《基于随机森林和决策树的亚马逊用户评论情感分析研究》深入探讨了利用机器学习技术对亚马逊用户评论数据进行情感分析的方法,旨在为电商企业提供更精准的用户反馈处理工具,以辅助产品优化和服务改进 通过采用决策树模型和随机森林模型这两种不同的机器学习算法,我们对用户评论的情感倾向进行了分类建模,并通过多种评估指标对比两种模型的表现 实验结果显示,所建立的模型能够有效地识别出评论中的积极与消极情感,并实现了较高的分类准确性,其中随机森林模型在测试集上的准确率达到了0.97以上 报告采用Python代码,字数共6000字左右,资料压缩包具体包括数据,代码,完整报告
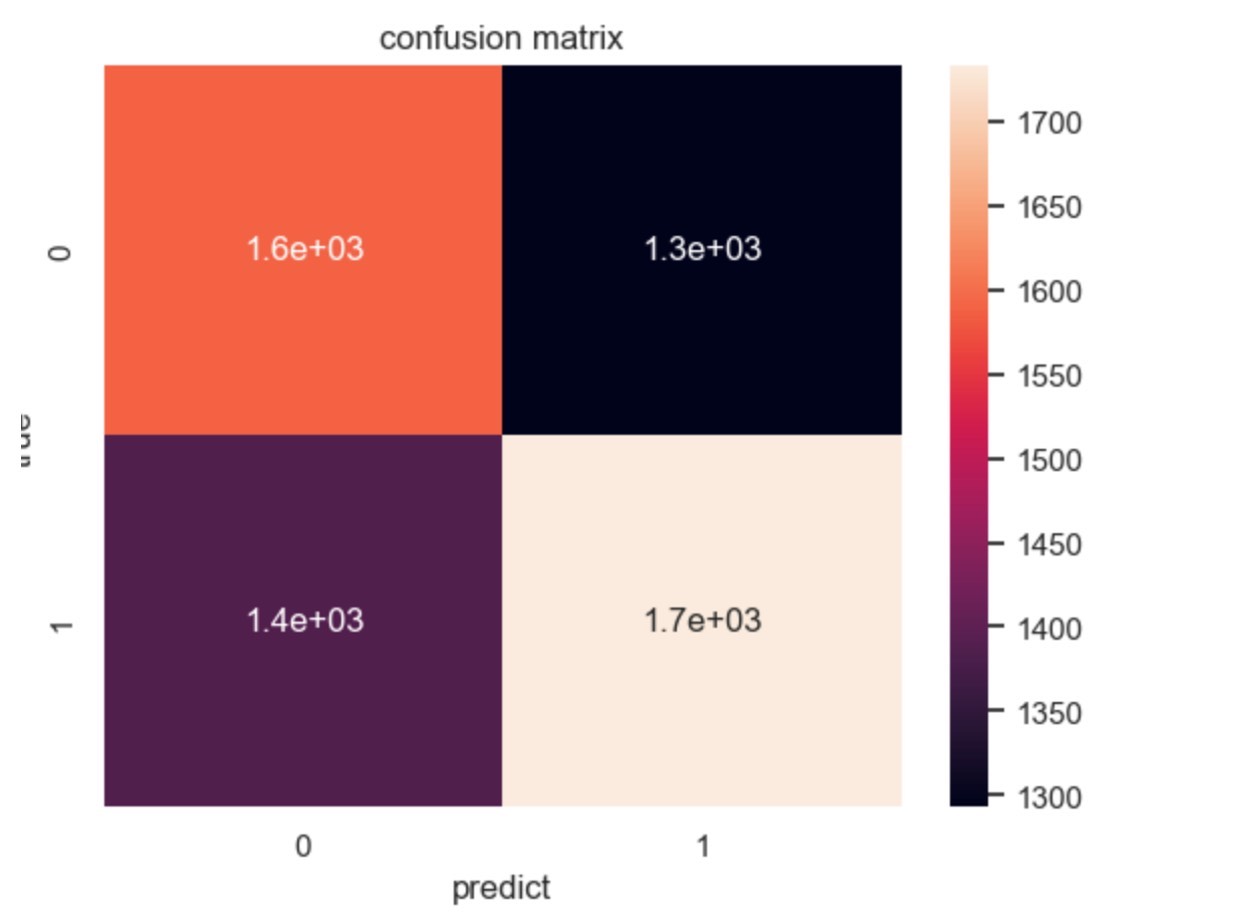
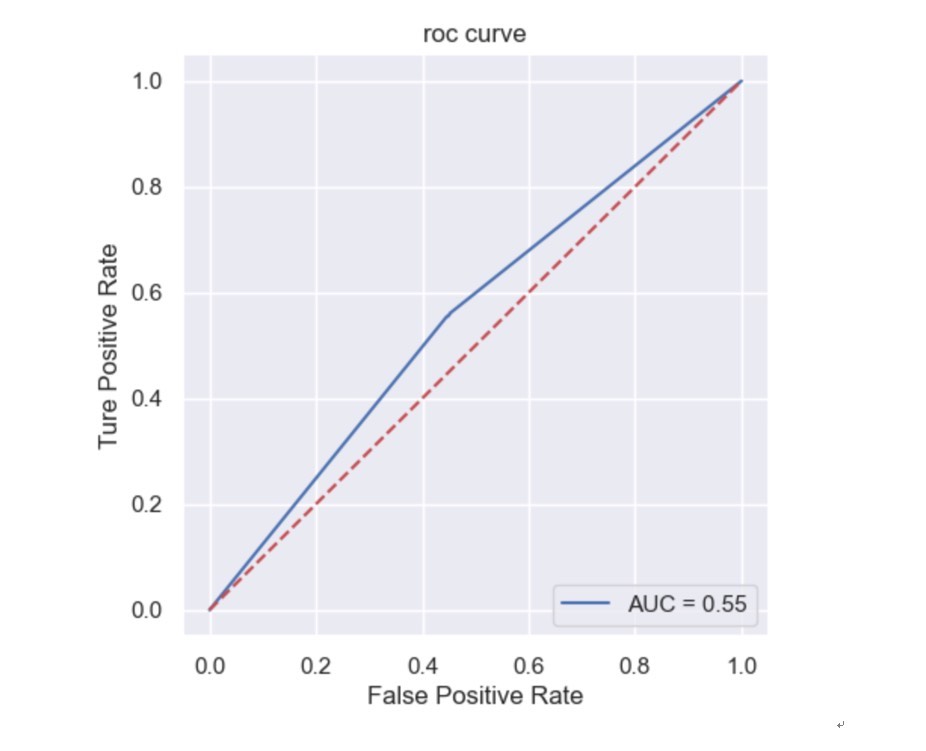
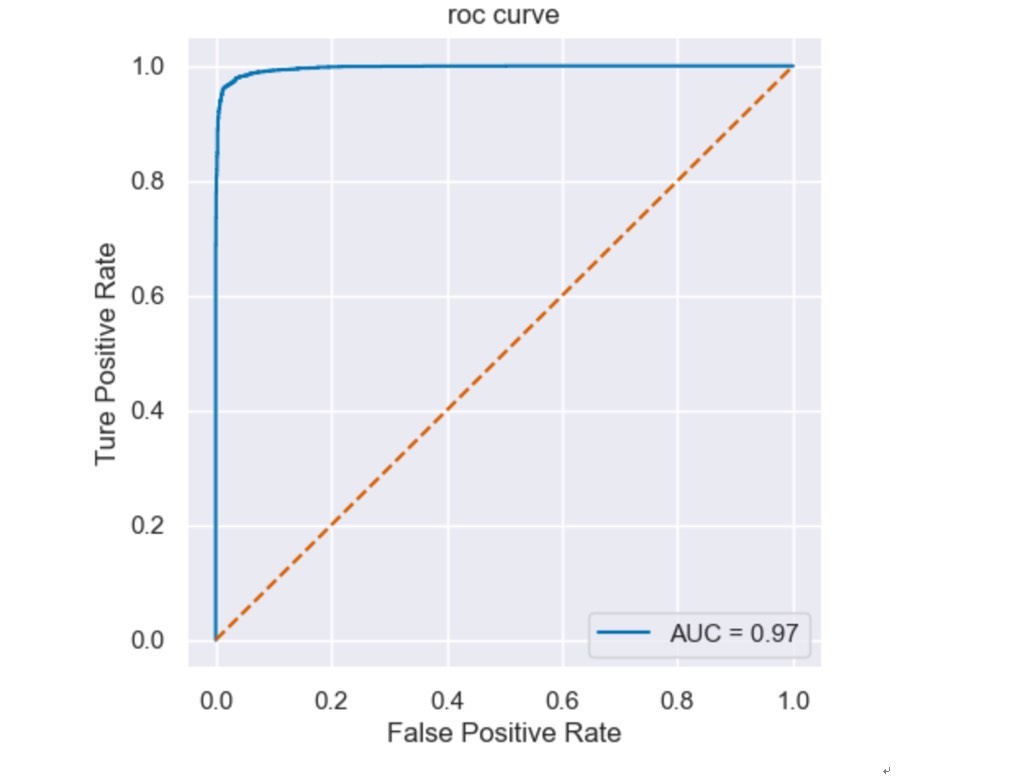
最近在折腾一个亚马逊评论情感分析的项目,发现随机森林这玩意儿真是把分类任务玩出花了。咱们先看个有意思的现象------用决策树跑出来的准确率明明也有0.93,换成随机森林直接飙到0.97+。这4%的提升到底怎么来的?咱们边撸代码边聊。
处理文本数据最头疼的就是怎么让机器看懂人话。这里用了个取巧的办法:把评论转成TF-IDF向量。别被专业名词吓到,其实就是给词语的重要性打分。来看这段预处理代码:
python
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(max_features=5000,
ngram_range=(1,2),
stop_words='english')
X = tfidf.fit_transform(df['review_text'])这里ngram_range=(1,2)是个关键参数,既考虑单个词也抓词语组合。比如"not good"和"good"在情感上完全相反,单看词频肯定要翻车。跑完这个转换器,每条评论都变成了包含5000个特征的数字向量------相当于给每条评论办了张特征身份证。
决策树的训练代码简单得不像话:
python
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(max_depth=10)
dt.fit(X_train, y_train)但这里藏着个坑------树太深容易过拟合。实测当max_depth超过15时,训练集准确率直奔1.0,测试集却开始跳水。这就像学生死记硬背考题,真遇到新题目就懵了。
随机森林的魔法就体现在这里:
python
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=200,
max_features='sqrt',
class_weight='balanced')nestimators=200**意味着让200棵决策树组团投票。重点是这个max features='sqrt',每棵树随机选择√5000≈70个特征来训练,确保各个树之间有差异性。这种多样性机制就像让专家委员会做决策,比单个专家靠谱得多。
特征重要性可视化是个很有意思的环节:
python
import matplotlib.pyplot as plt
features = tfidf.get_feature_names_out()
importances = rf.feature_importances_
plt.barh(features[np.argsort(importances)[-10:]],
sorted(importances)[-10:])
plt.title('Top 10 Important Features')跑出来的结果让人忍俊不禁------排前几的特征居然是"waste of money"和"highly recommend"。这两个短语在正负面评论中的区分度极高,比那些常见的中性词有用得多。这也解释了为什么需要做文本清洗,要是没过滤停用词,现在榜首可能就是"the"和"and"了。
模型评估时别光看准确率这个单一指标:
python
from sklearn.metrics import classification_report
print(classification_report(y_test, rf_pred))F1-score才是王道,特别是当数据存在类别不平衡时。比如负面评论占比只有20%,这时候准确率高可能只是模型学会了总是预测正面。用class_weight='balanced'参数能有效缓解这个问题,相当于给少数派样本加权重。

代码跑通之后,发现个有趣现象:随机森林在短文本(少于20词)上的表现略逊于决策树。猜测是因为短文本特征稀疏,随机抽特征可能导致部分树学不到有效模式。这时候可以试试调整max_features参数,或者用BERT这类预训练模型来处理短文本------不过那就是另一个故事了。
最后说点实战心得:处理用户评论时,千万别忽略表情符号和拼写错误。虽然TF-IDF能捕捉部分特征,但像"goooood"这种加强版好评,还是得靠自定义的正则表达式来处理。不过这次项目里为了保持模型通用性,忍痛放弃了些边角情况。毕竟在准确率97%的基础上,再想提升那1%可能要付出十倍工作量------这个性价比,产品经理估计要掀桌了。