初始化集群
Ambari Server 启动以后,浏览器已经可以打开 Ambari Plus 登录页。这个时候不要急着装一堆大数据组件,我更建议先做一个最小闭环:创建集群、接入三台主机、安装基础协调服务,让 Web UI 能正式进入控制台。
本文示例环境沿用前面准备好的三台 FQDN:
| 角色 | 主机名 |
|---|---|
| Ambari Server / 核心节点 | hadoop1.test.com |
| Worker 节点 | hadoop2.test.com |
| Worker 节点 | hadoop3.test.com |
这一篇先安装 ZOOKEEPER。它足够轻量,也能验证主机注册、仓库访问、组件安装、服务启动和 Service Check 是否完整跑通。HDFS、YARN、Hive、Ranger 这些服务,后面单独拆文章写会更清楚。
::: tip
截图里涉及 SSH 私钥的区域已经遮挡。真实操作时需要粘贴核心节点能免密登录目标主机的 PEM 私钥,文章里不展示私钥内容。
:::
1. 登录后进入安装向导
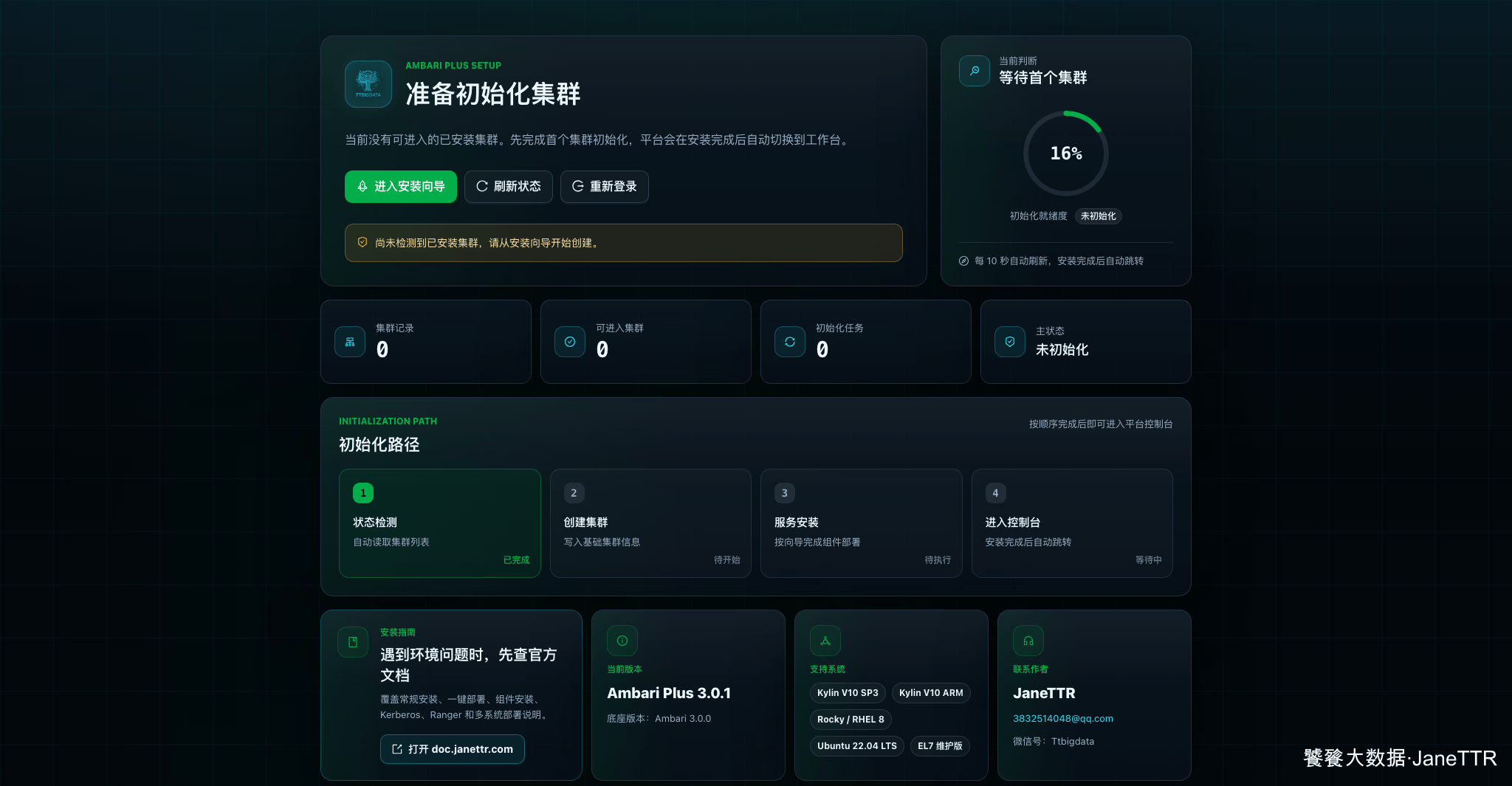
如果当前还没有可进入的集群,登录后会进入"准备初始化集群"页面。这里不是异常,而是新环境的正常入口。
页面上可以看到集群记录为 0、主状态为"未初始化",点击 进入安装向导。
我在这里重点看三个点:
| 检查点 | 说明 |
|---|---|
| 当前版本 | 页面显示 Ambari Plus 3.0.1,说明 Web 资源加载正常 |
| 集群记录 | 新环境应为 0,已有集群则不会走这条初始化路径 |
| 初始化路径 | 状态检测完成后,下一步就是创建集群 |
2. 校准 Stack 和仓库地址
进入向导后,第一步是选择 Stack 和填写组件仓库 Base URL。本文使用 BIGTOP-3.2.0,仓库地址沿用前面 Nginx 本地文件服务暴露出来的地址:
text
http://hadoop1.test.com/填完以后点击 验证连通性。看到"仓库地址可达""Base URL 校验通过",再进入下一步。
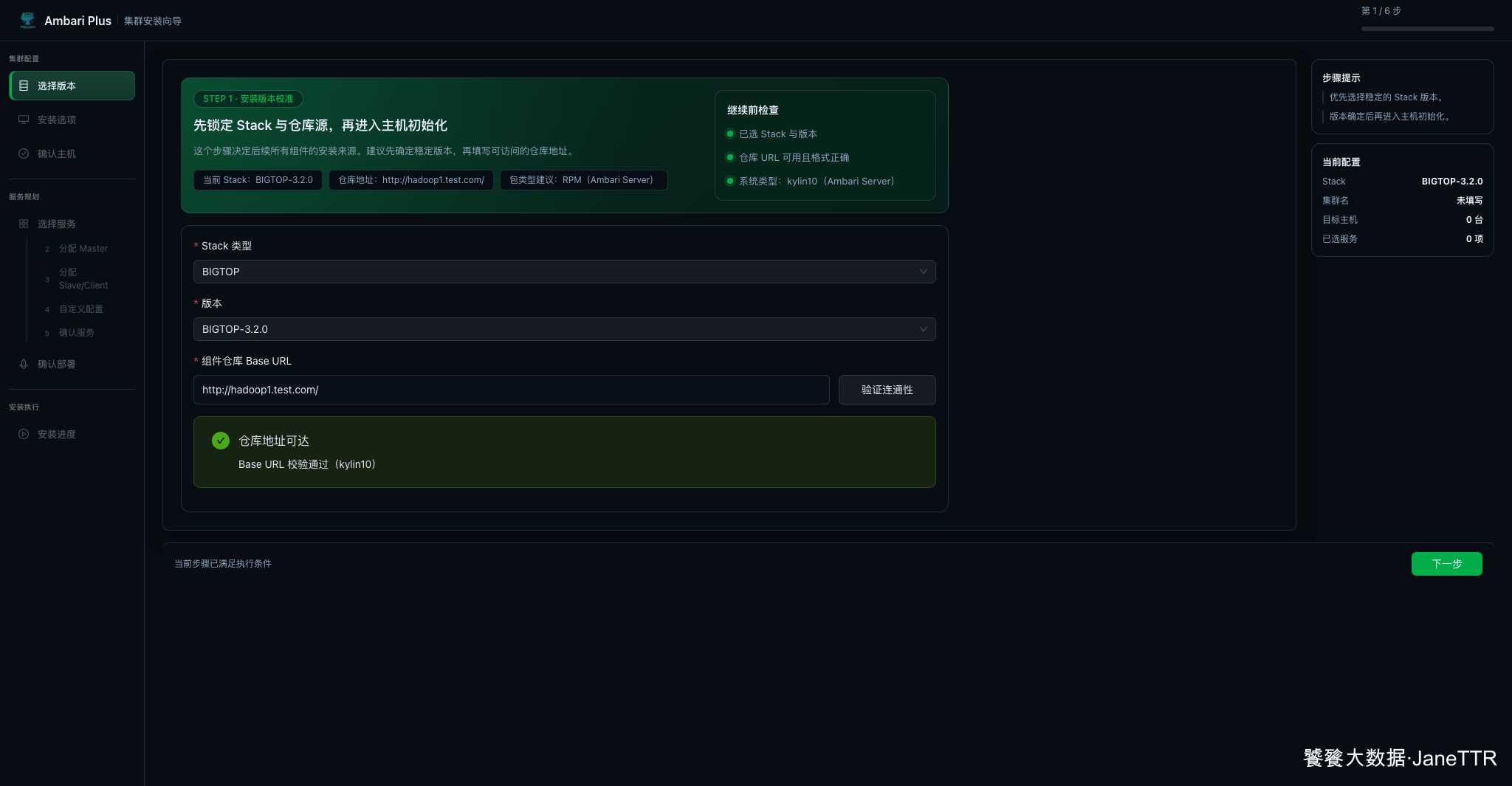
这里我建议不要跳过验证。仓库地址看起来只是一个 URL,但后面所有组件安装都会从这里拿包。这个地方如果填错,后面报错通常会散落在 Agent 安装、组件安装、yum 缓存、RPM 依赖等多个环节里,排查成本会高很多。
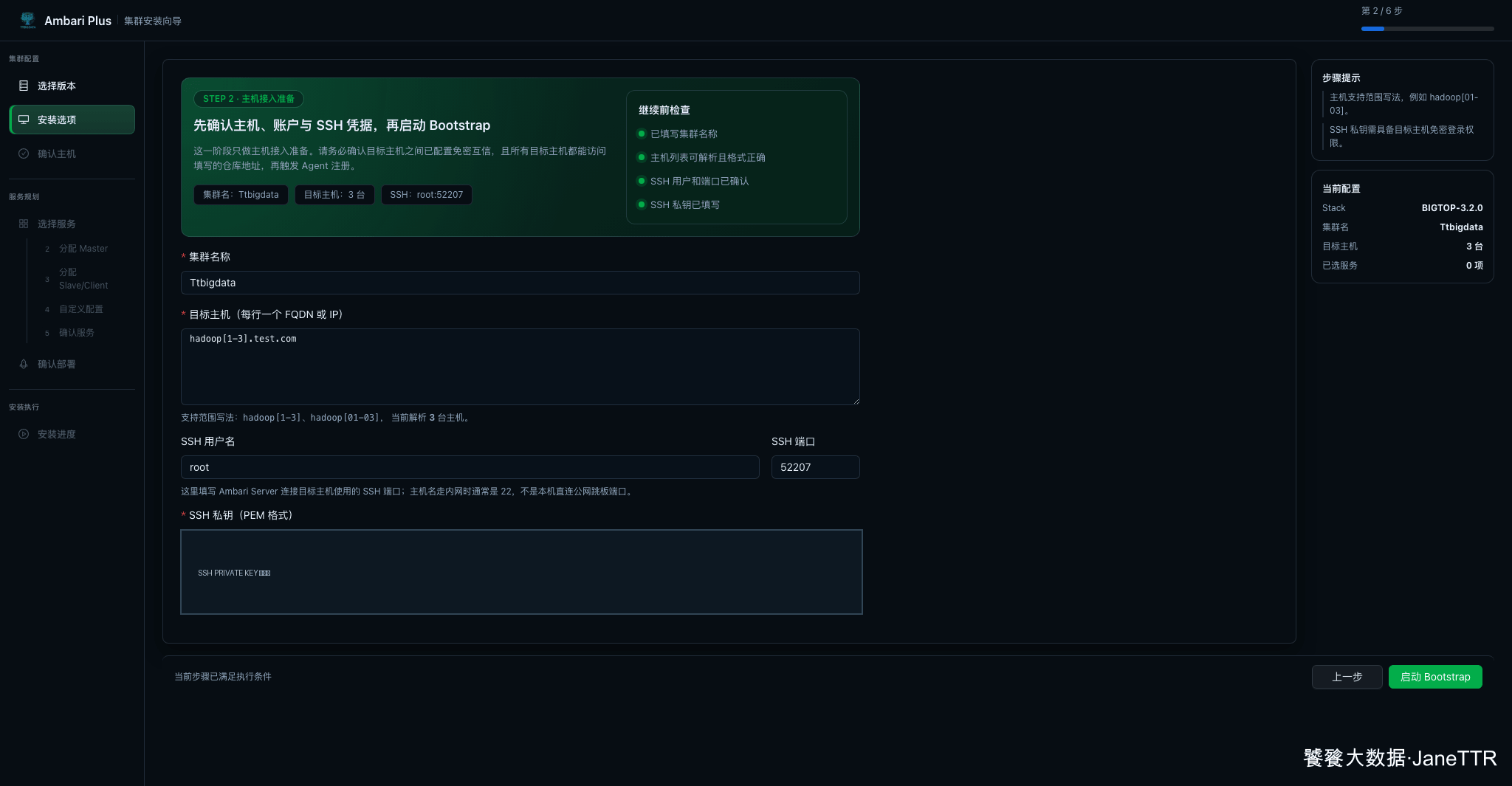
3. 填写主机和 SSH 凭据
第二步填写集群名称、目标主机、SSH 用户、SSH 端口和私钥。
本文示例填写:
| 配置项 | 示例值 |
|---|---|
| 集群名称 | Ttbigdata |
| 目标主机 | hadoop[1-3].test.com |
| SSH 用户 | root |
| SSH 端口 | 52207 |
| SSH 私钥 | 使用核心节点能登录三台目标主机的 PEM 私钥 |
::: note
常规内网环境 SSH 端口多为 22。本文示例环境的 SSH 服务监听在 52207,所以向导里填写 52207。这里填的是 Ambari Server 连接目标主机时使用的端口,不是浏览器访问 Web UI 的端口。
:::
主机支持范围写法,hadoop[1-3].test.com 会解析成三台主机。确认页面显示"目标主机:3 台",并且右下角按钮变成 启动 Bootstrap。
我在实际部署时会先在核心节点命令行做一次免密验证,避免把问题拖到 Web UI:
bash
for h in hadoop1.test.com hadoop2.test.com hadoop3.test.com; do
ssh -p 52207 -o BatchMode=yes "$h" "hostname -f"
done如果你的环境使用默认 22 端口,把 -p 52207 换成 -p 22,或者直接省略 -p。
4. 等待 Bootstrap 完成
点击 启动 Bootstrap 后,向导会进入确认主机页面。这个阶段会安装和注册 Agent,并把主机接入结果回传到页面。
等到三台主机都显示"已完成接入",整体进度为 100%,并且失败主机为 0,再继续下一步。
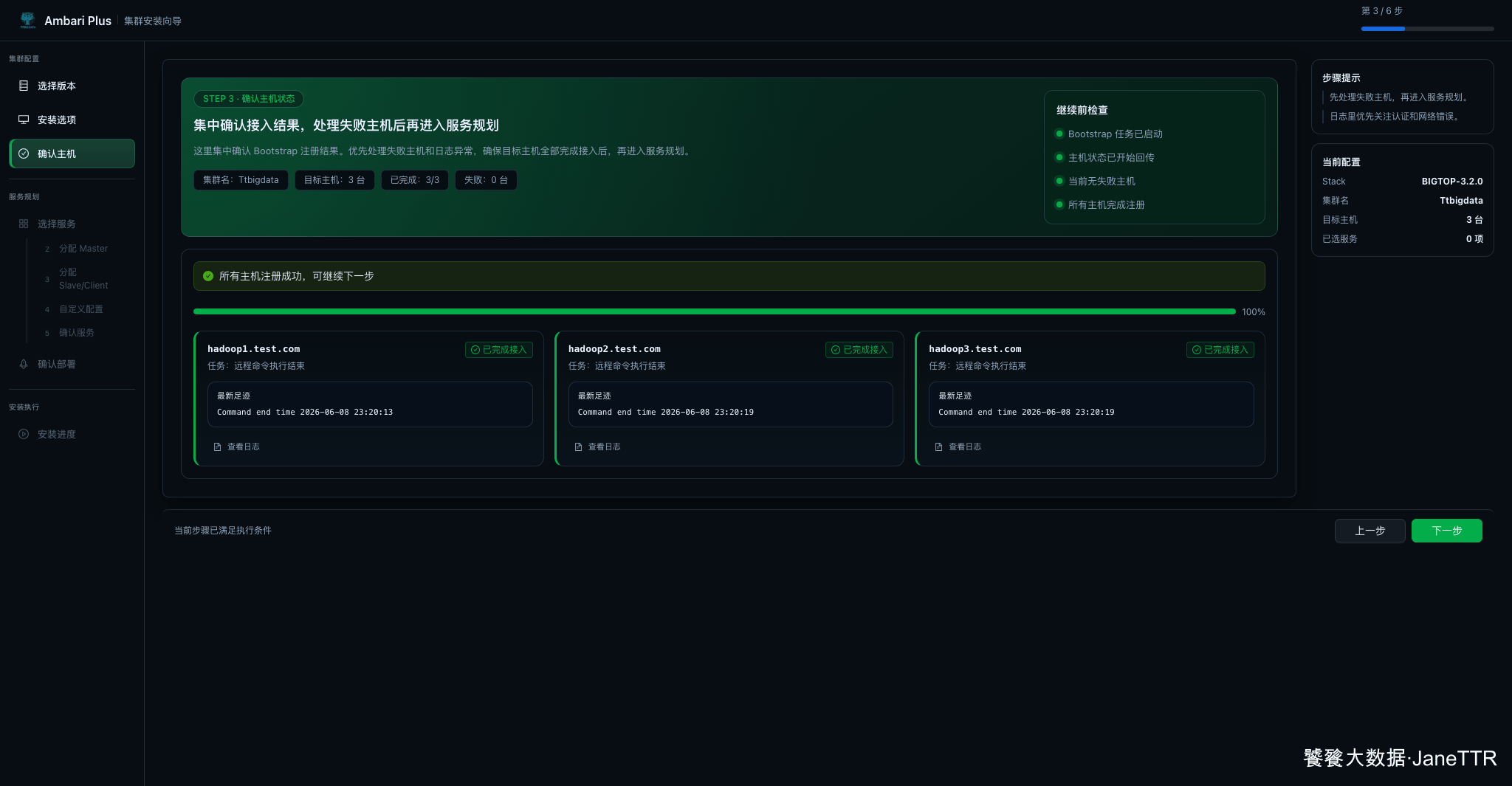
如果这里卡住,我一般先看三个方向:
| 现象 | 优先检查 |
|---|---|
| 主机一直进行中 | 目标主机 SSH 端口、私钥权限、sudo/root 权限 |
| 主机失败 | 点击单台主机的日志,看认证失败还是包安装失败 |
| Agent 无法注册 | ambari-agent.ini 的 Server 地址、主机名解析、时间同步 |
5. 选择本次要安装的服务
进入服务选择页后,本次只保留最小初始化服务。本文安装 ZOOKEEPER,先让基础协调服务跑起来。
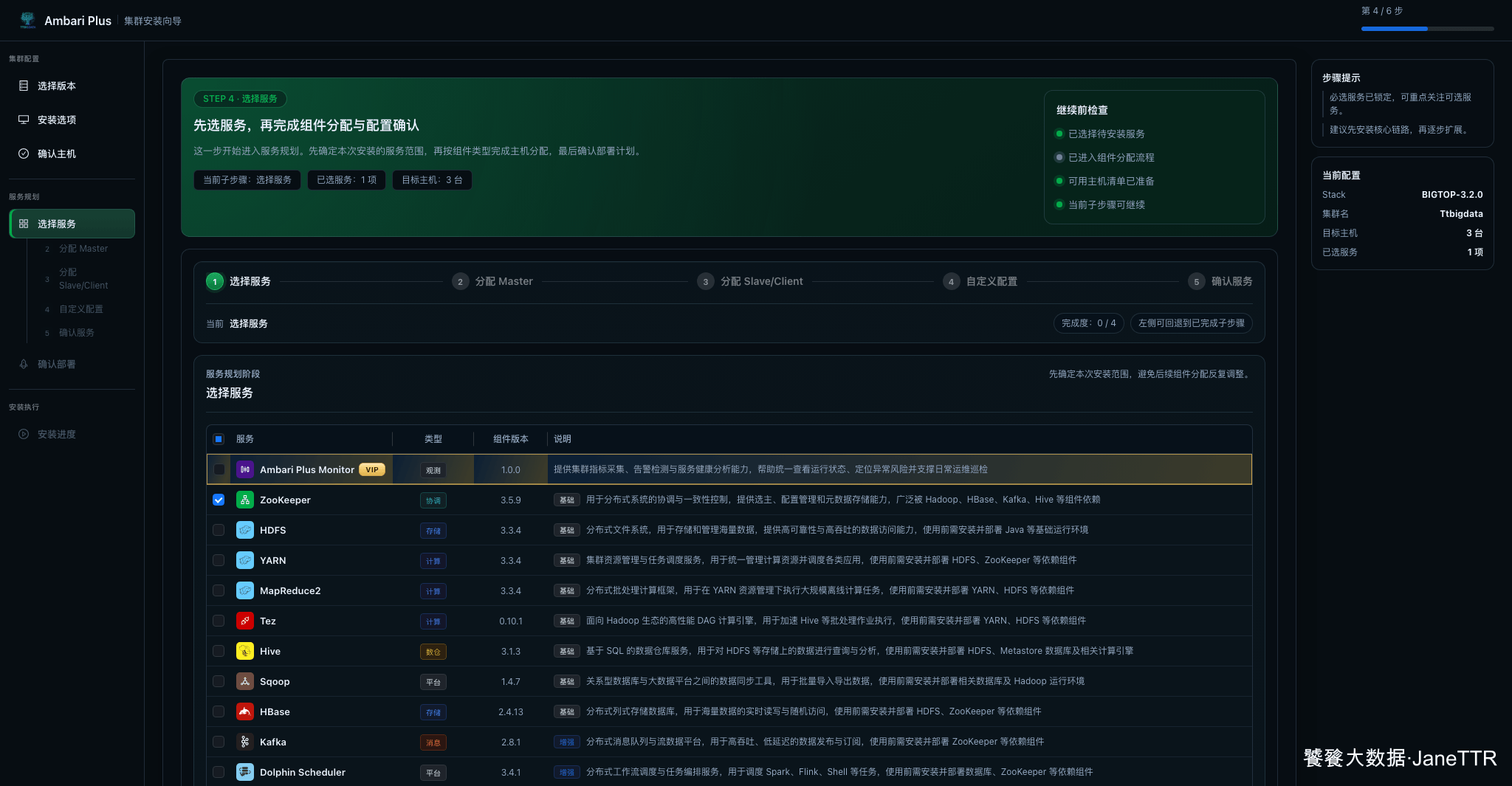
这个选择看起来很克制,但我觉得更适合写教程:初始化集群先验证主机、仓库和服务安装链路;等这条链路稳定,再继续安装 HDFS、YARN、Hive 等组件。一次性把所有服务都勾上,失败时很难判断第一个问题从哪里开始。
6. 分配 Master 组件
Master 分配页会把 ZOOKEEPER_SERVER 分配到三台主机,形成三节点 quorum。
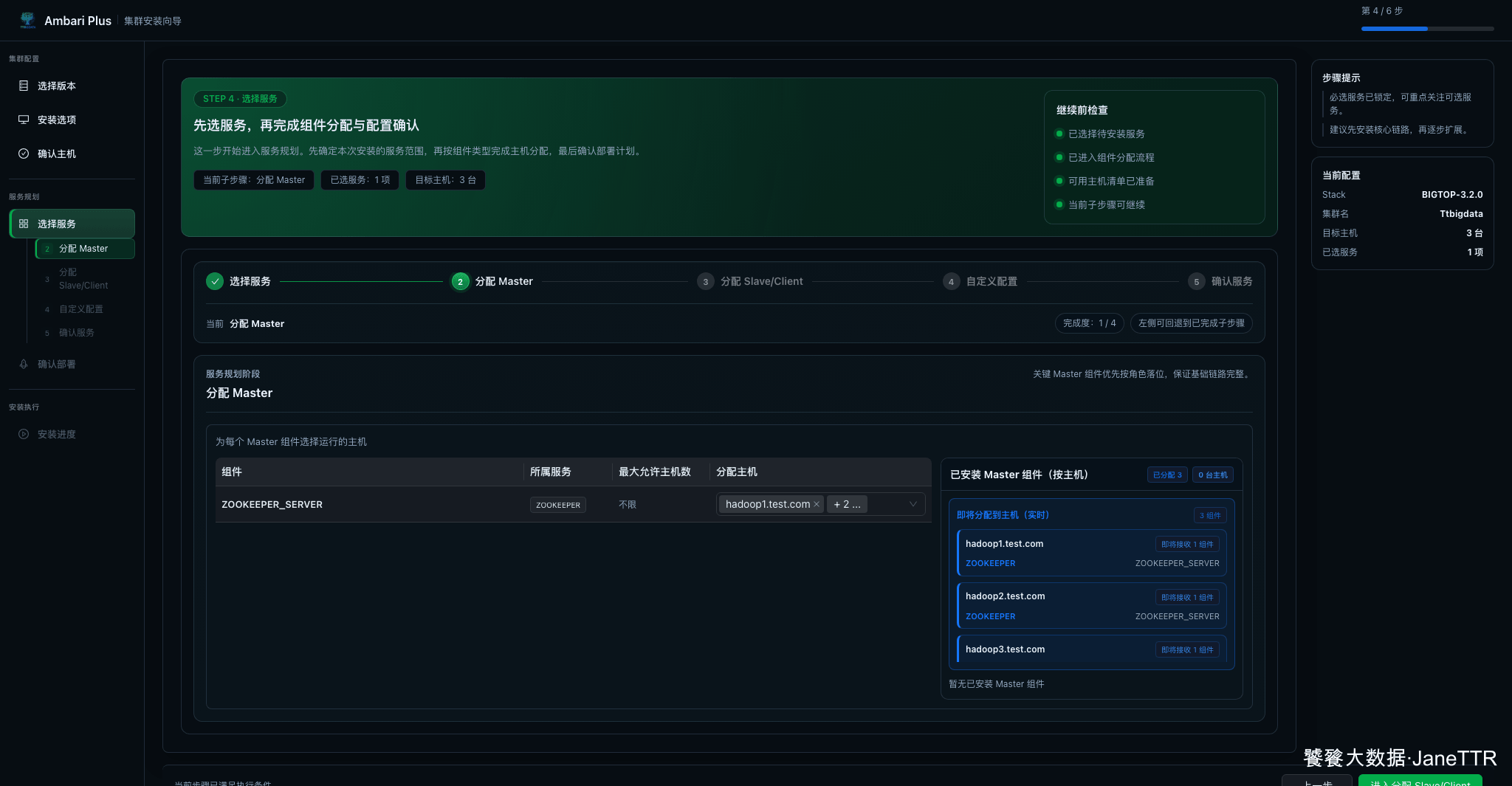
三节点 ZooKeeper 是比较常见的入门配置。它比单节点更接近生产形态,也能顺便验证三台主机都能安装、启动和参与服务检查。
7. 分配 Client 组件
Slave/Client 页面里没有需要分配的 Slave 组件,ZOOKEEPER_CLIENT 默认分配到三台主机。
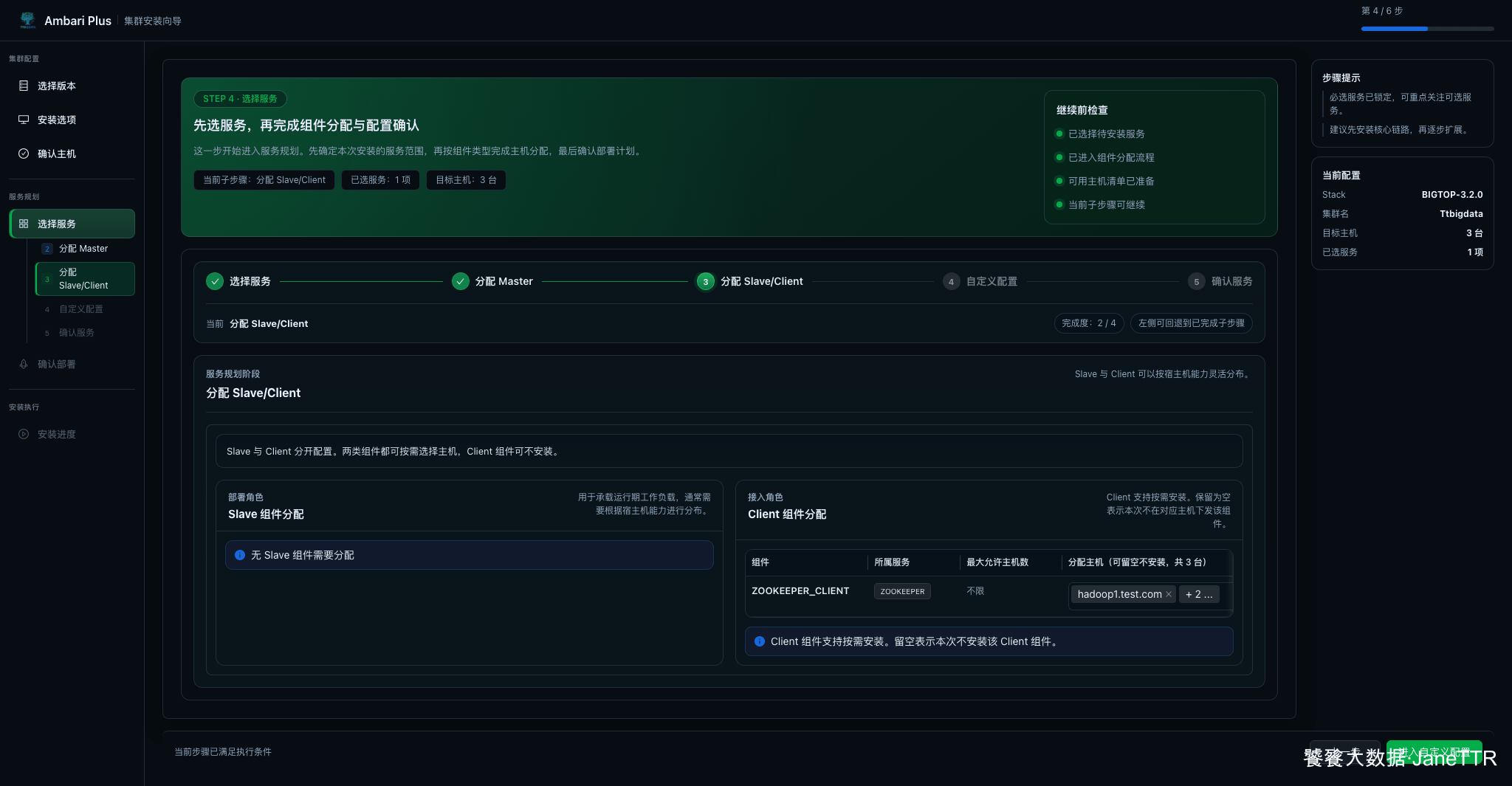
Client 组件不是每个服务都必须铺满所有节点,但 ZooKeeper Client 放在三台机器上问题不大。后续安装 HDFS、YARN、Hive 时,Client 分配就需要结合实际使用入口再决定。
8. 检查自定义配置
自定义配置页会根据当前服务和主机自动推荐一批参数。本文这里没有待填写项,ZooKeeper directory 推荐为:
text
/hadoop/zookeeper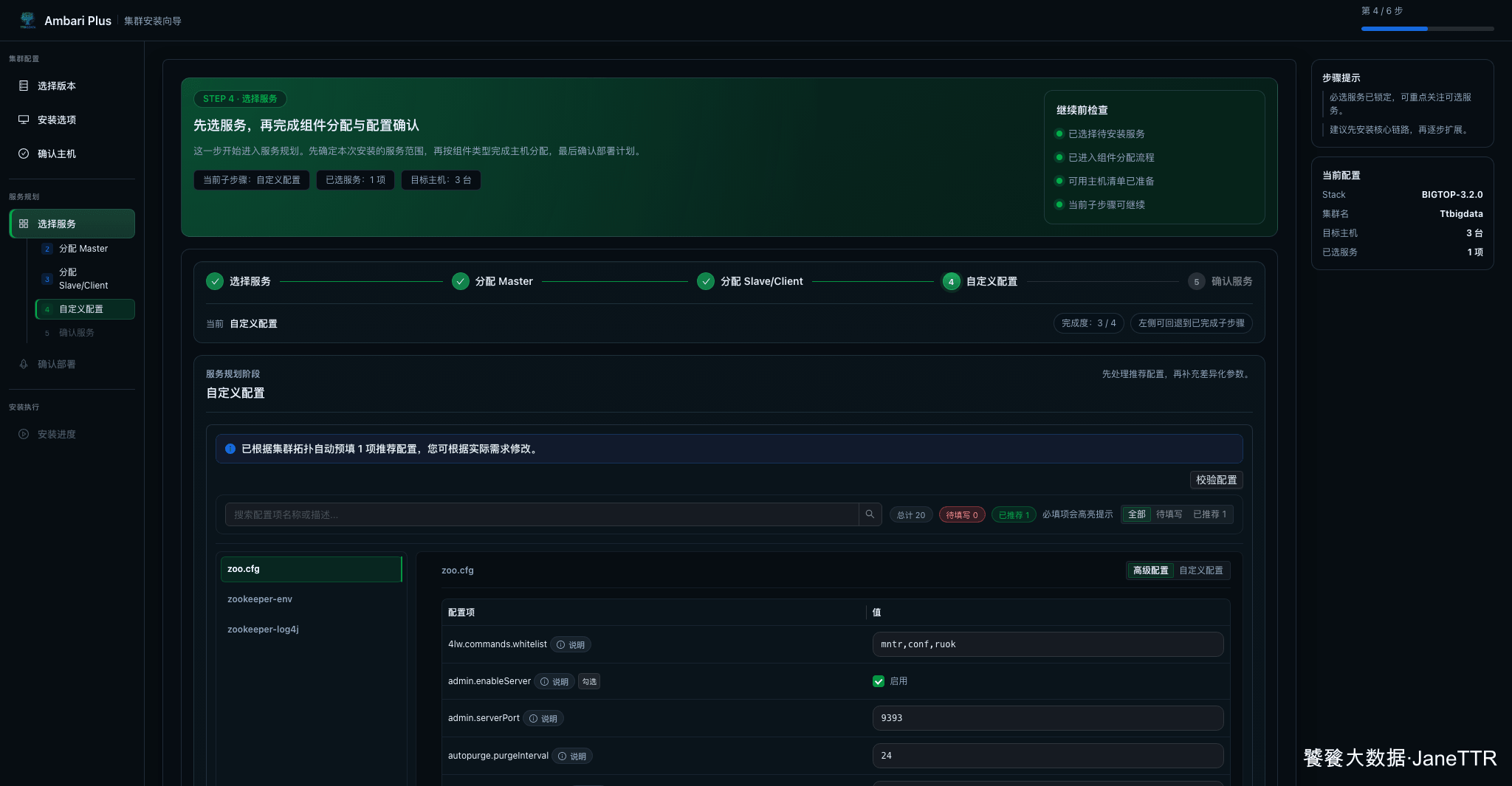
这里不建议为了"看起来专业"随意改参数。刚开始只要确认没有待填写项,目录符合自己的磁盘规划即可。等服务跑起来以后,再单独做容量、日志、端口和性能参数优化。
9. 确认服务规划
确认服务页会汇总本次新增服务、Client 分配和配置校验结果。本文这里可以看到新增服务为 ZOOKEEPER,Client 分配到三台主机,必填项已填写。
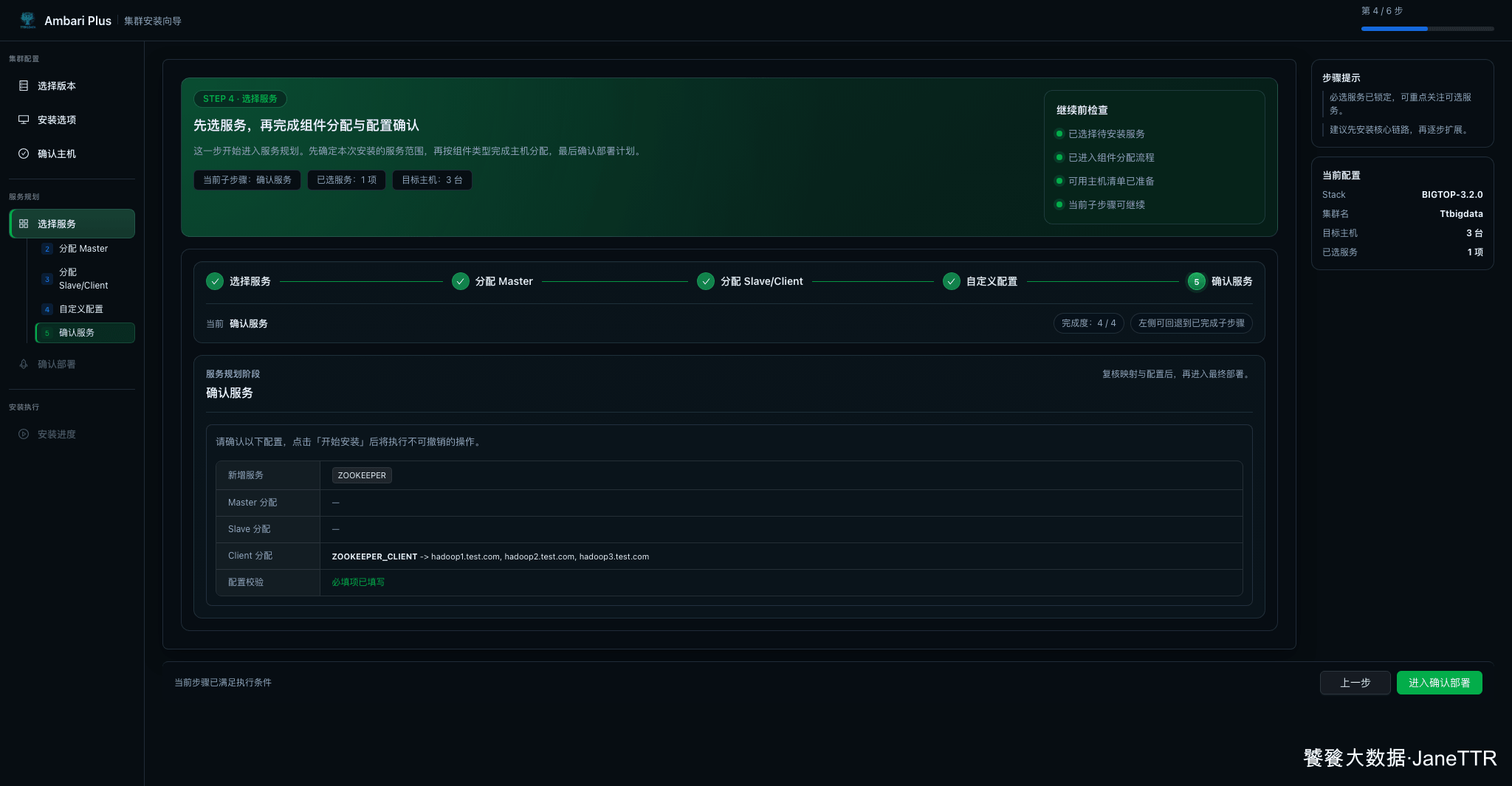
这一页适合停一下,确认自己没有误选太多服务。特别是第一次安装时,我建议先把服务范围控制住,等基础链路稳定以后再扩展。
10. 最终确认并开始安装
确认部署页会列出集群名、Stack 版本、主机列表和服务清单。确认无误后点击 开始安装。
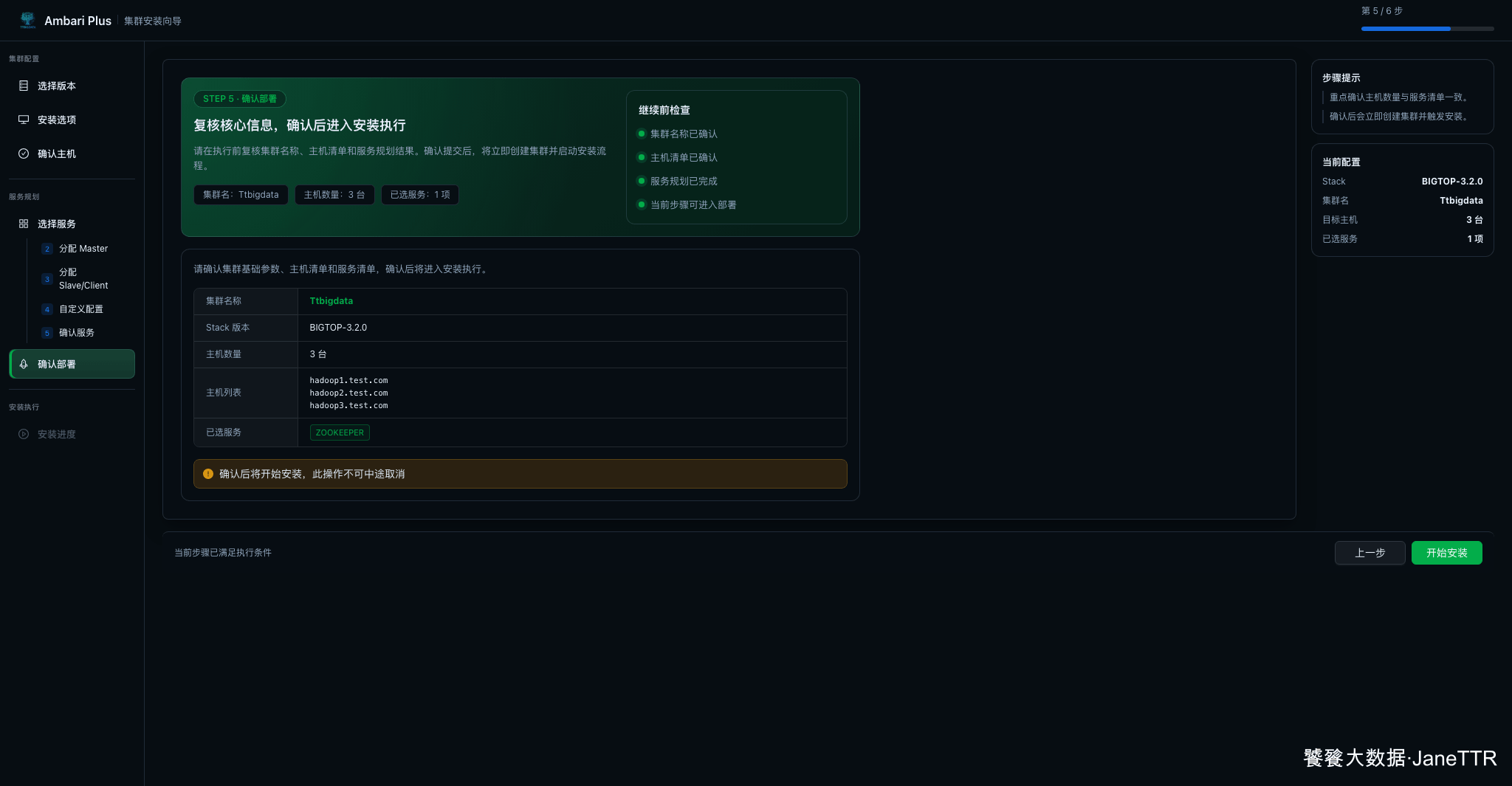
点击以后会立即创建集群并触发安装任务,这一步就不再是单纯的页面配置了。
11. 观察安装进度
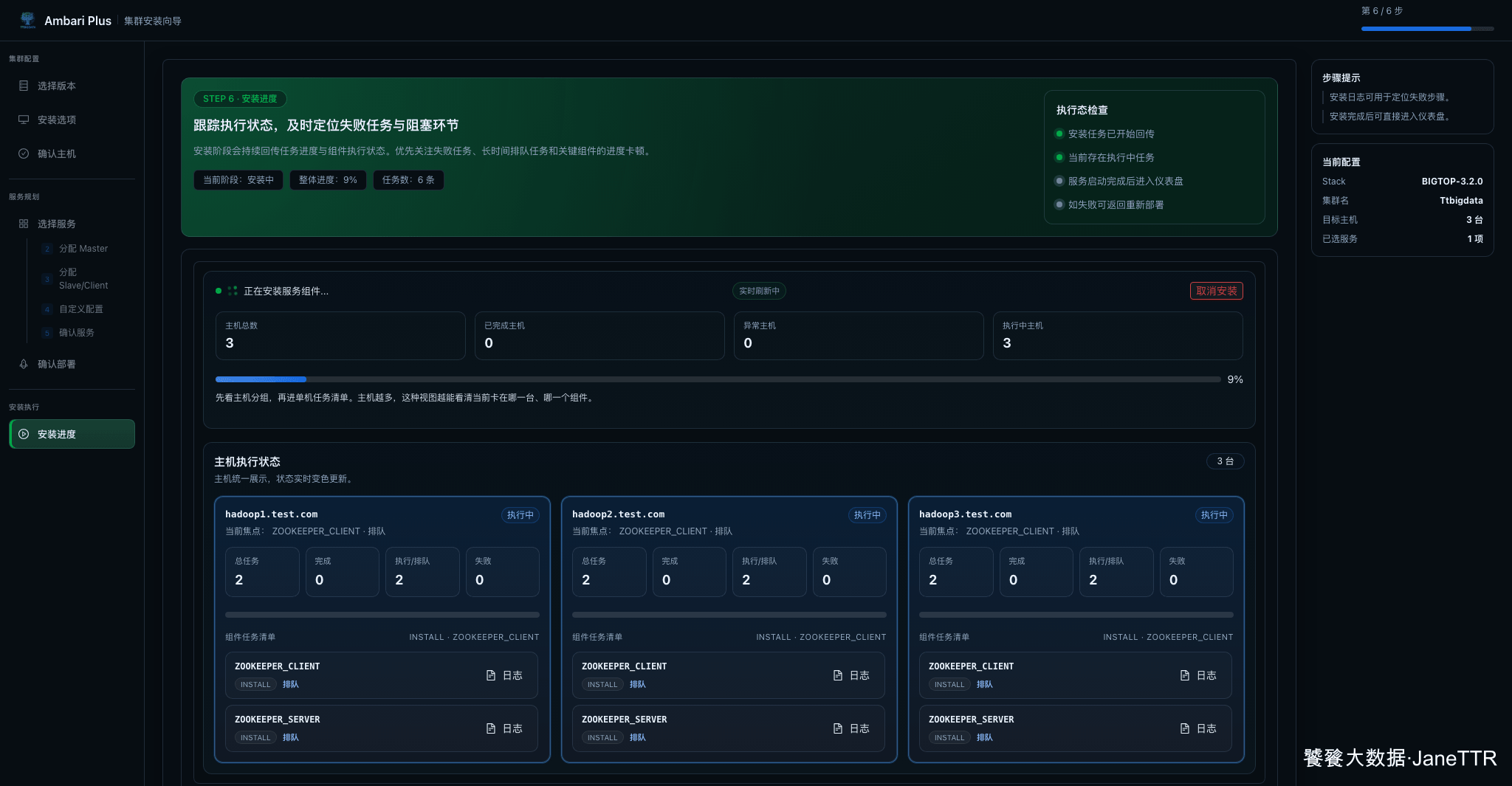
安装进度页会按主机展示组件任务。刚开始时可以看到各主机任务进入执行中,页面会持续刷新。
安装完成后,页面显示整体进度 100%,三台主机完成,异常主机为 0。本文这次还跑过了 ZOOKEEPER_QUORUM_SERVICE_CHECK。
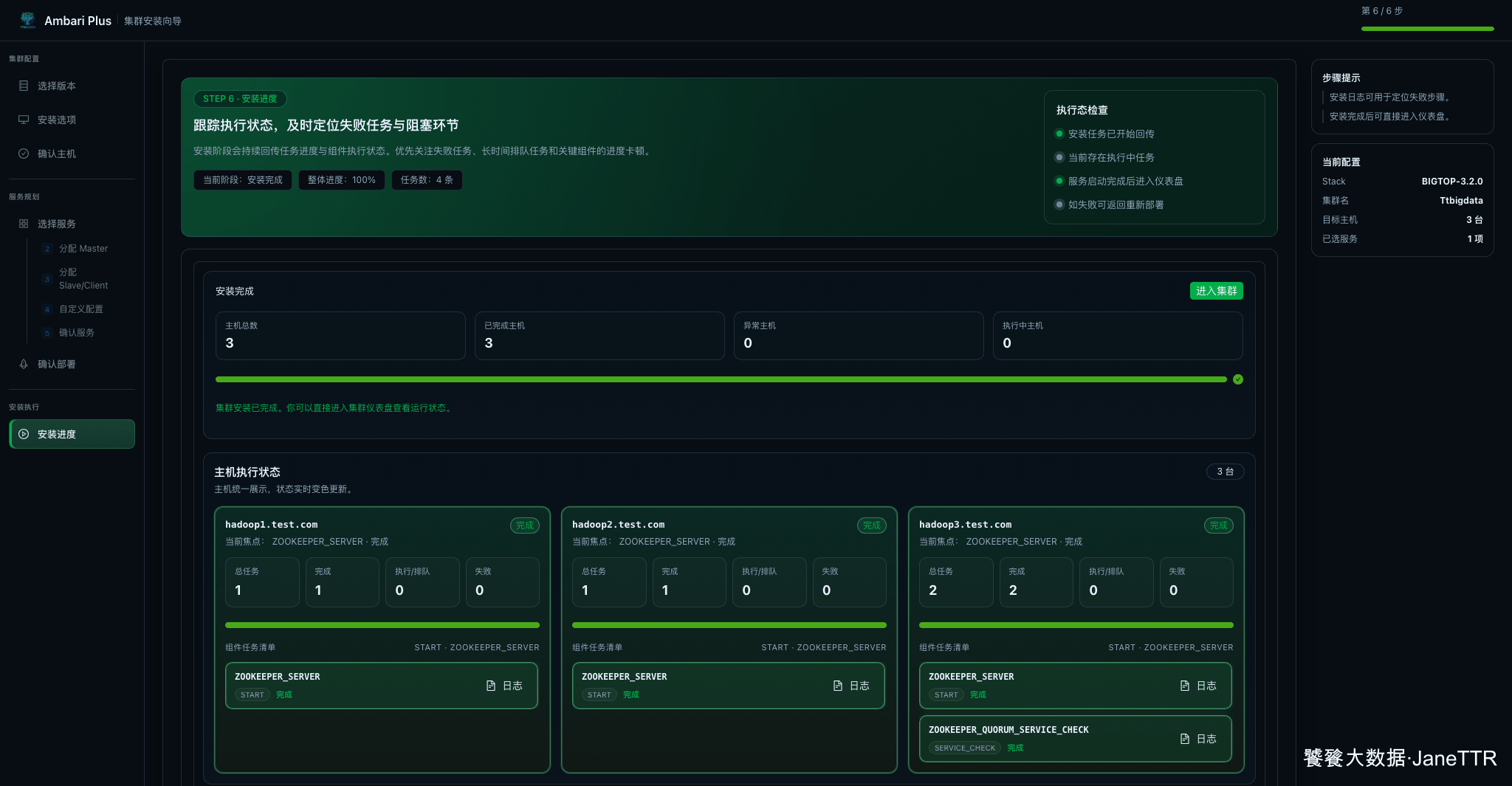
这一步看起来只是进度条完成,但我会重点看四个结果:
| 结果 | 期望值 |
|---|---|
| 整体进度 | 100% |
| 已完成主机 | 3 |
| 异常主机 | 0 |
| Service Check | ZOOKEEPER_QUORUM_SERVICE_CHECK 完成 |
12. 回到控制台确认服务入口
点击 进入集群 后,页面会进入 Ambari Plus 控制台。本文示例进入了"服务与组件"页面,可以看到服务总数为 1,ZOOKEEPER 处于运行中。
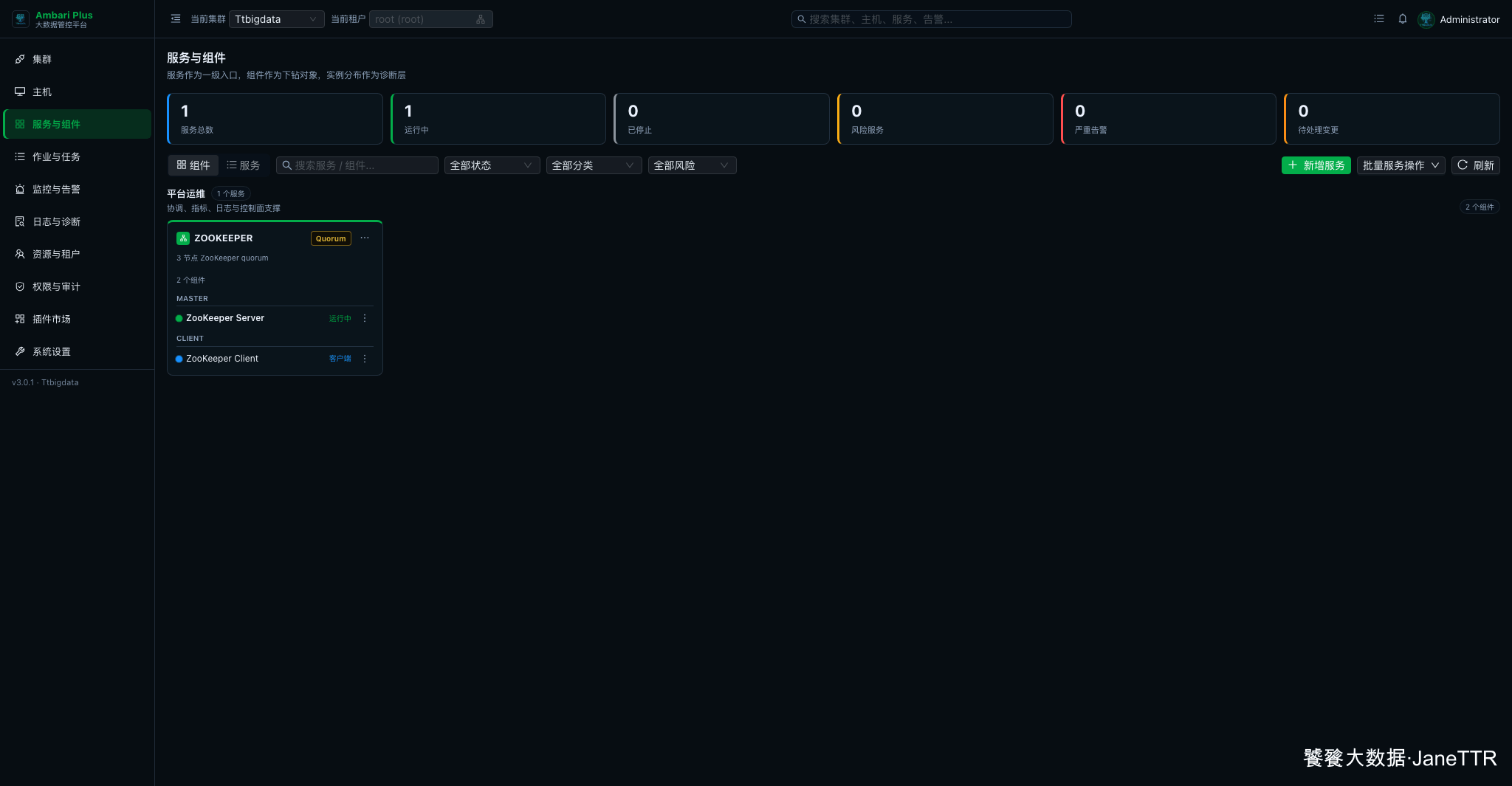
到这里,第一个集群已经初始化完成。