导读
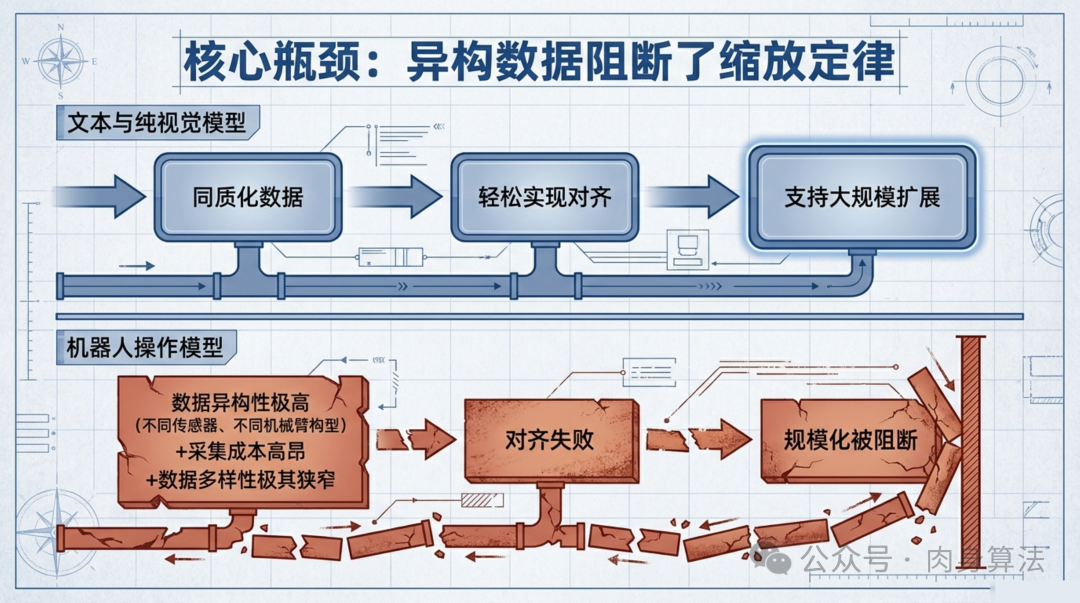
一个让人不安的事实是:大语言模型早已能流畅地写诗、编程、做数学推理,但全世界最好的机器人仍然连稳定地叠一件毛巾都做不到。问题出在哪里?不是算法不够聪明,而是数据太碎了------每个实验室的机械臂型号不同、传感器不同、坐标系不同,采集来的操作数据就像用十几种方言写成的菜谱,混在一起训练只会让模型更困惑。
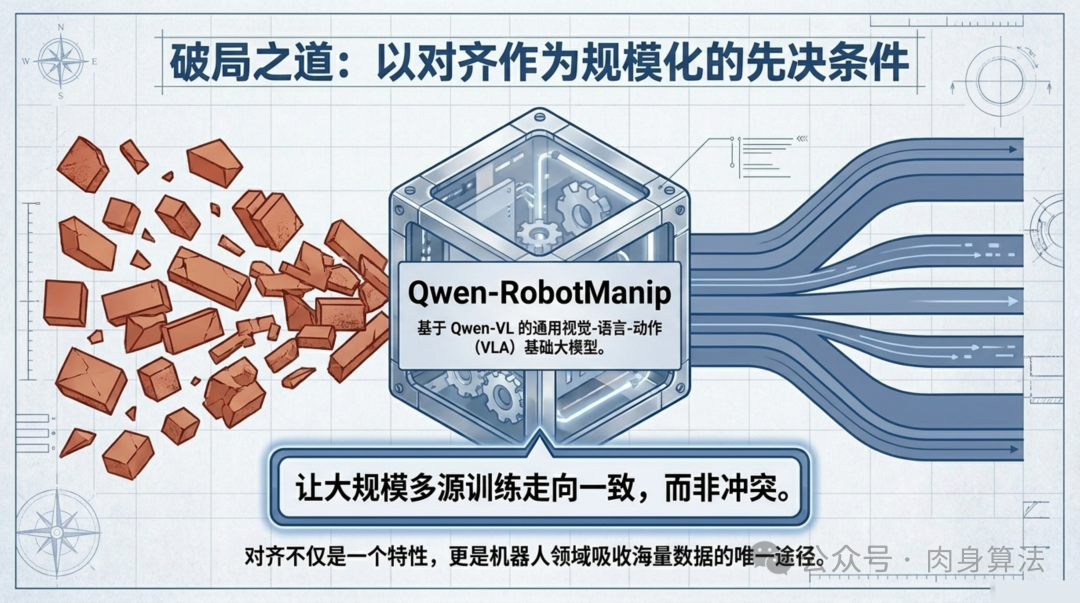
阿里巴巴 Qwen 团队在 2026 年 6 月 16 日发布的 Qwen-RobotManip 给出了一个直击要害的回答:与其试图统一数据格式,不如让模型自己学会"翻译"。通过一套覆盖表示、运动、行为三个维度的统一对齐框架,这个基于 Qwen-VL 构建的 VLA(视觉-语言-动作)基座模型,成功消化了 38,100 小时的开源训练数据------而且一分钱私有数据都没花。
结果?RoboChallenge 竞赛排名第一,相对提升 20%;在 6 个分布外测试集上全面碾压 pi-0.5 等前沿模型;在 ALOHA、Franka、UR、ARX 四种真实机器人上完成部署验证。这不是又一个刷榜论文,而是一次关于"规模化法则能否在机器人领域复现"的系统性回答。
背景与动机
大模型的成功有一个公认的前提:足够大、足够多样的数据,加上统一的训练范式。GPT 系列之所以能涌现出令人惊叹的能力,核心在于文本天然是同质化的------无论英文、中文还是代码,都是 token 序列,可以无缝拼接训练。视觉-语言模型同理,图片和文字虽然模态不同,但通过对比学习等技术已经找到了稳定的对齐方式。
但机器人操作数据完全不一样。一个 Franka 七轴臂采集的抓取轨迹,和一个双臂 ALOHA 录制的叠衣服演示,数据格式天差地别:自由度数量不同、控制频率不同、坐标系定义不同、甚至"成功"的定义都不一样。更要命的是,机器人数据的采集成本极高------一个小时的高质量遥操作数据可能需要一整天的人工标注,这使得任何单一来源的数据集都远远不够用。
过去的解决方案大多走两条路:要么只在单一平台上训练专用模型(放弃通用性),要么强行混合多源数据祈祷模型能自己搞定(通常效果不佳)。Qwen-RobotManip 的核心洞察是:对齐不是预训练的一个附加特性,而是规模化的先决条件。不先解决对齐问题,数据堆得再多也只是噪声。
核心方法
三维对齐框架:让异构数据"说同一种语言"
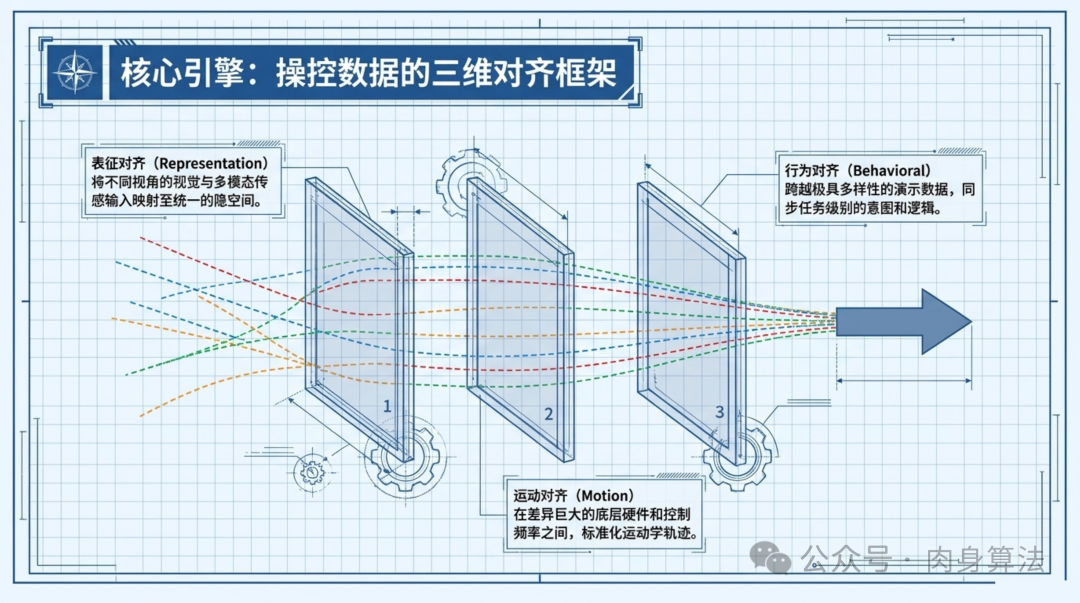
Qwen-RobotManip 的技术核心是一个三维对齐框架(Unified Alignment Framework),分别在表示、运动和行为三个层面上解决异构数据的冲突问题。可以把它想象成一个三层翻译系统:
表示对齐(Representation Alignment) 解决的是"看到的东西怎么统一理解"的问题。不同机器人的摄像头视角、分辨率、安装位置各不相同------有的是头顶俯视,有的是手腕上的第一人称视角,还有的是固定的第三人称摄像头。表示对齐的任务是将这些不同视角的视觉信息和配套的语言指令,映射到同一个语义空间中。这里 Qwen-VL 作为底座模型的优势就体现出来了:它本身就是一个经过大规模视觉-语言预训练的多模态模型,天然具备跨视角、跨场景的视觉理解能力。
运动对齐(Motion Alignment) 处理的是"不同身体怎么做同一个动作"的问题。一个六轴臂和一个七轴臂执行"把杯子放到桌子右边"这个任务,关节角度序列完全不同,但末端执行器的运动轨迹在语义上是一致的。运动对齐通过标准化的运动表示,在差异巨大的底层硬件和控制频率之间建立映射,让模型学到的是"任务级别的运动意图"而非"特定机械臂的关节角度"。
行为对齐(Behavioral Alignment) 是最高层级的对齐,它解决的是"同一个任务在不同数据集里的定义和标注标准不一致"的问题。有些数据集把"抓取成功"定义为"物体离开桌面",有些则要求"物体被稳定握持 3 秒";有些数据用语言指令标注,有些只有视频没有文字说明。行为对齐通过严格的数据策划管线(Curation Pipeline),将这些不同粒度、不同标注规范的数据集协调为一致的训练信号。
三者环环相扣:表示对齐让模型看懂不同视角,运动对齐让模型理解不同身体的动作等价性,行为对齐确保不同来源的任务标注不会自相矛盾。只有三者同时工作,大规模多源训练才不会变成一场灾难。
人机协同合成管线:把 YouTube 视频变成机器人训练数据
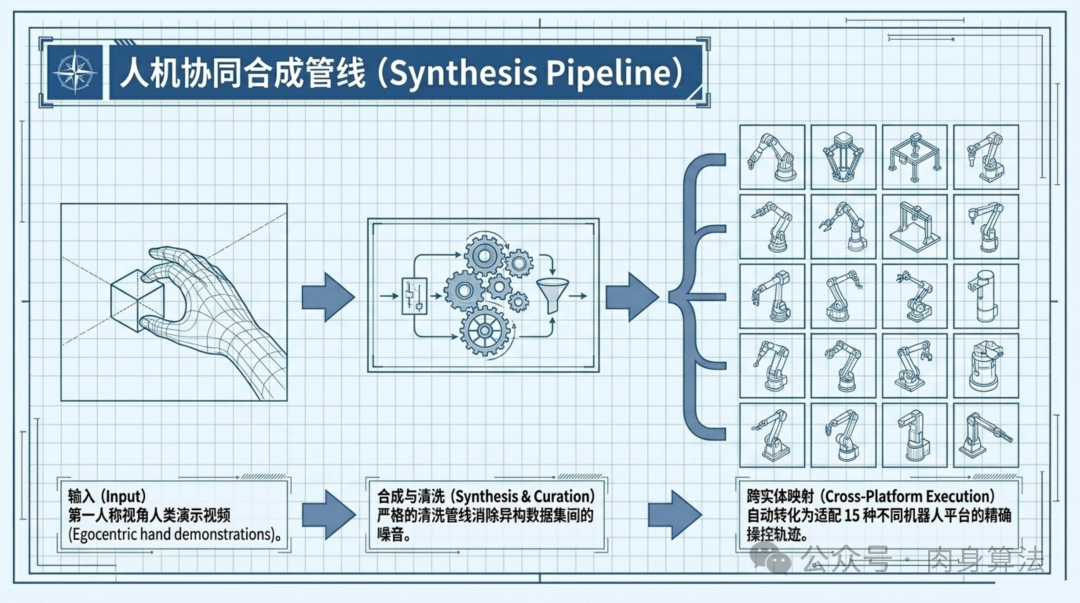
如果说三维对齐框架是 Qwen-RobotManip 的"大脑",那么人机协同合成管线(Human-to-Robot Synthesis Pipeline)就是它的"数据引擎"。
这条管线解决的是一个务实但极其重要的问题:高质量机器人操作数据太少了,但人类做同样事情的视频在互联网上有无穷无尽。管线的输入是第一人称视角(Egocentric)的人手操作演示视频------想象一下,你戴着 GoPro 做饭的视频------输出是可以在 15 种不同机器人平台上执行的操作轨迹。
这个转换过程涉及多个中间步骤:首先从视频中估计手部的 3D 姿态和运动轨迹,然后通过运动重定向(Retargeting)技术将人手的运动映射到不同构型的机械臂末端执行器上,最后通过逆运动学求解生成各平台的关节角度序列。整个过程是全自动的,这意味着只要有人类操作视频,就能源源不断地生成跨平台的训练数据。
正是这条管线让 Qwen-RobotManip 摆脱了对昂贵的遥操作数据采集的依赖,用纯开源数据和人类视频构建了约 38,100 小时的预训练语料库------这个规模比大多数现有的机器人操作数据集大了一到两个数量级。

实验与结果
为什么标准基准不够用了?
Qwen-RobotManip 团队做了一个大胆但合理的决定:放弃传统的分布内(In-Distribution)基准测试。他们的理由很直接------当你的模型在训练数据中见过 LIBERO 的标准环境配置,那 LIBERO 上的高分只能证明你记忆力好,不能证明你真的学会了操作。这就像一个学生反复刷同一套模拟题拿了满分,但换一张真题可能就傻眼。
因此,他们全面采用 OOD(Out-of-Distribution,分布外)设置:RoboCasa365(365 种未见过的厨房场景)、LIBERO-Plus(经过扰动的 LIBERO 变体)、EBench、以及 RoboTwin 系列的三个子集(Clean2Rand、IF、XE)。这些测试环境和训练数据存在系统性差异------场景布局不同、物体外观不同、甚至任务定义的措辞都不同。
全面碾压的 OOD 表现
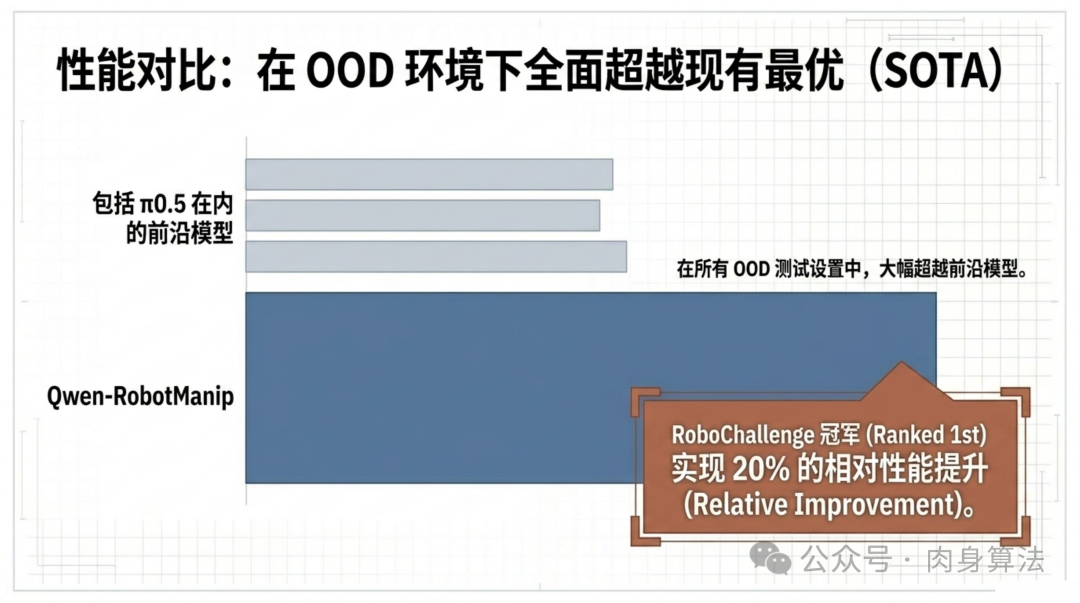
结果令人印象深刻:在所有 OOD 测试集上,Qwen-RobotManip 都大幅超越了包括 pi-0.5 在内的前沿模型。特别值得关注的是 RoboChallenge 竞赛的成绩------排名第一,且实现了 20% 的相对性能提升。这不是在某个指标上的微小优势,而是一个有统计显著性的系统性领先。
更重要的是,这些成绩是在零微调的情况下取得的。模型在面对从未见过的场景、物体和任务指令时,直接展现出了合理的操作策略,这说明三维对齐框架确实让模型学到了可迁移的操作知识,而非单纯的模式记忆。
真实机器人验证
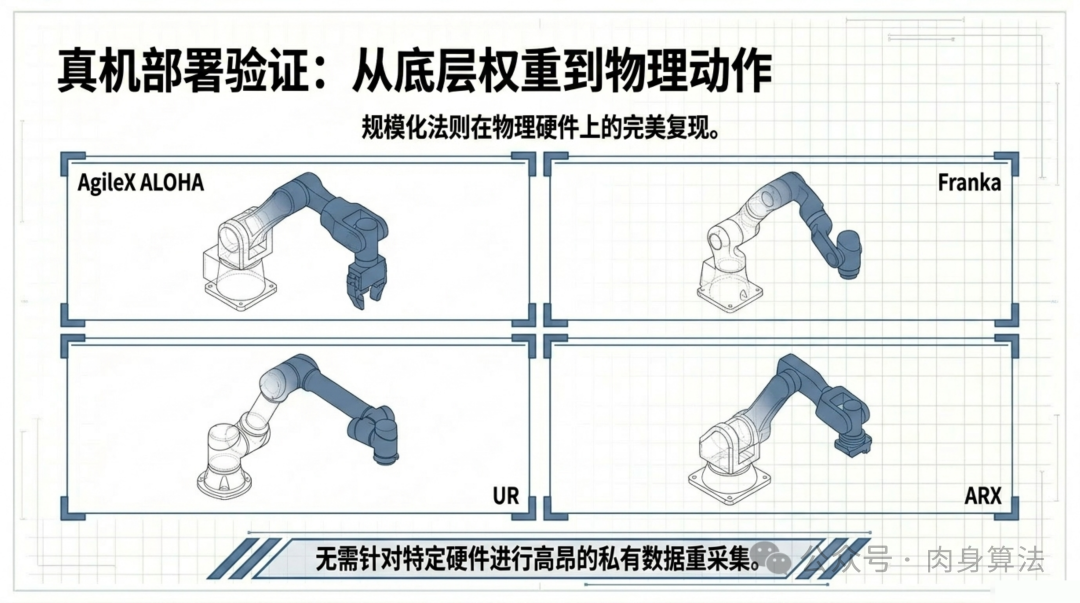
仿真结果再好,不上真机都是纸上谈兵。Qwen-RobotManip 在四个差异极大的真实机器人平台上完成了验证:
-
AgileX ALOHA:双臂协作平台,测试精细的双手配合任务
-
Franka:七自由度工业级机械臂,测试精确操作能力
-
UR:六轴协作机器人,工业场景中最常见的平台
-
ARX:轻量级桌面机械臂,面向研究和教育场景
四种截然不同的硬件构型、不同的自由度、不同的有效载荷------同一个模型权重直接部署,无需针对特定硬件做私有数据采集或专门微调。这才是"通用基座模型"应有的表现。
讨论与思考
对齐即翻译:一个被低估的范式转移
Qwen-RobotManip 的真正创新不在于某个具体的网络模块或训练技巧,而在于思维方式的转变:把机器人数据的异构性问题重新定义为一个对齐问题,而非一个数据格式标准化问题。
过去的做法倾向于从数据端入手------设计统一的数据格式、建立标准化的采集流程、定义通用的任务描述语言。这些努力当然有价值,但它们本质上是在要求整个社区围绕一个标准重新采集数据,可行性极低。Qwen-RobotManip 反其道而行之:让模型去适应数据的多样性,而非让数据去适应模型的偏好。这和 Transformer 架构在 NLP 领域的胜利逻辑一脉相承------不是设计更精巧的特征工程,而是建立足够通用的架构让模型自己从海量数据中学习。
开源数据的价值被严重低估了
38,100 小时的预训练语料,全部来自开源数据集和人类视频 ,这个信息值得反复强调。在一个 pi-0.5 等竞争对手大量使用私有遥操作数据的赛道上,Qwen-RobotManip 用纯开源方案实现了全面超越,这不仅是技术上的胜利,更是一种方法论上的宣言:真正的瓶颈不是数据量,而是数据利用效率。
人机协同合成管线本质上是一种数据放大器------它把互联网上近乎无穷的人类操作视频转化为可用的机器人训练数据。如果这条路线被证明可以持续扩展,那么机器人领域的"数据飞轮"终于可以开始转动了。
评测标准的进化同样重要
团队放弃传统基准、全面转向 OOD 测试的决策,本身就是一个重要的信号。当基座模型的能力进化到一定程度,标准测试集就会"饱和"------所有模型都能拿到接近满分的成绩,失去了区分能力。RoboTwin-XE(跨具身迁移测试)和 RoboCasa365(大规模场景随机化)这样的测试集,代表着评测标准正在追赶模型能力的进步。
这对整个社区有启示意义:不仅要关注"谁在哪个榜上刷了最高分",更要关注"那个榜还能不能反映真正的能力差距"。
局限性与开放问题
尽管成果亮眼,一些开放问题仍值得关注。首先,44 页的技术报告意味着完整的方法细节尚需深入研究------三维对齐框架各维度的具体损失函数设计、人机合成管线的精度上界、以及运动重定向在高精度装配任务上的表现,都是值得追踪的技术细节。其次,目前的验证主要集中在桌面级操作任务上,对于移动操作(Mobile Manipulation)、长时序规划(Long-Horizon Planning)等更复杂的场景,对齐框架是否同样有效,还有待检验。
总结
-
对齐是规模化的前提:Qwen-RobotManip 证明,在机器人操作领域,数据对齐比数据堆量更关键。三维对齐框架(表示、运动、行为)让异构数据从互相冲突变成互相增强。
-
开源数据足够用:38,100 小时的纯开源预训练语料,加上人机协同合成管线,实现了对使用私有数据的竞争对手的全面超越。
-
OOD 才是真实力:在 RoboChallenge 排名第一(相对提升 20%),六个分布外测试集全面领先 pi-0.5,零样本泛化能力已从"有趣的涌现"变成"可复现的工程指标"。
-
一个模型,四种机器人:同一组权重在 ALOHA、Franka、UR、ARX 上直接部署验证,跨具身迁移不再是美好愿景而是可交付的能力。
-
评测标准需要进化:传统分布内基准已经失去区分度,OOD 设置和跨平台测试将成为 VLA 基座模型评估的新常态。