一:背景
1. 讲故事
上个月有位朋友找到我,说他们公司的程序当内存达到一定阈值(2g+)之后,业务逻辑明显变慢导致下位机超时报警,想让我看下到底怎么回事,这种问题其实抓dump比较难搞,但朋友也说了有一个增长阈值,那就让朋友抓一个 2g+ 的dump发过来看看吧,当然越大越好。
二:内存洞察分析
1. 内存里都有什么
高级调试就是一门侦查学,需要根据发现到的多处零碎信息整合出一条合理可信的证据链,先用 !address -summary 观察内存布局。
C#
0:000> !address -summary
--- Usage Summary ---------------- RgnCount ----------- Total Size -------- %ofBusy %ofTotal
Free 648 7ff6`475ce000 ( 127.962 TB) 99.97%
<unknown> 1642 8`a5283200 ( 34.581 GB) 88.93% 0.03%
Heap 5255 0`d170f000 ( 3.273 GB) 8.42% 0.00%
Image 1922 0`2906ee00 ( 656.433 MB) 1.65% 0.00%
Stack 277 0`10d40000 ( 269.250 MB) 0.68% 0.00%
Other 61 0`08228000 ( 130.156 MB) 0.33% 0.00%
TEB 92 0`000b8000 ( 736.000 kB) 0.00% 0.00%
PEB 1 0`00001000 ( 4.000 kB) 0.00% 0.00%
--- State Summary ---------------- RgnCount ----------- Total Size -------- %ofBusy %ofTotal
MEM_FREE 648 7ff6`475ce000 ( 127.962 TB) 99.97%
MEM_RESERVE 3011 8`d5107000 ( 35.329 GB) 90.86% 0.03%
MEM_COMMIT 6239 0`e391b000 ( 3.556 GB) 9.14% 0.00%
...从卦中可以看到当前提交内存是 3.5G, 其中 heap 吃了 3.2G,这就说明内存都被非托管给吃掉了,接下来就是用老办法让朋友开启 ust,再次抓到dump之后使用 !heap -s 观察NT堆的分布。
C#
0:000> !heap -s
************************************************************************************************************************
NT HEAP STATS BELOW
************************************************************************************************************************
NtGlobalFlag enables following debugging aids for new heaps:
stack back traces
LFH Key : 0xfadda8b94efde698
Termination on corruption : ENABLED
Heap Flags Reserv Commit Virt Free List UCR Virt Lock Fast
(k) (k) (k) (k) length blocks cont. heap
-------------------------------------------------------------------------------------
00000160dead0000 08000002 939860 804212 939080 112851 4562 406 279 17556 LFH
External fragmentation 14 % (4562 free blocks)
Virtual address fragmentation 14 % (406 uncommited ranges)
...
000001608b690000 08001002 1845428 1058576 1844648 16053 2856 1243 0 1786 LFH
Virtual address fragmentation 42 % (1243 uncommited ranges)
...
-------------------------------------------------------------------------------------从卦中可以看到 heap=000001608b690000 这个堆吃了 1.8G,抽了一些样本之后,发现大多都是和 cogxsd 有关,比如其中一张截图:
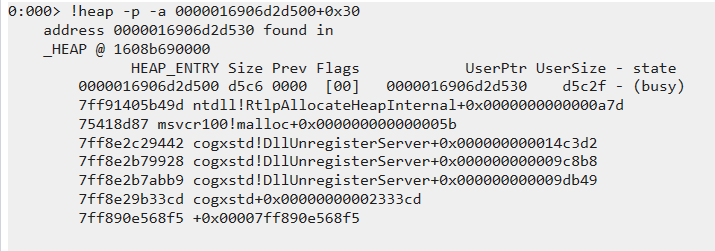
然后观察对应的托管方法。
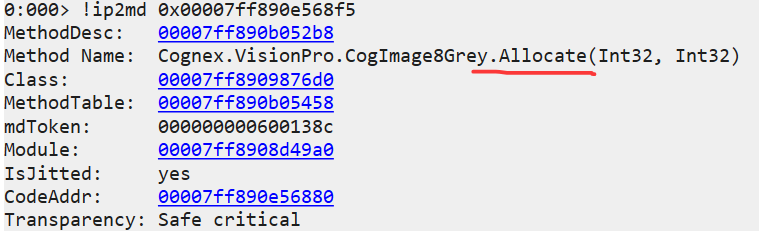
最后就是让朋友注意图片的分配方法 Allocate 的实现,比如升级 cogxsd 之类的。
2. 问题到此结束了吗
接下来的几天,朋友在这条路上没有闯出来,毕竟他的程序需要批量实时的处理图片,图片资源多是正常的,也用了很多的手段,但为什么会导致程序卡慢呢? 其实也没有完整可信的证据链,毕竟作为调试者一切都要让数据说话。
问题没有弄出来,所以我决定直击问题,而不是在内存上纠结不清,接下来就是让朋友在程序卡慢(下位机超时报警)的时候开启 perfview 跟踪,观察下程序的整体情况,朋友也是位动手能力强的能人,三下五除二就弄出来了。
3. perfview 里的真相
托管程序里有一个术语叫 STW,它是拖慢程序的一个很大的因素,所以在卡慢期间跟踪下GC情况,朋友跟踪了 12分钟,接下来打开 perfview 选择 Memory -> GCStats 选项卡,截图如下:
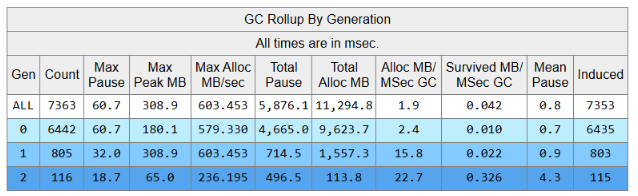
从卦中可以看到跟踪期间程序触发了 7363 次GC,fullgc 是 116次,接下来观察这 7363 次GC的触发详情,截图如下:

尼玛,简直是晕倒,所有的GC触发原因都是 InducedNotForced, 即 诱导GC,说简单点就是有人在故意调用 GC.Collect,在调试训练营里面跟大家介绍过 gc 触发的18种原因,其中 诱导GC 就是重中之重,反正也是无语了。
接下来切到 Event 事件选项卡,观察 Triggered 的调用栈,发现大量的和 Avl.Image 及 Avl.Region 的初始化有关,截图如下:
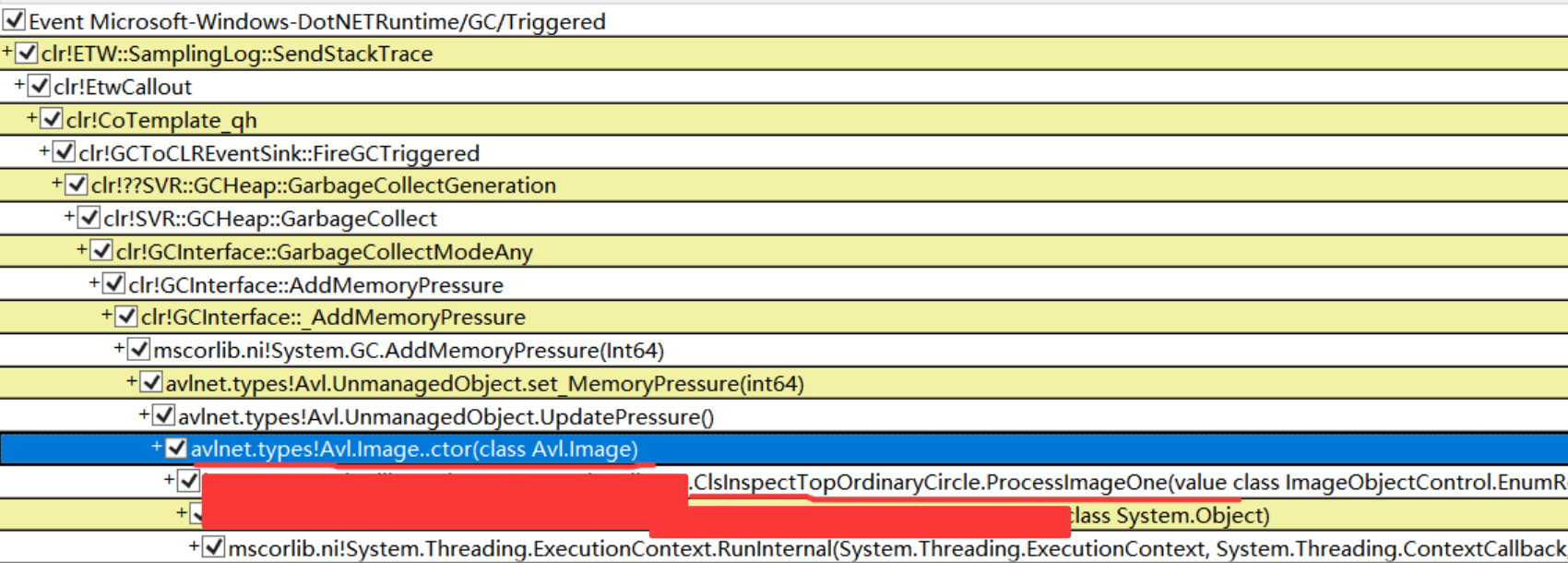
接下来寻找 ProcessImageOne 方法的源码实现,发现有不少这样的临时变量。
- Avl.Image

- Avl.Region
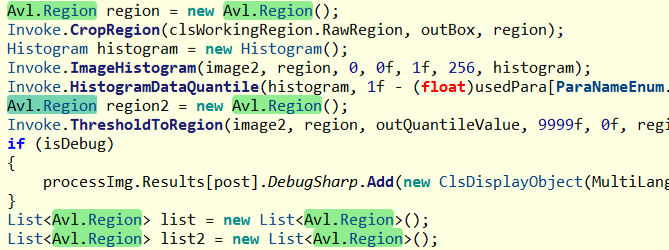
再回过头看下看托管堆上的 Avl.Image 和 Avl.Region 的数量,分别是 3w 和 11W,参考如下:
C#
0:000> !dumpheap -stat
Statistics:
MT Count TotalSize Class Name
...
00007ff890744ca8 32837 1313480 Avl.Image
...
00007ff89077b6f8 117356 4694240 Avl.Region
Total 851246 objects
Fragmented blocks larger than 0.5 MB:
Addr Size Followed by
0000016120b3eb70 0.6MB 0000016120bd7be8 Free到这里基本上整个证据链就串起来了,当 Image 和 Region 达到一定阈值时,GC触发的越来越频繁,并附带着其中的 STW 越来越多,导致程序越来越卡,引发下位机超时报警。
4. 如何解决
这种问题的常规思路就是池化处理 ,尽量减少临时 new Image 的发生导致内部的 GC 触发。
三:总结
这次生产事故还是有一定的逻辑性,这个案例也告诉我们,一定要拿数据说话,否则就会陷入误区而不能自拔。
