分析问题
在我们的语音直播项目中,消息系统是采购的环信IM,服务端和环信采用openapi的方式进行交互,但是在业务服务中偶发的出现连接错误:
bash
net/http: request canceled while waiting for connection咨询环信回复说,未收到错误的请求,应该是我们得请求未到达,建议我们这边进行排查。
从错误信息描述,应该是在tcp建连环节出现了超时错误,由于没有更加具体的日志,无法确认是建连的哪个环节存在超时,需要增加hook来定位具体出问题的步骤。
在日常中,一般使用域名来访问网络,比如我们要打开百度搜索主页,在浏览器输入www.zhihu.com即可打开主页。访问知乎的主页,需要经历如下几个步骤:
bash
dns解析 -> tcp建连 -> tls握手 -> 数据传输 -> 页面渲染在本次问题排查中,我们需要定位到是dns解析、tcp建连、tls握手,这三个步骤是哪个环节的超时。
增加http trace排查日志
golang提供http trace的方式,方便我们注入start、done方法,用于执行每个环节的自定义代码。 这里我们注入DNS、TCPConnect、TLSHandshake的start、done共计6个方法,在start中记录开始时间,在end中打印耗时,来收集每个环节的耗时。代码如下:
Go
func newHttpTrace(ctx context.Context) *httptrace.ClientTrace {
var dnsStart, connectStart, tlsStart time.Time
trace := &httptrace.ClientTrace{
DNSStart: func(info httptrace.DNSStartInfo) {
dnsStart = time.Now()
fmt.Printf("DNS start, host:%v\n", info.Host)
},
DNSDone: func(info httptrace.DNSDoneInfo) {
notification := fmt.Sprintf("DNS done cost: %v. [addrs:%v, err:%v, Coalesced:%v]", time.Since(dnsStart), info.Addrs, info.Err, info.Coalesced)
fmt.Printf("%v\n", notification)
},
ConnectStart: func(network, addr string) {
connectStart = time.Now()
fmt.Printf("TCP connect start, network:%v, addr:%v\n", network, addr)
},
ConnectDone: func(network, addr string, err error) {
notification := fmt.Sprintf("TCP connect done, cost: %v. [network:%v, addr:%v, err:%v]", time.Since(connectStart), network, addr, err)
fmt.Printf("%v\n", notification)
},
TLSHandshakeStart: func() { tlsStart = time.Now() },
TLSHandshakeDone: func(_ tls.ConnectionState, _ error) {
notification := fmt.Sprintf("TLS handshake done cost: %v", time.Since(tlsStart))
fmt.Printf("%v\n", notification)
},
}
return trace
}使用方式,在发起http请求时,把http trace注入到request中:
Go
func do(ctx context.Context, req *http.Request) ([]byte, int, error) {
req = req.WithContext(httptrace.WithClientTrace(req.Context(), newHttpTrace(ctx)))
resp, err := c.client.Do(req)
}dns耗时
修改之后,通过线上观察,发现dns解析耗时不稳定,偶尔会有2s的高耗时,而我们配置的请求总耗时只有2s。

简单说明一下DNS解析是什么:域名 → IP地址 的转换过程。 核心流程:
咨询过基础架构的老师,公司的coreDNS会做dns结果缓存,ttl是60s,那服务端的dns解析会先查询本地DNS缓存,向coreDNS查询,最后在向公网DNS查询。基础架构老师做了测试,公网DNS偶发的出现超时问题,概率不确定,但是问题确实存在。
建议我们做dns本地缓存,但是这并不解决问题,因为如果缓存都失效了,只要向公网DNS查询结果,就有概率发生超时。
DNS解析的路径:
-> k8s集群的coreDNS,查询缓存(ttl是60s)
-> 缓存失效,回源公网dns服务器(该步骤是超时问题的原因)
ps:如果想了解coreDNS,可以deepseek。
优化方案
分析日志发现,dns解析的高耗时不会连续的出现,即使是同时发起的连接,也不是都出现dns解析超时(有点怀疑是DNS公网劫持的问题,不确定)。所以只要指定一个dns超时时间,在发生超时立即返回然后重试,大概率可以规避掉这个问题。
优化一版http client配置,上线观察观察。具体的配置如下:
Go
// setDefaults 设置默认值
func (config *ClientConfig) setDefaults() {
timeout := config.Timeout
if timeout == 0 {
timeout = 2 * time.Second
}
// 设置默认值
if config.TCPTimeout == 0 {
config.TCPTimeout = 500 * time.Millisecond
}
if config.KeepAlive == 0 {
config.KeepAlive = 10 * time.Second
}
if config.MaxIdleConns == 0 {
config.MaxIdleConns = 6
}
if config.MaxIdleConnsPerHost == 0 {
config.MaxIdleConnsPerHost = 3
}
if config.MaxConnsPerHost == 0 {
config.MaxConnsPerHost = 6
}
if config.IdleConnTimeout == 0 {
config.IdleConnTimeout = 90 * time.Second
}
if config.TLSHandshakeTimeout == 0 {
config.TLSHandshakeTimeout = 500 * time.Millisecond
}
if config.ResponseHeaderTimeout == 0 {
config.ResponseHeaderTimeout = timeout / 2
}
}- TCPTimeout:连接超时时间,500ms
- TLSHandshakeTimeout:tls握手超时时间,500ms
建连阶段(包括DNS解析、TCP握手)超过500ms,会立即返回,进行下一次重试。
Go
// doWithRetry 执行请求并处理重试,支持重新构造请求体
func (c SimpleClient) doWithRetry(ctx context.Context, req *http.Request, originalBody []byte) ([]byte, int, error) {
// 第一次请求
body, statusCode, err := c.do(ctx, req)
// 检查是否需要重试
if shouldRetry(ctx, req, err) {
// 重试请求
return c.do(ctx, req)
}
return body, statusCode, err
}
func (c SimpleClient) do(ctx context.Context, req *http.Request) ([]byte, int, error) {
resp, err := c.client.Do(req)
if err != nil {
// 包含 timeout 和 请求异常
return []byte{}, 0, err
}
defer resp.Body.Close()
body, err := io.ReadAll(resp.Body)
if err != nil {
// 协议读取 err 理论不会出现
return []byte{}, resp.StatusCode, err
}
return body, resp.StatusCode, nil
}
// shouldRetry 检查是否应该重试请求
func shouldRetry(ctx context.Context, req *http.Request, err error) bool {
if err == nil {
return false
}
// TCP reset 错误需要重试
if isTcpResetError(err) {
return true
}
// DNS 或建连超时错误需要重试
if isDNSOrDialTimeoutError(err) {
fmt.Printf("请求失败重试: %s %s, err: %v\n", req.Method, req.URL.Host, err)
return true
}
return false
}
func isTcpResetError(err error) bool {
if err == nil {
return false
}
// read tcp 10.42.xx.xx:55214->xx.xx.53.xx:443: read: connection reset by peer
return strings.Contains(err.Error(), "connection reset by peer")
}
// isDNSOrDialTimeoutError 检查是否是 DNS 或建连超时错误
func isDNSOrDialTimeoutError(err error) bool {
if err == nil {
return false
}
errStr := err.Error()
// DNS 超时错误
dnsTimeoutErrors := []string{
"dial tcp: lookup zhihu.com: i/o timeout",
"dial tcp 1.1.1.1:443: i/o timeout",
"net/http: TLS handshake timeout",
}
// 检查 DNS 超时
for _, dnsErr := range dnsTimeoutErrors {
if strings.Contains(errStr, dnsErr) {
return true
}
}
return false
}超时错误:
- DNS超时:dial tcp: lookup zhihu.com: i/o timeout
- TCP握手超时:dial tcp xx.xx.xx.197:443: i/o timeout
- TLS握手超时:net/http: TLS handshake timeout
上线之后,观察两天,dns超时的问题解决了,但是有三个新的问题。
首先从日志看,第一次超时打印【请求失败重试】日志,通过trace id 追踪第二次,并没有在出现dns超时错误,至此dns超时问题已初步解决。下面详细分析一下出现的三个新问题:
- 一个新的错误,http2: timeout awaiting response headers
- 观察日志发现,每隔20s左右,连接会被主动关闭,再次发起请求需要建立新的连接
- 发现error有打印的error日志【请求失败重试】,第二次重试会返回400错误,说明请求已经发送到环信侧,该错误是环信的报错。错误代码:
html
<html>
<head><title>400 Bad Request</title></head>
<body bgcolor="white">
<center><h1>400 Bad Request</h1></center>
<hr><center>alb</center>
</body>
</html>问题1
错误信息应该是等待响应头超时,会看之前的配置,有一个ResponseHeaderTimeout,它设置为了Timeout/2=1s的时间,如果环信侧服务抖动导致接口响应超过1s,该错误就会发生。
后续把ResponseHeaderTimeout的时间配置去掉,默认永久等待,恢复正常。
问题2
原因是tcp连接被断开,新的业务请求到来需要重新建连。如果是客户端的原因,可能是tcp keepalive时间过短,一开始配置的是90s,缩短为15s还是会被断开。怀疑是被环信侧主动关闭。
咨询环信,回复说:阿里云slb的心跳间隔是15s,tcp keepalive的心跳包不算,只有业务包才算,所以只要连接空闲超过15s未发送过业务包,就会被阿里云的slb主动断开。
所以,tcp keepalive配不配置的没啥用处。
问题3
询问环信侧,回复说该错误是请求的body为空,通过服务日志发现,凡是该类错误的出现,必然是重试导致的,错误的上下文日志是:
json
[I 2025-10-10 11:08:30.054 1adefeafff873f83ec7f23deff2e81ec xhttp.go:83] [{"logger":"default"}] DNS start, host:xxxxx.com
[I 2025-10-10 11:08:30.087 1adefeafff873f83ec7f23deff2e81ec xhttp.go:87] [{"logger":"default"}] DNS done cost: 32.925355ms. [addrs:[{xxxx}], err:<nil>, Coalesced:false]
[I 2025-10-10 11:08:30.088 1adefeafff873f83ec7f23deff2e81ec xhttp.go:91] [{"logger":"default"}] TCP connect start, network:tcp, addr:xxxx:443
[E 2025-10-10 11:08:30.555 1adefeafff873f83ec7f23deff2e81ec http_segment.go:180] [{"elapsed":"500.71935ms","error.class":"Timeout","http.method":"POST","http.url":"https://xxxxx","logger":"default"}] dial tcp xxxxx:443: i/o timeout
[E 2025-10-10 11:08:30.556 1adefeafff873f83ec7f23deff2e81ec xhttp.go:146] [{"logger":"default"}] 请求失败重试: POST xxxx.com, err: Post "https://xxxx": dial tcp xxx:443: i/o timeout
[I 2025-10-10 11:08:30.556 1adefeafff873f83ec7f23deff2e81ec xhttp.go:83] [{"logger":"default"}] DNS start, host:xxxx.com
[I 2025-10-10 11:08:30.558 1adefeafff873f83ec7f23deff2e81ec xhttp.go:87] [{"logger":"default"}] DNS done cost: 2.068912ms. [addrs:[{xxxxx } {yyyyy }], err:<nil>, Coalesced:false]
[I 2025-10-10 11:08:30.558 1adefeafff873f83ec7f23deff2e81ec xhttp.go:91] [{"logger":"default"}] TCP connect start, network:tcp, addr:xxxxx:443
[I 2025-10-10 11:08:30.570 1adefeafff873f83ec7f23deff2e81ec xhttp.go:95] [{"logger":"default"}] TCP connect done, cost: 11.351552ms. [network:tcp, addr:xxxxx:443, err:<nil>]
[I 2025-10-10 11:08:30.587 1adefeafff873f83ec7f23deff2e81ec xhttp.go:100] [{"logger":"default"}] TLS handshake done cost: 16.616402ms
[E 2025-10-10 11:08:30.599 1adefeafff873f83ec7f23deff2e81ec http_segment.go:180] [{"elapsed":"42.660246ms","error.class":"Bad Request","http.method":"POST","http.status_code":400,"http.url":"https://xxxx","logger":"default"}] Bad Request所有该类型的错误,无一例外都是重试导致的,由此判断是第一次请求导致request body被读取消耗了,第二次重试读取的body为空。 现在需要排查到在哪个环节,request body被消耗了。复现问题的场景时间线:
shell
T0: client.Do(req)
T1: transport.RoundTrip(req)
T2: getConn() 获取连接
- T3: DNS 开始解析 (你的代码中有 600ms 延迟)
- T500ms: DNS 超时 (配置的 500ms 超时)
T500ms: getConn() 返回 DNS 超时错误 # 🚨 在这里失败
T500ms: transport.go:594 调用 req.closeBody()
T500ms: 重试时 Body 为空从net/http官方包,分析net/http/transport.go:591行代码,如果建连失败body会被关闭,但是body是io.NopCloser 类型,调用 closeBody 方法并不会产生影响。
公司的http耗时监控打点是注入到http.DefaultTransport中,该方法在处理请求时会被自动执行。除了公司的打点,我们还有一块是记录错误请求的中间件,也是通过注入到http.DefaultTransport的方式,这个打点在返回错误时打印了req body和resp body,伪代码如下:
Go
func WrapRoundTripper(original http.RoundTripper) http.RoundTripper {
return roundTripperFunc(func(r *http.Request) (*http.Response, error) {
ctx := r.Context()
_ = ctx
r = r.Clone(ctx)
depend := entity.NewDepend(entity.DEPEND_HTTP)
// 实际执行 http 请求
resp, err := original.RoundTrip(r)
// 统计
depend.ResponseTime = time.Now()
depend.Duration = time.Since(depend.RequestTime).Microseconds()
// 把 http 的非 200 返回也当做错误
var tmpErr = err
if err == nil && resp.StatusCode >= 400 {
tmpErr = errors.New(strconv.Itoa(resp.StatusCode))
}
// 记录异常事件
if tmpErr != nil {
var requestBody = ""
contentType := r.Header.Get("Content-Type")
if r.Body != nil && !strings.Contains(contentType, "multipart/form-data") {
reqBodyBytes, _ := io.ReadAll(r.Body)
_ = r.Body.Close()
r.Body = io.NopCloser(bytes.NewBuffer(reqBodyBytes))
requestBody = string(reqBodyBytes)
}
depend.Domain = r.Host
depend.Path = r.URL.Path + "?" + r.URL.RawQuery
depend.Method = r.Method
depend.Request = requestBody
// 获取 返回 body
if resp != nil {
var responseBody = "非 json 结构,不可展示"
cType := resp.Header.Get("Content-Type")
if resp.Body != nil && strings.Contains(cType, "application/json") {
respBodyBytes, _ := io.ReadAll(resp.Body)
_ = resp.Body.Close()
resp.Body = io.NopCloser(bytes.NewBuffer(respBodyBytes))
responseBody = string(respBodyBytes)
}
depend.Response = responseBody
}
saveDepend(depend)
}
return resp, err
})
}
type roundTripperFunc func(*http.Request) (*http.Response, error)
func (f roundTripperFunc) RoundTrip(r *http.Request) (*http.Response, error) { return f(r) }首先这块代码有个问题,request被clone了,虽然读取之后重置了body,但是原始的request的body还是被读取了,重置的只是clone的request。把r = r.Clone(ctx)一行注释掉,测试还是不好使。所以猜测传入此处的request不是最原始的那个,在RoundTrip 函数中的request可能就是个clone的。
果然,在net/http/client.go:232行代码,发现在调用 RoundTrip 之前,request被clone了一份,所以在RoundTrip 函数中,无论怎么重置request body都无济于事。
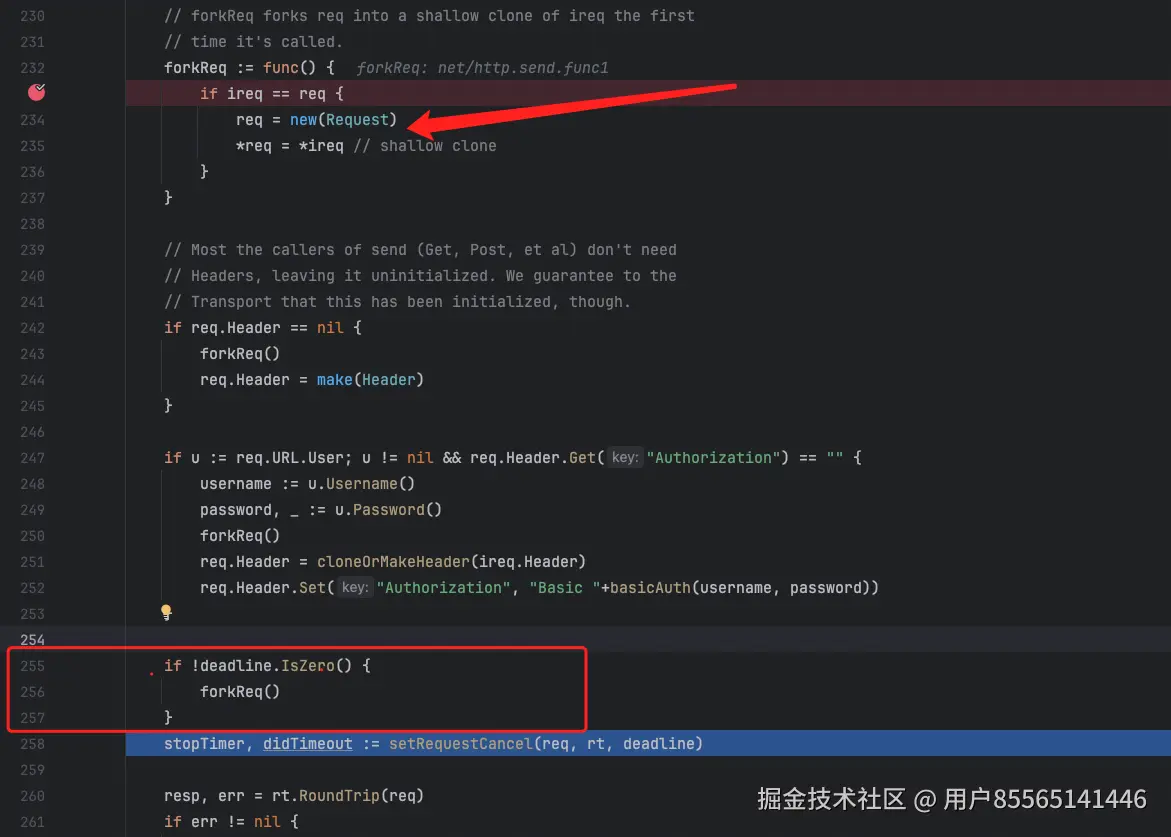
最终的解决方案,在 doWithRetry 方法中,在重试之前先把request body手动重置掉,以此来解决问题。
Go
// doWithRetry 执行请求并处理重试,支持重新构造请求体
func (c SimpleClient) doWithRetry(ctx context.Context, req *http.Request, originalBody []byte) ([]byte, int, error) {
// 第一次请求
body, statusCode, err := c.do(ctx, req)
// 检查是否需要重试
if shouldRetry(ctx, req, err) {
// 重新构造请求体,因为第一次失败时 req.Body 已经被 closeBody() 关闭
if originalBody != nil {
req.Body = io.NopCloser(bytes.NewReader(originalBody))
req.ContentLength = int64(len(originalBody))
}
// 重试请求
return c.do(ctx, req)
}
return body, statusCode, err
}