前言
在制造业 MES 系统中,有一类非常简单、独立的任务经常使用底层的方法实现。它们通常不由 HTTP 请求触发,而是通过 while 循环、定时器或后台服务持续运行,用于轮询数据库、同步状态、处理队列、扫描工单或执行周期性补偿逻辑。
从自动埋点的视角看,这类任务天然缺少一个外部请求入口。以 ASP.NET Core 应用为例,HTTP 接口、数据库访问、部分中间件调用通常可以由 Datadog .NET Tracer 自动采集,但是类似后台 while 循环的底层方法,其本身不会自动形成一个完整的 Trace 根节点。因此,假设在循环体中包含 Oracle 访问,观测云中可能只能看到零散的数据库 Span,而无法回答"这一轮任务从什么时候开始、执行了什么、是否失败、耗时多久"这些运维和研发都真正关心的问题。
这并不是自动埋点能力不足,而是后台任务的执行模型与传统请求链路存在差异。HTTP 请求天然有入口、出口、状态码和耗时,而 while 循环管理的后台任务只有开发人员知道一轮任务的边界在哪里。对于某大型制造业客户的 MES 应用来说,客户希望通过链路了解定时任务的执行细节,因此就需要在自动埋点之外,为特殊后台任务补充少量手动埋点。
本篇文章通过测试 Demo https://gitee.com/baihr/dotnetcore-trace-test ,讨论一种适合特殊后台任务场景的方案:在任务循环外层增加少量手动埋点,将每一轮后台任务报告为一条可分析的调用链路。
观测云集成方案
在本场景中,观测目标并不是替换已有的自动埋点能力,而是补齐后台任务本身缺失的链路入口。整体方案可以拆成三个部分来看:
- ASP.NET Core HTTP 请求仍然由 Datadog .NET Tracer 自动采集;
- Oracle 数据库访问仍然由 Datadog .NET Tracer 自动采集;
- 后台
while循环每一轮任务由.NET内置的ActivitySource手动创建一个父 Span。
Demo 是一个 .NET 8 的 ASP.NET Core Minimal API 应用,提供 /health、/slow、/oracle/ping 三个接口,同时包含一个 FixedIntervalOracleWorker 后台任务。后台任务通过 while 循环按固定间隔访问 Oracle,用来模拟 MES 系统中常见的周期性后台任务。
这里需要特别注意一个边界:我们并不需要为 HTTP 接口或 Oracle 调用重新手写埋点。HTTP 请求和 Oracle 数据库访问已经有成熟的自动埋点能力,手动埋点只补在后台任务每一轮循环的最外层,用来创建一个 job.execute Span,使循环体中产生的 Span 作为任务 Span 的子 Span。最终希望看到的链路结构大致如下:
job.execute / fixed-interval-oracle-probe
-> Oracle database span这样,后台任务不再只是进程中的一段循环代码,而是变成了观测平台中可以被查询、聚合、分析和告警的任务执行单元。
为什么使用 .NET 内置 ActivitySource
很多人在谈到手动埋点时,会直接想到引入 OpenTelemetry SDK 或特定厂商的自定义 API。不过在 .NET Core 应用中,一个容易被忽略的事实是:.NET 本身已经提供了手动埋点入口,即 System.Diagnostics.ActivitySource 和 System.Diagnostics.Activity。
ActivitySource 可以理解为 .NET 里的埋点源,Activity 可以理解为一次具体的 Span。应用或类库通过 ActivitySource.StartActivity(...) 创建 Activity,采集器再决定是否监听、采样和上报这些 Activity。对业务代码来说,这种方式的优势非常直接:
- 不需要额外引入 OpenTelemetry SDK NuGet 包;
- 不需要在业务代码中绑定某个观测厂商的 API;
- 可以继续复用 Datadog .NET Tracer 的自动埋点能力;
- 对高频路径比较友好,没有监听器时
StartActivity(...)可以返回null,避免不必要的对象创建。
Demo 的项目文件中,唯一的业务依赖是 Oracle 驱动:
<PackageReference Include="Oracle.ManagedDataAccess.Core" Version="23.26.200" />手动埋点能力来自 System.Diagnostics 命名空间,而不是额外安装完整的 OpenTelemetry SDK 包。这一点在客户现场非常重要,因为很多生产系统对于新增依赖、版本兼容和发布流程都比较谨慎。相比引入一套新的 SDK,在已有自动注入基础上使用运行时内置 API 补充关键 Span,是一个侵入性更低的方案。
实践步骤
部署 Datakit 并开启必要的采集器
在观测云中注册账号后,进入"集成 - Datakit",按照主机环境复制安装命令并完成 Datakit 部署。对于本例来说,需要开启 ddtrace 采集器,用于接收 Datadog .NET Tracer 上报的链路数据。
安装 Datadog .NET Tracer
访问 https://github.com/DataDog/dd-trace-dotnet/releases 下载并安装最新的稳定版本。
在代码中埋点
创建 ActivitySource
ActivitySource 适用于 .NET Core 5/6/7/8/9/10/11 .NET Framework 4.6.2/4.7/4.7.1/4.7.2/4.8,细节请参考:ActivitySource 类 (System.Diagnostics) | Microsoft Learn
Demo 中定义了一个稳定的 ActivitySource:
public static class Telemetry
{
public const string ActivitySourceName = "dotnetcore-trace-test";
public static readonly ActivitySource ActivitySource =
new(ActivitySourceName, "1.0.0");
}ActivitySourceName 是手动埋点的来源名称,建议保持稳定。它和 DD_SERVICE 不是同一个概念,前者表示埋点源,后者表示服务名。在测试项目中二者设置为同名只是为了排查时更加直观。
在 ASP.NET Core 依赖注入中,可以将它注册成单例,供后台任务使用:
builder.Services.AddSingleton(Telemetry.ActivitySource);为后台 while 循环创建任务 Span
后台任务的核心逻辑在 FixedIntervalOracleWorker 中。每一轮循环开始时,使用 ActivitySource.StartActivity(...) 创建一个 job.execute Span:
using (var activity = _activitySource.StartActivity("job.execute", ActivityKind.Internal))
{
activity?.SetTag("operation.name", "trace-test.job");
activity?.SetTag("resource.name", "fixed-interval-oracle-probe");
activity?.SetTag("span.type", "worker");
activity?.SetTag("job.name", "fixed-interval-oracle-probe");
activity?.SetTag("job.iteration", iteration);
activity?.SetTag("interval.seconds", intervalSeconds);
var result = await _oracleProbe.PingAsync("worker", stoppingToken);
activity?.SetTag("oracle.success", result.Success);
activity?.SetTag("oracle.elapsed_ms", result.ElapsedMs);
if (result.Success)
{
activity?.SetStatus(ActivityStatusCode.Ok);
}
else
{
activity?.SetStatus(ActivityStatusCode.Error, result.Error ?? "Oracle probe failed.");
activity?.SetTag("error", 1);
activity?.SetTag("error.message", result.Error);
activity?.SetTag("error.type", "OracleProbeFailed");
}
}这里有几个细节值得注意:
ActivityKind.Internal表示这是进程内部工作,而不是 HTTP Server、HTTP Client 或消息队列消费者。对于后台定时任务来说,这个语义是合适的;job.name、job.iteration、interval.seconds这类标签并不是协议强制字段,而是为了便于后续查询和分析。客户真正排查问题时,往往需要按任务名、执行轮次、执行结果、耗时等维度进行过滤,因此这些业务标签非常有价值,根据实际情况增减即可;- 错误状态需要手动设置。如果某一轮任务失败,只写日志当然可以帮助排查,但是链路本身如果没有被标记为 Error,就很难在 APM 视图中按错误任务进行检索和聚合。因此 Demo 中在失败时同时设置
ActivityStatusCode.Error和错误标签。
修改应用启动脚本
通过在应用启动脚本中增加环境变量启用探针自动注入并对探针进行初始配置:
-
启用 Datadog .NET Tracer 自动注入:
set CORECLR_ENABLE_PROFILING=1这样,HTTP 请求和 Oracle 数据库调用可以继续由自动埋点采集。对于
/oracle/ping这种由 HTTP 触发的接口来说,请求入口天然会形成 Trace 根节点,Oracle 调用会作为数据库子 Span 出现在链路中,因此不需要额外手写 Span。 -
配置探针将数据发到本机 Datakit 地址:
set DD_TRACE_AGENT_URL=http://localhost:9529 -
设置服务名、环境和版本等统一标签:
set DD_SERVICE=dotnetcore-trace-test set DD_ENV=test set DD_VERSION=1.0.0 -
启用 ActivitySource 采集
Datadog .NET Tracer 默认不会采集所有基于 OpenTelemetry/ActivitySource 的手动埋点,需要显式打开:
set DD_TRACE_OTEL_ENABLED=true
最终的完整启动脚本如下:
@echo off
rem Datadog .NET Core 自动注入
set CORECLR_ENABLE_PROFILING=1
rem Datadog 服务标识
set DD_SERVICE=dotnetcore-trace-test
set DD_ENV=test
set DD_VERSION=1.0.0
rem Datadog Agent 地址
set DD_TRACE_AGENT_URL=http://localhost:9529
rem 可选:日志与运行时指标
set DD_LOGS_INJECTION=true
set DD_RUNTIME_METRICS_ENABLED=true
rem 启用 OTel 手动埋点
set DD_TRACE_OTEL_ENABLED=true
rem 启用 Profile
set DD_PROFILING_ENABLED=1
C:\dotnet\dotnet.exe C:\dotnetcore-trace-test\publish\dotnetcore-trace-test.dll配置生效后,后台任务每一轮执行都会产生一个任务 Span,Oracle 自动埋点产生的数据库 Span 会挂在当前 Activity 下,从而形成完整的后台任务调用链。
一个容易忽略的耗时问题
这类后台任务埋点最容易犯的错误,是把等待下一轮执行的 Task.Delay 也放进 Span 作用域里。这样观测平台中看到的任务耗时会接近调度间隔,例如 30 秒,而不是本轮真实业务执行时间。
错误的写法大致如下:
using (var activity = _activitySource.StartActivity("job.execute", ActivityKind.Internal))
{
await _oracleProbe.PingAsync("worker", stoppingToken);
await Task.Delay(interval, stoppingToken);
}这种写法会让 Span 同时覆盖"业务执行时间"和"等待下一轮调度时间",最终得到一个不准确的任务耗时。
Demo 中采用的写法是将等待逻辑放在 using Activity 之外:
using (var activity = _activitySource.StartActivity("job.execute", ActivityKind.Internal))
{
await _oracleProbe.PingAsync("worker", stoppingToken);
}
await Task.Delay(interval, stoppingToken);这个细节非常重要。后台任务的链路应该描述"一轮任务做了什么",而不是描述"这个循环多久执行一次"。如果不区分这两个时间,链路数据会误导后续分析。
日志方案的边界
不过,手动埋点导出链路并不是这类后台任务的默认答案。对于简单的任务调度场景,如果我们只需要知道任务是否启动、是否结束、是否失败、耗时多久,其实通过日志就可以完成观测。比如后台任务每轮执行时输出如下结构化日志:
job=fixed-interval-oracle-probe iteration=1024 status=success elapsed_ms=35或者在失败时输出:
job=fixed-interval-oracle-probe iteration=1025 status=failed error="Oracle probe failed"这种信息已经足够支持很多任务观测场景。观测云支持通过 DataKit 采集主机日志、容器标准输出和多种第三方日志来源,并通过 Pipeline 对日志做结构化处理,最终通过日志完成任务分析和告警。也就是说,如果 MES 后台任务本身已经输出了任务名、执行结果、耗时、错误原因等日志,那么完全可以不修改代码,直接通过日志采集和处理完成任务观测。
从方案选型上看,可以采用如下判断:
- 如果只关心任务执行结果、耗时、失败原因,优先使用日志;
- 如果需要任务级告警,也可以优先使用结构化日志加日志监控器;
- 如果需要把后台任务、数据库调用、HTTP 调用或消息处理放在同一条 Trace 中分析,再考虑手动链路;
- 如果需要在 APM 视图中按任务 Span 聚合错误、耗时和下游调用,手动埋点就是更合适的方案。
换句话说,手动埋点解决的是"后台任务作为调用链入口"的问题,而日志解决的是"后台任务作为事件记录"的问题。两者不是互斥关系,但也不应该混用成一种不加判断的默认动作。
模拟验证
应用启动后,可以访问以下接口验证 HTTP 自动埋点:
Invoke-RestMethod http://127.0.0.1:5088/health
Invoke-RestMethod http://127.0.0.1:5088/oracle/ping
Invoke-RestMethod http://127.0.0.1:5088/slow其中 /oracle/ping 会产生 HTTP 请求 Span 和 Oracle 数据库 Span。后台 FixedIntervalOracleWorker 则不需要外部请求触发,它会按照 Worker:IntervalSeconds 配置周期性执行 Oracle 探测。稍等片刻后,在观测云"应用性能监测 - 链路"中可以观察到两类链路:
- 由 HTTP 请求触发的接口链路;
- 由
job.execute触发的后台任务链路。
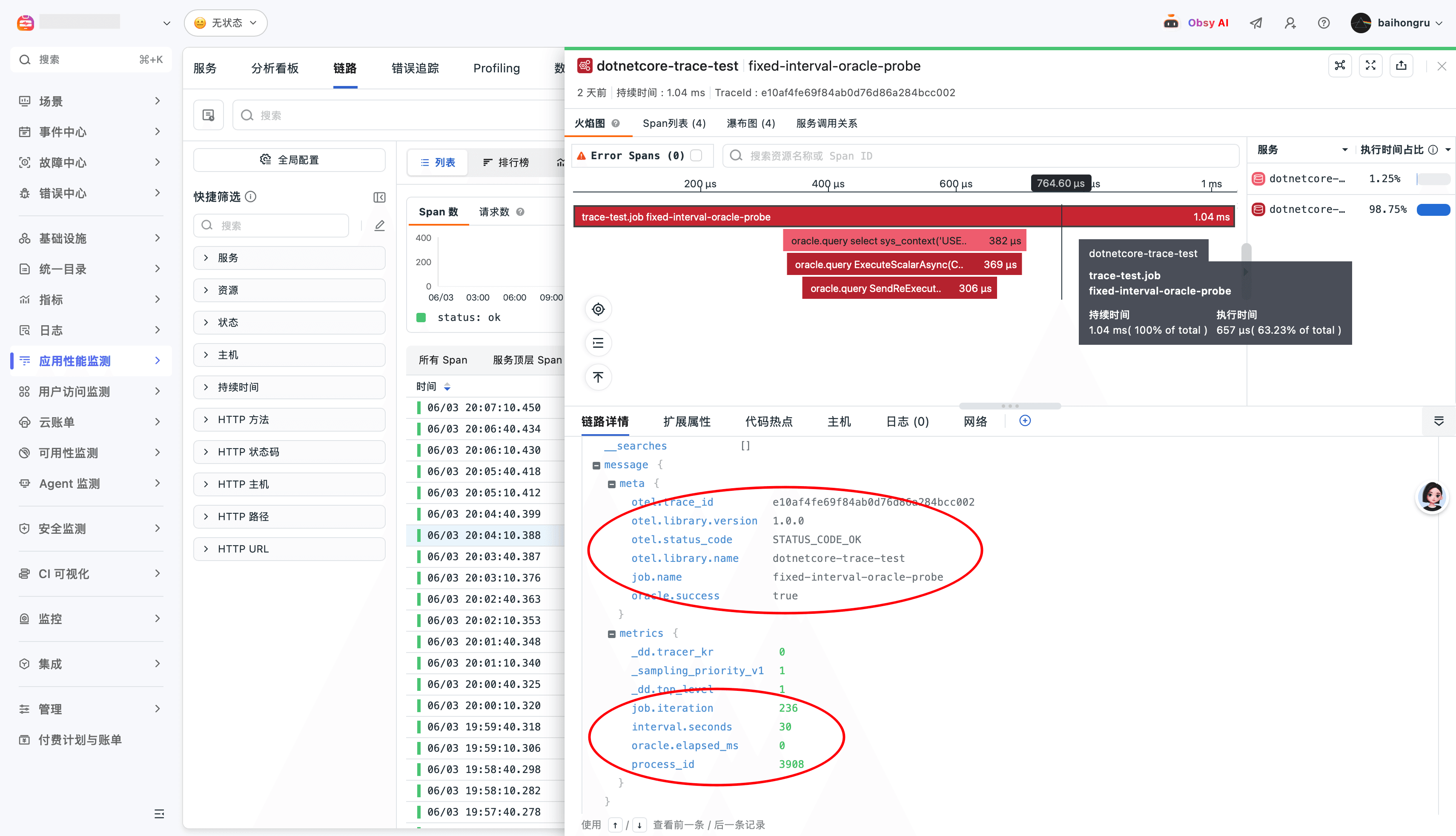
对于后台任务链路来说,重点观察以下信息:
- 根 Span 是否为
job.execute; - 资源名是否为
fixed-interval-oracle-probe; - Oracle 数据库调用是否作为子 Span 出现;
job.iteration、oracle.success、oracle.elapsed_ms等标签是否存在;- 失败任务是否被标记为 Error。
实际数据如下,注意,请按需增减数据标签:
总结
.NET Core 后台 while 任务不会天然产生完整调用链,这不是采集器能力不足,而是这类任务本身缺少外部请求入口。对于制造业 MES 中确实需要链路化分析的后台任务,可以使用 .NET 内置的 ActivitySource 在任务外层补一个 Span,并继续让自动埋点负责数据库、HTTP 等下游调用。
这个方案的价值在于:埋点足够少,不引入额外 OpenTelemetry SDK 依赖,也不破坏原有自动埋点路径。对于客户现场来说,它既能满足"通过链路了解定时任务细节"的诉求,又能把代码改造控制在非常小的范围内。
不过,从可观测方案设计的角度看,我们仍然需要保留一个更朴素的判断:简单任务优先用日志观测,复杂任务再用链路补齐结构。观测云已经支持日志采集、处理、分析和告警,很多任务调度场景完全可以不修改代码,仅通过日志完成观测。只有当任务执行过程需要与数据库、HTTP、消息等下游调用形成一条完整分析路径时,手动埋点才是更合适的选择。
在良好集成的基础上,开发和运维角色能够从任务 Span 进入链路细节,也能够从日志进入事件上下文,两条路径互相补充,最终形成对后台任务更加确定的分析能力。