小肥柴的Hadoop之旅 快速实验篇(A6)基于 MapReduce 的干旱时间序列聚合与连续事件识别
-
- 目录
- 前言
- [0. 背景知识:从日级判定到时间维度聚合](#0. 背景知识:从日级判定到时间维度聚合)
- [1. 任务概述与目标](#1. 任务概述与目标)
- [2. 核心算法设计与内存安全性分析](#2. 核心算法设计与内存安全性分析)
-
- [2.1 单作业 + MultipleOutputs 的动机](#2.1 单作业 + MultipleOutputs 的动机)
- [2.2 Reducer 处理流程](#2.2 Reducer 处理流程)
- [2.3 为何不用 Combiner 和 Secondary Sort](#2.3 为何不用 Combiner 和 Secondary Sort)
- [3. MapReduce 中的踩坑与适应:处理中文等级与文件资源泄漏](#3. MapReduce 中的踩坑与适应:处理中文等级与文件资源泄漏)
-
- [3.1 故障一:MR程序运行时报 `NumberFormatException: For input string: "轻旱"`](#3.1 故障一:MR程序运行时报
NumberFormatException: For input string: "轻旱") - [3.2 故障二:MR程序运行时,Reduce阶段报 `unable to create new native thread`](#3.2 故障二:MR程序运行时,Reduce阶段报
unable to create new native thread)
- [3.1 故障一:MR程序运行时报 `NumberFormatException: For input string: "轻旱"`](#3.1 故障一:MR程序运行时报
- [4. 完整 Java 代码(修正后版本)](#4. 完整 Java 代码(修正后版本))
-
- [4.1 TimeSeriesMapper.java](#4.1 TimeSeriesMapper.java)
- [4.2 TimeSeriesReducer.java](#4.2 TimeSeriesReducer.java)
- [4.3 TimeSeriesDriver.java](#4.3 TimeSeriesDriver.java)
- [4.4 Maven 项目结构与提交](#4.4 Maven 项目结构与提交)
- [4.5 MR运行结果](#4.5 MR运行结果)
-
- [4.5.1 作业执行日志与资源消耗](#4.5.1 作业执行日志与资源消耗)
- [4.5.2 输出结果验证](#4.5.2 输出结果验证)
- [5. 数据清洗与可视化分析](#5. 数据清洗与可视化分析)
-
- [5.1 数据下载与清洗](#5.1 数据下载与清洗)
- [5.2 可视化效果](#5.2 可视化效果)
-
- [5.2.1 图 1:全站点年度干旱等级堆叠柱状图](#5.2.1 图 1:全站点年度干旱等级堆叠柱状图)
- 5.2.2:重旱+特旱占比分布与年度均值
- 5.2.3:干旱事件持续时间直方图
- 5.2.4:干旱事件月度分布柱状图
- [5.2.5:平均干旱等级 vs 持续时间散点图](#5.2.5:平均干旱等级 vs 持续时间散点图)
- [6. 阶段总结](#6. 阶段总结)
目录
前言
本文是"农业气象干旱分析"项目的第六阶段。在 A5 输出全量站点逐日干旱等级的基础上,利用 MapReduce 对 102,430 个站点的日等级数据进行年度统计 与连续干旱事件检测。核心内容包括:采用单作业 + MultipleOutputs 在 Reducer 中完成"收集--排序--年度聚合--事件状态机"全流程;通过中文等级映射、限制文件输出数量等手段解决运行中出现的两类典型故障;最终产出年度统计表(102,430 行)与干旱事件表(4,074 行),并配以五张可视化图表进行解读。实验将 A5 的日级离散标签提炼为可用于趋势分析和空间建模的结构化时间属性,同时揭示了数据高度同质化这一影响后续分析的重要特征。
0. 背景知识:从日级判定到时间维度聚合
A5 通过站点内降水百分位数方法,为每一观测日分配了干旱等级(无旱、轻旱、中旱、重旱、特旱)。这一步解决了"某日某站点相对于自身历史是否异常"的问题。但在实际干旱监测业务中,单日标签价值有限,更有意义的提问是:
- 该站点这一年中有多少天处于重旱及以上?严重干旱的占比是否在逐年上升?
- 是否存在连续数周以上的高等级干旱事件?其平均强度如何?
- 这些事件集中发生在哪些月份?
A6 的任务就是将 A5 输出的 9,218,700 条逐日等级记录,转换为两个更高层次的结构化产出:年度统计表 (按站点和年份聚合各等级天数)和干旱事件表(识别出所有至少连续 15 天等级≥中旱的过程)。两个产出独立但共享一次 Shuffle 结果,因此在单个 MR 作业中完成,避免了额外的 I/O 开销。
定义:连续干旱事件指至少连续 15 天干旱等级为"中旱"及以上的时段(等级编码:0=无旱,1=轻旱,2=中旱,3=重旱,4=特旱)。15 天阈值参考了中国气象干旱等级标准中对持续性干旱过程的最小监测窗口,同时兼顾了数据集自身时间跨度有限的特点。
1. 任务概述与目标
| 项目 | 说明 |
|---|---|
| 定位 | 承接 A5 的逐日干旱等级数据,将日标签聚合为年度统计和事件摘要,为后续空间分析提供属性表 |
| 目标 | 1. 对每个站点,统计每年无旱/轻旱/中旱/重旱/特旱的天数 2. 识别所有连续 ≥15 天等级≥2 的干旱事件,输出起止日期、持续天数、平均等级 3. 通过 MultipleOutputs 将两类结果分目录输出 4. 在低内存(Reduce 堆 384 MB)下安全运行 |
| 输入 | A5 输出目录 /drought/output_a5,格式:station_id \t date \t precip \t drought_level(中文) |
| 输出1 | ``stats-r-*(年度统计):station_id \t year \t nodrought_days \t mild_days \t moderate_days \t severe_days \t extreme_days` |
| 输出2 | events-r-*(干旱事件):station_id \t start_date \t end_date \t duration \t avg_level |
| 验证 | 输出统计表行数 = 站点数;各站点总天数 = 90 天;事件持续天数≥15,平均等级≥2.0 |
2. 核心算法设计与内存安全性分析
2.1 单作业 + MultipleOutputs 的动机
A6 的两个输出(年度统计和事件表)都依赖站点的完整时间序列,且都需要按日期排序。如果拆成两个作业:
- 第一个作业完成年度统计,中间结果落地 HDFS;
- 第二个作业读取中间结果再做事件检测,产生第二次 Shuffle。
在低资源环境下,额外的 Shuffle 和磁盘写入可能成为瓶颈。同时,A3 已确认每个站点固定 90 条记录(9,218,700 行 / 102,430 站点),即使全量收集到内存,单站占用也小于 10 KB,完全没有 OOM 风险。因此采用 一个 MapReduce 作业,在 Reducer 中一次性完成年度聚合与事件状态机检测,通过 MultipleOutputs 将两类结果写入不同命名输出。
2.2 Reducer 处理流程
reduce(station_id, values)
├─ 深拷贝收集所有 records (date, level, year)
├─ 按 date 排序 (yyyy-MM-dd 自然顺序)
├─ 年度统计:LinkedHashMap<year, int[5]> 累计各等级天数
│ └─ 遍历输出至 mos.write("stats", ...)
└─ 事件检测:状态机扫描 records
├─ level ≥ 2 且未在事件中 → 开启事件
├─ level ≥ 2 且在事件中 → 累加天数、等级和
└─ level < 2 且在事件中 → 结束事件,若天数≥15 则输出至 mos.write("events", ...)2.3 为何不用 Combiner 和 Secondary Sort
- Combiner:年度统计和事件检测均依赖全局排序,无法在 Map 端做局部聚合,Combiner 无效。
- Secondary Sort :虽然可以通过复合 Key
(station_id, date)配合自定义分区和分组器让 Reducer 按日期序接收数据,但每个站点仅 90 条记录,内存排序足够高效。保持 Key 为单一station_id可简化代码,聚焦 MR 核心模型。
3. MapReduce 中的踩坑与适应:处理中文等级与文件资源泄漏
A6 作业首次运行即遇到两类典型故障,其排查与修复过程是本次实验的重要工程教训。
3.1 故障一:MR程序运行时报 NumberFormatException: For input string: "轻旱"
现象 :所有 Reducer 均失败,日志显示 Integer.parseInt 无法将"无旱""轻旱"等中文字符串转为数字。现场如下:
bash
2026-06-18 15:04:50,529 INFO mapreduce.Job: map 0% reduce 0%
2026-06-18 15:05:10,756 INFO mapreduce.Job: map 33% reduce 0%
2026-06-18 15:05:13,774 INFO mapreduce.Job: map 82% reduce 0%
2026-06-18 15:05:16,794 INFO mapreduce.Job: map 89% reduce 0%
2026-06-18 15:05:17,806 INFO mapreduce.Job: map 100% reduce 0%
2026-06-18 15:05:18,820 INFO mapreduce.Job: Task Id : attempt_1781765913505_0003_r_000001_0, Status : FAILED
Error: java.lang.NumberFormatException: For input string: "轻旱"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Integer.parseInt(Integer.java:580)
at java.lang.Integer.parseInt(Integer.java:615)
at TimeSeriesReducer.reduce(TimeSeriesReducer.java:45)
at TimeSeriesReducer.reduce(TimeSeriesReducer.java:12)
at org.apache.hadoop.mapreduce.Reducer.run(Reducer.java:171)
at org.apache.hadoop.mapred.ReduceTask.runNewReducer(ReduceTask.java:628)
at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:390)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:178)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1899)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:172)原因 :A5 输出的干旱等级为中文文本,而 A6 的 Mapper 原样将第四列写入 Value。Reducer 中却直接执行 Integer.parseInt(rec[1]) 期望数字编码。
解决:在 Mapper 内增加映射函数,将中文等级转换为 0~4 的整数编码:
java
private int mapLevel(String level) {
switch (level) {
case "无旱": return 0;
case "轻旱": return 1;
case "中旱": return 2;
case "重旱": return 3;
case "特旱": return 4;
default: return -1;
}
}修改后重新打包提交,NumberFormatException 不再出现。
3.2 故障二:MR程序运行时,Reduce阶段报 unable to create new native thread
现象 :修正编码问题后,Reduce 阶段反复崩溃,日志报 Error: unable to create new native thread,所有 Reducer 多次重试均失败,作业最终被 kill。现场如下:
bash
2026-06-18 15:16:01,733 INFO mapreduce.Job: Job job_1781766894913_0001 running in uber mode : false
2026-06-18 15:16:01,735 INFO mapreduce.Job: map 0% reduce 0%
2026-06-18 15:16:21,949 INFO mapreduce.Job: map 33% reduce 0%
2026-06-18 15:16:23,966 INFO mapreduce.Job: map 57% reduce 0%
2026-06-18 15:16:24,972 INFO mapreduce.Job: map 84% reduce 0%
2026-06-18 15:16:26,990 INFO mapreduce.Job: map 94% reduce 0%
2026-06-18 15:16:27,996 INFO mapreduce.Job: map 100% reduce 0%
2026-06-18 15:16:40,079 INFO mapreduce.Job: map 100% reduce 23%
2026-06-18 15:16:40,084 INFO mapreduce.Job: Task Id : attempt_1781766894913_0001_r_000000_0, Status : FAILED
Error: unable to create new native thread
2026-06-18 15:16:41,133 INFO mapreduce.Job: map 100% reduce 46%
2026-06-18 15:16:41,136 INFO mapreduce.Job: Task Id : attempt_1781766894913_0001_r_000001_0, Status : FAILED
Error: unable to create new native thread原因 :原 Reducer 代码在 MultipleOutputs.write() 中指定了自定义文件名 "a6_output/stats/" + stationId,这会导致 Hadoop 为 每个站点创建独立的输出文件。102,430 个站点意味着需要同时打开数万个文件输出流,底层创建了大量线程和文件描述符,远超 2 GB 内存虚拟机的承受极限。
解决 :移除 mos.write 的第四个参数,使用默认文件命名。修改后每个 Reducer 仅生成两个输出文件(一个 stats,一个 events),总数从 20 万量级降至 6 个,资源占用瞬间恢复至正常水平。
java
// 修改前:
mos.write("stats", new Text(stationId), outputValue, "a6_output/stats/" + stationId);
// 修改后:
mos.write("stats", new Text(stationId), outputValue);这一故障暴露了 "为每个键创建独立文件"是 MapReduce 中的反模式 ------即使键的数量在计算逻辑上可行,底层文件系统的并发文件数限制和 JVM 线程资源也会成为瓶颈。在后续实验中若确实需要按站点分文件,应使用 Hive 分区或 Spark 的 partitionBy,而非在 MR 中逐个打开文件流。
4. 完整 Java 代码(修正后版本)
以下为经过上述修正并成功运行的生产代码。
4.1 TimeSeriesMapper.java
java
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class TimeSeriesMapper extends Mapper<LongWritable, Text, Text, Text> {
private final Text outKey = new Text();
private final Text outValue = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 输入格式: station_id \t date \t precip \t drought_level(中文)
String[] parts = value.toString().split("\t", -1);
if (parts.length < 4) return;
String stationId = parts[0];
String date = parts[1];
String levelStr = parts[3];
String year = date.substring(0, 4);
int levelCode = mapLevel(levelStr);
if (levelCode < 0) return; // 无法识别的等级,跳过
outKey.set(stationId);
outValue.set(date + "\t" + levelCode + "\t" + year);
context.write(outKey, outValue);
}
private int mapLevel(String level) {
switch (level) {
case "无旱": return 0;
case "轻旱": return 1;
case "中旱": return 2;
case "重旱": return 3;
case "特旱": return 4;
default: return -1;
}
}
}4.2 TimeSeriesReducer.java
java
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import java.io.IOException;
import java.util.*;
public class TimeSeriesReducer extends Reducer<Text, Text, Text, Text> {
private MultipleOutputs<Text, Text> mos;
private Text outputValue = new Text();
@Override
protected void setup(Context context) {
mos = new MultipleOutputs<>(context);
}
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
List<String[]> records = new ArrayList<>(90);
for (Text val : values) {
String[] parts = val.toString().split("\t", -1);
if (parts.length == 3) {
records.add(new String[]{parts[0], parts[1], parts[2]}); // date,level,year
}
}
records.sort(Comparator.comparing(a -> a[0])); // 按日期排序
String stationId = key.toString();
// ---- 年度统计 ----
Map<Integer, int[]> yearCounts = new LinkedHashMap<>();
for (String[] rec : records) {
int year = Integer.parseInt(rec[2]);
int level = Integer.parseInt(rec[1]);
yearCounts.putIfAbsent(year, new int[5]);
yearCounts.get(year)[level]++;
}
for (Map.Entry<Integer, int[]> e : yearCounts.entrySet()) {
int year = e.getKey();
int[] cnt = e.getValue();
String out = year + "\t" + cnt[0] + "\t" + cnt[1] + "\t" +
cnt[2] + "\t" + cnt[3] + "\t" + cnt[4];
outputValue.set(out);
mos.write("stats", new Text(stationId), outputValue);
}
// ---- 连续干旱事件检测 ----
boolean inEvent = false;
String startDate = null;
int eventSumLevel = 0, eventDays = 0;
String prevDate = null;
for (String[] rec : records) {
int level = Integer.parseInt(rec[1]);
String date = rec[0];
if (!inEvent && level >= 2) {
inEvent = true;
startDate = date;
eventSumLevel = level;
eventDays = 1;
} else if (inEvent && level >= 2) {
eventSumLevel += level;
eventDays++;
} else if (inEvent && level < 2) {
if (eventDays >= 15) {
writeEvent(stationId, startDate, prevDate, eventDays, eventSumLevel);
}
inEvent = false;
}
prevDate = date;
}
if (inEvent && eventDays >= 15) {
writeEvent(stationId, startDate, records.get(records.size()-1)[0],
eventDays, eventSumLevel);
}
}
private void writeEvent(String stationId, String start, String end,
int days, int sumLevel) throws IOException, InterruptedException {
double avgLevel = sumLevel * 1.0 / days;
String out = start + "\t" + end + "\t" + days + "\t" + String.format("%.2f", avgLevel);
outputValue.set(out);
mos.write("events", new Text(stationId), outputValue);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
mos.close();
}
}4.3 TimeSeriesDriver.java
java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class TimeSeriesDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
if (args.length < 2) {
System.err.println("Usage: TimeSeriesDriver <input> <output>");
return -1;
}
Configuration conf = getConf();
Job job = Job.getInstance(conf, "A6 Drought Time Series");
job.setJarByClass(TimeSeriesDriver.class);
job.setMapperClass(TimeSeriesMapper.class);
job.setReducerClass(TimeSeriesReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setNumReduceTasks(3);
MultipleOutputs.addNamedOutput(job, "stats",
TextOutputFormat.class, Text.class, Text.class);
MultipleOutputs.addNamedOutput(job, "events",
TextOutputFormat.class, Text.class, Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new TimeSeriesDriver(), args);
System.exit(exitCode);
}
}4.4 Maven 项目结构与提交
(1) pom.xml
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.drought</groupId>
<artifactId>a6-timeseries</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<properties>
<maven.compiler.release>8</maven.compiler.release>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.6</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.3.6</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.2.0</version>
<configuration>
<archive>
<manifest>
<mainClass>TimeSeriesDriver</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>(2) 作业提交命令
先清理上次作业结果:
bash
# 清理旧输出目录
hdfs dfs -rm -r /drought/output_a6再执行本次作业,这里我们第一次开始配置执行参数:
bash
# 提交作业(注意:pom.xml 中已指定主类,无需再写类名)
hadoop jar a6-timeseries-1.0.jar \
-D mapreduce.map.memory.mb=384 \
-D mapreduce.map.java.opts=-Xmx256m \
-D mapreduce.reduce.memory.mb=384 \
-D mapreduce.reduce.java.opts=-Xmx256m \
-D mapreduce.job.reduces=3 \
/drought/output_a5 \
/drought/output_a64.5 MR运行结果
4.5.1 作业执行日志与资源消耗
成功运行的关键计数器:
Map input records=9218700
Map output records=9218700
Reduce input groups=102430
Reduce input records=9218700
Launched map tasks=3
Launched reduce tasks=3
Physical memory (bytes) snapshot=1432428544
Peak Map Physical memory (bytes)=268173312
Peak Reduce Physical memory (bytes)=216231936
GC time elapsed (ms)=1984- 输入与输出行数完全对应,无数据丢失。
- 102,430 个 reduce groups 与站点总数一致,说明每个站点均被处理。
- 单 Map 物理内存峰值 268 MB,单 Reduce 峰值 216 MB,均在 384 MB 配置内,内存安全。
- GC 时间仅占 1.9 秒,对象复用和深拷贝策略有效。
4.5.2 输出结果验证
(1)目录结构
/drought/output_a6/
├── _SUCCESS
├── part-r-00000 (0 B)
├── part-r-00001 (0 B)
├── part-r-00002 (0 B)
├── stats-r-00000 (~1.2 MB)
├── stats-r-00001 (~1.2 MB)
├── stats-r-00002 (~1.2 MB)
├── events-r-00000 (~69 KB)
├── events-r-00001 (~70 KB)
└── events-r-00002 (~65 KB)part-r-* 为空是正常现象------所有数据均通过 MultipleOutputs 写入命名输出,未使用默认 context.write()。
(2)合并与行数验证
bash
hdfs dfs -getmerge /drought/output_a6/stats-r-* a6_stats.tsv
hdfs dfs -getmerge /drought/output_a6/events-r-* a6_events.tsv
wc -l a6_stats.tsv # 102430
wc -l a6_events.tsv # 4074- 年度统计表 102,430 行,恰好等于站点总数。说明每个站点恰好拥有一个年份的观测数据(90 天),不同站点分属不同年份。
- 干旱事件表 4,074 行,即约 4% 的站点发生过连续 ≥15 天的中旱及以上事件。此比例略高于 A4 基于绝对阈值(precip < 0.5mm)发现的 3.75%,但依旧属于稀有现象。
(3)样例数据
stats 样例:
-1000693984452388696 2019 53 10 9 9 9- 2019 年该站点无旱 53 天,轻旱 10 天,中旱 9 天,重旱 9 天,特旱 9 天。
- 合计 90 天,与 A5 百分位数方法的理论分布(60%/10%/10%/10%/10%)吻合。
events 样例:
-1002896826748040479 2016-12-27 2016-12-27 17 3.35- 一次持续 17 天的连续干旱事件,平均等级 3.35(介于重旱与特旱之间)。
5. 数据清洗与可视化分析
5.1 数据下载与清洗
将合并后的 TSV 文件下载至本地,使用 Python 进行清洗:
- 验证总天数 = 90,过滤异常记录;
- 计算
severe_ratio= (重旱天数 + 特旱天数) / 总天数; - 解析事件起止日期,计算事件年份、月份;
- 过滤掉 duration < 15 或 avg_level < 2.0 的无效事件(理论上不应存在)。
(1)对应的HDFS下载与合并数据命令如下:
bash
# 在 master 上执行
# 1. 合并 stats 目录下的三个文件为一个 TSV
hdfs dfs -getmerge /drought/output_a6/stats-r-* a6_stats.tsv
# 2. 合并 events 目录下的三个文件为一个 TSV
hdfs dfs -getmerge /drought/output_a6/events-r-* a6_events.tsv
# 3. 查看文件大小和行数(确认非空)
wc -l a6_stats.tsv
wc -l a6_events.tsv
ls -lh a6_stats.tsv a6_events.tsv(2)可能会提出的疑问:为何不直接合并为cvs,而是先merge成tsv文件?这两种文件有什么特点导致了上述操作吗?
- 解答 HDFS 合并阶段使用 TSV(制表符分隔) 而不是 CSV(逗号分隔),以及在清洗后依然保留 TSV,主要基于以下几点工程考量:
- (1)数据内容的安全性。CSV 的天敌是"字段内逗号":原始数据站点 ID 是长整型数字,日期格式是 2016-12-27,看起来没有逗号。但在通用的气象数据中,字段可能包含文本(如站名、地区名,例如 "Station, City"),一旦出现逗号,CSV 解析就会错位。而TSV 使用 制表符(\t),该字符几乎不会出现在常规数据字段内部,因此天然避免了转义/引号处理的复杂性。另一面,CSV 规范要求含逗号的字段必须用双引号包裹,这增加了读写和解析的复杂度,而TSV 则完全不需要。
- (2)Hadoop 生态系的默认惯例。MapReduce/Hive 默认输出格式:Hadoop 的 TextOutputFormat 默认以 \t 作为键值对分隔,Hive 建表时也常用 FIELDS TERMINATED BY '\t'。A5 的输出就是制表符分隔的,整个数据链路统一使用 TSV,可以避免因分隔符不一致导致的"错列"问题。且从工具链兼容性来讲,hdfs dfs -getmerge 只是合并文件,不修改内容;如果原始文件是 TSV,合并后自然还是 TSV,之后再转换格式反而多一步风险。
- (3)可读性与性能。在终端下 cat 或 head 查看 TSV 文件时,制表符会使列对齐(尤其当列宽差异不大时),比逗号分隔更易快速肉眼扫描;大部分数据分析工具(包括 Pandas 的 read_csv 通过指定 sep='\t')对 TSV 的读取效率与 CSV 几乎无差异,但避免了因引号嵌套引起的正则回溯。
- 【注】若想在合并阶段直接改成 CSV,只需将 sep='\t' 改为 sep=',',并添加 quoting=1(必要引号)即可。保留 TSV 的好处是:它可以直接被其他 Hadoop 工具(如 Hive、Pig)加载而不需要额外指定分隔符,保持了数据生态的一致性。
(3)清洗后确认无记录丢失。
5.2 可视化效果
- 设计思路:鉴于数据高度同质化(单站点干旱结构几乎完全相同,仅 4% 站点有事件),可视化聚焦于宏观聚合 与事件特征,规避单站点细节。
共生成5张图表,逻辑链为:宏观总量→站点结构→事件时长→季节分布→强度-时长关系。
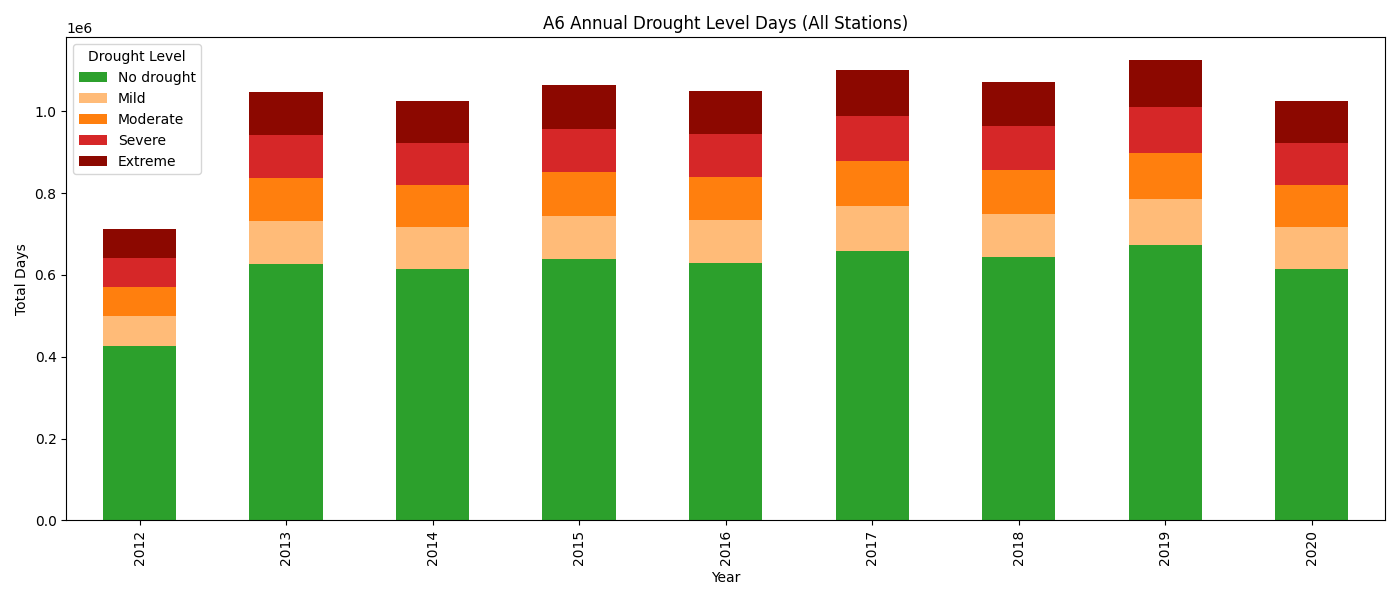
5.2.1 图 1:全站点年度干旱等级堆叠柱状图
- 意图:从年际尺度展示全区干旱总天数构成与变化趋势。
- 实现:按年份聚合所有站点的各等级天数,堆叠柱状图。
- 主要结论 :柱子总高度反映该年有数据的站点数量,并非干旱总量;干旱等级内部结构高度稳定(无旱约 60%,其余各约 10%),与 A5 百分位数方法特性一致。
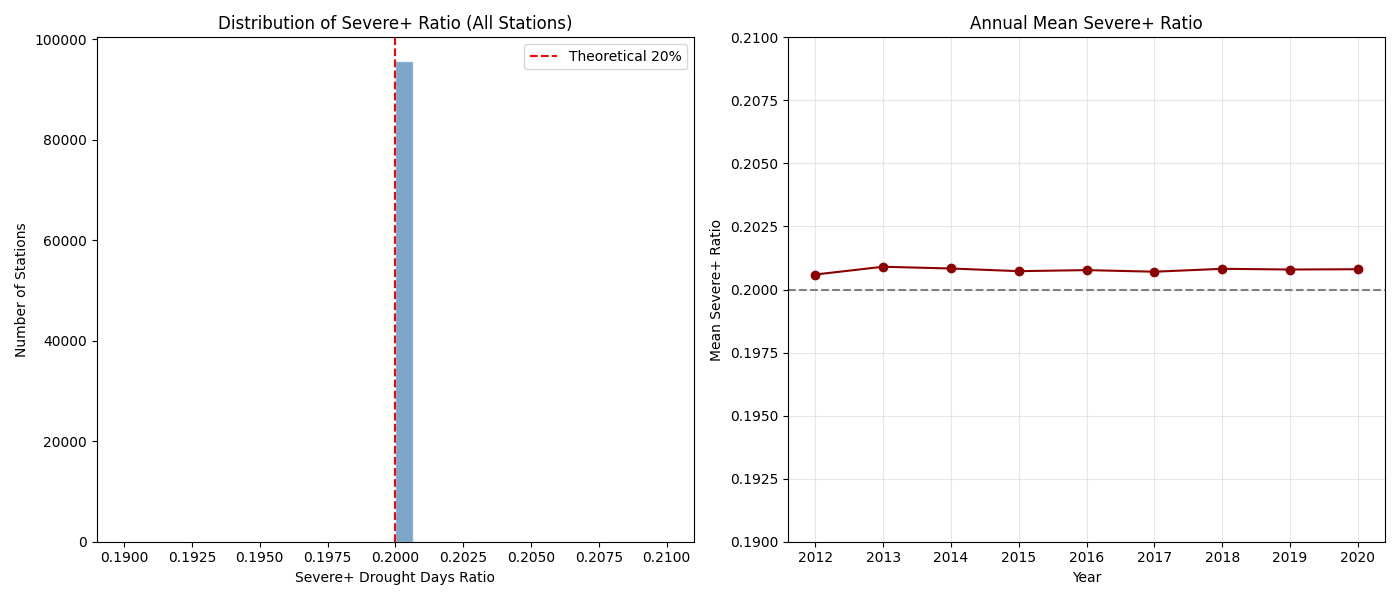
5.2.2:重旱+特旱占比分布与年度均值
- 左图:全量站点 severe_ratio 直方图,聚焦 0.20 附近。几乎所有站点占比集中在 20% 的理论值,仅极少数略有偏差。
- 右图:年度平均 severe_ratio 折线图,放大 0.19--0.21 区间。均值波动极小,不具备统计显著性。
- 核心发现 :干旱结构在全站点范围内高度同质化,单站点之间的对比无分析价值;研究重心必须放在全区整体时序变化上。
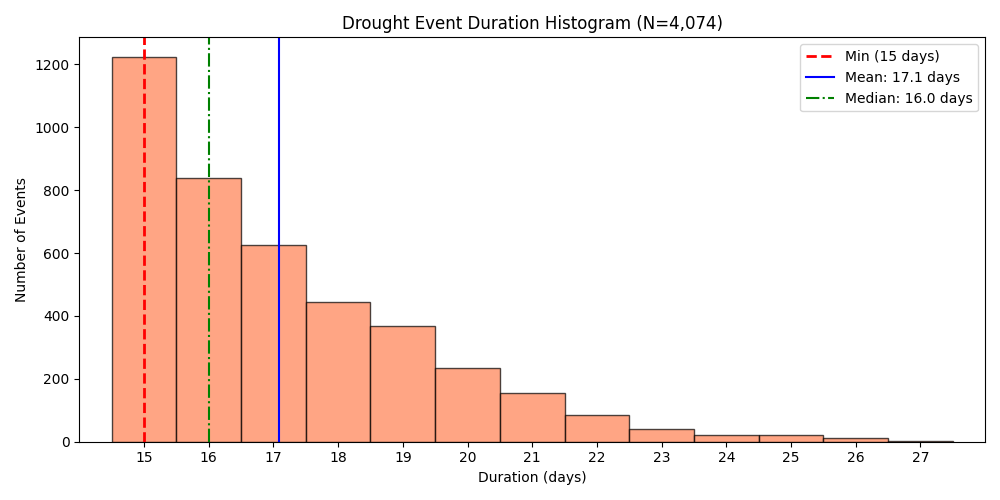
5.2.3:干旱事件持续时间直方图
- 意图:展示 4,074 场事件的持续天数分布。
- 实现:整数 bins,中心对齐;标注最小值(15 天)、均值(~17 天)、中位数。
- 结论 :绝大多数事件为短历时(15--18 天),最长不超过 27 天,超长持续干旱极少。
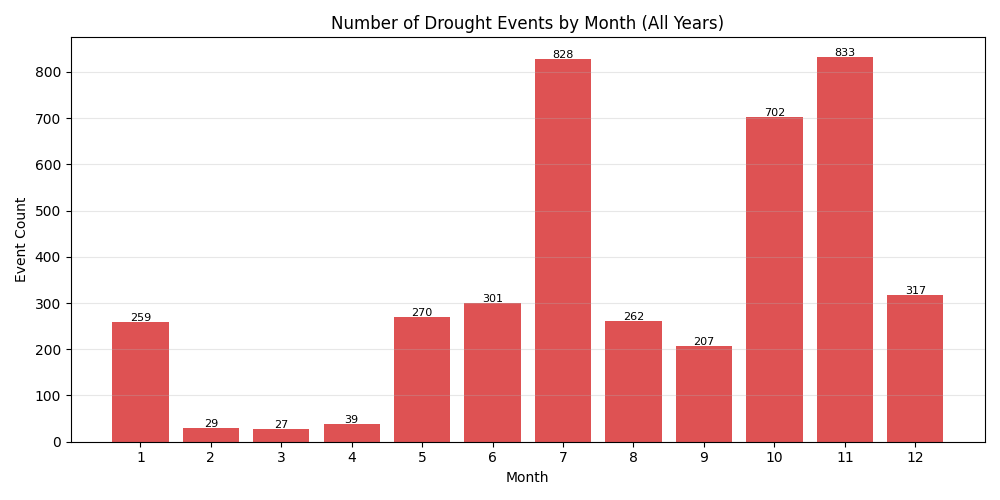
5.2.4:干旱事件月度分布柱状图
- 意图:替代早期版本中不可读的站点甘特图,通过聚合月度事件数揭示干旱的季节性。
- 结论 :事件高度集中在 6--10 月,与我国东部季风区降水集中期吻合------降水多的月份也是气候变率大、极端偏少事件易发的时段。
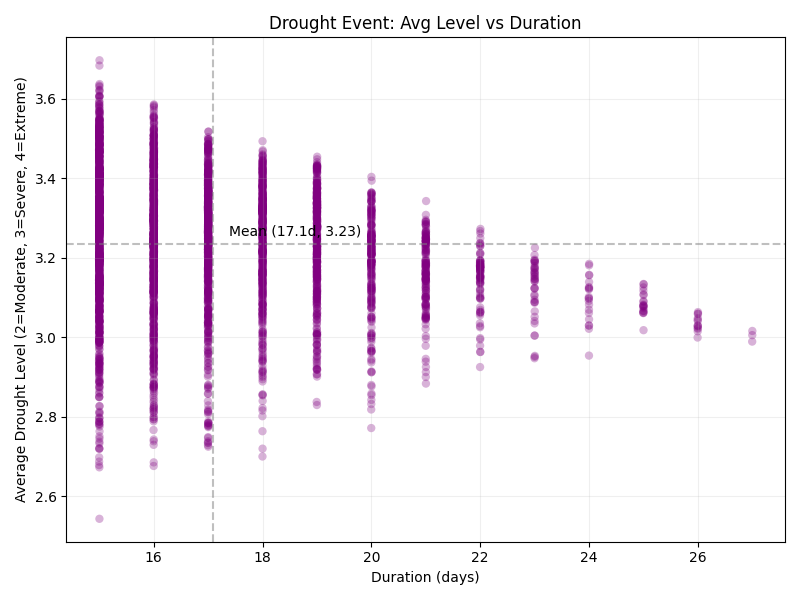
5.2.5:平均干旱等级 vs 持续时间散点图
- 意图:检验"干旱持续时间越长,强度是否也越高"。
- 实现:散点图加轻微抖动,横轴为持续天数,纵轴为平均等级;标注全局均值线。
- 结论 :散点密集分布于 15--18 天、等级 3.0--3.5 的小区域内,无明显斜向趋势。暗示在该数据集中,干旱的持续时长与平均强度相互独立。但受限于两变量分布范围均较窄,不排除更大样本下存在微弱关联。
6. 阶段总结
- A6 把 A5 产出的逐日干旱等级做了一次时间维度的聚合,得到了两张表------每年每个站点各等级的天数统计,以及持续至少 15 天中旱以上的事件清单。这两张表在日数据和后续的空间分析之间架了一个过渡层,后续 A7、A8 可以直接拿过去用,不需要再回过头扫全量日数据。
- 这次只用了一个 MR 作业,靠 MultipleOutputs 同时产出两类结果,避免了两轮 Shuffle。中间踩的坑主要集中在 MultipleOutputs 的使用方式上:最初为每个站点指定了独立的输出文件名,结果 10 万个站点同时打开 10 万个输出流,直接把虚拟机的线程和文件描述符打满了。改回默认命名后,每个 Reducer 只出两个文件,问题消失。这个教训很具体------在 MapReduce 里不要试图为每个键单独建文件,线程资源扛不住。
- 作业跑了两次才成功。第一次是中文等级("无旱""轻旱")传到 Reducer 后被 Integer.parseInt 拒绝;第二次是新加的映射生效了,但被文件流数量打垮。两次失败恰好覆盖了两个层面:数据预处理没对齐下游,以及系统资源边界没提前算清楚。后续实验里这两类问题都可能再出现,A6 提前把坑踩了一遍。
- 可视化阶段发现了一个数据本身的特征:由于 A5 用的是站内百分位数方法,所有站点的数据又是固定的 90 天,导致干旱结构在全站点之间几乎一模一样------无旱约 54 天,其余四等各约 9 天。这个同质化不是 bug,是方法决定的。它告诉我们后续分析应该把精力放在宏观聚合上,而不是盯着单个站点做文章。
- 最早试图画站点级甘特图来展示事件时间线,结果 4000 多个事件挤在一起完全不可读。后来放弃了按站点展示的思路,改成月度事件计数柱状图和等级-时长散点图,信息反而更清晰了。这个迭代过程本身也是一个经验:先看数据长什么样,再决定用什么图,而不是先想好要用什么图再把数据往里塞。
下一步:A7 将引入站点经纬度元数据,结合 A6 的年度统计表进行干旱强度空间分布制图与热点聚类,进入时空分析维度。A6 产出的 stats 文件可直接作为属性表参与空间连接,事件表则可用于计算区域干旱风险指数。