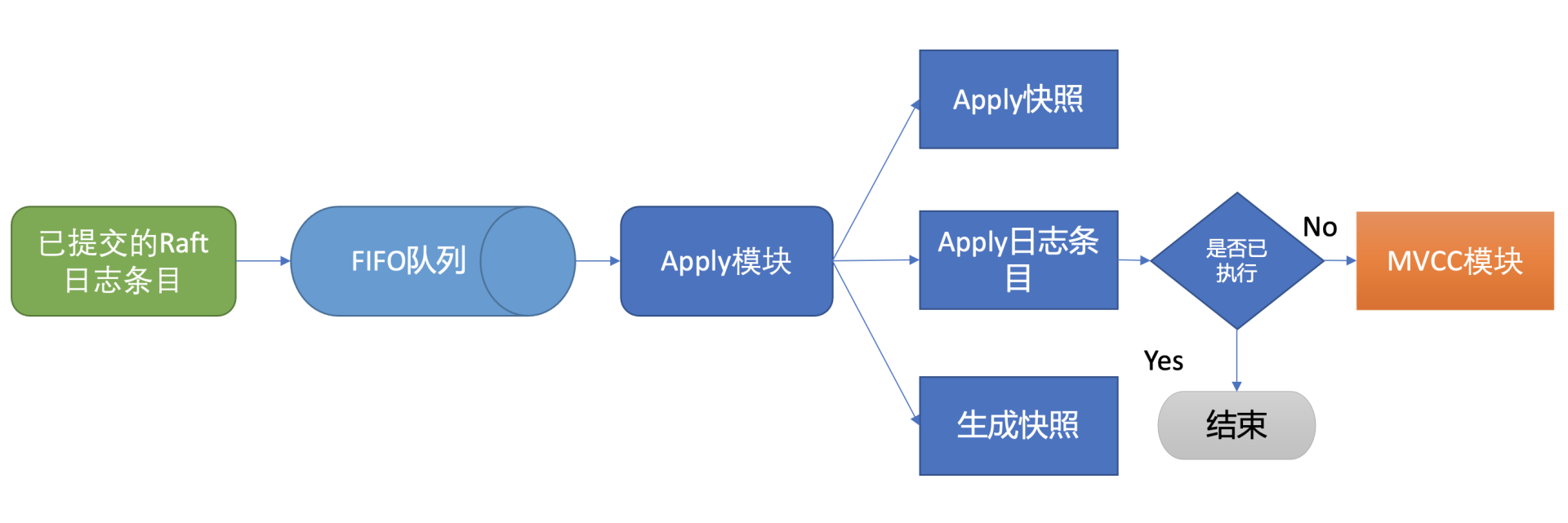
核心就是我们上面介绍的WAL日志,因为提交给Apply模块执行的提案已获得多数节点确认、持久化,etcd重启时,会从WAL中解析出Raft日志条目内容,追加到Raft日志的存储中,并重放已提交的日志提案给Apply模块执行。
然而这又引发了另外一个问题,如何确保幂等性,防止提案重复执行导致数据混乱呢?
我们在上一节课里讲到,etcd是个MVCC数据库,每次更新都会生成新的版本号。如果没有幂等性保护,同样的命令,一部分节点执行一次,一部分节点遭遇异常故障后执行多次,则系统的各节点一致性状态无法得到保证,导致数据混乱,这是严重故障。
因此etcd必须要确保幂等性。怎么做呢?Apply模块从Raft模块获得的日志条目信息里,是否有唯一的字段能标识这个提案?
答案就是我们上面介绍Raft日志条目中的索引(index)字段。日志条目索引是全局单调递增的,每个日志条目索引对应一个提案, 如果一个命令执行后,我们在db里面也记录下当前已经执行过的日志条目索引,是不是就可以解决幂等性问题呢?
是的。但是这还不够安全,如果执行命令的请求更新成功了,更新index的请求却失败了,是不是一样会导致异常?
因此我们在实现上,还需要将两个操作作为原子性事务提交,才能实现幂等。
正如我们上面的讨论的这样,etcd通过引入一个consistent index的字段,来存储系统当前已经执行过的日志条目索引,实现幂等性。
Apply模块在执行提案内容前,首先会判断当前提案是否已经执行过了,如果执行了则直接返回,若未执行同时无db配额满告警,则进入到MVCC模块,开始与持久化存储模块打交道。
MVCC
Apply模块判断此提案未执行后,就会调用MVCC模块来执行提案内容。MVCC主要由两部分组成,一个是内存索引模块treeIndex,保存key的历史版本号信息,另一个是boltdb模块,用来持久化存储key-value数据。那么MVCC模块执行put hello为world命令时,它是如何构建内存索引和保存哪些数据到db呢?
treeIndex
首先我们来看MVCC的索引模块treeIndex,当收到更新key hello为world的时候,此key的索引版本号信息是怎么生成的呢?需要维护、持久化存储一个全局版本号吗?
版本号(revision)在etcd里面发挥着重大作用,它是etcd的逻辑时钟。etcd启动的时候默认版本号是1,随着你对key的增、删、改操作而全局单调递增。
因为boltdb中的key就包含此信息,所以etcd并不需要再去持久化一个全局版本号。我们只需要在启动的时候,从最小值1开始枚举到最大值,未读到数据的时候则结束,最后读出来的版本号即是当前etcd的最大版本号currentRevision。
MVCC写事务在执行put hello为world的请求时,会基于currentRevision自增生成新的revision如{2,0},然后从treeIndex模块中查询key的创建版本号、修改次数信息。这些信息将填充到boltdb的value中,同时将用户的hello key和revision等信息存储到B-tree,也就是下面简易写事务图的流程一,整体架构图中的流程八。
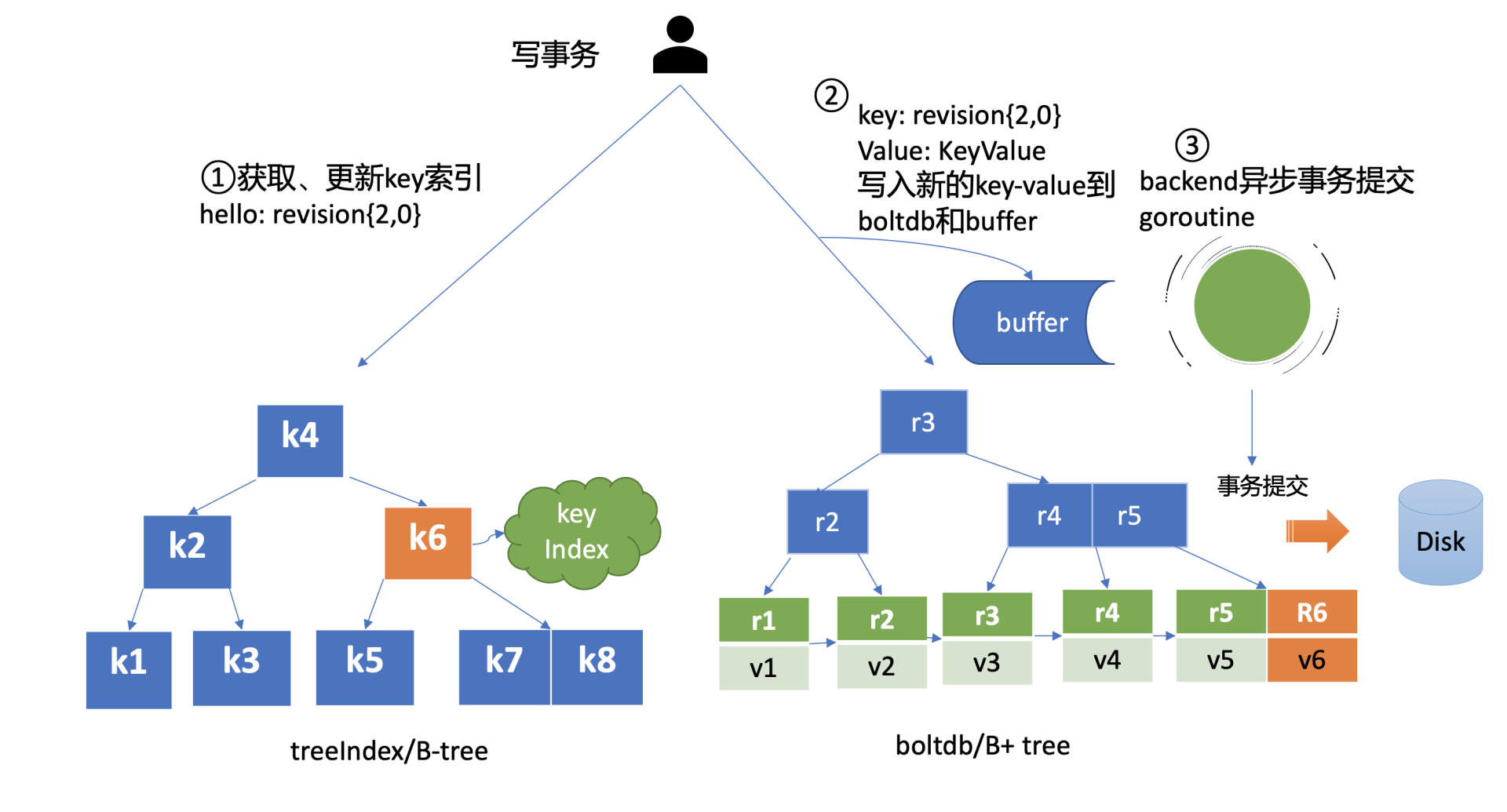
boltdb
MVCC写事务自增全局版本号后生成的revision{2,0},它就是boltdb的key,通过它就可以往boltdb写数据了,进入了整体架构图中的流程九。
boltdb上一篇我们提过它是一个基于B+tree实现的key-value嵌入式db,它通过提供桶(bucket)机制实现类似MySQL表的逻辑隔离。
在etcd里面你通过put/txn等KV API操作的数据,全部保存在一个名为key的桶里面,这个key桶在启动etcd的时候会自动创建。
除了保存用户KV数据的key桶,etcd本身及其它功能需要持久化存储的话,都会创建对应的桶。比如上面我们提到的etcd为了保证日志的幂等性,保存了一个名为consistent index的变量在db里面,它实际上就存储在元数据(meta)桶里面。
那么写入boltdb的value含有哪些信息呢?
写入boltdb的value, 并不是简单的"world",如果只存一个用户value,索引又是保存在易失的内存上,那重启etcd后,我们就丢失了用户的key名,无法构建treeIndex模块了。
因此为了构建索引和支持Lease等特性,etcd会持久化以下信息:
- key名称;
- key创建时的版本号(create_revision)、最后一次修改时的版本号(mod_revision)、key自身修改的次数(version);
- value值;
- 租约信息(后面介绍)。
boltdb value的值就是将含以上信息的结构体序列化成的二进制数据,然后通过boltdb提供的put接口,etcd就快速完成了将你的数据写入boltdb,对应上面简易写事务图的流程二。
但是put调用成功,就能够代表数据已经持久化到db文件了吗?
这里需要注意的是,在以上流程中,etcd并未提交事务(commit),因此数据只更新在boltdb所管理的内存数据结构中。
事务提交的过程,包含B+tree的平衡、分裂,将boltdb的脏数据(dirty page)、元数据信息刷新到磁盘,因此事务提交的开销是昂贵的。如果我们每次更新都提交事务,etcd写性能就会较差。
那么解决的办法是什么呢?etcd的解决方案是合并再合并。
首先boltdb key是版本号,put/delete操作时,都会基于当前版本号递增生成新的版本号,因此属于顺序写入,可以调整boltdb的bucket.FillPercent参数,使每个page填充更多数据,减少page的分裂次数并降低db空间。
其次etcd通过合并多个写事务请求,通常情况下,是异步机制定时(默认每隔100ms)将批量事务一次性提交(pending事务过多才会触发同步提交), 从而大大提高吞吐量,对应上面简易写事务图的流程三。
但是这优化又引发了另外的一个问题, 因为事务未提交,读请求可能无法从boltdb获取到最新数据。
为了解决这个问题,etcd引入了一个bucket buffer来保存暂未提交的事务数据。在更新boltdb的时候,etcd也会同步数据到bucket buffer。因此etcd处理读请求的时候会优先从bucket buffer里面读取,其次再从boltdb读,通过bucket buffer实现读写性能提升,同时保证数据一致性。
小结
最后我们来小结一下,今天我给你介绍了etcd的写请求流程,重点介绍了Quota、WAL、Apply模块。
首先我们介绍了Quota模块工作原理和我们熟悉的database space exceeded错误触发原因,写请求导致db大小增加、compact策略不合理、boltdb Bug等都会导致db大小超限。
其次介绍了WAL模块的存储结构,它由一条条记录顺序写入组成,每个记录含有Type、CRC、Data,每个提案被提交前都会被持久化到WAL文件中,以保证集群的一致性和可恢复性。
随后我们介绍了Apply模块基于consistent index和事务实现了幂等性,保证了节点在异常情况下不会重复执行重放的提案。
最后我们介绍了MVCC模块是如何维护索引版本号、重启后如何从boltdb模块中获取内存索引结构的。以及etcd通过异步、批量提交事务机制,以提升写QPS和吞吐量。
通过以上介绍,希望你对etcd的一个写语句执行流程有个初步的理解,明白WAL模块、Apply模块、MVCC模块三者是如何相互协作的,从而实现在节点遭遇crash等异常情况下,不丢任何已提交的数据、不重复执行任何提案。
思考题
expensive read请求(如Kubernetes场景中查询大量pod)会影响写请求的性能吗?
02思考题答案
上节课我给大家留了一个思考题,评论中有同学说buffer没读到,从boltdb读时会产生磁盘I/O,这是一个常见误区。
实际上,etcd在启动的时候会通过mmap机制将etcd db文件映射到etcd进程地址空间,并设置了mmap的MAP_POPULATE flag,它会告诉Linux内核预读文件,Linux内核会将文件内容拷贝到物理内存中,此时会产生磁盘I/O。节点内存足够的请求下,后续处理读请求过程中就不会产生磁盘I/IO了。
若etcd节点内存不足,可能会导致db文件对应的内存页被换出,当读请求命中的页未在内存中时,就会产生缺页异常,导致读过程中产生磁盘IO,你可以通过观察etcd进程的majflt字段来判断etcd是否产生了主缺页中断。
04 Raft协议:etcd如何实现高可用、数据强一致的?
在前面的etcd读写流程学习中,我和你多次提到了etcd是基于Raft协议实现高可用、数据强一致性的。
那么etcd是如何基于Raft来实现高可用、数据强一致性的呢?
这节课我们就以上一节中的hello写请求为案例,深入分析etcd在遇到Leader节点crash等异常后,Follower节点如何快速感知到异常,并高效选举出新的Leader,对外提供高可用服务的。
同时,我将通过一个日志复制整体流程图,为你介绍etcd如何保障各节点数据一致性,并介绍Raft算法为了确保数据一致性、完整性,对Leader选举和日志复制所增加的一系列安全规则。希望通过这节课,让你了解etcd在节点故障、网络分区等异常场景下是如何基于Raft算法实现高可用、数据强一致的。
如何避免单点故障
在介绍Raft算法之前,我们首先了解下它的诞生背景,Raft解决了分布式系统什么痛点呢?
首先我们回想下,早期我们使用的数据存储服务,它们往往是部署在单节点上的。但是单节点存在单点故障,一宕机就整个服务不可用,对业务影响非常大。
随后,为了解决单点问题,软件系统工程师引入了数据复制技术,实现多副本。通过数据复制方案,一方面我们可以提高服务可用性,避免单点故障。另一方面,多副本可以提升读吞吐量、甚至就近部署在业务所在的地理位置,降低访问延迟。
多副本复制是如何实现的呢?
多副本常用的技术方案主要有主从复制和去中心化复制。主从复制,又分为全同步复制、异步复制、半同步复制,比如MySQL/Redis单机主备版就基于主从复制实现的。
全同步复制是指主收到一个写请求后,必须等待全部从节点确认返回后,才能返回给客户端成功。因此如果一个从节点故障,整个系统就会不可用。这种方案为了保证多副本的一致性,而牺牲了可用性,一般使用不多。
异步复制是指主收到一个写请求后,可及时返回给client,异步将请求转发给各个副本,若还未将请求转发到副本前就故障了,则可能导致数据丢失,但是可用性是最高的。
半同步复制介于全同步复制、异步复制之间,它是指主收到一个写请求后,至少有一个副本接收数据后,就可以返回给客户端成功,在数据一致性、可用性上实现了平衡和取舍。
跟主从复制相反的就是去中心化复制,它是指在一个n副本节点集群中,任意节点都可接受写请求,但一个成功的写入需要w个节点确认,读取也必须查询至少r个节点。
你可以根据实际业务场景对数据一致性的敏感度,设置合适w/r参数。比如你希望每次写入后,任意client都能读取到新值,如果n是3个副本,你可以将w和r设置为2,这样当你读两个节点时候,必有一个节点含有最近写入的新值,这种读我们称之为法定票数读(quorum read)。
AWS的Dynamo系统就是基于去中心化的复制算法实现的。它的优点是节点角色都是平等的,降低运维复杂度,可用性更高。但是缺陷是去中心化复制,势必会导致各种写入冲突,业务需要关注冲突处理。
从以上分析中,为了解决单点故障,从而引入了多副本。但基于复制算法实现的数据库,为了保证服务可用性,大多数提供的是最终一致性,总而言之,不管是主从复制还是异步复制,都存在一定的缺陷。
如何解决以上复制算法的困境呢?
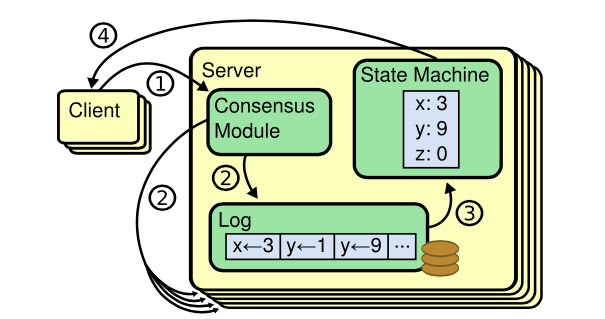
答案就是共识算法,它最早是基于复制状态机背景下提出来的。 下图是复制状态机的结构(引用自Raft paper), 它由共识模块、日志模块、状态机组成。通过共识模块保证各个节点日志的一致性,然后各个节点基于同样的日志、顺序执行指令,最终各个复制状态机的结果实现一致。
共识算法的祖师爷是Paxos, 但是由于它过于复杂,难于理解,工程实践上也较难落地,导致在工程界落地较慢。standford大学的Diego提出的Raft算法正是为了可理解性、易实现而诞生的,它通过问题分解,将复杂的共识问题拆分成三个子问题,分别是:
- Leader选举,Leader故障后集群能快速选出新Leader;
- 日志复制, 集群只有Leader能写入日志, Leader负责复制日志到Follower节点,并强制Follower节点与自己保持相同;
- 安全性,一个任期内集群只能产生一个Leader、已提交的日志条目在发生Leader选举时,一定会存在更高任期的新Leader日志中、各个节点的状态机应用的任意位置的日志条目内容应一样等。
下面我以实际场景为案例,分别和你深入讨论这三个子问题,看看Raft是如何解决这三个问题,以及在etcd中的应用实现。
Leader选举
当etcd server收到client发起的put hello写请求后,KV模块会向Raft模块提交一个put提案,我们知道只有集群Leader才能处理写提案,如果此时集群中无Leader, 整个请求就会超时。
那么Leader是怎么诞生的呢?Leader crash之后其他节点如何竞选呢?
首先在Raft协议中它定义了集群中的如下节点状态,任何时刻,每个节点肯定处于其中一个状态:
- Follower,跟随者, 同步从Leader收到的日志,etcd启动的时候默认为此状态;
- Candidate,竞选者,可以发起Leader选举;
- Leader,集群领导者, 唯一性,拥有同步日志的特权,需定时广播心跳给Follower节点,以维持领导者身份。
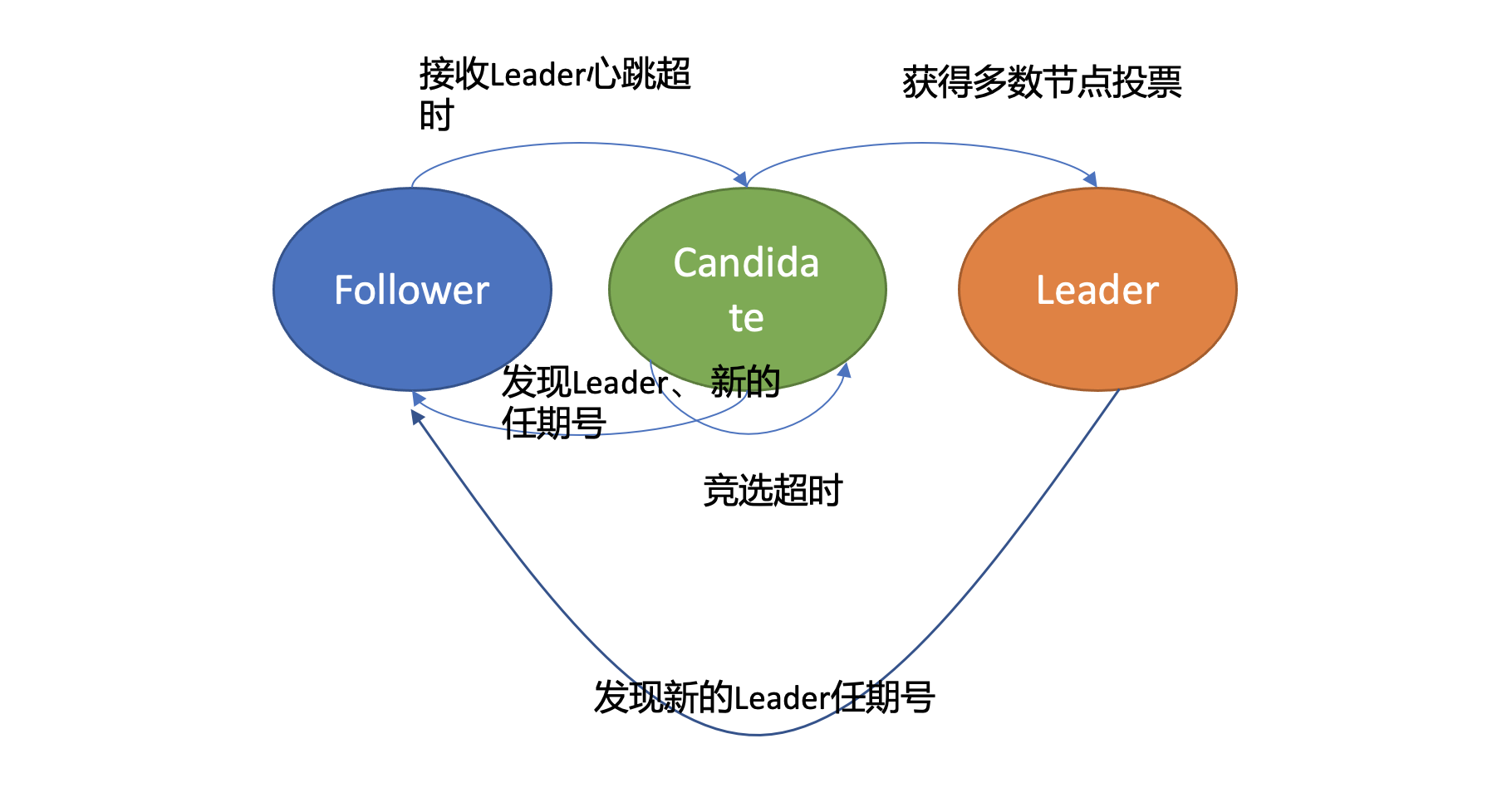
上图是节点状态变化关系图,当Follower节点接收Leader节点心跳消息超时后,它会转变成Candidate节点,并可发起竞选Leader投票,若获得集群多数节点的支持后,它就可转变成Leader节点。
下面我以Leader crash场景为案例,给你详细介绍一下etcd Leader选举原理。
假设集群总共3个节点,A节点为Leader,B、C节点为Follower。
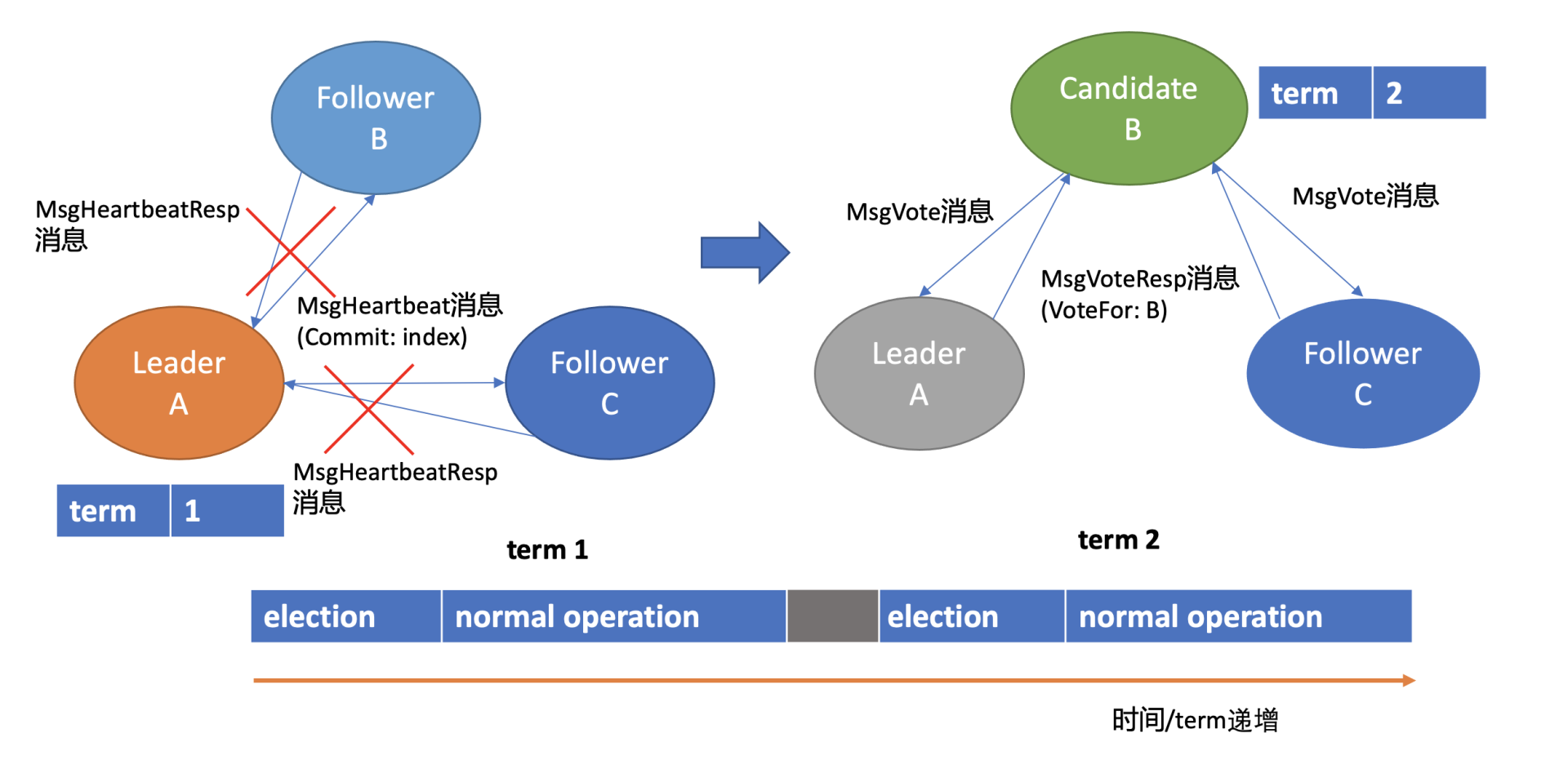
如上Leader选举图左边部分所示, 正常情况下,Leader节点会按照心跳间隔时间,定时广播心跳消息(MsgHeartbeat消息)给Follower节点,以维持Leader身份。 Follower收到后回复心跳应答包消息(MsgHeartbeatResp消息)给Leader。
细心的你可能注意到上图中的Leader节点下方有一个任期号(term), 它具有什么样的作用呢?
这是因为Raft将时间划分成一个个任期,任期用连续的整数表示,每个任期从一次选举开始,赢得选举的节点在该任期内充当Leader的职责,随着时间的消逝,集群可能会发生新的选举,任期号也会单调递增。
通过任期号,可以比较各个节点的数据新旧、识别过期的Leader等,它在Raft算法中充当逻辑时钟,发挥着重要作用。
了解完正常情况下Leader维持身份的原理后,我们再看异常情况下,也就Leader crash后,etcd是如何自愈的呢?
如上Leader选举图右边部分所示,当Leader节点异常后,Follower节点会接收Leader的心跳消息超时,当超时时间大于竞选超时时间后,它们会进入Candidate状态。
这里要提醒下你,etcd默认心跳间隔时间(heartbeat-interval)是100ms, 默认竞选超时时间(election timeout)是1000ms, 你需要根据实际部署环境、业务场景适当调优,否则就很可能会频繁发生Leader选举切换,导致服务稳定性下降,后面我们实践篇会再详细介绍。
进入Candidate状态的节点,会立即发起选举流程,自增任期号,投票给自己,并向其他节点发送竞选Leader投票消息(MsgVote)。
C节点收到Follower B节点竞选Leader消息后,这时候可能会出现如下两种情况:
- 第一种情况是C节点判断B节点的数据至少和自己一样新、B节点任期号大于C当前任期号、并且C未投票给其他候选者,就可投票给B。这时B节点获得了集群多数节点支持,于是成为了新的Leader。
- 第二种情况是,恰好C也心跳超时超过竞选时间了,它也发起了选举,并投票给了自己,那么它将拒绝投票给B,这时谁也无法获取集群多数派支持,只能等待竞选超时,开启新一轮选举。Raft为了优化选票被瓜分导致选举失败的问题,引入了随机数,每个节点等待发起选举的时间点不一致,优雅的解决了潜在的竞选活锁,同时易于理解。
Leader选出来后,它什么时候又会变成Follower状态呢? 从上面的状态转换关系图中你可以看到,如果现有Leader发现了新的Leader任期号,那么它就需要转换到Follower节点。A节点crash后,再次启动成为Follower,假设因为网络问题无法连通B、C节点,这时候根据状态图,我们知道它将不停自增任期号,发起选举。等A节点网络异常恢复后,那么现有Leader收到了新的任期号,就会触发新一轮Leader选举,影响服务的可用性。
然而A节点的数据是远远落后B、C的,是无法获得集群Leader地位的,发起的选举无效且对集群稳定性有伤害。
那如何避免以上场景中的无效的选举呢?
在etcd 3.4中,etcd引入了一个PreVote参数(默认false),可以用来启用PreCandidate状态解决此问题,如下图所示。Follower在转换成Candidate状态前,先进入PreCandidate状态,不自增任期号, 发起预投票。若获得集群多数节点认可,确定有概率成为Leader才能进入Candidate状态,发起选举流程。
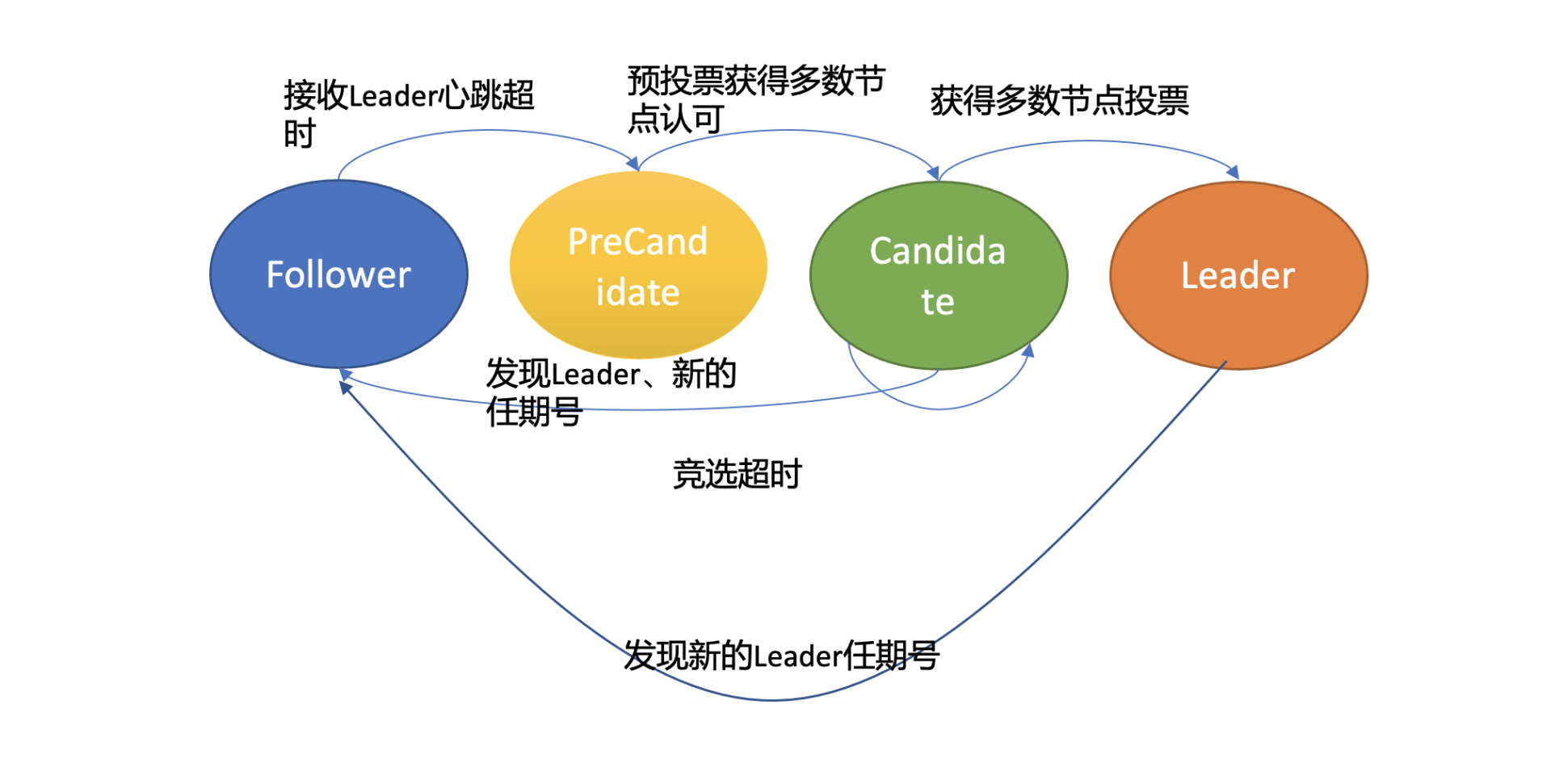
因A节点数据落后较多,预投票请求无法获得多数节点认可,因此它就不会进入Candidate状态,导致集群重新选举。
这就是Raft Leader选举核心原理,使用心跳机制维持Leader身份、触发Leader选举,etcd基于它实现了高可用,只要集群一半以上节点存活、可相互通信,Leader宕机后,就能快速选举出新的Leader,继续对外提供服务。
日志复制
假设在上面的Leader选举流程中,B成为了新的Leader,它收到put提案后,它是如何将日志同步给Follower节点的呢? 什么时候它可以确定一个日志条目为已提交,通知etcdserver模块应用日志条目指令到状态机呢?
这就涉及到Raft日志复制原理,为了帮助你理解日志复制的原理,下面我给你画了一幅Leader收到put请求后,向Follower节点复制日志的整体流程图,简称流程图,在图中我用序号给你标识了核心流程。
我将结合流程图、后面的Raft的日志图和你简要分析Leader B收到put hello为world的请求后,是如何将此请求同步给其他Follower节点的。
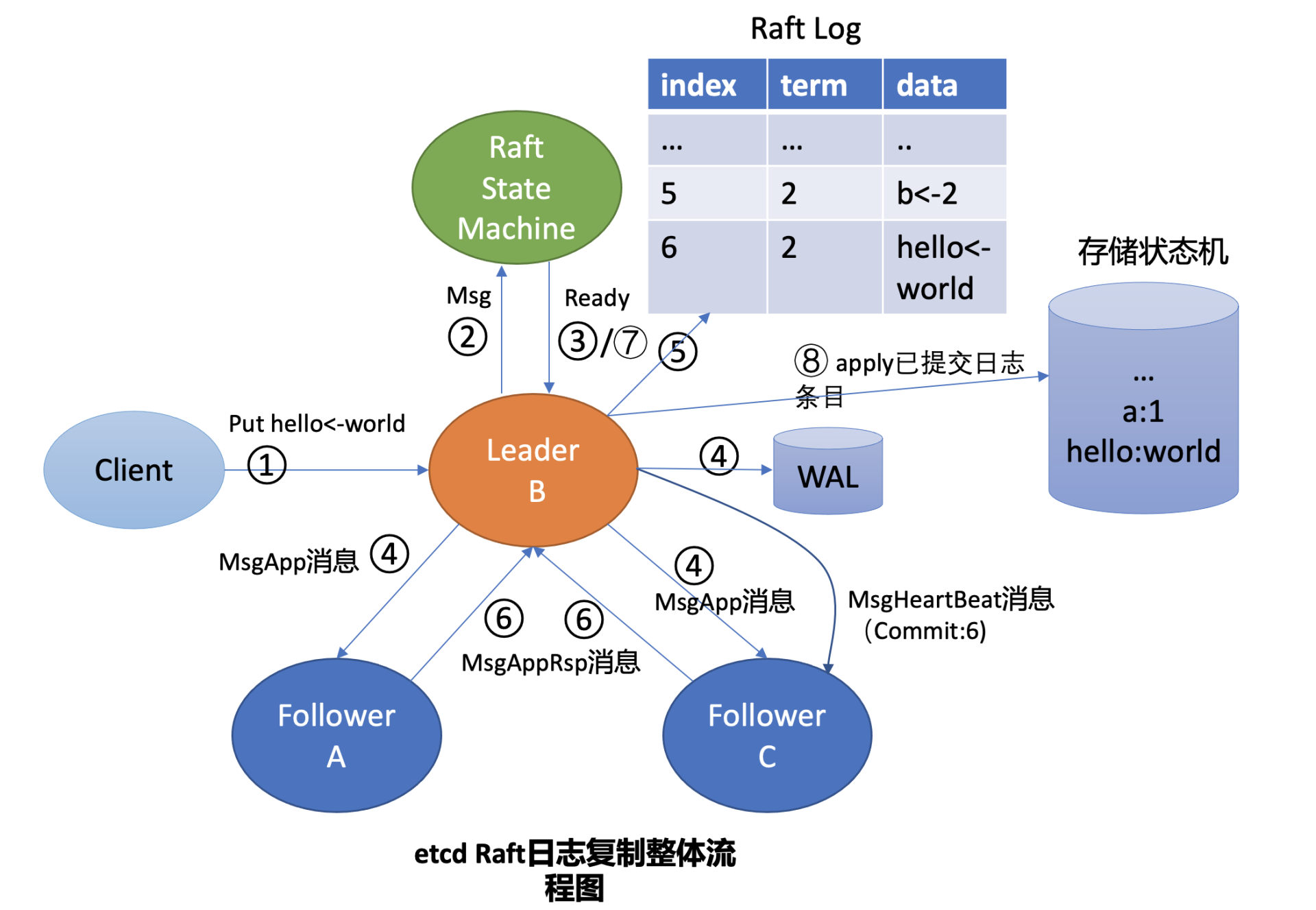
首先Leader收到client的请求后,etcdserver的KV模块会向Raft模块提交一个put hello为world提案消息(流程图中的序号2流程), 它的消息类型是MsgProp。
Leader的Raft模块获取到MsgProp提案消息后,为此提案生成一个日志条目,追加到未持久化、不稳定的Raft日志中,随后会遍历集群Follower列表和进度信息,为每个Follower生成追加(MsgApp)类型的RPC消息,此消息中包含待复制给Follower的日志条目。
这里就出现两个疑问了。第一,Leader是如何知道从哪个索引位置发送日志条目给Follower,以及Follower已复制的日志最大索引是多少呢?第二,日志条目什么时候才会追加到稳定的Raft日志中呢?Raft模块负责持久化吗?
首先我来给你介绍下什么是Raft日志。下图是Raft日志复制过程中的日志细节图,简称日志图1。
在日志图中,最上方的是日志条目序号/索引,日志由有序号标识的一个个条目组成,每个日志条目内容保存了Leader任期号和提案内容。最开始的时候,A节点是Leader,任期号为1,A节点crash后,B节点通过选举成为新的Leader, 任期号为2。
日志图1描述的是hello日志条目未提交前的各节点Raft日志状态。
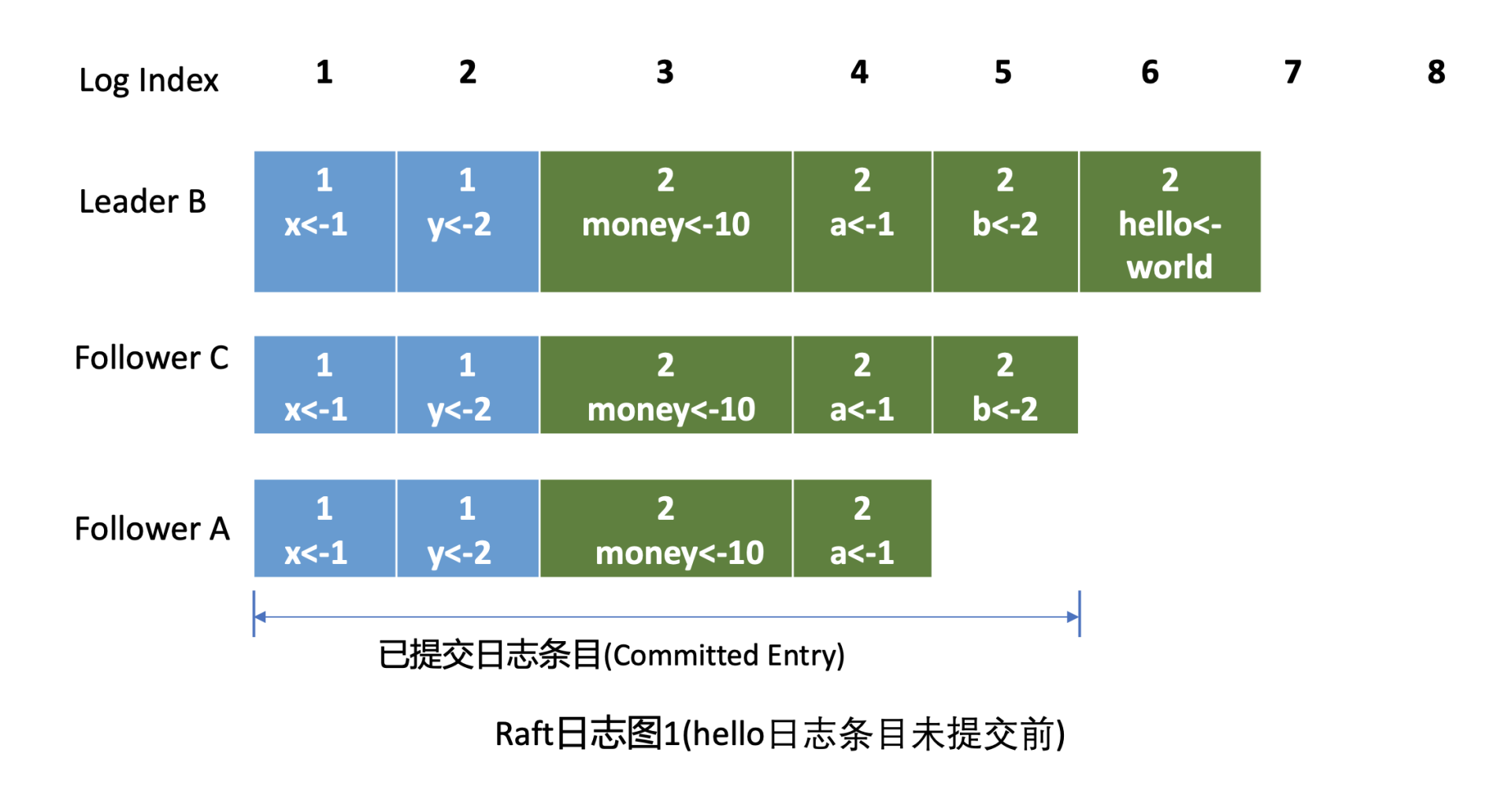
我们现在就可以来回答第一个疑问了。Leader会维护两个核心字段来追踪各个Follower的进度信息,一个字段是NextIndex, 它表示Leader发送给Follower节点的下一个日志条目索引。一个字段是MatchIndex, 它表示Follower节点已复制的最大日志条目的索引,比如上面的日志图1中C节点的已复制最大日志条目索引为5,A节点为4。
我们再看第二个疑问。etcd Raft模块设计实现上抽象了网络、存储、日志等模块,它本身并不会进行网络、存储相关的操作,上层应用需结合自己业务场景选择内置的模块或自定义实现网络、存储、日志等模块。
上层应用通过Raft模块的输出接口(如Ready结构),获取到待持久化的日志条目和待发送给Peer节点的消息后(如上面的MsgApp日志消息),需持久化日志条目到自定义的WAL模块,通过自定义的网络模块将消息发送给Peer节点。
日志条目持久化到稳定存储中后,这时候你就可以将日志条目追加到稳定的Raft日志中。即便这个日志是内存存储,节点重启时也不会丢失任何日志条目,因为WAL模块已持久化此日志条目,可通过它重建Raft日志。
etcd Raft模块提供了一个内置的内存存储(MemoryStorage)模块实现,etcd使用的就是它,Raft日志条目保存在内存中。网络模块并未提供内置的实现,etcd基于HTTP协议实现了peer节点间的网络通信,并根据消息类型,支持选择pipeline、stream等模式发送,显著提高了网络吞吐量、降低了延时。
解答完以上两个疑问后,我们继续分析etcd是如何与Raft模块交互,获取待持久化的日志条目和发送给peer节点的消息。
正如刚刚讲到的,Raft模块输入是Msg消息,输出是一个Ready结构,它包含待持久化的日志条目、发送给peer节点的消息、已提交的日志条目内容、线性查询结果等Raft输出核心信息。
etcdserver模块通过channel从Raft模块获取到Ready结构后(流程图中的序号3流程),因B节点是Leader,它首先会通过基于HTTP协议的网络模块将追加日志条目消息(MsgApp)广播给Follower,并同时将待持久化的日志条目持久化到WAL文件中(流程图中的序号4流程),最后将日志条目追加到稳定的Raft日志存储中(流程图中的序号5流程)。
各个Follower收到追加日志条目(MsgApp)消息,并通过安全检查后,它会持久化消息到WAL日志中,并将消息追加到Raft日志存储,随后会向Leader回复一个应答追加日志条目(MsgAppResp)的消息,告知Leader当前已复制的日志最大索引(流程图中的序号6流程)。
Leader收到应答追加日志条目(MsgAppResp)消息后,会将Follower回复的已复制日志最大索引更新到跟踪Follower进展的Match Index字段,如下面的日志图2中的Follower C MatchIndex为6,Follower A为5,日志图2描述的是hello日志条目提交后的各节点Raft日志状态。
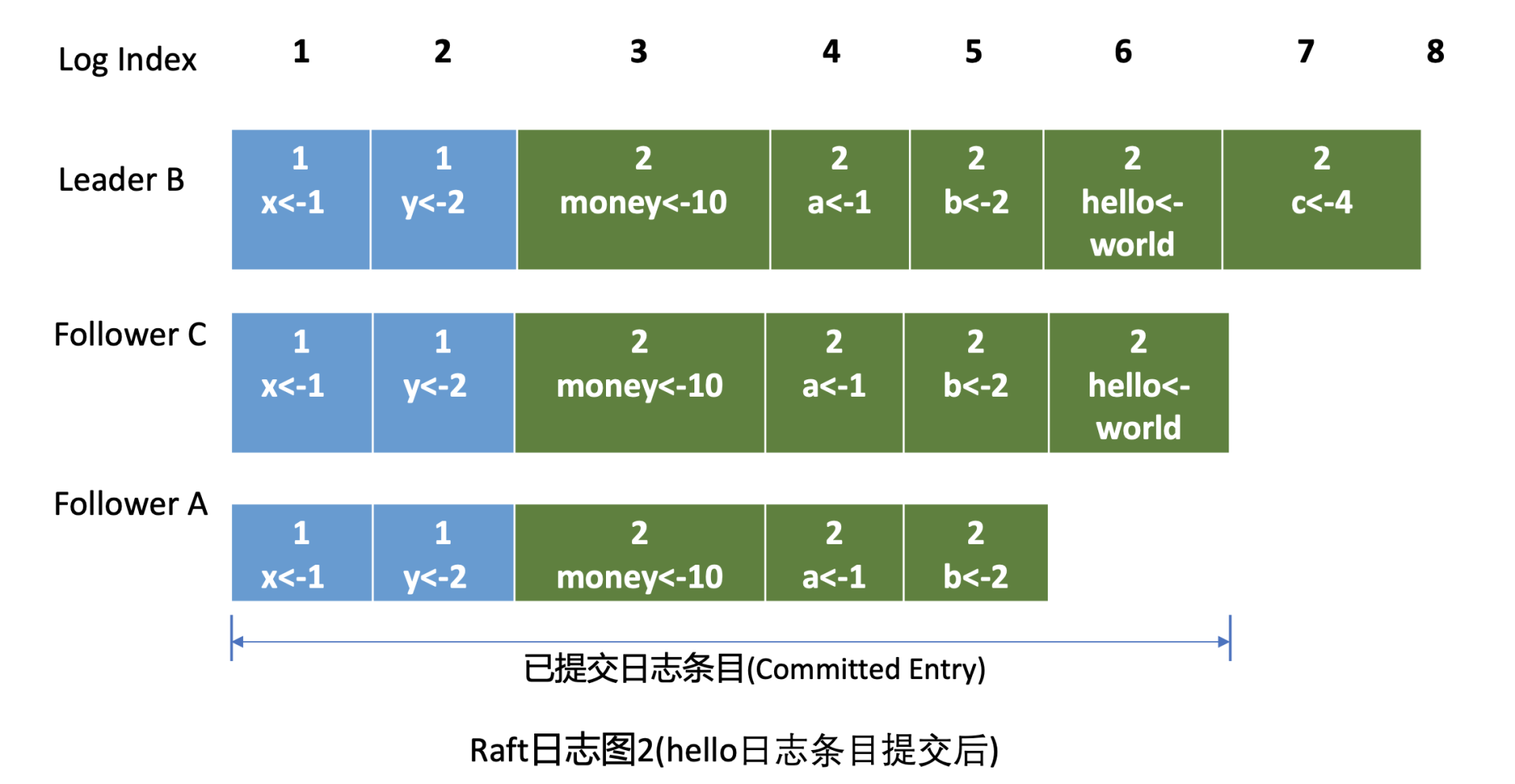
最后Leader根据Follower的MatchIndex信息,计算出一个位置,如果这个位置已经被一半以上节点持久化,那么这个位置之前的日志条目都可以被标记为已提交。
在我们这个案例中日志图2里6号索引位置之前的日志条目已被多数节点复制,那么他们状态都可被设置为已提交。Leader可通过在发送心跳消息(MsgHeartbeat)给Follower节点时,告知它已经提交的日志索引位置。
最后各个节点的etcdserver模块,可通过channel从Raft模块获取到已提交的日志条目(流程图中的序号7流程),应用日志条目内容到存储状态机(流程图中的序号8流程),返回结果给client。
通过以上流程,Leader就完成了同步日志条目给Follower的任务,一个日志条目被确定为已提交的前提是,它需要被Leader同步到一半以上节点上。以上就是etcd Raft日志复制的核心原理。
安全性
介绍完Leader选举和日志复制后,最后我们再来看看Raft是如何保证安全性的。
如果在上面的日志图2中,Leader B在应用日志指令put hello为world到状态机,并返回给client成功后,突然crash了,那么Follower A和C是否都有资格选举成为Leader呢?
从日志图2中我们可以看到,如果A成为了Leader那么就会导致数据丢失,因为它并未含有刚刚client已经写入成功的put hello为world指令。
Raft算法如何确保面对这类问题时不丢数据和各节点数据一致性呢?
这就是Raft的第三个子问题需要解决的。Raft通过给选举和日志复制增加一系列规则,来实现Raft算法的安全性。
选举规则
当节点收到选举投票的时候,需检查候选者的最后一条日志中的任期号,若小于自己则拒绝投票。如果任期号相同,日志却比自己短,也拒绝为其投票。
比如在日志图2中,Folllower A和C任期号相同,但是Follower C的数据比Follower A要长,那么在选举的时候,Follower C将拒绝投票给A, 因为它的数据不是最新的。
同时,对于一个给定的任期号,最多只会有一个leader被选举出来,leader的诞生需获得集群一半以上的节点支持。每个节点在同一个任期内只能为一个节点投票,节点需要将投票信息持久化,防止异常重启后再投票给其他节点。
通过以上规则就可防止日志图2中的Follower A节点成为Leader。
日志复制规则
在日志图2中,Leader B返回给client成功后若突然crash了,此时可能还并未将6号日志条目已提交的消息通知到Follower A和C,那么如何确保6号日志条目不被新Leader删除呢? 同时在etcd集群运行过程中,Leader节点若频繁发生crash后,可能会导致Follower节点与Leader节点日志条目冲突,如何保证各个节点的同Raft日志位置含有同样的日志条目?
以上各类异常场景的安全性是通过Raft算法中的Leader完全特性和只附加原则、日志匹配等安全机制来保证的。
Leader完全特性是指如果某个日志条目在某个任期号中已经被提交,那么这个条目必然出现在更大任期号的所有Leader中。
Leader只能追加日志条目,不能删除已持久化的日志条目(只附加原则),因此Follower C成为新Leader后,会将前任的6号日志条目复制到A节点。
为了保证各个节点日志一致性,Raft算法在追加日志的时候,引入了一致性检查。Leader在发送追加日志RPC消息时,会把新的日志条目紧接着之前的条目的索引位置和任期号包含在里面。Follower节点会检查相同索引位置的任期号是否与Leader一致,一致才能追加,这就是日志匹配特性。它本质上是一种归纳法,一开始日志空满足匹配特性,随后每增加一个日志条目时,都要求上一个日志条目信息与Leader一致,那么最终整个日志集肯定是一致的。
通过以上的Leader选举限制、Leader完全特性、只附加原则、日志匹配等安全特性,Raft就实现了一个可严格通过数学反证法、归纳法证明的高可用、一致性算法,为etcd的安全性保驾护航。
小结
最后我们来小结下今天的内容。我从如何避免单点故障说起,给你介绍了分布式系统中实现多副本技术的一系列方案,从主从复制到去中心化复制、再到状态机、共识算法,让你了解了各个方案的优缺点,以及主流存储产品的选择。
Raft虽然诞生晚,但它却是共识算法里面在工程界应用最广泛的。它将一个复杂问题拆分成三个子问题,分别是Leader选举、日志复制和安全性。
Raft通过心跳机制、随机化等实现了Leader选举,只要集群半数以上节点存活可相互通信,etcd就可对外提供高可用服务。
Raft日志复制确保了etcd多节点间的数据一致性,我通过一个etcd日志复制整体流程图为你详细介绍了etcd写请求从提交到Raft模块,到被应用到状态机执行的各个流程,剖析了日志复制的核心原理,即一个日志条目只有被Leader同步到一半以上节点上,此日志条目才能称之为成功复制、已提交。Raft的安全性,通过对Leader选举和日志复制增加一系列规则,保证了整个集群的一致性、完整性。
思考题
哪些场景会出现Follower日志与Leader冲突,我们知道etcd WAL模块只能持续追加日志条目,那冲突后Follower是如何删除无效的日志条目呢?
03思考题答案
在上一节课中,我给大家留了一个思考题:expensive request是否影响写请求性能。要搞懂这个问题,我们得回顾下etcd读写性能优化历史。
在etcd 3.0中,线性读请求需要走一遍Raft协议持久化到WAL日志中,因此读性能非常差,写请求肯定也会被影响。
在etcd 3.1中,引入了ReadIndex机制提升读性能,读请求无需再持久化到WAL中。
在etcd 3.2中, 优化思路转移到了MVCC/boltdb模块,boltdb的事务锁由粗粒度的互斥锁,优化成读写锁,实现"N reads or 1 write"的并行,同时引入了buffer来提升吞吐量。问题就出在这个buffer,读事务会加读锁,写事务结束时要升级锁更新buffer,但是expensive request导致读事务长时间持有锁,最终导致写请求超时。
在etcd 3.4中,实现了全并发读,创建读事务的时候会全量拷贝buffer, 读写事务不再因为buffer阻塞,大大缓解了expensive request对etcd性能的影响。尤其是Kubernetes List Pod等资源场景来说,etcd稳定性显著提升。在后面的实践篇中,我会和你再次深入讨论以上问题。
05 鉴权:如何保护你的数据安全?
不知道你有没有过这样的困惑,当你使用etcd存储业务敏感数据、多租户共享使用同etcd集群的时候,应该如何防止匿名用户访问你的etcd数据呢?多租户场景又如何最小化用户权限分配,防止越权访问的?
etcd鉴权模块就是为了解决以上痛点而生。
那么etcd是如何实现多种鉴权机制和细粒度的权限控制的?在实现鉴权模块的过程中最核心的挑战是什么?又该如何确保鉴权的安全性以及提升鉴权性能呢?
今天这节课,我将为你介绍etcd的鉴权模块,深入剖析etcd如何解决上面的这些痛点和挑战。希望通过这节课,帮助你掌握etcd鉴权模块的设计、实现精要,了解各种鉴权方案的优缺点。你能在实际应用中,根据自己的业务场景、安全诉求,选择合适的方案保护你的etcd数据安全。同时,你也可以参考其设计、实现思想应用到自己业务的鉴权系统上。
整体架构
在详细介绍etcd的认证、鉴权实现细节之前,我先给你从整体上介绍下etcd鉴权体系。
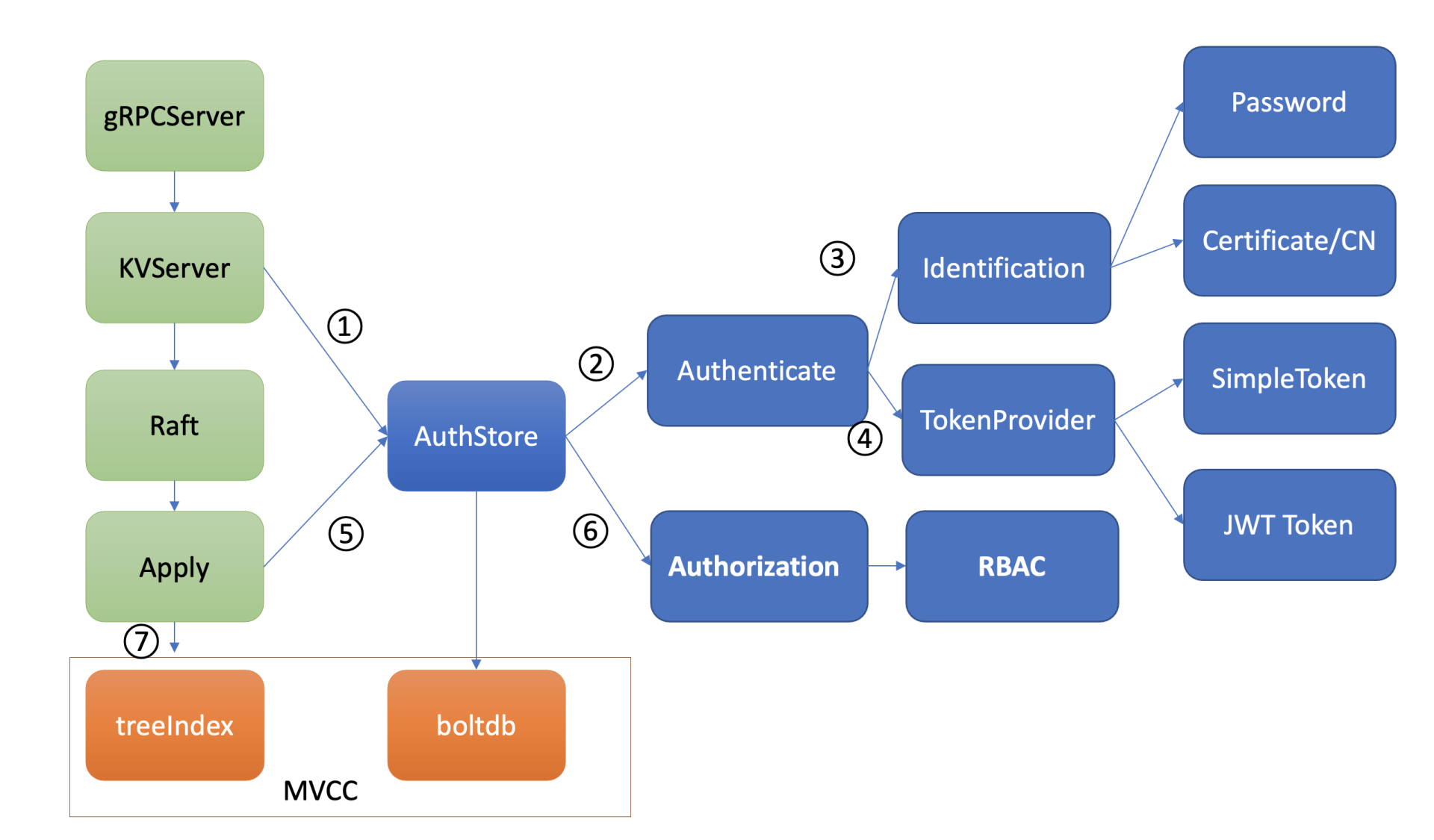
etcd鉴权体系架构由控制面和数据面组成。
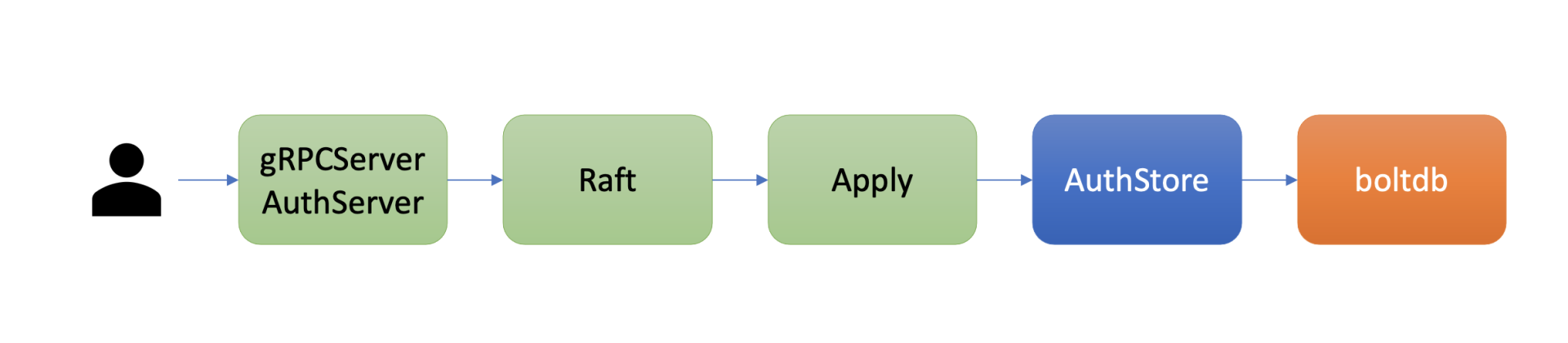
上图是是etcd鉴权体系控制面,你可以通过客户端工具etcdctl和鉴权API动态调整认证、鉴权规则,AuthServer收到请求后,为了确保各节点间鉴权元数据一致性,会通过Raft模块进行数据同步。
当对应的Raft日志条目被集群半数以上节点确认后,Apply模块通过鉴权存储(AuthStore)模块,执行日志条目的内容,将规则存储到boltdb的一系列"鉴权表"里面。
下图是数据面鉴权流程,由认证和授权流程组成。认证的目的是检查client的身份是否合法、防止匿名用户访问等。目前etcd实现了两种认证机制,分别是密码认证和证书认证。
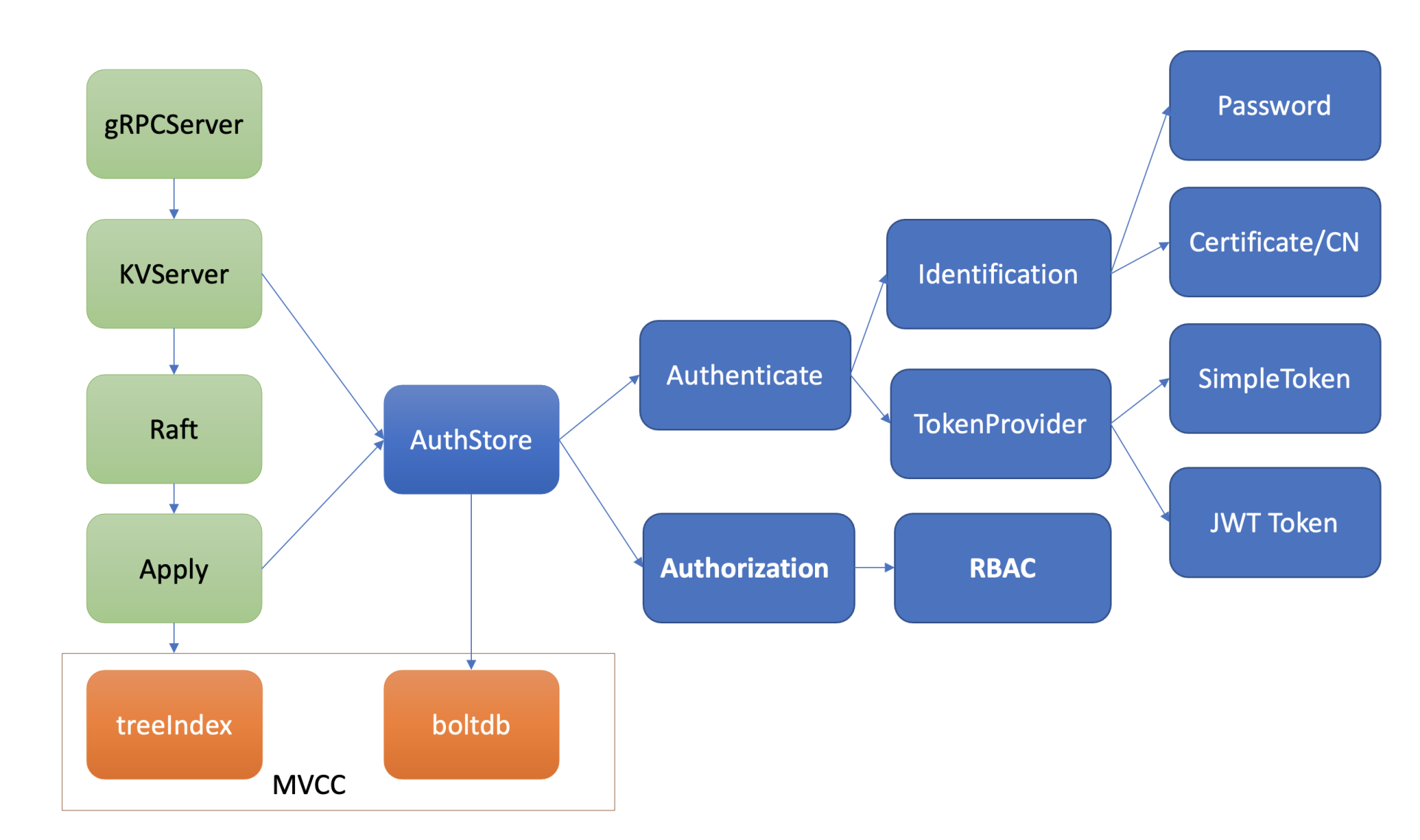
认证通过后,为了提高密码认证性能,会分配一个Token(类似我们生活中的门票、通信证)给client,client后续其他请求携带此Token,server就可快速完成client的身份校验工作。
实现分配Token的服务也有多种,这是TokenProvider所负责的,目前支持SimpleToken和JWT两种。
通过认证后,在访问MVCC模块之前,还需要通过授权流程。授权的目的是检查client是否有权限操作你请求的数据路径,etcd实现了RBAC机制,支持为每个用户分配一个角色,为每个角色授予最小化的权限。
好了,etcd鉴权体系的整个流程讲完了,下面我们就以第三节课中提到的put hello命令为例,给你深入分析以上鉴权体系是如何进行身份认证来防止匿名访问的,又是如何实现细粒度的权限控制以防止越权访问的。
认证
首先我们来看第一个问题,如何防止匿名用户访问你的etcd数据呢?
解决方案当然是认证用户身份。那etcd提供了哪些机制来验证client身份呢?
正如我整体架构中给你介绍的,etcd目前实现了两种机制,分别是用户密码认证和证书认证,下面我分别给你介绍这两种机制在etcd中如何实现,以及这两种机制各自的优缺点。
密码认证
首先我们来讲讲用户密码认证。etcd支持为每个用户分配一个账号名称、密码。密码认证在我们生活中无处不在,从银行卡取款到微信、微博app登录,再到核武器发射,密码认证应用及其广泛,是最基础的鉴权的方式。
但密码认证存在两大难点,它们分别是如何保障密码安全性和提升密码认证性能。
如何保障密码安全性
我们首先来看第一个难点:如何保障密码安全性。
也许刚刚毕业的你会说直接明文存储,收到用户鉴权请求的时候,检查用户请求中密码与存储中是否一样,不就可以了吗? 这种方案的确够简单,但你是否想过,若存储密码的文件万一被黑客脱库了,那么所有用户的密码都将被泄露,进而可能会导致重大数据泄露事故。
也许你又会说,自己可以奇思妙想构建一个加密算法,然后将密码翻译下,比如将密码中的每个字符按照字母表序替换成字母后的第XX个字母。然而这种加密算法,它是可逆的,一旦被黑客识别到规律,还原出你的密码后,脱库后也将导致全部账号数据泄密。
那么是否我们用一种不可逆的加密算法就行了呢?比如常见的MD5,SHA-1,这方案听起来似乎有点道理,然而还是不严谨,因为它们的计算速度非常快,黑客可以通过暴力枚举、字典、彩虹表等手段,快速将你的密码全部破解。
LinkedIn在2012年的时候650万用户密码被泄露,黑客3天就暴力破解出90%用户的密码,原因就是LinkedIn仅仅使用了SHA-1加密算法。
那应该如何进一步增强不可逆hash算法的破解难度?
一方面我们可以使用安全性更高的hash算法,比如SHA-256,它输出位数更多、计算更加复杂且耗CPU。
另一方面我们可以在每个用户密码hash值的计算过程中,引入一个随机、较长的加盐(salt)参数,它可以让相同的密码输出不同的结果,这让彩虹表破解直接失效。
彩虹表是黑客破解密码的一种方法之一,它预加载了常用密码使用MD5/SHA-1计算的hash值,可通过hash值匹配快速破解你的密码。
最后我们还可以增加密码hash值计算过程中的开销,比如循环迭代更多次,增加破解的时间成本。
etcd的鉴权模块如何安全存储用户密码?
etcd的用户密码存储正是融合了以上讨论的高安全性hash函数(Blowfish encryption algorithm)、随机的加盐salt、可自定义的hash值计算迭代次数cost。
下面我将通过几个简单etcd鉴权API,为你介绍密码认证的原理。
首先你可以通过如下的auth enable命令开启鉴权,注意etcd会先要求你创建一个root账号,它拥有集群的最高读写权限。
bash
$ etcdctl user add root:root
User root created
$ etcdctl auth enable
Authentication Enabled启用鉴权后,这时client发起如下put hello操作时, etcd server会返回"user name is empty"错误给client,就初步达到了防止匿名用户访问你的etcd数据目的。 那么etcd server是在哪里做的鉴权的呢?
bash
$ etcdctl put hello world
Error: etcdserver: user name is emptyetcd server收到put hello请求的时候,在提交到Raft模块前,它会从你请求的上下文中获取你的用户身份信息。如果你未通过认证,那么在状态机应用put命令的时候,检查身份权限的时候发现是空,就会返回此错误给client。
下面我通过鉴权模块的user命令,给etcd增加一个alice账号。我们一起来看看etcd鉴权模块是如何基于我上面介绍的技术方案,来安全存储alice账号信息。
bash
$ etcdctl user add alice:alice --user root:root
User alice created鉴权模块收到此命令后,它会使用bcrpt库的blowfish算法,基于明文密码、随机分配的salt、自定义的cost、迭代多次计算得到一个hash值,并将加密算法版本、salt值、cost、hash值组成一个字符串,作为加密后的密码。
最后,鉴权模块将用户名alice作为key,用户名、加密后的密码作为value,存储到boltdb的authUsers bucket里面,完成一个账号创建。
当你使用alice账号访问etcd的时候,你需要先调用鉴权模块的Authenticate接口,它会验证你的身份合法性。
那么etcd如何验证你密码正确性的呢?
鉴权模块首先会根据你请求的用户名alice,从boltdb获取加密后的密码,因此hash值包含了算法版本、salt、cost等信息,因此可以根据你请求中的明文密码,计算出最终的hash值,若计算结果与存储一致,那么身份校验通过。
如何提升密码认证性能
通过以上的鉴权安全性的深入分析,我们知道身份验证这个过程开销极其昂贵,那么问题来了,如何避免频繁、昂贵的密码计算匹配,提升密码认证的性能呢?
这就是密码认证的第二个难点,如何保证性能。
想想我们办理港澳通行证的时候,流程特别复杂,需要各种身份证明、照片、指纹信息,办理成功后,下发通信证,每次过关你只需要刷下通信证即可,高效而便捷。
那么,在软件系统领域如果身份验证通过了后,我们是否也可以返回一个类似通信证的凭据给client,后续请求携带通信证,只要通行证合法且在有效期内,就无需再次鉴权了呢?
是的,etcd也有类似这样的凭据。当etcd server验证用户密码成功后,它就会返回一个Token字符串给client,用于表示用户的身份。后续请求携带此Token,就无需再次进行密码校验,实现了通信证的效果。
etcd目前支持两种Token,分别为Simple Token和JWT Token。
Simple Token
Simple Token实现正如名字所言,简单。
Simple Token的核心原理是当一个用户身份验证通过后,生成一个随机的字符串值Token返回给client,并在内存中使用map存储用户和Token映射关系。当收到用户的请求时, etcd会从请求中获取Token值,转换成对应的用户名信息,返回给下层模块使用。
Token是你身份的象征,若此Token泄露了,那你的数据就可能存在泄露的风险。etcd是如何应对这种潜在的安全风险呢?
etcd生成的每个Token,都有一个过期时间TTL属性,Token过期后client需再次验证身份,因此可显著缩小数据泄露的时间窗口,在性能上、安全性上实现平衡。
在etcd v3.4.9版本中,Token默认有效期是5分钟,etcd server会定时检查你的Token是否过期,若过期则从map数据结构中删除此Token。
不过你要注意的是,Simple Token字符串本身并未含任何有价值信息,因此client无法及时、准确获取到Token过期时间。所以client不容易提前去规避因Token失效导致的请求报错。
从以上介绍中,你觉得Simple Token有哪些不足之处?为什么etcd社区仅建议在开发、测试环境中使用Simple Token呢?
首先它是有状态的,etcd server需要使用内存存储Token和用户名的映射关系。
其次,它的可描述性很弱,client无法通过Token获取到过期时间、用户名、签发者等信息。
etcd鉴权模块实现的另外一个Token Provider方案JWT,正是为了解决这些不足之处而生。
JWT Token
JWT是Json Web Token缩写, 它是一个基于JSON的开放标准(RFC 7519)定义的一种紧凑、独立的格式,可用于在身份提供者和服务提供者间,传递被认证的用户身份信息。它由Header、Payload、Signature三个对象组成, 每个对象都是一个JSON结构体。
第一个对象是Header,它包含alg和typ两个字段,alg表示签名的算法,etcd支持RSA、ESA、PS系列,typ表示类型就是JWT。
json
{
"alg": "RS256",
"typ": "JWT"
}第二对象是Payload,它表示载荷,包含用户名、过期时间等信息,可以自定义添加字段。
json
{
"username": username,
"revision": revision,
"exp": time.Now().Add(t.ttl).Unix(),
}第三个对象是签名,首先它将header、payload使用base64 url编码,然后将编码后的
字符串用"."连接在一起,最后用我们选择的签名算法比如RSA系列的私钥对其计算签名,输出结果即是Signature。
bash
signature=RSA256(
base64UrlEncode(header) + "." +
base64UrlEncode(payload),
key)JWT就是由base64UrlEncode(header).base64UrlEncode(payload).signature组成。
为什么说JWT是独立、紧凑的格式呢?
从以上原理介绍中我们知道,它是无状态的。JWT Token自带用户名、版本号、过期时间等描述信息,etcd server不需要保存它,client可方便、高效的获取到Token的过期时间、用户名等信息。它解决了Simple Token的若干不足之处,安全性更高,etcd社区建议大家在生产环境若使用了密码认证,应使用JWT Token( --auth-token 'jwt'),而不是默认的Simple Token。
在给你介绍完密码认证实现过程中的两个核心挑战,密码存储安全和性能的解决方案之后,你是否对密码认证的安全性、性能还有所担忧呢?
接下来我给你介绍etcd的另外一种高性能、更安全的鉴权方案,x509证书认证。
证书认证
密码认证一般使用在client和server基于HTTP协议通信的内网场景中。当对安全有更高要求的时候,你需要使用HTTPS协议加密通信数据,防止中间人攻击和数据被篡改等安全风险。
HTTPS是利用非对称加密实现身份认证和密钥协商,因此使用HTTPS协议的时候,你需要使用CA证书给client生成证书才能访问。
那么一个client证书包含哪些信息呢?使用证书认证的时候,etcd server如何知道你发送的请求对应的用户名称?
我们可以使用下面的openssl命令查看client证书的内容,下图是一个x509 client证书的内容,它含有证书版本、序列号、签名算法、签发者、有效期、主体名等信息,我们重点要关注的是主体名中的CN字段。
在etcd中,如果你使用了HTTPS协议并启用了client证书认证(--client-cert-auth),它会取CN字段作为用户名,在我们的案例中,alice就是client发送请求的用户名。
bash
openssl x509 -noout -text -in client.pem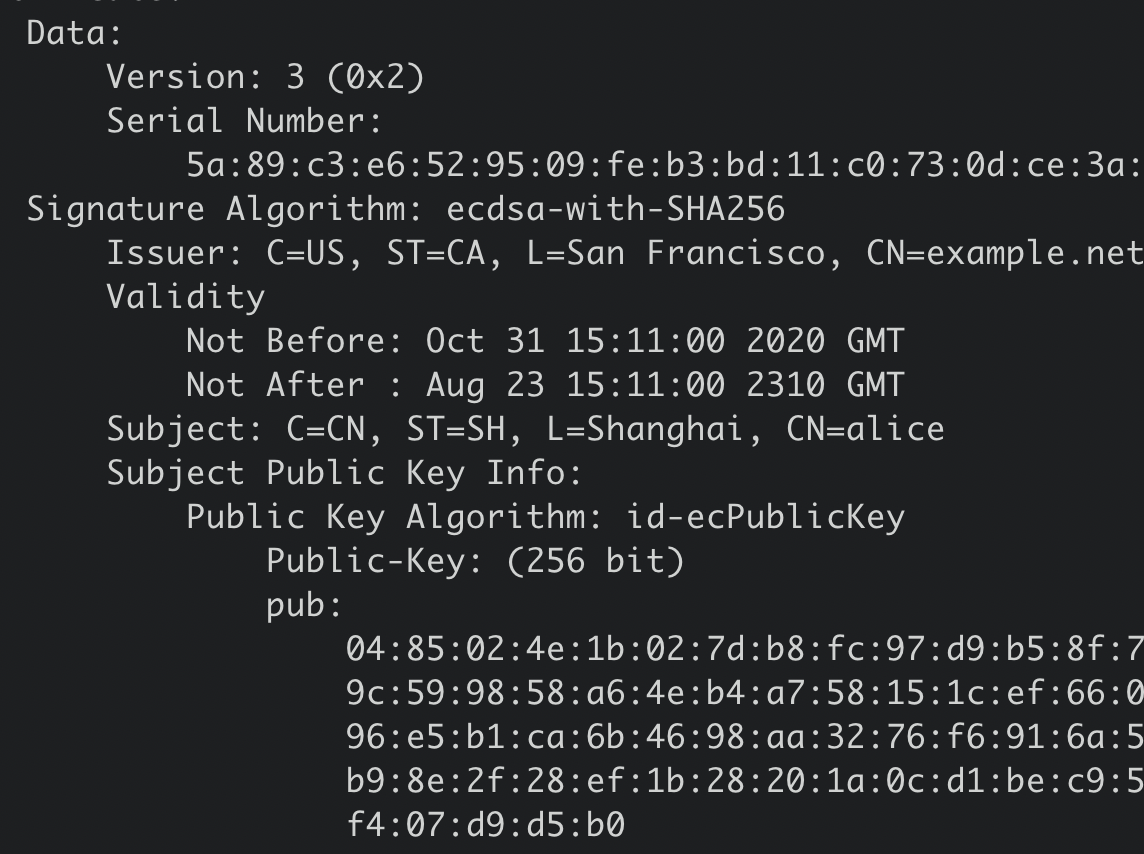
证书认证在稳定性、性能上都优于密码认证。
稳定性上,它不存在Token过期、使用更加方便、会让你少踩坑,避免了不少Token失效而触发的Bug。性能上,证书认证无需像密码认证一样调用昂贵的密码认证操作(Authenticate请求),此接口支持的性能极低,后面实践篇会和你深入讨论。
授权
当我们使用如上创建的alice账号执行put hello操作的时候,etcd却会返回如下的"etcdserver: permission denied"无权限错误,这是为什么呢?
bash
$ etcdctl put hello world --user alice:alice
Error: etcdserver: permission denied这是因为开启鉴权后,put请求命令在应用到状态机前,etcd还会对发出此请求的用户进行权限检查, 判断其是否有权限操作请求的数据。常用的权限控制方法有ACL(Access Control List)、ABAC(Attribute-based access control)、RBAC(Role-based access control),etcd实现的是RBAC机制。
RBAC
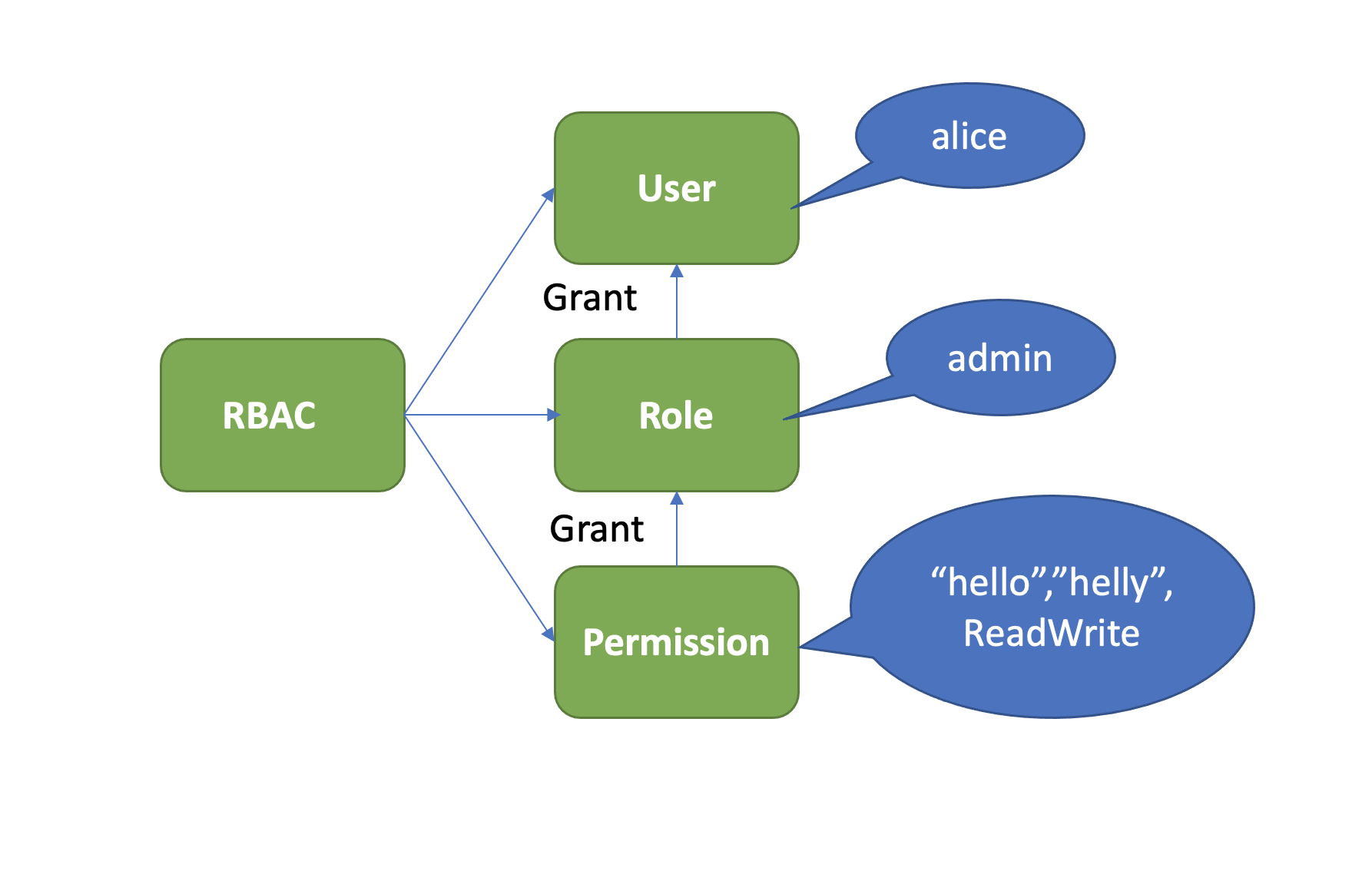
什么是基于角色权限的控制系统(RBAC)呢?
它由下图中的三部分组成,User、Role、Permission。User表示用户,如alice。Role表示角色,它是权限的赋予对象。Permission表示具体权限明细,比如赋予Role对key范围在key,KeyEnd数据拥有什么权限。目前支持三种权限,分别是READ、WRITE、READWRITE。
下面我们通过etcd的RBAC机制,给alice用户赋予一个可读写hello,helly数据范围的读写权限, 如何操作呢?
按照上面介绍的RBAC原理,首先你需要创建一个role,这里我们命名为admin,然后新增了一个可读写hello,helly数据范围的权限给admin角色,并将admin的角色的权限授予了用户alice。详细如下:
bash
$ #创建一个admin role
etcdctl role add admin --user root:root
Role admin created
# #分配一个可读写[hello,helly]范围数据的权限给admin role
$ etcdctl role grant-permission admin readwrite hello helly --user root:root
Role admin updated
# 将用户alice和admin role关联起来,赋予admin权限给user
$ etcdctl user grant-role alice admin --user root:root
Role admin is granted to user alice然后当你再次使用etcdctl执行put hello命令时,鉴权模块会从boltdb查询alice用户对应的权限列表。
因为有可能一个用户拥有成百上千个权限列表,etcd为了提升权限检查的性能,引入了区间树,检查用户操作的key是否在已授权的区间,时间复杂度仅为O(logN)。
在我们的这个案例中,很明显hello在admin角色可读写的[hello,helly)数据范围内,因此它有权限更新key hello,执行成功。你也可以尝试更新key hey,因为此key未在鉴权的数据区间内,因此etcd server会返回"etcdserver: permission denied"错误给client,如下所示。
bash
$ etcdctl put hello world --user alice:alice
OK
$ etcdctl put hey hey --user alice:alice
Error: etcdserver: permission denied小结
最后我和你总结下今天的内容,从etcd鉴权模块核心原理分析过程中,你会发现设计实现一个鉴权模块最关键的目标和挑战应该是安全、性能以及一致性。
首先鉴权目的是为了保证安全,必须防止恶意用户绕过鉴权系统、伪造、篡改、越权等行为,同时设计上要有前瞻性,做到即使被拖库也影响可控。etcd的解决方案是通过密码安全加密存储、证书认证、RBAC等机制保证其安全性。
然后,鉴权作为了一个核心的前置模块,性能上不能拖后腿,不能成为影响业务性能的一个核心瓶颈。etcd的解决方案是通过Token降低频繁、昂贵的密码验证开销,可应用在内网、小规模业务场景,同时支持使用证书认证,不存在Token过期,巧妙的取CN字段作为用户名,可满足较大规模的业务场景鉴权诉求。
接着,鉴权系统面临的业务场景是复杂的,因此权限控制系统应当具备良好的扩展性,业务可根据自己实际场景选择合适的鉴权方法。etcd的Token Provider和RBAC扩展机制,都具备较好的扩展性、灵活性。尤其是RBAC机制,让你可以精细化的控制每个用户权限,实现权限最小化分配。
最后鉴权系统元数据的存储应当是可靠的,各个节点鉴权数据应确保一致,确保鉴权行为一致性。早期etcd v2版本时,因鉴权命令未经过Raft模块,存在数据不一致的问题,在etcd v3中通过Raft模块同步鉴权指令日志指令,实现鉴权数据一致性。
思考题
最后,我给你留了一个思考题。你在使用etcd鉴权特性过程中遇到了哪些问题?又是如何解决的呢?
04思考题参考答案
04讲的思考题mckee同学给出了精彩回答,下面是他的回答。
1.哪些场景会出现 Follower 日志与 Leader 冲突?
leader崩溃的情况下可能(如老的leader可能还没有完全复制所有的日志条目),如果leader和follower出现持续崩溃会加剧这个现象。follower可能会丢失一些在新的leader中有的日志条目,他也可能拥有一些leader没有的日志条目,或者两者都发生。
2.follower如何删除无效日志?
leader处理不一致是通过强制follower直接复制自己的日志来解决。因此在follower中的冲突的日志条目会被leader的日志覆盖。leader会记录follower的日志复制进度nextIndex,如果follower在追加日志时一致性检查失败,就会拒绝请求,此时leader就会减小 nextIndex 值并进行重试,最终在某个位置让follower跟leader一致。
这里我补充下为什么WAL日志模块只通过追加,也能删除已持久化冲突的日志条目呢? 其实这里etcd在实现上采用了一些比较有技巧的方法,在WAL日志中的确没删除废弃的日志条目,你可以在其中搜索到冲突的日志条目。只是etcd加载WAL日志时,发现一个raft log index位置上有多个日志条目的时候,会通过覆盖的方式,将最后写入的日志条目追加到raft log中,实现了删除冲突日志条目效果,你如果感兴趣可以参考下我和Google ptabor关于这个问题的讨论。