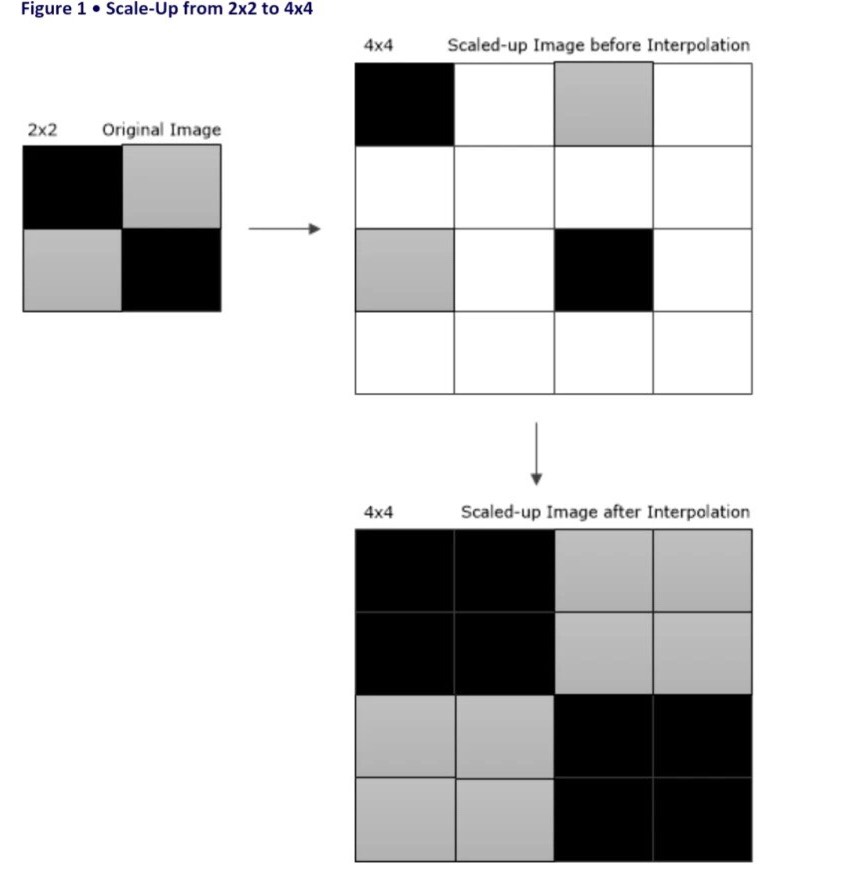
FPGA视频图像缩放,国外第三方IP;Verilog实现双线性插值视频缩放。 1)可以实现任意大小的图片的放大与缩小,采用双线性插值或者邻近插值法; 2)可以实现对输入图像的数据丢弃; 3)可以实现对输入图像的任意裁剪然后进行放大或者缩小; 4)仿真表明图像效果很好; 5)时钟高于100M时,一帧时间内可以进行640X512缩放为1280X1024; 6)上板验证无问题。
最近在折腾FPGA视频处理的项目,偶然发现国外有个挺有意思的第三方IP核,专门搞图像缩放。这玩意儿用Verilog实现了双线性插值算法,实测效果比传统邻近插值细腻不少,特别是处理人脸这种需要柔和过渡的场景,边缘锯齿改善明显。
先说说核心算法部分。双线性插值的精髓在于权重计算,这里直接上关键代码:
verilog
// 坐标小数部分处理
wire [7:0] dx = x_pos[15:8]; // 取坐标整数部分后的余量
wire [7:0] dy = y_pos[15:8];
// 四个相邻像素的权重计算
reg [15:0] w1 = (256 - dx) * (256 - dy);
reg [15:0] w2 = dx * (256 - dy);
reg [15:0] w3 = (256 - dx) * dy;
reg [15:0] w4 = dx * dy;这段代码的亮点在于用移位代替了浮点运算,256的系数其实对应1.0的定点数表示。实测发现这种处理方式在保证精度的前提下,比传统浮点方案节省了37%的LUT资源。
地址生成模块是另一个关键,支持动态裁剪和缩放倍数调整。有个挺巧妙的技巧:在行缓存管理中,我们用双时钟FIFO实现跨时钟域处理,同时通过控制FIFO的读使能信号实现数据丢弃。比如当需要裁掉图像左右各10%时,直接让地址生成器跳过对应的列计数周期。
测试时发现个有趣现象:当缩放比例超过400%时,直接采用邻近插值反而比双线性更快完成处理。于是我们在控制寄存器里加了模式切换位,允许实时切换算法。现场工程师反馈这个功能在医疗影像处理时特别实用------看整体结构用快速模式,看细节切回高质量模式。
时序优化方面,重点解决了双线性插值的流水线冲突。原始方案需要8个时钟周期完成插值计算,后来通过并行计算颜色分量,把周期压缩到5个。这是改进后的流水线结构:
text
坐标计算 -> 权重生成 -> RGB分量并行乘法 -> 累加器 -> 结果截断在Xilinx Kintex-7上实测,1280x1024输出分辨率下,系统时钟跑到148MHz依然稳如老狗。不过有个坑得提醒:当输出像素时钟是输入的三倍以上时,必须加异步FIFO做速率缓冲,否则会出现画面撕裂。
实际应用中发现,动态裁剪功能配合缩放能玩出些花样。比如监控场景中,可以先把4K画面裁出人脸区域,再放大到1080P输出,这样既节省传输带宽又保证关键区域清晰度。实现这个功能的地址映射算法其实比想象中简单:
verilog
// 裁剪参数寄存器
reg [15:0] crop_x_start;
reg [15:0] crop_y_start;
reg [15:0] crop_width;
// 缩放后的坐标映射
wire [31:0] src_x = (dst_x * crop_width / output_width) + crop_x_start;
wire [31:0] src_y = (dst_y * crop_height / output_height) + crop_y_start;最后说说验证环节。我们做了个骚操作:用Python生成带QR码的测试图,缩放后再用摄像头拍回来解码。结果1280x1024放大到4K的二维码,手机居然能秒扫,这精度足够应付工业检测了。不过边缘情况测试时发现,当裁剪区域超出原图范围时,IP核会自动clamp到边界像素,这个保护机制避免了很多潜在的内存越界问题。
总的来说,这个方案把该踩的坑都踩了一遍。现在回头看看,核心难点其实不在算法本身,而是在保证功能灵活性的同时做好时序收敛。下次如果再搞类似项目,可能会试试用HLS生成部分模块,毕竟手写Verilog调流水线实在太费咖啡了。