Browser-CDP + Python 抓取 SPA 单页面应用内容

一、问题背景
如果要抓取的页面 是一个 React SPA(单页面应用),传统抓取手段均失效:
方法 问题
web_fetch 只返回空壳 HTML(含 webpack chunk 引用,无实际内容)
web_search 未配置 API Key,无法使用
browser(标准) 被 SSRF 策略阻止,无法访问
ProSearch 脚本 PowerShell 编码冲突导致 JSON 解析失败
根本原因:SPA 内容由 JavaScript 动态渲染,静态 HTTP 请求无法获取。
二、解决方案:Browser-CDP Skill
2.1 核心思路
通过 Chrome DevTools Protocol(CDP)控制真实浏览器实例,加载页面并等待 JS 执行完毕,再提取渲染后的 DOM 文本内容。
2.2 技术架构
browser-cdp skill
├── browser_launcher.py → 启动/管理 Chrome 实例 + CDP 端口
├── cdp_client.py → CDP 协议客户端(发送命令、接收事件)
└── page_snapshot.py → 页面快照(get_text / screenshot)关键参数:
launch( browser='chrome',
reuse_profile=False, # 隔离实例,避免用户登录态冲突
wait_for_user=False )2.3 核心代码模板
import sys
sys.path.insert(0, r'\browser-cdp\scripts')
from browser_launcher import BrowserLauncher, BrowserNeedsCDPError
from cdp_client import CDPClient
from page_snapshot import PageSnapshot
# 1. 启动浏览器(隔离 profile,无用户登录态)
launcher = BrowserLauncher()
try:
cdp_url = launcher.launch(browser='chrome', reuse_profile=False)
except BrowserNeedsCDPError as e:
print(f'请用户在 Chrome 中授权远程调试: {e}')
sys.exit(1)
# 2. 连接 CDP
client = CDPClient(cdp_url)
client.connect()
# 3. 创建新标签页
tab = client.create_tab('网址')
client.attach(tab['id'])
# 4. 等待页面渲染(5秒适应 SPA 加载)
import time
time.sleep(5)
# 5. 提取文本内容
snapshot = PageSnapshot(client)
text = snapshot.get_text()
# 6. 保存
with open('output.md', 'w', encoding='utf-8') as f:
f.write(f'# 标题\n\n{text}')三、批量抓取:2 分钟间隔策略
3.1 遇到的问题
早期版本脚本在抓取第 2 个文档时遇到错误:
CDP error for 'Target.attachToTarget': [-32001] Session with given id not found.原因:CDP Session 在关闭标签页或超时后失效,后续 attach 操作失败。
3.2 解决:每次操作前检查 session 有效性
for i, (name, url) in enumerate(urls):
try:
# 每次操作前检查 session 是否有效
client.send('Target.getTargets', {})
except:
# session 无效,重新连接
client.connect()
# 创建新标签页
tab = client.create_tab(url)
client.attach(tab['id'])
# 等待渲染
time.sleep(5)
# 提取内容
snapshot = PageSnapshot(client)
text = snapshot.get_text()
# 保存
with open(f'扣子文档_{name}.md', 'w', encoding='utf-8') as f:
f.write(f'# {name}\n\n{text}')
# 等待 2 分钟(避免频率过高)
if i < len(urls) - 1:
time.sleep(120)3.3 稳定性保障
问题 解决方案
CDP session 失效 每次操作前检查并重连
Chrome 未授权调试 脚本退出,提示用户手动授权
页面未完全渲染 time.sleep(5) 等待
脚本被系统终止(SIGKILL) 使用 PTY 模式运行,缩短等待时间到 2 分钟
核心功能:
-
启动隔离 Chrome 实例
-
遍历 20 个文档 URL(每 2 分钟抓取一个)
-
自动重连失效的 CDP session
-
保存为 Markdown 文件(含抓取时间、来源 URL)
六、关键经验总结
6.1 SPA 抓取三原则
-
永远使用真实浏览器:SPA 内容由 JS 渲染,静态请求无效
-
等待页面稳定:SPA 加载后还需等待数据请求完成,一般 3-5 秒
-
隔离优于复用 :使用
reuse_profile=False避免与用户 Chrome 冲突
6.2 批量抓取注意事项
-
设置合理间隔(≥2 分钟),避免被封禁
-
每次操作前检查 CDP session 有效性
-
使用 PTY 模式运行长时间脚本,防止被系统 SIGKILL
-
脚本崩溃后能断点续传(已有文件不重复抓取)
6.3 编码问题
-
PowerShell 5.1 的
Invoke-RestMethod会将 Body 静默转为 GBK -
解决:使用 Python 的
requests库代替,或将 Body 转为 UTF-8 字节数组 -
脚本内部使用 Python,绕过 PowerShell 编码问题
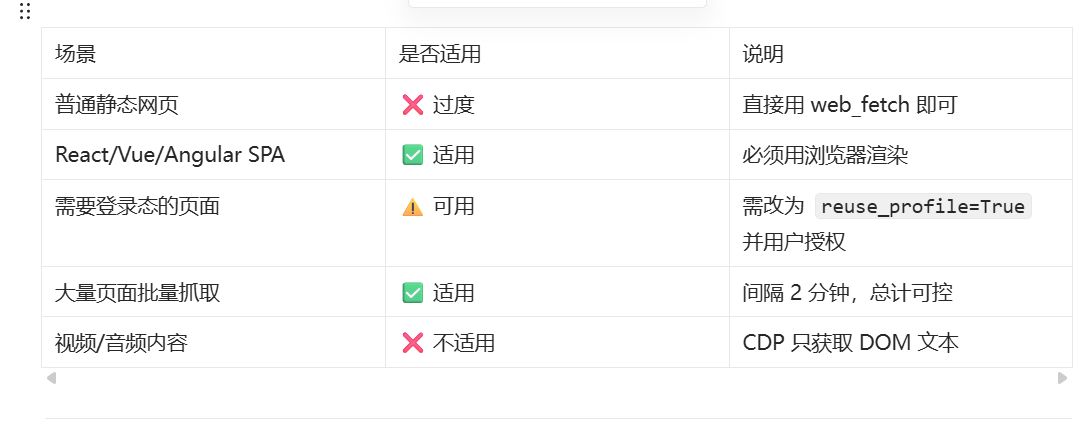
七、适用场景