OpenCV-Python实战(29)------基于视觉显著性的自动多目标跟踪系统
-
- [0. 前言](#0. 前言)
- [1. 视觉显著性](#1. 视觉显著性)
- [2. 规划应用程序](#2. 规划应用程序)
- [2. 搭建应用程序](#2. 搭建应用程序)
-
- [2.1 实现主函数](#2.1 实现主函数)
- [2.2 MultiObjectTracker 类](#2.2 MultiObjectTracker 类)
- [3. 绘制视觉显著性图](#3. 绘制视觉显著性图)
-
- [3.1 傅里叶分析](#3.1 傅里叶分析)
- [3.2 自然场景统计特征](#3.2 自然场景统计特征)
- [3.3 使用频谱残差方法生成显著性图](#3.3 使用频谱残差方法生成显著性图)
- [3.4 检测场景中的原始物体](#3.4 检测场景中的原始物体)
- [4. 均值漂移跟踪](#4. 均值漂移跟踪)
-
- [4.1 自动跟踪足球场上的所有球员](#4.1 自动跟踪足球场上的所有球员)
- [5. OpenCV 跟踪 API](#5. OpenCV 跟踪 API)
- [6. 综合实践](#6. 综合实践)
- 小结
- 系列链接
0. 前言
本节的目标是在视频序列中同时跟踪多个视觉显著物体。我们不会手动标记视频中感兴趣的物体,而是让算法自主判断视频帧中哪些区域值得跟踪。
此前,我们已经学习了如何在严格受控的场景中检测简单的感兴趣物体(例如人手),以及如何从相机运动中推断视觉场景的几何特征。在本节中,我们将探讨通过分析大量视频帧的图像统计信息,能够从视觉场景中学习到哪些内容。
通过分析自然图像的傅里叶频谱,我们将构建一个显著性图,从而能够将图像中某些在统计上具有显著性的区域标记为(潜在或实际的)原始物体。然后,我们将所有原始物体的位置输入均值漂移跟踪器,这样就可以持续跟踪物体在帧与帧之间的运动轨迹。
1. 视觉显著性
视觉显著性 (Visual Saliency) 是一个来自认知心理学的专业术语,它试图描述某些物体或项目能够立即吸引我们注意力的视觉特性。我们的大脑不断地将目光导向视觉场景中的重要区域,并持续跟踪这些区域,使我们能够快速扫描周围环境以寻找有趣的物体和事件,同时忽略那些不太重要的部分。
下图展示了一个普通 RGB 图像及其转换为显著性图的示例,其中统计上有趣的区域显示为亮色,其他区域显示为暗色:

傅里叶分析使我们能够从整体上理解自然图像的统计特性,这有助于我们构建一个关于一般图像背景样貌的模型。通过将背景模型与特定图像帧进行比较和对比,我们可以定位出图像中从周围环境中"跳脱"出来的子区域(如上图所示)。理想情况下,这些子区域对应于我们在观看图像时会立即吸引注意力的图像块。
传统的模型可能会尝试将特定的特征与每个目标关联起来(就像在《通过特征匹配和透视变换寻找物体》中的特征匹配方法一样),这将把问题转化为检测特定类别的物体。然而,这些模型需要人工标注和训练。但是,如果待跟踪物体的特征或数量是未知的呢?
相反,我们将尝试模拟大脑的工作方式,即根据自然图像的统计特性来调整算法,从而能够立即定位视觉场景中"吸引我们注意力"的模式或子区域(即偏离这些统计规律的模式),并将它们标记出来以供进一步处理。这样得到的算法可以处理场景中任意数量的原始物体,例如跟踪足球场上的所有球员。请参考以下截图序列,看看它是如何工作的:
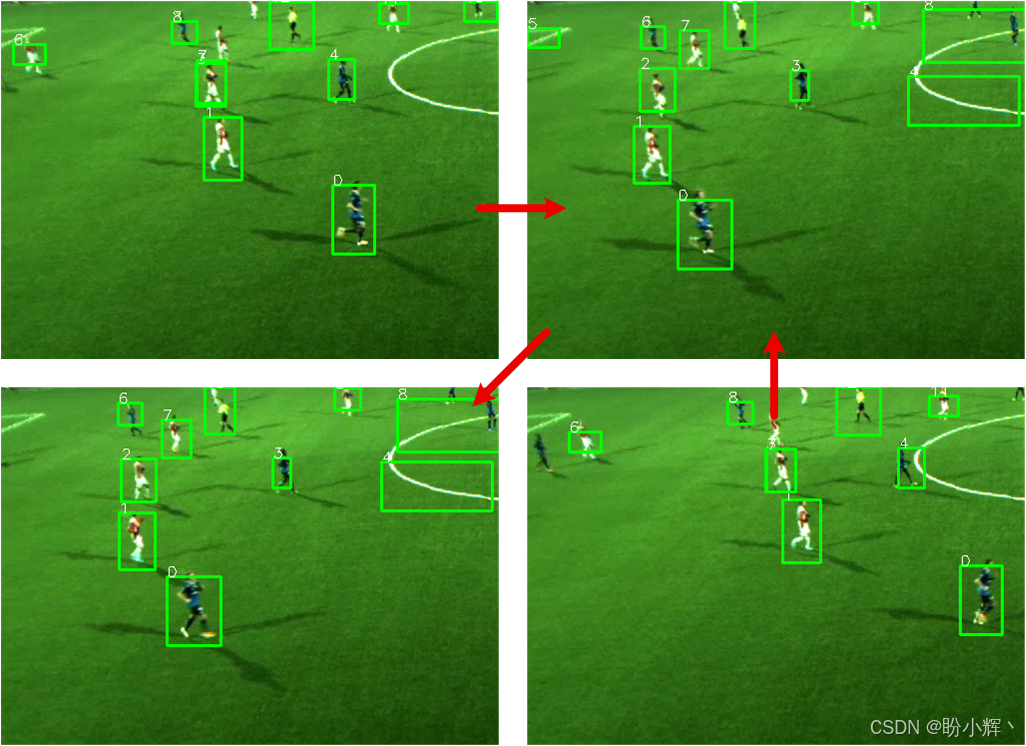
正如这四张截图所示,一旦定位了图像中所有潜在有趣的图像块,我们就可以使用一种简单而有效的方法------称为"物体均值漂移跟踪"------来跟踪它们在多帧之间的运动。由于场景中可能存在多个原始物体,并且它们的外观可能随时间变化,我们需要能够区分它们并持续跟踪所有物体。
2. 规划应用程序
为了构建这个应用程序,我们需要结合前面讨论的两个主要功能:显著性图和物体跟踪。最终的应用程序将把视频序列中的每一帧 RGB 图像转换为显著性图,提取所有有趣的原始物体,并将它们输入均值漂移跟踪算法。为此,我们需要以下组件:
main:启动应用程序的主要功能例程(在tracking_visually_salient.py中)saliency.py:这是一个从RGB彩色图像生成显著性图和原始物体图的模块。它包含以下函数:get_saliency_map:将RGB彩色图像转换为显著性图的函数get_proto_objects_map:将显著性图转换为包含所有原始物体的二值掩模的函数plot_power_density:显示RGB彩色图像的二维功率密度的函数,有助于理解傅里叶变换plot_power_spectrum:显示RGB彩色图像的径向平均功率谱的函数,有助于理解自然图像统计特性MultiObjectTracker:这是一个使用均值漂移跟踪在视频中跟踪多个物体的类。它包含以下公共方法:MultiObjectTracker.advance_frame:更新新一帧跟踪信息的方法,使用当前帧显著性图上的均值漂移算法,将上一帧的边界框位置更新到当前帧MultiObjectTracker.draw_good_boxes:在当前帧中绘制跟踪结果的方法
在以下各小节中,我们将详细讨论这些步骤。
2. 搭建应用程序
为了运行我们的应用程序,我们需要执行主函数,该函数读取视频流的一帧,生成显著性图,提取原始物体的位置,并在帧与帧之间跟踪这些位置。
2.1 实现主函数
主流程由 tracking_visually_salient.py 中的 main 函数处理,该函数实例化跟踪器 (MultipleObjectTracker) 并打开一个视频文件,显示球场上的球员人数:
python
import cv2
from os import path
from saliency import get_saliency_map, get_proto_objects_map
from tracking import MultipleObjectsTracker
import time
def main(video_file='soccer.avi', roi=((140, 100), (500, 600))):
if not path.isfile(video_file):
print(f'File "{video_file}" does not exist.')
raise SystemExit
video = cv2.VideoCapture(video_file)
mot = MultipleObjectsTracker()然后,该函数将逐帧读取视频,并提取一个有意义的感兴趣区域:
python
for _, img in iter(video.read, (False, None)):
if roi:
# original video is too big: grab some meaningful ROI
img = img[roi[0][0]:roi[1][0], roi[0][1]:roi[1][1]]之后,感兴趣区域将被传递给一个函数,该函数会生成该区域的显著性图。接着,基于显著性图生成有趣的原始物体,最后将原始物体与感兴趣区域一起输入跟踪器。跟踪器的输出是带有边界框标注的输入区域,如前面的截图序列所示:
python
saliency = get_saliency_map(img, use_numpy_fft=False,
gauss_kernel=(3, 3))
objects = get_proto_objects_map(saliency, use_otsu=False)
cv2.imshow('original', img)
cv2.imshow('saliency', saliency)
cv2.imshow('objects', objects)
cv2.imshow('tracker', mot.advance_frame(img, objects,saliency))应用程序将遍历视频的所有帧,直到到达文件末尾或用户按下 q 键:
python
if cv2.waitKey(100) & 0xFF == ord('q'):
break在下一小节中,我们将学习 MultiObjectTracker 类。
2.2 MultiObjectTracker 类
跟踪器类的构造函数很简单。它所做的只是设置均值漂移跟踪的终止准则,并存储在后续计算步骤中需要考虑的最小轮廓面积 (min_area) 和按物体尺寸归一化的最小平均速度 (min_speed_per_pix) 的条件:
python
def __init__(self, min_object_area: int = 400,
min_speed_per_pix: float = 0.02):
self.object_boxes = []
self.min_object_area = min_object_area
self.min_speed_per_pix = min_speed_per_pix
self.num_frame_tracked = 0
self.term_crit = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT,
5, 1)此后,用户可以调用 advance_frame 方法向跟踪器输入新的一帧。然而,在利用所有这些功能之前,我们需要了解图像统计以及如何生成显著性图。
3. 绘制视觉显著性图
正如本节前面提到的,视觉显著性试图描述某些物体或项目能够立即吸引我们注意力的视觉特性。我们的大脑不断地将目光导向视觉场景中的重要区域,就好像用手电筒照亮视觉世界的不同子区域一样,使我们能够快速扫描周围环境以寻找有趣的物体和事件,同时忽略不太重要的部分。
这被认为是一种进化策略,用于应对生活在视觉丰富环境中持续不断的信息过载。例如,当我们在丛林中随意行走时,会希望在欣赏面前蝴蝶翅膀上复杂的色彩图案之前,能够注意到左边灌木丛中正在准备攻击的老虎。因此,视觉上显著的物体具有从周围环境中"脱颖而出"的显著特性,就像下图中作为目标的长条一样:

识别使这些目标"脱颖而出"的视觉特征可能并不总是那么简单。如果在彩色状态下观看左侧图像,可能会立刻注意到图中唯一的那根红色长条。但是,如果以灰度模式观看这张图像,目标长条可能就有点难找了。
与颜色显著性类似,右侧图像中也存在一个视觉上显著的长条。尽管左侧图像中的目标长条具有独特的颜色,右侧图像中的目标长条具有独特的方向,但当我们把这两种特征放在一起时,那个独特的目标长条突然就不再那么"脱颖而出"了:

在上图中,同样有一根独特且与其他所有长条不同的长条。但是,由于干扰项的设计方式,几乎没有显著性线索能引导我们找到目标长条。相反,我们会发现自己似乎在随机地扫描图像,寻找有趣的东西。(提示:目标是图中唯一红色且近乎垂直的长条)
你可能会问,这与计算机视觉有什么关系?实际上,关系相当大。人工视觉系统也饱受信息过载之苦,它们对世界的了解比我们更少。我们能否从生物学中提取一些见解,并用它们来教会我们的算法一些关于世界的知识?
想象一下,车上的行车记录仪能自动聚焦到最相关的交通标志上;野生动物观测站的监控摄像头能自动检测并跟踪鸭嘴兽的踪迹,而忽略其他。我们该如何教会算法什么是重要的、什么是不重要的?我们又如何让那只鸭嘴兽"脱颖而出"?由此,我们进入了傅里叶分析的领域。
3.1 傅里叶分析
要找到图像中视觉上显著的子区域,我们需要观察其频谱。到目前为止,我们一直在空间域中处理所有图像和视频帧,即通过分析像素或研究图像强度在图像不同子区域中的变化。然而,图像也可以在频率域中表示,即通过分析像素频率或研究像素在图像中出现的频率和周期性。
通过对图像应用傅里叶变换,可以将其从空间域转换到频率域。在频率域中,我们不再以图像坐标 ( x , y ) (x, y) (x,y) 来思考,而是致力于寻找图像的频谱。傅里叶的思想基本上可以归结为这样一个问题:如果任何信号或图像都可以转换为一系列圆形路径(也称为谐波)的叠加,那会怎样?
例如,在彩虹中,白色的阳光(由许多不同的颜色或光谱成分组成)被分散成它的频谱。在这里,阳光的光谱在光线穿过水滴时显露出来(就像白光穿过玻璃棱镜一样)。傅里叶变换的目标是同样的------恢复阳光中包含的所有不同光谱成分。
对于任意图像,也可以实现类似的效果。与彩虹中频率对应电磁频率不同,在图像中我们考虑的是空间频率,即像素值的空间周期性。在一张扶梯图像中,可以把空间频率理解为相邻两根栏杆之间距离的倒数。
从这种视角转变中获得的见解非常强大。在不深入细节的情况下,我们只需指出,傅里叶频谱同时包含幅值和相位。幅值描述了图像中不同频率的数量/多少,而相位则描述了这些频率的空间位置。下图左侧显示了一张图像,右侧显示了其(灰度版本的)对应的傅里叶幅值频谱:

右侧的幅值频谱告诉我们,在左侧图像的灰度版本中,哪些频率成分是最突出(最亮)的。该频谱经过调整,使得图像中心对应于 x x x 和 y y y 方向上的零频率。越往图像边缘移动,频率就越高。这个特定的频谱告诉我们,左侧图像中存在大量的低频成分(聚集在图像中心附近)。
在 OpenCV 中,这种转换可以借助离散傅里叶变换 (Discrete Fourier Transform, DFT) 来实现。让我们构造一个完成此功能的函数。它包含以下步骤:
(1) 首先,如有必要,将图像转换为灰度。该函数同时接受灰度图像和 RGB 彩色图像,因此我们需要确保操作的是单通道图像:
python
def calc_magnitude_spectrum(img: np.ndarray):
if len(img.shape) > 2:
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)(2) 我们将图像调整为最佳尺寸。事实证明,DFT 的性能取决于图像尺寸。当图像尺寸是 2 的倍数时,DFT 的运行速度通常最快。因此,通常建议用 0 填充图像:
python
rows, cols = img.shape
nrows = cv2.getOptimalDFTSize(rows)
ncols = cv2.getOptimalDFTSize(cols)
frame = cv2.copyMakeBorder(img, 0, ncols - cols, 0, nrows - rows,
cv2.BORDER_CONSTANT, value=0)(3) 然后应用 DFT。在 NumPy 中只需调用一个函数。结果是一个二维复数矩阵:
python
img_dft = np.fft.fft2(img)(4) 接着,将实部和虚部转换为幅值。一个复数包含实部和虚部。要提取幅值,我们取其绝对值:
python
magn = np.abs(img_dft)(5) 然后转换为对数刻度。事实证明,傅里叶系数的动态范围通常太大,无法在屏幕上直接显示。我们既有低值也有高值的变化,这样是无法观察清楚的。因此,高值都会显示为白点,低值则显示为黑点。为了使用灰度值进行可视化,我们可以将线性刻度转换为对数刻度:
python
log_magn = np.log10(magn)(6) 接着进行象限交换,将频谱中心移到图像中央。这样更便于目视检查幅值频谱:
python
spectrum = np.fft.fftshift(log_magn)(7) 返回绘图用的结果:
python
return spectrum/np.max(spectrum)*255现在我们理解了图像的傅里叶频谱是什么以及如何计算,接下来分析自然场景统计特性。
3.2 自然场景统计特征
人类大脑早在很久以前就弄清楚了如何聚焦于视觉上显著的物体。我们赖以生存的自然世界具有某些统计规律性,这些规律性使其区别于棋盘图案或随机的公司标志,具有独特的"自然"属性。最广为人知的统计规律可能就是 1 / f 1/f 1/f 定律。该定律指出,自然图像集合的振幅服从 1 / f 1/f 1/f 分布(如下图所示)。这有时也被称为尺度不变性。
二维图像的一维功率谱(作为频率的函数)可以通过以下 plot_power_spectrum 函数进行可视化。我们可以使用与之前幅值频谱类似的步骤,但必须确保正确地将二维频谱压缩到单个轴上:
(1) 定义函数,并在必要时将图像转换为灰度:
python
def plot_power_spectrum(frame: np.ndarray, use_numpy_fft=True) -> None:
if len(frame.shape) > 2:
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)(2) 将图像扩展到最佳尺寸:
python
rows, cols = frame.shape
nrows = cv2.getOptimalDFTSize(rows)
ncols = cv2.getOptimalDFTSize(cols)
frame = cv2.copyMakeBorder(frame, 0, ncols - cols, 0, nrows - rows,
cv2.BORDER_CONSTANT, value=0)(3) 然后应用 DFT 并得到对数频谱。这里我们通过 use_numpy_fft 标志给用户提供一个选项,可以选择使用 NumPy 或 OpenCV 的傅里叶工具:\
python
if use_numpy_fft:
img_dft = np.fft.fft2(frame)
spectrum = np.log10(np.real(np.abs(img_dft))**2)
else:
img_dft = cv2.dft(np.float32(frame), flags=cv2.DFT_COMPLEX_OUTPUT)
spectrum = np.log10(img_dft[:, :, 0]**2 + img_dft[:, :, 1]**2)(4) 然后执行径向平均。简单地在 x x x 或 y y y 方向上对二维频谱进行平均并不正确,我们感兴趣的是作为频率函数、且与具体方向无关的频谱。这有时也被称为径向平均功率谱 (Radially Averaged Power Spectrum, RAPS)。
可以通过从图像中心开始,沿所有可能的(径向)方向,对从某个频率 r 到 r+dr 范围内的所有频率幅值进行求和来实现。我们使用 NumPy 的直方图分箱函数来累加这些数值,并将结果存储在 histo 变量中:
python
L = max(frame.shape)
freqs = np.fft.fftfreq(L)[:L // 2]
dists = np.sqrt(np.fft.fftfreq(frame.shape[0])[:, np.newaxis]**2 +
np.fft.fftfreq(frame.shape[1])**2)
dcount = np.histogram(dists.ravel(), bins=freqs)[0]
histo, bins = np.histogram(dists.ravel(), bins=freqs,
weights=spectrum.ravel())(5) 然后绘制结果,最终,我们可以绘制出 histo 中累加得到的数值,但切记要按箱大小 (dcount) 进行归一化:
python
centers = (bins[:-1] + bins[1:]) / 2
plt.plot(centers, histo / dcount)
plt.xlabel('frequency')
plt.ylabel('log-spectrum')
plt.show()结果是一个与频率成反比的函数。如果你想绝对确定是否符合 1 / f 1/f 1/f 特性,可以对所有 x x x 值取 np.log10,并确保曲线大致呈线性下降趋势。在线性 x x x 轴和对数 y y y 轴的坐标系下,如下图所示:

这个性质相当显著。它表明,如果我们对所有曾经拍摄过的自然场景图像(当然,排除那些使用花哨图像滤镜拍摄的图像)的频谱进行平均,我们将得到一条与上图中所示非常相似的曲线。
但是,回到小姐姐的图像,单张图像的情况又如何呢?我们刚刚观察了这张图像的功率谱,并验证了其 1 / f 1/f 1/f 特性。我们该如何利用我们对自然图像统计特性的了解,来告诉算法不要盯着人物面部,而是聚焦于在手中的蛋糕呢?如下图所示场景:

这时我们才真正意识到显著性究竟意味着什么。接下来,让我们看看如何通过频谱残差方法来生成显著性图。
3.3 使用频谱残差方法生成显著性图
图像中值得我们注意的,并不是那些遵循 1 / f 1/f 1/f 定律的图像块,而是那些从平滑曲线中"凸现"出来的块,换句话说,就是统计上的异常。这些异常被称为图像的频谱残差,它们对应于图像中潜在有趣的区域(或称为原始物体)。将这些统计异常显示为亮点的图,就叫做显著性图。
单通道的显著性图可以通过 _get_channel_sal_magn 函数,按照以下流程生成。为了基于频谱残差方法生成显著性图,我们需要分别处理输入图像的每个通道(灰度输入图像对应单通道,RGB 彩色输入图像对应三个独立的通道):
(1) 使用 NumPy 的 fft 模块或 OpenCV 的功能,计算图像傅里叶频谱的幅度和相位:
python
def _calc_channel_sal_magn(channel: np.ndarray,
use_numpy_fft: bool = True) -> np.ndarray:
if use_numpy_fft:
img_dft = np.fft.fft2(channel)
magnitude, angle = cv2.cartToPolar(np.real(img_dft),
np.imag(img_dft))
else:
img_dft = cv2.dft(np.float32(channel),
flags=cv2.DFT_COMPLEX_OUTPUT)
magnitude, angle = cv2.cartToPolar(img_dft[:, :, 0],
img_dft[:, :, 1])(2) 计算傅立叶频谱的对数幅度。我们将幅度的下限裁剪为 1e-9,以防止在计算对数时出现除以零的情况
python
log_ampl = np.log10(magnitude.clip(min=1e-9))(3) 通过将图像与局部平均滤波器进行卷积,来近似典型自然图像的平均频谱:
python
log_ampl_blur = cv2.blur(log_ampl, (3, 3))(4) 计算频谱残差。频谱残差主要包含场景中的非平凡(或意外)部分:
python
residual = np.exp(log_ampl - log_ampl_blur)(5) 通过 NumPy 中的 fft 模块或 OpenCV 使用傅立叶逆变换来计算显着性图:
python
if use_numpy_fft:
real_part, imag_part = cv2.polarToCart(residual, angle)
img_combined = np.fft.ifft2(real_part + 1j * imag_part)
magnitude, _ = cv2.cartToPolar(np.real(img_combined),
np.imag(img_combined))
else:
img_dft[:, :, 0], img_dft[:, :, 1] = cv2.polarToCart(residual,
angle)
img_combined = cv2.idft(img_dft)
magnitude, _ = cv2.cartToPolar(img_combined[:, :, 0],
img_combined[:, :, 1])
return magnitudeget_saliency_map 函数使用上述单通道显著性图(幅值),并对输入图像的所有通道重复该过程。如果输入图像是灰度图,那么这一步基本上就完成了:
python
def get_saliency_map(frame: np.ndarray,
small_shape: Tuple[int] = (64, 64),
gauss_kernel: Tuple[int] = (5, 5),
use_numpy_fft: bool = True) -> np.ndarray:
frame_small = cv2.resize(frame, small_shape)
if len(frame.shape) == 2:
# single channelsmall_shape[1::-1]
sal = _calc_channel_sal_magn(frame, use_numpy_fft)然而,如果输入图像有多个通道(例如 RGB 彩色图像),则需要分别处理每个通道:
python
else:
# multiple channels: consider each channel independently
sal = np.zeros_like(frame_small).astype(np.float32)
for c in range(frame_small.shape[2]):
small = frame_small[:, :, c]
sal[:, :, c] = _calc_channel_sal_magn(small, use_numpy_fft)然后,通过平均全部通道确定多通道图像的总体显着性:
python
sal = np.mean(sal, axis=2)最后,我们需要进行一些后处理,例如可选的模糊步骤,使结果看起来更平滑:
python
if gauss_kernel is not None:
sal = cv2.GaussianBlur(sal, gauss_kernel, sigmaX=8, sigmaY=0)此外,按照原始论文作者的概述,我们需要对 sal 中的值进行平方,以突显高显著性的区域。为了显示图像,我们将其缩放回原始分辨率并归一化数值,使最大值为 1。
接下来,归一化 sal 中的数值,使最大值为 1,然后按照原始论文作者的概述进行平方以突显高显著性区域,最后缩放回原始分辨率以便显示图像:
python
if gauss_kernel is not None:
sal = cv2.GaussianBlur(sal, gauss_kernel, sigmaX=8, sigmaY=0)
sal = sal**2
sal = np.float32(sal)/np.max(sal)
sal = cv2.resize(sal, frame.shape[1::-1])
sal /= np.max(sal)
return cv2.resize(sal ** 2, frame.shape[1::-1])得到的显著性图如下图所示:

现在我们可以清楚地看到图中的人脸(位于左上角),它是图像中最显著的子区域之一。图中还有其他显著区域,例如下方的枕头。
在下一小节中,我们将学习如何检测场景中的原始物体。
3.4 检测场景中的原始物体
从某种意义上说,显著性图已经是原始物体的一种显式表示,因为它只包含图像中感兴趣的部分。所以,既然我们已经完成了所有繁重的工作,要获得原始物体图,剩下的工作就是对显著性图进行阈值化处理。
这里唯一需要考虑的开放参数就是阈值。阈值设置过低会导致大量区域被标记为原始物体,其中可能包括一些不含任何感兴趣内容的区域(虚警)。另一方面,阈值设置过高则会忽略图像中大部分显著区域,可能导致我们根本找不到任何原始物体。
原始谱残差方法的作者选择将图像中那些显著度大于图像平均显著度三倍的区域标记为原始目标。我们允许用户选择实现这一阈值方法,或者通过将输入标志 use_otsu 设置为 True 来使用 Otsu 阈值方法:
python
def get_proto_objects_map(saliency: np.ndarray, use_otsu=True) -> np.ndarray:然后,我们将显著图转换为 uint8 精度,以便将其传递给 cv2.threshold,设置阈值处理的参数,最后应用阈值处理并返回原始物体:
python
saliency = np.uint8(saliency * 255)
if use_otsu:
thresh_type = cv2.THRESH_OTSU
# For threshold value, simply pass zero.
thresh_value = 0
else:
thresh_type = cv2.THRESH_BINARY
thresh_value = np.mean(saliency) * 3
_, img_objects = cv2.threshold(saliency,
thresh_value, 255, thresh_type)
return img_objects得到的原始物体掩码如下所示:

该原始物体掩码随后将作为跟踪算法的输入,我们将在下一小节中介绍。
4. 均值漂移跟踪
到目前为止,我们使用前面讨论的显著性检测器来寻找原始物体的边界框。我们可以简单地将该算法应用于视频序列的每一帧,从而获得物体位置的良好估计。然而,这样做会丢失对应信息。
想象一个繁忙场景的视频序列,例如城市中心或体育场馆的录像。尽管显著图可以在录制视频的每一帧中高亮显示所有原始物体,但该算法无法建立前一帧原始物体与当前帧原始目标之间的对应关系。
另外,原始物体图可能包含一些误报,我们需要一种方法来选择最可能对应于真实世界目标的边界框。在以下示例中可以观察到这种误报:
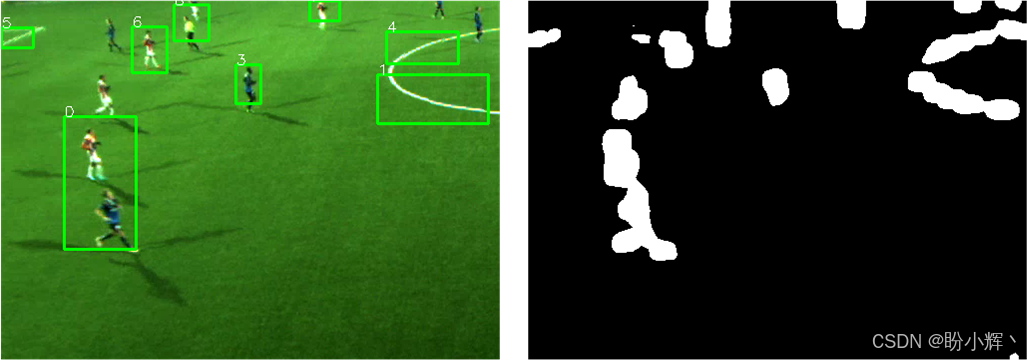
可以看到,从上图中从原始物体图中提取的边界框至少犯了三个错误:它漏掉了一名球员(左上角)、将两名球员合并到同一个边界框中,还高亮了一些额外的、虽然有视觉显著性但未必有趣的物体。为了改进这些结果并保持对应关系,我们希望利用跟踪算法。
要解决对应问题,我们可以使用之前学过的方法,例如特征匹配和光流法,但在本节中,我们将使用均值漂移算法进行跟踪。
均值漂移是一种简单但非常有效的物体跟踪技术。均值漂移背后的直观思想是,将感兴趣小区域(例如,我们要跟踪的物体的边界框)内的像素视为从某个最能描述目标的基础概率密度函数中采样得到的点。
例如,考虑下图:
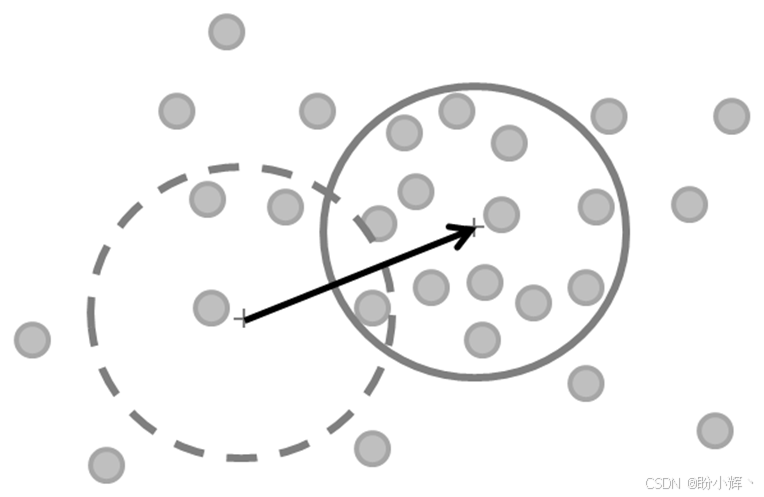
图中,灰色小点表示从一个概率分布中采样得到的样本。假设点之间的距离越近,它们彼此之间越相似。直观来说,均值漂移试图做的是找到这个分布中最密集的区域,并在其周围画一个圆。算法可能一开始将一个圆放在一个并不密集的区域上(虚线圆),随着时间的推移,它会逐渐向最密集的区域移动(实线圆),并最终固定在那里。
如果我们把这个分布设计得比简单的点更有意义,就可以使用均值漂移跟踪来找到场景中感兴趣的物体。例如,如果我们给每个点赋予一个数值,表示物体的颜色直方图与该物体相同大小的图像邻域的颜色直方图之间的匹配程度,那么我们就可以对得到的点集应用均值漂移来跟踪该物体。后者正是通常与均值漂移跟踪相关联的方法。在本节中,我们将直接使用显著性图本身。
均值漂移有许多应用(例如聚类、寻找概率密度函数的众数),但它也特别适合目标跟踪。在 OpenCV 中,该算法通过 cv2.meanShift 实现,它接受一个二维数组(例如灰度图像,如显著性图)和一个窗口(在本节中,使用物体的边界框)作为输入。它根据均值漂移算法返回窗口的新位置,步骤如下:
- 固定一个窗口位置
- 计算窗口内数据的平均值
- 将窗口移动到均值位置,重复直到收敛。我们可以通过指定终止条件来控制迭代方法的长度和精度
接下来,我们看看该算法如何跟踪并用边界框在视觉上标出场上的球员。
4.1 自动跟踪足球场上的所有球员
我们的目标是将显著性检测器与均值漂移跟踪相结合,自动跟踪足球场上的所有球员。由显著性检测器识别出的原始物体将作为均值漂移跟踪器的输入。具体来说,我们将使用来自 Alfheim 数据集的一个视频序列,该数据集可以免费获取。
将这两种算法(显著性图与均值漂移跟踪)结合的原因是为了保持不同帧之间物体的对应信息,同时去除一些误报并提高检测物体的准确性。
主要工作由前面介绍的 MultiObjectTracker 类及其 advance_frame 方法完成。每当新的一帧到来时,就会调用 advance_frame 方法,该方法接收原始物体图 (proto_objects) 和显著性图 (saliency) 作为输入:
python
def advance_frame(self,
frame: np.ndarray,
proto_objects_map: np.ndarray,
saliency: np.ndarray) -> np.ndarray:该方法包含以下步骤:
(1) 从 proto_objects_map 中创建轮廓,并找出所有面积大于 min_object_area 的轮廓的边界矩形。后者是用于均值漂移跟踪的候选边界框:
python
object_contours, _ = cv2.findContours(proto_objects_map, 1, 2)
object_boxes = [cv2.boundingRect(contour)
for contour in object_contours
if cv2.contourArea(contour) > self.min_object_area](2) 候选框可能并非最适合在帧间进行跟踪的框。例如,在这种情况下,如果两名球员彼此靠近,它们会合并成一个物体框。我们需要某种方法来筛选出最优的框。可以考虑设计某种算法,结合从上一帧跟踪到的框和从显著性图中获得的框,来推断出最可能的框。
但这里我们采用一种简单的方法:如果从显著性图中得到的框数量没有增加,则使用当前帧的显著性图,将上一帧中的框跟踪到当前帧,并将结果保存为 object_boxes:
python
if len(self.object_boxes) >= len(object_boxes):
object_boxes = [cv2.meanShift(saliency, box, self.term_crit)[1]
for box in self.object_boxes]
self.num_frame_tracked += 1(3) 如果框数量增加了,则重置跟踪信息,即重置物体被跟踪的帧数,并重新计算物体的初始中心:
python
else:
self.num_frame_tracked = 0
self.object_initial_centers = [
(x + w / 2, y + h / 2) for (x, y, w, h) in object_boxes](4) 最后,保存这些框,并在当前帧上绘制跟踪信息的可视化结果:
python
self.object_boxes = object_boxes
return self.draw_good_boxes(copy.deepcopy(frame))我们只关注那些会移动的框。为此,我们计算每个框从其跟踪开始时的初始位置发生的位移。我们假设在帧中看起来更大的物体应该移动得更快,因此我们按框的宽度对位移进行归一化:
python
def draw_good_boxes(self, frame: np.ndarray) -> np.ndarray:
displacements = [((x + w / 2 - cx)**2 + (y + w / 2 - cy)**2)**0.5 / w
for (x, y, w, h), (cx, cy)
in zip(self.object_boxes, self.object_initial_centers)]接下来,我们绘制那些平均每帧位移(即速度)大于跟踪器初始化时指定的阈值的边界框及其编号。为了避免在跟踪的第一帧出现除以零的情况,我们在分母上加了一个小常数:
python
for (x, y, w, h), displacement, i in zip(
self.object_boxes, displacements, itertools.count()):
# Draw only those which have some avarage speed
if displacement / (self.num_frame_tracked + 0.01) > self.min_speed_per_pix:
cv2.rectangle(frame, (x, y), (x + w, y + h),
(0, 255, 0), 2)
cv2.putText(frame, str(i), (x, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255))
return frame现在,我们已经了解了如何使用均值漂移算法来实现跟踪。这只是众多跟踪方法中的一种。当物体尺寸快速变化时(例如感兴趣的物体径直朝相机运动),均值漂移跟踪可能会失效。
针对这种情况,OpenCV 提供了另一种算法 cv2.CamShift,它还会考虑旋转和尺寸变化,其中 CAMShift 代表"连续自适应均值漂移" (Continuously Adaptive Mean-Shift)。此外,OpenCV 还有一系列可直接使用的跟踪器,统称为 OpenCV 跟踪 API。我们将在下一小节中学习它们。
5. OpenCV 跟踪 API
我们已经将均值漂移算法应用于显著性图来跟踪显著物体。当然,并非世界上所有物体都是显著的,因此我们不能用这种方法来跟踪任意物体。如前所述,我们也可以将 HSV 直方图与均值漂移算法结合来跟踪物体。后者不需要显著性图------只要选定一个区域,该方法就会尝试在后续帧中跟踪选定的物体。
在本节中,我们将创建一个脚本,能够使用 OpenCV 中可用的跟踪算法在整个视频中跟踪一个物体。所有这些算法都具有相同的 API,统称为 OpenCV 跟踪 API。这些算法用于跟踪单个物体------一旦向算法提供初始边界框,它就会尝试在后续帧中维持该框的新位置。当然,我们也可以为场景中的每个物体分别创建跟踪器,从而实现多物体跟踪。
首先,导入我们将使用的库并定义常量:
python
import argparse
import time
import cv2
import numpy as np
# Define Constants
FONT = cv2.FONT_HERSHEY_SIMPLEX
GREEN = (20, 200, 20)
RED = (20, 20, 255)定义一个包含所有跟踪器构造函数的映射表:
python
trackers = {
'BOOSTING': cv2.TrackerBoosting_create,
'MIL': cv2.TrackerMIL_create,
'KCF': cv2.TrackerKCF_create,
'TLD': cv2.TrackerTLD_create,
'MEDIANFLOW': cv2.TrackerMedianFlow_create,
'GOTURN': cv2.TrackerGOTURN_create,
'MOSSE': cv2.TrackerMOSSE_create,
'CSRT': cv2.TrackerCSRT_create
}我们的脚本将能够接受跟踪器名称和视频路径作为参数。为此,我们创建参数,设置其默认值,并使用之前导入的 argparse 模块进行解析:
python
parser = argparse.ArgumentParser(description='Tracking API demo.')
parser.add_argument(
'--tracker',
default="KCF",
help=f"One of {trackers.keys()}")
parser.add_argument(
'--video',
help="Video file to use",
default="videos/test.mp4")
args = parser.parse_args()然后,我们确保存在这样的跟踪器,并尝试从指定视频中读取第一帧。
现在我们已经设置好脚本并可以接受参数,接下来要做的是实例化跟踪器:
(1) 首先,最好让脚本不区分大小写,并检查传入的跟踪器是否存在:
python
tracker_name = args.tracker.upper()
assert tracker_name in trackers, f"Tracker should be one of {trackers.keys()}"(2) 打开视频并读取第一帧。如果视频无法读取,则中断脚本:
python
video = cv2.VideoCapture(args.video)
assert video.isOpened(), "Could not open video"
ok, frame = video.read()
assert ok, "Video file is not readable"(3) 选择一个感兴趣区域(使用边界框)用于在整个视频中进行跟踪。OpenCV 提供了一个基于用户界面的实现来完成这一操作:
python
bbox = cv2.selectROI(frame, False)一旦调用此方法,将会出现一个界面,可以在其中选择一个框。按下回车键后,所选框的坐标将被返回。
(4) 使用第一帧和选定的边界框初始化跟踪器:
python
tracker = trackers[tracker_name]()
tracker.init(frame, bbox)现在,我们有了一个跟踪器实例,该实例已使用第一帧初始化并选定了感兴趣的边界框。我们使用后续帧更新跟踪器,以找到物体在边界框中的新位置。同时,我们使用 time 模块估算所选跟踪算法的每秒帧数 (frames per second, FPS):
python
for ok, frame in iter(video.read, (False, None)):
start_time = time.time()
ok, bbox = tracker.update(frame)
fps = 1 / (time.time() - start_time)至此,所有计算都已完成。现在,我们为每次迭代绘制结果:
python
if ok:
x, y, w, h = np.array(bbox, dtype=np.int)
cv2.rectangle(frame, (x, y), (x + w, y + w), GREEN, 2, 1)
else:
cv2.putText(frame, "Tracking failed", (100, 80), FONT, 0.7, RED, 2)
cv2.putText(frame, f"{tracker_name} Tracker",
(100, 20), FONT, 0.7, GREEN, 2)
cv2.putText(frame, f"FPS : {fps:.0f}", (100, 50), FONT, 0.7, GREEN, 2)
cv2.imshow("Tracking", frame)
if cv2.waitKey(1) & 0xff == 27:
break如果算法返回了一个边界框,我们就在当前帧上绘制该框;否则,我们标记跟踪失败,这意味着所选算法未能在当前帧中找到物体。同时,我们在帧上显示跟踪器的名称和当前的 FPS。
可以在不同的视频上使用不同的算法运行此脚本,以观察算法的表现,特别是它们如何处理遮挡、快速运动的物体以及外观变化很大的物体。尝试完这些算法后,也可以阅读这些算法的原始论文,以了解实现细节。
为了使用这些算法跟踪多个物体,OpenCV 提供了一个便捷的包装类,可以组合多个跟踪器实例并同时更新它们。要使用它,首先创建一个该类的实例:
python
multiTracker = cv2.MultiTracker_create()接下来,对每个感兴趣的边界框,创建一个新的跟踪器(此处使用 MIL 跟踪器),并将其添加到 multiTracker 对象中:
python
for bbox in bboxes:
multiTracker.add(cv2.TrackerMIL_create(), frame, bbox) 最后,通过使用新的一帧更新 multiTracker 对象,获得边界框的新位置:
python
success, boxes = multiTracker.update(frame)我们也可以尝试用本章介绍的其中一种跟踪器,来替换应用程序中用于跟踪显著物体的均值漂移跟踪方法。具体实现时,可以使用 multiTracker 配合其中一种跟踪器,来更新原始物体边界框的位置。
6. 综合实践
应用程序的运行结果如下图所示:
在整个视频序列中,该算法能够捕捉球员的位置,并通过均值漂移跟踪逐帧成功跟踪他们。
小结
本节我们探索了一种标记视觉场景中潜在有趣物体的方法,即使这些物体的形状和数量都是未知的。我们利用傅里叶分析研究了自然图像统计特性,并实现了一种提取自然场景中视觉显著区域的方法。此外,我们将显著性检测器的输出与跟踪算法相结合,在一个足球比赛视频序列中跟踪了多个形状和数量未知的物体。我们还介绍了 OpenCV 中其他更复杂的跟踪算法,可以用它们替代应用程序中的均值漂移跟踪,甚至创建自己的应用程序。当然,也可以用之前学过的技术(如特征匹配或光流法)来替换均值漂移跟踪器。
系列链接
OpenCV-Python实战(1)------OpenCV简介与图像处理基础
OpenCV-Python实战(2)------图像与视频文件的处理
OpenCV-Python实战(3)------OpenCV中绘制图形与文本
OpenCV-Python实战(4)------OpenCV常见图像处理技术
OpenCV-Python实战(5)------OpenCV图像运算
OpenCV-Python实战(6)------OpenCV中的色彩空间和色彩映射
OpenCV-Python实战(8)------直方图均衡化
OpenCV-Python实战(9)------OpenCV用于图像分割的阈值技术
OpenCV-Python实战(10)------OpenCV轮廓检测
OpenCV-Python实战(11)------OpenCV轮廓检测相关应用
OpenCV-Python实战(12)------一文详解AR增强现实
OpenCV-Python实战(13)------OpenCV与机器学习的碰撞
OpenCV-Python实战(14)------人脸检测详解
OpenCV-Python实战(15)------面部特征点检测详解
OpenCV-Python实战(16)------人脸追踪详解
OpenCV-Python实战(17)------人脸识别详解
OpenCV-Python实战(18)------深度学习简介与入门示例
OpenCV-Python实战(19)------OpenCV与深度学习的碰撞
OpenCV-Python实战(20)------OpenCV计算机视觉项目在Web端的部署
OpenCV-Python实战(21)------OpenCV人脸检测项目在Web端的部署
OpenCV-Python实战(22)------使用Keras和Flask在Web端部署图像识别应用
OpenCV-Python实战(23)------将OpenCV计算机视觉项目部署到云端
OpenCV-Python实战(24)------打造实时图像滤镜系统
OpenCV-Python实战(25)------基于深度传感器与凸性分析打造实时手势识别系统
OpenCV-Python实战(26)------复杂场景下的实时物体检测与跟踪