效果:
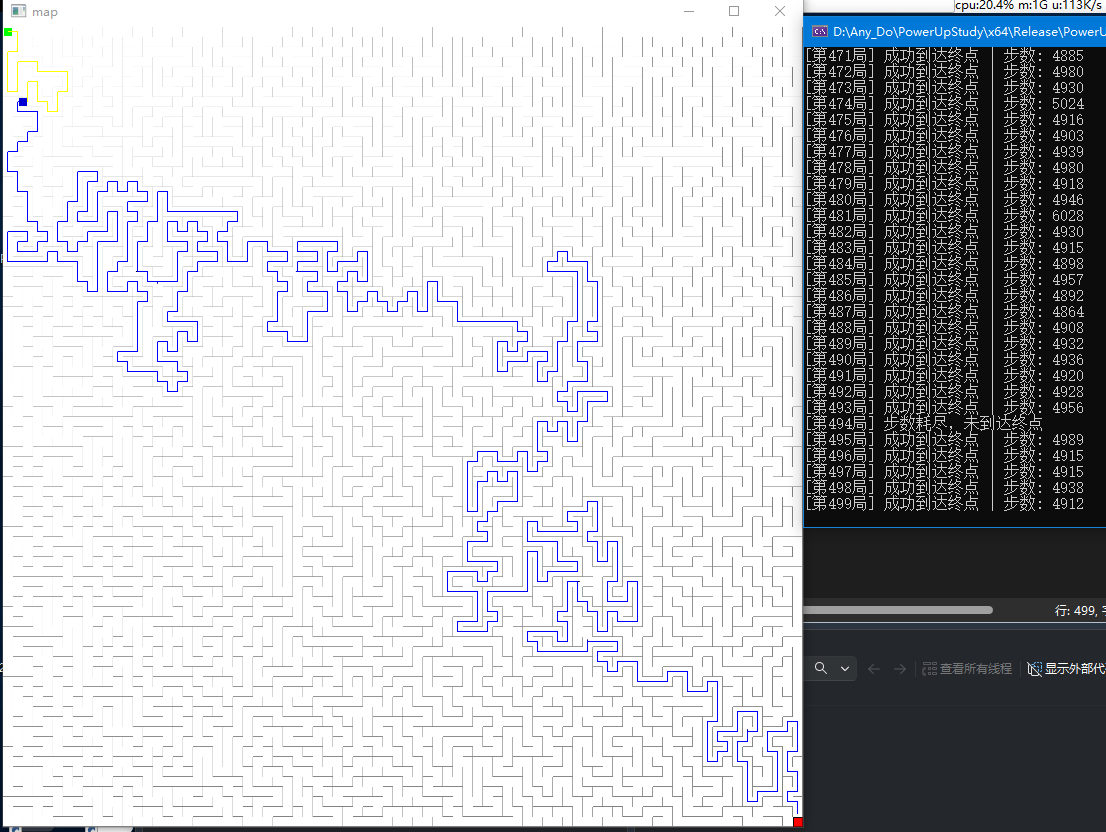
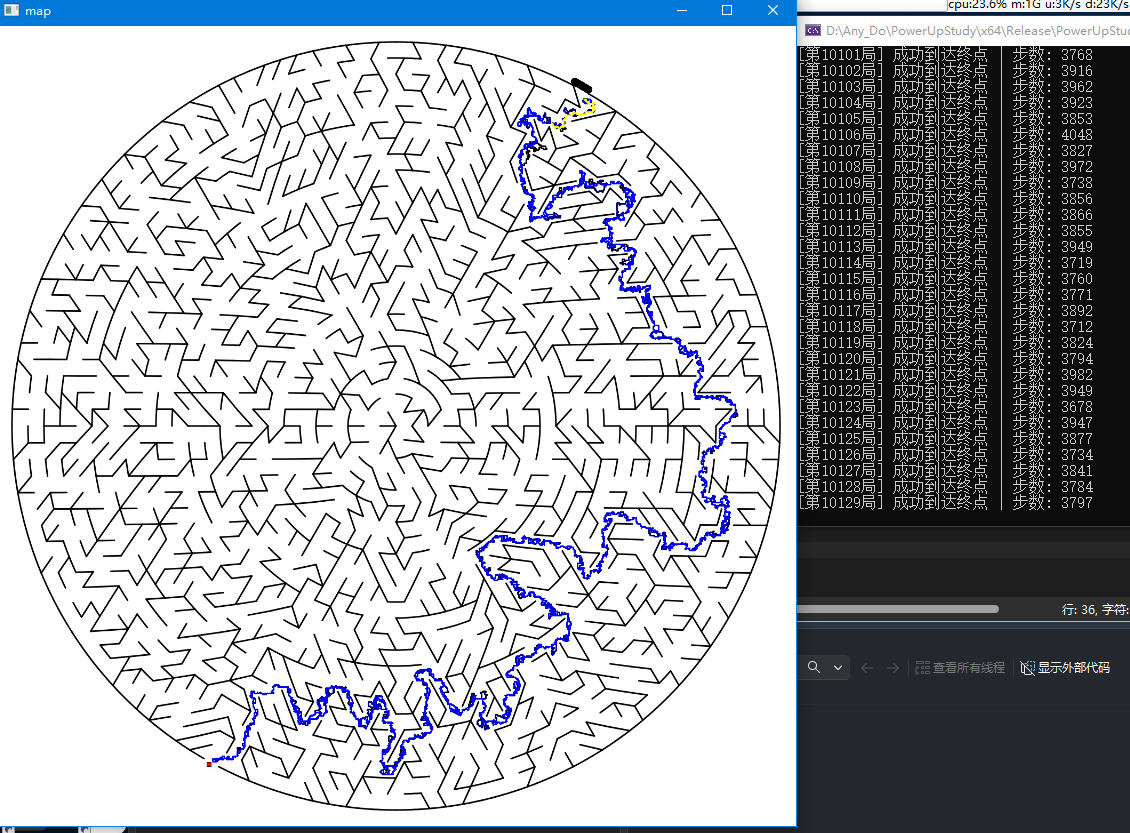
项目目的为个人学习,此处仅做文章记录,供开发参考。如被csdn平台自行变为vip,可评论通知,我会自行发布回公开,毕竟这个只是个笔记一样的文章...
QLearning:走迷宫
支持任意不规则迷宫,令自定义尺寸的智能体通过强化学习寻觅到通往终点的道路。
此处为了让一个模块可以适配各种不同的场景需求,将QLearning部分抽出成模块,具体问题处理部分设置为回调。
现有如下QLearning的通用模块和具体功能实现。
QLearning通用模块代码:
cpp
//QLearning模块
class Qlearning {
public:
//Q表参数
struct StQTable {
int iCols; //列数
int iRows; //行数
int iActions; //选项数
};
//步骤结果
struct StStepResult {
int iCurSY; //被更新的Q表状态空间X位置
int iCurSX; //被更新的Q表状态空间Y位置
int iAction; //被更新的Q表指定状态空间中采用的动作
double dReward; //本次产生的奖励
double dNextMaxQ; //下一个最佳动作的Q值
bool isPass; //是否已通关本局
bool isStepOver;//是否已步骤达到约定上限
};
//初始化模块
bool Init(StQTable(*createQTable)(void* pUserData), void* pUserData);
//重置回初始开局时的回调方法
void SetResetEpisodeCallBack(void (*resetEpisodeCallBack)(Qlearning* qlearning, void* pUserData)) {
this->resetEpisodeCallBack = resetEpisodeCallBack;
}
//下一步时的回调方法
void SetNextStepCallBack(bool (*nextStepCallBack)(Qlearning* qlearning, StStepResult& stStepResult, void* pUserData)) {
this->nextStepCallBack = nextStepCallBack;
}
//一局结束时的回调方法
void SetEpisodeFinishCallBack(void (*episodeFinishCallBack)(Qlearning* qlearning, bool isPass, void* pUserData)) {
this->episodeFinishCallBack = episodeFinishCallBack;
}
//返回有多少局是通过的
int GetPassCount() const { return m_iPassCount; }
//返回已经运行了多少局
int GetEpisodeCount() const { return m_iEpisodeCount; }
//获取指定状态的最大Q值
double GetMaxQ(int stateX, int stateY) const;
//ε-贪心策略选择动作(含随机)
int ChooseAction(int stateX, int stateY);
//执行一步决策与更新,返回false表示结束终止
bool NextStep();
//重置单局状态,回到起点开始新一局
void ResetEpisode();
private:
void (*resetEpisodeCallBack)(Qlearning* qlearning, void* pUser) = nullptr;
bool (*nextStepCallBack)(Qlearning* qlearning, StStepResult& stStepResult, void* pUser) = nullptr;
void (*episodeFinishCallBack)(Qlearning* qlearning, bool isPass, void* pUser) = nullptr;
void* pUserData = nullptr;
StQTable m_stQTable; //Q表参数
std::vector<std::vector<std::vector<double>>> m_vecQTable; //Q表
//Q-learning超参数
double m_dAlpha = 0.1; //学习率
double m_dGamma = 0.9; //折扣因子
double m_dEpsilon = 0.1; //ε-贪心探索率
int m_iEpisodeCount = 1; //当前是第几局数
int m_iPassCount = 0; //已通关局数
};
bool Qlearning::Init(StQTable(*createQTable)(void* pUserData), void* pUserData) {
this->pUserData = pUserData;
if (nullptr == resetEpisodeCallBack) {
std::cerr << "resetEpisodeCallBack不可为空";
return false;
}
if (nullptr == nextStepCallBack) {
std::cerr << "nextStepCallBack不可为空";
return false;
}
if (nullptr == episodeFinishCallBack) {
std::cerr << "episodeFinishCallBack不可为空";
return false;
}
m_stQTable = createQTable(pUserData);
std::cout << "已创建Q表,大小" << m_stQTable.iCols << "x" << m_stQTable.iRows << std::endl;
//初始化Q表,所有状态-动作对初始值为0
m_vecQTable.resize(m_stQTable.iRows);
for (int y = 0; y < m_stQTable.iRows; ++y) {
m_vecQTable[y].resize(m_stQTable.iCols);
for (int x = 0; x < m_stQTable.iCols; ++x) {
m_vecQTable[y][x].resize(m_stQTable.iActions, 0.0);
}
}
ResetEpisode();
return true;
}
double Qlearning::GetMaxQ(int stateX, int stateY) const {
double maxQ = -1e9;
for (int a = 0; a < m_stQTable.iActions; ++a) {
maxQ = std::max(maxQ, m_vecQTable[stateY][stateX][a]);
}
return maxQ;
}
int Qlearning::ChooseAction(int stateX, int stateY) {
//ε概率随机探索
if ((std::rand() / static_cast<double>(RAND_MAX)) < m_dEpsilon) {
return std::rand() % m_stQTable.iActions;
}
//贪心选择Q值最大的动作
double maxQ = -1e9;
int bestAction = 0;
for (int a = 0; a < m_stQTable.iActions; ++a) {
if (m_vecQTable[stateY][stateX][a] > maxQ) {
maxQ = m_vecQTable[stateY][stateX][a];
bestAction = a;
}
}
return bestAction;
}
void Qlearning::ResetEpisode() {
resetEpisodeCallBack(this, pUserData);
}
bool Qlearning::NextStep() {
StStepResult stStepResult;
int isContinue = nextStepCallBack(this, stStepResult, pUserData);
//贝尔曼方程更新Q表
m_vecQTable[stStepResult.iCurSY][stStepResult.iCurSX][stStepResult.iAction] +=
m_dAlpha * (stStepResult.dReward + m_dGamma * stStepResult.dNextMaxQ - m_vecQTable[stStepResult.iCurSY][stStepResult.iCurSX][stStepResult.iAction]);
//本局结束判定
if (stStepResult.isPass || stStepResult.isStepOver) {
if (stStepResult.isPass)
++m_iPassCount;
episodeFinishCallBack(this, stStepResult.isPass, pUserData);
//重置状态,开启下一局
ResetEpisode();
++m_iEpisodeCount;
}
return isContinue;
}对于这个模块的使用,我们使用Qlearning qlearning新建对象。
随后在Init之前设置三个回调
SetResetEpisodeCallBack :将自己的自定义数据还原回初始开局。
SetNextStepCallBack :控制返回true还是false来表达是否仍应该继续强化学习,并设置从参数中由模型传入StStepResult结构体的各项数值,进行Q表的采样数据更新,用于他的强化学习。
SetEpisodeFinishCallBack :一局结束后的回调,告知本局是否达成目标。
这之后,Init时也需传入一个回调,其返回值用于告知模型要创建的Q表尺寸和动作数。
随后持续地NextStep,进行模型的强化学习,途中会不断调用SetNextStepCallBack回调做采样和更新,直至在回调内按自定义条件返回false时终止,此时可以视作强化学习完成。
比如本文核心例子,为应对走迷宫的需求,使用QLearning模块的完整例程如下
cpp
//C++20支持
/*
Qlearning类内允许上下左右四个方向的移动,目标是碰到终点,即智能体与终点有哪怕一个像素的重叠。
普通走路扣1分
走到了以前走过的路扣20分
和地图的黑色墙壁撞一块了扣100分
遇到终点了+一万分
步数上限为地图长*宽/移动步长
如果到达了终点,那么在图中留下一条起点到终点的移动路径。
每一局过去,上一次的移动路径都会逐渐变淡消失,十局后彻底消失
*/
#include <iostream>
#include <vector>
#include <iomanip>
#include <cmath>
#include <cstdlib>
#include <ctime>
#include <algorithm>
#include <utility>
#include <opencv2/opencv.hpp>
//#include "Eigen/Dense"
//不需要这个,new一个大的数组去存和算Q表就好
//至少多少局后再开始渲染画面
#define NO_RENDER_MIN 0
//至少通过多少局后再开始渲染画面
#define PASS_MIN 5000
//智能体
struct StPawn {
int iCurX; //智能体中心X像素坐标
int iCurY; //智能体中心Y像素坐标
int iLen; //智能体正方形边长(半边长用于边界计算)
cv::Scalar color; //智能体绘制颜色 BGR
};
//历史路径结构体:存储路径点与透明度
struct StHistoryPath {
std::vector<cv::Point> path;
double alpha;
};
//动作枚举:上下左右四个方向
enum EAction {
UP = 0,
DOWN,
LEFT,
RIGHT,
ACTION_COUNT
};
//在地图图像绘制网格,间隔30像素横竖线,标注像素坐标与单位,辅助用户定位落点坐标
cv::Mat DrawXYLineAtMap(const cv::Mat& matMap)
{
const int GRID_STEP = 30; //网格间隔像素
const cv::Scalar LINE_COLOR(120, 120, 120); //网格线条颜色 BGR灰色
const int LINE_THICK = 1; //网格线条粗细
const cv::Scalar TEXT_COLOR(0, 0, 255); //坐标文字颜色 BGR红色
const double FONT_SCALE = 0.4; //文字缩放系数
const int TEXT_THICK = 1; //文字线条粗细
const int TEXT_GAP = GRID_STEP * 2; //每2个网格标注一次坐标,避免文字重叠
cv::Mat matXYLine = matMap.clone();
int iImgW = matXYLine.cols;
int iImgH = matXYLine.rows;
//绘制纵向竖线
for (int iX = 0; iX < iImgW; iX += GRID_STEP)
{
cv::line(matXYLine, cv::Point(iX, 0), cv::Point(iX, iImgH - 1), LINE_COLOR, LINE_THICK);
//间隔指定网格标注X坐标文字
if (iX % TEXT_GAP == 0)
{
const std::string szText = "X:" + std::to_string(iX);
cv::putText(matXYLine, szText, cv::Point(iX + 2, 12),
cv::FONT_HERSHEY_SIMPLEX, FONT_SCALE, TEXT_COLOR, TEXT_THICK);
}
}
//绘制横向横线 (固定Y,横向贯穿整张图)
for (int iY = 0; iY < iImgH; iY += GRID_STEP)
{
cv::line(matXYLine, cv::Point(0, iY), cv::Point(iImgW - 1, iY), LINE_COLOR, LINE_THICK);
//间隔指定网格标注Y坐标文字
if (iY % TEXT_GAP == 0)
{
const std::string szText = "Y:" + std::to_string(iY);
cv::putText(matXYLine, szText, cv::Point(2, iY + 12),
cv::FONT_HERSHEY_SIMPLEX, FONT_SCALE, TEXT_COLOR, TEXT_THICK);
}
}
//底部绘制网格单位说明文字
const std::string szUnitTip = "Unit:30 Pixel";
cv::putText(matXYLine, szUnitTip, cv::Point(5, iImgH - 8),
cv::FONT_HERSHEY_SIMPLEX, FONT_SCALE, cv::Scalar(0, 255, 0), TEXT_THICK);
return matXYLine;
}
//在地图上把智能体绘制出来
cv::Mat DrawPawnAtMap(const cv::Mat& matMap, const StPawn& stPawn)
{
cv::Mat matResult = matMap.clone();
cv::Point ptTopLeft(stPawn.iCurX, stPawn.iCurY);
cv::Point ptBottomRight(stPawn.iCurX + stPawn.iLen, stPawn.iCurY + stPawn.iLen);
//实心填充正方形作为智能体
cv::rectangle(matResult, ptTopLeft, ptBottomRight, stPawn.color, cv::FILLED);
//增加黑色描边给智能体
cv::rectangle(matResult, ptTopLeft, ptBottomRight, cv::Scalar(0, 0, 0), 1);
return matResult;
}
//将具体像素坐标根据步长进行缩放,比如将100个像素根据步长20,划分为5格,简化并加速后续运算和移动
std::pair<int, int> PosToState(int x, int y, int iMoveStep) {
return { x / iMoveStep, y / iMoveStep };
}
//返回智能体是否撞墙了(没完整地在道路上,即和墙存在重合视作撞墙)
bool IsHitGrid(const cv::Mat& matMap, const StPawn& stPawn)
{
const int iBoxLeft = stPawn.iCurX;
const int iBoxRight = stPawn.iCurX + stPawn.iLen;
const int iBoxTop = stPawn.iCurY;
const int iBoxBottom = stPawn.iCurY + stPawn.iLen;
const int iImgW = matMap.cols;
const int iImgH = matMap.rows;
//超出地图边界直接判定碰撞
if (iBoxLeft < 0 || iBoxRight >= iImgW || iBoxTop < 0 || iBoxBottom >= iImgH)
return true;
//遍历智能体包围盒内所有像素,检测墙壁(三通道RGB图的非纯白像素均视作墙壁,这里用RGB<(200,200,200)认为是墙壁)
for (int iY = iBoxTop; iY <= iBoxBottom; ++iY)
{
for (int iX = iBoxLeft; iX <= iBoxRight; ++iX)
{
cv::Vec3b vPixel = matMap.at<cv::Vec3b>(iY, iX);
if (vPixel[0] < 200 || vPixel[1] < 200 || vPixel[2] < 200)
{
return true;
}
}
}
return false;
}
//是否两个智能体相撞了(目前用于检测是否撞到了终点)
bool IsHitPawn(const StPawn& pawnSrc, const StPawn& pawnDst) {
//智能体包围盒(左上角+边长)
int pawnL = pawnSrc.iCurX;
int pawnR = pawnSrc.iCurX + pawnSrc.iLen;
int pawnT = pawnSrc.iCurY;
int pawnB = pawnSrc.iCurY + pawnSrc.iLen;
//终点包围盒
int tgtL = pawnDst.iCurX;
int tgtR = pawnDst.iCurX + pawnDst.iLen;
int tgtT = pawnDst.iCurY;
int tgtB = pawnDst.iCurY + pawnDst.iLen;
//矩形相交判定
return !(pawnR < tgtL || pawnL > tgtR || pawnB < tgtT || pawnT > tgtB);
}
//QLearning模块
class Qlearning {
public:
//Q表参数
struct StQTable {
int iCols; //列数
int iRows; //行数
int iActions; //选项数
};
//步骤结果
struct StStepResult {
int iCurSY; //被更新的Q表状态空间X位置
int iCurSX; //被更新的Q表状态空间Y位置
int iAction; //被更新的Q表指定状态空间中采用的动作
double dReward; //本次产生的奖励
double dNextMaxQ; //下一个最佳动作的Q值
bool isPass; //是否已通关本局
bool isStepOver;//是否已步骤达到约定上限
};
//初始化模块
bool Init(StQTable(*createQTable)(void* pUserData), void* pUserData);
//重置回初始开局时的回调方法
void SetResetEpisodeCallBack(void (*resetEpisodeCallBack)(Qlearning* qlearning, void* pUserData)) {
this->resetEpisodeCallBack = resetEpisodeCallBack;
}
//下一步时的回调方法
void SetNextStepCallBack(bool (*nextStepCallBack)(Qlearning* qlearning, StStepResult& stStepResult, void* pUserData)) {
this->nextStepCallBack = nextStepCallBack;
}
//一局结束时的回调方法
void SetEpisodeFinishCallBack(void (*episodeFinishCallBack)(Qlearning* qlearning, bool isPass, void* pUserData)) {
this->episodeFinishCallBack = episodeFinishCallBack;
}
//返回有多少局是通过的
int GetPassCount() const { return m_iPassCount; }
//返回已经运行了多少局
int GetEpisodeCount() const { return m_iEpisodeCount; }
//获取指定状态的最大Q值
double GetMaxQ(int stateX, int stateY) const;
//ε-贪心策略选择动作(含随机)
int ChooseAction(int stateX, int stateY);
//执行一步决策与更新,返回false表示结束终止
bool NextStep();
//重置单局状态,回到起点开始新一局
void ResetEpisode();
private:
void (*resetEpisodeCallBack)(Qlearning* qlearning, void* pUser) = nullptr;
bool (*nextStepCallBack)(Qlearning* qlearning, StStepResult& stStepResult, void* pUser) = nullptr;
void (*episodeFinishCallBack)(Qlearning* qlearning, bool isPass, void* pUser) = nullptr;
void* pUserData = nullptr;
StQTable m_stQTable; //Q表参数
std::vector<std::vector<std::vector<double>>> m_vecQTable; //Q表
//Q-learning超参数
double m_dAlpha = 0.1; //学习率
double m_dGamma = 0.9; //折扣因子
double m_dEpsilon = 0.1; //ε-贪心探索率
int m_iEpisodeCount = 1; //当前是第几局数
int m_iPassCount = 0; //已通关局数
};
bool Qlearning::Init(StQTable(*createQTable)(void* pUserData), void* pUserData) {
this->pUserData = pUserData;
if (nullptr == resetEpisodeCallBack) {
std::cerr << "resetEpisodeCallBack不可为空";
return false;
}
if (nullptr == nextStepCallBack) {
std::cerr << "nextStepCallBack不可为空";
return false;
}
if (nullptr == episodeFinishCallBack) {
std::cerr << "episodeFinishCallBack不可为空";
return false;
}
m_stQTable = createQTable(pUserData);
std::cout << "已创建Q表,大小" << m_stQTable.iCols << "x" << m_stQTable.iRows << std::endl;
//初始化Q表,所有状态-动作对初始值为0
m_vecQTable.resize(m_stQTable.iRows);
for (int y = 0; y < m_stQTable.iRows; ++y) {
m_vecQTable[y].resize(m_stQTable.iCols);
for (int x = 0; x < m_stQTable.iCols; ++x) {
m_vecQTable[y][x].resize(m_stQTable.iActions, 0.0);
}
}
ResetEpisode();
return true;
}
double Qlearning::GetMaxQ(int stateX, int stateY) const {
double maxQ = -1e9;
for (int a = 0; a < m_stQTable.iActions; ++a) {
maxQ = std::max(maxQ, m_vecQTable[stateY][stateX][a]);
}
return maxQ;
}
int Qlearning::ChooseAction(int stateX, int stateY) {
//ε概率随机探索
if ((std::rand() / static_cast<double>(RAND_MAX)) < m_dEpsilon) {
return std::rand() % m_stQTable.iActions;
}
//贪心选择Q值最大的动作
double maxQ = -1e9;
int bestAction = 0;
for (int a = 0; a < m_stQTable.iActions; ++a) {
if (m_vecQTable[stateY][stateX][a] > maxQ) {
maxQ = m_vecQTable[stateY][stateX][a];
bestAction = a;
}
}
return bestAction;
}
void Qlearning::ResetEpisode() {
resetEpisodeCallBack(this, pUserData);
}
bool Qlearning::NextStep() {
StStepResult stStepResult;
int isContinue = nextStepCallBack(this, stStepResult, pUserData);
//贝尔曼方程更新Q表
m_vecQTable[stStepResult.iCurSY][stStepResult.iCurSX][stStepResult.iAction] +=
m_dAlpha * (stStepResult.dReward + m_dGamma * stStepResult.dNextMaxQ - m_vecQTable[stStepResult.iCurSY][stStepResult.iCurSX][stStepResult.iAction]);
//本局结束判定
if (stStepResult.isPass || stStepResult.isStepOver) {
if (stStepResult.isPass)
++m_iPassCount;
episodeFinishCallBack(this, stStepResult.isPass, pUserData);
//重置状态,开启下一局
ResetEpisode();
++m_iEpisodeCount;
}
return isContinue;
}
struct StUserData {
cv::Mat matMap; //迷宫原图
StPawn stPawn; //当前智能体状态
StPawn stStartPoint; //起点
StPawn stTargetPoint; //终点
int iMoveStep; //单步移动像素步长
int iStepCount; //当前局已走步数
std::vector<std::vector<bool>> vecVisited; //本局访问标记
int iStateWidth; //离散状态空间宽度
int iStateHeight; //离散状态空间高度
int iStepCountMax; //单局步数上限
std::vector<cv::Point> vecCurrentPath; //当前局路径点
std::deque<StHistoryPath> deqHistoryPath; //历史成功路径队列
};
void Render(const Qlearning& qlearning, const StUserData& stUserData) {
if (qlearning.GetPassCount() < PASS_MIN)
return;
if (qlearning.GetEpisodeCount() < NO_RENDER_MIN)
return;
cv::Mat matRender;
//绘制起点与终点
matRender = DrawPawnAtMap(stUserData.matMap, stUserData.stStartPoint);
matRender = DrawPawnAtMap(matRender, stUserData.stTargetPoint);
//绘制历史成功路径(蓝色,随局数增加逐渐变淡)
for (const auto& hist : stUserData.deqHistoryPath) {
if (hist.path.size() < 2) continue;
uchar blueVal = static_cast<uchar>(255 * std::max(0.0, hist.alpha));
cv::Scalar pathColor(blueVal, 0, 0);
for (size_t i = 0; i < hist.path.size() - 1; ++i) {
cv::line(matRender, hist.path[i], hist.path[i + 1], pathColor, 2);
}
}
//绘制当前局已行走了的路径(黄色实线)
if (stUserData.vecCurrentPath.size() >= 2) {
for (size_t i = 0; i < stUserData.vecCurrentPath.size() - 1; ++i) {
cv::line(matRender, stUserData.vecCurrentPath[i], stUserData.vecCurrentPath[i + 1], cv::Scalar(0, 255, 255), 2);
}
}
//绘制当前智能体
matRender = DrawPawnAtMap(matRender, stUserData.stPawn);
cv::resize(matRender, matRender, cv::Size(800, 800));
//显示画面
cv::imshow("map", matRender);
cv::waitKey(1);
}
int main()
{
std::srand(static_cast<unsigned int>(std::time(nullptr)));
const std::string szImgPath = "D:\\Any_Do\\PowerUpStudy\\x64\\Release\\map2.png";
cv::Mat matMap = cv::imread(szImgPath);
if (matMap.empty()) {
std::cerr << "迷宫的RGB图片(白底黑边) " << szImgPath << " 不存在,请采集自:https://www.lddgo.net/math/maze-generator" << std::endl;
return -1;
}
const int iMapGridW = matMap.cols;
const int iMapGridH = matMap.rows;
std::cout << "地图宽:" << iMapGridW << " 高:" << iMapGridH << std::endl;
cv::Mat matShow;
//给地图每隔30像素就画上一条横线或竖线,以做网格划分,并列出单位,帮助用户认知到他想落下的位置的坐标大概是多少
cv::Mat matXYLine = DrawXYLineAtMap(matMap);
cv::resize(matXYLine, matShow, cv::Size(800, 800));
cv::imshow("map", matShow);
cv::moveWindow("map", 0, 0);
cv::waitKey(1);
StPawn stPawn, stStartPoint, stTargetPoint;
stPawn.iLen = 0;
while (stPawn.iLen <= 0) {
std::cout << "请输入智能体正方形的边长值:";
std::cin >> stPawn.iLen;
}
stStartPoint.iLen = stTargetPoint.iLen = stPawn.iLen;
std::cout << "智能体正方形的边长本次设置为" << stPawn.iLen << std::endl;
//===================== 配置三类Pawn颜色(BGR格式)=====================
stPawn.color = cv::Scalar(211, 0, 0); //运行智能体:蓝色
stStartPoint.color = cv::Scalar(0, 255, 0); //起点:绿色
stTargetPoint.color = cv::Scalar(0, 0, 255); //终点:红色
int iMoveStep = 0;
while (iMoveStep <= 0) {
std::cout << "请输入智能体的移动步长值:";
std::cin >> iMoveStep;
}
std::cout << "智能体的移动步长本次设置为" << iMoveStep << std::endl;
//输入起点
stStartPoint.iCurX = 0;
stStartPoint.iCurY = 0;
while (true) {
std::cout << "请输入起点的xy值,首先是横坐标x值:";
std::cin >> stStartPoint.iCurX;
std::cout << "请输入起点的xy值,然后是竖坐标y值:";
std::cin >> stStartPoint.iCurY;
cv::Mat matStartPoint = DrawPawnAtMap(matXYLine, stStartPoint);
cv::resize(matStartPoint, matShow, cv::Size(800, 800));
cv::imshow("map", matShow);
cv::waitKey(1);
bool bIsHitGrid = IsHitGrid(matMap, stStartPoint);
if (bIsHitGrid) {
std::cout << "落点与墙壁冲突或超出地图边界,请重新输入落点位置..." << std::endl;
continue;
}
std::cout << "起点落点合法,无墙壁碰撞" << std::endl;
break;
}
//输入终点
stTargetPoint.iCurX = 0;
stTargetPoint.iCurY = 0;
while (true) {
std::cout << "请输入终点的xy值,首先是横坐标x值:";
std::cin >> stTargetPoint.iCurX;
std::cout << "请输入终点的xy值,然后是竖坐标y值:";
std::cin >> stTargetPoint.iCurY;
cv::Mat matStartTemp = DrawPawnAtMap(matXYLine, stStartPoint);
cv::Mat matTargetPoint = DrawPawnAtMap(matStartTemp, stTargetPoint);
cv::resize(matTargetPoint, matShow, cv::Size(800, 800));
cv::imshow("map", matShow);
cv::waitKey(1);
bool bIsHitGrid = IsHitGrid(matMap, stTargetPoint);
if (bIsHitGrid) {
std::cout << "落点与墙壁冲突或超出地图边界,请重新输入落点位置..." << std::endl;
continue;
}
std::cout << "终点落点合法,无墙壁碰撞" << std::endl;
break;
}
//画布叠加起点+终点
matXYLine = DrawPawnAtMap(matXYLine, stStartPoint);
matXYLine = DrawPawnAtMap(matXYLine, stTargetPoint);
cv::resize(matXYLine, matShow, cv::Size(800, 800));
cv::imshow("map", matShow);
cv::waitKey(1);
std::cout << "当前地图设置如图,按任意键开始" << std::endl;
system("pause");
static constexpr int MAX_HISTORY = 10; //历史路径最大保留局数
StUserData stUserData;
stUserData.matMap = matMap;
stUserData.stPawn = stPawn;
stUserData.stStartPoint = stStartPoint;
stUserData.stTargetPoint = stTargetPoint;
stUserData.iMoveStep = iMoveStep;
/*走迷宫5要素,matMap, stPawn, stStartPoint, stTargetPoint, iMoveStep均已经准备完成*/
Qlearning qlearning;
qlearning.SetResetEpisodeCallBack([](Qlearning* qlearning, void* pUserData) {
StUserData& stUserData = *((StUserData*)pUserData);
//智能体回到起点
stUserData.stPawn.iCurX = stUserData.stStartPoint.iCurX;
stUserData.stPawn.iCurY = stUserData.stStartPoint.iCurY;
//步数清零
stUserData.iStepCount = 0;
//清空访问标记,标记起点为已访问
for (auto& row : stUserData.vecVisited) {
std::fill(row.begin(), row.end(), false);
}
auto [startSX, startSY] = PosToState(stUserData.stStartPoint.iCurX, stUserData.stStartPoint.iCurY, stUserData.iMoveStep);
if (startSX >= 0 && startSX < stUserData.iStateWidth && startSY >= 0 && startSY < stUserData.iStateHeight) {
stUserData.vecVisited[startSY][startSX] = true;
}
//重置当前路径,加入起点中心点
stUserData.vecCurrentPath.clear();
stUserData.vecCurrentPath.emplace_back(
stUserData.stStartPoint.iCurX + stUserData.stStartPoint.iLen / 2,
stUserData.stStartPoint.iCurY + stUserData.stStartPoint.iLen / 2
);
});
qlearning.SetNextStepCallBack([](Qlearning* qlearning, Qlearning::StStepResult& stStepResult, void* pUserData) {
//stStepResult的每一项都需要在这个回调方法中给他设置好值,用于返回给模型使用,迭代数据
StUserData& stUserData = *((StUserData*)pUserData);
//获取当前离散状态
auto [iCurSX, iCurSY] = PosToState(stUserData.stPawn.iCurX, stUserData.stPawn.iCurY, stUserData.iMoveStep);
stStepResult.iCurSX = iCurSX;
stStepResult.iCurSY = iCurSY;
if (iCurSX < 0 || iCurSX >= stUserData.iStateWidth || iCurSY < 0 || iCurSY >= stUserData.iStateHeight) {
return false;
}
//选择动作
stStepResult.iAction = qlearning->ChooseAction(iCurSX, iCurSY);
//计算动作执行后的新位置
int newX = stUserData.stPawn.iCurX;
int newY = stUserData.stPawn.iCurY;
switch (stStepResult.iAction) {
case UP: newY -= stUserData.iMoveStep; break;
case DOWN: newY += stUserData.iMoveStep; break;
case LEFT: newX -= stUserData.iMoveStep; break;
case RIGHT: newX += stUserData.iMoveStep; break;
}
//检测撞墙/出界
StPawn tempPawn = stUserData.stPawn;
tempPawn.iCurX = newX;
tempPawn.iCurY = newY;
bool hitWall = IsHitGrid(stUserData.matMap, tempPawn);
//检测是否到达终点(没有越过墙壁去摸到终点,且确实和终点有重叠)
stStepResult.isPass = !hitWall && IsHitPawn(tempPawn, stUserData.stTargetPoint);
//计算奖励
stStepResult.dReward = 0.0;
if (stStepResult.isPass) {
stStepResult.dReward = 10000.0; //到达终点奖励
}
else if (hitWall) {
stStepResult.dReward = -100.0; //撞墙惩罚
}
else {
auto [newSX, newSY] = PosToState(newX, newY, stUserData.iMoveStep);
stStepResult.dReward = stUserData.vecVisited[newSY][newSX] ? -20.0 : -1.0; //走老路/普通移动惩罚
}
//计算下一状态的最大Q值
stStepResult.dNextMaxQ = 0.0;
if (!stStepResult.isPass) { //到达终点为终止状态,无后续状态,maxQ为0
if (hitWall) {
stStepResult.dNextMaxQ = qlearning->GetMaxQ(iCurSX, iCurSY); //撞墙不移动,下一状态即当前状态
}
else {
auto [newSX, newSY] = PosToState(newX, newY, stUserData.iMoveStep);
stStepResult.dNextMaxQ = qlearning->GetMaxQ(newSX, newSY);
}
}
//更新位置与访问记录
if (!hitWall) {
stUserData.stPawn.iCurX = newX;
stUserData.stPawn.iCurY = newY;
auto [newSX, newSY] = PosToState(newX, newY, stUserData.iMoveStep);
stUserData.vecVisited[newSY][newSX] = true;
//记录路径点(智能体中心坐标)
stUserData.vecCurrentPath.emplace_back(newX + stUserData.stPawn.iLen / 2, newY + stUserData.stPawn.iLen / 2);
}
stUserData.iStepCount++;
stStepResult.isStepOver = stUserData.iStepCount >= stUserData.iStepCountMax;
//本局结束判定
if (stStepResult.isPass || stStepResult.isStepOver) {
if (stStepResult.isPass) {
std::cout << "[第" << qlearning->GetEpisodeCount() << "局] 成功到达终点 | 步数: " << stUserData.iStepCount << std::endl;
}
else {
std::cout << "[第" << qlearning->GetEpisodeCount() << "局] 步数耗尽,未到达终点" << std::endl;
}
}
return true;
});
qlearning.SetEpisodeFinishCallBack([](Qlearning* qlearning, bool isPass, void* pUserData) {
StUserData& stUserData = *((StUserData*)pUserData);
//所有历史路径透明度衰减
for (auto& hist : stUserData.deqHistoryPath) {
hist.alpha -= 1.0 / MAX_HISTORY;
}
//移除完全透明的路径
while (!stUserData.deqHistoryPath.empty() && stUserData.deqHistoryPath.front().alpha <= 0) {
stUserData.deqHistoryPath.pop_front();
}
//仅成功到达终点的局保留路径记录
if (isPass) {
stUserData.deqHistoryPath.push_back({ stUserData.vecCurrentPath, 1.0 });
}
});
qlearning.Init([](void* pUserData) {
StUserData& stUserData = *((StUserData*)pUserData);
//计算离散状态空间尺寸
stUserData.iStateWidth = stUserData.matMap.cols / stUserData.iMoveStep + 1;
stUserData.iStateHeight = stUserData.matMap.rows / stUserData.iMoveStep + 1;
//初始化访问标记数组
stUserData.vecVisited.resize(stUserData.iStateHeight, std::vector<bool>(stUserData.iStateWidth, false));
//计算单局最大步数 = 地图总像素数 / 移动步长
stUserData.iStepCountMax = ((stUserData.matMap.cols / stUserData.iMoveStep) * (stUserData.matMap.rows / stUserData.iMoveStep));
std::cout << "单局最大步数:" << stUserData.iStepCountMax;
return Qlearning::StQTable{ stUserData.iStateWidth, stUserData.iStateHeight,ACTION_COUNT };
}, &stUserData);
while (qlearning.NextStep()) {
Render(qlearning, stUserData);
}
Render(qlearning, stUserData);
std::cout << "已经结束,任意键退出" << std::endl;
system("pause");
cv::destroyAllWindows();
return 0;
}可以看出,我们主要围绕以下这个自定义的结构体在SetNextStepCallBack中的回调里进行数据迭代,通过设置StStepResult的成员值进行采样反馈,供模型进行进一步强化学习。
cpp
struct StUserData {
cv::Mat matMap; //迷宫原图
StPawn stPawn; //当前智能体状态
StPawn stStartPoint; //起点
StPawn stTargetPoint; //终点
int iMoveStep; //单步移动像素步长
int iStepCount; //当前局已走步数
std::vector<std::vector<bool>> vecVisited; //本局访问标记
int iStateWidth; //离散状态空间宽度
int iStateHeight; //离散状态空间高度
int iStepCountMax; //单局步数上限
std::vector<cv::Point> vecCurrentPath; //当前局路径点
std::deque<StHistoryPath> deqHistoryPath; //历史成功路径队列
};对于QLearning强化学习,他的模型和强化学习过程分成两部分。
这有助于我们了解模型本身就是Q表,模型更新就是Q表更新。
强化学习过程,就是通过贝尔曼方程对Q表每一项的值进行更新。
这个更新,由下一步回调SetNextStepCallBack给出方程需要的值,其为StStepResult的前五项成员(状态xy,动作,奖励,未来Q值),通过方程计算,使得Q表状态空间的Q值更新,用于优化下一次同样状态下的动作选择。
整个项目,QLearning模块之外的都是自定义环境,根据不同的用途和强化学习目标,更改成不同的逻辑和参数结构。
这具体落实到代码中则是对StUserData结构体和模型的三个回调执行内容的改动。
以下是使用的素材和参数,请注意可能的csdn水印影响。

上面迷宫的运行参数:25 5 2 2 2372 2372
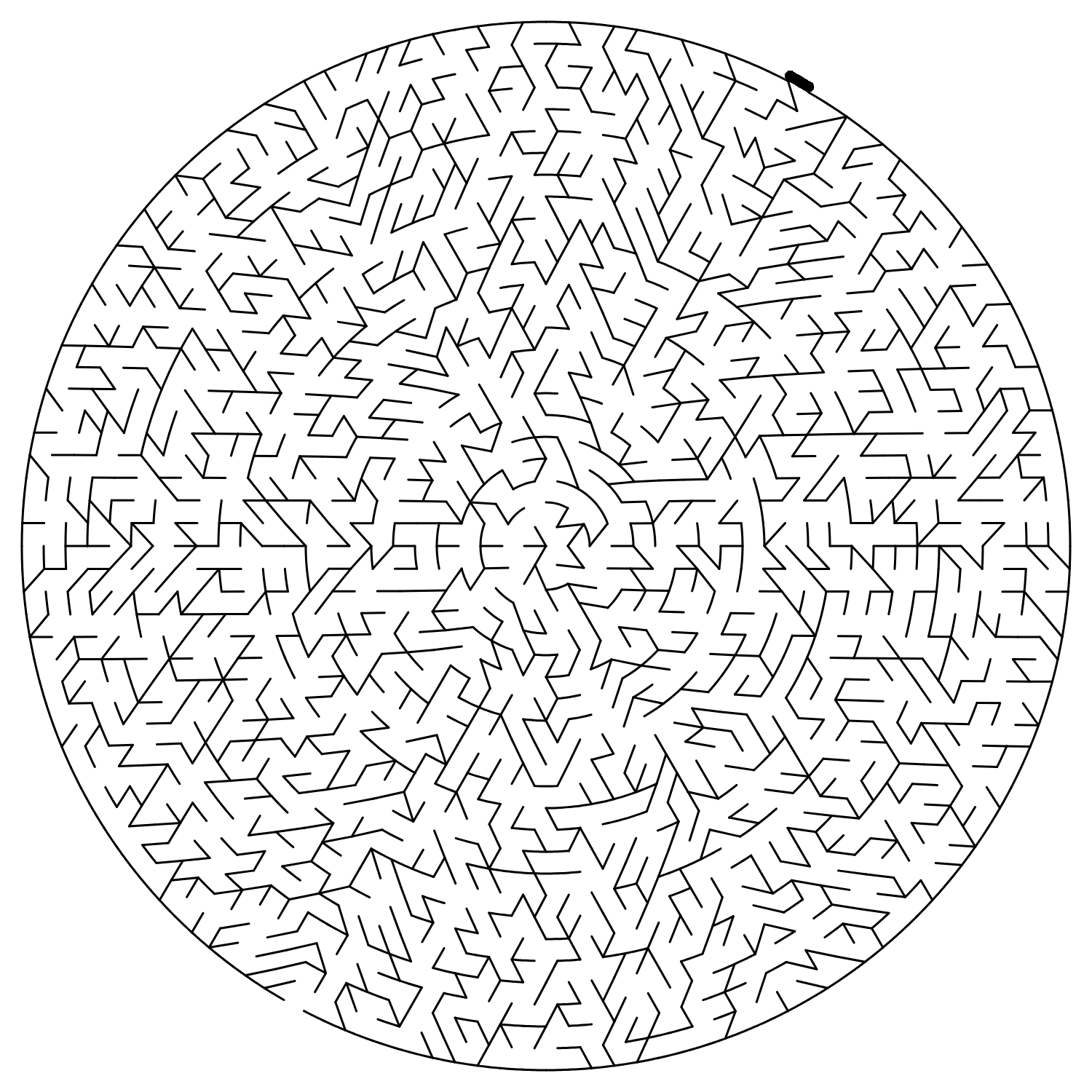
上面迷宫的运行参数:8 2 1100 135 395 1380