第二章 数据库基础知识之关系数据库
候选码,主码、外码:是关系数据库中最核心、最基础的术语。这三个概念共同确保了:"在一张表里唯一找到某一行数据" "把两张表联系起来"。
-
候选码 (Candidate Key) :在一张表中,能够唯一标识一个元组的一个或一组属性。而且它必须是最小的(不能有多余的属性)。在"学生表"中:
- 学号 :全校唯一,能确定是你。 -> 是候选码。
- 身份证号 :全国唯一,能确定是你。 -> 是候选码。
- 姓名 :可能有重名(比如两个"张伟"),不能唯一确定---> 不是候选码 。
(姓名 + 班级):虽然能确定是你,但因为它包含了多余的"班级"(光靠学号就够了,或者光靠身份证就够了),不符合"最小性",因此不是候选码。
-
主码 (Primary Key):从多个"候选码"中,人为挑选出来的一个,作为该表的主要标识符。如个人证件号码。
一个表只能有一个主码。主码的值绝对不能为空 (NOT NULL),也绝对不能重复。在"学生表"中,我们在"学号"和"身份证号"这两个候选码中,选择了"学号"作为主码。
因此,主码一定是候选码,但候选码不一定是主码。如果候选码未被选为某表的主码,就被称为备用码。
3.外码 (Foreign Key) :如果表 A 中的某个属性(或属性组),是表 B 的主码(或候选码) ,那么这个属性在表 A 中就被称为"外码"。外码是表与表之间的"桥梁"或"超链接"。它用来建立两张表的联系。
- 表 A(学生表) :主码是
学号。 - 表 B(成绩表) :里面有
课程号和分数。为了知道这是谁的成绩,成绩表里必须有一列学号。 此时B表里的学号就是外码。它指向了学生表的主码。
假设我们有两张表:学生表 和 选课表。
表 1:学生表 (Student)
| 学号 (主码) | 姓名 | 身份证号 (候选码) | 性别 |
|---|---|---|---|
| 2023001 | 张三 | 110105... | 男 |
| 2023002 | 李四 | 110106... | 女 |
- 候选码 :
学号、身份证号(都能唯一确定一个人)。 - 主码 :我们选
学号(因为短,好记,且在学校中用的最多)。
表 2:选课表 (Course_Selection)
| 选课ID (主码) | 学号 (外码) | 课程名 | 成绩 |
|---|---|---|---|
| 1001 | 2023001 | 数据库 | 90 |
| 1002 | 2023002 | 数学 | 85 |
| 1003 | 2023001 | 英语 | 88 |
-
主码 :
选课ID(唯一标识每一次选课记录)。 -
外码 :
学号。-
为什么它是外码? 因为它引用了"学生表"的主码。
-
它的作用是什么? 它把"选课表"和"学生表"联系起来了。通过外码
2023001,我们知道 1001 号选课记录属于"张三"。 -
参照完整性约束 :你不能 在选课表里填一个
学号 = 99999,因为学生表里根本没有这个人!这就是外码带来的约束。
-
1、关系模型(Relational Model)由哪几部分组成?
答:关系数据结构、关系操作集合、关系完整性约束。
(1)关系数据结构(Relational Data Structure):确定了数据长什么样。
在关系模型中,唯一的数据结构就是"二维表"(Table)。这是关系模型的"骨架"。我们在前面讨论过的所有概念:关系、元组、属性、域、码,都属于这一部分:它规定了数据库里的数据必须老老实实地排成行和列,不能是树状,也不能是网状。
(2)关系操作集合(Relational Operations):确定了怎么操作和查询数据。通过一套数学工具来对表里的数据进行增删改查。关系模型的操作分为两大类:
传统集合操作:因为关系本质上是元组的集合,所以支持数学上的并(Union)、差(Difference)、交(Intersection)、笛卡尔积(Cartesian Product)。
专门的关系操作:这是关系模型独有的,也是 SQL 语言的底层逻辑:
选择(Selection):挑出符合条件的行(如 `WHERE age > 18`)。
投影(Projection):挑出指定的列(如 `SELECT name, age`)。
连接(Join):把两张表通过公共属性拼在一起(如 `JOIN`)。
除(Division):用于处理"全部包含"这类复杂查询。
用户平时写的 SQL 语句(如 `SELECT * FROM 表 WHERE...`),本质上就是在调用这些关系操作。数据库系统(DBMS)会在底层把这些操作转化为高效的执行计划。
(3)关系完整性约束(Relational Integrity Constraints):保证数据不乱、不错、不矛盾。为了防止用户输入垃圾数据或破坏数据之间的关联,关系模型强制规定了三大完整性规则:
实体完整性(Entity Integrity):主键(Primary Key)的值不能为空(NOT NULL),且不能重复。保证每一行数据都是独一无二的,能被唯一找到。(比如:学号不能为空,也不能有两个学生共用一个学号)。
参照完整性(Referential Integrity):外键(Foreign Key)的值,要么为空,要么必须等于另一张表中主键的某个现有值。保证表与表之间的关联是有效的,不会出现"孤儿数据"。(比如:成绩表里的"学号",必须在学生表里真实存在,不能给一个不存在的学号录成绩)。
用户定义完整性(User-defined Integrity):针对具体业务场景自定义的规则。满足特定业务需求。(比如:年龄必须在 0-150 之间,性别只能是"男"或"女",邮箱必须包含 `@` 符号)。
举例:将关系模型想象成 "管理一个大型图书馆":
1. 数据结构(二维表):书架和登记册(规定了书必须按书名、作者、ISBN号登记在册)。
2. 操作集合(关系代数):借阅和检索规则(规定了怎么查书、怎么借书、怎么把两批书合并)。
3. 完整性约束(三大完整性) = 图书馆管理条例(规定了每本书必须有唯一ISBN号【实体完整性】;借书人必须是注册读者【参照完整性】;借书数量不能超过5本【用户定义完整性】)。
这三者缺一不可,共同构成了今天支撑着全球绝大多数核心业务系统的关系模型。2、关系数据语言有哪些特点?
答:关系数据语言(Relational Data Language)是用户与关系数据库管理系统(RDBMS)进行交互的接口。虽然理论上它包括"关系代数"(过程化)和"关系演算"(非过程化),但在实际工程和绝大多数教材中,关系数据语言的代表和绝对主流就是 SQL(结构化查询语言)。
以 SQL 为例总结关系数据语言的五大核心特点:
- 高度非过程化(声明式)。用户只需提出 "做什么"(What) ,而不需要指出 "怎么做"(How)。存取路径的选择和具体操作由 DBMS 的查询优化器自动完成。
过程化语言(如 C/Java):就像你走进后厨,告诉厨师:"先去冰箱拿鸡蛋,打碎在碗里,加盐,开火,倒油,炒三分钟......"(你必须指挥每一步)。
非过程化语言(SQL):就像你坐在餐桌前看菜单,对服务员说:"我要一份番茄炒蛋。"(你只说结果,怎么做是厨师/DBMS 的事)。例如:你写 `SELECT * FROM 学生 WHERE 年龄 > 20`。你不需要告诉数据库是先查索引还是全表扫描,也不需要写循环去逐行比对,DBMS 会自动选择最高效的底层算法去执行。- 面向集合的操作方式。关系数据语言的操作对象和返回结果都是元组的集合(即二维表),而不是单条记录。
- 对比早期数据库 :在网状/层次模型中,程序员必须使用"导航式"语言,通过指针一条一条地移动记录(如"取当前记录的下一条")。如果你想把全校所有学生的年龄加 1 岁:在过程化语言中,你需要写一个
for循环,遍历每一行,读取年龄,加1,再写回。在 SQL 中,只需一句:UPDATE 学生 SET 年龄 = 年龄 + 1。这一句话就同时作用于整个集合,极其高效。
- 功能综合统一:关系数据语言将多种功能高度集成在一套语法体系中。用户只需要学习一种语言,就能完成数据库从创建、使用到安全管理的全部生命周期工作。它不仅仅是"查询"语言,而是包含了:
-
- DDL(数据定义语言) :建库、建表、定义约束(
CREATE,ALTER,DROP)。 - DML(数据操纵语言) :增删改查数据(
INSERT,DELETE,UPDATE,SELECT)。 - DCL(数据控制语言) :权限管理、事务控制(
GRANT,REVOKE,COMMIT)。
- DDL(数据定义语言) :建库、建表、定义约束(
- 提供两种灵活的使用方式:关系数据语言既可以独立使用,也可以嵌入到高级编程语言中:
自含式语言(交互式):用户可以直接在数据库的命令行终端(如 MySQL Command Line)或图形化界面(如 Navicat)中,直接输入 SQL 语句,数据库立刻执行并返回结果。适合数据分析和临时查询。
嵌入式语言:SQL 语句可以嵌入到 C、C++、Java、Python 等高级编程语言中(如 JDBC, MyBatis)。程序在运行时,将 SQL 发送给数据库执行,从而开发出复杂的业务系统(如淘宝、微信后端)。- 语言简洁,易学易用:SQL 的语法结构非常接近自然英语,核心动词极少(主要是 SELECT, FROM, WHERE, INSERT, UPDATE, DELETE 等),通过不同的组合可以表达极其复杂的数据操作需求。大大降低了数据库的使用门槛,使得非计算机专业的人员(如财务、运营、数据分析师)也能通过简单的培训掌握数据查询技能。
总结:关系数据库语言特点:"非过程、向集合、功统一、双方式、语简洁"。
3、关系代数的运算是怎么样的?
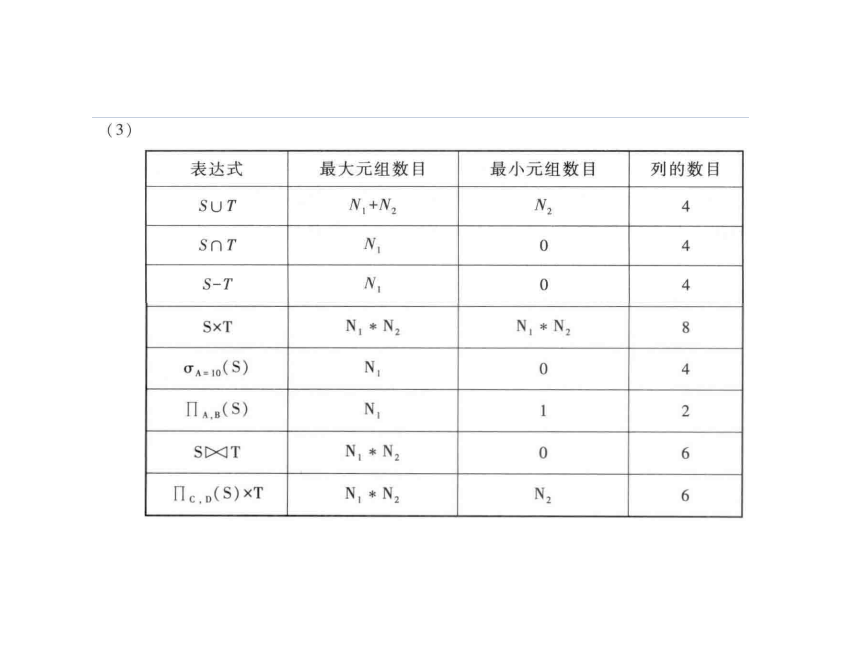
关系代数是关系数据库系统的数学理论基础。它是一种过程化的查询语言,它通过一系列数学运算,将一张或多张表(关系)作为输入,经过运算后输出一张新的表(结果关系)。关系代数的运算主要分为两大类:传统的集合运算 和 专门的关系运算。
1、 传统集合运算:将关系(表)视为元组(行)的集合。进行并、交、差运算时,参与运算的两个关系必须具有相同的属性个数,且对应属性的数据类型(域)必须相同。
1. 并 (Union,符号∪)
- 定义 :将两个关系中的所有元组合并,并自动去除重复行。即把两张结构相同的表上下拼起来,去掉重复的。
- SQL对应 :
SELECT ... UNION SELECT ...
2. 差 (Difference, 符号 −)
- 定义:属于关系 R 但不属于关系 R 的元组组成的集合。即在表 A 中去掉那些也存在于表 B 中的行。
- SQL对应 :
SELECT ... EXCEPT SELECT ...(或MINUS)
3. 交 (Intersection, 符号∩)
- 定义:既属于关系 R 又属于关系 S 的元组组成的集合。如找出两张表中完全相同的行。
- SQL对应 :
SELECT ... INTERSECT SELECT ...
4. 笛卡尔积 (Cartesian Product, 符号×)
- 定义 :将关系 R 的每一行与关系 S 的每一行进行两两组合。如果 R 有 m m m 行,S 有 n n n 行,结果就有m X n行。如不加任何条件,把两张表的所有行强行排列组合。在实际业务中,纯粹的笛卡尔积通常没有意义,它通常作为连接运算的中间步骤。
二、 专门的关系运算:
这类运算是关系数据库特有的,主要用于处理表内部的行和列,以及表与表之间的关联。
1. 选择 (Selection,符号 σ,读作sigma) ------ 挑行
定义 :从关系 R 中挑选出满足给定条件的元组(行)。相当于 SQL 中的 WHERE 子句。是对表进行水平切割。
如:σ年龄>20(学生表) -> 找出所有年龄大于20岁的学生。
2. 投影 (Projection, 符号π,读作pi) ------ 挑列
- 定义 :从关系 R 中挑选出指定的属性(列),并自动去除重复行。相当于 SQL 中的
SELECT 列名。是对表进行垂直切割。如:π姓名, 学号(学生表) -> 只查看学生的姓名和学号,不查看其他信息。
3. 连接 (Join, 符号⋈,读作bowtie,音译:包泰) ------ 拼表
-
定义 :从两个关系的笛卡尔积中,选取属性间满足一定条件的元组。相当于 SQL 中的
JOIN ... ON ...。 -
常见类型:
-
θ 连接:是广义的连接,形式为 ( R⋈aθb S ),其中θ可以是任意比较运算符,包括 (=, >, <, ≥,≤,≠) 等。 例如:( R ⋈ R.A > S.B S ) 就是一个 θ 连接。
-
等值连接:等值连接是 θ 连接的一种特殊情况。连接条件为"="。例如:σR.学号 = S.学号(R X S)。因此等值连接特指θ为等号的θ连接。例如:( R ⋈ R.A = S.B S ) 是等值连接。因此,等值连接是 θ 连接的真子集,两者是包含关系)
#自然连接 (Natural Join, ⋈):是一种特殊的等值连接,要求两个关系中在所有的公共属性(同名属性)上进行等值连接,并且在结果中**去掉重复的公共属性列,只保留一列。如果用户没有特殊指定,默认连接就是自然连接。
-
-
4. 除 (Division, 符号÷,读作div) ------ 找"全部"
-
定义 :这是关系代数中最难理解的一个运算。它用于表达 "全部"、"所有" 这类查询需求。找出在关系 R 中,与关系 S 中所有元组都有对应关系的元组。
-
经典例子:
- 表 R(选课表):包含 (学号, 课号)
- 表 S(课程表):包含 (课号) -> 假设里面有"数学"和"英语"两门课。
- 运算 R ÷ S 的结果:找出选修了 S 表中所有课程 (即既选了数学又选了英语)的学号。
SQL对应:SQL 中没有直接的除法关键字,通常需要用
NOT EXISTS嵌套查询或GROUP BY + HAVING COUNT来实现。
三、 关系代数与 SQL 的直观映射
| 关系代数运算 | 符号 | 操作对象 | 对应的 SQL 核心关键字 |
|---|---|---|---|
| 选择 | σ | 筛选行 | WHERE |
| 投影 | π | 筛选列 | SELECT |
| 连接 | ⋈ | 关联多表 | JOIN ... ON ... |
| 并 | ∪ | 合并结果集 | UNION |
| 差 | − | 排除结果集 | EXCEPT / MINUS |
| 交 | ∩ | 取交集 | INTERSECT |
| 除 | ÷ | 查询**"全部"** | NOT EXISTS / HAVING COUNT |
常见说法辨析1:关系模型中的数据操作只有增删改查。
分析:该说法比较主流。但严格来说数据操作只有两类:更新和查询。插入、删除、修改是更新所包含的。
常见说法辨析2:关系代数中的常见8种运算是选择、投影、并、差、笛卡尔积、交、连接、除。
分析:这也是主流说法之一。但要记得其中最基本的5种运算是选择、投影、并、差、积。剩下三种(交、连接、除)可以用基本操作定义推导得出:
(1)交(Intersection):R∩S=R−(R−S)
(2)连接(Join):R⋈FS=σF(R×S)R⋈F S=σF(R×S)(θ 连接)
从定义上来说,θ连接包含等值连接,等值连接包含自然连接。很多教材会这样写:"连接操作有 θ 连接和自然连接之分",这里的"之分"是突出两者在是否去重和是否限全同名属性上的区别,并不否认自然连接在定义上属于 θ 连接。
(3)除(Division):R÷S=πX(R)−πX((πX(R)×S)−R),其中X是R中除去与S相同属性后的属性集。四、 一个综合运算示例
假设我们有两张表:
- 学生表 (Student):(学号, 姓名, 年龄, 系别)
- 选课表 (SC):(学号, 课号, 成绩)
需求:查询"计算机系"且"成绩大于90分"的学生姓名。
关系代数表达式:π姓名(σ系别='计算机'(Student) ⋈ Student.学号=SC.学号 σ成绩>90 (SC) )
运算步骤拆解(从内向外):
1. σ成绩>90 (SC):在选课表中,筛选出成绩大于90的行(即元组)。
2. σ系别='计算机'(Student):在学生表中,筛选出计算机系的行。
3. ⋈ Student.学号=SC.学号:将上面两个选择结果,通过"学号"进行自然连接(拼成一张大表)。
4. π姓名:从拼好的大表中,只提取"姓名"这一列(投影)。对应的 SQL 语句:
sql
ŠSELECT S.姓名
FROM Student
JOIN SC ON Student.学号 = SC.学号
WHERE S.系别 = '计算机' AND SC.成绩 > 90;
为什么不能写成:
π S.姓名
from Student
⋈ Student.学号=SC.学号
σ系别='计算机'(Student) & σ成绩>90 (SC)在关系代数中,SQL 的 FROM 关键字并没有一个绝对单一的对应符号,而是取决于 FROM 后面跟了几个表以及怎么连接的。最核心的对应关系是:笛卡尔积 × 或 连接 ⋈ 。一般有三种情况:
- 当
FROM后面只有一个表时,对应符号:无(直接指代关系本身)
如果 SQL 是 SELECT 姓名 FROM 学生表,在关系代数中,不需要任何运算符号,直接写关系名称即可:
- 关系代数:π姓名(学生表)
- 解释 :
FROM 学生表只是指定了数据来源,没有发生表与表之间的运算。
- 当
FROM后面用逗号分隔多个表时(隐式连接)对应符号:笛卡尔积 ×
如果 SQL 是 FROM 学生表, 选课表,在关系代数中,这代表将两张表进行笛卡尔积运算。
- SQL :
SELECT * FROM 学生表, 选课表 - 关系代数:学生表 × 选课表
- 解释:笛卡尔积会将"学生表"的每一行与"选课表"的每一行进行两两强行组合。如果学生表有 100 行,选课表有 500 行,笛卡尔积的结果就是 50,000 行。
- 当
FROM后面使用JOIN关键字时(显式连接)对应符号:连接 ⋈
如果 SQL 是 FROM 学生表 JOIN 选课表 ON 学生表.学号 = 选课表.学号,在关系代数中,这对应连接运算。
- SQL :
SELECT * FROM 学生表 JOIN 选课表 ON 学生表.学号 = 选课表.学号 - 关系代数 : 学生表 ⋈ 学生表 . 学号 = 选课表 . 学号 选课表 学生表 \bowtie_{学生表.学号 = 选课表.学号} 选课表 学生表⋈学生表.学号=选课表.学号选课表 (等值连接)
- 解释 :连接运算本质上是 笛卡尔积 ( × \times ×) + 选择 ( σ \sigma σ) 的合体。它先做笛卡尔积,然后立刻把不满足
ON条件的行过滤掉。
从 SQL 执行顺序看 FROM 的地位
要理解 FROM 对应什么,需要知道 SQL 的底层执行顺序。数据库在执行 SQL 时,并不是从上往下读的,而是:
FROM(第一步:先确定数据来源,把表拼起来 → \rightarrow → 对应 × \times × 或 ⋈ \bowtie ⋈)WHERE(第二步:对拼好的大表进行行过滤 → \rightarrow → 对应 σ \sigma σ)GROUP BY(第三步:分组 → \rightarrow → 对应 G \mathcal{G} G)HAVING(第四步:对分组后的结果进行过滤 → \rightarrow → 对应 σ \sigma σ)SELECT(第五步:最后提取需要的列 → \rightarrow → 对应 π \pi π)
举个例子:
sql
SELECT S.姓名, SC.成绩
FROM 学生表 S, 选课表 SC
WHERE S.学号 = SC.学号 AND S.年龄 > 20;翻译成关系代数(从内向外执行):
- 先执行
FROM:学生表 × 选课表(笛卡尔积,拼成大表) - 再执行
WHERE:σ学号=学号 ^ 年龄>20} (...) (选择,过滤行) - 最后执行
SELECT:π姓名, 成绩 (...) (投影,提取列)
最终的关系代数表达式:π姓名,成绩 (σ S.学号=SC.学号 ^ 年龄>20 (学生表×选课表) )
总之,
-
看到
FROM 表A, 表B:想到 笛卡尔积 × -
看到
FROM 表A JOIN 表B:想到 连接⋈ -
看到
FROM 表A:想到 关系本身(无符号)关系完备性是数据库理论中衡量查询语言表达能力的基准。它由EF Codd提出,指的是:如果一种查询语言L能够表达出关系代数所能表达的全部查询,那么就称L是关系完备的。
关系演算在语言能力上是完备的。关系验算分为元组关系演算和域关系演算。codd证明了一个重要结论:安全的关系演算与关系代数在表达能力上等价。也就是说,所有可以用关系代数表达的查询,都可以用关系演算表达。反之亦然。因此关系演算完全满足关系完备性的定义。
五、 为什么要学关系代数?
- 理解数据库优化器的本质:当你写出一条 SQL 时,数据库的查询优化器会在内部将其转化为关系代数表达式(语法树),然后通过代数等价变换(如:提前做选择运算σ以减少参与连接的数据量)来寻找最高效的执行计划。
- 解决复杂查询:对于"查询选修了所有课程的学生"这种包含"全部"语义的复杂需求,用关系代数的"除法"思维去推导,能帮你写出正确的 SQL。
- 理论基石:它是关系数据库之所以被称为"关系"数据库的数学证明,保证了数据操作的严密性和一致性。
4、习题

5、解答