本文分析 NVSHMEM 的内存管理方案,涉及 symmetric heap 的类型、初始化流程、分配释放流程,以及 symmetric heap 与通信路径之间的关系。
1. 概述
1.1 目标
NVSHMEM 的内存管理围绕 symmetric heap 展开。主要回答下面四个问题:
- NVSHMEM 支持哪些 symmetric heap 类型,每种类型的特点是什么。
nvshmem_init()如何初始化 symmetric heap。- 软件如何通过 NVSHMEM API 从 symmetric heap 分配和释放内存。
- symmetric heap 初始化出的元数据如何支撑后续通信路径。
1.2 关键代码
关键入口如下:
| 主题 | 文件 |
|---|---|
Public API 声明与 nvshmem_init() 包装 |
src/include/host/nvshmem_api.h |
| Host 初始化主流程 | src/host/init/init.cu |
| Symmetric heap 实现 | src/host/mem/mem_heap.cpp |
| Symmetric heap 类定义 | src/include/internal/host/nvshmemi_symmetric_heap.hpp |
| Remote / P2P memory transport 辅助 | src/host/mem/mem_transport.cpp |
| Host 内部状态定义 | src/include/internal/host/nvshmemi_types.h |
| Device 可见状态定义 | src/include/device_host/nvshmem_types.h |
1.3 核心概念
NVSHMEM 的 symmetric heap 是一个所有 PE 都参与管理的对称内存区域。每个 PE 上的 heap_base 可以不同,但只要所有 PE 以一致顺序、相同大小执行分配,同一个对象在各 PE heap 中的 offset 就一致。远端地址通常由如下关系得到:
text
remote_addr(pe) = peer_heap_base(pe) + (local_ptr - local_heap_base)这也是 nvshmem_ptr()、device 端 P2P load/store、IBGDA/remote transport 计算远端地址的基础。
2. 总体架构
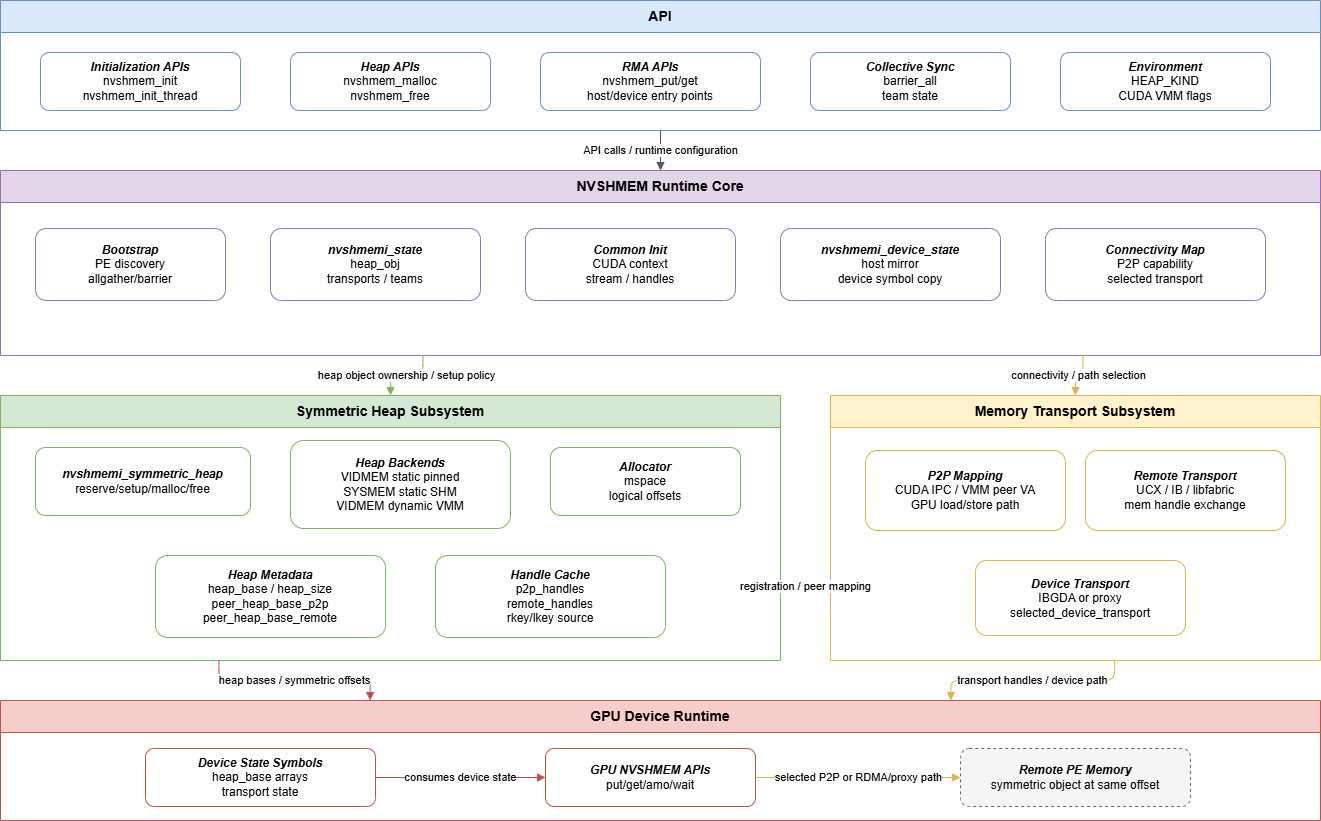
NVSHMEM 内存管理可以看成五层:
- API :暴露
nvshmem_init()、nvshmem_malloc()、nvshmem_free()、nvshmem_put()、nvshmem_get()等接口。 - NVSHMEM Runtime Core :维护
nvshmemi_state和nvshmemi_device_state,state 中保存了通信用到的内存和 transport 信息。 - Symmetric heap Subsystem :通过
nvshmemi_symmetric_heap多态接口屏蔽不同 heap 后端。 - Memory transport Subsystem:负责 P2P 映射、remote mem handle 注册、handle allgather。
- GPU Device Runtime:实现 NVSHMEM device-side API,并根据 host 初始化发布的 device state 选择 P2P transport 或 remote transport 路径完成通信。
2.1 API
src/include/host/nvshmem_api.h 中的 nvshmem_init() 是一个 static inline 包装函数,实际调用:
text
nvshmem_init()
-> nvshmemi_init_thread(NVSHMEM_THREAD_SERIALIZED, ...)内存管理 API 包括:
c
void *nvshmem_malloc(size_t size);
void *nvshmem_calloc(size_t count, size_t size);
void *nvshmem_align(size_t alignment, size_t size);
void nvshmem_free(void *ptr);这些 API 分配出来的地址属于 NVSHMEM symmetric heap。
2.2 NVSHMEM Runtime Core
nvshmemi_state 是 host 侧运行时主状态,其中保存 bootstrap、transport、team、heap object 等 host 可见信息。它的 heap_obj 字段指向当前使用的 symmetric heap 实例。nvshmemi_device_state 是 host/device 共享的设备状态镜像。初始化时,host 会把关键字段拷贝到 device symbol,使 GPU kernel 中的 NVSHMEM device API 能访问,重要的成员如下:
heap_baseheap_sizepeer_heap_base_p2ppeer_heap_base_remotemypenpesselected_device_transport
2.3 Symmetric heap Subsystem
基类 nvshmemi_symmetric_heap 定义统一接口:
cpp
[src/include/internal/host/nvshmemi_symmetric_heap.hpp]
class nvshmemi_symmetric_heap {
......
/** Common to all memory kinds */
/**
* This function will statically reserve heap memory based on memory kind in child class
* For dynamic vidmem types, only virtual memory is reserved and mspace is initialized
* For static vidmem and sysmem, virtual and physical memory is reserved/pre-allocated and
* mspace is initialized
*
* @param void
* @return On success, return 0 and on failure return non-zero NVSHMEM internal error code.
*/
virtual int reserve_heap(void) = 0;
virtual int setup_symmetric_heap() = 0;
virtual int cleanup_symmetric_heap() = 0;
/** Top-level public facing functions */
virtual void *heap_malloc(size_t size);
virtual void *heap_calloc(size_t size, size_t count);
virtual void *heap_align(size_t size, size_t alignment);
virtual void heap_deallocate(void *ptr);
/* Functions to map and unmap user buffers
* memory registered using nvshmemx_buffer_register_symmetric call
* is refered to as external allocation
* while memory allocated using nvshmem_malloc is referred to as internal
* allocation in the code
*/
virtual void *mmap_mem(void *ptr, size_t size, int flags) = 0;
virtual int unmap_mem(void *ptr, size_t size) = 0;
......
}不同 heap 后端只需要实现内存保留、注册、映射和释放的细节。
2.4 Memory transport Subsystem
NVSHMEM 区分两类访问能力:
- P2P / map capable transport:可以把远端 PE heap 映射到本 PE 地址空间,device 端可直接 load/store。包括 PCIe P2P 和 NVLink P2P。
- Remote transport:不能直接映射时,通过 transport mem handle 支持 RDMA、IBGDA、UCX 等远程访问。
初始化时,heap 层会和 transport 层协作:
- 导出本地 heap 或 chunk 的 mem handle。
- 通过 bootstrap allgather 交换各 PE handle。
- 对 P2P peer 执行映射。
- 对 remote transport 更新远程 mem handle 缓存。
2.5 GPU Device Runtime
Device 端访问 symmetric heap 时不会重新查询 host 对象,而是依赖初始化时同步下来的 device state:
text
peer_heap_base_p2p[pe] != NULL
-> 直接用 peer P2P 映射地址访问
peer_heap_base_p2p[pe] == NULL
-> 通过 selected_device_transport 进入 proxy / IBGDA 等远程路径因此,symmetric heap 初始化不仅是分配内存,还决定了后续通信 API 的地址计算和路径选择。
3. Symmetric Heap 类型与特点
3.1 nvshmemi_symmetric_heap 类层次
代码中的类层次如下:
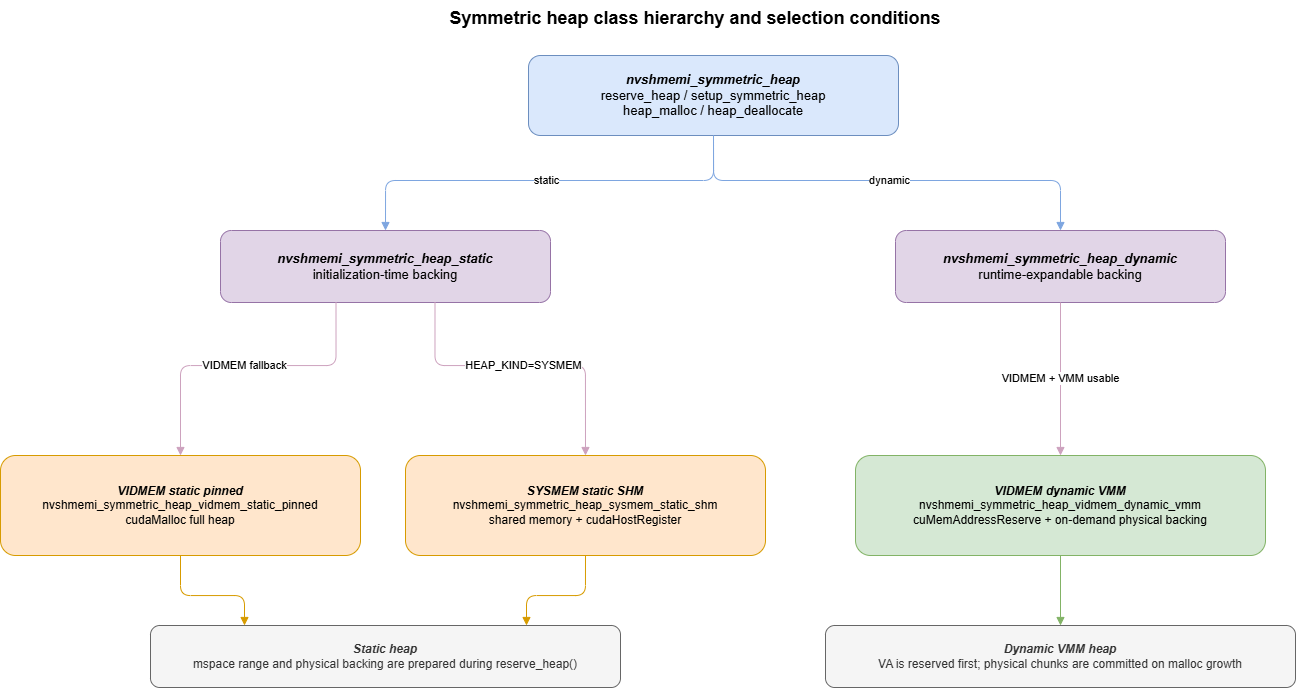
nvshmemi_symmetric_heap 是基类。它下面分两大类:
nvshmemi_symmetric_heap_staticnvshmemi_symmetric_heap_dynamic
当前代码中有三种具体 heap:
| 类型 | 具体类 | 底层内存 |
|---|---|---|
| VIDMEM static pinned | nvshmemi_symmetric_heap_vidmem_static_pinned |
cudaMalloc |
| SYSMEM static SHM | nvshmemi_symmetric_heap_sysmem_static_shm |
Linux shared memory + cudaHostRegister |
| VIDMEM dynamic VMM | nvshmemi_symmetric_heap_vidmem_dynamic_vmm |
CUDA VMM, cuMemAddressReserve / cuMemCreate / cuMemMap |
3.2 VIDMEM static pinned
该类型用于 CUDA VMM 不启用或不可用、且 heap kind 为 device memory 的场景。特点如下:
- 初始化时一次性
cudaMalloc(&heap_base_, heap_size_)。 heap_size_来自NVSHMEM_SYMMETRIC_SIZE + heapextra,再按 granularity 对齐。- 物理内存在初始化时已经分配完整。
mspace管理整个[heap_base_, heap_base_ + heap_size_)。nvshmem_malloc()只是从已有 mspace 中切出一段内存。- 初始化时会注册整段 heap,建立 P2P 映射和 remote mem handle 缓存。
VIDMEM static pinned heap 优点是实现简单、初始化后分配成本低;代价是初始化时就占用完整 symmetric heap 物理内存。
3.3 SYSMEM static SHM
该类型由 NVSHMEM_HEAP_KIND=SYSMEM 选择。它在节点内创建共享内存 slab,每个本地 PE 使用其中一个 slice。特点如下:
- 节点内 rank 0 创建 shared memory,其余本地 rank 打开同一 shm。
- shm 大小为
heap_size_ * npes_node。 - 每个 PE 的
heap_base_是该 shm 的 device pointer 加上本地 PE offset。 - 通过
cudaHostRegister()注册 host shared memory,再用cudaHostGetDevicePointer()获取 device 可见地址。 - 支持 rail optimization 的场景只在 SYSMEM heap 下启用。
SYSMEM static SHM heap 适合需要 host-visible symmetric heap 或特殊 rail optimization 的场景;代价是访问路径和性能特征不同于纯 device memory,可能会有性能损失。
3.4 VIDMEM dynamic VMM
该类型用于 heap kind 为 VIDMEM、CUDA VMM 可用且没有被 NVSHMEM_DISABLE_CUDA_VMM 禁用的场景。特点如下:
- 初始化时只 reserve 大块虚拟地址空间,不立即提交全部物理内存。
heap_size_使用max(NVSHMEM_MAX_MEMORY_PER_GPU, heapextra),再按 granularity 对齐。cuMemAddressReserve()reserve 的范围为p2p_npes * heap_size_,为本地 heap 和 P2P peer 窗口预留连续 VA。physical_internal_heap_size_记录已经为nvshmem_malloc()分配的物理内存。nvshmem_malloc()触发 mspace 不足时,才通过cuMemCreate()/cuMemMap()分配并映射新的物理内存。- 每次扩展 chunk 后,会注册新 chunk 的 mem handle,并更新 device state。
VIDMEM dynamic VMM heap 优点是虚拟地址空间大、物理内存按需提交;代价是首次分配或扩容时需要更多注册、映射和同步工作。
3.5 三种 Symmetric Heap 的对比
| 维度 | VIDMEM static pinned | SYSMEM static SHM | VIDMEM dynamic VMM |
|---|---|---|---|
| 底层内存 | GPU device memory | Host shared memory | GPU device memory |
| 主要 API | cudaMalloc |
shm + cudaHostRegister |
CUDA VMM |
| 物理内存分配时机 | 初始化时一次性分配 | 初始化时一次性分配 | nvshmem_malloc() 按需扩展 |
| heap VA 模型 | 单段本地 heap | 节点内共享 slab 切片 | 本地 heap + peer VA window |
| mspace 初始范围 | 整段 heap | 当前 PE slice | 初始已分配物理内存为 0 |
| P2P 映射 | 初始化时注册/映射 | 初始化时注册/映射 | 初始化预留 VA,扩容时映射 chunk |
| remote mem handle | 初始化注册整段 heap | 初始化注册整段 heap | 扩容时注册 chunk |
| 典型优势 | 简单、分配快 | host-visible、支持 SYSMEM 特性 | 按需提交、VA 空间灵活 |
| 典型代价 | 初始化占用完整显存 | 访问性能受 sysmem 影响 | 扩容路径复杂 |
3.6 Heap 信息与内部管理结构
Heap 大小和对齐由以下信息共同决定:
NVSHMEM_SYMMETRIC_SIZENVSHMEM_MAX_MEMORY_PER_GPU- CUDA allocation granularity
NVSHMEMI_MAX_HANDLE_LENGTH- 内部通信 buffer、team 管理和对齐额外空间
heapextra
内部管理结构主要包括:
heap_base_:当前 PE heap 起始地址。global_heap_base_:对 SYSMEM/VMM 场景可能代表更大共享或 reserve 区域。heap_size_:每个 PE 的逻辑 heap 大小。physical_internal_heap_size_:dynamic VMM 已经分配的内部 heap 物理内存大小。heap_mspace_:管理nvshmem_malloc/calloc/align的 allocator。mmap_mspace_:dynamic VMM 中管理外部用户 buffer 映射进 symmetric heap VA 后的地址分配。peer_heap_base_p2p_:device 可直接 P2P 访问的 peer base。peer_heap_base_remote_:remote transport 用于计算远端 heap offset 的 peer base。remote_handles_/p2p_handles_:transport mem handle 缓存。
4. Symmetric Heap 初始化流程
4.1 调用链
初始化入口如下:
text
nvshmem_init()
-> nvshmemi_init_thread()
-> nvshmemid_hostlib_init_attr()
-> nvshmemi_options_init()
-> nvshmemi_bootstrap_preinit()
-> nvshmemi_bootstrap()
-> nvshmemi_state
-> nvshmemi_try_common_init()
-> nvshmemi_common_init()nvshmemid_hostlib_init_attr() 完成版本检查、bootstrap、线程临界区初始化、debug/NVTX 初始化、nvshmemi_state 分配等工作。真正涉及 CUDA context、transport、heap 和 device state 的流程在 nvshmemi_common_init()。

4.2 创建 heap 对象
nvshmemi_init_symmetric_heap 函数只创建具体 heap 对象,不分配和注册内存:
text
if is_vmm
-> new nvshmemi_symmetric_heap_vidmem_dynamic_vmm
else if heap_kind == SYSMEM
-> new nvshmemi_symmetric_heap_sysmem_static_shm
else if heap_kind == VIDMEM
-> new nvshmemi_symmetric_heap_vidmem_static_pinned如果选择 dynamic VMM,state->vmm_heap 也会指向该具体对象,供 NVLS 和 external symmetric mmap buffer 注册等路径使用。构造 static/dynamic heap 时,还会设置 P2P transport 和 remote transport 引用:
text
set_p2p_transport(nvshmemi_mem_p2p_transport::get_instance(...))
set_remote_transport(nvshmemi_mem_remote_transport::get_instance())
state->p2p_transport = get_p2pref()4.3 reserve_heap
reserve_heap() 在 transport 初始化之前执行。它负责准备当前 PE 的本地 heap 地址空间和 allocator 基础结构。
4.3.1 Static heap
对于 static heap,nvshmemi_symmetric_heap_static::reserve_heap() 的框架相同,差别由各自 allocate_heap_memory() 决定:
- VIDMEM static 的
allocate_heap_memory()使用cudaMalloc()。 - SYSMEM static 的
allocate_heap_memory()使用 shared memory、cudaHostRegister()和cudaHostGetDevicePointer()。
4.3.2 Dynamic VMM
nvshmemi_symmetric_heap_vidmem_dynamic_vmm::reserve_heap() 做的是虚拟地址预留:
text
cuMemGetAllocationGranularity()
heap_size_ = round_up(max(MAX_MEMORY_PER_GPU, heapextra))
cuMemAddressReserve(global_heap_base_, p2p_npes * heap_size_)
heap_base_ = global_heap_base_
mmap_base_ = heap_base_ + heap_size_
setup_mspace()注意 dynamic VMM 的 physical_internal_heap_size_ 初始为 0,因此初始化时不会分配物理内存。
4.4 transport
Heap reserve 后,nvshmemi_common_init() 进入 transport 初始化和连接建立阶段。主要的工作如下:
- 初始化可用的 transport。
- 测试 peer PE 可用 transport 的到达性,以及 capability。
- 选择最优的 transport,然后建立连接。
text
nvshmemi_transport_init()
nvshmemi_build_transport_map()
nvshmemi_setup_cuda_handles()
nvshmemi_setup_nvshmem_handles()
nvshmemi_setup_connections()需要先区分两组对象:
state->transports[]:真正参与通信路径选择的 runtime transport,包括 P2P、IBRC、UCX、IBDEVX、libfabric、IBGDA 等。nvshmemi_mem_p2p_transport/nvshmemi_mem_remote_transport:heap 层使用的 memory transport helper。它们在 heap 构造函数里挂到heap_obj上,后续负责 P2P handle 导入导出、remote mem handle 注册和 device state 更新等内存注册辅助工作。
4.4.1 初始化
nvshmemi_transport_init() 会按固定顺序尝试初始化 transport,并把成功的对象放入 state->transports[]。
P2P transport 默认优先初始化,除非通过环境变量禁用:
text
if !NVSHMEM_DISABLE_P2P:
nvshmemt_p2p_init(&transports[index])
-> 获取当前 CUDA context 对应的 CUdevice
-> 枚举本进程可见 CUDA device
-> 记录每个 device 的 PCIe domain/bus/device id
-> host_ops.can_reach_peer = nvshmemt_p2p_can_reach_peer
-> attr = NVSHMEM_TRANSPORT_ATTR_NO_ENDPOINTS
-> no_proxy = trueP2P transport 不需要 connect_endpoints(),因为它不是网络 endpoint 模型。它的作用是判断某个 peer 是否可以被映射到本 PE 地址空间,并在 heap setup 阶段支撑 CUDA IPC 或 CUDA VMM shareable handle 的导入导出。
remote transport 由 NVSHMEM_REMOTE_TRANSPORT 选择。编译时支持哪些插件,就在这些插件中选一个传统 remote transport:
text
NVSHMEM_REMOTE_TRANSPORT=ibrc -> nvshmem_transport_ibrc.so.*
NVSHMEM_REMOTE_TRANSPORT=ucx -> nvshmem_transport_ucx.so.*
NVSHMEM_REMOTE_TRANSPORT=ibdevx -> nvshmem_transport_ibdevx.so.*
NVSHMEM_REMOTE_TRANSPORT=libfabric -> nvshmem_transport_libfabric.so.*
NVSHMEM_REMOTE_TRANSPORT=none -> 不加载传统 remote transport初始化流程是:
text
dlopen(selected transport .so)
dlsym("nvshmemt_init")
nvshmemt_init(&transports[index], cuda_syms, interface_version)
-> transport 插件填充 host_ops、attr、n_devices、capability 相关状态
-> runtime 填充 boot_handle、heap_base、cap[]、index、my_pe、n_pes
-> runtime 挂接 cache_handle、alias_va_map、egm_map如果启用 NVSHMEM_IB_ENABLE_IBGDA,还会额外尝试加载 nvshmem_transport_ibgda.so.*。IBGDA 是 device-side IB transport,初始化成功后会设置:
text
nvshmemi_device_state.ibgda_is_initialized = true
nvshmemi_device_state.selected_device_transport = NVSHMEMI_DEVICE_TRANSPORT_TYPE_IBGDA它和传统 remote transport 的区别是:IBGDA 主要服务 GPU device 端直接发起 RDMA 的路径,不作为普通 host API 的 selected_transport_for_rma/amo。
最终只要至少有一个 transport 初始化成功,则state->num_initialized_transports 记录成功个数;如果 P2P、remote、IBGDA 都不可用,初始化失败。
4.4.2 获取 transport 能力
nvshmemi_build_transport_map() 会汇总所有 transport 的能力。
4.4.2.1 P2P transport
P2P 是否可用不是简单看"同节点",而是在 nvshmemi_build_transport_map() 阶段,对每个 peer 调用 P2P transport 的 nvshmemt_p2p_can_reach_peer() 得到 capability。
大致逻辑如下:
text
peer 在 MNNVL / NVLink fabric connected PE 列表中
-> MAP | GPU_LD | GPU_ST | GPU_ATOMICS
peer 与本 PE 不在同 host
-> 不能走普通 P2P map,返回 0
peer PE 使用的 GPU 与本 PE 当前 CUDA device 是同一个物理 GPU
-> MAP | GPU_LD | GPU_ST | GPU_ATOMICS
peer device 对本进程可见
-> cudaDeviceCanAccessPeer()
-> 若可访问,设置 MAP | GPU_LD | GPU_ST
-> cudaDeviceGetP2PAttribute(native atomic)
-> 若 native atomic 可用,额外设置 GPU_ATOMICS
peer device 不可见,但可以用 NVML 查询
-> nvmlDeviceGetP2PStatus(READ/WRITE/ATOMICS)
-> 根据 NVML status 设置 MAP、GPU_LD、GPU_ST、GPU_ATOMICS对于 dynamic VMM heap,还有一个与 P2P helper 相关的初始化结果:nvshmemi_mem_p2p_transport 在构造时会用 NVML 发现 MNNVL / NVLink fabric 信息,并选择 CUDA allocation handle type:
text
MNNVL fabric 可用且设备支持 CU_MEM_HANDLE_TYPE_FABRIC
-> CU_MEM_HANDLE_TYPE_FABRIC
否则
-> CU_MEM_HANDLE_TYPE_POSIX_FILE_DESCRIPTOR
如果设置 NVSHMEM_CUMEM_HANDLE_TYPE
-> 使用用户指定的 FABRIC 或 FILE_DESCRIPTOR这个类型后续会传给 dynamic VMM 的 cuMemCreate(),决定 VMM shareable handle 通过 fabric handle 还是 POSIX FD 表示。
4.4.2.2 remote transport
remote transport 插件初始化后,也会在 nvshmemi_build_transport_map() 中对每个 peer 调用自己的 host_ops.can_reach_peer()。插件返回的 capability 可能包括:
text
CPU_READ / CPU_WRITE / CPU_ATOMICS
GPU_READ / GPU_WRITE / GPU_ATOMICS这些 capability 表示该 remote transport 能否为目标 peer 提供 host-side RMA/AMO、proxy 路径或 device-side transport 支撑。注意这一阶段仍然没有注册 symmetric heap;这里只是在回答"这个 transport 能否到达这个 peer"。
4.4.3 选择 transport
nvshmemi_setup_nvshmem_handles() 根据前面得到的 capability,为每个 peer 选择最优的 transport。选择策略很直接:按 state->transports[] 的顺序扫描,选第一个满足能力要求的 transport。
text
RMA 可用:
CPU_READ / CPU_WRITE / MAP_GPU_LD / MAP_GPU_ST
AMO 可用:
CPU_ATOMICS / MAP_GPU_ATOMICS因为 P2P transport 通常先于 remote transport 初始化,所以如果某个 peer 支持 P2P map,RMA/AMO 会优先落到 P2P capability;如果 P2P 不可用,就继续扫描 IBRC/UCX/IBDEVX/libfabric 等 remote transport。IBGDA 不通过这两个数组服务普通 host API,它通过 selected_device_transport 和 IBGDA 自己的 device state 服务 device-side 路径。
实际访问时还会结合 heap setup 之后填好的 peer_heap_base_p2p[pe]:如果该 peer 已经有 P2P 映射地址,host/device 路径可以直接走 mapped RMA;否则才依赖 remote transport 及其 mem handle/device state。
4.4.4 transport connect
nvshmemi_setup_connections() 只处理带 NVSHMEM_TRANSPORT_ATTR_CONNECTED 的 transport。P2P transport 的属性是 NVSHMEM_TRANSPORT_ATTR_NO_ENDPOINTS,因此会被跳过。
对 connected remote transport,流程是:
text
for each initialized transport:
if transport 不在 transport_bitmap:
continue
if !(transport->attr & CONNECTED):
continue
根据 transport->n_devices 和本节点 PE 数计算可选 NIC/device 数
if NVSHMEM_ENABLE_NIC_PE_MAPPING:
selected_device = mype_node % n_devices
else:
nvshmemi_get_devices_by_distance()
transport->host_ops.connect_endpoints(selected_devices)
bootstrap barrier
if 连接失败:
nvshmemi_transport_finalize_one()如果连接建立失败,nvshmemi_common_init() 会重新调用 nvshmemi_build_transport_map(),把失败的 transport 从后续选择中剔除。
至此,NVSHMEM runtime Core 已经完成如下的任务:
- 可用 transport 初始化成功。
- 每个 peer 对每个 transport 的 capability。
- host RMA/AMO 对每个 peer 选择哪个 transport。
- connected remote transport 的 endpoints 是否建好。
- dynamic VMM 应使用哪种 CUDA shareable handle type。
4.5 setup_symmetric_heap
setup_symmetric_heap() 在 transport map 和 connection 完成后执行,负责把 heap 地址信息和 transport 注册关系补齐。
首先调用公共逻辑 allgather_peer_base() 获取所有 PE 的 heap base,并初始化两类 peer base 数组:
text
allgather_peer_base()
peer_heap_base_remote_ = calloc(npes)
allgather(heap_base_ -> peer_heap_base_remote_)
peer_heap_base_p2p_ = calloc(npes)
peer_heap_base_p2p_[mype] = heap_base_其中 peer_heap_base_remote_ 保存所有 PE 原始 heap_base_,主要用于 remote transport / IBGDA 按 offset 计算远端地址;peer_heap_base_p2p_ 是 P2P 映射地址表,allgather_peer_base() 只填入本 PE 的 heap_base_,其他 PE 的 P2P 地址由后续 static heap 或 dynamic VMM 逻辑继续填充。
4.5.1 Static heap
Static heap 包括 VIDMEM static pinned 和 SYSMEM static shm。两者的 setup_symmetric_heap() 使用同一个公共入口,流程非常短:
text
nvshmemi_symmetric_heap_static::setup_symmetric_heap()
-> allgather_peer_base()
peer_heap_base_remote_ = all PE 原始 heap_base_
peer_heap_base_p2p_[mype] = heap_base_
-> register_heap_memory(NULL, heap_base_, heap_size_)
为整段 static heap 建立后续通信所需的映射和注册关系
-> 如果失败:
cleanup_symmetric_heap()
free_heap_memory(heap_base_)register_heap_memory() 的输入是整段 [heap_base_, heap_base_ + heap_size_)。因此 static heap 初始化成功后,后续 nvshmem_malloc() 只需要从已经准备好的 mspace 中切分对象,不需要为每次普通分配重新注册整段 heap。
下面两节分别说明两种 static heap 在 P2P transport 和 remote transport 下的具体差异。
4.5.1.1 VIDMEM static pinned
VIDMEM static pinned 的底层内存来自 cudaMalloc()。在 setup_symmetric_heap() 阶段,整段 device heap 会同时准备 P2P 映射信息和 remote transport mem handle。
P2P transport 路径
对具备 NVSHMEM_TRANSPORT_CAP_MAP 的 peer,VIDMEM static pinned 走 CUDA IPC。PCIe P2P 场景下常见的 CUDA IPC 共享 handle 导出、交换和打开远端内存,主要就在 map_heap_memory()、export_memory()、import_memory() 这条链路里完成。具体流程如下:

remote transport 路径
对于不走 MAP 的 remote transport,VIDMEM static pinned 会把整段 device heap 按 NVSHMEMI_MAX_HANDLE_LENGTH 限制切成一个或多个注册 chunk。每个 chunk 走如下流程:

remote_handles_ 保存所有 PE 针对各 remote transport 的 mem handle;update_heap_handle_cache() 建立 heap 地址范围到 remote_handles_ 下标的索引。后续 host RMA 或 transport 注册 buffer 查询可以通过 symmetric address 找到对应 remote handle。
4.5.1.2 SYSMEM static shm
SYSMEM static shm 的底层内存是节点内 Linux shared memory slab。reserve_heap() 阶段已经完成 shm mmap、first touch、cudaHostRegister() 和 cudaHostGetDevicePointer(),并把每个本地 PE 的 heap 设为共享 slab 中的一个 slice:
text
heap_base_ = global_heap_base_ + mype_node * heap_size_P2P transport 路径
SYSMEM static shm 仍然复用 static heap 的 register_heap_memory() 框架,但具体导出、handle 交换和 peer 地址填表动作不同,具体流程如下:

这里不需要 CUDA IPC handle,也不需要 cudaIpcOpenMemHandle()。原因是节点内共享内存 slab 已经在 reserve_heap() 阶段映射到本进程,并通过 cudaHostRegister() 获得 device 可见地址;P2P 表里只需要填入 peer 对应 slice 的 device pointer。
remote transport 路径
SYSMEM static shm 的 remote 注册仍然通过 register_heap_chunk_by_size(),但 register_heap_memory_handle() 有一个 rail optimization 分支:
text
rail optimization 关闭:
-> transport->host_ops.get_mem_handle(buf_start, registration_size)
-> allgather remote handles
-> remotetran.gather_mem_handles(heap_offset, registration_size)
-> update_heap_handle_cache(buf_start, registration_size)
rail optimization 开启:
-> 第一次注册:
transport->host_ops.get_mem_handle(global_heap_base_,
heap_size_ * npes_node)
allgather remote handles
remotetran.gather_mem_handles(0, heap_size_ * npes_node)
gather_mem_handles_done_ = true
update_heap_handle_cache(global heap range)
-> 后续注册:
复用 remote_handles_.front() 中已经缓存的 handle因此,SYSMEM static shm 在 remote transport 下既可以按普通 chunk 注册当前 PE slice,也可以在 rail optimization 场景下注册节点内共享 slab 大段,减少重复注册和重复向 device transport 发布 handle 的成本。
4.5.2 Dynamic VMM
P2P transport 路径
Dynamic VMM 的 setup_symmetric_heap() 在 allgather_peer_base() 之后只设置 peer VA window,不注册尚未分配物理内存的 VA 范围:
text
setup_symmetric_heap()
-> 为 P2P peer 设置 peer_heap_base_p2p[i] 的 VA window
-> 创建 proc_mapremote transport 路径
Dynamic VMM 的 remote transport 注册也在 register_heap_memory() 里完成,但粒度是新提交的物理内存 chunk,而不是初始化时的完整 heap。具体流程如下:

因此 dynamic heap 可以按需提交物理内存,同时保持 symmetric heap 的虚拟地址模型。NVLink / MNNVL fabric 场景下,dynamic VMM 的 P2P shareable handle 导出和导入发生在 cuMemExportToShareableHandle() 与 cuMemImportFromShareableHandle() 路径中;remote transport 则并行维护自己的 remote_handles_ / remote_mmap_handles_ 和 transport device state。
4.6 device state
Heap setup 完成后,nvshmemi_common_init() 调用 nvshmemi_init_device_state(),把 heap 信息写入 host 侧 nvshmemi_device_state,并创建 device 端数组:
text
heap_base_array_dptr <- heap_obj->get_local_pe_base()
heap_base_actual_array_dptr <- heap_obj->get_remote_pe_base()
nvshmemi_device_state.peer_heap_base_p2p = heap_base_array_dptr
nvshmemi_device_state.peer_heap_base_remote = heap_base_actual_array_dptr
nvshmemi_device_state.heap_base = heap_obj->get_base()
nvshmemi_device_state.heap_size = heap_obj->get_size()peer_heap_base_remote 是 remote transport / IBGDA device 侧按 offset 计算远端地址的基础:
text
remote_addr = peer_heap_base_remote[pe] + (local_ptr - heap_base)需要区分 common device state 和 transport-specific device state:peer_heap_base_remote、heap_base、heap_size 等属于 common device state;remote mem handle、rkey/lkey、QP 等属于具体 transport 的 device state。remotetran.gather_mem_handles() 在 heap setup 或 dynamic 扩容阶段会调用 transport->host_ops.add_device_remote_mem_handles(),把 remote handles 加入 transport 的 device-visible 状态。随后 nvshmemi_update_device_state() 会把 common device state 拷贝到已注册的 device state symbol;如果选中了 IBGDA,还会同步 nvshmemi_ibgda_device_state。最后 nvshmemi_device_state.nvshmemi_is_nvshmem_initialized 被置为 1,表示 common init 已完成。
5. 内存分配与释放
本节从两个 public API 入口理解 symmetric heap 的运行时行为:
nvshmem_malloc():collective 分配 symmetric object。nvshmem_free():collective 释放 symmetric object。
nvshmem_calloc() 和 nvshmem_align() 与 nvshmem_malloc() 使用同一套框架,只是分别进入 heap_calloc() / heap_align(),最终走 mspace::allocate_zeroed() 或 mspace::allocate_aligned()。
5.1 nvshmem_malloc() 分配流程
nvshmem_malloc(size) 分配流程里有四个关键点。
第一,nvshmemi_check_state_and_init() 支持懒初始化。如果已经 bootstrap 但尚未 full init,会在这里触发 nvshmemi_common_init(),确保 heap、transport、device state 都已经准备好。
第二,heap_malloc() 是 symmetric heap 抽象层入口。默认情况下它进入 heap_allocate(size, 0, 0, NVSHMEMX_MALLOC);如果开启 ENABLE_ALIGNED_MALLOC,则使用 mem_granularity_ 作为 alignment 进入 NVSHMEMX_ALIGN 路径。heap_allocate() 会先调用 is_symmetric(size),在开启 error check 时通过 bootstrap allgather 检查所有 PE 的 size 是否一致。
第三,三类 heap 在普通 malloc 路径上的主调用链是一致的。通过 allocate_symmetric_memory 调用 allocate_virtual_memory_from_mspace。
allocate_virtual_memory_from_mspace() 根据分配类型调用不同的 mspace 接口:
text
NVSHMEMX_MALLOC -> heap_mspace_->allocate(size)
NVSHMEMX_CALLOC -> heap_mspace_->allocate_zeroed(count, size)
NVSHMEMX_ALIGN -> heap_mspace_->allocate_aligned(alignment, size)对于 nvshmem_malloc() 的默认路径,heap_mspace_->allocate(size) 调用的是 mspace::allocate(size_t bytes)。这个函数不会直接向 CUDA 或 OS 申请物理内存,而是在 mspace map 已经管理的 range 中查找可用 chunk。
这里可以把"mspace map"理解为 mspace 内部的三个 allocator metadata map:
free_chunks_start:以 free chunk 起始地址为 key。free_chunks_end:以 free chunk 结束地址为 key,用于释放时和前一个 chunk 合并。inuse_chunks:记录已经分配出去的 block。
三种 heap 的 allocate_symmetric_memory() 差异如下:
- VIDMEM static pinned :
reserve_heap()阶段已经通过cudaMalloc()分配完整 GPU device heap,并在setup_symmetric_heap()注册整段 heap。运行时allocate_symmetric_memory()只调用allocate_virtual_memory_from_mspace();如果 mspace 返回NULL,通常说明当前 static heap 剩余空间不足,需要增大NVSHMEM_SYMMETRIC_SIZE或减少分配量。 - SYSMEM static shm :
reserve_heap()阶段已经创建节点内 shared memory slab,完成 mmap、cudaHostRegister()和cudaHostGetDevicePointer(),并把当前 PE slice 加入heap_mspace_。运行时allocate_symmetric_memory()同样只调用allocate_virtual_memory_from_mspace()。 - VIDMEM dynamic VMM :
reserve_heap()阶段只cuMemAddressReserve()预留 VA,heap_mspace_初始没有可分配 chunk。运行时allocate_symmetric_memory()先调用allocate_virtual_memory_from_mspace();若返回NULL且 size 大于 0,则调用allocate_physical_memory_to_heap(size + alignment)分配物理内存,具体流程后面介绍。
第四,分配成功后才会执行 nvshmemi_barrier_all()。如果 size 为 0 或最终 ptr 为 NULL,会直接返回,不进入 barrier。这个 barrier 的作用是:
- 保证所有 PE 都完成本次 collective allocation。
- 保证所有 PE 的 heap allocator 状态以一致顺序推进。
- 保证后续对同一 symmetric object 的通信不会发生在其他 PE 尚未完成分配之前。
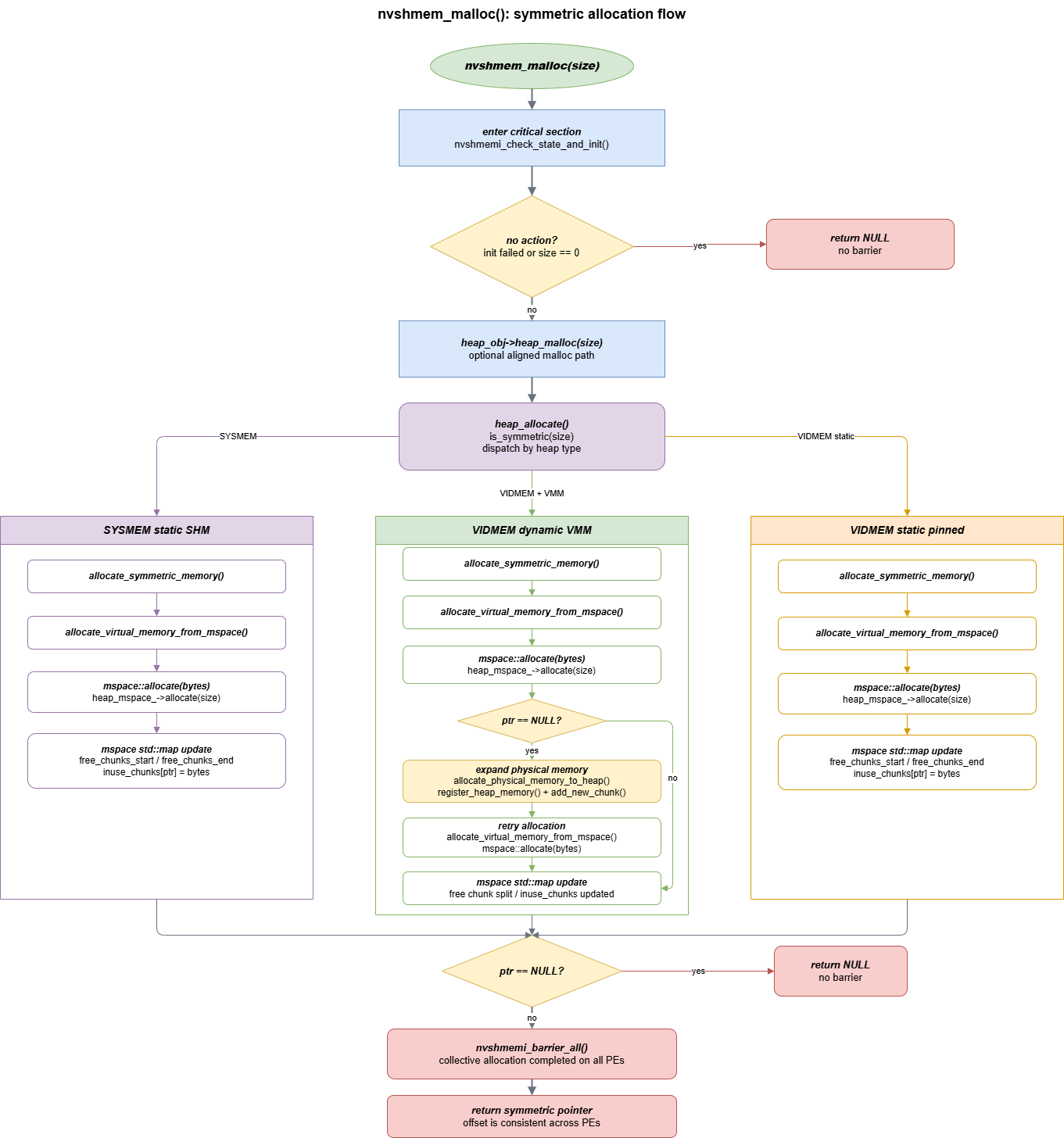
对于 VIDMEM dynamic VMM 类型的 heap,当物理内存不够时,会动态扩展,具体流程如下:
allocate_physical_memory_to_heap(size + alignment),执行cuMemCreate()、cuMemMap()、cuMemSetAccess()分配物理内存。- 通过
register_heap_memory()注册新 chunk 的 P2P 和 remote mem handle。register_heap_memory()会把新 chunk 通过heap_mspace_->add_new_chunk()加入 mspace,然后再次调用。 allocate_virtual_memory_from_mspace()重新分配,成功后再nvshmemi_update_device_state()。

NVSHMEM symmetric allocation 要求所有 PE 以相同顺序参与分配,并使用兼容参数。后续通信 API 才能只传递本地 symmetric pointer 和目标 PE,就计算出远端对应地址。
5.2 nvshmem_free() 释放流程
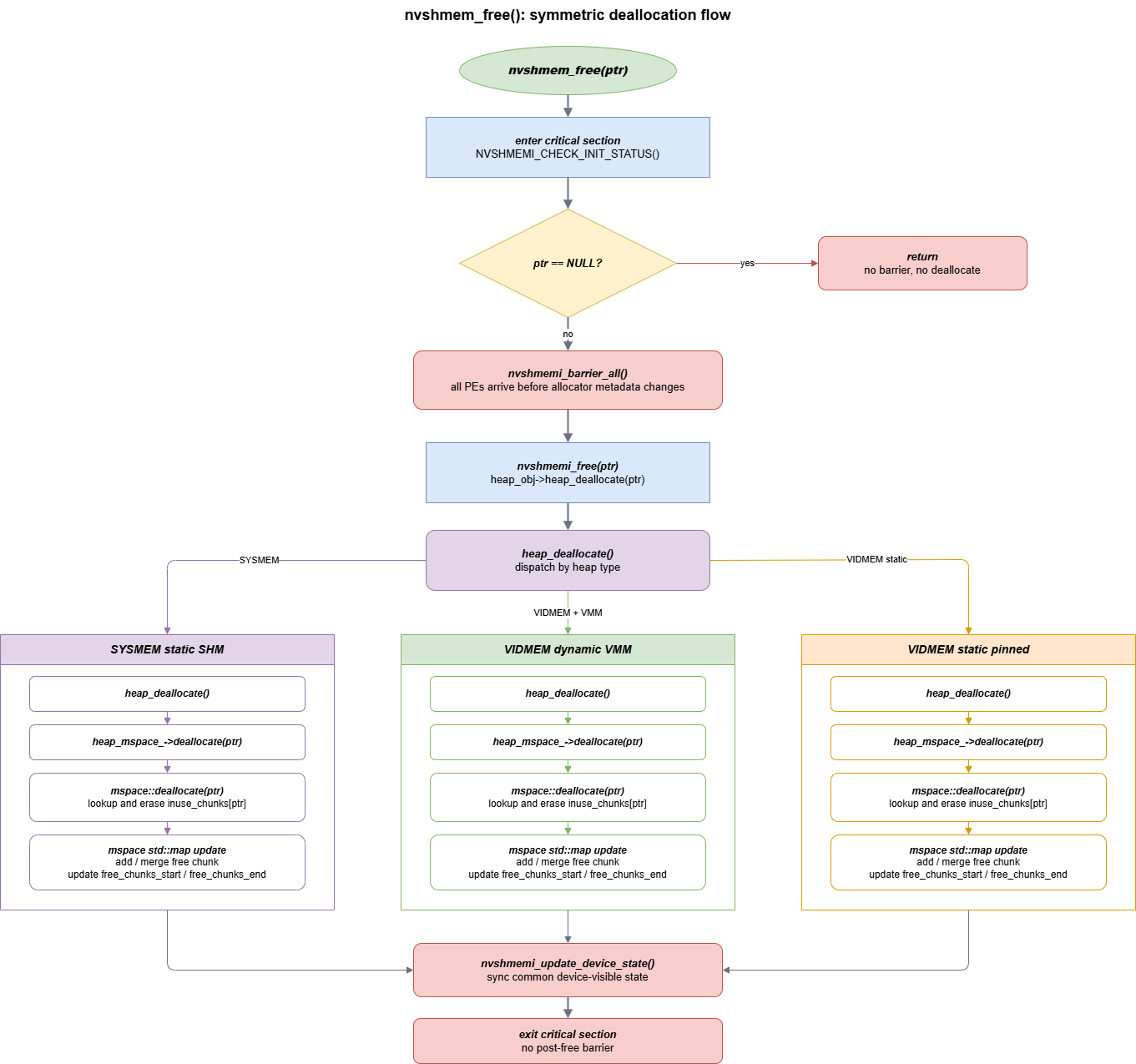
nvshmem_free(ptr) 释放流程里有四个关键点。
第一,nvshmem_free(ptr) 进入 critical section 后先检查 init 状态。如果 ptr == NULL,直接返回,不进入 nvshmemi_barrier_all(),也不会修改 mspace metadata。
第二,释放流程里最重要的是 barrier 的位置:nvshmemi_barrier_all() 在真正回收 mspace block 之前执行。barrier 保证所有 PE 在释放前都到达同一个 collective free 点,避免某个 PE 仍在使用 symmetric object,而另一个 PE 已经回收 allocator metadata。
释放后没有显式 barrier,因此调用者应遵守 NVSHMEM collective allocation/free 的配对约束,不能让不同 PE 以不同顺序交错分配和释放。
第三,三类 heap 在普通 free 路径上的主调用链是一致的。通过 heap_deallocate 调用 deallocate。mspace::deallocate(ptr) 不释放底层 CUDA / OS / transport backing,而是更新 mspace map。
- 通过
free_chunks_end判断前一个 chunk 是否空闲。 - 通过
free_chunks_start判断后一个 chunk 是否空闲。 - 最终更新
free_chunks_start/free_chunks_end,使这段地址重新可被后续mspace::allocate()使用。
第四,三种 heap 的释放路径在函数调用上基本一致,差异主要是底层的内存分配方式:
- VIDMEM static pinned :只把 block 还给
heap_mspace_。 - SYSMEM static shm :只把当前 PE slice 中的 block 还给
heap_mspace_。 - VIDMEM dynamic VMM :普通 free 也只回收 mspace metadata。已经
cuMemCreate()/cuMemMap()的物理 chunk、P2P VMM mapping 和 remote mem handle 会继续保留并可被后续分配复用,不是每次nvshmem_free()都立即cuMemUnmap()。
因此,nvshmem_free() 的语义是 collective 地回收 symmetric heap allocator metadata,而不是释放 register_heap_memory 注册的 heap 内存以及 Memory handle。
6. Symmetric Heap 与通信路径的关系
6.1 heap_base
初始化完成后,device 端主要依赖三类地址:
text
heap_base
当前 PE symmetric heap 起点
peer_heap_base_p2p[pe]
如果非 NULL,说明该 peer heap 已映射到当前 PE,可直接 GPU load/store
peer_heap_base_remote[pe]
remote transport 用的 peer heap base,用于计算远端 RMA 地址这些地址由 host 初始化流程填充,并通过 nvshmemi_init_device_state() / nvshmemi_update_device_state() 同步给 device。
6.2 如何定位远端地址
无论 P2P 还是 remote transport,基本地址模型都是 offset 模型:
text
offset = local_symmetric_ptr - heap_base
remote_ptr = peer_heap_base + offsetP2P 路径使用 peer_heap_base_p2p[pe]。Remote/IBGDA 路径使用 peer_heap_base_remote[pe] 或 transport 内部缓存的 remote base/rkey 信息。
6.3 如何选择 transport
Device 端 put/get 通常先检查 peer_heap_base_p2p[pe]:
text
if peer_heap_base_p2p[pe] != NULL:
直接 memcpy/load/store
else:
进入 nvshmemi_transfer_rma*
根据 selected_device_transport 选择 proxy / IBGDA因此,Device在通信的时候优先使用 P2P transport,若无法使用,则会选择 Remote transport。
6.4 IBGDA 场景
IBGDA device 代码需要:
- 本地 buffer 的 lkey。
- 远端 symmetric heap 地址对应的 rkey。
- 远端 base 与 offset 计算出的 RDMA address。
这些 key 信息来自 host 初始化或 dynamic VMM 扩容时注册的 mem handle。对于 static heap,整段 heap 初始化时就注册。对于 dynamic VMM,物理 chunk 扩容时注册并更新 IBGDA device state。
因此,IBGDA 能从 GPU 直接发起 RDMA 并不是单靠 device 代码完成的;它依赖 host 初始化阶段把 heap、QP、DCT、lkey/rkey 等元数据全部准备并发布到 device 可访问状态。
7. 总结
7.1 内存管理设计要点
NVSHMEM 内存管理的核心是 symmetric heap offset 一致性。每个 PE 的实际 heap base 可以不同,但通过 collective allocation 保证对象 offset 一致,从而让通信 API 可以用本地 pointer 表示远端对象。
7.2 三种 symmetric heap 的适用场景
- VIDMEM static pinned:适合简单、稳定、初始化时可接受完整显存预留的场景。
- SYSMEM static SHM:适合需要系统内存 heap、节点内共享内存或 rail optimization 的场景。
- VIDMEM dynamic VMM:适合需要大虚拟地址空间、按需物理内存提交和更灵活 P2P VA 管理的场景。
8. 参考资料
- NVIDIA OpenSHMEM Library (NVSHMEM) Documentation: https://docs.nvidia.com/nvshmem/api/
- NVSHMEM Memory Management APIs: https://docs.nvidia.com/nvshmem/api/gen/api/memory.html
- CUDA Driver API, Virtual Memory Management: https://docs.nvidia.com/cuda/cuda-driver-api/group__CUDA__VA.html
- CUDA Runtime API, Memory Management: https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__MEMORY.html