前一篇OpenSpec和Superpowers串不起来跑?问题出在交接格式上 聊了OpenSpec(管规格)和Superpowers(管工程纪律)组合使用的实践,文中给出了翻译层的方案来解决"两个工具串不上"的问题------在中间加一个plan-ready.md,把OpenSpec的需求语言转成Superpowers能直接执行的工程语言,留言区反应很热闹,聊得最多的两个评论:一是想详细了解skill实现,二是能不能开源。
这段时间也在实际项目里跑了很多次,好消息是propose→apply→archive的三阶段大框架稳定,没有结构性改动。坏消息是发现了五个设计阶段没预见的问题------其中一个恰恰出在翻译层本身。每一个都推翻了最初的一个设计假设。
我把整个skill重写了一遍,改名叫HyperSpec,正式开源了。简单说,HyperSpec是一个AI编程工作流的编排层------协调两个工具:OpenSpec管"做什么和为什么"(规格文档),Superpowers管"怎么做和做得对不对"(TDD + 代码审查)。HyperSpec本身不干具体活,只做项目感知、状态追踪、阶段路由和commit纪律。你给它一个需求,它自动把需求变成规格文档,再变成可执行的实现计划,然后按计划TDD实现、验证、审查、归档,一条龙走完。
这篇把最新的完整实现拆开给你看------有什么、哪里改了、为什么改、怎么改的。
打开HyperSpec:目录结构和文件分工
HyperSpec的目录结构很简单,5个文件:

分工逻辑和之前一样:SKILL.md是调度员,不做具体工作,负责状态检测和阶段路由。三个阶段文件各自独立,互不知道对方的存在,文件之间通过openspec/changes/下的文档和superpowers/plans/下的实现计划交接。
如果你看过之前的文章,会发现一个变化:plan-ready.md不见了。之前的设计里,这个文件卡在spec和build之间,由spec阶段最后一步生成,被build阶段第一步消费------它是OpenSpec和Superpowers之间的"翻译层"。**它被去掉了!**为什么?后面细说。
三阶段工作流:propose→apply→archive
一次完整的开发周期仍然分为三个阶段,每个阶段有质量硬门和出口条件:

propose阶段 是OpenSpec的地盘,新增了"项目分析"作为第一步,然后需求确认、生成规格文档、生成实现计划。质量硬门不变:一条代码都不许写。
apply阶段 是Superpowers的地盘,读propose阶段生成的实现计划,按TDD铁律执行,验证,审查。质量硬门不变:禁止修改规格文档。
archive阶段做验证和归档,拿着design.md逐项检查代码实现是否和规格一致,全部对上后归档。质量硬门不变:只做验证不改代码。
大框架没变,变化藏在每个阶段的细节里。接下来逐阶段拆开,对比讲清楚哪里改了、为什么改、怎么改的。
propose阶段:去掉翻译层,让下游直接消费上游产出
propose阶段现在是5个步骤:
-
项目分析
------自动探测语言、框架、构建工具(新增);
-
需求确认------和用户交互确认需求;
-
调用openspec-propose------产出proposal.md、design.md、specs/、tasks.md;
-
调用writing-plans------产出带checkbox的实现计划;
-
用户确认。
对比之前的设计,少了"任务预拆分"------就是生成plan-ready.md的那一步。这是最大的一个变化。
原来的设计: OpenSpec生成4个文档 → 编排skill把它们翻译成plan-ready.md → Superpowers的writing-plans拿到plan-ready.md展开成实现计划。翻译层在中间做"需求文档→执行指令"的转换。
实际踩到的坑:
**两层翻译导致token浪费(毕竟token也挺贵的)。**原来从openspec artifacts到最终实现计划,中间要经过两次AI生成:先由编排skill把openspec的4个文档翻译成plan-ready.md(花一次token),再由writing-plans把plan-ready.md展开成带TDD微步骤的实现计划(又花一次token)。两次生成的内容大量重叠。
先看中间产物plan-ready.md长什么样(编排skill花token生成的):
go
### Task 1: JWT认证基础设施
- 目标:搭建JWT签发和验证的基础设施
- 改动文件:JwtUtil.java(新建), AuthFilter.java(新建)
- 验证方式:mvn test -pl auth
### Task 2: 用户登录接口
- 目标:实现POST /api/login,签发token
- 改动文件:LoginController.java(新建), UserService.java(修改)
- 验证方式:mvn test -pl controllerwriting-plans拿到它,展开后的实现计划(实际格式):
go
### Task 1: JWT认证基础设施
**Files:**
- Create: `src/auth/JwtUtil.java`
- Create: `src/auth/AuthFilter.java`
- Test: `src/test/auth/JwtUtilTest.java`
- [ ] **Step 1: Write failing test for JwtUtil**
// ... 省略具体设计代码
- [ ] **Step 2: Run test to verify it fails**
Run: `mvn test -pl auth`
- [ ] **Step 3: Write JwtUtil implementation**
// ... 省略具体设计代码
- [ ] **Step 4: Run test to verify it passes**
Run: `mvn test -pl auth`
- [ ] **Step 5: Commit**
### Task 2: 用户登录接口
**Files:**
- Create: `src/controller/LoginController.java`
- Modify: `src/service/UserService.java`
- [ ] **Step 1: Write failing test for LoginController**
// ... 省略具体设计代码
- [ ] **Step 2: Write LoginController implementation**
// ... 省略具体设计代码
- [ ] **Step 3: Compile check**
Run: `mvn compile`对比一下就清楚了------同样的任务名("JWT认证基础设施"、"用户登录接口"),同样的文件路径(JwtUtil.java、AuthFilter.java),同样的验证命令(mvn test -pl auth)。这一层翻译本质上是花token把已有的信息重新组织了一遍,然后writing-plans又花token把它再组织一遍。两次组织的内容大部分重叠,真正有价值的增量只有TDD微步骤那部分。
**现在的设计:**去掉plan-ready.md,让writing-plans直接消费openspec的4个产出文档。但直接扔给它也不行------openspec的文档里只有需求和技术方案,没有项目的技术栈信息。writing-plans不知道项目是Java还是Python、用Maven还是npm,就会生成错误的import路径和构建命令。所以HyperSpec在调用writing-plans时,把项目的语言、框架、构建工具、编译命令作为上下文一起传入。这样writing-plans一步就能生成和技术栈匹配的实现计划,不需要中间翻译层。这是propose.md里的实际源码:
go
# propose.md Step 4: 调用 writing-plans
变更名: add-user-auth
项目技术栈: java + spring-boot
构建工具: maven
测试框架: mvn test
项目结构: single-module
编译命令: mvn compile -q
计划保存路径: superpowers/plans/2026-05-17-add-user-auth.md
编译约束:
- 每个Task完成后必须使用 mvn compile -q 验证编译
- 接口和实现分开定义在不同Task会导致编译失败,
必须在同一Task中同时修改
checkbox唯一性约束:
- 每个Step的描述必须全局唯一,
不能仅靠步骤编号区分
框架API注意事项:
- 项目中实际的API签名(从已有代码中扫描)
openspec artifacts:
- proposal.md、design.md、specs/、tasks.md 的完整内容对比一下新旧参数的差异。旧设计只传了任务拆分结果(plan-ready.md),新设计传的是完整的技术栈上下文------编译命令、编译约束(接口+实现不能拆开)、框架API的实际签名。writing-plans拿到这些,一步就能生成正确的实现计划。少了一层翻译,少了一层token浪费,也少了一层同步负担。
但编排层不是"调完就不管了"。HyperSpec在调用writing-plans前后各做了一件事,这两个步骤是之前的设计完全没有的。
**调用前的API验证。**writing-plans生成的计划里会包含详细的代码实现,代码中会有import语句和方法调用。但如果项目用的框架有多个重载方法,或者某个工具类的实际签名跟直觉不一样,计划里写的就是错的------到apply阶段才会发现编译失败。所以HyperSpec在调用writing-plans之前,会扫描项目中已有的同类代码(比如同模块的Controller、Service),提取框架API的实际签名,作为约束传入。这样writing-plans从一开始就能生成正确代码的import和方法调用,不用到apply阶段再修。
**调用后的质量审查。**writing-plans生成计划后,HyperSpec不是直接用,而是逐项检查:接口和实现是不是放在了同一个Task里(拆开会编译失败)、import路径是否跟项目实际路径一致、有没有无意义的占位代码、前面Task定义的类型后面Task是否正确引用。发现问题直接在计划文件里修复。这一步确保计划进入apply阶段时是可执行的,不会到编译时才暴露问题。
编排层的价值不只是"把A的输出传给B"。调用前准备充分的上下文,调用后验证结果的质量,这两步才是真正减少返工的关键。
propose阶段的新成员:自适应技术栈检测
上面那段参数里的"项目技术栈: java + spring-boot,构建工具: maven"从哪来的?propose阶段新增了第一步:项目分析器。这也是实战踩出来的需求。
原来的设计: 对所有项目一视同仁,apply阶段的编译检查步骤就一句话:"运行一次compile"。Java/Maven项目没问题。换成go语言项目?Python项目?实际踩到的坑:go项目执行task后编译检查报错,整个流程卡住。compile这个命令根本不存在。
现在的设计: 首次运行时自动扫描项目------看根目录有没有pom.xml、package.json、go.mod------推导出编译命令和测试命令,存到状态文件里:

后面的阶段直接用推导出来的命令。Python项目检测到没有编译步骤,跳过。零配置,开箱即用。
还有一步容易忽略:推导完命令后会实际运行一次验证。 如果编译失败是因为环境问题(JDK版本不匹配、依赖下载不下来),立即阻塞并报告,等用户确认正确的命令后再继续。如果失败是因为已有代码的编译错误,命令本身没问题,正常进入后续流程。不是推导完就完事,还得验证推导结果确实能用。
apply阶段:从"一刀切"到多因子自适应执行
apply阶段的步骤没有大变:读实现计划→执行(TDD+子代理审查)→验证→全局审查→最终确认。变化在执行模式的选择逻辑上。
**原来的设计:**一条规则------任务≥6用子代理并行执行,≤5在当前会话串行执行。
**实际踩到的坑:**8个task,但全部在改同一个Controller,前后有严格依赖关系。按规则应该并行,但并行意味着多个子代理同时改一个文件,冲突概率极高。反过来,4个task但分别改4个独立模块,串行执行浪费时间。
**现在的设计:**多因子决策。除了任务数量,还看三个维度:
-
任务独立性
------任务之间有没有依赖关系?高独立性适合并行
-
跨模块性
------涉及几个不同模块/目录?≥3个模块倾向并行
-
项目结构
------monorepo还是单模块?monorepo更容易并行
**决策依据从"有多少活"变成了"活和活之间有没有冲突"。**4个独立task也可以并行(子代理不会打架),6个强依赖task也可以串行(避免冲突)。
完整的决策规则(来自apply.md源码):
go
# apply.md: 智能执行模式选择
完整模式(subagent-driven-development):满足任一条件
- 任务 ≥ 6
- 涉及 ≥ 3 个不同模块/目录的修改
- monorepo 结构 + 任务 ≥ 3
- 任务间无依赖关系(独立性高)且任务 ≥ 4
轻量模式(inline执行):满足任一条件
- 任务 ≤ 5 且集中在 1-2 个模块
- 任务间有强依赖关系(需要顺序执行)
- 独立性否决:即使满足完整模式条件,
但存在强编译依赖时仍优先轻量模式选完执行模式后,每个task完成时的提交纪律也有讲究。不是"写完代码就commit",而是一条原子性流水线:编译检查通过 → 更新计划文件的checkbox → 更新.hyperspec-state.yaml的checkpoint → 把代码+计划文件+状态文件一起commit。四步一个commit,全程不做push。先更新状态再commit,保证了三者一致------如果commit前中断,重跑时该task会被重新执行(但代码已写入,TDD测试会直接通过);如果commit后中断,checkpoint和checkbox已更新,重跑时会跳过该task。
还有一个安全阀:全局代码审查如果循环超过3次仍有Critical问题,apply阶段不会继续死磕,而是提示用户"可能需要回到propose阶段重新审视设计方案"。防止AI在一个设计层面就有问题的方案上反复修补,浪费token却修不好。
状态管理:从文件扫描到结构化状态机
propose阶段和apply阶段各干各的,谁来协调?SKILL.md。它的状态检测逻辑也做了大改。
**原来的设计:**每次触发都扫描文件系统------有没有活跃变更?有没有plan-ready.md?计划文件的checkbox勾了几个?只能区分到阶段级别,不知道具体在哪个步骤。apply阶段执行了8个task中的3个然后中断了,重新启动只能判断"你在apply阶段",然后从头检查所有checkbox来猜进度。
现在的设计: 引入.hyperspec-state.yaml,一个结构化的状态文件。里面记录了当前阶段、精确到task级别的checkpoint,以及项目的技术栈信息:
go
# .hyperspec-state.yaml(来自SKILL.md设计)
version: 1
active_change: add-user-auth
phase: apply
checkpoint: task-3-complete
project_profile:
languages: [java]
frameworks: [spring-boot]
build_tool: maven
compile_command: mvn compile -q
test_command: mvn test
structure: single-module
has_ci: true启动时先读这个文件做快速路由------不用扫描目录,直接知道"在apply阶段的task-3完成后中断了"。然后在关键节点验证:状态文件说task-3完成了,就检查task-3的checkbox确实勾了。
整个流程有12个checkpoint,从profiler-done到done,每个对应一个明确的系统状态。apply阶段每个task完成后先更新checkpoint再commit,保证了两者的一致性------中断后从checkpoint声明的位置恢复,不用猜。
SKILL.md里的跨阶段验证逻辑(源码):
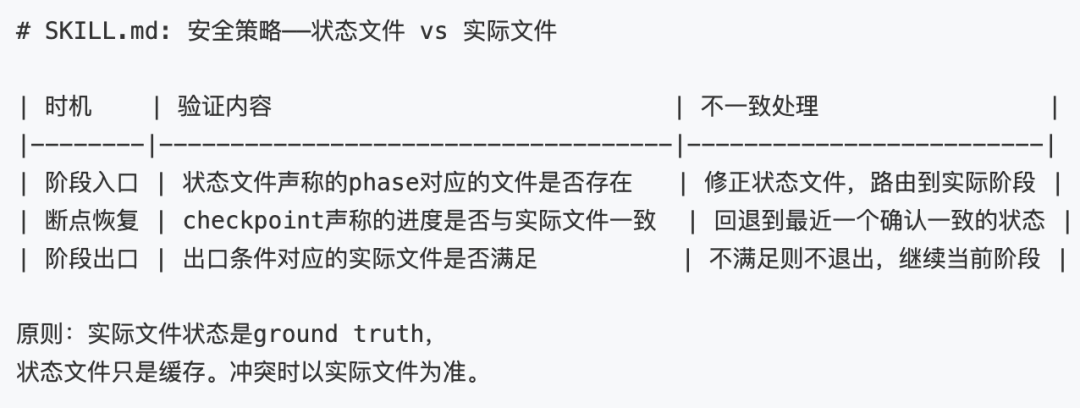
状态文件说"apply已完成",但检查计划文件发现还有checkbox没勾------**以实际文件为准,回退到apply阶段。**这个"状态文件是缓存,文件系统是真相"的双校验机制,比单纯依赖任何一方都可靠。
上篇说"AI没有可靠的跨会话记忆,但文件是持久的"。这句话只对了一半------文件确实持久,但扫描文件来推断状态的粒度太粗。状态文件做快速路由,实际文件做真相校验,两者结合才是正解。
archive阶段:一致性验证与断点恢复
archive阶段的变化最小。拿着design.md和specs/逐项检查代码实现是否和规格一致,验证通过后调用openspec-archive-change归档。这块上篇已经讲过,不重复。
**原来的问题:**archive阶段中断了,重新启动不知道验证跑到哪了------只能重来一遍。
现在的设计: 新增了一个.close-verification-done标记文件------验证完成后创建,中断后根据这个文件判断是重跑验证还是直接进归档。和apply阶段的checkpoint机制一脉相承。
验证发现不一致时的处理也值得说说。HyperSpec会列出所有不一致项,让用户选择:改代码 还是改规格 。改代码的简单修复可以在archive阶段直接做;如果改动复杂(会影响规格定义),就回退到apply阶段重新走一圈。改规格则直接更新openspec文档。但无论选哪种,修复后都必须删掉验证标记文件、回退checkpoint、重新验证,直到全部通过才能进归档。不是改完就完事,是改完必须重新证明一致性。
开源与安装使用
HyperSpec skill已开源,GitHub地址:
https://github.com/wind7rui/HyperSpec
这个项目会根据实际使用情况持续迭代,如果觉得有用,帮忙点个Star,有想法欢迎提Issue讨论,也欢迎提交PR共建。
HyperSpec skill 使用前需先安装两个前置依赖,请按各自GitHub说明自行安装:
-
Superpowers:https://github.com/obra/superpowers
以下分别说明不同工具中如何安装HyperSpec skill:
- Claude Code安装(原生支持,完整功能):
go
git clone https://github.com/wind7rui/HyperSpec hyperspec
cp -r hyperspec ~/.claude/skills/hyperspec使用:对话中直接说"用hyperspec开发一个用户认证功能",skill自动检测项目状态并路由到对应阶段。也可以显式指定:先做规格→propose阶段,直接开始实现→apply阶段(需已有计划),归档收尾→archive阶段。
- Cursor安装(支持SKILL.md格式读取):
go
git clone https://github.com/wind7rui/HyperSpec hyperspec
cp -r hyperspec .cursor/skills/hyperspec使用:在Chat中@hyperspec触发,或直接描述需求。Cursor能读取SKILL.md的完整内容,HyperSpec的核心逻辑(状态检测、阶段路由、断点恢复)可以正常运行。部分依赖Skill工具调用的功能(如调用openspec-propose、子代理并行执行)取决于Cursor对skill协议的支持程度。
- Codex CLI安装(原生支持SKILL.md格式):
go
git clone https://github.com/wind7rui/HyperSpec hyperspec
cp -r hyperspec ~/.codex/skills/hyperspec使用:对话中描述需求即可触发。
回头看这五个改动,背后有一条一致的思路:编排层最关键的不是"格式翻译",而是流程状态的精确追踪和可恢复。 格式不匹配可以靠参数注入解决,但状态丢失了,就真丢了------AI不记得,文件系统也不会自动告诉你。这个设计思路不限于Claude Code------编排层 + 结构化状态文件 + 阶段路由的模式,可以用在任何AI编程工具中。
以上就是本篇的全部内容,欢迎留言探讨。
往期回顾: