DeepSeek 终于"睁眼看世界"了!识图模式全解析,一文搞懂怎么用
从 OCR 到真正的图像理解,DeepSeek 多模态能力全面解读
6 月 18 日,DeepSeek 多模态研究员 Xiaokang Chen 宣布了一个重磅消息:DeepSeek 识图模式已在网页端和 App 端正式上线!
这意味着什么?意味着 DeepSeek 不再只是一个"只会读文字"的 AI,它现在真的能**"看懂图片"**了。而且,它的能力远不止简单的文字提取------从识别场景、理解物体关系,到推理空间逻辑、解读梗图笑点,DeepSeek 识图模式正在重新定义 AI 与图像交互的边界。
今天这篇文章,我们就来全面、深入、通俗地拆解 DeepSeek 识图模式:它是什么、怎么用、能做什么、背后什么技术、和竞品比怎么样......看完这篇,你就全明白了。
一、识图模式是什么?三句话讲清楚
如果你之前用过 DeepSeek,一定知道它有**"快速模式"** 和**"专家模式"** 两种对话模式。现在,输入框上方多了一个新伙伴------"识图模式",三者并列。
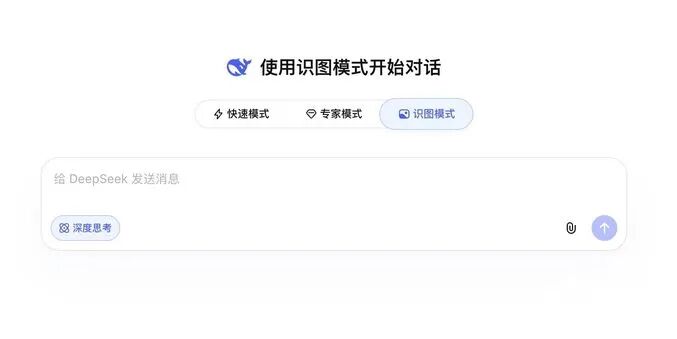
简单来说:
✅ 识图模式 = 上传图片 + AI 深度理解
✅ 不是简单的 OCR 文字识别,而是真正的"看图说话"
✅ 支持场景分析、物体识别、逻辑推理、代码还原......能力远超你的想象
开启识图模式后,你就可以直接上传图片,让 DeepSeek 帮你"看"世界。
二、和普通 OCR 有什么区别?这是关键
很多人第一反应是:"识图?不就是 OCR 识别文字吗?这有什么稀奇的?"
还真不是。 传统 OCR 只能做一件事:把图片里的文字"抄"出来。而 DeepSeek 识图模式做的是全方位的图像理解。我们用一张表来对比:
| 对比维度 | 传统 OCR | DeepSeek 识图模式 |
|---|---|---|
| 文字提取 | ✅ 能做 | ✅ 能做,且更准 |
| 场景理解 | ❌ 不行 | ✅ 能识别"这是高铁车厢" |
| 逻辑推理 | ❌ 不行 | ✅ 能推理"F=靠窗" |
| 空间关系 | ❌ 不行 | ✅ 能判断物体左右上下 |
| 代码还原 | ❌ 不行 | ✅ 截图直接生成可运行代码 |
| 联网增强 | ❌ 不行 | ✅ 结合网络信息深度推理 |
举个真实例子:有人上传了一张高铁座位信息牌 的照片。传统 OCR 只能告诉你牌子上写了"G1234、5车、12F"。但 DeepSeek 识图模式不仅识别出这些文字,还能推理出"这是 G1234 次列车 5 车 12F 座位,F 表示靠窗"------它通过文字语义推理出了场景类型和座位位置,这就是"理解"和"抄写"的本质区别。
三、怎么用?手把手教你(网页端 + App 端)
📱 网页端操作
Step 1 打开浏览器,访问 deepseek.com
Step 2 登录账号,进入对话界面
Step 3 在输入框上方,点击**"识图模式"**按钮(与"快速""专家"并列)
Step 4 点击输入框旁的**"上传图片"**按钮,选择本地图片
Step 5 输入你的问题,比如"请描述这张图片的内容"
Step 6 等待几秒,获得图文结合的分析结果
📲 App 端操作
Step 1 打开 DeepSeek App,进入对话界面
Step 2 切换到**"识图模式"**
Step 3 点击输入框旁的 "+" 号,选择**"图片识文字"** 或**"拍照识文字"**
Step 4 从相册选择图片(最多 20 张),或直接拍照
Step 5 输入具体需求,如"翻译图片中的英文"或"识别植物种类"
Step 6 获取结果,可继续多轮追问
⚠️ 温馨提示: 目前 App 端识图模式可能仍提示"图片理解功能内测中",网页端已无此限制。建议优先使用网页端体验完整功能。
四、深度思考 vs 快速回答:该开哪个?
识图模式里有一个关键开关------"深度思考"。开不开,体验完全不同:
🚀 关闭深度思考
• 响应极快,几乎秒回
• 适合简单识别任务
• 如:提取文字、描述内容
• 推理能力有限
🧠 开启深度思考
• 耗时较长(可能数分钟)
• 适合复杂推理任务
• 如:空间推理、逻辑分析
• 准确率大幅提升
实测发现,一道空间拼图题,关闭深度思考时**"秒错"** ,开启后成功给出正确答案(虽然耗时 4 分多钟)。所以:
📌 简单任务(OCR、描述、翻译)→ 关闭深度思考,追求速度
📌 复杂任务(推理、分析、解题)→ 开启深度思考,追求准确
五、8 大核心能力,一个比一个强
根据实测反馈,DeepSeek 识图模式目前展现出以下核心能力:
1️⃣ 图像内容理解
上传任意图片(截图、照片、文档扫描件),DeepSeek 能够识别图中文字、理解文字之间的逻辑关系(如标题-正文、表格行列)、描述图像整体场景,还能回答基于图像的自然语言问题。
2️⃣ 场景与物体识别
不仅能识别"图里有什么",还能理解"它们在干什么"。比如上传一张灵隐寺的照片,仅凭路灯上的草书字样和建筑风格,就能快速锁定地理位置并给出精确经纬度------这已经不是简单的图像识别,而是场景推理。
3️⃣ 表格与数据提取
上传包含表格的图片,DeepSeek 不仅能识别表格内容,还能自动转换为规范的 Markdown 格式,行列对齐、数据完整。对于财务报表、数据截图等场景,这个能力堪称神器。
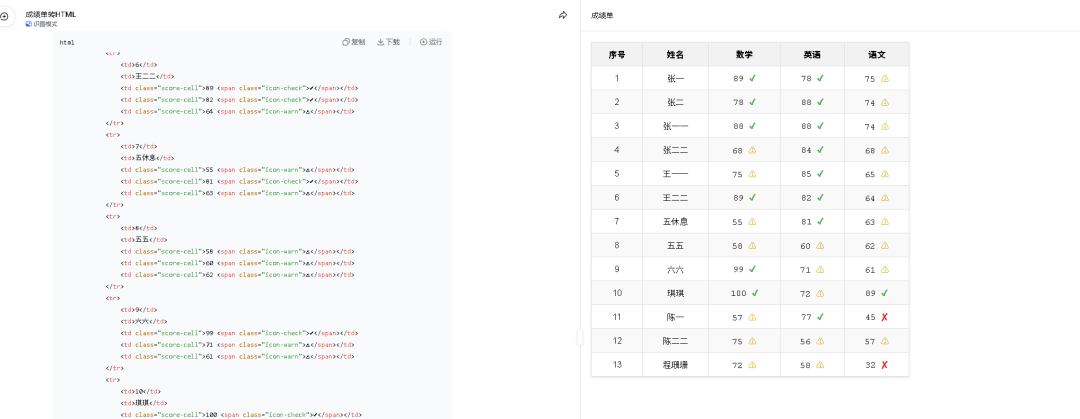
4️⃣ 代码与 UI 还原
这是最让人惊艳的能力之一。上传一张网页截图或代码截图,DeepSeek 不仅能提取所有文字,还能直接生成可交互的 HTML 代码,复原原网页的跳转按钮和布局。相当于一个"截图转码器",前端开发者狂喜。
5️⃣ 手写文字识别
上传手写潦草的笔记图片,DeepSeek 能精准识别大部分内容,整体准确率远超预期。对学生党和经常处理手写笔记的人群十分友好。
6️⃣ 梗图与表情包解读
是的,它甚至能看懂梗图。上传一张流行的表情包,DeepSeek 能精准识别图片内容,解读出笑点和转发理由,甚至理解小猫的情绪。这已经不是"识别",而是"共情"了。
7️⃣ 联网增强问答
在"联网搜索"模式下,DeepSeek 可结合图像内容与网络信息进行深度推理。比如:
💊 上传药品说明书图片 → 问"该药是否可用于孕妇?" → 自动检索权威资料回答
🔌 上传电路图 → 问"这个元件型号是什么?哪里可以购买?" → 联网搜索给出购买链接
8️⃣ 文物与专业领域识别
上传一件玉器的照片,DeepSeek 能详细描述纹理与材质,甚至准确推断出这是 18 世纪清代乾隆时期的"痕都斯坦风格"。这种专业领域的识别能力,已经超越了普通用户的认知范围。
六、背后什么技术?"以视觉原语思考"通俗解读
DeepSeek 识图模式之所以这么强,背后有一套创新的技术框架------Thinking with Visual Primitives(以视觉原语思考)。名字听起来很学术,我们用大白话来解释。
🤔 以前的方法有什么问题?
传统的多模态 AI 看图,基本上是"先看图,再说话"------先把图片转成一堆数字(token),然后让语言模型去处理这些数字。问题是:语言是模糊的。当 AI 想说"右边的红色方块"时,"右边"到底是多右?"红色"到底是多红?这种模糊性导致 AI 在空间推理时经常出错。
💡 DeepSeek 的创新:让 AI 学会"指图说话"
DeepSeek 的思路是:既然语言模糊,那就让 AI 在思考的时候,直接"指"到图片上的具体位置。
就像你教小朋友认路------光说"往右拐再往左拐"他可能迷糊,但如果你用手指着地图 说"从这里走到这里",他就明白了。DeepSeek 让 AI 在推理过程中,把"点"和"框"这些视觉元素当作**"思维的基本单元"**,直接嵌入思考链路中,就像给 AI 装了一根"手指",让它能一边想一边指。
⚡ 还有一个绝招:超级压缩
一张 756×756 的图片,传统方案需要大量视觉 token 喂给语言模型,非常吃内存。DeepSeek 用了**"压缩稀疏注意力"(CSA)**机制,经过三步压缩:
🔹 图片经 ViT 处理 → 2916 个图像块 token
🔹 3×3 空间压缩 → 324 个 token
🔹 CSA 进一步压缩 → 仅 81 个视觉 KV 条目
📊 整体压缩比:7056 倍!
这意味着 DeepSeek 只用其他前沿系统所需视觉 token 的一小部分,就能达到相当甚至更好的认知深度。省内存、速度快、效果还好------这就是工程上的硬实力。
七、实测案例:看看它到底有多能
光说不练假把式,我们来看几个真实测试案例:
📋 案例 1:高铁信息牌识别
**输入:**一张高铁座位信息牌照片
**输出:**不仅识别出"G1234 次列车 5 车 12F",还推理出"F 表示靠窗座位",并通过文字语义推断出场景类型
**亮点:**超越 OCR,实现了语义推理 🌟
🎮 案例 2:多邻国界面解读
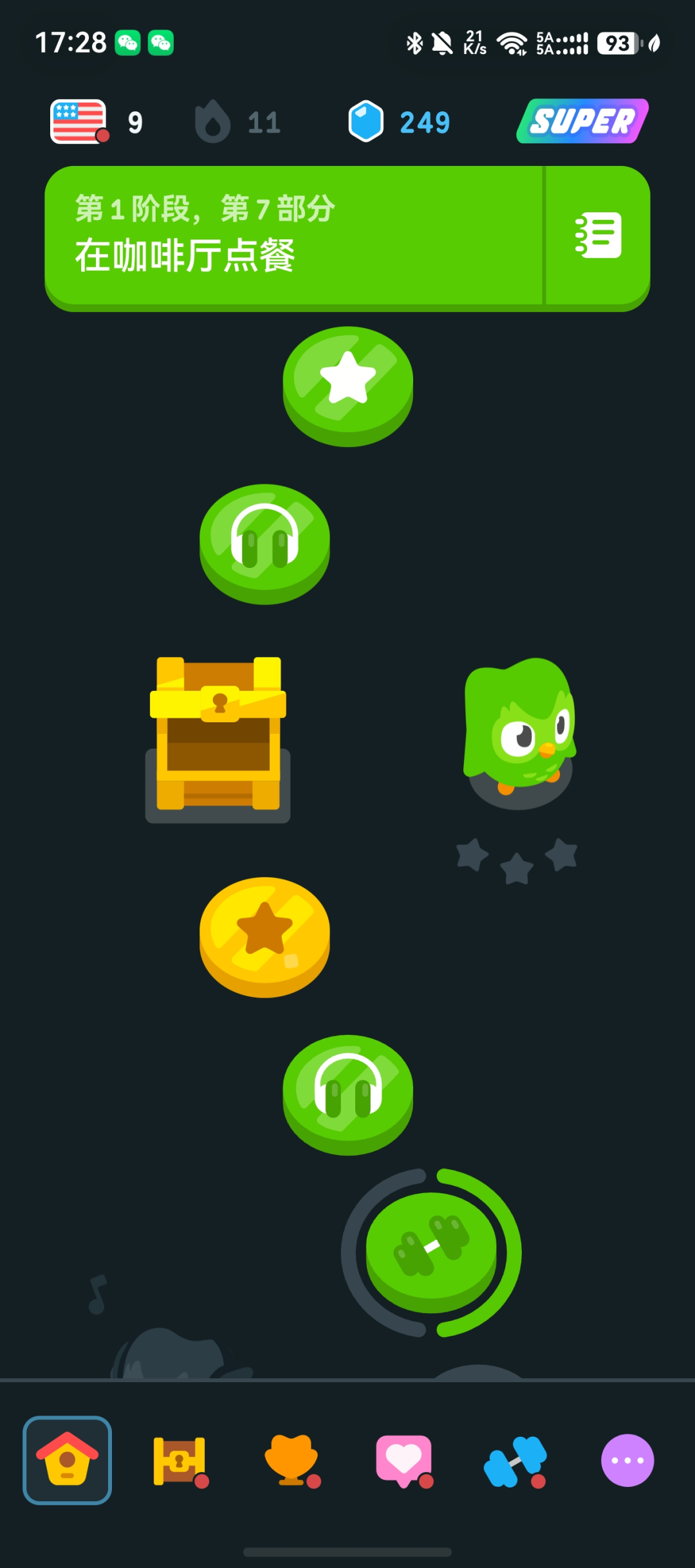
**输入:**一张多邻国(Duolingo)猫头鹰界面截图
**输出:**成功识别应用名称"Duolingo"、界面功能区域、当前学习进度、猫头鹰角色状态

**亮点:**对 UI 界面的结构化理解 🌟
🏛️ 案例 3:灵隐寺场景定位
**输入:**一张灵隐寺照片(无明确地名标识)
**输出:**仅凭路灯草书字样和建筑风格,锁定地理位置并给出精确经纬度
**亮点:**跨模态推理 + 知识关联 🌟


💻 案例 4:网页截图转代码
**输入:**一张包含按钮和表格的网页截图
**输出:**生成可交互的 HTML 代码,复原原网页布局和跳转按钮
**亮点:**从像素到代码的跨越 🌟
八、6 大实用场景,总有一个用得上
说了这么多能力,那到底在什么场景下用呢?这里整理了 6 个最实用的场景:
🎓 学习场景
拍板书 → 自动整理笔记 | 拍试卷 → 获取答案解析 | 拍手写稿 → 精准识别转文字
💼 办公场景
拍报表 → 提取数据转表格 | 拍合同 → 快速定位关键条款 | 拍名片 → 自动录入联系人
🛒 生活场景
拍商品 → 比价找同款 | 拍药品 → 查说明书和禁忌 | 拍植物 → 识别品种和养护方法
👨💻 开发场景
拍 UI 截图 → 生成前端代码 | 拍报错信息 → 获取修复建议 | 拍流程图 → 生成代码逻辑
🎨 设计场景
拍设计稿 → 提取配色和字体 | 拍 Logo → 分析设计风格 | 拍竞品界面 → 对比功能差异
🏥 专业场景
拍医学影像 → 辅助解读 | 拍文物 → 鉴定年代风格 | 拍电路图 → 分析元件和连接
九、和竞品比,DeepSeek 识图模式强在哪?
目前市面上支持图片理解的 AI 不止 DeepSeek 一家,GPT-4o、Claude、Gemini 都有类似能力。DeepSeek 的优势在哪?
| 维度 | DeepSeek | GPT-4o | Claude | Gemini |
|---|---|---|---|---|
| 中文理解 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 空间推理 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 代码还原 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| 免费使用 | ✅ 完全免费 | ❌ 需付费 | ❌ 需付费 | ⚠️ 有限免费 |
| 国内访问 | ✅ 直连 | ❌ 需梯子 | ❌ 需梯子 | ❌ 需梯子 |
DeepSeek 识图模式最大的差异化优势是:免费 + 国内直连 + 中文理解强。对于国内用户来说,这是目前最容易上手、最没有门槛的多模态 AI 识图工具。
十、使用技巧与注意事项
🔧 提升识别效果的 5 个技巧
1. 图片尽量清晰,建议 300dpi 以上,避免模糊、反光
2. 提问要具体,"请识别这张图"不如"请提取图中表格数据并转为 Markdown"
3. 批量处理时,网页端支持 Ctrl 多选,App 端长按触发多选
4. 上传大文件建议用 Wi-Fi,5G 网络下 10MB 图片约 1.2 秒
5. 善用多轮对话,第一轮识别后可追问细节、要求格式调整
⚠️ 需要注意的 3 个问题
1. App 端可能仍提示"内测中",优先用网页端
2. 深度思考模式耗时较长(复杂任务可能 4 分钟+),请耐心等待
3. 色盲测试等极端场景偶有失误,视觉模型仍有改进空间
🔒 隐私保护
在账号设置中可开启**"上传记录自动清除"**功能,系统将在 24 小时后删除原始图片数据。对于敏感图片,建议上传前用系统自带马赛克工具处理关键信息。
十一、开发者怎么接入?API 调用速览
如果你是开发者,想在自己的产品中集成 DeepSeek 的图片识别能力,可以通过 API 接口调用:
Python 示例
import requests
url = "https://api.deepseek.com/v1/chat/completions"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
图片需转为 Base64 编码
支持 JPEG/PNG,文件不超过 5MB
data = {
"model": "deepseek-vl",
"messages": {"role": "user", "content": \[...}]
}
输出格式可选 Markdown、JSON 或纯文本,适用于自动化文档处理、智能客服、教育辅助等场景。开发者可通过 vLLM 接口调用,支持流式(streaming)模式,具备低延迟、高并发的推理能力。
十二、未来展望:多模态是 AI 的必经之路
DeepSeek 识图模式的上线,标志着国产大模型正从纯文本向多模态加速迈进。这不仅仅是一个功能更新,更是 AI 发展方向的一个信号:
🔮 **短期:**识图模式灰度范围持续扩大,更多用户将获得访问权限
🔮 **中期:**深度思考的推理效率将优化,4 分钟 → 更快;视觉模型精度持续提升
🔮 **长期:**多模态能力将成为大模型标配,从"感知智能"向"认知智能"深层演进
DeepSeek 官方技术报告显示,其视觉模型在计数和空间推理基准测试中的表现,已与 GPT、Claude 和 Gemini 的最新版本持平甚至超越。这套"以视觉原语思考"的技术路径,为行业提供了宝贵的参考方向。
未来,随着识图模式的持续优化和更多模态(音频、视频)的加入,AI 助手将真正实现"看、听、说、想"的全维度交互。而 DeepSeek,正在这条路上加速奔跑。
写在最后
DeepSeek 识图模式的上线,让"AI 看图"这件事从概念走向了现实。它不是简单的 OCR 升级版,而是一个真正能理解图像、推理逻辑、连接知识的多模态 AI。
最重要的是------它免费、国内直连、中文能力强。对于每一个国内用户来说,这是目前体验多模态 AI 最零门槛的选择。
赶紧打开 deepseek.com,切换到识图模式,上传一张图片试试吧。相信我,你会被它的能力惊艳到。
你用 DeepSeek 识图模式做过什么有趣的事?
欢迎在评论区分享你的体验 👇
参考资料:IT之家、腾讯云开发者社区、太平洋科技、搜狐科技、36氪等
撰写日期:2026 年 6 月 18 日