1 整体架构
3FS 的整体架构由 Cluster Manager、Client、Meta Service 和 Storage Service 四部分组成。所有组件均接入 RDMA 网络实现高速互联,DeepSeek 内部实际使用的是 InfiniBand。
- Cluster Manager 是整个集群的中控,承担节点管理的职责
- Cluster Manager 采用多节点热备的方式解决自身的高可用问题,选主机制复用 Meta Service 依赖的 FoundationDB 实现;
- Meta Service 和 Storage Service 的所有节点,均通过周期性心跳机制维持在线状态,一旦这些节点状态有变化,由 Cluster Manager 负责通知到整个集群;
- Client 同样通过心跳向 Cluster Manager 汇报在线状态,如果失联,由 Cluster Manager 帮助回收该 Client 上的文件写打开状态。
- Client 提供两种客户端接入方案
- FUSE 客户端 hf3fs_fuse 方便易用,提供了对常见 POSIX 接口的支持
- 原生客户端 USRBIO 提供的是 SDK 接入方式,应用需要改造代码才能使用,但性能相比 FUSE 客户端可提升 3-5 倍。
- Meta Service 提供元数据服务,采用存算分离设计
- 元数据持久化存储到 FoundationDB 中,FoundationDB 同时提供事务机制支撑上层实现文件系统目录树语义;
- Meta Service 的节点本身是无状态、可横向扩展的,负责将 POSIX 定义的目录树操作翻译成 FoundationDB 的读写事务来执行。
- Storage Service 提供数据存储服务,采用存算一体设计:
- 每个存储节点管理本地 SSD 存储资源,提供读写能力;
- 每份数据 3 副本存储,采用的链式复制协议 CRAQ(Chain Replication with Apportioned Queries)提供 write-all-read-any 语义,对读更友好;
- 系统将数据进行分块,尽可能打散到多个节点的 SSD 上进行数据和负载均摊。
2 Meta Service
Meta Service 负责存储和管理文件系统的元数据采用存算分离的设计理念,将元数据持久化存储于 FoundationDB(分布式的、支持 SSI 隔离级别事务) 中,同时利用 FoundationDB 提供的事务机制实现文件系统目录树语义(所有事务是一个一个按序执行的,而每一个目录树操作都基于事务做,自然就是等价于每个目录树操作都是等价于串行化运行的,自然不存在任何一致性问题)。
3FS的元数据架构将元数据构建在高性能KV存储系统, 并在此基础之上其将文件系统元数据分解为 inode 和目录条目(directory entries)两种核心结构,然后通过事务化的键值存储实现高效的Posix操作。
FoundationDB的乐观事务模型在事务冲突场景下性能会衰退的比较厉害,3FS在schema上有针对Inode和Dentry作了分离的设计
- 让同一目录下的Dentry聚集在一起,这样减少readdir的交互
- Inode id小端存储, 利用inode id连续分配和FoundationDB的range分片特性,将inode打散在不同节点
3FS MetaServer将Meta请求会按照多种随机策略将请求转发到不同的MetaServer上,MetaServer再将Posix语义转换为KV事务请求下发到FoundationDB。整个请求路径上端到端没有任何缓存而是采用及其简单的事务配合以coroutine调度来满足高吞吐,与此同时MetaServer内部内置了多个组件配合保证Posix语义在事务场景下的高效运转。
- MetaOperation: 具体Posix请求的解析和处理
- Forward & BatchOp: 将部分高频可合并的写请求转发到对应的节点并Batch执行
- InodeAllocator: InodeID分配器
- Session: 在分布式场景下,维护文件open状态
- ChainAllocator: 文件数据Layout所依赖Chain分配器
- GC:垃圾回收, 在删除文件尤其是递归删除目录路径上能够快速返回
- KVEngine: KV引擎
3 元数据管理
几种经典的元数据管理方式:
- 静态子树:将文件目录树划分成不同的子树,不同子树固定到不同的metanode托管
- hash分区: 通过file或者dir将文件系统的元数据通过hash算法映射到不同的元数据节点MDS
- 动态子树:mds的负载情况动态的调整目录子树到不同的mds
- 基于分布式数据库:利用分布式数据库海量数据存储能力,将文件系统的层级元数据转化成扁平的数据结构存储到数据库,同时利用数据库的事务保障元数据操作的原子性
对比1
| 优点 | 不足 | |
|---|---|---|
| 静态子树 | 解决了扩展性问题 | 较容易出现热点数据,需要运维将热点目录拆分,运维成本高 |
| hash分区 | 避免了数据热点 | 在扩展节点时,会面临元数据的重映射,存在元数据的迁移,影响业务使用 |
| 动态子树 | 理论上扩展性和性能是比较好 | 热点数据比较分散,mds经常性的动态迁移从而影响到性能 |
| 基于分布式数据库 | 很好的解决扩展性问题 | 避免不了额外的运营成本,对于低延迟的业务场景还可能针对性的优化分布式数据库 |
对比2
| HDFS | CephFs | JuiceFs | CubeFS | 3FS | |
|---|---|---|---|---|---|
| 元数据管理 | 静态子树 | 动态子树 | 基于分布式数据库 | 基于inode id进行范围分区 | 基于分布式数据库 |
3.1 元数据模型
3.1.1 inode和dentry组织方式
Metadata Service 采用 inode 和 dentry 分离的设计思路,两种结构的主键分别采用不同的前缀从而模拟出两种不同的数据模型。
| Table name | key | value | 说明 |
|---|---|---|---|
| Dentry Table | "DENT" + parent inode_id + entry name | parent_id, name, inode_type, dirAcl, uuid, gcInfo | Inode和Dentry编码到两张逻辑表,且FoundationDB按Range分片^[1](#Table name key value 说明 Dentry Table "DENT" + parent inode_id + entry name parent_id, name, inode_type, dirAcl, uuid, gcInfo Inode和Dentry编码到两张逻辑表,且FoundationDB按Range分片[1],全局有序,从而将不同类型数据从物理上隔离,对Readdir场景遍历dentry友好 Dentry Table的key把附录inode id作为前缀,同一目录下dentry在物理上连续放置,Readdir请求可以通过Scan连续读取 Inode Table "INOD" + inode_id 基本属性 + 附加属性 Inode id小端存储[2], 利用inode id连续分配,以及FoundationDB全局有序特性,可以将inode散列在不同的数据分片上,GetAttr请求集群内分布跟均衡,提升系统吞出 同一文件的inode和dentry未做数据亲和处理,dentry和inode可能落在不同的FoundationDB不同的数据分片上,Lookup时需要跨分片读取一次inode)^,全局有序,从而将不同类型数据从物理上隔离,对Readdir场景遍历dentry友好 Dentry Table的key把附录inode id作为前缀,同一目录下dentry在物理上连续放置,Readdir请求可以通过Scan连续读取 |
| Inode Table | "INOD" + inode_id | 基本属性 + 附加属性 | Inode id小端存储^[2](#Table name key value 说明 Dentry Table "DENT" + parent inode_id + entry name parent_id, name, inode_type, dirAcl, uuid, gcInfo Inode和Dentry编码到两张逻辑表,且FoundationDB按Range分片[1],全局有序,从而将不同类型数据从物理上隔离,对Readdir场景遍历dentry友好 Dentry Table的key把附录inode id作为前缀,同一目录下dentry在物理上连续放置,Readdir请求可以通过Scan连续读取 Inode Table "INOD" + inode_id 基本属性 + 附加属性 Inode id小端存储[2], 利用inode id连续分配,以及FoundationDB全局有序特性,可以将inode散列在不同的数据分片上,GetAttr请求集群内分布跟均衡,提升系统吞出 同一文件的inode和dentry未做数据亲和处理,dentry和inode可能落在不同的FoundationDB不同的数据分片上,Lookup时需要跨分片读取一次inode)^, 利用inode id连续分配,以及FoundationDB全局有序特性,可以将inode散列在不同的数据分片上,GetAttr请求集群内分布跟均衡,提升系统吞出 同一文件的inode和dentry未做数据亲和处理,dentry和inode可能落在不同的FoundationDB不同的数据分片上,Lookup时需要跨分片读取一次inode |
3.1.2 举例
每个文件或者目录目录会抽象为两条数据,比如下图中的/home/file1在KV视图中对应了第二条Dentry和第三条Inode.
FS视图:
bash
/
|--home
| |--file1
| |--file2
| |--file3KV视图 :
Dentry Table:
| Dentry Table |
|---|
| (DENT,0,"home")-> (inodeid:2, other) |
| (DENT,2,"file1")-> (inodeid:3, other) |
| (DENT,2,"file2")-> (inodeid:4, other) |
| (DENT,2,"file3")-> (inodeid:5, other) |
Inode Table:
| Inode Table |
|---|
| (INOD,0)-> (type:Directory, other) |
| (INOD,2)-> (type:Directory, other) |
| (INOD,3)-> (type:File, other) |
| (INOD,4)-> (type:File, other) |
| (INOD,5)-> (type:File, other) |
| 采用这种数据模型的目的便是是为了支持目录树层级结构上以下几种读写模式: |
- 点查询模式
- 路径查找+Inode属性查找: 两种查找都可以转换为对应的Prefix Key上的点读:
- /home/file1的Path Resolve流程,既是在DentryTable依次查找出(DENT,0,"home")和(DENT,2,"file1")
- home/file1的Getattr流程,既是在Inode Table出查找(INOD,3)
- 路径查找+Inode属性查找: 两种查找都可以转换为对应的Prefix Key上的点读:
- 范围查询
- Readdir查询可以转换为基于DENT+父目录InodeID的范围查询,/home目录下的list既在Dentry Table中以DENT+2为Prefix进行范围查询
- 写事务:一条或多条记录的写事务
3.1.3 模型劣势和弥补措施
- 每个节点都承载一定数量的分片,跨分片更新多个key的数据时涉及的事务操作开销较大
- Metadata key的布局特点决定了文件系统的create、rename等常见更新类操作,若严格按照标准POSIX协议实现,在FoundationDB侧等同于一个事务中更新多个key的操作。如果多个key被分配到KVDB集群的不同分片上,为保证事务操作的原子性会触发两阶段提交(2PC),相比单个key或者多个key落在同一个分片上的情况(可简化为1PC提交),时延明显增加。
- 3FS在实现上为减少事务冲突,选择在文件创建时不更新父目录属性,以牺牲通用文件POSIX语义来换取特定场景下的性能
- 由于FoundationDB采用串行化快照事务隔离级别(SSI),这种高隔离级别的事务开销较大,事务冲突场景下性能衰退严重。当两个并行的元数据更新操作发生冲突时,KVDB层检测到事务冲突后会导致一个事务被取消,之后在IO路径上触发Meta Service层的重试事务,可能影响吞吐量。另外,通用文件系统里更复杂的操作(如递归删除目录),会涉及大量事务提交,性能影响更大
- 3FS采用支持非空目录删除与标记删除来尽力规避这种问题,以牺牲通用文件POSIX语义来换取特定场景下的性能
- SSI的串行化隔离级别在KVDB的实现上依赖一个全局的单点TSO时钟,这会成为扩展的瓶颈, 在大规模集群场景下,整个文件系统的并发能力的上限受到限制,并且TSO时钟本身的授时开销也会增加元数据访问的时延。
- 3FS通过FFrecord文件格式来规避这个问题,通过在应用层将小文件合并成大文件,保存在FoundationDB中的元数据量可以大幅减少
3.2 Inode分配机制
InodeID将uint64的值区间拆分成两个区间:
- 高52位:从全局ID分配器(DB)申请获取(
class InodeIdAllocator) - 低12位:本地负责分配
同时本地InodeID分配器在本地InodeID不足的情况下提前去DB分配高位InodeID。
3.2.1 类图和函数
c++
// src/fbs/meta/Schema.h
struct InodeData {
}
// src/fbs/meta/Schema.h
struct Inode : InodeData {
}
// src/fbs/meta/Common.h
class InodeId {
private:
uint64_t val_;
}
// src/common/util/IdAllocator.h
template <typename RetryStrategy>
class IdAllocator {
public:
CoTryTask<uint64_t> allocate(...)
kv::IKVEngine &kvEngine_; //抽象的数据库引擎
RetryStrategy strategy_; //申请失败的重试策略
String keyPrefix_;
uint8_t numShard_;
std::atomic<size_t> shardIdx_;
std::vector<uint8_t> shardList_; //根据numShard_初始化
}
// src/meta/components/InodeAllcator.h
/*
* Generate InodeId range from 0x00000000_00001000 to 0x01ffffff_ffffffff.
* Generated InodeId format: [ high 52bits: generated by IdAllocator ][ low 12 bits: local generated ].
* InodeIdAllocator first use IdAllocator to generate a 52bits value, then left shift 12 bits and generate lower 12 bits
* locally. So it only need to access the FoundationDB after generate 4096 InodeIds.
*/
class InodeIdAllocator {
public:
static constexpr size_t kAllocatorShard = 32; // avoid txn conflictation
static constexpr uint64_t kAllocatorShift = 12; // 低12bit
static constexpr uint64_t kAllocatorBit = 64 - kAllocatorShift; // 高52bit
static constexpr uint64_t kAllocatorMask = (1ULL << kAllocatorBit) - 1; // 52bit全1
static constexpr uint64_t kAllocateBatch = 1 << kAllocatorShift; //4096
CoTryTask<InodeId> allocate(...); //申请inode接口
std::shared_ptr<kv::IKVEngine> engine_; //KV Engine
// 在构造函数中初始化allocator_,设置keyPrefix_为空,numShard_为32
IdAllocator<kv::FDBRetryStrategy> allocator_;
folly::coro::BoundedQueue<InodeId, false, false> queue_;
}3.2.2 申请inode算法
InodeIdAllocator-> allocate()-> allocateFromDB() 使用类IdAllocator->allocate()生成高52bit的值,然后从本地申请低12bit的值,简要流程如下:
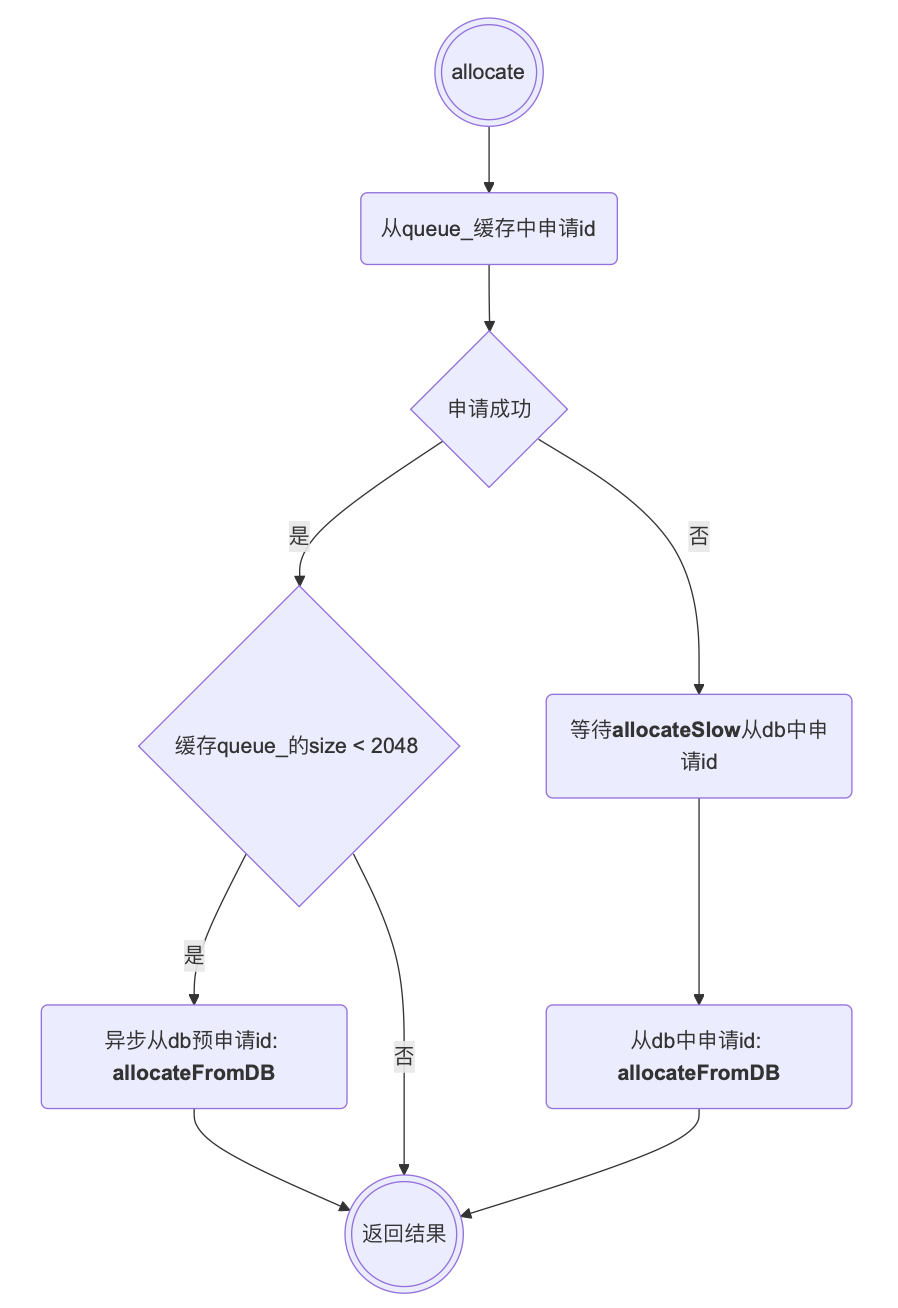
allocateFromDB的申请逻辑:
- IdAllocator-> allocate()-> allocateTxn(),从数据库申请得到ID
- 递增shardIdx_,将shardIdx_对shardList_.size()取模选择对应的shard,即轮询shard分配
- 获取shardKey, 格式为"keyPrefix-shard",从数据库中获取当前分片的计数值val,然后val += 1,转换为小端序,并写入数据库
- 新ID的计算公式是:(val * numShard_) + shard, 其中numShard_是分片总数,shard是当前分片的索引,这种计算方式可以确保不同分片生成的ID是唯一的。
- 举例:如果有32个分片(numShard_=32),分片0的ID序列是:0,32,64,128,...,分片1的ID序列是:1,33,65,129...
- 比如对于分片0,上次val计数为0,则分配的ID是0,本次val +=1,则val = 1,分配的ID是32。
- 对申请得到的ID << kAllocatorShift, 左移12位,低12位本次申请id,存储到缓存队列中
c++
auto first = result.value() << kAllocatorShift; //result << 12
for (uint64_t i = 0; i < kAllocateBatch; i++) { // for (uint64_t i = 0; i < 4096; i++) {
meta::InodeId id(first + i);
co_await queue_.enqueue(id);
}3.3 元数据操作-MetaOperation
c++
// src/meta/store/MetaStore.h
template <typename Rsp>
class IOperation {
virtual bool isReadOnly() = 0;
virtual bool retryMaybeCommitted() { return true; }
virtual CoTryTask<Rsp> run(IReadWriteTransaction &) = 0;
virtual void retry(const Status &) = 0;
virtual void finish(const Result<Rsp> &) = 0;
CoTryTask<Rsp> operator()(IReadWriteTransaction &txn) { co_return co_await run(txn); }
}
// src/meta/store/Operation.h
template <typename Rsp>
class Operation : public IOperation<Rsp> {
Operation(MetaStore &meta) : meta_(meta) {}
PathResolveOp resolve();
CoTryTask<InodeId> allocateInodeId();
MetaStore &meta_;
}
// src/meta/store/MetaStore.h
class MetaStore {
template <typename Rsp>
using Op = IOperation<Rsp>;
template <typename Rsp>
using OpPtr = std::unique_ptr<IOperation<Rsp>>;
static OpPtr<Void> initFileSystem(ChainAllocator &chainAlloc, Layout rootLayout); //初始化文件系统
OpPtr<Void> initFs(Layout rootLayout); // initFs->initFileSystem()
OpPtr<StatFsRsp> statFs(const StatFsReq &req);
OpPtr<StatRsp> stat(const StatReq &req);
OpPtr<BatchStatRsp> batchStat(const BatchStatReq &req);
OpPtr<BatchStatByPathRsp> batchStatByPath(const BatchStatByPathReq &req);
OpPtr<GetRealPathRsp> getRealPath(const GetRealPathReq &req);
OpPtr<OpenRsp> open(OpenReq &req);
OpPtr<CreateRsp> tryOpen(CreateReq &req);
OpPtr<MkdirsRsp> mkdirs(const MkdirsReq &req);
OpPtr<SymlinkRsp> symlink(const SymlinkReq &req);
OpPtr<RemoveRsp> remove(const RemoveReq &req);
OpPtr<RenameRsp> rename(const RenameReq &req);
OpPtr<ListRsp> list(const ListReq &req);
OpPtr<SyncRsp> sync(const SyncReq &req);
OpPtr<HardLinkRsp> hardLink(const HardLinkReq &req);
OpPtr<SetAttrRsp> setAttr(const SetAttrReq &req);
OpPtr<PruneSessionRsp> pruneSession(const PruneSessionReq &req);
OpPtr<TestRpcRsp> testRpc(const TestRpcReq &req);
OpPtr<LockDirectoryRsp> lockDirectory(const LockDirectoryReq &req);
}
// src/meta/service/MetaOperator.h
class MetaOperator {
CoTryTask<void> init(std::optional<Layout> rootLayout);
public:
void start(CPUExecutorGroup &exec);
void beforeStop();
void afterStop();
CoTryTask<AuthRsp> authenticate(AuthReq req);
CoTryTask<StatFsRsp> statFs(StatFsReq req);
CoTryTask<StatRsp> stat(StatReq req);
CoTryTask<GetRealPathRsp> getRealPath(GetRealPathReq req);
CoTryTask<OpenRsp> open(OpenReq req);
CoTryTask<CloseRsp> close(CloseReq req);
CoTryTask<CreateRsp> create(CreateReq req);
CoTryTask<MkdirsRsp> mkdirs(MkdirsReq req);
CoTryTask<SymlinkRsp> symlink(SymlinkReq req);
CoTryTask<RemoveRsp> remove(RemoveReq req);
CoTryTask<RenameRsp> rename(RenameReq req);
CoTryTask<ListRsp> list(ListReq req);
CoTryTask<TruncateRsp> truncate(TruncateReq req);
CoTryTask<SyncRsp> sync(SyncReq req);
CoTryTask<HardLinkRsp> hardLink(HardLinkReq req);
CoTryTask<SetAttrRsp> setAttr(SetAttrReq req);
CoTryTask<PruneSessionRsp> pruneSession(PruneSessionReq req);
CoTryTask<DropUserCacheRsp> dropUserCache(DropUserCacheReq req);
CoTryTask<LockDirectoryRsp> lockDirectory(LockDirectoryReq req);
CoTryTask<TestRpcRsp> testRpc(TestRpcReq req);
CoTryTask<BatchStatRsp> batchStat(BatchStatReq req);
CoTryTask<BatchStatByPathRsp> batchStatByPath(BatchStatByPathReq req);
private:
const Config &config_;
flat::NodeId nodeId_;
analytics::StructuredTraceLog<MetaEventTrace> metaEventTraceLog_;
std::shared_ptr<kv::IKVEngine> kvEngine_;
std::shared_ptr<client::ICommonMgmtdClient> mgmtd_;
std::shared_ptr<Distributor> distributor_;
std::shared_ptr<core::UserStoreEx> userStore_;
std::shared_ptr<InodeIdAllocator> inodeIdAlloc_;
std::shared_ptr<ChainAllocator> chainAlloc_;
std::shared_ptr<FileHelper> fileHelper_;
std::shared_ptr<SessionManager> sessionManager_;
std::shared_ptr<GcManager> gcManager_;
std::unique_ptr<Forward> forward_;
std::unique_ptr<MetaStore> metaStore_;
Shards<std::map<InodeId, Batch>, 63> batches_;
}
// src/fbs/meta/Service.h
struct RspBase {}3.3.1 create
- 客户端发送create请求:
MetaClient::create()- Stub:
IMPL_META_STUB_METHOD(create, CreateReq, CreateRsp);
- Stub:
- Meta Server相应处理:
MetaOperator::create()->- 获取父目录所在的服务器节点作为目标节点
- 如果当前节点就是目标节点,调用
MetaOperator::runInBatch()在本地处理创建请求 - 如果目标节点是其他节点,调用
Forward::forward()将请求转发到目标节点处理
- 如果当前节点就是目标节点,调用
- 获取父目录所在的服务器节点作为目标节点
- Meta Server创建文件:
BatchedOp::create()ChainAllocator::allocateChainsForLayout()allocateInodeId()DirEntry::newFile()Inode::newFile()co_return std::make_pair(inode, entry)
3.3.1.1 Batch处理
然后在MetaOperator层,3FS对一些高频且可合并的写事务做了Forward 和Batch处理:
- 将不同Inode上的写请求的处理按照InodeID转发到对应的Node上(这里依赖Distributer组件)
- 同一个Meta Node下按照InodeID的Hash散到不同的BatchOP上,同一个Hash分片上的BatchOP采用队列组织,每完成一个Batch事务会唤醒下一个
- 同一个Inode上的写请求在BatchOP采用一个共同的Transaction并在本地做合并,比如多个Setattr可以在内存里Apply完最后一把提交
目前支持Batch化处理的请求包括Sync、SetAttr、Create、Close。
3.3.2 mkdirs
3.3.2.1 meta server内部逻辑
下面以mkdir为例描述Meta Operation: src/meta/store/ops/Mkdirs.cc, mkdir支持创建路径所有目录,比如传入创建A/B/C,则A B C全部创建
- 客户端发送mkdirs请求:
MetaClient::mkdirs()- Stub:
IMPL_META_STUB_METHOD(mkdirs, MkdirsReq, MkdirsRsp); //src/stubs/MetaService/MetaServiceStub.cc
- Stub:
- Meta Server相应处理:
MetaOperator::mkdirs()->MetaStore::mkdirs()- Service:
META_SERVICE_METHOD(mkdirs, MkdirsReq, MkdirsRsp);
- Service:
c++
class MkdirsOp : public Operation<MkdirsRsp> {
public:
CoTryTask<MkdirsRsp> run(IReadWriteTransaction &txn) override {
...
}
private:
const MkdirsReq &req_;
}
5 参考
- https://github.com/deepseek-ai/3FS/blob/main/docs/design_notes.md
- DeepSeek 3FS 架构分析和思考(上篇)
- DeepSeek 3FS:端到端无缓存的存储新范式
- JuiceFS 元数据引擎初探:高层架构、引擎选型、读写工作流
- CubeFS存储技术揭秘-元数据管理
- DeepSeek 3FS解读与源码分析(4):Meta Service解读
-
基本概念
Range 分片是指将整个键空间按照键的范围划分为多个连续的区间,每个区间作为一个分片(Shard),每个分片会被分配到不同的存储节点上进行管理和存储。这样一来,整个数据库的数据就被分散存储在多个节点上,从而实现数据的分布式存储和处理。
负载均衡
随着数据的不断写入和删除,各个分片的数据量可能会出现不均衡的情况。FoundationDB 会自动监测各个分片的负载情况,当某个分片的数据量过大或者访问过于频繁时,系统会自动对分片进行拆分和重新分配,将一部分数据迁移到其他节点上,以保证各个节点的负载相对均衡。 ↩︎
-
在小端存储模式中,数据的低位字节存于低地址,高位字节存于高地址。
以
short int类型的变量x为例,其值为0x1234。假设x的地址为0x1000,在小端存储模式下,内存中的存储情况如下内存地址 存储内容 0x1000 0x34 0x1001 0x12