在 DiT (Diffusion Transformer) 模型(如 HunyuanVideo)的训练中,LayerNorm 和 AdaLayerNorm (AdaLN) 是计算图中出现频率极高的算子。原生的 PyTorch 实现往往受限于显存带宽(Memory Bound),导致频繁的内核启动和显存读写。
TeleTron 框架通过引入融合 CUDA 内核(Fused CUDA Kernels),将归一化、缩放(Scale)和位移(Shift)操作合并为单一内核,显著提升了训练吞吐量。本文将带你深入代码底层,剖析这一优化技术的完整实现路径。
1. 灵活的开关:环境控制机制
优秀的工程设计允许在"高性能"与"调试模式"之间无缝切换。TeleTron 通过环境变量实现了对融合内核的动态控制。
在模型初始化阶段(model.py),代码会检查 FUSED_KERNELS 环境变量:
python
# model.py:70
if os.environ.get("FUSED_KERNELS"):
fused_kernels_bool = bool(int(os.environ.get("FUSED_KERNELS")))
self.fused_kernels = fused_kernels_bool这个标志位会一路向下传递,从 HunyuanVideoTransformer3DModel 传至具体的 Transformer Block,最终决定 FusedAdaLayerNormZero 层是调用原生 PyTorch 实现还是优化的 CUDA 内核。
💡 核心设计: 这种非侵入式的设计使得开发者可以在不修改代码的情况下,通过 export FUSED_KERNELS=1 开启加速,或者在遇到 NaN 问题时快速回退排查。
2. 算子融合的核心:AdaLayerNorm 实现路径
AdaLN 是 DiT 架构的核心组件,负责根据时间步(Timestep)和条件嵌入调节特征。
2.1 融合逻辑
在原生实现中,AdaLN 需要三个步骤:GroupNorm/LayerNorm -> 调制参数计算(Scale/Shift)-> 逐元素仿射变换。这导致了三次显存读写。
TeleTron 的 FusedAdaLayerNormZero 将其压缩为一步:
python
# dit_fusedlayers.py
class AdaLNModelFunction(Function):
@staticmethod
def forward(ctx, x, scale, shift, epsilon, cols):
# ... 省略部分检查代码 ...
# 直接调用 C++ 绑定的 CUDA 接口
fused_adaln.torch_launch_adaln_forward(
output, x_norm, x, scale, shift_, ctx.rows, ctx.cols, ctx.eps, invvar
)
return output2.2 CUDA 内核深度优化 (adaln_forward.cu)
源码展示了几个关键的优化手段,针对 cols=3072(HunyuanVideo 的隐藏层维度)进行了特化:
-
Welford 在线算法 :
为了在 BF16 半精度下保持数值稳定性,内核使用了 Welford 算法计算均值和方差。这避免了直接平方求和可能导致的溢出或精度损失。
cpp// adaln_forward.cu WelfordCombine<float>(__bfloat162float(val.x), &thread_mean, &thread_m2, &thread_count); -
向量化访存 (Vectorized Memory Access) :
代码使用了 float4 类型进行加载,每次读取 128 位数据(即 8 个 BF16 元素)。这极大提高了显存带宽利用率。
cppconstexpr int pack_size = 8; // ... *reinterpret_cast<float4*>(pack_data) = *reinterpret_cast<float4*>(input_ptr); -
Warp 级归约 (Warp Reduction) :
利用 __shfl_down_sync 在寄存器层面进行线程间通信,快速计算 block 内的统计量,避免了慢速的共享内存原子操作。
3. 极致轻量化:RMSNorm 融合实现
针对 Attention 机制中的 QK-Norm,TeleTron 实现了专门的 RMSNorm 融合内核。
3.1 针对 Head Dimension 的特化
与 AdaLN 不同,RMSNorm 在此处主要用于 Attention Head 的归一化,因此代码强制检查 cols=128(即 Head Dim):
python
# dit_fusedlayers.py:366
if fused_kernels_bool is True and fused_rmsnorm is not None and self.hidden_size == 128:
return RMSNormModelFunction.apply(...)3.2 高效的 CUDA 实现 (rms_forward.cu)
RMSNorm 不需要计算均值,只需要计算均方根。内核采用了极其紧凑的实现:
-
Grid 配置:采用 2D Grid (rows >> 4) 和 2D Block (16x16),充分利用 GPU 的 SM 资源。
-
快速数学指令:通过编译器标志 --use_fast_math 和代码中的 rsqrt 指令加速计算。
-
寄存器重用:输入数据加载到寄存器后,先计算平方和,归一化后再写回,全程无多余显存访问。
4. 桥接 Python 与 CUDA:编译加载机制
最后,所有的 CUDA 代码通过 PyTorch 的 CppExtension 机制暴露给上层。
4.1 JIT/AOT 编译配置 (setup.py)
构建脚本明确指定了高性能编译选项:
python
# setup.py
CUDAExtension(
"fused_adaln",
sources=[...],
extra_compile_args={
'nvcc': [
'-O3',
'-DENABLE_BF16',
'--use_fast_math',
'-gencode=arch=compute_90,code=sm_90' # 针对 H800/H100 Hopper 架构优化
]
}
)4.2 C++ 绑定
通过 PYBIND11_MODULE 将 C++ 函数注册为 Python 模块,使得 Python 层可以直接传递 torch.Tensor 指针给 CUDA 内核,实现了零拷贝调用的开销最小化。
总结
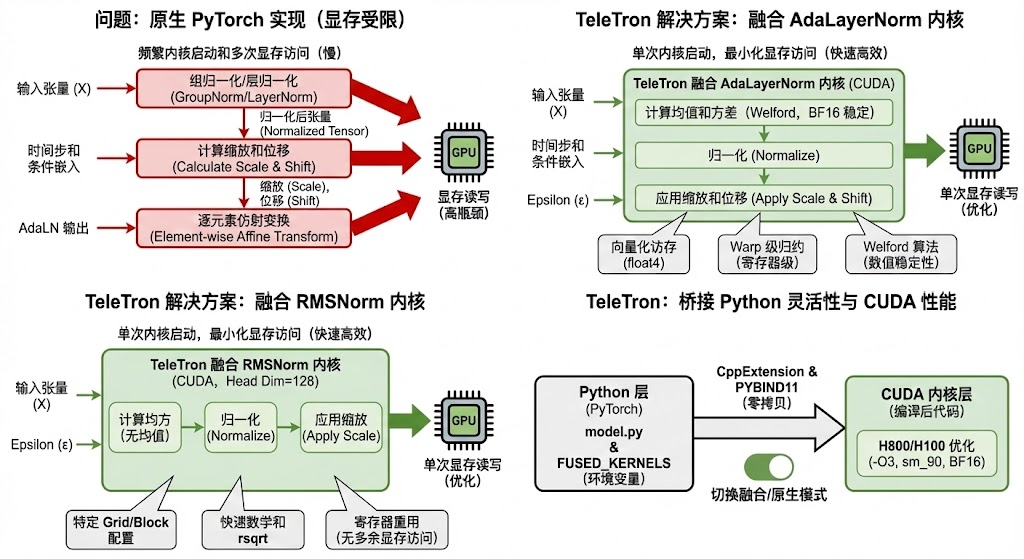
TeleTron 的融合内核实现是算子融合(Operator Fusion)技术的教科书式案例。通过将 Python 层的多次调度合并为一次精心手写的 CUDA 内核执行,并结合向量化访存 、Welford 算法 以及针对特定维度的模版特化,它成功打破了 Transformer 训练中的显存墙。
对于追求极致训练效率的 AI 基础设施工程师来说,深入理解并复用这套路径,是提升大模型训练效率的关键一步。
本文代码片段截取自 TeleAI-infra Team 的 TeleTron 框架源码。