开篇引入:指针谜题的"万能钥匙"
嘿,还记得我们之前聊过的指针吗?是不是觉得已经摸到点门道了?别急,今天咱们要聊的,绝对是面试和笔试里的"常客",也是让无数初学者栽跟头的"重灾区"。
想象一下,你信心满满地写下 sizeof(arr),以为能算出整个数组的大小,结果编译器给你的答案却让你一脸懵。或者,你用一个 strlen 去测一个字符数组,程序直接崩溃,报个"内存访问错误"。
为什么会这样?明明都是处理数组,怎么结果天差地别?
别慌,今天这篇博客,就是来帮你彻底理清这些让人头大的概念。咱们就从最基础的 sizeof 和 strlen 讲起,然后直接上"硬菜"------用一堆经典的笔试题,带你把指针和数组的那些弯弯绕绕,一次性全部搞明白。
底层原理:sizeof 与 strlen 的"本质区别"
要解决问题,得先搞懂原理。sizeof 和 strlen 虽然都能和"长度"扯上关系,但它俩从根本上就不是一个东西。
sizeof:一个冷酷的"空间测量员"
- 本质 :它压根就不是个函数,而是 C 语言的一个操作符。
- 工作方式 :它的任务非常单一且粗暴:计算操作数在内存中占用的字节大小。它只关心"你占了多少地盘",完全不关心你这块地盘里存了啥数据。
- 类比:它就像一个房地产测量员,只负责告诉你这套房子的建筑面积是 100 平米,至于里面是住着人、堆着货还是空着,他一概不管。
strlen:一个较真的"内容统计员"
- 本质 :它是一个标准的库函数 ,定义在
string.h头文件里。 - 工作方式 :它的任务是统计一个字符串的有效字符长度 。它会从给定的地址开始,一个字节一个字节地往后数,直到遇到第一个字符串结束标志
\0为止。 - 类比 :它像一个图书管理员,从书架的第一本书开始数,一直数到看到一本写着"完"的书(
\0)才停下。如果书架上根本没有这本"完"的书,他就会一直数下去,直到撞到墙(内存越界)。
核心区别一句话总结:sizeof 看的是"类型和空间",strlen 看的是"内容和结束符"。
基础语法:实战演练,看清它们的真面目
光说不练假把式,我们直接上代码,看看它俩在实际中到底有啥不同。
cpp
#include <stdio.h>
#include <string.h> // strlen 函数的头文件
int main()
{
// 场景一:sizeof 的基本用法
int a = 10;
printf("sizeof(a): %zu\n", sizeof(a)); // 计算变量 a 的大小
printf("sizeof(int): %zu\n", sizeof(int)); // 计算 int 类型的大小
// 输出都是 4 (在32/64位系统下通常如此)
// 场景二:strlen 的基本用法
char arr1[] = {'a', 'b', 'c'}; // 没有 \0 的字符数组
char arr2[] = "abc"; // 有 \0 的字符串
// strlen 会一直找 \0,arr1 没有,所以结果是随机的(内存垃圾值)
printf("strlen(arr1): %zu\n", strlen(arr1));
// arr2 的内容是 'a', 'b', 'c', '\0',strlen 数到 \0 停止,结果是 3
printf("strlen(arr2): %zu\n", strlen(arr2));
// 场景三:sizeof 对数组的"特殊待遇"
// sizeof 看到数组名 arr2,知道是整个数组,大小是 4 个字节 ('a','b','c','\0')
printf("sizeof(arr2): %zu\n", sizeof(arr2));
return 0;
}代码解读:
sizeof的冷酷 :你看,不管是变量a还是类型int,sizeof都只返回它们占用的内存大小,非常稳定。strlen的较真与危险 :strlen(arr1)的结果是随机的,因为它会越过arr1的边界,在内存里继续寻找\0,直到碰巧遇到一个为止。这就是典型的内存越界访问 ,非常危险!而strlen(arr2)就安全得多,因为它能正常找到\0。sizeof的"特殊待遇" :这是关键!当sizeof的操作数是数组名 时,它会把数组名看作整个数组,计算出总大小。而strlen接收的永远是一个地址,它只会从这个地址开始数。
概念辨析:指针运算的两大"公理"
刚才提到了 sizeof 对数组名的特殊处理,这其实是理解所有指针数组笔试题的核心钥匙。但光有这个还不够,要真正像解数学题一样严谨地分析每一个表达式,我们需要掌握两个更底层的"公理"。
公理一:指针运算的"步长法则"
这是 C 语言指针运算的根本法则,是放之四海而皆准的真理。
公式化表述:
对于任意一个类型为 T* 的指针 p,其加减整数的运算规则如下:
p ± n 的地址偏移量 = n * sizeof(T)
解读:
指针的算术运算,不是简单的地址加减,而是以它所指向的数据类型的大小为单位进行的。
int *p:p + 1的地址值会增加1 * sizeof(int),通常是 4 个字节。double *p:p + 1的地址值会增加1 * sizeof(double),通常是 8 个字节。int (*p)[5](一个指向包含 5 个整数的数组的指针):p + 1的地址值会增加1 * sizeof(int[5]),即1 * 5 * 4 = 20个字节。
这个规则是绝对的,是编译器生成机器码的依据。
公理二:数组名的"身份切换法则"
这是 C 语言为了方便程序员而设计的一条语法规则 。它决定了在表达式中,arr 这个符号到底代表什么。
公式化表述:
对于一个类型为 T arr[N] 的数组,数组名 arr 在表达式中的身份遵循以下规则:
- 作为整个数组:当
arr是sizeof(arr)或&arr的操作数时。- 此时,
arr代表整个数组对象。 &arr的类型是T(*)[N](指向包含 N 个 T 类型元素的数组的指针)。
- 此时,
- 作为首元素地址:在所有其他情况下。
- 此时,
arr会被隐式转换(decay)为指向其首元素的指针。 arr的类型是T*。
- 此时,
解读:
这个法则之所以关键,正是因为它改变了参与运算的指针的类型。
- 当你写
arr + 1时,根据法则二,arr的类型是T*。再根据法则一,步长就是sizeof(T)。 - 当你写
&arr + 1时,根据法则二,&arr的类型是T(*)[N]。再根据法则一,步长就变成了sizeof(T[N]),即N * sizeof(T)。
正是这两个公理的协同作用,导致了看似相同的地址,进行 +1 运算后却指向了完全不同的位置。
避坑指南:那些年我们踩过的指针"大坑"
当初我学到这里的时候,也被下面这些代码折磨得够呛。咱们来复盘一下,看看坑到底在哪。
踩坑经历:
我记得第一次看到 int *ptr = (int *)(&arr + 1); 这种代码时,大脑直接宕机。arr 是啥?&arr 又是啥?它俩加 1 能一样吗?
坑点分析:
问题的根源就在于没分清 arr 和 &arr 的区别,也就是没用好我们的"身份切换法则"。
arr:根据法则二,它代表首元素地址,类型是int*。根据法则一,arr + 1就是跳过一个int的大小(通常是 4 字节),指向第二个元素。&arr:根据法则二,它代表整个数组的地址,类型是int(*)[5](假设数组有 5 个元素)。根据法则一,&arr + 1是跳过整个数组的大小(5 * 4 = 20 字节),指向数组末尾的下一个位置。
虽然 arr 和 &arr 的数值(地址)是一样的,但它们的类型完全不同,这决定了它们进行指针运算时"步长"的巨大差异。
正误代码对比:
cpp
int arr[5] = {1, 2, 3, 4, 5};
错误理解:以为 arr 和 &arr 是一回事
int *p1 = arr + 1; p1 指向 arr[1],即数字 2
int *p2 = &arr + 1; p2 指向 arr[5] 之后的位置,越界了!
正确理解:
int *p1 = arr + 1; 步长是 sizeof(int),指向 2
int (*p2)[5] = &arr + 1; 步长是 sizeof(arr),即 5*sizeof(int),指向数组后面综合实战:经典笔试题大闯关
好了,理论武装完毕,现在我们来实战演练,用刚才学的两大公理,像解数学题一样,一口气干掉下面这些经典题目。
第一关:一维数组的 sizeof 迷宫
cpp
#include <stdio.h>
int main()
{
int a[] = { 1, 2, 3, 4 };
假设 int 占 4 字节,指针占 8 字节 (64位环境)
printf("%zu\n", sizeof(a)); 1. 整个数组大小:4 * 4 = 16
printf("%zu\n", sizeof(a + 0)); 2. a是首元素地址,+0还是地址,大小是 8
printf("%zu\n", sizeof(*a)); 3. *a 是首元素 a[0],大小是 4
printf("%zu\n", sizeof(a + 1)); 4. a+1是第二个元素地址,大小是 8
printf("%zu\n", sizeof(a[1])); 5. a[1] 是第二个元素,大小是 4
printf("%zu\n", sizeof(&a)); 6. &a是整个数组地址,但仍是地址,大小是 8
printf("%zu\n", sizeof(&a + 1)); 7. &a+1是数组后的地址,仍是地址,大小是 8
return 0;
}逻辑拆解:
这关的核心就是反复运用"数组名的双重身份"规则。看到 sizeof(a),马上反应是求整个数组大小。看到 a+0、&a 等,马上反应它们是地址,sizeof 计算的就是指针的大小。
第二关:字符数组的 strlen 陷阱
cpp
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[] = {'a', 'b', 'c', 'd', 'e', 'f'}; 没有 \0
char arr2[] = "abcdef"; 有 \0
printf("%zu\n", strlen(arr1)); 随机值!会越界寻找 \0
printf("%zu\n", strlen(arr2)); 6,正常统计
printf("%zu\n", sizeof(arr1)); 6,数组大小就是 6 个字符
printf("%zu\n", sizeof(arr2)); 7,数组大小是 6 个字符 + 1 个 \0
return 0;
}逻辑拆解:
这关是 sizeof 和 strlen 的正面 PK。sizeof 永远稳稳地返回定义的数组大小。而 strlen 则完全依赖 \0,arr1 没有 \0,所以结果是未知的,这就是一个大坑。
第三关:指针运算的"步长"游戏
cpp
#include <stdio.h>
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int *ptr1 = (int *)(&a + 1); &a是数组地址,+1跳过整个数组
int *ptr2 = (int *)(*(a + 1)); a+1是a[1]的地址,*(a+1)就是a[1]的值,即2
ptr1 指向 a[5] 之后的位置,ptr1-1 就回退一个int,指向 a[4],即 5
ptr2 的值是 2,把它当地址用,*(ptr2-1) 是访问地址 1 处的内存,这是非法访问!
但很多题目只会问 *(ptr1 - 1) 的值,那就是 5。
printf("%d\n", *(ptr1 - 1)); // 输出 5
return 0;
}逻辑拆解:
这题是"步长"概念的终极考验。&a + 1 的步长是整个数组,而 a + 1 的步长是一个元素。搞清这一点,ptr1 指向哪里就一目了然了。
高阶拓展:二维数组的指针视角
二维数组看起来复杂,其实只是把这套逻辑又嵌套了一层。
核心原理:
结合两大"公理",以int a[3][4]为例:
a代表首行(一个包含 4 个 int 的数组)的地址,类型是int(*)[4]。a + 1会跳过一整行(4个int),指向第二行。a[0]代表首行的首元素地址,类型是int*。a[0] + 1会跳过一个 int,指向第一行的第二个元素。&a:代表整个数组的地址,类型是int (*)[3][4],加 1 跳过整个数组。
理解了这一点,sizeof(a) 就是整个二维数组的大小,sizeof(a[0]) 就是第一行的大小,sizeof(a[0][0]) 就是第一个元素的大小。一切都有迹可循。
sizeof(arr)计算的是整个数组的大小。sizeof(arr + 0)的结果是指针大小,因为arr在这里被转换为了指针。sizeof(&arr)的结果也是指针大小,尽管它指向的是整个数组,但它本身仍然是一个地址,其存储大小与其他指针无异。
实战应用:二维数组笔试题深度解析
理论背得再熟,不如代码跑一遍。下面这 5 道题是 C 语言考试和面试中的"常客",专门用来考察对 a、a[0]、&a 三者类型及步长的理解。请结合刚才的"两大公理"进行推导。
题目 1:一维数组与 sizeof 的博弈
虽然这是一维数组,但它是理解后续二维数组的基础。请注意 a 在不同语境下的身份切换。
cpp
#include <stdio.h>
int main()
{
int a[] = {1, 2, 3, 4};
1. sizeof(a)
分析:单独放在 sizeof 内部,a 代表整个数组。
计算:4个元素 * 4字节 = 16
printf("sizeof(a) = %zu\n", sizeof(a));
2. sizeof(a + 0)
分析:a + 0 发生了运算,不再是单独的数组名。
a 退化为首元素地址 (int*),+0 还是首元素地址。
既然是地址(指针),在 32 位下为 4,64 位下为 8。
printf("sizeof(a + 0) = %zu\n", sizeof(a + 0));
3. sizeof(*a)
分析:*a 等价于 *(a+0),即访问首元素 a[0]。
a[0] 是 int 类型。
计算:sizeof(int) = 4
printf("sizeof(*a) = %zu\n", sizeof(*a));
4. sizeof(a + 1)
分析:同第 2 点,a+1 是指针运算,指向第二个元素。
它依然是个地址(指针)。
结果:4 或 8
printf("sizeof(a + 1) = %zu\n", sizeof(a + 1));
return 0;
}题目 2:字符数组与字符串的陷阱
这里引入了 \0,是 sizeof 和 strlen 最容易混淆的地方。
cpp
#include <stdio.h>
#include <string.h>
int main()
{
char arr[] = {'a', 'b', 'c', 'd', 'e', 'f'};
1. sizeof(arr)
分析:arr 代表整个数组,包含 6 个字符。
结果:6
printf("sizeof(arr) = %zu\n", sizeof(arr));
2. sizeof(arr + 0)
分析:arr + 0 是首元素地址(char*)。
结果:4 或 8
printf("sizeof(arr + 0) = %zu\n", sizeof(arr + 0));
3. strlen(arr)
分析:strlen 找 '\0'。arr 中没有 '\0'。
结果:随机值(直到在内存中偶然碰到 0 为止)
printf("strlen(arr) = %zu (随机值)\n", strlen(arr));
4. strlen(arr + 0)
分析:同上,从 'a' 开始找 '\0'。
结果:随机值
printf("strlen(arr + 0) = %zu (随机值)\n", strlen(arr + 0));
return 0;
}题目 3:常量字符串 vs 字符数组
注意双引号 "" 带来的隐形 \0。
cpp
#include <stdio.h>
#include <string.h>
int main()
{
char arr[] = "abcdef";
1. sizeof(arr)
分析:"abcdef" 包含 6 个字符 + 1 个隐藏的 '\0'。
结果:7
printf("sizeof(arr) = %zu\n", sizeof(arr));
2. strlen(arr)
分析:strlen 数到 '\0' 停止,不计算 '\0' 本身。
结果:6
printf("strlen(arr) = %zu\n", strlen(arr));
return 0;
}题目 4:指针与数组名的混合运算
这是最容易混淆的地方,重点在于区分"数组名"和"指针变量"。
cpp
#include <stdio.h>
int main()
{
char *p = "abcdef";
1. sizeof(p)
分析:p 是一个指针变量,不是数组名。
无论指向什么,指针变量的大小固定。
结果:4 (32位) 或 8 (64位)
printf("sizeof(p) = %zu\n", sizeof(p));
2. strlen(p)
分析:p 指向字符串首地址,strlen 正常计数。
结果:6
printf("strlen(p) = %zu\n", strlen(p));
return 0;
}题目 5:二维数组的终极试炼
回到我们今天的主题,这是检验你是否掌握"行指针"与"元素指针"区别的关键题。
cpp
#include <stdio.h>
int main()
{
int a[3][4] = {0};
1. sizeof(a)
分析:a 代表整个二维数组。
计算:3行 * 4列 * 4字节 = 48
printf("sizeof(a) = %zu\n", sizeof(a));
2. sizeof(a[0][0])
分析:这是具体的某一个元素,int 类型。
结果:4
printf("sizeof(a[0][0]) = %zu\n", sizeof(a[0][0]));
3. sizeof(a[0])
分析:a[0] 是第一行的数组名,代表第一行这个整体。
第一行有 4 个 int。
结果:16
printf("sizeof(a[0]) = %zu\n", sizeof(a[0]));
4. sizeof(a[0] + 1)
分析:a[0] 虽然是数组名,但参与了 +1 运算,退化为 int* 指针。
指针的大小。
结果:4 或 8
printf("sizeof(a[0] + 1) = %zu\n", sizeof(a[0] + 1));
5. sizeof(a + 1)
分析:a 是行指针 int(*)[4],+1 跳过一行,还是指针。
结果:4 或 8
printf("sizeof(a + 1) = %zu\n", sizeof(a + 1));
return 0;
}一步一步详细拆解:
题目1:
cpp
#include <stdio.h>
int main()
{
int aa[2][5] = { 1,2,3,4,5,6,7,8,9,10 };
int* ptr1 = (int*)(&aa + 1);
int* ptr2 = (int*)(*(aa + 1));
printf("%d\n %d\n", *(ptr1 - 1), *(ptr2 - 1));
}这是一道非常经典的 C 语言指针与数组题目,主要考察的是 二维数组名、取地址符 & 以及指针算术运算 之间的区别。
程序的最终输出结果是:
cpp
10,5详细推导过程
内存布局分析
首先,我们需要明确二维数组 int aa[2][5] 在内存中是连续存储的(行优先)。
- 第 0 行 :
{1, 2, 3, 4, 5}(索引 0~4) - 第 1 行 :
{6, 7, 8, 9, 10}(索引 5~9)
分析 ptr1 (第 5 行代码)
代码:int *ptr1 = (int *)(&aa + 1);
&aa的类型 :aa是数组名。&aa表示取整个数组的地址。- 它的类型是 指向整个二维数组的指针 ,即
int (*)[2][5]。
&aa + 1的含义 :- 因为
&aa指向的是整个数组,所以+1会跳过 整个数组的大小。 - 它会指向数组最后一个元素(数字 10)之后的那个内存位置。
- 因为
- 强制转换
(int *):- 将上述地址强制转换为普通整型指针
int *。此时ptr1指向的是数组末尾之后的那个位置。
- 将上述地址强制转换为普通整型指针
- 计算
*(ptr1 - 1):ptr1是int *类型,所以ptr1 - 1会向低地址方向移动一个int的大小(4字节)。- 这正好回退到数组的 最后一个元素。
- 结果 :数组最后一个元素是 10。
分析 ptr2 (第 6 行代码)
代码:int *ptr2 = (int *)(*(aa + 1));
aa + 1的含义 :- 这里的
aa作为数组名,代表首元素的地址(即第 0 行的地址)。 aa + 1表示指向 第 1 行 的地址。
- 这里的
- 解引用
*(aa + 1):- 对"第 1 行的地址"进行解引用,得到的是 第 1 行这个一维数组本身。
- 在表达式中,第 1 行数组名会退化为首元素的地址,即指向数字 6 的地址。
- 其类型为
int *。
- 赋值给
ptr2:ptr2现在指向第 1 行的第一个元素(数字 6)。
- 计算
*(ptr2 - 1):ptr2指向数字 6。ptr2 - 1向前移动一个int的位置。- 由于内存是连续的,第 1 行之前紧挨着的就是第 0 行的最后一个元素。
- 结果 :第 0 行最后一个元素是 5。
总结图示
为了方便理解,可以将内存想象成一条直线:
cpp
地址方向: 低 <--------------------------------------------> 高
数据内容: [ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ]
^ ^ | ^
| | | |
ptr2-1 | | ptr1
(值为5) | | (指向10后面)
| |
ptr2 ptr1-1
(值为6) (值为10)ptr1 - 1从数组尾巴往后退一步,拿到了 10。ptr2 - 1从第二行开头往前退一步,跨过了行的界限,拿到了第一行的末尾 5。
题目2:
cpp
#include <stdio.h>
int main()
{
char* c[] = { "ENTER","NEW","POINT","FIRST" };
char** cp[] = { c + 3,c + 2,c + 1,c };
char*** cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *-- * ++cpp + 3);
printf("%s\n", *cpp[-2] + 3);
printf("%s\n", cpp[-1][-1] + 1);
return 0;
}这道题是 C 语言指针运算的"终极试炼"。要解对这道题,必须死死抓住 两个关键点:
- 指针的指向(Target):时刻清楚当前指针指向的是哪个变量(地址)。
- 副作用(Side Effect) :前置
++/--会永久改变指针本身的值,后续代码必须基于修改后的新位置计算。
我们将通过追踪内存状态的变化来一步步推导。
初始状态分析
首先建立内存模型。假设数组首地址如下(仅为示意):
-
字符串常量池:
"ENTER"(地址 A)"NEW"(地址 B)"POINT"(地址 C)"FIRST"(地址 D)
-
数组
c(char *c[4]):存储字符串首地址c[0] = A,c[1] = B,c[2] = C,c[3] = D
-
数组
cp(char **cp[4]) :存储c中元素的地址cp[0] = &c[3](指向 "FIRST")cp[1] = &c[2](指向 "POINT")cp[2] = &c[1](指向 "NEW")cp[3] = &c[0](指向 "ENTER")
-
指针
cpp(char ***cpp):- 初始化
cpp = cp,即cpp指向&cp[0]。
- 初始化
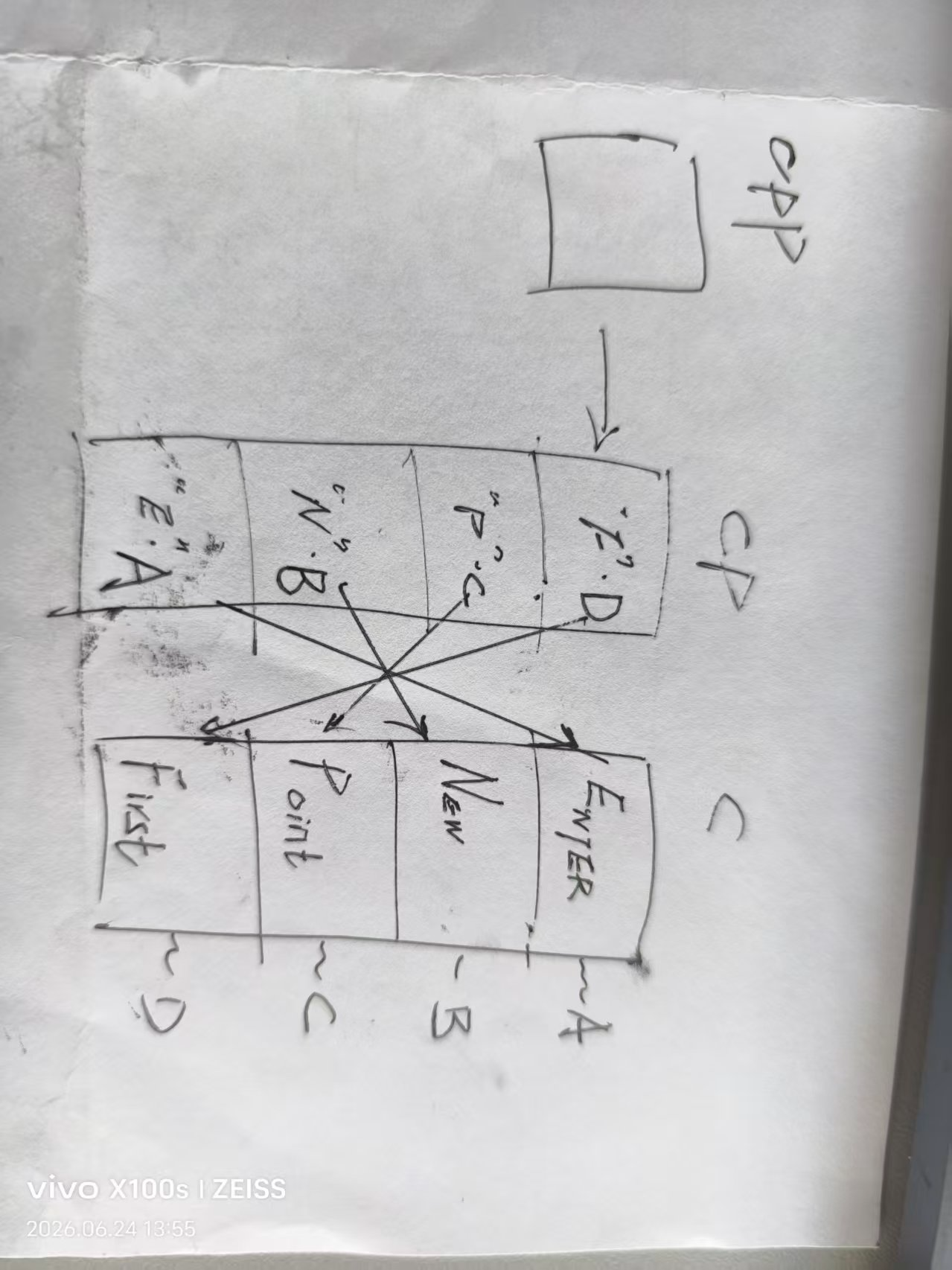
逐行推导过程
第 7 行:printf("%s\n", **++cpp);
这里涉及 关键点 2(副作用) :++cpp 是前置自增。
- 执行
++cpp:cpp原本指向cp[0]。- 自增后,cpp(char***)+1 步长 8 字节,指向 cp 1;
- 当前状态 :
cpp -> cp[1]。
- 第一次解引用
*cpp:- 取出
cp[1]的值。根据定义,cp[1]存的是&c[2]。
- 取出
- 第二次解引用
**cpp:- 取出
c[2]的值。根据定义,c[2]存的是"POINT"的首地址。
- 取出
- 输出结果 :
POINT
注意 :此时
cpp依然指向cp[1],这个状态会影响下一行代码。
第 8 行:printf("%s\n", *--*++cpp + 3);
这一行最复杂,需严格按照优先级和结合性从右向左解析。
- 执行
++cpp(再次触发副作用):cpp原本指向cp[1]。- 自增后,
cpp向后移动一位,现在指向cp[2]。 - 当前状态 :
cpp -> cp[2]。
- 执行
*cpp:- 取出
cp[2]的值,即&c[1]。
- 取出
- 执行
--(*cpp)(关键难点):- 这里是对
cp[2]里面存的值进行自减! cp[2]原本存的是&c[1]。- 自减后,
cp[2]变成了&c[0]。 - 内存被修改了 :现在
cp[2]指向c[0]("ENTER")。
- 这里是对
- 执行
*(...):- 取出刚才修改后的值
&c[0]所指向的内容,即c[0]的值。 c[0]是"ENTER"的首地址。
- 取出刚才修改后的值
- 执行
+ 3:- 偏移 3 位后指向第二个
'E'。
- 偏移 3 位后指向第二个
- 输出结果 :
ER
当前状态总结 :
cpp指向cp[2];且cp[2]内部存储的值已被改为&c[0]。
第 9 行:printf("%s\n", *cpp[-2] + 3);
这里没有自增自减,只有下标运算。
- 计算
cpp[-2]:cpp当前指向cp[2]。cpp[-2]等价于*(cpp - 2),即回退两格,指向cp[0]。- 取出
cp[0]的值:&c[3]。
- 执行
*解引用 :- 取出
c[3]的值,即"FIRST"的首地址。
- 取出
- 执行
+ 3:- 偏移 3 位后指向
'S'。
- 偏移 3 位后指向
- 输出结果 :
ST
第 10 行:printf("%s\n", cpp[-1][-1] + 1);
这是二维数组风格的指针访问。
- 计算
cpp[-1]:cpp当前指向cp[2]。cpp[-1]等价于*(cpp - 1),即回退一格,指向cp[1]。- 取出
cp[1]的值:&c[2]。
- 计算
[-1]:- 在上一步得到的
&c[2]基础上回退一格。 &c[2] - 1得到&c[1]。
- 在上一步得到的
- 隐式解引用 :
- 取出
c[1]的值,即"NEW"的首地址。
- 取出
- 执行
+ 1:- 偏移 1 位后指向
'E'。
- 偏移 1 位后指向
- 输出结果 :
EW
最终答案
程序的完整输出为:
cpp
POINT
ER
ST
EW以上即为该程序完整的执行逻辑与输出结果。
全文完整总结(回扣全文脊柱:指针类型决定一切)
- sizeof 与 strlen 底层区分:sizeof 依靠变量 / 数组完整类型统计内存;strlen 固定接收
char*指针,依靠内存终止符计数; - 数组名切换规则:仅
sizeof(arr)、&arr保留完整数组类型,其余场景全部降级为对应层级指针,类型直接改变偏移步长; - 全文核心脊柱(重中之重):所有指针
±整数的偏移字节,完全由指针自身类型决定。int*步长 4、行指针int(*)[N]步长 N*4、数组指针步长整个数组字节,解题第一步必须标注清楚当前表达式的完整指针类型; - 所有越界、取值错误、笔试题迷惑项,根源都是运算前忽略指针类型,错判步长;二维、三级多层指针运算,只需逐层拆解每层指针类型,套用步长公式即可全部理清。
指针与数组看似错综复杂,本质是围绕「指针类型」展开的逻辑计算。只要养成习惯:任何地址运算先写出完整类型,再计算对应步长,所有迷惑难题都会迎刃而解。多画内存布局图、区分每层指针类型、调试打印地址验证步长,就能彻底吃透指针体系。
指针的世界就是这样,初看像一团乱麻,但只要你抓住"类型决定步长"和"数组名的双重身份"这两根主线,就能把它理得清清楚楚。别怕,多画内存图,多调试几遍,你也能成为指针高手。
深夜的键盘声,是程序员的安眠曲。当最后一个指针指向正确的位置,那种拨云见日的感觉,比什么都治愈。
灯火阑珊处,代码渐入佳境,指针所指,皆是逻辑的归途。