什么是 Tree-Shaking
Tree-Shaking 是一种删除无用代码(Dead Code Elimination) 用于现代 JavaScript 打包过程中,旨在移除那些被定义但从未被引用或使用的模块、函数或变量,从而减小最终打包产物的体积。
这个概念我们可以把它比喻为"摇一棵树":树上枯黄的叶子(即未被使用的代码)在摇动中自然脱落,而真正有用的枝叶(被引用的代码)则得以保留,这正是 Tree-Shaking 名称的由来。
Dead Code Elimination 的思想最早可追溯至 2009 年 Google 发布的Closure Compiler,该工具通过静态分析移除无效代码、重写并压缩 JavaScript,以提升执行效率和加载性能,后来 Rich Harris(Svelte 框架的作者)将这一理念引入到了现代前端工程化体系中。
2015 年,他在开发打包工具Rollup.js 时,首次提出了 Tree-Shaking 这一术语,并基于ES Modules(ESM) 的静态结构特性实现了该技术。由于 ES 模块的import和export是静态声明,在编译时即可确定依赖关系,因此工具可以进行静态分析,精准识别出哪些导出未被使用,并在打包时将其"摇掉"。 2016 年,webpack 2 引入了 Tree-Shaking 支持,使其迅速在前端社区普及。此后,包括 esbuild、Vite、Rspack等现代构建工具也都实现了更高效、更精确的 Tree-Shaking 机制,进一步推动了前端构建性能与产物优化的发展。
如何开启 Tree-Shaking
在 Rspack 中开启 Tree-Shaking 其机制与 webpack 一样,都需要满足以下两个关键前置条件:
- 将 mode 设置为 production :Rspack 在
production模式下会自动启用一系列优化策略,包括压缩、代码分割和 Tree-Shaking。开发模式(development)出于调试便利考虑,通常不会进行彻底的死代码消除; - 使用 ES modules 语法(即 import 和 export):这是实现 Tree-Shaking 的核心前提。只有基于 ES Modules 的静态模块结构,构建工具才能在编译时进行静态分析,从而准确判断哪些代码未被引用,可以安全移除。
注意:如果使用 CommonJS(
require/module.exports),则无法启用 Tree-Shaking。因为 CommonJS 是动态模块系统 ,导入和导出可以在运行时动态决定(例如通过变量拼接require(moduleName)),这使得构建工具无法在打包阶段静态推断模块依赖关系。
Rspack 默认在production模式下已开启 Tree-Shaking 支持,只要你使用的是 ESM 语法且项目配置合理,即可自动享受优化,但你也可以通过optimization字段控制其行为:
js
// rspack.config.js
module.exports = {
mode: "production", // 必须为 production 才能启用完整优化
optimization: {
providedExports: true, // 分析每个模块的导出列表(如 export { a, b })
usedExports: true, // 标记哪些导出被实际使用,未使用的将在打包时被移除
sideEffects: true, // 启用副作用分析,用于判断模块是否可安全删除
innerGraph: true, // 启用细粒度的变量依赖追踪,提升 Tree-Shaking 精度
minimize: true, // 是否使用 optimization.minimizer 中声明的压缩器对产物进行压缩
minimizer: [], // 自定义压缩器。默认使用 SwcJsMinimizerRspackPlugin
...
},
};各配置项详解:
- providedExports :分析模块中所有被
export声明的变量,构建导出清单; - usedExports :检查每个导出是否在其他模块中被
import引用。如果某个导出从未被使用,它将被标记为"未使用",并在最终打包时剔除; - sideEffects :判断模块是否有"副作用"(如执行全局配置、修改原型链等)。若模块无副作用且未被引用,整个模块可被完全移除。你也可以在
package.json中通过"sideEffects": false或数组形式显式声明无副作用的模块,帮助工具更激进地优化; - innerGraph :进一步追踪模块内部变量的引用链(例如:
export const a = b.c中b.c是否被使用),实现更细粒度的死代码消除,尤其对复杂表达式和链式调用有显著优化效果; - minimize :是否使用
optimization.minimizer中声明的压缩器对产物进行压缩; - minimizer :自定义压缩器,默认使用
SwcJsMinimizerRspackPlugin和LightningCssMinimizerRspackPlugin进行压缩。
实现原理
刚才我们介绍了开启 Tree-Shaking 所需的关键配置项(如providedExports、usedExports、sideEffects、innerGraph等)。实际上,Rspack 中 Tree-Shaking 的实现机制正是围绕这些配置展开的,整个 Tree-Shaking 过程可以分为四个关键阶段:
解析模块导出
Tree-Shaking 的第一步是识别模块中哪些符号被导出。这一步发生在编译的make阶段,具体是在模块构建过程中调用的parser_and_generator方法中。在之前的文章我们介绍过 make 阶段调用 parser_and_generator 方法的流程,你可以查看 Rspack 原理:webpack,我为什么不要你 这篇文章。为了便于理解 Tree-Shaking 在整个构建流程中的位置,我准备了如下流程图帮助你更好地理解:
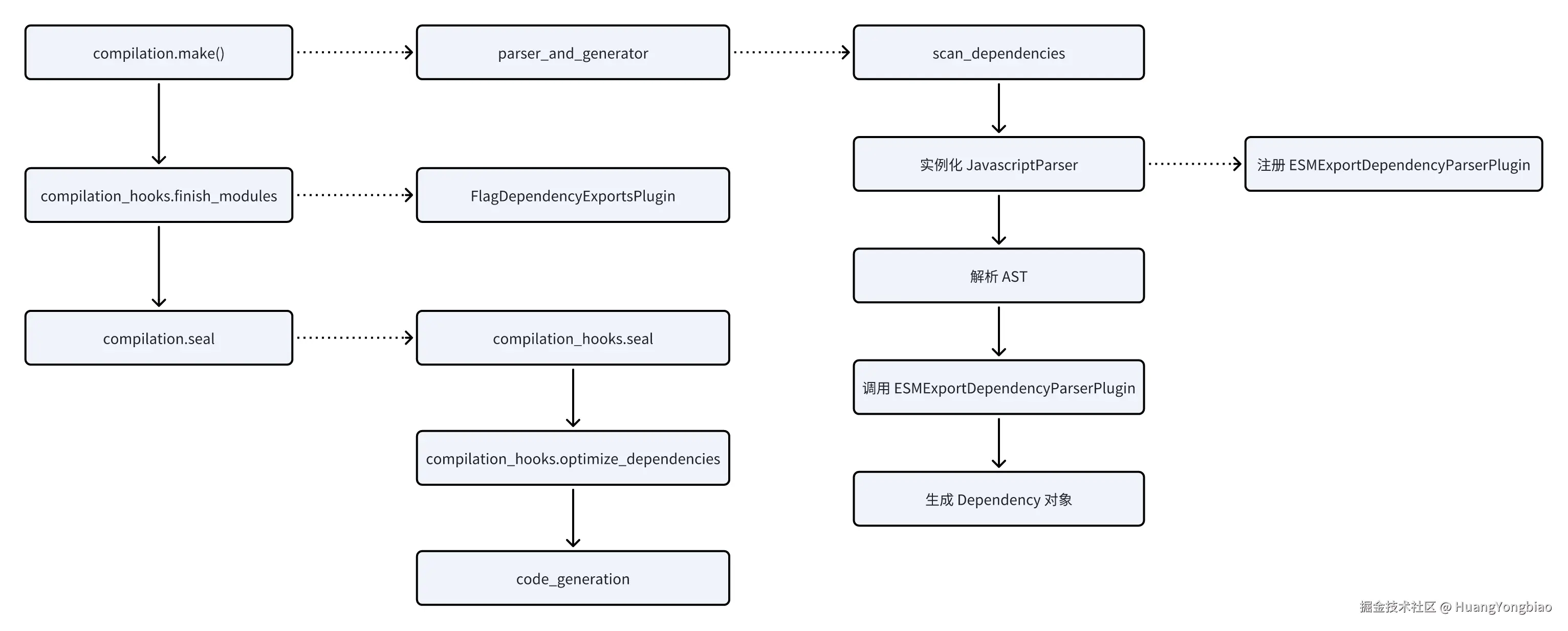
在make阶段,Rspack 会通过scan_dependencies方法对模块的源代码进行依赖扫描。这个过程的核心是使用基于 SWC 的高性能 JavaScript Parser 构建抽象语法树(AST),然后通过一系列插件来识别 ESM(ECMAScript Module)语法中的导出语句,其中最关键的插件是:ESMExportDependencyParserPlugin。
ESMExportDependencyParserPlugin的注册是在实例化JavaScriptParser的时候,该插件负责将不同的 ESM 导出语法转换为对应的Dependency 对象,从而为后续的静态分析提供结构化数据支持。不同类型的导出语句会被映射为不同类型的 Dependency 实例,规则如下:
- 当导出本地标识符(如
export { a as b })时,会生成ESMExportSpecifierDependency对象,用于记录导出名与本地变量的对应关系; - 当导出表达式或声明(如
export default function() {})时,会生成 ESMExportExpressionDependency 对象,用于描述默认导出的表达式节点; - 当导出来自其他模块的符号或整体导出(重导出(Re-export) ,如
export * from 'foo'或export { x } from 'foo')时,则创建ESMExportImportedSpecifierDependency对象以及配合ESMImportSideEffectDependency对象来建立跨模块引用,并标记可能存在的副作用。
特别说明:重导出(Re-export)的处理机制
以如下语句为例:
js
export * from './foo';这条语句看似只是转发导出,但实际上它隐含了一个导入动作,并且可能触发副作用执行。Rspack 将其等价理解为:
js
import * as _foos from './foo';
export { ..._foos };因此,在依赖图中,会同时创建两个Dependency:
- ESMImportSideEffectDependency :表示我们导入了
'./foo'模块,并且需要考虑它的副作用(例如模块顶层的执行语句); - ESMExportImportedSpecifierDependency :表示我们将来自
foo的某些或全部符号重新导出。
因此ESMImportSideEffectDependency对象就表示:我导入了foo,并且它可能有副作用需要执行。
这意味着即使没有直接引用
foo中的任何变量,只要存在export * from 'foo',Rspack 就不会对foo模块进行 Tree-Shaking,除非明确标注sideEffects: false。
ESMExportDependencyParserPlugin插件同时还会通过 InnerGraphPlugin::add_variable_usage标记变量使用信息,追踪符号引用关系:
js
fn export_specifier(
&self,
parser: &mut JavascriptParser,
statement: ExportLocal,
local_id: &Atom,
export_name: &Atom,
export_name_span: Span,
) -> Option<bool> {
InnerGraphPlugin::add_variable_usage(
parser,
local_id,
InnerGraphMapUsage::Value(export_name.clone()),
);
...
}理解起来有点抽象,这里涉及到 内部引用图(Inner Graph) 的概念,内部图(Inner Graph)状态的核心数据结构如下:
js
#[derive(Default)]
pub struct InnerGraphState {
pub(crate) inner_graph: HashMap<TopLevelSymbol, InnerGraphMapValue>,
pub(crate) usage_callback_map: HashMap<TopLevelSymbol, Vec<UsageCallback>>,
current_top_level_symbol: Option<TopLevelSymbol>,
enable: bool,
}我们来介绍下InnerGraphState内部的几个字段:
- inner_graph :存储顶级符号到内部图映射值的映射关系,使用
FxHashMap高性能数据结构; - usage_callback_map:存储每个顶级符号对应的使用回调函数列表,用于跟踪符号的使用情况,支持代码分析和优化;
- current_top_level_symbol:当前正在处理的顶级符号,在解析过程中跟踪当前处理的符号;
- enable:是否启用内部图功能,控制是否进行内部图分析。
我们来举个例子解释下:
js
// test.js
export const a = 1;
export const b = 2;
const c = a + b;
export default c;在这个test.js模块中:
a和b是命名导出;c是局部变量,但它构成了默认导出的值;c的计算依赖于a和b。
现在假设外部模块只引用了这个模块的default导出:
js
import result from './test.js';
console.log(result); // 输出 3在这种情况下,虽然a和b没有被直接引用,但由于default依赖它们,所以a和b不能被删除。InnerGraphPlugin的工作就是追踪模块内部的变量的依赖关系,记录变量之间的引用关系,以上述代码为例,InnerGraphPlugin会构建如下依赖图:
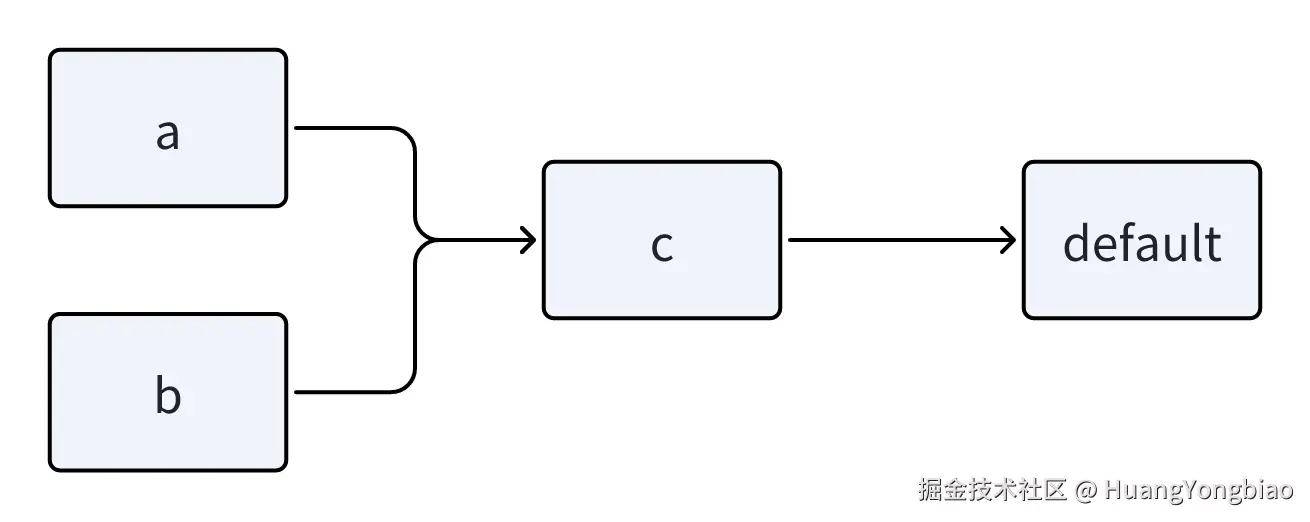
当后续进行"标记使用"阶段时,只要发现default被使用,就会沿着这张图反向追溯,将c、a、b全部标记为"活跃"(used),从而避免误删。
此功能对应配置项:innerGraph: true,启用内部引用图分析
收集模块导出信息
当所有模块完成make阶段的依赖扫描与 AST 解析后,模块依赖图(ModuleGraph) 已经基本构建完成。此时,每个模块不仅包含了自身的源码和资源信息,还通过JavascriptParser解析出了各种 ESM 导出语句,并将其转换为对应的Dependency对象(如ESMExportSpecifierDependency等)。
但这只是第一步,为了实现 Tree-Shaking,Rspack 需要弄清楚每模块到底导出了哪些符号?这些符号是否依赖于其他模块的导出?这就进入了 Tree-Shaking 流程的第二阶段:收集模块导出信息。
该阶段的核心任务是:
- 为每个模块生成一份结构化的导出描述(
ExportsInfo); - 建立跨模块的导出依赖关系图;
- 为后续的
usedExports分析和 Dead Code 删除提供数据基础。
这一过程主要由FlagDependencyExportsPlugin插件驱动,在finish_modules钩子中被触发执行。
js
impl Plugin for FlagDependencyExportsPlugin {
fn name(&self) -> &'static str {
"FlagDependencyExportsPlugin"
}
fn apply(&self, ctx: &mut rspack_core::ApplyContext<'_>) -> Result<()> {
ctx
.compilation_hooks
.finish_modules
.tap(finish_modules::new(self));
Ok(())
}
}FlagDependencyExportsPlugin会遍历当前模块的所有 Dependency,并对每一个与"导出"相关的 Dependency 调用其 .get_exports() 方法,获取一个ExportsSpec对象。
ExportsSpec的结构如下:
js
pub struct ExportsSpec {
pub exports: ExportsOfExportsSpec, // 导出哪些符号
pub priority: Option<u8>, // 优先级
pub can_mangle: Option<bool>, // 是否可压缩
pub terminal_binding: Option<bool>, // 是否终端绑定
pub from: Option<ModuleGraphConnection>, // 来源模块
pub dependencies: Option<Vec<ModuleIdentifier>>, // 依赖模块列表
pub hide_export: Option<FxHashSet<Atom>>, // 隐藏某些导出
pub exclude_exports: Option<FxHashSet<Atom>>, // 排除某些导出符号
}举个例子
- 当你写导出语句
export const a = 1,生成的Dependency对象是ESMExportSpecifierDependency,对应的ExportsSpec是{ exports: ["a"], from: None }; - 当你写导出语句
export * from "foo"生成的Dependency对象是ESMExportImportedSpecifierDependency,对应的ExportsSpec是{ exports: UnknownExports, from: foo }。
收集完所有ExportsSpec后,FlagDependencyExportsPlugin将它们合并(merge) 到一个统一的数据结构中:ExportsInfoData,ExportsInfoData是挂载在ModuleGraph中每个模块上的元数据。 执行完FlagDependencyExportsPlugin后,每个模块在ModuleGraph中都拥有一份ExportsInfoData,用于描述每个模块"导出了什么"以及"从哪导出"。
标记模块的使用情况
在完成收集模块导出信息阶段后,Rspack 已为每个模块构建了完整的ExportsInfoData,明确了"每个模块导出了什么"以及"这些导出是否依赖于其他模块"。接下来,进入 Tree-Shaking 的关键阶段:标记模块使用情况,该阶段的目标是:
- 从入口模块出发,沿着依赖图(ModuleGraph)反向追踪;
- 识别哪些导出符号被实际使用(
used); - 将未被引用的导出标记为"可删除"。
这一过程发生在seal阶段,Rspack 会触发optimize_dependencies钩子,然后触发以下两个核心插件的执行:
- SideEffectsFlagPlugin:判断模块是否具有副作用,决定是否可被 Tree-Shaking;
js
impl Plugin for SideEffectsFlagPlugin {
fn name(&self) -> &'static str {
"SideEffectsFlagPlugin"
}
fn apply(&self, ctx: &mut rspack_core::ApplyContext<'_>) -> Result<()> {
ctx
.normal_module_factory_hooks
.module
.tap(nmf_module::new(self));
ctx
.compilation_hooks
.optimize_dependencies
.tap(optimize_dependencies::new(self));
Ok(())
}
}- FlagDependencyUsagePlugin:遍历依赖图,标记具体导出符号的使用状态。
js
impl Plugin for FlagDependencyUsagePlugin {
fn apply(&self, ctx: &mut rspack_core::ApplyContext<'_>) -> Result<()> {
ctx
.compilation_hooks
.optimize_dependencies
.tap(optimize_dependencies::new(self));
Ok(())
}
}SideEffectsFlagPlugin遍历所有模块,对每个模块,查找其所属package.json中的sideEffects配置,若配置允许(如 false 或不包含该文件),则标记模块为"可摇树",否则标记为"有副作用",即使导出未被使用,也必须保留整个模块。
此功能对应配置项:sideEffects: true,启用副作用分析,用于判断模块是否可安全删除
FlagDependencyUsagePlugin从入口 entry 模块开始遍历 ModuleGraph,对每个模块调用get_exports_info获取模块的exports_info,然后遍历模块的exports_info.get_exports所有导出,调用get_referenced_exports()获取该依赖引用了哪些导出。
然后调用set_used_conditionally方法,修改exportInfo的used_in_runtime属性,标记为具体的UsageState状态(如Used、Unused、OnlyPropertiesUsed等)。
此功能对应配置项:usedExports: true,标记哪些导出被实际使用,未使用的将在打包时被移除
这一阶段完成后,Rspack 就具备了删除死代码的全部依据。接下来,进入最后一个阶段:代码生成和删除 Dead Code 阶段。
生成代码和删除 Dead Code
经过前面的收集与标记步骤后,Rspack 已经在 ModuleGraph 体系中清楚地记录了每个模块都导出了哪些值,以及每个导出值又被哪个模块所使用。
该阶段调用generate进行代码生成,Rspack 会根据导出值的使用情况生成不同的代码。
核心逻辑位于DependencyTemplate.render方法中(DependencyTemplate是一个策略模式的实现,不同的 Dependency 类型如ESMExportSpecifierDependency、ESMImportSpecifierDependency 等都有对应的 Template 实现,每个Template的render方法负责将该依赖类型转换为具体的 JavaScript 代码,并根据使用状态决定生成正常代码还是死代码注释)。
该方法会读取 ModuleGraph 中存储的exports_info,并通过调用get_used获取每个导出项在运行时的使用状态(UsageState枚举),然后根据使用状态决定是否调用get_used_name来获取实际使用的名称。UsageState枚举如下:
js
pub enum UsageState {
Unused = 0,
OnlyPropertiesUsed = 1,
NoInfo = 2,
#[default]
Unknown = 3,
Used = 4,
}- Used:导出值被完整使用,按正常逻辑生成绑定/访问代码;
- Unused :导出值未被使用,保留函数体或或生成注释占位(如
/* unused export / undefined、/ ESM default export /等),最后由 SWC 压缩清理; - OnlyPropertiesUsed:仅部分属性被使用,生成部分属性访问代码 ;
- NoInfo :使用状态未知,需要进一步分析;
- Unknown:使用状态不确定,保守处理为"可能被使用",生成正常代码。
基于上述状态,Rspack 为不同使用情况创建对应的InitFragment对象,并将其添加到TemplateContext.init_fragments数组中。随后通过render_init_fragments函数遍历该数组,将所有活跃的代码片段组合并渲染为最终的输出代码。
以上的流程理解起来有点抽象,我们抓住重点就行:Rspack 对于不同使用状态的导出会生成不同形式的代码,例如被标记为Unused的导出会生成注释形式的代码,然后依赖内置的SwcJsMinimizerRspackPlugin(基于 SWC 的高性能压缩器)进行最终压缩清理。 举个例子,unused函数为未使用的导出:
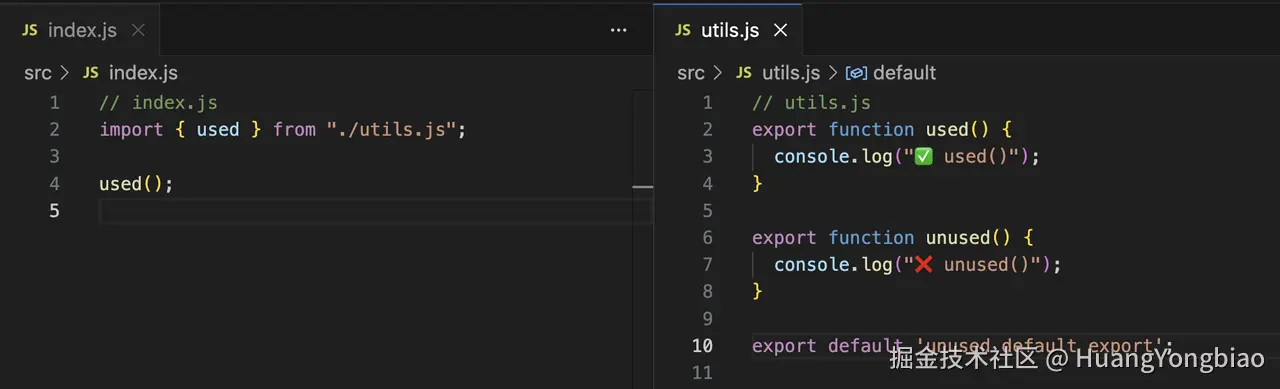
未开启minimize: false,构建生成代码如下,可以看到,对于未使用的函数声明导出会保留函数体,而对于表达式导出会生成注释:ESM default export:
总结
到此为止,Rspack Tree-Shaking 的核心流程已介绍完毕。总结来说,Rspack 的 Tree-Shaking 实现机制与 webpack 在算法层面高度一致,均基于 ES Modules 的静态结构,通过四个关键阶段:解析导出、收集信息、标记使用、生成和删除代码。其核心逻辑依赖于ModuleGraph和ExportsInfo的精细化建模,辅以sideEffects、usedExports、innerGraph等配置项实现精准控制。
那么,Rust 是否真的让 Tree-Shaking 更彻底?答案是未必。Tree-Shaking 的"彻底性"本质上取决于静态分析的精度与策略,在这方面,Rspack 并未引入全新的算法,而是继承并实现了与 webpack 相同的分析算法,因此在优化精度上与 webpack 相比是接近的。
但是,Rspack 的真正优势在于性能层面:更快的构建速度、并发与并行处理能力、零成本抽象与内存安全等,例如 Rust 的rayon库支持高效的数据并行,能在make阶段并行扫描多个模块的依赖,显著提升providedExports和usedExports的分析效率、FxHashMap高性能数据存储结构,支持更快的查找和更新。这种性能优势使得高精度的静态分析(如innerGraph)在大型项目中得以稳定、高效地运行,从而在构建中实现更可靠、更高效的 Tree-Shaking。