一、前言
前两天针对轻量级TTS引擎Kokoro做了一些测试( https://mp.weixin.qq.com/s/xKBLfAkfImwHrjYIml0KuA ),测试下来发现效果居然挺好的,而且自带8种音色的支持,纯CPU跑,速度还快,测完了我就停不下来了,当时就想把它整合到我的OddTTS项目,今天周末终于有空,于是就简单搞了一下,现在已经在我的小落同学上用上了。
二、主要更新
先看效果
正常语速wav格式: https://www.oddmeta.net/wp-content/uploads/2026/03/OddTTS-kokoro-正常速度wav格式.wav
正常语速mp3格式: https://www.oddmeta.net/wp-content/uploads/2026/03/OddTTS-kokoro-正常速度mp3格式.mp3
3倍语速mp3格式: https://www.oddmeta.net/wp-content/uploads/2026/03/OddTTS-kokoro-3倍速mp3格式.mp3
更新内容
- demo前端从gradio改成flask(降低依赖)
- BaseTTS接口调整
- MP3、WAV格式转换
- Kokoro 中文引擎支持。
三、如何使用
1. 安装
bash
pip install -i https://pypi.org/simple/ oddtts2. 启动
- 默认的参数启动:绑定127.0.0.1环回地址,默认使用9001端口。
bash
oddtts启动后,浏览器打开地址:http://127.0.0.1:9001
- 自定义参数启动
若要允许其他IP访问,请使用以下命令启动服务,将host设置为0.0.0.0,端口也可以改成你自定义的端口。
bash
oddtts --host 0.0.0.0 --port 8080启动后,浏览器打开地址:http://your_ip_addr:8080
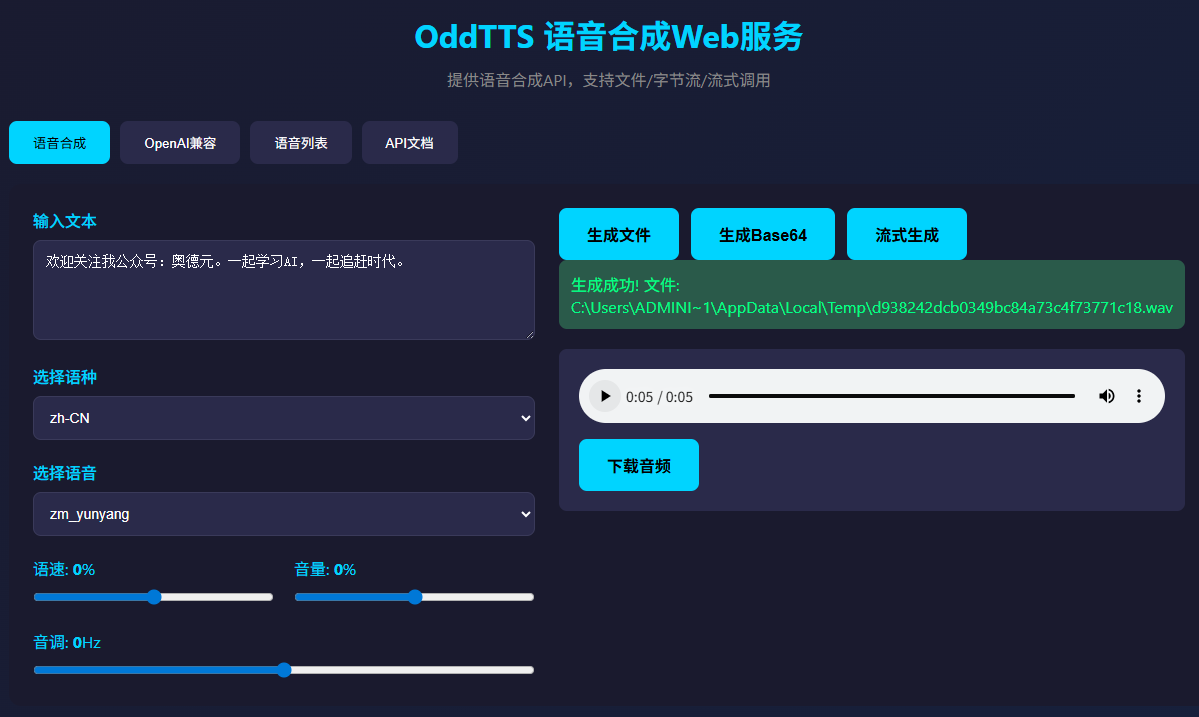
3. API调用示例
以下是一个OddTTS的API调用的示例,建议用OpenAI 兼容接口
from openai import OpenAI
base_url = "http://localhost:9001/v1"
model = "oddtts-1"
api_key = "dummy"
voice = "zf_xiaobei"
text = "欢迎关注我的公众号: 奥德元。一起学习AI,一起追赶时代!Good good study, day day up!"
def test_openai_tts_api(voice_id):
client = OpenAI(
api_key=api_key,
base_url=base_url
)
response = client.audio.speech.create(
model=model,
input=text,
voice=voice_id,
response_format="mp3"
)
response.write_to_file("output.mp3")
if __name__ == "__main__":
test_openai_tts_api(voice)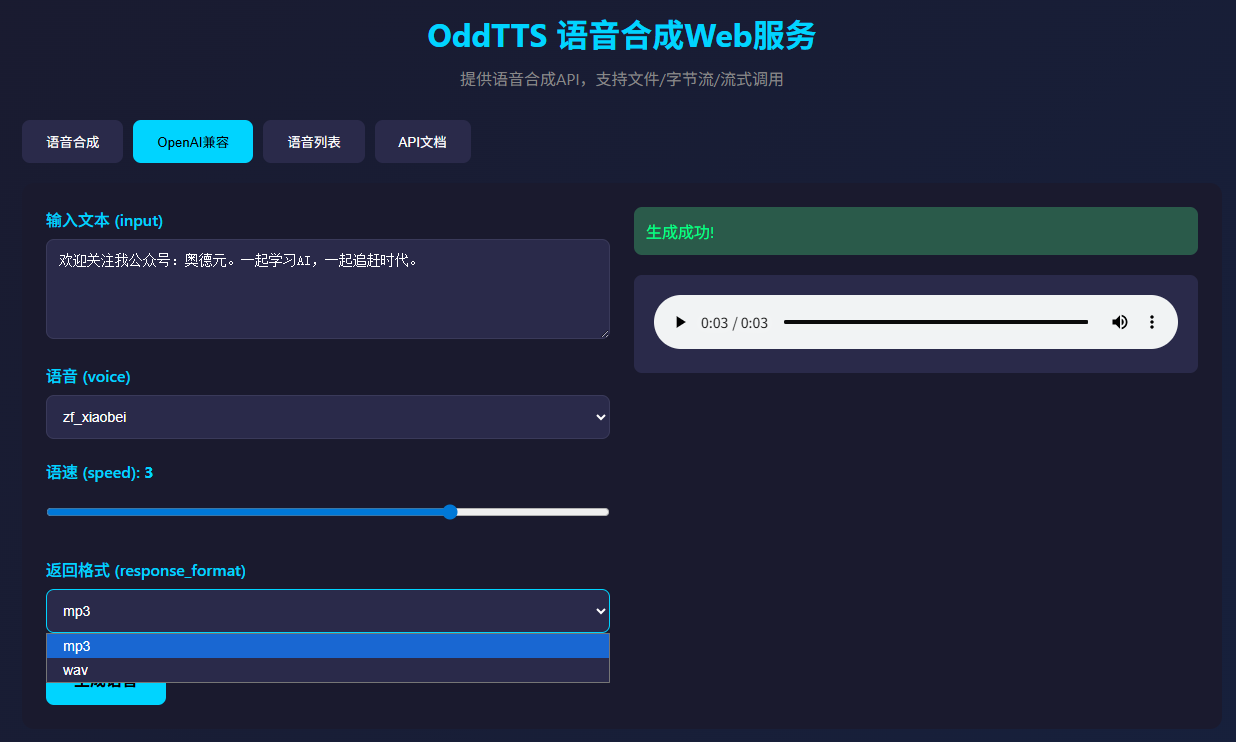
四、注意事项
模型下载问题
Kokoro的模型放在huggingface.co上,在国内访问存在问题,解决方案:
- Windows
set HF_ENDPOINT=https://hf-mirror.com
set HF_HOME=F:/ai_share/models
- Linux/MacOS
export HF_ENDPOINT=https://hf-mirror.com
export HF_HOME=/opt/ai_share/models
输出wav正常,输出MP3报错
OddTTS的依赖里有加了ffmpeg,但是如果你机器上原先就有安装过ffmpeg有可能会报错,若是报错了,请再手动安装一下ffmpeg即可。
服务启动失败
- 检查端口是否被占用
- 确认所有依赖包已正确安装
- 查看日志文件获取详细错误信息
语音合成失败
- 检查TTS引擎配置是否正确
- 确认选择的语音存在于当前TTS引擎中
- 对于某些需要联网的引擎,确认网络连接正常(如: EdgeTTS)
如何切换TTS引擎
- 修改
oddtts_config.py文件中的tts_type配置项 - 重启服务使配置生效
输出格式
- 默认输出格式为mp3
- 可以通过
response_format参数指定其他格式,如wav、mp3等
环境要求
- Python 3.12+(低版本也能用,但是建议用3.12+)
- 至少 2GB 可用磁盘空间(模型350M,再加python依赖,语音合成临时文件)
- 推荐 4GB+ 内存