前言
前几天负责维护的一套核心系统的主机CPU,出现了一次小的CPU波动,(正常5%左右,问题时段最高到15%)因为是最核心的系统,所以要追查根本原因;跟着博主一起来看,是什么造成的这次CPU波动。
现象
出现问题时间并未引起关注,因为主机的性能非常强悍,这次微小的CPU波动也只是最高到15%的使用率,远远没有到达预警值;但是因为是最为核心的MES系统,在日常点检中巡查到这次波动,所以要排查根因;
1.首先要找到问题的表象,利用OEM查看问题时段的CPU走势,确实有个微小的波峰,同时拉长时段看,同周同月同时段无相同波峰(排除schedule job)
PS:OEM真的是排查异常的好帮手!
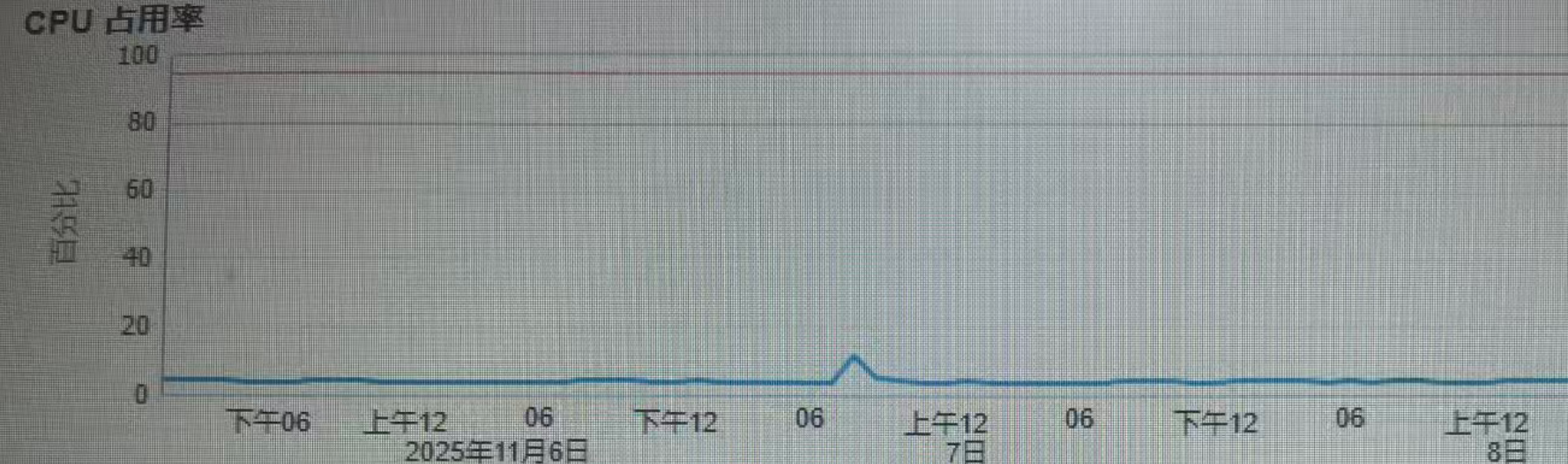
2.查看OEM数据库的性能主页,可以看到明细的波峰,等待事件为direct path read,该等待事件最常见的是大报表SQL的;
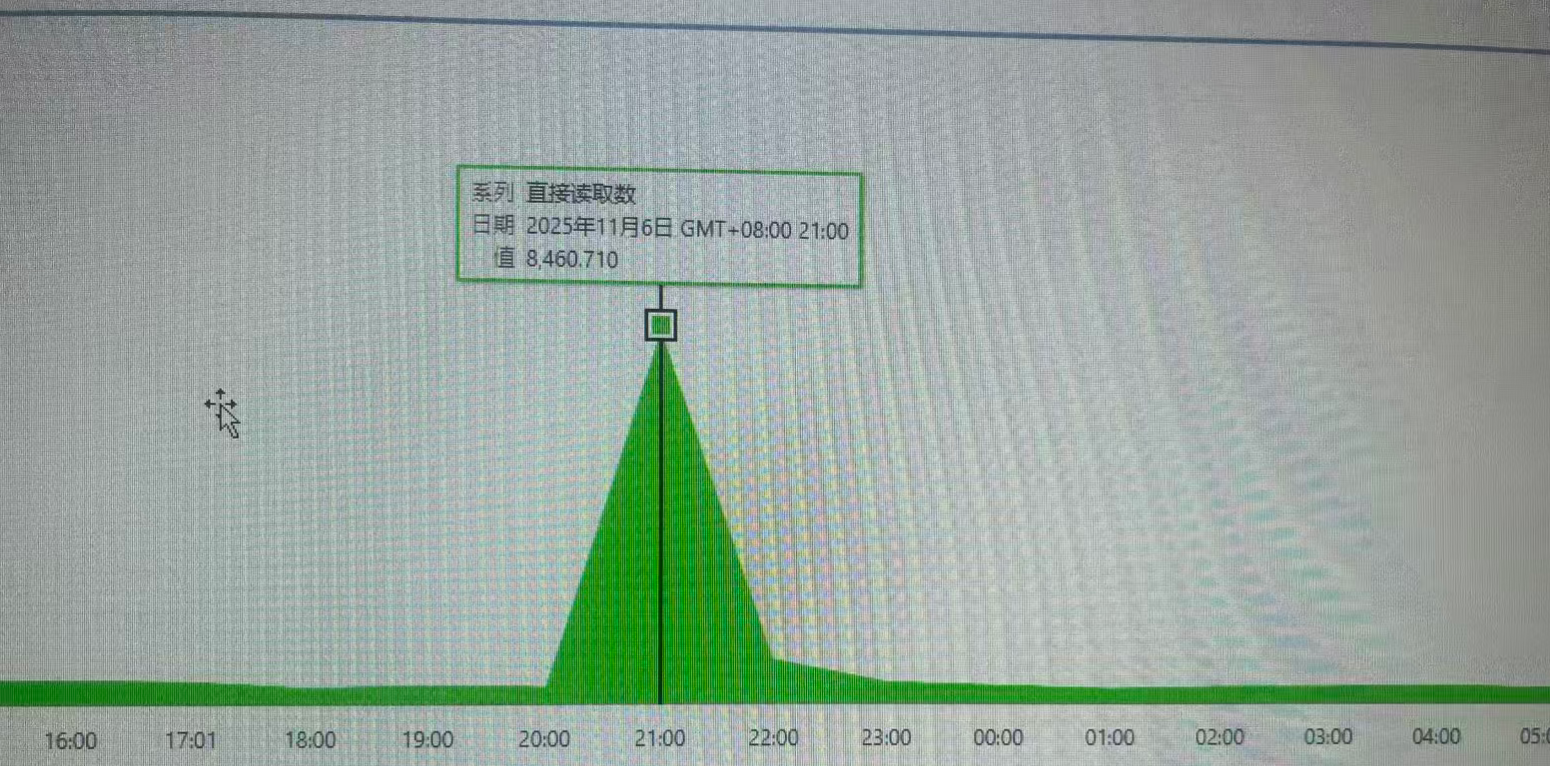
3.为了排除是否定时任务等的干扰,需要查询相应JOB和归档量规律
select * from dba_jobs;
select * from dba_schedule_jobs;
#同时查询各个时段的归档量,看问题时段是否有规律性增长
---- Show the Number of Redo Log Switches Per Hour
SET PAUSE ON
SET PAUSE 'Press Return to Continue'
SET PAGESIZE 60
SET LINESIZE 300
SELECT to_char(first_time, 'yyyy - mm - dd') aday,
to_char(first_time, 'hh24') hour,
count(*) total
FROM v$log_history
WHERE thread#=&EnterThreadId
GROUP BY to_char(first_time, 'yyyy - mm - dd'),
to_char(first_time, 'hh24')
ORDER BY to_char(first_time, 'yyyy - mm - dd'),
to_char(first_time, 'hh24') asc
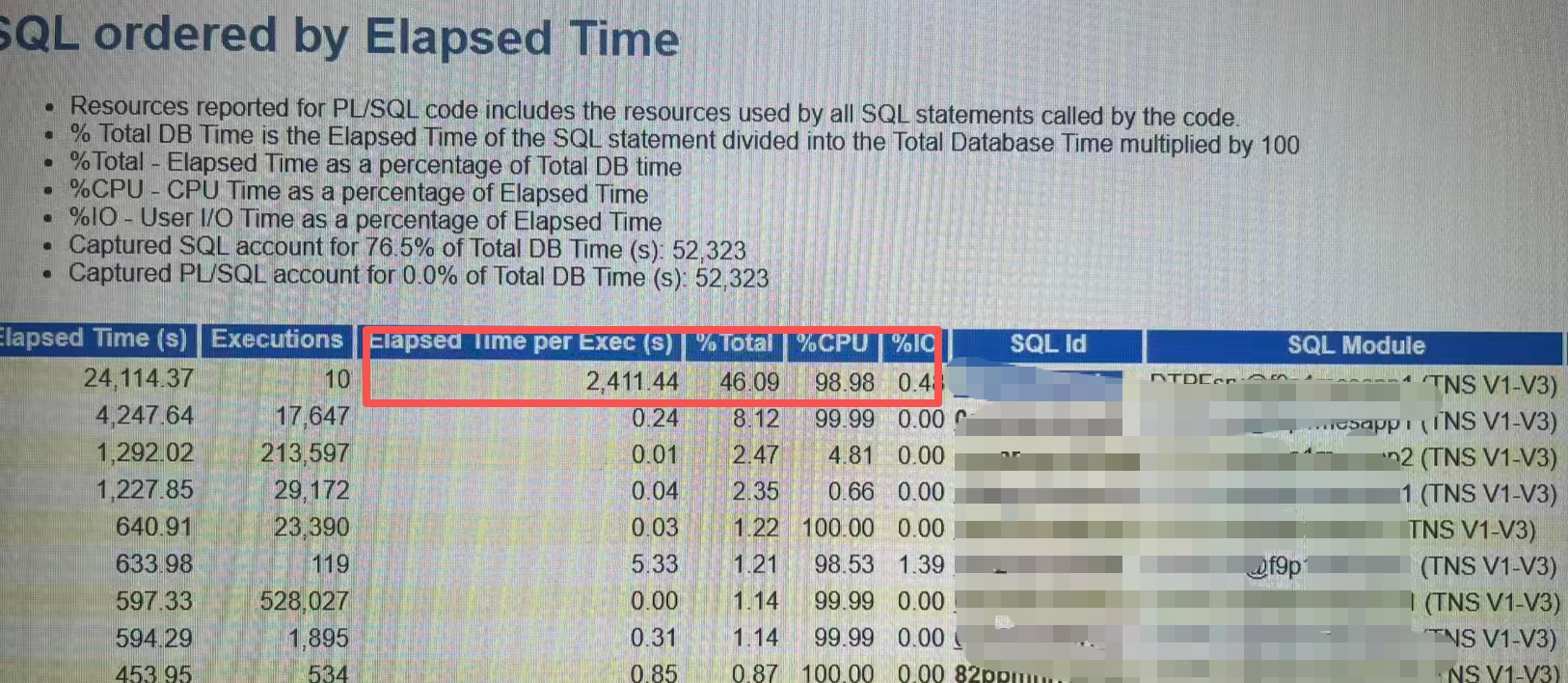
/4.以上都排除后,加上问题指向异常sql,拉取问题时段的AWR报表 看看能不能找到什么端倪
通过AWR轻松找到一个问题sql,该sql执行了10次 每次居然需要2400多秒,明显不太正常。
5.定位到这个异常sql,进一步来追查,这个sql 是不是发生了执行计划偏移
这里就想到了使用sqlhc来查一下这个sql id具体状况,使用办法很简单 执行sqlhc.sql 参数1 D,参数2:sql id
就可以得到一个压缩包,大概有如下的报告,关键为第一个main.html 这里有关于这个sql的执行的详细信息

更多 可以参考官方文档SQL Tuning Health-Check Script (SQLHC) (Doc ID 1366133.1)
从这里看到有两个执行计划,其中一个不正常有2000多秒,而且可以看到first snapshot时间和CPU的异常波动时间 完全吻合。
这里就可以基本断定,这次异常的CPU波动的直接原因是这个sql id执行计划偏移造成的。

根因
直接原因找到了,但是根本原因是什么?也就是说是什么造成的这个sql的执行计划变了。只有找到了根本原因才能从根本上解决这个问题。
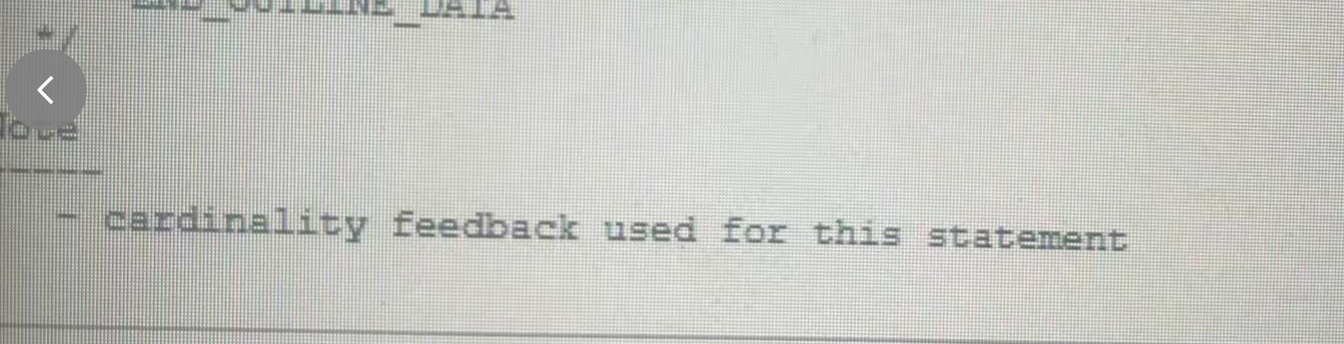
观察这个sql的执行计划 可以在执行计划的最后清楚的看到**cardinality feedback used for this statement,**一下就让我想起了之前曾经遇到过的一个案例,几乎一模一样。
前文:好好的数据库怎么跑不动了
何为基数反馈?
Cardinality Feedback是11gR2出现的新特性(ps:12C后改名为Statistics Feedback,统计反馈,本文还是以个人习惯称为基数反馈 ),基数反馈是优化器自动改进对基数估计错误的重复查询的计划的能力。由于多种原因,优化器可能不正确地估算基数,例如缺少统计信息、不准确的统计信息或复杂的谓词。基数反馈帮助优化器从错误计算中学习,以便使用更准确的基数估计生成更好的计划。
基数反馈是如何工作
即使统计数据被尽可能准确地计算,估计的基数可能也是不准确的。在第一次执行 SQL 语句时,会生成一个执行计划。在计划优化期间,会注意到某些类型的估算,并监视生成的游标。执行完成后,计划中的一些基数估算会与执行期间实际观察到的基数进行比较。如果发现这些估算与实际基数存在显著差异,则会存储更正后的基数以供以后使用。下次执行查询时,将再次对其进行优化(硬解析),而这次优化器将使用这些更正后的估算值来替代之前使用的原始估算值。基于更准确的统计数据可能会创建不同的计划。
Oracle 能够使用统计反馈重复地重新优化语句。这可能是必要的,因为基数差异可能取决于计划的结构和形状。因此,在第二次执行查询时,使用统计反馈生成新计划后,仍可能发现更多的基数估算与实际基数存在显著偏差。在这种情况下,Oracle 可以在下次执行时再次重新优化。
但是,有一些保障措施可确保在少数执行后这种情况将稳定下来,因此您可能会在最初的几次执行中看到计划的变化,但最终将选择出一个计划,并用于所有后续的执行。
流程图如下
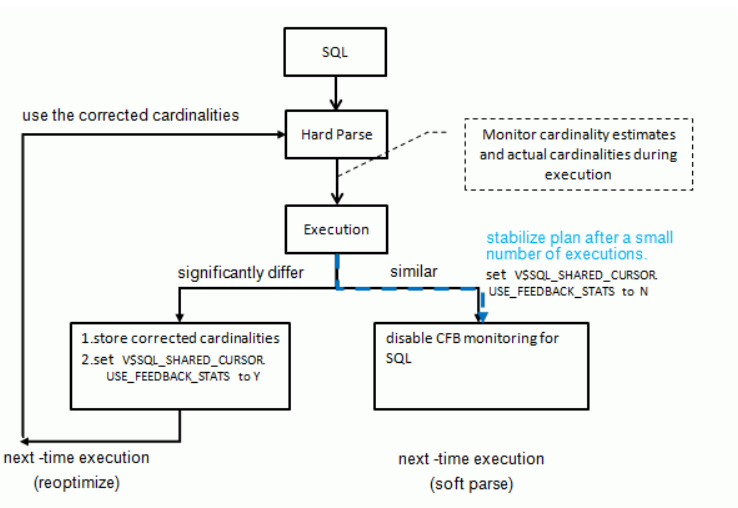
官方建议什么情况下适合启用基数反馈
- 没有统计信息且未使用动态采样表
- 表上有多个连接或分离的过滤谓词,且没有扩展统计信息
- 包含复杂运算符的谓词,优化器无法准确计算选择性估算值
在某些情况下,还有其他可用的技术来改善估算;例如,动态采样或多列统计允许优化器更准确地估算连接谓词的选择性。在这些技术适用的情况下,Statistics Feedback将不被启用。
然而,如果对于相关列的组合不存在多列统计信息,则优化器可以回退到使用Statistics Feedback。
如何关闭基数反馈
基数反馈有隐含参数_OPTIMIZER_USE_FEEDBACK控制,默认是开启的 ,可以在session和system级别关闭
1.会话级别或者系统级别关闭基数反馈
alter session set "_OPTIMIZER_USE_FEEDBACK" = FALSE;
alter system set "_OPTIMIZER_USE_FEEDBACK" = FALSE;
2.sql级别加hint
select /*+ opt_param('_optimizer_use_feedback' 'false') */ ...为什么基数反馈后执行计划反而变坏
参考Bug 16837274 - Cardinality feedback produces poor subsequent plan (Doc ID 16837274.8)
Description A suboptimal execution plan may be produced due to cardinality feedback for the object on the right side of NLJ .(nested loops join) Rediscovery Notes Bad plan due to cardinality feedback for the object on the right side of NLJ. Workaround Set "_optimizer_use_feedback"=false Note: This fix effectively fixes all of the cases fixed by Bug 13454409 and should be used instead of that fix.
处理办法
如果sqlid被刷出内存,在次被加载后就有可能触发基数反馈。 本次直接使用尝试coe_xfr_sql_profile.sql ,但是只能带出异常的sqlplan,没有带出正常的sql plan;这时候该如何处理?
如果一个sql的执行计划有问题,但是不能动到原sql,可以利用生成一个加了hint 的执行计划绑定到原有的sql中,这样不会影响到原来的sql,具体要求和步骤如下:
coe_load_sql_baseline.sql 和 coe_load_sql_profile.sql 有很多应用场景。下面以一个典型例子说明如何强制优化器使用只能通过 Hint 才能得到的执行计划。操作步骤
- 确保原始 SQL(不带 Hint)和加了 Hint 的 SQL 都在共享池中(可以通过先执行一遍来实现)。
- 分别找出两条 SQL 的 sql_id 和 plan_hash_value。
选择使用 Baseline 还是 Profile:
- 想要完全保证计划稳定性 → 使用 SQL Plan Baseline(推荐)
- 只想"引导"优化器但保留一定灵活性 → 使用 SQL Profile
3. 进入 sqlt/utl 目录。
目录下有两个脚本可实现本文目标:
- coe_load_sql_baseline.sql (11g 及以上)
把加了 Hint 的 SQL 的执行计划加载为原始 SQL 的自定义 SQL Plan Baseline。 - coe_load_sql_profile.sql (10g 及以上)
把加了 Hint 的 SQL 的执行计划加载为原始 SQL 的自定义 SQL Profile。
**4.运行脚本,**提供原始 SQL 的 sql_id 以及加了 Hint 的 SQL 的 sql_id 和 plan_hash_value。
示例环境准备:
SQL> -- 创建索引用于演示
SQL> create index i_emp_ename on emp(ename);
Index created.
SQL> -- 收集统计信息
SQL> exec dbms_stats.gather_table_stats(ownname=>'USER_ID',tabname=>'EMP')
PL/SQL procedure successfully completed.步骤 1:执行原始 SQL(不带 Hint)
SQL> select ename from emp where ename='name';
Plan hash value: 3045807146
---------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
---------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 6 | 1 (0)|
|* 1 | INDEX RANGE SCAN| I_EMP_ENAME | 1 | 6 | 1 (0)|
---------------------------------------------------------------------这就是我们要改变执行计划的原始语句。
步骤 2:执行加了 Hint 的 SQL
SQL> select /*+ FULL (EMP) */ ename from emp where ename='name';
Plan hash value: 2872589290
---------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
---------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 6 | 3 (0)|
|* 1 | TABLE ACCESS FULL| EMP | 1 | 6 | 3 (0)|
---------------------------------------------------------------这就是我们想要的"完美计划"。
步骤 3:查找两条 SQL 的 sql_id 和 plan_hash_value
SQL> select sql_id, plan_hash_value, sql_text
from v$sql
where sql_text like '%emp%';
SQL_ID PLAN_HASH_VALUE SQL_TEXT
------------- ----------------- -------------------------------------------------
0vdqhcj6gaqnt 3924418374 select sql_id ,plan_hash_value, sql_text from v$sql ...
4f74t4ab7rd5y 2872589290 select /*+ FULL (EMP) */ ename from emp where ename='name'
329d885bxvrcr 3045807146 select ename from emp where ename='name'- 原始 SQL_ID:329d885bxvrcr
- 加 Hint SQL_ID:4f74t4ab7rd5y
- 目标计划的 Plan Hash Value:2872589290
步骤 4:选择方案固定计划方案 A:使用 coe_load_sql_baseline.sql(推荐,强制使用指定计划)
要求:
- 原始 SQL 必须在共享池或 AWR 中
- 加 Hint 的 SQL 必须在共享池中
以 DBA 权限用户(如 SYSTEM)连接,不要用 SYS(SYS 模式下无法创建 staging 表,会报 ORA-19381)
SQL> @coe_load_sql_baseline.sql
Parameter 1:
ORIGINAL_SQL_ID (required)
Enter value for 1: 329d885bxvrcr
Parameter 2:
MODIFIED_SQL_ID (required)
Enter value for 2: 4f74t4ab7rd5y
PLAN_HASH_VALUE AVG_ET_SECS
-------------------- --------------------
2872589290 .003
Parameter 3:
PLAN_HASH_VALUE (required)
Enter value for 3: 2872589290
...
****************************************************************************
* Enter <User_Name> password to export staging table STGTAB_BASELINE_329d885bxvrcr
****************************************************************************
...
coe_load_sql_baseline completed.再次执行原始 SQL:
SQL> select ename from emp where ename='name';
Plan hash value: 2872589290
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 6 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| EMP | 1 | 6 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------
Note
-----
- SQL plan baseline "329D885BXVRCR_4F74T4AB7RD5Y" used for this statement原始 SQL 已经成功使用我们指定的执行计划,且创建了 SQL Plan Baseline。
方案 B:使用 coe_load_sql_profile.sql要求同上
SQL> @coe_load_sql_profile.sql
Parameter 1: ORIGINAL_SQL_ID → 329d885bxvrcr
Parameter 2: MODIFIED_SQL_ID → 4f74t4ab7rd5y
Parameter 3: PLAN_HASH_VALUE → 2872589290
...
coe_load_sql_profile completed.再次执行原始 SQL:
SQL> select ename from emp where ename='Name';
Plan hash value: 2872589290
...
Note
-----
- SQL profile "329D885BXVRCR_2872589290" used for this statement如何将sql plan 刷出share pool步骤如下
1.Find ADDRESS and HASH_VALUE using SQL_ID
SQL> select ADDRESS, HASH_VALUE from V$SQLAREA where SQL_ID like '<SQL_ID>';
Example:
SQL> select ADDRESS, HASH_VALUE from V$SQLAREA where SQL_ID='XXXXXXXXXXX';
ADDRESS HASH_VALUE
---------------- ----------
000000085FD77CF0 808321886
2) Now purge the plan from Shared pool using DBMS_SHARED_POOL procedure
SQL>exec DBMS_SHARED_POOL.PURGE ('000000085FD77CF0, 808321886', 'C');
PL/SQL procedure successfully completed.
NOTE:
'C' (for cursor) or 'S' (for SQL)
3) Check the shared pool again after the purge successfully completes which should show no rows.
SQL> select ADDRESS, HASH_VALUE from V$SQLAREA where SQL_ID='XXXXXXXXXXX';
no rows selected参考文档
Directing Plans with Baselines/Profiles Using coe_load_sql_baseline.sql / coe_load_sql_profile.sql (shipped with SQLT) (Doc ID 1400903.1)
Document 1524658.1 FAQ: SQL Plan Management (SPM) Frequently Asked Questions
Bug 16837274 - Cardinality feedback produces poor subsequent plan (Doc ID 16837274.8)
SQL Tuning Health-Check Script (SQLHC) (Doc ID 1366133.1)
Document 1359841.1 Plan Stability Features (Including SPM) Start Point
Document 271196.1 Automatic SQL Tuning - SQL Profiles