MySQL 8.0 实现 JSON 字段全文检索 | ngram 分词支持单字/字母/中英文混合搜索
-
- 前言
- 一、业务场景
- 二、技术痛点
- 三、概念解释
-
- [3.1 ngram 中日韩分词器](#3.1 ngram 中日韩分词器)
- [3.2 生成列(Generated Column)](#3.2 生成列(Generated Column))
- [3.3 全文索引(FULLTEXT INDEX)](#3.3 全文索引(FULLTEXT INDEX))
- [3.4 停用词表](#3.4 停用词表)
- [3.5 BOOLEAN MODE(布尔检索模式)](#3.5 BOOLEAN MODE(布尔检索模式))
- 四、环境
- [五、MySQL 全局配置(my.cnf / my.ini)](#五、MySQL 全局配置(my.cnf / my.ini))
-
- [5.1 完整配置文件](#5.1 完整配置文件)
- [5.2 重启 MySQL 服务](#5.2 重启 MySQL 服务)
- [5.3 验证配置是否生效](#5.3 验证配置是否生效)
- 六、创建空停用词表
- [七、生成列 + 全文索引构建(核心步骤)](#七、生成列 + 全文索引构建(核心步骤))
- 八、功能验证
- [十、MySQL 主流全文检索分词插件拓展](#十、MySQL 主流全文检索分词插件拓展)
-
- [10.1 ngram(本文使用)](#10.1 ngram(本文使用))
- [10.2 Jieba 分词(结巴分词)](#10.2 Jieba 分词(结巴分词))
- [10.3 Simple Chinese Tokenizer](#10.3 Simple Chinese Tokenizer)
- [10.4 Lucene Analyzer](#10.4 Lucene Analyzer)
- 十一、实战踩坑问题汇总
-
- 全文索引失效排查路径
- [问题 1:单个字母、中英文混合词(A计划)搜索不到](#问题 1:单个字母、中英文混合词(A计划)搜索不到)
- [问题 2:生成列长度不足导致内容截断,部分关键词检索不到](#问题 2:生成列长度不足导致内容截断,部分关键词检索不到)
- [问题 3:不同 MySQL 版本语法兼容性问题](#问题 3:不同 MySQL 版本语法兼容性问题)
- [问题 4:JSON 数组元素超过 20 个导致部分内容未索引](#问题 4:JSON 数组元素超过 20 个导致部分内容未索引)
- [问题 5:全文索引命中率低或结果不准确](#问题 5:全文索引命中率低或结果不准确)
- 十二、总结
前言
在企业级应用开发中,表单数据常以 JSON 数组格式存储于数据库。传统 LIKE '%关键词%' 模糊查询不仅效率低下,更无法满足单字、单个字母及中英文混合关键词(如"A"、"A计划")的精准检索需求。本文采用 MySQL 8.0 官方 ngram 分词器,结合生成列与全文索引,构建一套高性能、全场景兼容的 JSON 字段检索方案。
一、业务场景
- 业务表
form存储表单数据,核心字段:title(标题)、digest(JSON 格式内容) - JSON 固定格式:
[{"label":"标题","value":"内容"}],需要提取内部value值参与检索 - 检索要求:支持单字、单个字母、中英文混合词(A计划)、长文本搜索
- 性能要求:拒绝模糊查询,使用全文索引实现高效检索
二、技术痛点
- MySQL 无原生中文分词能力,无法直接对中文内容做全文检索;
- JSON 类型字段不能直接建立全文索引,需要额外处理;
- ngram 默认双字分词,单字、单字母无法命中;
- MySQL 内置停用词表会过滤 a、A、an 等短字母词汇,混合词搜索失效;
- 生成列长度不足导致内容截断,部分关键词检索不到;
- 不同 MySQL 版本语法、配置参数存在兼容性问题。
三、概念解释
3.1 ngram 中日韩分词器
MySQL 官方内置的全文检索分词插件,专门针对中文、日文、韩文等无天然分隔符的文本设计,无需额外安装。
- 分词规则:按照固定字符长度对文本做连续切割;
- 核心参数
ngram_token_size:- 取值 1:单字分词,支持所有字符检索(本文采用);
- 取值 2:双字分词(MySQL 默认值),仅支持 2 个及以上字符检索。
3.2 生成列(Generated Column)
MySQL 虚拟列,可基于表中已有字段(本文为 JSON 字段)通过表达式自动计算生成新字段。
- STORED 模式:数据物理持久化到磁盘,支持建立索引;
- 优势:JSON 数据更新时,生成列自动同步,无需代码手动维护。
3.3 全文索引(FULLTEXT INDEX)
针对大文本字段设计的专用索引,搭配分词器使用,检索效率远超普通索引和模糊查询。
3.4 停用词表
MySQL 全文检索内置的过滤规则表,默认会过滤 a、the、is 等语义无意义的短词汇。
本文场景:必须禁用默认停用词规则,否则单个字母会被过滤,搜索失效。
3.5 BOOLEAN MODE(布尔检索模式)
MySQL 全文检索常用模式,支持精准匹配、关键词组合、逻辑运算,是业务系统关键字搜索的首选模式。
四、环境
- MySQL 版本:8.0.11
- 存储引擎:InnoDB(全文索引主流引擎)
- 数据库字符集:utf8mb4(兼容所有中文、符号、生僻字)
- 业务表:
formtitle:表单标题(普通文本字段)digest:表单内容(JSON 格式字段)
五、MySQL 全局配置(my.cnf / my.ini)
5.1 完整配置文件
添加全文检索与分词相关参数:
bash
[mysqld]
# ========== ngram 分词核心配置 ==========
# ngram 分词长度:1=单字分词,支持单字、字母、中英文混合搜索
ngram_token_size = 1
# InnoDB 引擎全文索引最小词长度,允许索引单个字符
innodb_ft_min_token_size = 1
# MyISAM 引擎全文索引最小词长度,做版本兼容配置
ft_min_word_len = 1
# 自定义空停用词表:关闭默认停用词过滤,保留 A/B/C 等字母
# 格式要求:库名/表名(必须使用斜杠 /,禁止使用英文点 .)
innodb_ft_server_stopword_table = mysql/stopwords_table
# ========== 数据库基础性能配置 ==========
innodb_buffer_pool_size = 128M
performance_schema = OFF
max_connections = 1000
wait_timeout = 60
interactive_timeout = 60
open_files_limit = 8192
table_open_cache = 2048
# ========== SQL 运行模式 ==========
sql_mode = STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION5.2 重启 MySQL 服务
配置修改后必须重启服务:
bash
# Linux 重启 MySQL
systemctl restart mysqld
# Docker 容器重启 MySQL
docker restart 你的MySQL容器名5.3 验证配置是否生效
登录 MySQL 客户端,执行以下 SQL,核对参数值:
sql
-- 查看数据库版本
SELECT VERSION();
-- 校验分词、索引、停用词相关配置
SHOW VARIABLES LIKE 'ngram_token_size';
SHOW VARIABLES LIKE 'innodb_ft_min_token_size';
SHOW VARIABLES LIKE 'ft_min_word_len';
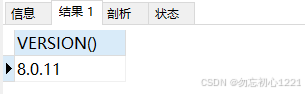
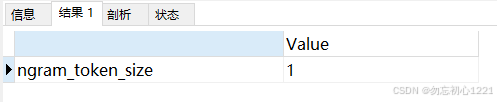
SHOW VARIABLES LIKE 'innodb_ft_server_stopword_table';执行上述 SQL 后的查询结果如下图所示:
mysql版本号,
ngram_token_size=1,
innodb_ft_min_token_size=1,
ft_min_word_len=1,
innodb_ft_server_stopword_table=mysql/stopwords_table。



六、创建空停用词表
MySQL 8.0 废弃了 innodb_ft_stopword_file 参数,统一使用数据表管理停用词。创建一张空表,即可实现「无停用词过滤」。
sql
-- 使用 MySQL 系统库,安全稳定,不会被业务操作误删
USE mysql;
-- 创建空停用词表,固定结构不可修改
CREATE TABLE IF NOT EXISTS stopwords_table (
value VARCHAR(30) PRIMARY KEY
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;
-- 验证:表内无任何数据即为正常
SELECT * FROM mysql.stopwords_table;
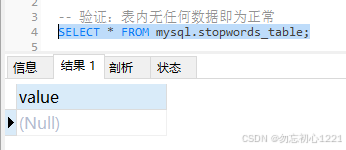
-- 验证:查看 MySQL 默认内置停用词列表
SELECT * FROM information_schema.INNODB_FT_DEFAULT_STOPWORD;空停用词表的查询结果如下图所示,表中无任何数据。
MySQL 默认内置停用词列表查询结果如下:
sql
a, about, an, are, as, at, be, by, com, de, en, for, from,
how, i, in, is, it, la, of, on, or, that, the, this, to,
was, what, when, where, who, will, with, und, the, www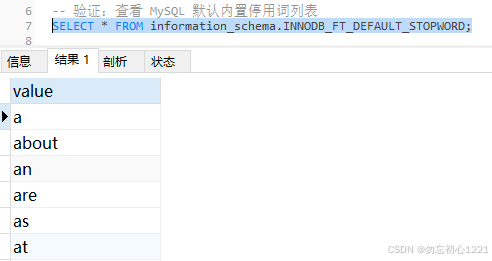
七、生成列 + 全文索引构建(核心步骤)
7.1 执行顺序(严格遵守,避免语法报错)
- 删除旧全文索引
- 删除旧生成列
- 新建生成列(抽取 JSON 中的 value 数据)
- 新建带 ngram 解析器的全文索引
7.2 完整可执行 SQL
1)删除旧全文索引
sql
ALTER TABLE `form` DROP INDEX `ft_digest_values_title`;2)删除旧生成列
sql
ALTER TABLE `form` DROP COLUMN `digest_all_values`;3)重建生成列
字段长度设置为 VARCHAR(2048),避免内容过长被截断;自动解析 JSON 并拼接所有 value 值:
sql
ALTER TABLE `form`
ADD COLUMN `digest_all_values` VARCHAR(2048)
GENERATED ALWAYS AS (
IF(
JSON_VALID(CAST(`digest` AS JSON)), -- 校验 JSON 格式合法性,非法 JSON 返回空字符串
CONCAT_WS(',',
-- 依次提取 JSON 数组前 20 个元素的 value 值,去空格、过滤空值
NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(CAST(`digest` AS JSON), '$[0].value'))), ''), ''),
NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(CAST(`digest` AS JSON), '$[1].value'))), ''), ''),
NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(CAST(`digest` AS JSON), '$[2].value'))), ''), ''),
NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(CAST(`digest` AS JSON), '$[3].value'))), ''), ''),
NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(CAST(`digest` AS JSON), '$[4].value'))), ''), ''),
NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(CAST(`digest` AS JSON), '$[5].value'))), ''), ''),
NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(CAST(`digest` AS JSON), '$[6].value'))), ''), ''),
NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(CAST(`digest` AS JSON), '$[7].value'))), ''), ''),
NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(CAST(`digest` AS JSON), '$[8].value'))), ''), ''),
NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(CAST(`digest` AS JSON), '$[9].value'))), ''), ''),
NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(CAST(`digest` AS JSON), '$[10].value'))), ''), ''),
NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(CAST(`digest` AS JSON), '$[11].value'))), ''), ''),
NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(CAST(`digest` AS JSON), '$[12].value'))), ''), ''),
NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(CAST(`digest` AS JSON), '$[13].value'))), ''), ''),
NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(CAST(`digest` AS JSON), '$[14].value'))), ''), ''),
NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(CAST(`digest` AS JSON), '$[15].value'))), ''), ''),
NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(CAST(`digest` AS JSON), '$[16].value'))), ''), ''),
NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(CAST(`digest` AS JSON), '$[17].value'))), ''), ''),
NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(CAST(`digest` AS JSON), '$[18].value'))), ''), ''),
NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(CAST(`digest` AS JSON), '$[19].value'))), ''), '')
),
''
)
) STORED; -- STORED:物理存储,支持索引生成列digest_all_values,如下图所示:
4)重建全文索引
绑定 ngram 分词解析器,联合 title、digest_all_values 两个字段建立索引:
sql
ALTER TABLE `form`
ADD FULLTEXT INDEX `ft_digest_values_title`
(`digest_all_values`, `title`) WITH PARSER ngram;生成表索引ft_digest_values_title,如下图所示:

八、功能验证
执行以下 SQL,依次验证不同类型关键词检索能力:
sql
-- 1. 校验生成列是否正常提取 JSON 数据
SELECT digest, digest_all_values FROM form LIMIT 5;
-- 2. 单字搜索测试
SELECT * FROM form WHERE MATCH(digest_all_values, title) AGAINST('计' IN BOOLEAN MODE);
-- 3. 单字母搜索测试
SELECT * FROM form WHERE MATCH(digest_all_values, title) AGAINST('A' IN BOOLEAN MODE);
-- 4. 中英文混合搜索测试(核心场景:A计划)
SELECT * FROM form WHERE MATCH(digest_all_values, title) AGAINST('A计划' IN BOOLEAN MODE);关键词"A计","A计划"搜索成功的结果如下图所示:


十、MySQL 主流全文检索分词插件拓展
除官方 ngram 外,常用的 MySQL 全文分词插件还有多种,根据业务选型有:
10.1 ngram(本文使用)
- 归属:MySQL 官方内置;
- 优点:开箱即用、稳定可靠、零部署、版本兼容好;
- 缺点:仅做固定长度切分,无语义分词;
- 适用场景:后台管理系统、表单检索、内部业务系统(90% 企业首选)。
10.2 Jieba 分词(结巴分词)
- 归属:第三方开源分词插件,适配 MySQL;
- 优点:基于中文语义分词,分词精度高,贴近自然语言;
- 缺点:需要手动编译、安装、升级,运维成本高;
- 适用场景:电商商品搜索、博客/文章内容检索、面向 C 端用户的搜索。
10.3 Simple Chinese Tokenizer
- 归属:轻量级第三方插件;
- 优点:体积小、配置简单;
- 缺点:功能单一,分词规则简陋;
- 适用场景:小型项目、简单文本检索。
10.4 Lucene Analyzer
- 归属:基于 Lucene 生态的分词器;
- 优点:语义分析能力强,支持多语种;
- 缺点:与 MySQL 集成复杂度高,资源占用大;
- 适用场景:大型门户、知识库、专业文档检索系统。
十一、实战踩坑问题汇总
全文索引失效排查路径
当全文索引出现搜索不到、命中率低等问题时,可按照以下流程快速定位问题根源:
- 配置问题:主要检查MySQL全局配置、停用词表、字符集等基础设置
- 数据问题:重点验证生成列数据完整性,避免截断和解析失败
- 索引问题:确认索引覆盖字段、查询模式和执行计划
- 综合排查:按照流程图顺序逐一检查,快速定位问题类型后参考对应解决方案
问题 1:单个字母、中英文混合词(A计划)搜索不到
问题原因
- 未配置空停用词表,MySQL 默认过滤短字母;
- 停用词表配置格式错误,使用
mysql.stopwords_table(英文点); - 修改配置后未重启 MySQL、未重建全文索引。
解决方案
- 确认配置文件 :确保
my.cnf或my.ini中innodb_ft_server_stopword_table = mysql/stopwords_table配置正确,使用斜杠/而非英文点.。 - 创建空停用词表 :在
mysql系统库中执行CREATE TABLE IF NOT EXISTS stopwords_table ...语句,并确保表内无任何数据。 - 重启 MySQL 服务:配置修改后必须重启 MySQL 服务使参数生效。
- 重建全文索引 :删除旧索引后,重新执行
ADD FULLTEXT INDEX ... WITH PARSER ngram语句。 - 验证配置 :执行
SHOW VARIABLES LIKE 'innodb_ft_server_stopword_table';确认参数已指向空表。
问题 2:生成列长度不足导致内容截断,部分关键词检索不到
问题原因
- 生成列
digest_all_values定义为VARCHAR(255)等较小长度,当 JSON 数组元素过多或单个value值过长时,拼接后的字符串超出定义长度,超长部分被截断。 - 被截断的内容未进入全文索引,导致包含被截断部分的关键词搜索失败。
解决方案
- 预估最大长度 :根据业务数据模型,估算 JSON 数组中所有
value值的最大可能拼接长度。建议预留充足余量。 - 使用足够长的 VARCHAR :将生成列定义为
VARCHAR(2048)或VARCHAR(4096)。本文示例采用VARCHAR(2048),可覆盖绝大多数场景。 - 使用 LONGTEXT 类型 :如果数据量极大,不确定上限,可考虑使用
LONGTEXT类型,但需注意全文索引对LONGTEXT的支持情况(MySQL 8.0 支持对LONGTEXT建立全文索引)。 - 重建生成列:按正确长度重新执行生成列创建 SQL。
- 验证数据完整性 :创建后执行
SELECT digest, digest_all_values FROM form LIMIT 5;,人工核对提取内容是否完整,无截断。
问题 3:不同 MySQL 版本语法兼容性问题
问题原因
- 全文索引语法差异 :MySQL 5.7 与 8.0 在创建全文索引时,对
WITH PARSER ngram子句的支持和位置要求可能不同。 - 停用词配置方式变更 :MySQL 8.0 废弃了
innodb_ft_stopword_file参数,统一使用innodb_ft_server_stopword_table系统表管理,而 5.7 版本可能仍支持文件方式。 - 生成列支持度:MySQL 5.7 开始支持生成列,但某些早期小版本可能存在限制或 Bug。
- ngram 插件版本:不同 MySQL 发行版(如官方社区版、Percona Server、MariaDB)中 ngram 插件的内置情况和默认参数可能不同。
解决方案
- 明确版本并查阅官方文档 :执行
SELECT VERSION();确认数据库确切版本,并查阅对应版本的官方文档中关于FULLTEXT INDEX、Generated Columns和ngram的章节。 - 适配索引创建语句 :
- MySQL 8.0+ :使用
ALTER TABLE ... ADD FULLTEXT INDEX ... WITH PARSER ngram;语法。 - MySQL 5.7 :语法基本相同,但需确保 ngram 插件已安装并启用。可先执行
INSTALL PLUGIN ngram SONAME 'ngram.so';(Linux)或查看插件状态。
- MySQL 8.0+ :使用
- 停用词配置适配 :
- MySQL 8.0+ :严格使用
innodb_ft_server_stopword_table系统表方案。 - MySQL 5.7 :如果使用文件方式,需确认
innodb_ft_stopword_file参数路径及文件格式,本文方案不适用。
- MySQL 8.0+ :严格使用
- 测试环境先行:在生产环境大规模改动前,在相同版本的测试环境中完整演练所有 SQL 步骤。
- 考虑使用条件 SQL :在自动化脚本中,可根据
SELECT VERSION()的结果动态拼接不同的 SQL 语句,以兼容多版本。
问题 4:JSON 数组元素超过 20 个导致部分内容未索引
问题原因
- 生成列 SQL 硬编码限制 :本文第七节提供的生成列创建 SQL 中,使用
JSON_EXTRACT(CAST(digest AS JSON), '$[0].value')到'$[19].value'的方式,仅提取了 JSON 数组的前 20 个元素。当表单字段数量超过 20 个时,第 21 个及之后的元素内容将无法被提取到生成列中。 - 内容缺失导致索引不全 :未提取的
value值不会出现在digest_all_values列中,因此无法被全文索引覆盖,导致包含这些内容的关键词搜索失败。 - 业务数据动态性:实际业务中,表单字段数量可能动态变化,硬编码上限无法适应所有场景。
解决方案
-
使用 MySQL JSON_TABLE 函数动态解析(推荐,MySQL 8.0.4+)
利用
JSON_TABLE函数动态展开 JSON 数组,自动处理任意长度。修改生成列创建语句如下:sqlALTER TABLE `form` ADD COLUMN `digest_all_values` VARCHAR(4096) GENERATED ALWAYS AS ( IF( JSON_VALID(CAST(`digest` AS JSON)), ( SELECT GROUP_CONCAT(TRIM(jt.value) SEPARATOR ',') FROM JSON_TABLE( CAST(`digest` AS JSON), '$[*]' COLUMNS( value VARCHAR(255) PATH '$.value' ) ) AS jt WHERE jt.value IS NOT NULL AND jt.value != '' ), '' ) ) STORED;优点:
- 自动处理任意长度的 JSON 数组,无元素数量限制。
- 代码简洁,易于维护。
- 使用
GROUP_CONCAT将所有value拼接为单个字符串。
注意事项:
GROUP_CONCAT默认有长度限制(group_concat_max_len,默认 1024 字符)。如果拼接后的字符串可能超长,需提前执行SET SESSION group_concat_max_len = 4096;或更大值。- 确保生成列长度
VARCHAR(4096)足够容纳拼接后的字符串。
-
使用存储过程或应用程序层预处理
如果 MySQL 版本低于 8.0.4(不支持
JSON_TABLE),或GROUP_CONCAT性能/长度受限,可考虑:- 存储过程:编写存储过程,使用循环动态解析 JSON 数组并拼接。
- 应用程序层 :在插入/更新数据时,由应用程序(如 Java)解析 JSON 数组,拼接所有
value后直接写入一个普通字段(非生成列),并对该字段建立全文索引。 - 触发器 :创建
BEFORE INSERT/UPDATE触发器,在数据库层完成 JSON 解析与拼接。
-
调整生成列长度并评估上限
即使使用动态解析,也需合理设置生成列长度:
- 评估业务中单个
value的最大长度、JSON 数组的最大元素数量。 - 按
最大元素数 × 平均每个value长度 × 安全系数估算总长度。 - 如不确定上限,可使用
LONGTEXT类型(MySQL 8.0 支持对LONGTEXT建立全文索引)。
- 评估业务中单个
-
验证数据完整性
创建生成列后,务必执行验证 SQL,确保所有数据都被正确提取:
sql-- 检查是否有数据因数组超长而未提取 SELECT id, JSON_LENGTH(CAST(digest AS JSON)) as original_array_length, LENGTH(digest_all_values) - LENGTH(REPLACE(digest_all_values, ',', '')) + 1 as extracted_value_count FROM form WHERE JSON_LENGTH(CAST(digest AS JSON)) > 20;如果
extracted_value_count小于original_array_length,说明部分元素未被提取,需检查 SQL 逻辑或调整生成列定义。 -
重建全文索引
修改生成列后,必须删除并重新创建全文索引,使新内容被索引:
sqlALTER TABLE `form` DROP INDEX `ft_digest_values_title`; ALTER TABLE `form` ADD FULLTEXT INDEX `ft_digest_values_title` (`digest_all_values`, `title`) WITH PARSER ngram;
问题 5:全文索引命中率低或结果不准确
问题原因
- 分词粒度不匹配 :
ngram_token_size参数设置不当。例如,设置为默认值 2(双字分词)时,单字和单个字母无法被索引和检索;设置为 1 时,短词检索可能召回过多无关结果。 - 停用词配置问题:未正确配置空停用词表,导致 MySQL 默认停用词过滤了短字母(如 A、B、C)或常见中文虚词,影响命中率。
- 数据字符集不一致 :表、列、连接字符集不统一(如
utf8mb4与utf8混用),导致分词和索引时字符处理异常,影响匹配准确性。 - 查询模式选择不当 :错误使用
IN NATURAL LANGUAGE MODE(自然语言模式),该模式会自动过滤短词和高频词,不适合单字/字母检索场景。 - 生成列数据质量问题 :生成列提取的
value值包含大量空格、换行、特殊符号,或 JSON 解析失败导致内容为空,影响索引构建。 - 索引未覆盖所有查询字段 :全文索引仅建立在部分字段上,但查询时使用了未索引的字段进行
MATCH操作。 - 最小词长度配置冲突 :
innodb_ft_min_token_size(InnoDB)与ft_min_word_len(MyISAM)配置不一致,或与ngram_token_size不协调。
排查步骤
-
验证分词配置
sql-- 检查核心分词参数 SHOW VARIABLES LIKE 'ngram_token_size'; SHOW VARIABLES LIKE 'innodb_ft_min_token_size'; SHOW VARIABLES LIKE 'ft_min_word_len'; SHOW VARIABLES LIKE 'innodb_ft_server_stopword_table';确保:
ngram_token_size=1、innodb_ft_min_token_size=1、停用词表指向空表。 -
检查字符集一致性
sql-- 查看表、列字符集 SELECT TABLE_SCHEMA, TABLE_NAME, COLUMN_NAME, CHARACTER_SET_NAME, COLLATION_NAME FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME = 'form' AND COLUMN_NAME IN ('title', 'digest_all_values'); -- 查看数据库默认字符集 SHOW VARIABLES LIKE 'character_set_database'; SHOW VARIABLES LIKE 'collation_database';确保所有相关字符集均为
utf8mb4。 -
验证生成列数据质量
sql-- 检查生成列内容是否完整、无异常 SELECT id, LENGTH(digest_all_values) as content_length, digest_all_values FROM form WHERE digest_all_values IS NULL OR digest_all_values = '' OR digest_all_values LIKE '% %' -- 检查多余空格 LIMIT 10; -- 检查 JSON 解析是否成功 SELECT id, JSON_VALID(CAST(digest AS JSON)) as is_valid_json, digest FROM form WHERE JSON_VALID(CAST(digest AS JSON)) = 0 LIMIT 10; -
分析索引覆盖情况
sql-- 查看表的索引信息,确认全文索引字段 SHOW INDEX FROM form; -- 确认全文索引包含所有需要检索的字段 -- 本文示例应为:`digest_all_values` 和 `title` -
测试不同查询模式
sql-- 对比 BOOLEAN MODE 与 NATURAL LANGUAGE MODE 结果差异 SELECT 'BOOLEAN MODE' as mode, COUNT(*) as result_count FROM form WHERE MATCH(digest_all_values, title) AGAINST('A计划' IN BOOLEAN MODE) UNION ALL SELECT 'NATURAL LANGUAGE MODE' as mode, COUNT(*) as result_count FROM form WHERE MATCH(digest_all_values, title) AGAINST('A计划' IN NATURAL LANGUAGE MODE); -
使用
EXPLAIN分析查询执行计划sqlEXPLAIN SELECT * FROM form WHERE MATCH(digest_all_values, title) AGAINST('A计' IN BOOLEAN MODE);确认查询使用了全文索引(
type列为fulltext)。
解决方案
-
统一分词粒度配置
-
在
my.cnf/my.ini中明确设置:bash[mysqld] ngram_token_size = 1 # 单字分词,支持单字/字母 innodb_ft_min_token_size = 1 # InnoDB 最小词长 ft_min_word_len = 1 # MyISAM 最小词长(兼容性) -
重启 MySQL 服务使配置生效。
-
重建全文索引:先删除旧索引,再使用新配置创建。
-
-
正确配置停用词表
-
确保已创建空停用词表(参考本文第六节)。
-
验证配置生效:
sql-- 应返回 'mysql/stopwords_table' SHOW VARIABLES LIKE 'innodb_ft_server_stopword_table'; -- 确认表为空 SELECT COUNT(*) FROM mysql.stopwords_table;
-
-
统一字符集为 utf8mb4
-
修改表字符集(如果当前不是 utf8mb4):
sqlALTER TABLE form CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; -
修改生成列字符集:
sqlALTER TABLE form MODIFY COLUMN digest_all_values VARCHAR(2048) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; -
确保数据库连接字符集也为 utf8mb4(在 JDBC URL 中添加
?characterEncoding=utf8mb4)。
-
-
强制使用 BOOLEAN MODE
-
在所有业务查询中明确指定
IN BOOLEAN MODE,避免误用自然语言模式。 -
在 MyBatis mapper 中固化查询模式:
xml<select id="listForm" resultType="com.xxx.FormVO"> SELECT * FROM form <where> <if test="keyword != null and keyword != ''"> AND MATCH(form.title, digest_all_values) AGAINST(#{keyword} IN BOOLEAN MODE) </if> </where> </select>
-
-
优化生成列数据质量
-
在生成列表达式中增加数据清洗:
sql-- 示例:增加 TRIM() 和 NULLIF() 处理 NULLIF(COALESCE(TRIM(JSON_UNQUOTE(JSON_EXTRACT(...))), ''), '') -
对于 JSON 解析失败的情况,在应用层增加校验逻辑,确保存入的 JSON 格式合法。
-
定期检查生成列内容,清理异常数据。
-
-
确保索引覆盖所有查询字段
-
如果查询涉及更多字段,扩展全文索引:
sqlALTER TABLE form ADD FULLTEXT INDEX ft_extended (digest_all_values, title, other_field1, other_field2) WITH PARSER ngram; -
注意:联合全文索引的字段顺序会影响查询效率,将最常搜索的字段放在前面。
-
-
重建索引并验证
-
在修正配置后,必须重建全文索引:
sql-- 删除旧索引 ALTER TABLE form DROP INDEX ft_digest_values_title; -- 使用新配置创建索引 ALTER TABLE form ADD FULLTEXT INDEX ft_digest_values_title (digest_all_values, title) WITH PARSER ngram; -
使用
ANALYZE TABLE更新索引统计信息:sqlANALYZE TABLE form;
-
-
业务层容错与监控
-
在应用程序中添加命中率监控:
java// 记录每次搜索的命中数量 log.info("Search keyword: {}, hit count: {}", keyword, resultList.size()); -
设置命中率告警阈值,当命中率异常下降时自动通知。
-
定期(如每周)执行索引健康检查:
sql-- 检查索引碎片率 SELECT table_name, index_name, stat_value * @@innodb_page_size / 1024 / 1024 as index_size_mb FROM mysql.innodb_index_stats WHERE database_name = DATABASE() AND table_name = 'form' AND index_name = 'ft_digest_values_title';
-
最佳实践建议
- 配置标准化:将分词、停用词、字符集等配置写入项目文档,确保开发、测试、生产环境一致。
- 测试全覆盖:建立完整的检索测试用例,覆盖单字、单字母、中英文混合词、长文本等场景。
- 监控常态化:将全文索引命中率、查询响应时间纳入系统监控指标。
- 定期维护 :每月执行一次
OPTIMIZE TABLE form;和ANALYZE TABLE form;,保持索引性能。 - 版本升级验证:MySQL 版本升级后,重新验证全文检索功能,确保配置兼容性。
十二、总结
本文基于MySQL8.0原生能力,采用ngram单字分词+生成列+全文索引组合方案,替代低效LIKE模糊查询。通过开启单字分词、自建空停用词表、全局统一utf8mb4字符集,解决单汉字、单字母、中英文混合词检索痛点,适配表单JSON数组存储业务,方案无第三方依赖、易部署、运维成本低,可直接投产使用。
本次实战全覆盖配置、索引、SQL及排障流程,提供高低版本兼容的JSON解析方案,汇总六大生产高频踩坑问题及标准化解法。业务落地建议固定布尔检索模式、扩容生成列长度、统一多环境数据库配置,配合索引定时维护、业务重试兜底,保障检索精准性与实时性,适配企业后台表单类检索业务。