文章目录
- [1. 实战概述](#1. 实战概述)
- [2. 实战步骤](#2. 实战步骤)
-
- [2.1 修改Hive配置文件](#2.1 修改Hive配置文件)
- [2.2 分发Hive配置文件到Spark配置目录](#2.2 分发Hive配置文件到Spark配置目录)
- [2.3 分发HikariCP数据库连接池JAR包](#2.3 分发HikariCP数据库连接池JAR包)
- [2.4 修改Hadoop核心配置文件](#2.4 修改Hadoop核心配置文件)
- [2.5 启动Hadoop服务](#2.5 启动Hadoop服务)
- [2.6 启动Hive相关服务](#2.6 启动Hive相关服务)
- [2.7 进行词频统计](#2.7 进行词频统计)
-
- [2.7.1 采用Hive on YARN来实现](#2.7.1 采用Hive on YARN来实现)
- [2.7.2 采用Hive on Spark来实现](#2.7.2 采用Hive on Spark来实现)
- [2.7.3 两种实现方式的简单对比](#2.7.3 两种实现方式的简单对比)
- [3. 实战总结](#3. 实战总结)
1. 实战概述
- 本实战通过配置 Hive 与 Spark 集成,分别基于 YARN(MapReduce)和 Spark 引擎执行词频统计任务,验证了 Hive on Spark 在查询性能上的显著优势,同时展示了 Hadoop、Hive 和 Spark 的协同部署与关键配置步骤。
2. 实战步骤
2.1 修改Hive配置文件
- 切换到Hive配置目录
- 执行命令:
cd $HIVE_HOME/conf
- 执行命令:
- 修改Hive配置文件
-
执行命令:
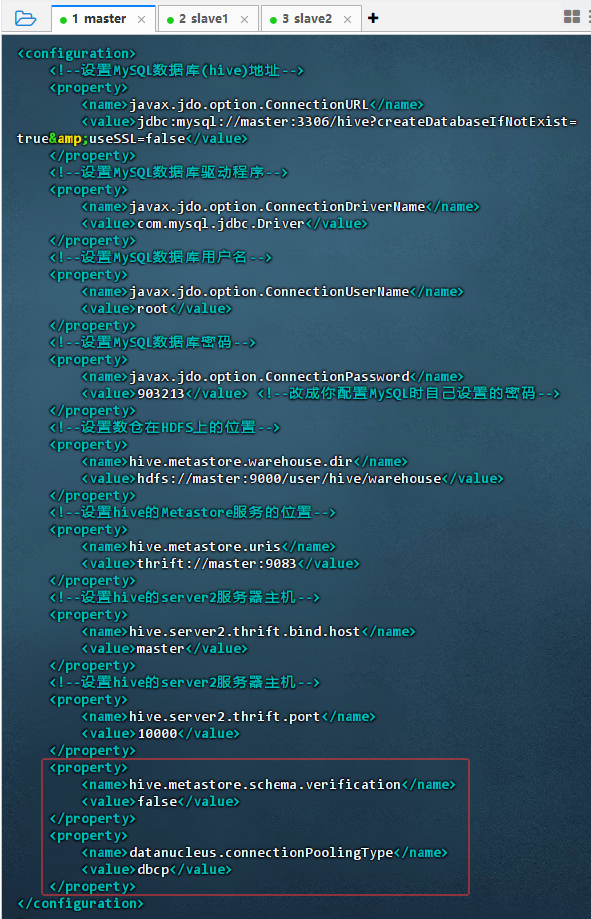
vim hive-site.xml,添加两个属性设置
 xml
xml<property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <property> <name>datanucleus.connectionPoolingType</name> <value>dbcp</value> </property> -
配置说明
hive.metastore.schema.verification=false表示禁用元数据 schema 版本校验,便于升级或兼容不同版本;datanucleus.connectionPoolingType=dbcp指定使用 DBCP 作为数据库连接池类型,提升元数据操作性能。
-
2.2 分发Hive配置文件到Spark配置目录
-
主节点上拷贝Hive配置文件到Spark配置目录
- 执行命令:
cp hive-site.xml $SPARK_HOME/conf
- 执行命令:
-
主节点上分发Hive配置文件到slave1的Spark配置目录
- 执行命令:
scp hive-site.xml root@slave1:$SPARK_HOME/conf
- 执行命令:
-
主节点上分发Hive配置文件到slave2的Spark配置目录
- 执行命令:
scp hive-site.xml root@slave2:$SPARK_HOME/conf
- 执行命令:
2.3 分发HikariCP数据库连接池JAR包
-
切换到Hive的库目录
- 执行命令:
cd $HIVE_HOME/lib
- 执行命令:
-
主节点上将HikariCP数据库连接池JAR包复制到Spark的jars目录
- 执行命令:
cp HikariCP-2.6.1.jar $SPARK_HOME/jars
- 执行命令:
-
主节点上将HikariCP数据库连接池JAR 包分发到slave1的Spark的jars目录
- 执行命令:
scp HikariCP-2.6.1.jar root@slave1:$SPARK_HOME/jars

- 执行命令:
-
主节点上将HikariCP数据库连接池JAR包分发到slave2的Spark的jars目录
- 执行命令:
scp HikariCP-2.6.1.jar root@slave2:$SPARK_HOME/jars

- 执行命令:
2.4 修改Hadoop核心配置文件
-
进入Hadoop配置目录
- 执行命令:
cd $HADOOP_HOME/etc/hadoop
- 执行命令:
-
修改Hadoop核心配置文件
-
执行命令:
vim core-site.xml,添加两个属性
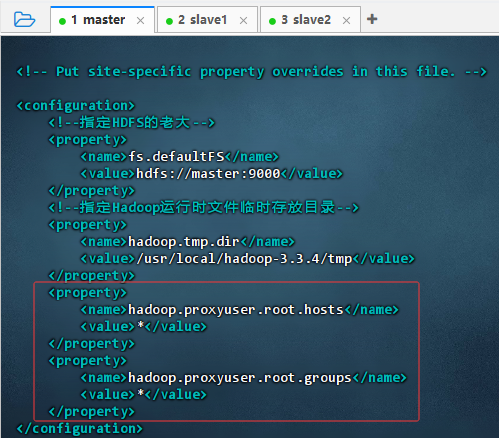 xml
xml<property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> -
配置说明:该配置允许
root用户代理访问 Hadoop 服务。hadoop.proxyuser.root.hosts=*表示允许所有主机以 root 身份提交代理请求;hadoop.proxyuser.root.groups=*表示 root 可代表任意用户组执行操作。常用于 Spark、Hive 等服务通过 root 代理访问 HDFS/YARN,但存在安全风险,生产环境应限制具体主机和组。
-
-
将Hadoop核心配置文件分发到slave1节点
- 执行命令:
scp core-site.xml root@slave1:$HADOOP_HOME/etc/hadoop

- 执行命令:
-
将Hadoop核心配置文件分发到slave2节点
- 执行命令:
scp core-site.xml root@slave2:$HADOOP_HOME/etc/hadoop

- 执行命令:
2.5 启动Hadoop服务
- 执行命令:
start-dfs.sh
- 执行命令:
start-yarn.sh
2.6 启动Hive相关服务
- 执行命令:
nohup hive --service metastore >> log.out 2>&1 &

- 执行命令:
nohup hive --service hiveserver2 >> log.out 2>&1 &

2.7 进行词频统计
2.7.1 采用Hive on YARN来实现
-
执行命令:
hive,进入Hive客户端
-
执行命令:
create external table t_word(words string) location '/hivewc/input';基于HDFS文件创建外部表

-
执行命令:
select word, count(*) from (select explode(split(words, ' ')) as word from t_word) as v_word group by word;
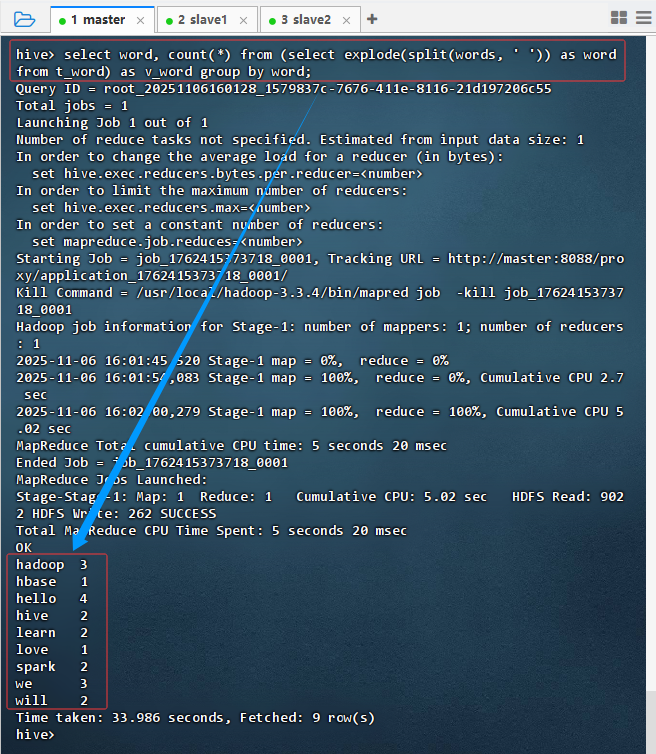
-
结果说明:该查询在 Hive 中执行词频统计,通过
explode和split对文本字段进行分词并聚合。结果返回 9 行数据,显示各单词及其出现次数(如"hadoop"出现 3 次)。执行耗时 33.986 秒,使用 MapReduce 引擎完成计算,验证了 Hive 基于 Hadoop 的批处理能力。 -
执行命令:
exit;,退出Hive客户端
2.7.2 采用Hive on Spark来实现
- 执行命令:
spark-sql
- 执行命令:
show databases;
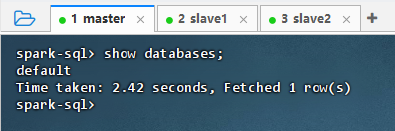
- 结果说明:该命令在 Spark SQL 中执行
show databases;,返回结果为default,表明当前连接的 Hive 元数据中存在默认数据库。查询耗时 2.42 秒,成功获取 1 行数据,说明 Spark SQL 已正确集成 Hive 元数据服务,可正常访问 Hive 数据库结构。 - 执行命令:
select word, count(*) from (select explode(split(words, ' ')) as word from t_word) as v_word group by word;
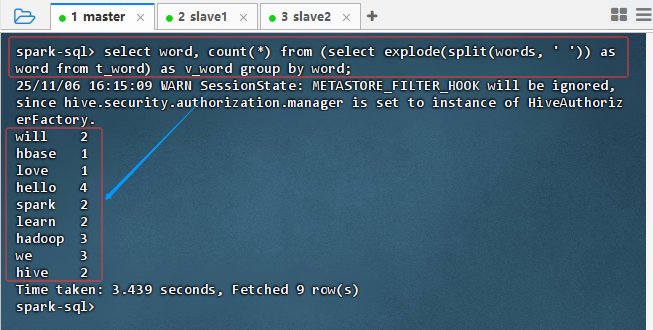
- 结果说明:该查询对文本字段
words进行分词并统计词频,结果返回 9 行数据,显示各单词及其出现次数(如 "hadoop" 出现 3 次)。执行耗时 3.439 秒,说明 Spark SQL 成功处理了数据解析与聚合操作,验证了 Hive on Spark 的计算能力。
2.7.3 两种实现方式的简单对比
- Hive on YARN(MapReduce)耗时 33.986 秒,而 Hive on Spark 仅需 3.439 秒,性能显著提升。两者均基于同一 Hive 元数据和外部表,但计算引擎不同:MapReduce 启动开销大、适合稳定批处理;Spark 内存计算快、适合迭代与交互式查询,验证了 Spark 作为 Hive 执行引擎的高效性。
3. 实战总结
- 本次实战成功完成了 Hive on YARN 与 Hive on Spark 两种执行模式的部署与对比验证。通过配置
hive-site.xml、分发依赖 JAR 包、设置 Hadoop 代理用户权限,并启动 HDFS、YARN、Hive Metastore 及 HiveServer2 服务,构建了完整的数据处理环境。基于同一外部表执行词频统计任务,Hive on MapReduce 耗时约 34 秒,而 Hive on Spark 仅需约 3.4 秒,性能提升近 10 倍,充分体现了 Spark 内存计算在迭代和聚合场景下的高效性。实验不仅验证了 Hive 与 Spark 的无缝集成能力,也为后续选择合适执行引擎提供了实践依据,同时强调了生产环境中需优化安全配置(如限制 proxyuser 范围)的重要性。