具体配置步骤
1. 确保 Ollama 服务正常运行
-
先在本地启动 Ollama 服务:
bashollama serve -
确保已经下载了需要的模型,例如:
bashollama pull qwen3.6:lastest
2. 在 SOLO 中填写配置
直接在「添加模型」表单里填:
| 配置项 | 填写内容 | 说明 |
|---|---|---|
| API 格式 | OpenAI Chat Completions 格式 |
保持默认即可 |
| 自定义请求地址 | http://localhost:11434/v1 |
不要加 /chat/completions,SOLO 会自动补全 |
| 模型 ID | Ollama 模型名,如 qwen3.6:lastest |
必须和 ollama list 里的名称完全一致 |
| API 密钥 | 任意字符串,比如 ollama |
Ollama 默认不需要密钥,填任意值即可 |
| 模型展示名称 | 自定义名称,如 qwen3.6:lastest |
可选,方便识别 |
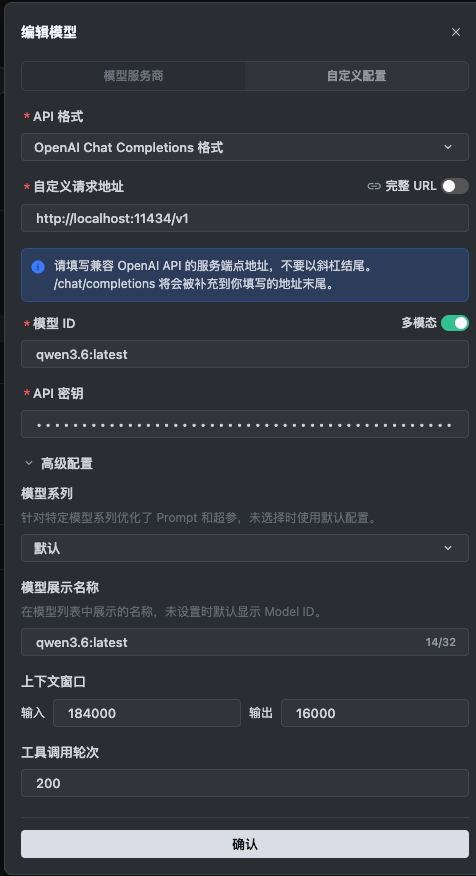
3. 保存并测试
点击「确定」保存,之后就可以在 SOLO 里选择这个本地 Ollama 模型使用了。
常见问题与优化建议
- 连接不上?
- 确认 Ollama 服务在
11434端口运行,且没有被防火墙拦截。 - 如果是跨设备访问,把
localhost换成运行 Ollama 的设备的局域网 IP,并设置OLLAMA_HOST=0.0.0.0让 Ollama 监听所有地址。
- 确认 Ollama 服务在
- 模型列表不显示?
- 直接手动输入模型 ID 即可,不需要依赖自动获取列表。
- 性能优化
- 优先选择 7B/14B 等轻量模型,更适合本地运行。
- 可以通过 Ollama 的参数(如
ollama run qwen3.6:lastest --num_ctx 4096)调整上下文窗口大小。