需求
先说需求,客户会给我们一张平面图,然后我们需要通过js渲染出可以点击的车位按钮,用来帮助选择车位进行操作,之前我们是通过手动拖拽,但是面对上百上千的量人工成本太高了
最终效果
先上效果图,这是一张有600个车位车位平面图的部分展示效果,在设置精度必须满0.9的情况下能正确的识别出来500多个,因为图比较大,所以这里显示部分 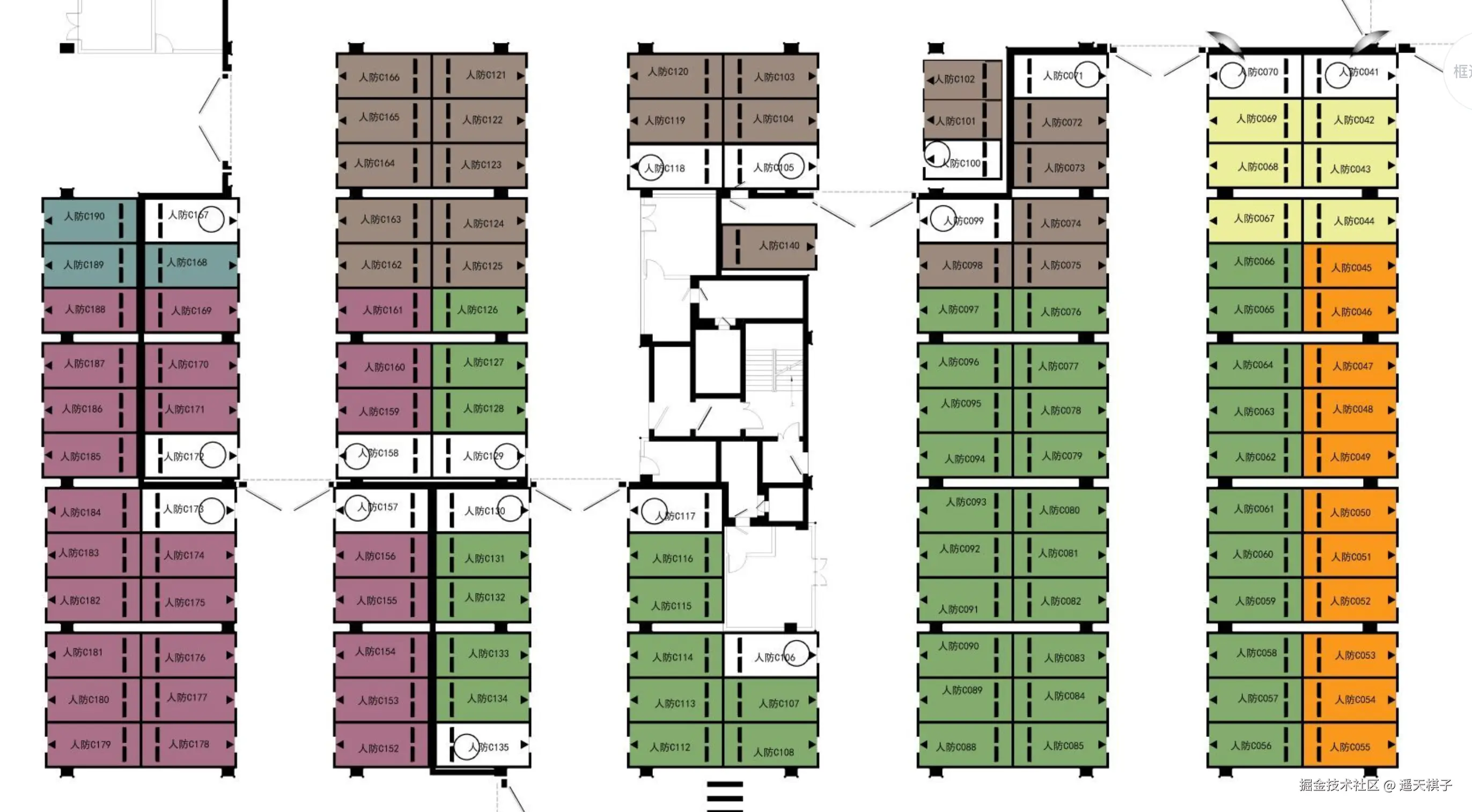 通过识别
通过识别 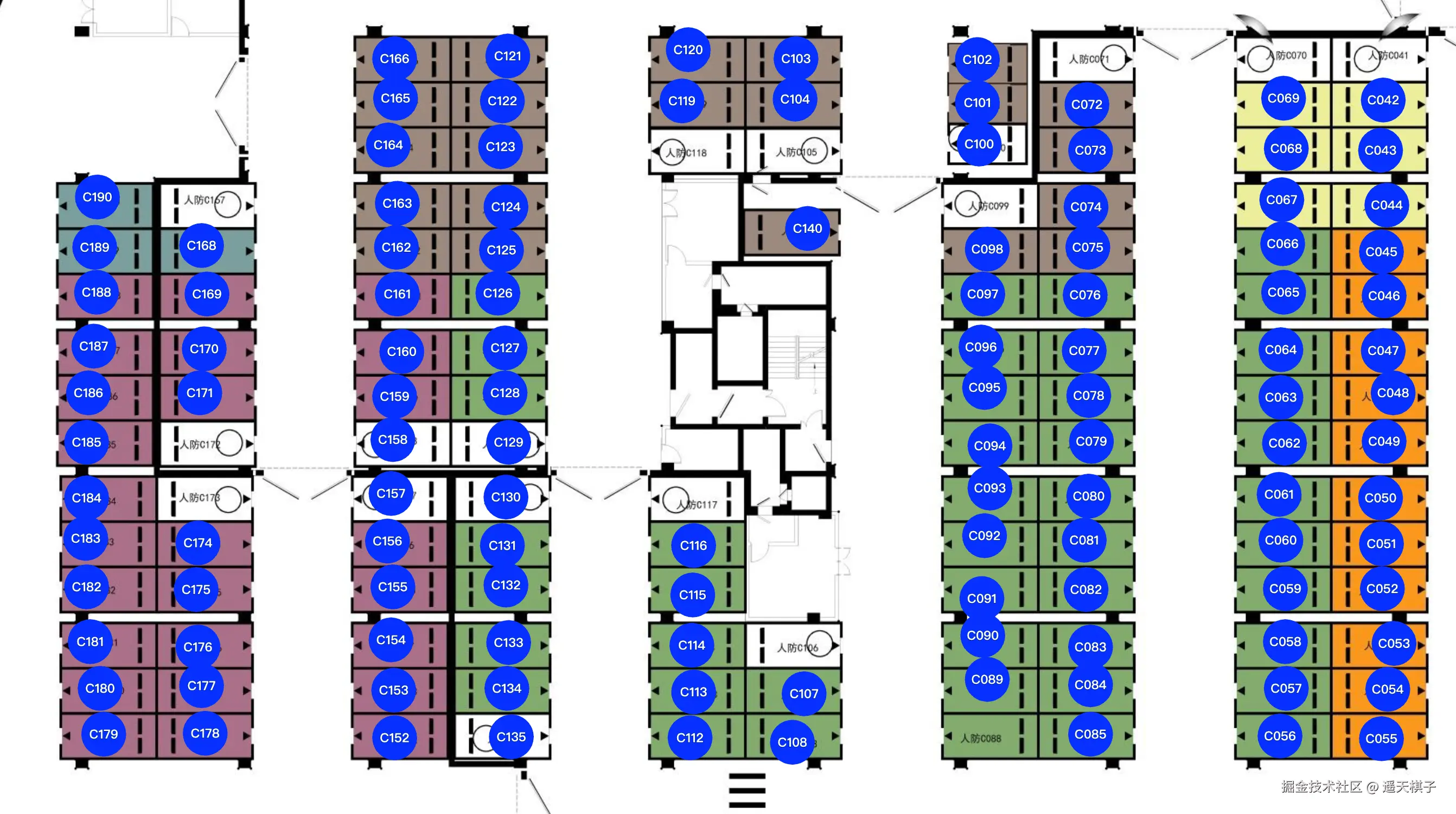
准备工作
API文档地址: ai.baidu.com/ai-doc/AIST... 从右上角控制台获取token
获取文字错标
PaddleOcr 响应结构体
go
// PaddleOcr 响应结构体
type ResPaddleOCR struct {
LogId string `json:"logId"` // 日志ID
Result struct {
OcrResults []struct {
PrunedResult struct {
RecTexts []string `json:"rec_texts"` // 识别文本
RecBoxes [][]int `json:"rec_boxes"` // 识别框坐标
} `json:"prunedResult"`
} `json:"ocrResults"`
DataInfo struct {
Width int `json:"width"` // 图片宽度
Height int `json:"height"` // 图片高度
Type string `json:"type"` // 图片类型
} `json:"dataInfo"`
} `json:"result"`
ErrorCode int `json:"errorCode"` // 错误码
ErrorMsg string `json:"errorMsg"` // 错误信息
}
// 配置信息
const (
API_URL = "https://wfy6da03m00fd1w1.aistudio-app.com/ocr"
TOKEN = ""
)获取远程图片
golang
// 获取远程图片base64编码
func GetOssImg64(fileURL string) (fileData string, err error) {
resp, err := http.Get("https://" + global.Conf.Oss.BucketName + "." + global.Conf.Oss.Endpoint + "/" + fileURL)
if err != nil {
err = fmt.Errorf("获取图片失败: %w", err)
return
}
defer resp.Body.Close()
body, err := io.ReadAll(resp.Body)
if err != nil {
err = fmt.Errorf("读取图片失败: %w", err)
return
}
fileData = base64.StdEncoding.EncodeToString(body)
return
}请求PaddleOCR服务api
golang
func PaddleOCR(fileUrl string) (respData ResPaddleOCR, err error) {
fileData, err := GetOssImg64(fileUrl)
if err != nil {
return
}
// 构建请求参数
payload := map[string]interface{}{
"file": fileData, // 文件内容的Base64编码结果
"fileType": 1, // 文件类型。0表示PDF文件,1表示图像文件
"useDocOrientationClassify": false, // 是否在推理时使用文档方向分类模块
"useDocUnwarping": false, // 是否在推理时使用文本图像矫正模块
"useTextlineOrientation": false, // 是否在推理时使用文本行方向分类模块
"textDetLimitSideLen": 64, // 文本检测的图像边长限制
"textDetLimitType": "min", // 文本检测的边长度限制类型
"textDetThresh": 0.3, // 文本检测像素阈值
"textDetBoxThresh": 0.6, // 文本检测框阈值
"textDetUnclipRatio": 1.5, // 文本检测扩张系数
"textRecScoreThresh": 0.8, // 文本识别阈值
"visualize": false, // 是否可视化识别结果
}
payloadBytes, _ := json.Marshal(payload)
client := &http.Client{}
req, _ := http.NewRequest("POST", API_URL, bytes.NewBuffer(payloadBytes))
// 设置请求头
req.Header.Set("Content-Type", "application/json")
req.Header.Set("Authorization", fmt.Sprintf("token %s", TOKEN))
res, err := client.Do(req)
if err != nil {
err = fmt.Errorf("发送请求失败: %w", err)
return
}
defer res.Body.Close()
if res.StatusCode != http.StatusOK {
err = fmt.Errorf("返回状态码错误: %d", res.StatusCode)
return
}
body, err := io.ReadAll(res.Body)
if err != nil {
err = fmt.Errorf("读取响应体失败: %w", err)
return
}
fmt.Println(string(body))
if err = json.Unmarshal(body, &respData); err != nil {
err = fmt.Errorf("解析响应体失败: %w", err)
return
}
return
}对接现有系统
我们系统前端存储每个坐标点的格式是,其中name对应图中的车位号
json
{
"room_id": 1,
"name": "001"
"style": "....",
"x":0,
"y":0
}过滤数据
比如我们系统是识别车位号,就把Ocr不符合格式的数据全部过滤,并存储好x,y坐标
golang
// 处理数据
var (
xMap = make(map[string]int) // 横坐标
yMap = make(map[string]int) // 纵坐标
OcrStrs = make([]string, 0) // 有效数据
RecTexts = ocrData.Result.OcrResults[0].PrunedResult.RecTexts // Ocr文字数据
RecBoxes = ocrData.Result.OcrResults[0].PrunedResult.RecBoxes // Ocr坐标数据
imgWidth = ocrData.Result.DataInfo.Width // 图片宽
imgHeight = ocrData.Result.DataInfo.Height // 图片高
)
// 处理Ocr结果
re := regexp.MustCompile(`[\p{Han}\s]+`)
for index, v := range RecBoxes {
// 过滤数据正则
result := re.ReplaceAllString(RecTexts[index], "")
// 排除空字符串
if result == "" {
continue
}
OcrStrs = append(OcrStrs, result)
// 计算文本中心坐标并存储
xMap[result] = (v[0]+v[2])/2 - imgWidth/2
yMap[result] = -((v[1]+v[3])/2 - imgHeight/2)
}渲染数据拼接
golang
sqlData := GetMapData()
// 渲染数据
for index, v := range sqlData {
sqlData[index].X = float64(xMap[v.Name])
sqlData[index].Y = float64(yMap[v.Name])
}这样就完成了AI图片定点
后续改进
- 我保存了文件的md5值和处理结果,所以同样的图片不会处理第二次
- 使用异步通知客户ai标记任务完成,这个接口还是挺慢的,和我本地跑这个模型没有太大区别