三、Transformer之注意力机制(attentoin)
- 前言
-
- 一、注意力机制的数学公式
- 二、代码逐段详解
-
- [1. `d_k = query.size(-1)`](#1.
d_k = query.size(-1)) - [2. 计算相似度分数 `scores`](#2. 计算相似度分数
scores) - [3、 掩码处理](#3、 掩码处理)
- [4、Softmax 归一化](#4、Softmax 归一化)
- [5、 Dropout 正则化](#5、 Dropout 正则化)
- 6、加权求和与输出
- [1. `d_k = query.size(-1)`](#1.
- [三、 为什么这样设计?------ 公式与代码的对应](#三、 为什么这样设计?—— 公式与代码的对应)
- [4. 扩展思考](#4. 扩展思考)
- [5. 总结](#5. 总结)
- 总结
前言
Transformer 架构彻底改变了自然语言处理领域,而其中的核心组件就是注意力机制(Attention) 。本文将围绕一段经典的 attention 函数代码,逐行分析其实现细节,并和数学公式进行对照,帮助读者彻底理解缩放点积注意力(Scaled Dot-Product Attention)的工作原理。
在Transformer中 中attention函数实现注意力计算的核心部分。计算query和key之间的点积(矩阵相乘), 并根据该相似度对value进行加加权求和
一、注意力机制的数学公式
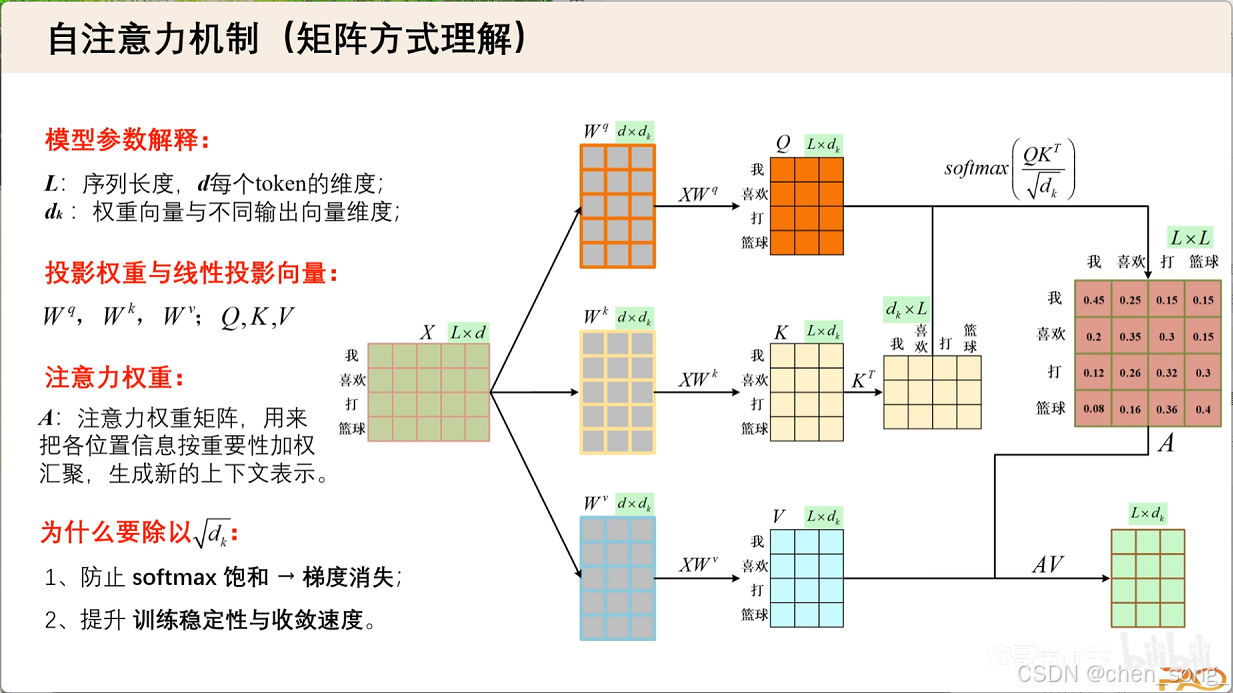
论文《Attention Is All You Need》中给出的缩放点积注意力公式如下:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V {\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V} Attention(Q,K,V)=softmax(dk QKT)V
其中:
- Q {Q} Q:Query 矩阵,形状通常为
(batch_size, num_heads, seq_len, d_k) - K { K} K:Key 矩阵,形状同 Q
- V { V } V:Value 矩阵,形状同 Q
- d k {d_k } dk:Key 向量的维度,用于缩放点积,防止点积过大导致 softmax 梯度消失
这个公式可以拆解为以下步骤:
- 计算 Query 和 Key 的点积相似度: scores = Q K T { \text{scores} = QK^T } scores=QKT
- 缩放: scores = Q K T d k { \text{scores} = \frac{QK^T}{\sqrt{d_k}} } scores=dk QKT
- (可选)施加掩码:将特定位置的分数替换为一个非常大的负数
- 用 softmax 转换为概率分布: attn = softmax ( scores ) { \text{attn} = \text{softmax}(\text{scores}) } attn=softmax(scores)
- (可选)应用 Dropout
- 用注意力权重对 Value 加权求和: output = attn ⋅ V { \text{output} = \text{attn} \cdot V } output=attn⋅V
接下来,我们就用一段 Python 代码把上述过程完整实现。
二、代码逐段详解
python
def attention(query, key, value, mask=None, dropout=None):
# 将query矩阵的最后一个维度值作为d_k
d_k = query.size(-1)
# 将key的最后两个维度互换(转置),才能与query矩阵相乘,乘完了还要除以d_k开根号
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)1. d_k = query.size(-1)
query 的 shape 一般是 (..., seq_len, d_k),即最后一个维度代表每个 token 的特征维度。这里用 query.size(-1) 取得 d_k,方便后续的缩放操作。该维度也被称为 d_model // num_heads(多头注意力中每个头的维度)。
2. 计算相似度分数 scores
key.transpose(-2, -1)将 Key 的最后两个维度进行转置 。假设 Key 形状为(..., seq_len, d_k),转置后变为(..., d_k, seq_len)。torch.matmul(query, key.transpose(-2, -1))完成了 ( QK^T ) 矩阵乘法,得到形状(..., seq_len, seq_len)的注意力分数矩阵。- 之后除以 d k { \sqrt{d_k} } dk 进行缩放 ,这就是"缩放点积"的由来。当 d k { d_k } dk较大时,点积的结果方差会增大,导致 softmax 后梯度很小,缩放可以有效缓解该问题。
python
# 如果存在要进行mask的内容,则将那些为0的部分替换成一个很大的负数
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)3、 掩码处理
mask是一个与scores广播后形状兼容的张量,其中值为 1 的位置表示"保留",值为 0 的位置表示"遮蔽"。mask == 0会生成一个布尔掩码,指出哪些位置的分数需要被遮掩。scores.masked_fill(mask == 0, -1e9)将这些位置的分数替换为-1e9(非常小的负数)。经过 softmax 之后,这些位置的注意力权重会趋近于 0,从而达到"看不见"的效果。
掩码的常见类型:
- Padding mask :处理批次中不等长序列时,为填充的
<pad>位置生成掩码,防止模型注意到无意义的填充部分。Encoder 和 Decoder 中都会使用。 - Sequence mask(因果掩码) :在 Decoder 的自注意力中,为了防止当前位置看到未来信息,构造一个上三角全为 0 的矩阵。例如,
t时刻只能注意1,2,...,t时刻的信息。
python
# 将mask后的attention矩阵按照最后一个维度进行softmax
p_attn = F.softmax(scores, dim=-1)4、Softmax 归一化
对 scores 的最后一个维度 (即针对每一行,所有位置的分数)进行 softmax,得到概率分布 p_attn。此时每一行的所有元素之和为 1,代表当前 Query token 对所有 Key token 的注意力权重。
python
# 如果dropout参数设置为非空,则进行dropout操作
if dropout is not None:
p_attn = dropout(p_attn)5、 Dropout 正则化
训练时,以一定的概率随机将注意力权重中的部分元素置零,防止过拟合。dropout 是 PyTorch 的 nn.Dropout 实例。注意,它只会在 model.train() 模式下生效。
python
# 最后返回注意力矩阵跟value的乘积,以及注意力矩阵
return torch.matmul(p_attn, value), p_attn6、加权求和与输出
torch.matmul(p_attn, value)完成了注意力权重与 Value 矩阵的加权求和:每个 token 的输出是所有 Value 向量的加权组合。- 函数返回两个值:
- 加权后的输出 :形状与输入 Query 相同(
..., seq_len, d_k)。 - 注意力权重矩阵:可用于可视化或分析模型注意力的分布。
- 加权后的输出 :形状与输入 Query 相同(
三、 为什么这样设计?------ 公式与代码的对应
| 步骤 | 公式 / 概念 | 代码实现 |
|---|---|---|
| 1. 获取维度 | d k {d_k } dk | d_k = query.size(-1) |
| 2. 点积 + 缩放 | Q K T d k {\frac{QK^T}{\sqrt{d_k}} } dk QKT | torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k) |
| 3. 掩码 | 把非法位置的分数设为极小值 | scores.masked_fill(mask == 0, -1e9) |
| 4. Softmax | softmax ( ⋅ ) { \text{softmax}(\cdot) } softmax(⋅) | F.softmax(scores, dim=-1) |
| 5. Dropout | 随机丢弃部分注意力权重 | dropout(p_attn) |
| 6. 输出 | attn ⋅ V { \text{attn} \cdot V } attn⋅V | torch.matmul(p_attn, value) |
这种设计将公式完美地映射成了简洁的 PyTorch 操作,并且在多头注意力机制中,可以对每个头独立调用此函数,之后再将各头结果拼接起来。
4. 扩展思考
- Mask 的灵活性:同一个函数既能用于 Encoder 自注意力(只使用 padding mask),也能用于 Decoder 自注意力(padding mask + sequence mask)以及交叉注意力(Encoder-Decoder Attention)。代码简洁而强大。
- 数值稳定性:通过减去极大值再 softmax,避免了直接对 0 位置计算指数导致的小概率问题,实际工程中非常常用。
- 可解释性 :返回的注意力矩阵
p_attn可以直接热力图展示,帮助理解模型在不同层、不同头中关注了哪些上下文。
5. 总结
本文我们从 Transformer 的核心公式出发,结合一段精简而经典的 attention 函数实现,逐行解析了缩放点积注意力的内在逻辑。理解这段代码,就等同于抓住了 Transformer 和现代大语言模型的基石。无论是初学者还是进阶研究者,反复研读这一实现都能不断加深对注意力机制本质的认知。
希望这篇博客能够帮助你彻底吃透注意力机制的代码与公式。如果你想继续深入,不妨试试手动实现多头注意力,并与 PyTorch 的 nn.MultiheadAttention 进行对比验证。
总结
Transformer原理分析:https://chensongpoixs.github.io/artificial_intelligence/Transfomer