6.3 临时性对象(Temporary Objects)
假如我们有一个函数,形式如下:
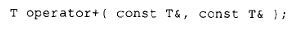
以及两个 T 类的对象 a 和 b,那么表达式:
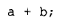
可能会产生一个临时对象来存放返回的结果。是否会生成临时对象,一部分取决于编译器的优化激进程度,另一部分取决于该表达式所处的程序上下文。例如,考虑下面这个程序片段:
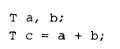
编译器可能会引入一个临时对象来保存 a + b 的结果,然后用这个临时对象通过 T 的拷贝构造函数来初始化 c。然而,更可能的转换方式是直接把 c 构造为该表达式的返回值(参见 2.3 节对加法运算符转换的讨论),从而既消除了临时对象,也省去了与之相关的构造函数和析构函数调用。
此外,根据 operator+() 的具体定义,还可能应用具名返回值优化(NRV,参见 2.3 节)。这样一来,表达式的结果会被直接求值到 c 中,从而避免了拷贝构造函数的调用以及具名对象的析构函数调用。
在这三种情况下,c 的最终值都一样,区别仅在于初始化的开销。那么,编译器是否一定会这样做呢?严格来说,并不一定。标准允许实现(编译器)在临时对象的生成上拥有完全的自由:"在某些情况下,处理器可能需要或方便地生成一个临时对象。至于具体在何时引入这样的临时对象,则由实现定义。(第 12.2 节)"
理论上,标准给了实现完全的自由。但在实践中,市场竞争实际上保证了任何形如:
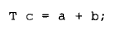
的表达式(其中加法运算符定义为 T operator+( const T&, const T& ); 或 T T::operator+( const T& );)在实现时都不会生成临时对象。
需要指出的是,等价的赋值语句:
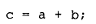
无法安全地消除临时对象。相反,它会产生下面这样的一般序列:

在标有 //1 的行中,尚未构造的临时对象(上图没有显式调用temp的构造函数,可能就意味着没有调用,只是分配了内存,由后续的调用操作来构造)被传给了 operator+()。这意味着,要么表达式的结果通过拷贝构造放入该临时对象,要么该临时对象直接被用作 NRV 优化的目标。在后一种情况下,原本应用于 NRV 的构造函数会被应用到该临时对象上。
无论哪种情况,直接把赋值的目标 c 传给运算符函数都是有问题的。因为该运算符函数返回的是一个对象,返回值应该被构造到c中,但c位置可能已经构造好了对象,如果直接在c处构造返回值,则可能会覆盖c中原数据,导致c中资源泄露,所以c的析构函数需要在调用加法运算符之前被调用。然而,这样一来,转换的语义就变成了用"析构+拷贝构造"来替代赋值操作,即:
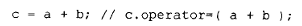
被替换为:
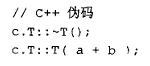
拷贝构造函数、析构函数和拷贝赋值运算符都可能是用户提供的函数,因此无法保证这两种序列具有相同的语义。所以,用"析构+拷贝构造"来替代赋值通常是不安全的,临时对象因此被保留下来。
因此,形如:
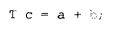
的初始化语句,在实际编译中总是比形如:
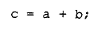
的赋值语句效率更高。
表达式的第三种形式是没有任何目标:
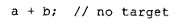
在这种情况下,临时对象是必然要生成的,用来存放表达式的结果。虽然这本身看起来有些奇怪,但在实际编程中,它却常常出现在子表达式里。例如,假设我们有:
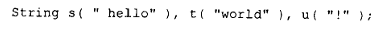
那么无论是:
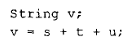
还是:
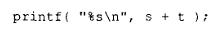
都会为 s + t 这个子表达式生成一个临时对象。
最后一个表达式引出了一个比较晦涩的问题:临时对象的生命周期------这值得我们仔细看看。在标准 C++ 之前,临时对象的生命周期(即它的析构函数何时被调用)被明确地规定为未指定,也就是说由实现决定。这意味着像上面那个 printf() 调用这样的表达式,不能保证一定是安全的,因为它的正确性取决于 s + t 所关联的临时对象在何时被销毁。
在这个 String 类的例子中,我们假设该类定义了一个转换运算符,形式为:
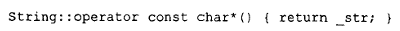
其中 _str 是一个私有成员,指向在 String 对象构造时分配的存储空间,并在其析构函数中被释放。
因此,如果临时对象在调用 printf() 之前就被销毁了,那么转换运算符传给 printf() 的地址就很可能是无效的。实际结果取决于底层 delete 运算符在释放内存时的激进程度------有些实现在将内存标记为空闲后,并不会实际修改其中的内容。在它被其他东西占用之前,这段内存还可以像未被删除一样使用。虽然这显然不是软件工程中值得称道的做法,但这种"在内存释放后仍然访问它"的用法并不少见。事实上,许多 malloc() 的实现甚至提供了特殊的调用方式:
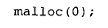
来保证这种"释放后仍可访问"的行为(分配一个大小为0的内存,虽然这一行为是未定义的,也许在某些实现下,刚释放就调用malloc(0)可以继续访问已释放的内存,这不重要,代码里不要用到这一点)。
例如,下面这个在标准之前的转换方式是合法的,但很可能会引发灾难性后果:

另一种(也是在此处更可取的)转换方式,是将 String 的析构函数推迟到 printf() 调用之后执行。在标准 C++ 中,这正是该表达式所要求的转换方式。标准原文为:临时对象在包含其创建点的完整表达式(full-expression)求值的最后一步被销毁。(第 12.2 节)
什么是完整表达式?通俗地说,就是最外层的那个表达式。例如,考虑下面这个例子:

这个完整的 ?: 表达式中包含了 5 个子表达式。这意味着,在这 5 个子表达式中的任何一个里所产生的临时对象,都必须等到整个三元表达式求值完成后才能被销毁。
当临时对象的生成依赖于程序运行时的条件语义时,临时对象生命周期的规则实现起来就变得有些复杂了。例如,下面这个表达式的难点在哪里:

在于 u + v 这个子表达式只有在 s + t 求值为 false 时才会被条件性地求值。与第二个子表达式相关联的临时对象必须被销毁,但显然,它不应该被无条件地销毁。也就是说,我们只希望在这个临时对象确实被创建了的情况下才去销毁它!
在临时对象生命周期规则尚未明确之前,标准的实现方式是把临时对象的初始化和销毁都附着在第二个子表达式的求值上。例如,对于下面这个类声明:

以及下面这个对两个 X 类对象的条件测试:

下面是 cfront 对 main() 生成的程序转换(输出经过略微美化和注释):


这种将临时对象的析构函数放在每个子表达式求值过程中的策略,绕开了"是否需要追踪第二个子表达式是否真正被求值"的问题。然而,在标准 C++ 的临时对象生命周期规则下,这种实现策略不再被允许。临时对象必须等到完整表达式(即表达式两侧都求值完成之后)才被销毁,因此现在必须插入某种形式的条件判断,来决定是否销毁与第二个子表达式相关联的临时对象。
临时对象生命周期规则有两个例外。第一个例外涉及用于初始化对象的表达式,例如:

其中 progName 和 progVersion 都是 String 对象。为了存放加法运算符的结果,会生成一个临时对象:

这个临时对象必须根据 verbose 的测试结果有条件地销毁。按照临时对象生命周期规则,该临时对象应在完整的 ?: 表达式求值完成后立即销毁。然而,如果 progNameVersion 的初始化需要调用拷贝构造函数:

那么在 ?: 表达式求值完成后立即销毁临时对象显然不是我们想要的。因此,标准规定:
......存放表达式结果的临时对象应当持续存在,直到对象的初始化完成为止。
尽管标准在临时对象生命周期方面做了诸多明确规定,但程序员仍然有可能让临时对象在不知情的情况下被销毁。现在的主要区别在于,这种行为现在是良好定义的了。例如,下面这个初始化在新的临时对象生命周期规则下注定会失败:

其中 progName 和 progVersion 同样都是 String 对象。为此生成的代码大致如下:

此时 progNameVersion 指向的已是未定义的堆内存。
临时对象生命周期规则的第二个例外涉及临时对象被绑定到引用的情况。例如:

会生成类似下面的代码:
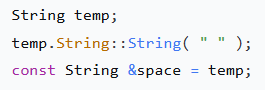
显然,如果此时临时对象被销毁,这个引用就变得几近无用。因此,规则是:
绑定到引用的临时对象,其生命周期延续到该引用被初始化的生命周期结束为止,或者延续到临时对象被创建的作用域结束为止,两者取其先。
临时性对象的迷思、神话、传说(A Temporary Myth,应翻译为一个关于临时对象的误解
)
有一种普遍的看法认为,当前 C++ 实现中临时对象的生成会导致程序执行效率低下,使得 C++ 在科学计算和工程计算领域成为比 FORTRAN 差得多的第二选择。此外,人们认为这种效率的不足抵消了 C++ 更强的抽象能力(参见 BUDGE92 为例)(针对这一立场的反驳,参见 NACK94)。在这方面,BUDGE94 在《The Journal of C Language Translation》上发表了一项有趣的研究。
在这项研究中,Kent Budge 及其同事用 FORTRAN-77 和 C++ 两种语言编写了一个复数测试用例(复数在 FORTRAN 中是内置类型,而在 C++ 中,它是一个具体类,包含两个成员:一个实部和一个虚部,标准 C++ 已将该复数类纳入了标准库)。C++ 程序实现了内联算术运算符,形式如下:

请注意,在 C++ 中,按值传递带有构造函数和析构函数的类对象而不是使用引用传递,通常不是好的编程风格。例如:

除了按值拷贝可能造成的大对象开销之外,每个形参的局部实例还需要进行拷贝构造和析构,并可能导致临时对象的生成。不过在该测试用例中,作者声称将形参改为 const 引用并未显著提升性能。这仅仅是因为每个函数调用都被内联展开了。
测试函数大致如下:

其中,complex C++ 类的加法、减法、乘法和赋值运算符均为内联实例。该 C++ 代码生成了 5 个临时对象:
1.存放子表达式 bi+ci 值的临时对象。
2.存放子表达式 bi*ci 值的临时对象。
3.存放"第 1 项减去第 2 项"结果的临时对象。
4.另外两个临时对象,分别存放第 1 项和第 2 项的结果,以便执行第 3 步的减法(调用减法运算符时,需要将1和2的结果分别赋值给运算符的参数,从而又生成了两个运算符内部的局部对象)。
与 FORTRAN-77 代码进行时间对比,结果显示 FORTRAN 代码几乎快了一倍。他们首先怀疑临时对象是罪魁祸首。为了验证这一点,他们手动消除了 cfront 中间输出中的所有临时对象。不出所料,性能提升了一倍,与 FORTRAN-77 持平。
Budge 和他的同事并未止步于此,他们还尝试了另一种方法。他们不是消除临时对象,而是将它们"分解"------即手工将临时对象中的聚合类结构改写成成对的临时 double 变量。他们发现,这种分解方式达到的效率与消除临时对象一样高。他们指出:
我们测试的翻译系统显然能够消除内置类型的局部变量,但无法消除类类型的局部变量。这是 C 后端的局限,而非 C++ 前端的问题,而且这一局限似乎普遍存在,因为它出现在 Sun CC、GNU g++ 和 HP CC 中。BUDGE94
这篇论文分析了生成的汇编代码,并指出性能下降的原因是大量的程序栈访问------读写各个类成员时频繁出入栈。通过将类分解、把各个成员移入寄存器,他们获得了将近两倍的性能提升。由此他们得出以下结论:
结构体的分解虽然实现起来不费太大力气,但在 C++ 引入之前,它并未被普遍认为是一种重要的优化手段 BUDGE94。
从某种意义上说,这项研究只是为"好的优化"提供了一个有力的论据。据我所知,目前已经有一些优化器能够将临时类中的部分成员放入寄存器中。随着编译器实现的重心从语言特性支持(标准 C++ 已完成)转向实现质量(quality of implementation)问题,像分解这样的优化应该会变得越来越普遍。