1. Hugging Face / ModelScope 是什么?
Hugging Face 🤗:拥抱脸 -- 构建未来的人工智能社区。
-
定位: AI界的"GitHub",专注于自然语言处理(NLP)
-
核心价值: 提供海量预训练模型、数据集和工具库
-
特点 : 国际化社区,英文资源为主

ModelScope 🏮:概览 · 魔搭社区
-
定位: 阿里巴巴推出的中文AI模型社区
-
核心价值: 专注于中文场景,提供丰富的中文预训练模型
-
特点: 对中文用户更友好,文档和模型更适合中文任务
2. 核心组件概览
2.1 模型仓库 (Model Hub)
text
Hugging Face Hub: huggingface.co/models:
ModelScope Hub: modelscope.cn/models就像手机应用商店,可以搜索下载各种AI模型
2.2 核心Python库
Hugging Face生态:
-
transformers: 核心模型库 -
datasets: 数据集管理 -
tokenizers: 分词器 -
accelerate: 分布式训练
ModelScope生态:
-
modelscope: 核心库 -
transformers(兼容): 可以无缝使用
3. 环境准备和安装
3.1 安装必要的库
bash
# 安装Hugging Face核心库
pip install transformers datasets tokenizers
# 或者安装ModelScope核心库
pip install modelscope
# 如果使用GPU,还需要安装PyTorch
pip install torch torchvision torchaudio3.2 验证安装
python
# 检查安装是否成功
import transformers
print(f"Transformers版本: {transformers.__version__}")
# 或者ModelScope
import modelscope
print(f"ModelScope版本: {modelscope.__version__}")4. 第一个示例:文本分类
4.1 使用Hugging Face
python
from transformers import pipeline
# 创建一个文本分类的管道
# pipeline会自动下载合适的模型
classifier = pipeline("sentiment-analysis")
# 使用分类器分析文本情感
result = classifier("I love this movie! It's amazing!")
print(result)
# 输出: [{'label': 'POSITIVE', 'score': 0.9998}]
# 批量处理多个文本
results = classifier([
"This is great!",
"I hate this product.",
"It's okay, not bad."
])
for result in results:
print(f"文本: {result}")4.2 使用ModelScope
python
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
# 创建情感分析管道
classifier = pipeline(Tasks.text_classification,
model='damo/nlp_structbert_sentiment-classification_chinese-base')
# 分析中文文本情感
result = classifier("这部电影真是太精彩了!演员表演出色,剧情扣人心弦。")
print(result)5. 理解Pipeline(管道)
5.1 Pipeline是什么?
Pipeline是预配置的工作流,将多个步骤封装成一个简单接口:
输入文本 → 分词 → 模型推理 → 后处理 → 输出结果
5.2 常用的Pipeline任务
python
# 1. 文本分类
classifier = pipeline("text-classification")
# 2. 文本生成
generator = pipeline("text-generation")
# 3. 命名实体识别
ner = pipeline("ner")
# 4. 问答系统
qa = pipeline("question-answering")
# 5. 翻译
translator = pipeline("translation", model="Helsinki-NLP/opus-mt-zh-en")6. 深入理解:模型、分词器、配置
6.1 三个核心组件
python
from transformers import AutoTokenizer, AutoModel, AutoConfig
# 1. 分词器 - 将文本转换为数字
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# 2. 配置 - 模型的超参数
config = AutoConfig.from_pretrained("bert-base-uncased")
# 3. 模型 - 神经网络本身
model = AutoModel.from_pretrained("bert-base-uncased")6.2 完整的使用流程
python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
# 加载模型和分词器
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
# 准备输入文本
text = "I love programming with Hugging Face!"
# 分词处理
inputs = tokenizer(text, return_tensors="pt")
print("分词结果:", inputs)
# 模型推理
with torch.no_grad():
outputs = model(**inputs)
# 处理输出
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print("预测概率:", predictions)
# 获取预测标签
predicted_class_id = predictions.argmax().item()
label = model.config.id2label[predicted_class_id]
print(f"预测结果: {label}")7. 常用模型类型介绍
7.1 编码器模型 (Encoder-only)
-
代表: BERT, RoBERTa, DistilBERT
-
用途: 文本分类、命名实体识别、情感分析
-
特点: 理解文本含义
7.2 解码器模型 (Decoder-only)
-
代表: GPT系列
-
用途: 文本生成、对话系统
-
特点: 生成连贯文本
7.3 编码器-解码器模型 (Encoder-Decoder)
-
代表: T5, BART
-
用途: 翻译、文本摘要
-
特点: 序列到序列任务
8. 如何选择适合的模型?
8.1 根据任务类型选择
python
# 不同任务对应的模型类型
task_model_mapping = {
"文本分类": ["bert-base-uncased", "distilbert-base-uncased"],
"文本生成": ["gpt2", "facebook/blenderbot-400M-distill"],
"翻译": ["Helsinki-NLP/opus-mt-zh-en", "Helsinki-NLP/opus-mt-en-zh"],
"问答": ["bert-large-uncased-whole-word-masking-finetuned-squad"],
"摘要": ["facebook/bart-large-cnn", "t5-small"],
"中文任务": ["bert-base-chinese", "hfl/chinese-bert-wwm-ext"]
}8.2 模型选择的实用技巧
python
from transformers import AutoModel, AutoTokenizer
def evaluate_model_suitability(model_name, task_type):
"""评估模型是否适合当前任务"""
try:
# 尝试加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
print(f"✅ 模型 {model_name} 加载成功")
print(f" 参数量: {sum(p.numel() for p in model.parameters()):,}")
print(f" 分词器词汇量: {tokenizer.vocab_size}")
# 检查是否支持所需功能
if task_type == "text-generation" and hasattr(model, "generate"):
print(" ✅ 支持文本生成")
else:
print(" ❌ 不支持文本生成")
except Exception as e:
print(f"❌ 模型 {model_name} 加载失败: {e}")
# 测试几个模型
evaluate_model_suitability("bert-base-uncased", "text-classification")
evaluate_model_suitability("gpt2", "text-generation")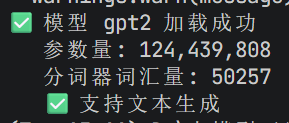
9. 分词器(Tokenizer)深度解析
9.1 分词器的工作原理
python
from transformers import AutoTokenizer
# 加载不同模型的分词器
bert_tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
gpt2_tokenizer = AutoTokenizer.from_pretrained("gpt2")
t5_tokenizer = AutoTokenizer.from_pretrained("t5-small")
text = "Hello, how are you? 你好吗?I'm doing great!"
def analyze_tokenization(tokenizer, name, text):
print(f"\n=== {name} 分词分析 ===")
# 基本分词
tokens = tokenizer.tokenize(text)
print(f"Tokens: {tokens}")
# 转换为ID
input_ids = tokenizer.encode(text)
print(f"Input IDs: {input_ids}")
# 详细的分词过程
encoding = tokenizer(
text,
return_tensors="pt",
padding=True,
truncation=True,
max_length=20,
return_attention_mask=True,
return_token_type_ids=True # 对于BERT类模型
)
print("完整编码:")
for key, value in encoding.items():
print(f" {key}: {value}")
# 解码回文本
decoded = tokenizer.decode(input_ids)
print(f"解码回文本: {decoded}")
analyze_tokenization(bert_tokenizer, "BERT", text)
analyze_tokenization(gpt2_tokenizer, "GPT-2", text)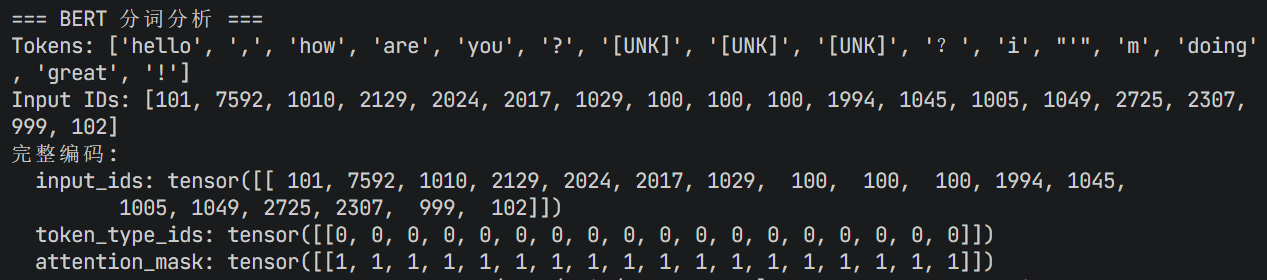

9.2 处理特殊情况的技巧
python
# 1. 处理长文本(分块处理)
def chunk_text(text, tokenizer, max_length=512):
"""将长文本分割成适合模型输入的块"""
tokens = tokenizer.encode(text)
chunks = []
for i in range(0, len(tokens), max_length):
chunk = tokens[i:i + max_length]
chunks.append(chunk)
return chunks
long_text = "这是一段很长的文本..." * 100 # 模拟长文本
chunks = chunk_text(long_text, bert_tokenizer)
print(f"将长文本分割成了 {len(chunks)} 个块")
# 2. 处理特殊符号和表情
special_text = "Hello 😊 @user #hashtag http://example.com"
tokens = bert_tokenizer.tokenize(special_text)
print(f"特殊文本分词: {tokens}")
# 3. 处理中文文本
chinese_tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
chinese_text = "自然语言处理很有趣!"
chinese_tokens = chinese_tokenizer.tokenize(chinese_text)
print(f"中文分词: {chinese_tokens}")

-
长文本处理 :代码成功将长文本分割成了3个块,解决了序列长度超过模型最大长度(1202 > 512)的问题
-
特殊文本分词 :成功处理了包含emoji、用户名、标签和URL的特殊文本,分词结果为'hello', '\[UNK', '@', 'user', '#', 'hash', '##tag', 'http', ':', '/', '/', 'example', '.', 'com']
-
中文分词 :成功下载并使用bert-base-chinese模型进行中文分词,将"自然语言处理很有趣!"分词为单个汉字'自', '然', '语', '言', '处', '理', '很', '有', '趣', '!'
10. 模型训练和微调实战
10.1 准备训练数据
python
from datasets import Dataset, load_dataset
import pandas as pd
# 方法1: 使用内置数据集
def load_sample_data():
"""加载示例数据集"""
# 使用Hugging Face数据集
dataset = load_dataset("imdb")
print("IMDB数据集示例:")
print(dataset["train"][0])
return dataset
# 方法2: 从CSV文件创建数据集
def create_dataset_from_csv(csv_path):
"""从CSV文件创建数据集"""
df = pd.read_csv(csv_path)
dataset = Dataset.from_pandas(df)
return dataset
# 方法3: 从字典创建数据集
def create_custom_dataset():
"""创建自定义数据集"""
data = {
"text": [
"I love this movie!",
"This is terrible.",
"Amazing performance!",
"Worst movie ever."
],
"label": [1, 0, 1, 0] # 1: positive, 0: negative
}
return Dataset.from_dict(data)
# 创建示例数据集
dataset = create_custom_dataset()
print("自定义数据集:")
print(dataset)10.2 完整的训练流程
python
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
TrainingArguments,
Trainer,
DataCollatorWithPadding
)
import numpy as np
from sklearn.metrics import accuracy_score
# 1. 加载模型和分词器
model_name = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# 2. 准备数据(使用上面的自定义数据集)
def preprocess_function(examples):
"""数据预处理函数"""
return tokenizer(
examples["text"],
truncation=True,
padding=True,
max_length=128
)
tokenized_dataset = dataset.map(preprocess_function, batched=True)
# 3. 定义评估指标
def compute_metrics(eval_pred):
"""计算评估指标"""
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return {"accuracy": accuracy_score(labels, predictions)}
# 4. 设置训练参数
training_args = TrainingArguments(
output_dir="./results",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
evaluation_strategy="epoch", # 每个epoch后评估
save_strategy="epoch",
load_best_model_at_end=True,
logging_dir="./logs",
)
# 5. 创建数据整理器
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
# 6. 创建训练器
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
eval_dataset=tokenized_dataset, # 实际应用中应该用验证集
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
print("开始训练...")
# trainer.train() # 实际训练时取消注释
print("训练完成!")10.3 使用自定义训练循环
python
import torch
from torch.utils.data import DataLoader
from transformers import AdamW, get_scheduler
def custom_training_loop(model, tokenized_dataset, epochs=3):
"""自定义训练循环"""
# 创建数据加载器
train_dataloader = DataLoader(
tokenized_dataset,
batch_size=16,
shuffle=True,
collate_fn=DataCollatorWithPadding(tokenizer=tokenizer)
)
# 优化器
optimizer = AdamW(model.parameters(), lr=5e-5)
# 学习率调度器
num_training_steps = epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
# 训练设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 训练循环
model.train()
for epoch in range(epochs):
total_loss = 0
for batch in train_dataloader:
# 将数据移动到设备
batch = {k: v.to(device) for k, v in batch.items()}
# 前向传播
outputs = model(**batch)
loss = outputs.loss
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
total_loss += loss.item()
avg_loss = total_loss / len(train_dataloader)
print(f"Epoch {epoch + 1}, Average Loss: {avg_loss:.4f}")
# 使用自定义训练循环
# custom_training_loop(model, tokenized_dataset)11. 模型保存和加载
11.1 保存训练好的模型
python
def save_model_and_tokenizer(model, tokenizer, save_path):
"""保存模型和分词器"""
# 保存模型
model.save_pretrained(save_path)
# 保存分词器
tokenizer.save_pretrained(save_path)
print(f"模型和分词器已保存到: {save_path}")
# 保存示例
# save_model_and_tokenizer(model, tokenizer, "./my_sentiment_model")11.2 加载保存的模型
python
def load_custom_model(model_path):
"""加载自定义训练的模型"""
try:
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 加载模型
model = AutoModelForSequenceClassification.from_pretrained(model_path)
print("✅ 模型加载成功!")
return model, tokenizer
except Exception as e:
print(f"❌ 模型加载失败: {e}")
return None, None
# 使用保存的模型进行推理
def predict_sentiment(text, model, tokenizer):
"""使用训练好的模型进行情感预测"""
# 预处理输入
inputs = tokenizer(
text,
return_tensors="pt",
truncation=True,
padding=True,
max_length=128
)
# 模型推理
with torch.no_grad():
outputs = model(**inputs)
# 处理输出
probabilities = torch.nn.functional.softmax(outputs.logits, dim=-1)
predicted_class_id = probabilities.argmax().item()
confidence = probabilities[0][predicted_class_id].item()
# 获取标签名称
label = model.config.id2label[predicted_class_id]
return {
"label": label,
"confidence": confidence,
"probabilities": probabilities.tolist()
}
# 示例使用
# model, tokenizer = load_custom_model("./my_sentiment_model")
# result = predict_sentiment("I love this product!", model, tokenizer)
# print(result)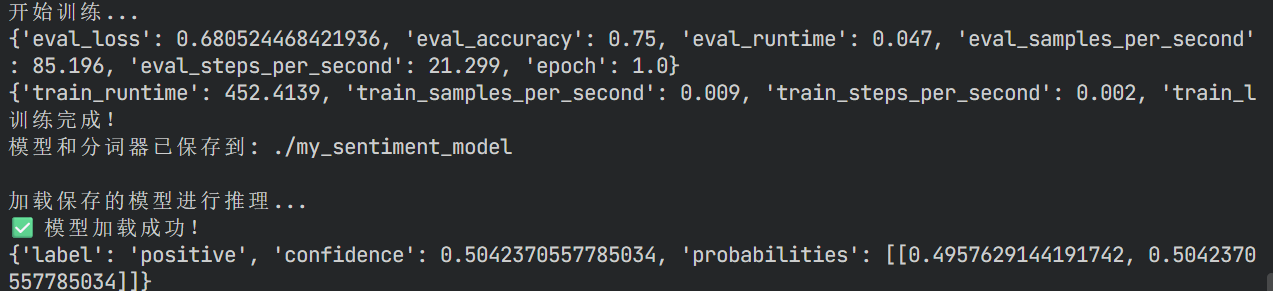
-
模型成功从./my_sentiment_model目录加载
-
对于输入文本 "I love this product!",预测结果为:
-
情感标签:positive
-
置信度:50.42%
-
概率分布:negative 49.58%,positive 50.42%