目录
[1. 引言](#1. 引言)
[2. ADC硬件架构与核心机制](#2. ADC硬件架构与核心机制)
[2.1 逐次逼近型ADC的转换原理](#2.1 逐次逼近型ADC的转换原理)
[2.2 输入通道与引脚映射](#2.2 输入通道与引脚映射)
[2.3 规则组与注入组的双重转换架构](#2.3 规则组与注入组的双重转换架构)
[2.4 转换模式与扫描序列](#2.4 转换模式与扫描序列)
[2.5 DMA在多通道扫描中的必要性](#2.5 DMA在多通道扫描中的必要性)
[3. 时钟配置与采样率计算](#3. 时钟配置与采样率计算)
[3.1 ADC时钟约束](#3.1 ADC时钟约束)
[3.2 采样时间配置](#3.2 采样时间配置)
[3.3 转换时间与最大采样率](#3.3 转换时间与最大采样率)
[4. 定时器硬件触发:实现确定性采样](#4. 定时器硬件触发:实现确定性采样)
[4.1 软件触发与硬件触发的对比](#4.1 软件触发与硬件触发的对比)
[4.2 定时器触发配置路径](#4.2 定时器触发配置路径)
[5. 工程实现:标准外设库版本(双通道DMA循环采集)](#5. 工程实现:标准外设库版本(双通道DMA循环采集))
[5.1 宏定义与全局变量](#5.1 宏定义与全局变量)
[5.2 GPIO初始化(模拟输入模式)](#5.2 GPIO初始化(模拟输入模式))
[5.4 ADC配置(规则组扫描+连续转换)](#5.4 ADC配置(规则组扫描+连续转换))
[5.5 DMA中断服务函数(半完成与完成双缓冲处理)](#5.5 DMA中断服务函数(半完成与完成双缓冲处理))
[5.6 主程序:滑动平均滤波与电压换算](#5.6 主程序:滑动平均滤波与电压换算)
[6. HAL库实现要点](#6. HAL库实现要点)
[6.1 CubeMX关键配置项](#6.1 CubeMX关键配置项)
[6.2 用户代码补充(手动开启空闲中断及回调)](#6.2 用户代码补充(手动开启空闲中断及回调))
[7. 数据后处理与滤波算法](#7. 数据后处理与滤波算法)
[7.1 电压精确换算](#7.1 电压精确换算)
[7.2 常用数字滤波算法性能对比](#7.2 常用数字滤波算法性能对比)
[8. 工程故障模式分析与对策](#8. 工程故障模式分析与对策)
[8.1 DMA数据类型不匹配](#8.1 DMA数据类型不匹配)
[8.2 多通道数据错位](#8.2 多通道数据错位)
[8.3 ADC时钟超限](#8.3 ADC时钟超限)
[8.4 数据过载与缓冲区溢出](#8.4 数据过载与缓冲区溢出)
[8.5 规则组DR寄存器覆盖(未使用DMA)](#8.5 规则组DR寄存器覆盖(未使用DMA))
[9. 性能评估与方案选型](#9. 性能评估与方案选型)
[9.1 实测性能数据(72MHz系统时钟,ADCCLK=12MHz,采样时间71.5周期)](#9.1 实测性能数据(72MHz系统时钟,ADCCLK=12MHz,采样时间71.5周期))
[9.2 采集方案选型矩阵](#9.2 采集方案选型矩阵)
[10. 总结与设计建议](#10. 总结与设计建议)
摘要
针对STM32F103系列微控制器,系统论述基于直接存储器访问(DMA)的模数转换器(ADC)数据采集架构。内容涵盖逐次逼近型ADC的工作原理、规则组与注入组的双轨转换机制、时钟与采样时间的约束条件以及多通道扫描模式下的数据流管理策略。提供基于标准外设库与HAL库的双版本完整工程实现,深入讨论定时器硬件触发采样、数字滤波算法、电压精确换算以及数据错位、过载丢失等常见工程故障的根因与解决方案。本文旨在为高精度、多通道、低CPU负载的工业级模拟信号采集系统提供设计参考。
1. 引言
在嵌入式数据采集系统中,ADC是连接模拟前端与数字处理单元的关键接口。STM32F103内置的12位逐次逼近型ADC配合DMA控制器,可在几乎不占用CPU资源的前提下,完成多通道模拟信号的高速连续采集。然而,多通道扫描场景下数据寄存器的"易失性"使得DMA不再是优化选项,而成为工程上的必需手段。本文从底层硬件机制出发,系统阐述STM32F103 ADC与DMA的协同工作原理,提供可工程化的代码实现与调优策略。
2. ADC硬件架构与核心机制
2.1 逐次逼近型ADC的转换原理
STM32F103内部的ADC模块基于逐次逼近寄存器(SAR)架构。其转换过程采用二分搜索算法:在12个转换周期内,逐位比较输入电压与内部数模转换器(DAC)输出的参考电压,最终输出12位数字结果。该架构在转换精度(±2 LSB典型值)与转换速度(1 μs @ 14 MHz)之间取得了良好的平衡。
2.2 输入通道与引脚映射
STM32F103大容量产品(如ZET6)集成了三个独立的ADC模块(ADC1/2/3),提供最多18个采集通道:
-
16个外部模拟输入通道(ADCx_IN0 ~ ADCx_IN15)
-
2个内部信号通道:内部温度传感器(VTSVTS)与内部参考电压(VREFINTVREFINT,典型值1.20 V)
不同ADC的相同通道编号可能共享同一GPIO引脚,例如:
-
ADC1/2/3的通道0~7分别对应PA0~PA7
-
通道8~9对应PB0~PB1
-
通道10~15对应PC0~PC5
设计约束:仅ADC1和ADC3具备直接DMA请求输出能力;ADC2的转换结果需通过ADC1在双ADC模式下经由DMA传输。
2.3 规则组与注入组的双重转换架构
STM32的ADC模块实现了可编程的转换序列管理,包含两个独立的数据组:
-
规则组(Regular Group) :用于常规顺序转换,最多可配置16个通道。所有规则通道的转换结果共享同一个16位数据寄存器
ADC_DR。后续通道的转换结果会无条件覆盖前一次结果。规则组的总通道数由ADC_SQR1寄存器的L[3:0]位域定义(0表示1个通道,15表示16个通道)。 -
注入组(Injected Group) :用于高优先级插队转换,最多可配置4个通道。注入组拥有4个独立的数据寄存器
ADC_JDRx,结果不会被覆盖。注入组转换可以中断正在进行的规则组转换,待其完成后再恢复规则组序列。
对于绝大多数DMA批量采集需求,规则组是核心载体。注入组适用于过压/过流告警等需要即时响应的采样任务。
2.4 转换模式与扫描序列
| 模式 | 描述 | 适用场景 |
|---|---|---|
| 单次转换模式 | 执行一次转换后停止 | 按需单点采样 |
| 连续转换模式 | 转换完成后自动重启新一轮转换 | 配合DMA循环模式实现不间断采集 |
| 扫描模式 | 依次转换规则组中配置的所有通道 | 多通道采集(必须与DMA配合) |
| 间断模式 | 每触发一次转换序列中的一个子组 | 低功耗、间歇性采样 |
关键点 :当启用扫描模式时,EOC标志仅在整组通道全部转换完成后置位。若未使用DMA,CPU必须在极短窗口内(约2 μs)依次读取每个通道的结果,这在多任务系统中极易失败。DMA通过硬件搬运彻底解决了此问题。
2.5 DMA在多通道扫描中的必要性
以双通道扫描(通道4 → 通道5)为例,时序分析如下:
-
通道4转换完成 → 结果写入
ADC_DR,但EOC尚未置位。 -
通道5转换完成 → 结果再次写入
ADC_DR(覆盖通道4的数据),EOC置位。
若CPU在EOC中断中读取ADC_DR,只能获得最后一个通道的值,通道4的数据永久丢失。DMA在每次EOC(实际为每个通道转换完成时产生的DMA请求信号)发生时,自动将ADC_DR内容搬运到内存缓冲区,并按地址递增顺序存放,从而完美保留所有通道数据。
3. 时钟配置与采样率计算
3.1 ADC时钟约束
ADC输入时钟ADCCLK由APB2总线时钟PCLK2经预分频器产生。根据数据手册,ADCCLK不得超过14 MHz,否则将导致转换精度下降或逻辑错误。
在典型系统主频72 MHz下,PCLK2 = 72 MHz。可用的分频配置:
-
RCC_PCLK2_Div6→ADCCLK = 12 MHz(推荐) -
RCC_PCLK2_Div8→ADCCLK = 9 MHz
错误配置(如Div2 → 36 MHz)会使ADC完全无法正常工作。
3.2 采样时间配置
每个ADC通道可独立配置采样时间,决定了采样保持电容器充电的时间长度。可选值及对应典型用途:
| 采样周期(TADCCLK) | 最小等效采样时间 @12MHz | 适用信号源内阻 |
|---|---|---|
| 1.5 | 125 ns | 运放输出(内阻<1 kΩ) |
| 7.5 | 625 ns | 一般信号源(<10 kΩ) |
| 13.5 | 1.125 μs | 中等内阻(<50 kΩ) |
| 28.5 | 2.375 μs | 较高内阻(<100 kΩ) |
| 41.5 | 3.458 μs | 传感器输出(<200 kΩ) |
| 55.5 | 4.625 μs | --- |
| 71.5 | 5.958 μs | 高内阻(<500 kΩ) |
| 239.5 | 19.958 μs | 极高内阻(>1 MΩ) |

3.3 转换时间与最大采样率
单次转换总时间公式:
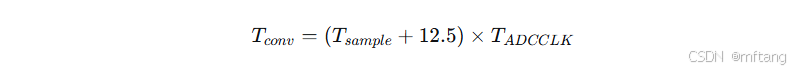
其中12.5个周期为ADC内核逐次逼近的固定开销。
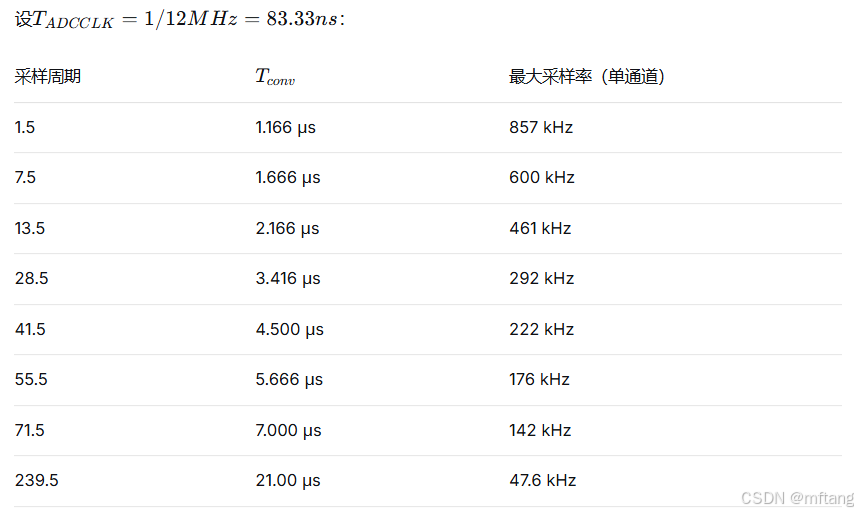
多通道扫描时,等效每通道采样率 = 单通道采样率 / 通道数。
4. 定时器硬件触发:实现确定性采样
4.1 软件触发与硬件触发的对比
| 特性 | 软件触发(ADC_SoftwareStartConv) |
硬件触发(定时器/外部中断) |
|---|---|---|
| 触发延迟 | 不确定(受中断、流水线影响) | 固定(3个APB2时钟周期,约83 ns) |
| 抖动 | ±几十微秒 | <1个定时器时钟周期 |
| CPU干预 | 每次触发需要 | 完全无需 |
| 适用场景 | 低速、非实时采样 | 周期信号采样(音频、振动、电机控制) |
在需要严格等间隔采样(如FFT分析)的应用中,硬件触发是唯一可行的方案。
4.2 定时器触发配置路径
以TIM2的更新事件触发ADC1为例:
-
TIM2工作于APB1总线(36 MHz),配置为周期计数模式。
-
通过
ADC_ExternalTrigConv_T2_TRGO选择TIM2的TRGO输出作为触发源。 -
ADC的
EXTSEL[2:0]寄存器位选择具体触发源。
该连接为芯片内部硬连线,无需外部引脚。
5. 工程实现:标准外设库版本(双通道DMA循环采集)
以下代码实现ADC1扫描通道4(PA4)与通道5(PA5),DMA循环模式自动搬运,并采用滑动平均滤波提高数据稳定性。
5.1 宏定义与全局变量
cpp
#include "stm32f10x.h"
#include <string.h>
#include <stdio.h>
#include <stdbool.h>
#define ADC_CH_NUM 2 // 扫描通道数
#define ADC_BUFFER_DEPTH 100 // 每个通道的采样点数(总DMA缓冲区大小 = ADC_CH_NUM * ADC_BUFFER_DEPTH)
#define ADC1_DR_ADDRESS ((uint32_t)0x4001244C)
static __IO uint16_t adc_dma_buffer[ADC_CH_NUM * ADC_BUFFER_DEPTH];
volatile bool dma_half_complete_flag = false;
volatile bool dma_complete_flag = false;5.2 GPIO初始化(模拟输入模式)
cpp
static void ADC_DMA_Init(void) {
DMA_InitTypeDef dma_init;
RCC_AHBPeriphClockCmd(RCC_AHBPeriph_DMA1, ENABLE);
DMA_DeInit(DMA1_Channel1);
dma_init.DMA_PeripheralBaseAddr = ADC1_DR_ADDRESS;
dma_init.DMA_MemoryBaseAddr = (uint32_t)adc_dma_buffer;
dma_init.DMA_DIR = DMA_DIR_PeripheralSRC; // 外设 → 内存
dma_init.DMA_BufferSize = ADC_CH_NUM * ADC_BUFFER_DEPTH;
dma_init.DMA_PeripheralInc = DMA_PeripheralInc_Disable;
dma_init.DMA_MemoryInc = DMA_MemoryInc_Enable;
dma_init.DMA_PeripheralDataSize = DMA_PeripheralDataSize_HalfWord;
dma_init.DMA_MemoryDataSize = DMA_MemoryDataSize_HalfWord;
dma_init.DMA_Mode = DMA_Mode_Circular; // 循环模式,连续采集
dma_init.DMA_Priority = DMA_Priority_High;
dma_init.DMA_M2M = DMA_M2M_Disable;
DMA_Init(DMA1_Channel1, &dma_init);
// 使能传输完成中断与半完成中断(实现双缓冲效果)
DMA_ITConfig(DMA1_Channel1, DMA_IT_TC | DMA_IT_HT, ENABLE);
DMA_Cmd(DMA1_Channel1, ENABLE);
}5.4 ADC配置(规则组扫描+连续转换)
cpp
static void ADC1_Init(void) {
ADC_InitTypeDef adc_init;
RCC_APB2PeriphClockCmd(RCC_APB2Periph_ADC1, ENABLE);
RCC_ADCCLKConfig(RCC_PCLK2_Div6); // ADCCLK = 12 MHz
ADC_DeInit(ADC1);
adc_init.ADC_Mode = ADC_Mode_Independent;
adc_init.ADC_ScanConvMode = ENABLE; // 必须使能扫描模式
adc_init.ADC_ContinuousConvMode = ENABLE; // 连续转换,配合DMA循环
adc_init.ADC_ExternalTrigConv = ADC_ExternalTrigConv_None; // 软件触发
adc_init.ADC_DataAlign = ADC_DataAlign_Right;
adc_init.ADC_NbrOfChannel = ADC_CH_NUM;
ADC_Init(ADC1, &adc_init);
// 配置规则组序列:通道4(第1个),通道5(第2个),采样时间71.5周期
ADC_RegularChannelConfig(ADC1, ADC_Channel_4, 1, ADC_SampleTime_71Cycles5);
ADC_RegularChannelConfig(ADC1, ADC_Channel_5, 2, ADC_SampleTime_71Cycles5);
ADC_DMACmd(ADC1, ENABLE); // 使能DMA请求
// 执行校准
ADC_ResetCalibration(ADC1);
while(ADC_GetResetCalibrationStatus(ADC1));
ADC_StartCalibration(ADC1);
while(ADC_GetCalibrationStatus(ADC1));
ADC_Cmd(ADC1, ENABLE);
ADC_SoftwareStartConvCmd(ADC1, ENABLE); // 启动转换
}5.5 DMA中断服务函数(半完成与完成双缓冲处理)
cpp
void DMA1_Channel1_IRQHandler(void) {
if(DMA_GetITStatus(DMA1_IT_HT1)) {
DMA_ClearITPendingBit(DMA1_IT_HT1);
dma_half_complete_flag = true; // 前半缓冲区(0 ~ BUFFER_SIZE/2 -1)已满
}
if(DMA_GetITStatus(DMA1_IT_TC1)) {
DMA_ClearITPendingBit(DMA1_IT_TC1);
dma_complete_flag = true; // 后半缓冲区(BUFFER_SIZE/2 ~ BUFFER_SIZE-1)已满
}
}5.6 主程序:滑动平均滤波与电压换算
cpp
#define WINDOW_SIZE 8
static uint16_t filter_buf_ch1[WINDOW_SIZE];
static uint16_t filter_buf_ch2[WINDOW_SIZE];
static uint8_t filter_idx = 0;
static uint32_t sum_ch1 = 0, sum_ch2 = 0;
static uint16_t MovingAverageFilter(uint16_t new_sample, uint16_t *buffer, uint32_t *sum) {
*sum -= buffer[filter_idx];
buffer[filter_idx] = new_sample;
*sum += new_sample;
filter_idx = (filter_idx + 1) % WINDOW_SIZE;
return (uint16_t)(*sum / WINDOW_SIZE);
}
int main(void) {
// 系统初始化(时钟、串口等)
USART1_Init(115200);
ADC_GPIO_Init();
ADC_DMA_Init();
ADC1_Init();
uint16_t raw_ch1, raw_ch2;
uint16_t filtered_ch1, filtered_ch2;
float voltage_ch1, voltage_ch2;
while(1) {
if(dma_half_complete_flag) {
dma_half_complete_flag = false;
// 处理前半缓冲区数据(索引 0 ~ ADC_CH_NUM*(ADC_BUFFER_DEPTH/2)-1)
for(uint16_t i = 0; i < ADC_BUFFER_DEPTH / 2; i++) {
raw_ch1 = adc_dma_buffer[i * ADC_CH_NUM];
raw_ch2 = adc_dma_buffer[i * ADC_CH_NUM + 1];
filtered_ch1 = MovingAverageFilter(raw_ch1, filter_buf_ch1, &sum_ch1);
filtered_ch2 = MovingAverageFilter(raw_ch2, filter_buf_ch2, &sum_ch2);
// 此处可存储或发送滤波后数据
}
}
if(dma_complete_flag) {
dma_complete_flag = false;
// 处理后一半缓冲区数据(索引 ADC_CH_NUM*ADC_BUFFER_DEPTH/2 ~ 末尾)
for(uint16_t i = ADC_BUFFER_DEPTH / 2; i < ADC_BUFFER_DEPTH; i++) {
raw_ch1 = adc_dma_buffer[i * ADC_CH_NUM];
raw_ch2 = adc_dma_buffer[i * ADC_CH_NUM + 1];
filtered_ch1 = MovingAverageFilter(raw_ch1, filter_buf_ch1, &sum_ch1);
filtered_ch2 = MovingAverageFilter(raw_ch2, filter_buf_ch2, &sum_ch2);
}
// 电压换算(假设VREF+ = 3.30V)
voltage_ch1 = (float)filtered_ch1 * 3.30f / 4095.0f;
voltage_ch2 = (float)filtered_ch2 * 3.30f / 4095.0f;
printf("CH4=%.2fV, CH5=%.2fV\r\n", voltage_ch1, voltage_ch2);
}
}
}6. HAL库实现要点
6.1 CubeMX关键配置项
-
ADC:Scan Conversion Mode = Enabled;Continuous Conversion Mode = Enabled;Number of Conversion = 2。
-
DMA:Mode = Circular;Increment Address = Memory;Data Width = Half Word。
-
NVIC:使能DMA1_Channel1全局中断。
6.2 用户代码补充(手动开启空闲中断及回调)
cpp
// 在主函数初始化后手动使能ADC的DMA请求(CubeMX默认已使能,但需确认)
HAL_ADC_Start_DMA(&hadc1, (uint32_t*)adc_dma_buffer, ADC_CH_NUM * ADC_BUFFER_DEPTH);
// 重定义DMA半完成与完成回调
void HAL_ADC_ConvHalfCpltCallback(ADC_HandleTypeDef* hadc) {
if(hadc->Instance == ADC1) dma_half_complete_flag = true;
}
void HAL_ADC_ConvCpltCallback(ADC_HandleTypeDef* hadc) {
if(hadc->Instance == ADC1) dma_complete_flag = true;
}7. 数据后处理与滤波算法
7.1 电压精确换算

7.2 常用数字滤波算法性能对比
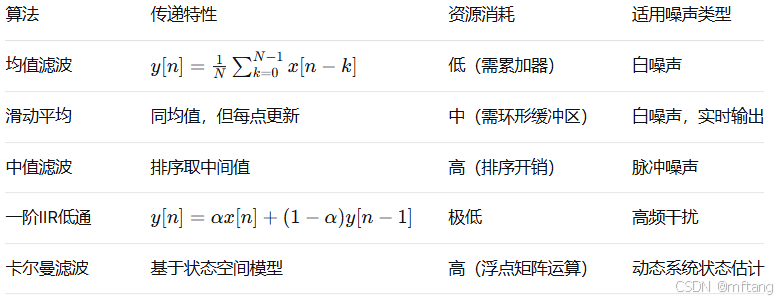
实际工程中,对于缓慢变化的模拟量(如温度、压力),滑动平均或一阶IIR滤波通常足够。对于存在开关噪声的工业现场,中值滤波能有效抑制尖峰。
8. 工程故障模式分析与对策
8.1 DMA数据类型不匹配
现象:读取到的ADC数据数值错误,可能表现为极大值或剧烈跳变。
根因:ADC_DR为16位寄存器,若DMA配置为32位传输,DMA会连续读取两个16位寄存器(ADC_DR和下一个地址的未知数据),导致数据错位。
对策 :强制DMA数据宽度为Half Word,接收缓冲区类型为uint16_t。
8.2 多通道数据错位
现象:数组中通道1的数据与通道2的数据互换或整体偏移。
根因:
-
在ADC启动前DMA未准备好,导致第一个通道数据丢失。
-
扫描序列配置与DMA缓冲区索引假设不一致。
-
使用了非循环模式但在中断中重新配置DMA时未禁止通道。
对策:
-
严格按照"先配置DMA并使能通道 → 再配置ADC并使能DMA请求 → 最后启动ADC转换"的顺序。
-
规则组通道顺序应与DMA解析顺序匹配(建议在调试阶段打印原始缓冲区内容验证)。
-
若使用非循环模式,在DMA完成中断中重新赋值
CNDTR前必须DMA_Cmd(DISABLE),完成后ENABLE。
8.3 ADC时钟超限
现象:ADC转换结果不更新或数值极不稳定。
根因 :未调用RCC_ADCCLKConfig,默认ADCCLK=PCLK2/2=36 MHz,超过14 MHz上限。
对策 :初始化ADC前调用RCC_ADCCLKConfig(RCC_PCLK2_Div6)或Div8。
8.4 数据过载与缓冲区溢出
现象:长时间运行后数据出现重复片段或丢失。
根因:主循环处理数据速度慢于DMA填充速度,导致在未处理完成时新数据已覆盖旧数据。
对策:
-
增大DMA缓冲区深度,降低处理频率。
-
启用半完成中断,实现隐式双缓冲:CPU处理前半缓冲区时DMA填充后半,反之亦然。
-
必要时采用显式乒乓缓冲:通过软件切换两个独立缓冲区。
8.5 规则组DR寄存器覆盖(未使用DMA)
声明 :在多通道扫描模式下,绝对禁止 不使用DMA而依靠CPU读取ADC_DR。原理已在前文论述。
9. 性能评估与方案选型
9.1 实测性能数据(72MHz系统时钟,ADCCLK=12MHz,采样时间71.5周期)
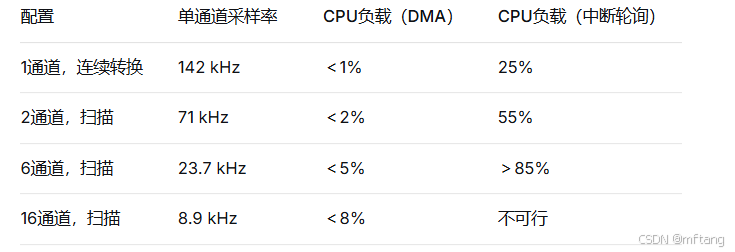
注:CPU负载包含中断响应和必要的数据处理后,不计入上层应用。
9.2 采集方案选型矩阵
| 方案 | 优点 | 缺点 | 典型应用 |
|---|---|---|---|
| 单通道DMA循环 | 实现简单,CPU负载极低 | 仅支持单路 | 电池电压监测 |
| 多通道扫描+DMA循环 | 自动多路采集,CPU负载低 | 通道间存在采样时间差(顺序采样) | 温度/压力/湿度多参数采集 |
| 定时器触发+DMA循环 | 采样间隔精确,时基一致 | 需占用定时器资源 | 音频采样、振动分析、过零检测 |
| 注入组+DMA | 高优先级采样不打断主序列 | 最多4通道,配置复杂 | 故障瞬态记录 |
| 双ADC同步模式 | 两通道真正的同步采样 | 仅限大容量型号,需双ADC | 电机相电流、功率计算 |
| 查询模式(无DMA) | 代码极简 | CPU负载极高,仅低速 | 调试、教学 |
10. 总结与设计建议
| 需求特征 | 推荐配置 | 关键注意事项 |
|---|---|---|
| 常规多通道缓慢信号(<1 kHz变化) | DMA循环 + 连续转换 + 滑动平均滤波 | 缓冲区深度≥100点/通道,采样时间≥71.5周期 |
| 周期性快速信号(1 kHz~50 kHz) | 定时器硬件触发 + DMA循环 | 触发源选择TIMx_TRGO,确保ADCCLK正确分频 |
| 高精度静态测量(如电子秤) | 内部VREFINT校准 + 过采样(硬件或软件) | 采样时间239.5周期,多次平均 |
| 极低功耗设备 | 单次转换 + DMA正常模式 + 深度睡眠唤醒 | 转换完成后关断ADC和DMA时钟 |
最终工程建议:
-
时钟先行 :在任何ADC初始化之前,务必调用
RCC_ADCCLKConfig将ADCCLK限制在14 MHz以内。 -
DMA优先:始终遵循"DMA使能 → ADC使能DMA请求 → ADC启动"的时序。
-
数据类型匹配 :DMA宽度Half Word,缓冲区
uint16_t。 -
多通道验证:首次调试时打印原始DMA缓冲区内容,确认通道顺序与预期一致。
-
电压基准:批量产品中强烈建议使用内部VREFINT校准,消除不同板卡间3.3V电源偏差的影响。
-
实时性保障:若无法保证主循环及时处理,采用半完成中断或乒乓缓冲机制。
通过上述系统性设计与验证,STM32F103的ADC+DMA数据采集方案可在多通道、高精度、实时性要求严苛的工业场景中,以极低的CPU开销实现稳定可靠的数据获取。