这里写目录标题
- 前言
- 一、阶段学习目标
- 二、项目完整目录(沿用第五阶段工程结构)
- 三、前置安装依赖
- 四、分步完整代码实现
-
- [4.1 环境配置 .env](#4.1 环境配置 .env)
- [4.2 config/settings.py](#4.2 config/settings.py)
- [4.3 database/session.py 引擎与依赖](#4.3 database/session.py 引擎与依赖)
- [4.4 common/response.py 全局统一返回模板(泛型)](#4.4 common/response.py 全局统一返回模板(泛型))
- [4.5 common/exception.py 全局异常捕获](#4.5 common/exception.py 全局异常捕获)
- [4.6 models 数据库实体(一对多 用户-地址)](#4.6 models 数据库实体(一对多 用户-地址))
-
- [4.6.1 models/user.py](#4.6.1 models/user.py)
- [4.6.2 models/address.py](#4.6.2 models/address.py)
- [4.7 schemas DTO分层模型](#4.7 schemas DTO分层模型)
-
- [4.7.1 schemas/user_schema.py](#4.7.1 schemas/user_schema.py)
- [4.7.2 schemas/address_schema.py](#4.7.2 schemas/address_schema.py)
- [4.8 crud 通用基类 + 业务CRUD](#4.8 crud 通用基类 + 业务CRUD)
-
- [4.8.1 crud/base.py](#4.8.1 crud/base.py)
- [4.8.2 crud/user_crud.py](#4.8.2 crud/user_crud.py)
- [4.8.3 crud/address_crud.py](#4.8.3 crud/address_crud.py)
- [4.9 routers 接口路由](#4.9 routers 接口路由)
-
- [4.9.1 routers/user_router.py](#4.9.1 routers/user_router.py)
- [4.9.2 routers/init.py](#4.9.2 routers/init.py)
- [4.10 main.py 项目入口](#4.10 main.py 项目入口)
- 五、项目运行与Alembic迁移规范
-
- [5.1 启动项目](#5.1 启动项目)
- [5.2 线上迁移流程(禁止create_all)](#5.2 线上迁移流程(禁止create_all))
- 六、实战覆盖全套知识点复盘
前言
本系列前5篇完整覆盖:基础CRUD、高级字段DTO、关联多表、事务高级查询、工程分层与Alembic迁移。
本篇作为系列收官综合实战,整合全部知识点,搭建一套可直接上线的FastAPI用户+地址后台管理项目:
- 复用pydantic-settings环境配置
- 分层models/schemas/crud标准工程结构
- 一对多关联(用户-收货地址)
- 通用BaseCRUD封装
- FastAPI依赖注入、分页接口、统一返回格式
- 全局异常捕获、入参自动校验
- 配套Alembic迁移规范
全程无碎片化代码,完整项目可直接运行,实现前后端标准RESTful接口。
一、阶段学习目标
- 掌握FastAPI + SQLModel完整项目分层落地;
- 熟练使用
Depends数据库会话依赖注入; - 实现单表+一对多关联完整CRUD接口;
- 统一接口返回泛型模板、分页封装;
- 全局异常处理器,标准化错误JSON;
- 入参DTO校验、返回脱敏隐藏敏感密码;
- 项目启动、数据库迁移上线完整流程。
二、项目完整目录(沿用第五阶段工程结构)
fastapi_sqlmodel_demo/
├── .env # 环境配置
├── alembic/ # 数据库迁移
├── alembic.ini
├── config/
│ └── settings.py # pydantic-settings配置
├── database/
│ └── session.py # engine、get_db依赖
├── models/
│ ├── user.py # 用户表(主表)
│ └── address.py # 地址子表(一对多)
├── schemas/
│ ├── user_schema.py # 用户DTO:Create/Update/Public
│ └── address_schema.py
├── crud/
│ ├── base.py # 通用CRUD父类
│ ├── user_crud.py
│ └── address_crud.py
├── routers/
│ ├── __init__.py
│ ├── user_router.py # 用户接口路由
│ └── address_router.py
├── common/
│ ├── response.py # 统一返回泛型模型
│ └── exception.py # 全局异常处理
└── main.py # 项目入口三、前置安装依赖
bash
pip install fastapi uvicorn sqlmodel pydantic-settings python-dotenv pydantic[email-validator] alembic四、分步完整代码实现
4.1 环境配置 .env
env
# .env
APP_ENV=dev
DEBUG=True
DB_URL=sqlite:///./dev.db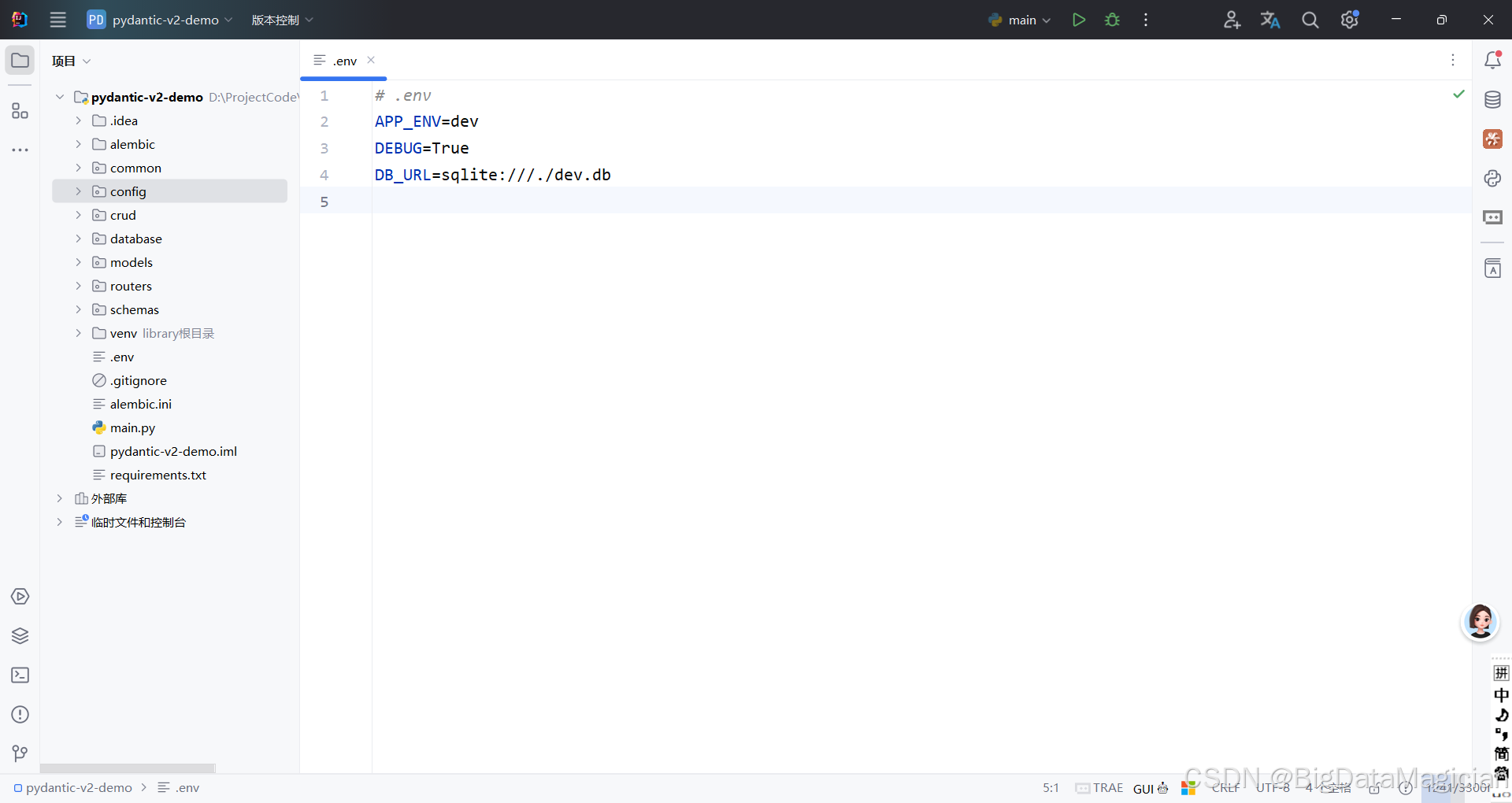
4.2 config/settings.py
python
from pydantic_settings import BaseSettings, SettingsConfigDict
class GlobalSettings(BaseSettings):
model_config = SettingsConfigDict(env_file=".env", env_file_encoding="utf-8", extra="ignore")
app_env: str
debug: bool
db_url: str
settings = GlobalSettings()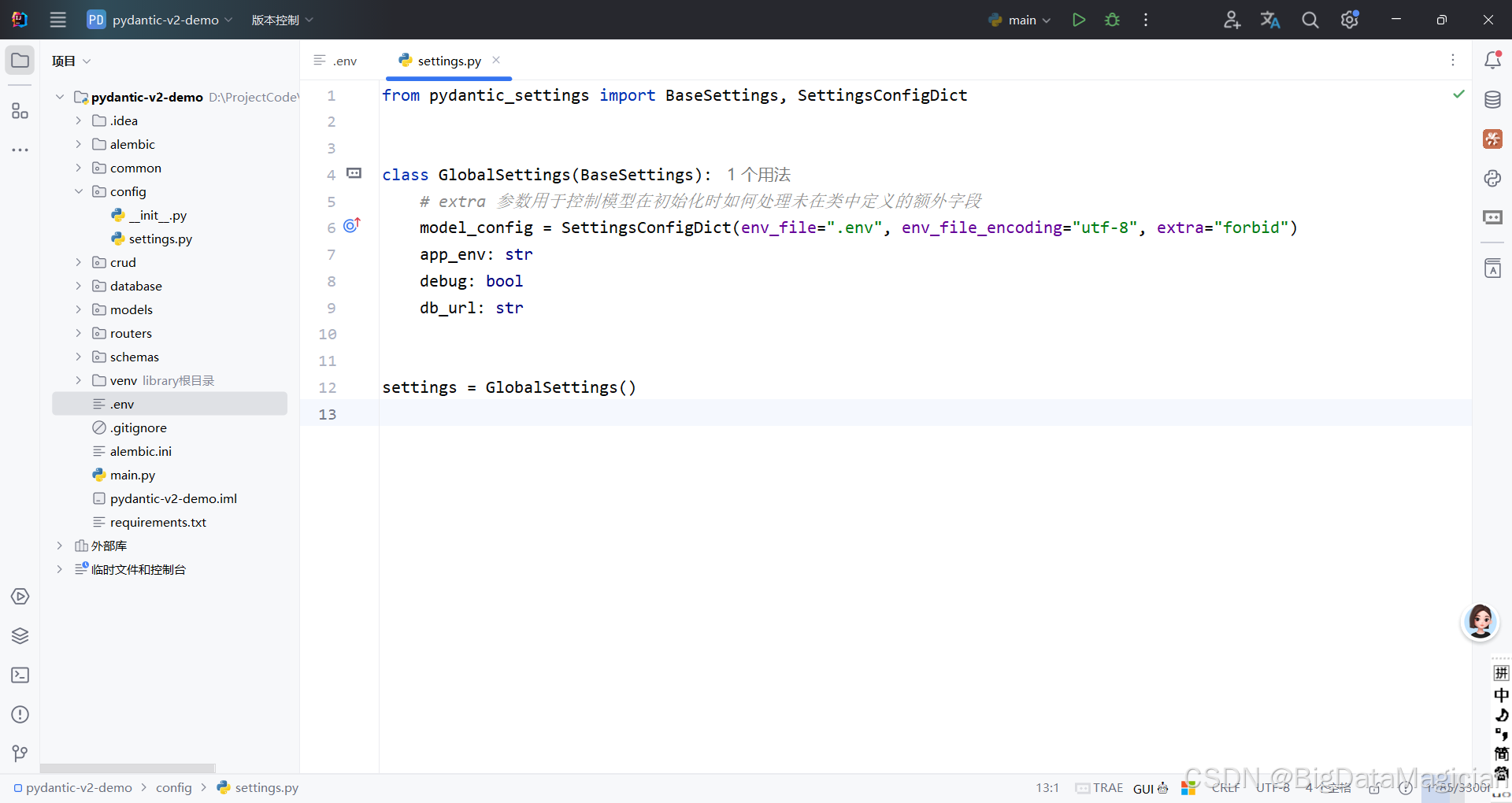
4.3 database/session.py 引擎与依赖
python
from sqlmodel import create_engine, Session
from config.settings import settings
# 1. 创建数据库引擎 (Engine),它是与数据库通信的核心对象,内部维护了一个数据库连接池。
engine = create_engine(
# settings.db_url: 数据库的连接字符串(例如 sqlite:///./app.db 或 mysql+pymysql://...)
settings.db_url,
# echo=settings.debug: 是否开启 SQL 语句的回显。当 debug 为 True 时,SQLAlchemy 会将所有生成的 SQL 语句打印到控制台,非常有利于开发和调试。
echo=settings.debug,
# 这里的 check_same_thread=False 是 SQLite 的专属配置。
# 因为 SQLite 默认限制同一个连接只能在创建它的线程中使用,而 FastAPI 是异步多线程/多协程框架,
# 关闭此限制可以避免在多线程环境下抛出 "SQLite objects created in a thread can only be used in that same thread" 异常。
connect_args={"check_same_thread": False}
)
# 2. 定义 FastAPI 的数据库依赖注入函数
# 使用 yield 关键字是 FastAPI 官方推荐的数据库 Session 管理方式。
def get_db():
# 使用上下文管理器创建 Session 实例
with Session(engine) as session:
# yield 会将当前的 session 对象传递给路由函数使用。路由函数执行完毕后,代码会继续向下执行。
yield session
# (隐式行为):当路由函数执行结束(无论是否发生异常),
# 离开 with 代码块时,session 会自动执行 commit/rollback 并关闭连接,将连接归还给连接池。
# 这种机制完美避免了数据库连接泄露的问题。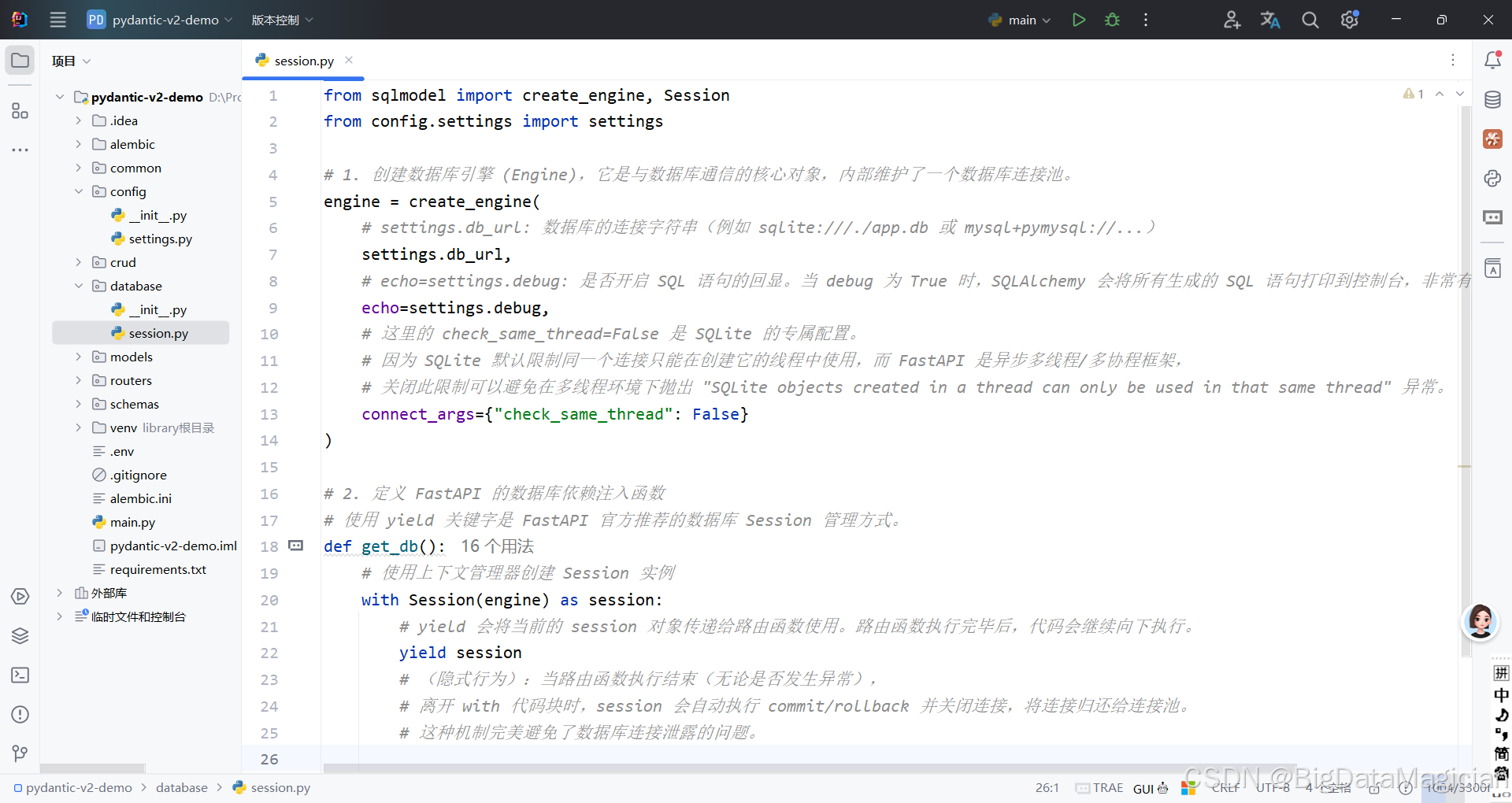
4.4 common/response.py 全局统一返回模板(泛型)
python
from typing import Generic, TypeVar, Optional, List
from sqlmodel import SQLModel
T = TypeVar("T")
# 分页通用结构
class PageData(SQLModel, Generic[T]):
page: int
page_size: int
total: int
items: List[T]
# 全局接口统一返回体
class ApiResp(SQLModel, Generic[T]):
code: int = 200
msg: str = "success"
data: Optional[T] = None
# 失败快捷封装
def fail_resp(msg: str, code: int = 400) -> ApiResp:
return ApiResp(code=code, msg=msg)
# 成功快捷封装
def success_resp(data = None) -> ApiResp:
return Api(data=data)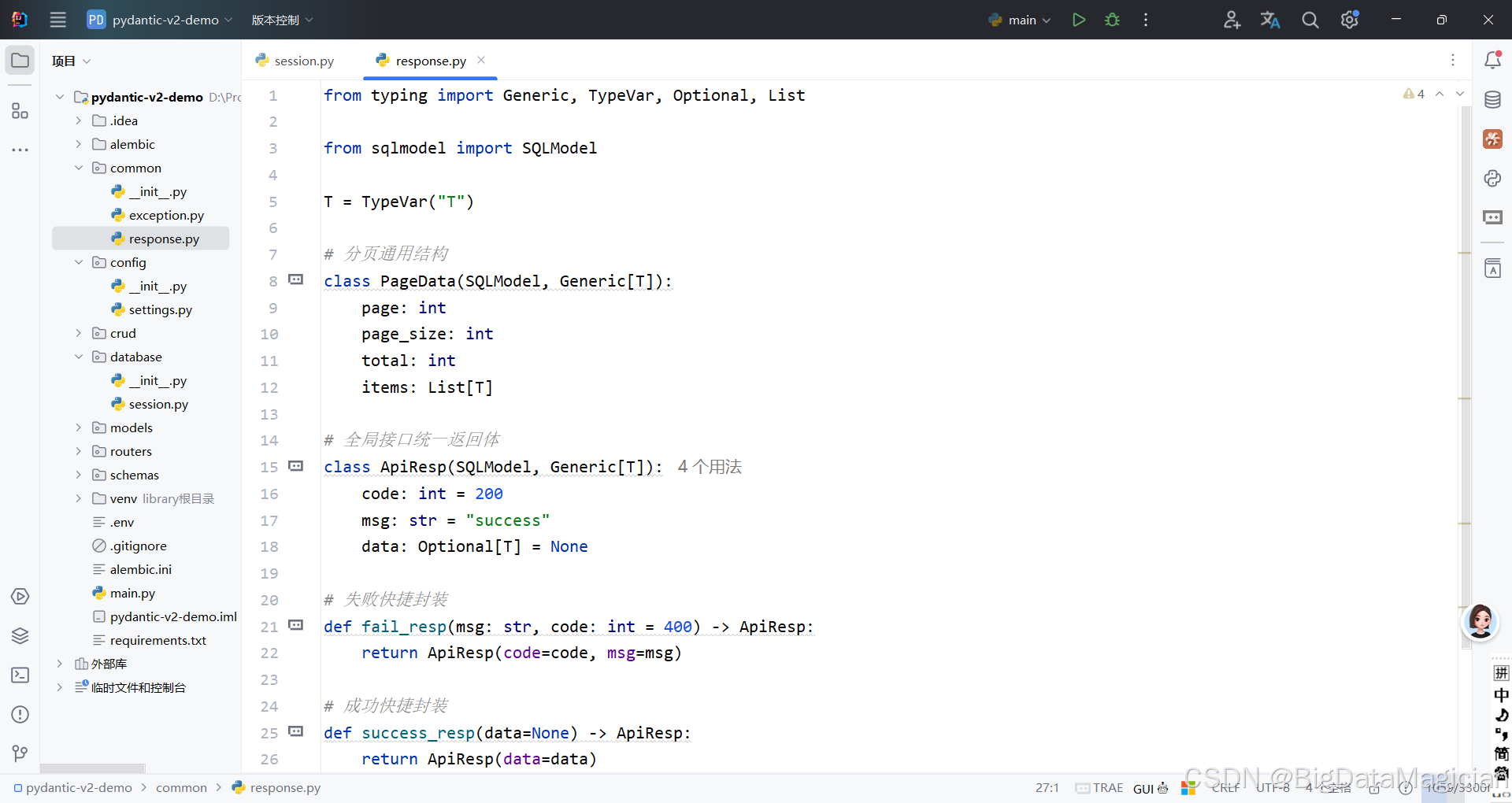
4.5 common/exception.py 全局异常捕获
python
from fastapi import FastAPI, Request, HTTPException
from fastapi.exceptions import RequestValidationError
from fastapi.responses import JSONResponse
from common.response import fail_resp
def register_exception(app: FastAPI):
# 1. 捕获参数校验错误 (RequestValidationError)。当客户端传入的数据不符合 Pydantic 模型定义(如类型错误、缺少必填项等)时,FastAPI 会抛出此异常。
@app.exception_handler(RequestValidationError)
async def validation_err_handler(request: Request, exc: RequestValidationError):
# exc.errors() 返回一个包含所有校验错误详情的列表。这里取第一个错误([0])的 "msg" 字段,提取出最直接的错误提示。
err_msg = exc.errors()[0]["msg"]
# 返回 HTTP 400 状态码,并将错误信息封装到统一的失败响应格式中
return JSONResponse(content=fail_resp(f"参数错误:{err_msg}").model_dump(), status_code=400)
# 2. 捕获业务级 HTTP 异常 (HTTPException)
# 当我们在业务代码中主动抛出 HTTPException 时(例如:用户不存在、密码错误、无权限等),会触发此处理器。
@app.exception_handler(HTTPException)
async def http_err_handler(request: Request, exc: HTTPException):
# 使用异常对象自带的 detail(错误详情)和 status_code(状态码)来构建响应
return JSONResponse(content=fail_resp(exc.detail, exc.status_code).model_dump(), status_code=exc.status_code)
# 3. 兜底系统异常 (Exception)
# 这是全局的"最后一道防线"。当程序发生未预料的致命错误(如数据库连接断开、代码逻辑报错等)且未被上面两个处理器捕获时,会触发此处理器。
@app.exception_handler(Exception)
async def global_err_handler(request: Request, exc: Exception):
# 为了防止将敏感的报错堆栈信息暴露给前端,这里统一返回通用的"服务器内部错误"提示
return JSONResponse(content=fail_resp("服务器内部错误", 500).model_dump(), status_code=500)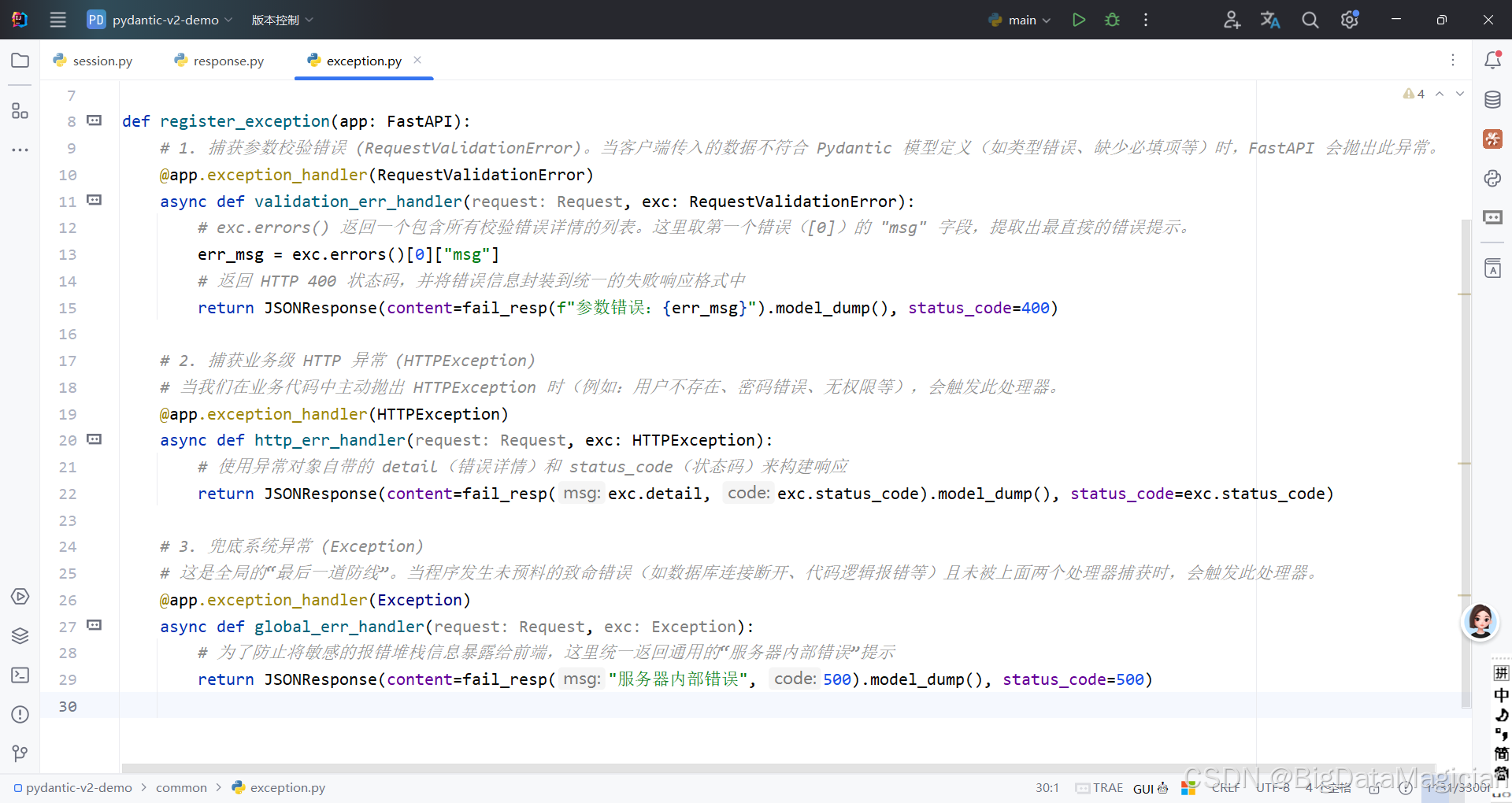
4.6 models 数据库实体(一对多 用户-地址)
4.6.1 models/user.py
python
from sqlmodel import SQLModel, Field, Relationship
from typing import Optional, List
from datetime import datetime
class User(SQLModel, table=True):
# 1. 定义主键字段
# Optional[int]: 表示该字段可以为空(在插入新记录时由数据库自动生成)。
# default=None: 默认值为 None。
# primary_key=True: 将其标记为数据库表的主键。
id: Optional[int] = Field(default=None, primary_key=True)
# 2. 定义用户名及校验规则
# min_length=3, max=16: 限制字符串长度在 3 到 16 之间(Pydantic 校验)。
# unique=True: 在数据库层面保证该字段值唯一。
# index=True: 为该字段创建数据库索引,加快查询速度。
# alias='user_name': 字段别名。在 API 接口接收和返回数据时使用 'user_name',但在数据库和代码内部仍使用 'username'。
username: str = Field(min_length=3, max_length=16, unique=True, index=True, alias='user_name')
# 3. 定义邮箱字段
# index=True: 同样为邮箱创建索引,便于通过邮箱快速查找用户。
email: str = Field(index=True)
# 4. 定义年龄字段及范围校验
# ge=0, le=120: 限制年龄的取值范围(Greater or Equal to 0, Less or Equal to 120)。
age: Optional[int] = Field(default=None, ge=0, le=120)
# 5. 定义密码字段
# exclude=True: 序列化排除。当使用 model_dump() 或 model_dump_json() 将对象转为字典/JSON时,
# 该字段会被自动隐藏,防止密码泄露给前端。
# max_length=100: 限制密码最大长度。
password: str = Field(exclude=True, max_length=100)
# 6. 定义创建时间
# default_factory=datetime.utcnow: 每次创建新记录时,自动将当前 UTC 时间赋值给该字段。
create_time: datetime = Field(default_factory=datetime.utcnow)
# 7. 定义一对多关系 (Relationship)
# List["Address"]: 表示一个用户对应多个地址(注意这里使用了字符串形式的延迟引用)。
# back_populates="user": 建立双向绑定,指向 Address 模型中名为 "user" 的 Relationship 字段。
# cascade_delete=True: 级联删除。当删除该用户时,数据库中关联的所有地址记录也会被自动删除。
addresses: List["Address"] = Relationship(back_populates="user", cascade_delete=True)
# 8. 解决循环引用 (Circular Import)
# 因为 User 和 Address 互相引用对方的类,直接 import 会导致循环依赖报错。
# 解决方案:将 Address 的导入放在文件末尾,并使用延迟字符串引用("Address")。
from models.address import Address
# 9. 重建模型 (Model Rebuild)
# 由于在定义 User 时,Address 类尚未被加载(使用了字符串 "Address"),
# Pydantic 无法在初始化时解析这个关联类型。
# 在导入 Address 之后调用 model_rebuild(),可以强制 Pydantic 重新解析并补全模型的内部结构,
# 确保 Relationship 能够正常工作。
User.model_rebuild()4.6.2 models/address.py
python
from sqlmodel import SQLModel, Field, Relationship
from typing import Optional
class Address(SQLModel, table=True):
# 1. 定义主键字段
# Optional[int]: 允许为空,插入时由数据库自动生成。
# default=None: 默认值为 None。
# primary_key=True: 标记为数据库表的主键。
id: Optional[int] = Field(default=None, primary_key=True)
# 2. 定义地址的基本信息字段
province: str # 省份
city: str # 城市
detail: str # 详细地址(如街道、门牌号等)
# 3. 定义外键字段
# foreign_key="user.id": 声明这是一个外键,指向 user 表的 id 字段,建立数据库层面的关联。
# ondelete="CASCADE": 数据库级别的级联删除策略。
# 当父表(user)中的记录被删除时,数据库会自动删除所有关联的子表(address)记录,保证数据完整性。
user_id: Optional[int] = Field(default=None, foreign_key="user.id", ondelete="CASCADE")
# 4. 定义反向关系(多对一)
# Optional["User"]: 表示多个地址归属于一个用户。使用字符串延迟引用以避免循环导入。
# back_populates="addresses": 建立双向绑定,指向 User 模型中名为 "addresses" 的 Relationship 字段。
user: Optional["User"] = Relationship(back_populates="addresses")
# 5. 解决循环引用 (Circular Import)
# 将 User 模型的导入放在文件末尾,配合类定义中的字符串延迟引用 "User",
# 彻底避免两个模型文件互相 import 导致的循环依赖报错。
from models.user import User
# 6. 重建模型 (Model Rebuild)
# 在导入 User 之后调用此方法,强制 Pydantic 重新解析模型内部结构,
# 确保 Address 模型能够正确识别并映射到 User 模型,使双向关系查询正常工作。
Address.model_rebuild()4.7 schemas DTO分层模型
4.7.1 schemas/user_schema.py
python
from sqlmodel import SQLModel
from pydantic import EmailStr, field_validator
from typing import Optional, List
from schemas.address_schema import AddressPublic
# 基础公共字段
class UserBase(SQLModel):
username: str
email: EmailStr
age: Optional[int] = None
# 创建入参
class UserCreate(UserBase):
password: str
@field_validator("password")
def check_pwd(cls, v):
import re
if len(v) <8 or not re.search(r"[A-Z]",v) or not re.search(r"\d",v):
raise ValueError("密码8位以上,包含大写字母+数字")
return v
# 更新入参(全部可选)
class UserUpdate(SQLModel):
username: Optional[str] = None
email: Optional[EmailStr] = None
age: Optional[int] = None
# 返回脱敏模型(不含密码,嵌套地址)
class UserPublic(UserBase):
id: int
create_time: str
addresses: List[AddressPublic] = []4.7.2 schemas/address_schema.py
python
from sqlmodel import SQLModel
from typing import Optional
class AddressBase(SQLModel):
province: str
city: str
detail: str
class AddressCreate(AddressBase):
user_id: int
class AddressUpdate(SQLModel):
province: Optional[str] = None
city: Optional[str] = None
detail: Optional[str] = None
class AddressPublic(AddressBase):
id: int
user_id: int4.8 crud 通用基类 + 业务CRUD
4.8.1 crud/base.py
python
from typing import Type, TypeVar, Generic, Optional
from sqlmodel import SQLModel, Session, select, func, update
# 1. 定义 ORM 模型类型的泛型变量
# TypeVar("ModelT", bound=SQLModel):
# 创建一个名为 ModelT 的类型变量,并使用 bound=SQLModel 限制其类型边界。
# 这意味着在后续使用 ModelT 的地方,传入的类型必须是 SQLModel 的子类(即数据库表模型,如 User, Address)。
# 作用:让通用的增删改查方法能够准确识别并返回具体的数据库表模型。
ModelT = TypeVar("ModelT", bound=SQLModel)
# 2. 定义创建/更新数据模型类型的泛型变量
# TypeVar("CreateT", bound=SQLModel):
# 创建一个名为 CreateT 的类型变量,同样限制其必须是 SQLModel 的子类。
# 作用:通常用于接收前端传入的数据(例如 CreateUser 模型,它可能只包含 username 和 password,而不包含 id 和 create_time)。
# 将"数据库表模型"和"前端提交的数据模型"分开,可以防止前端恶意传入主键或敏感字段。
CreateT = TypeVar("CreateT", bound=SQLModel)
# 1. 定义泛型 CRUD 基类
# Generic[ModelT, CreateT]: 声明该类接收两个泛型参数。
# ModelT 代表数据库表模型(如 User),CreateT 代表前端传入的创建数据模型(如 CreateUser)。
class BaseCRUD(Generic[ModelT, CreateT]):
# 2. 初始化方法
# model: Type[ModelT]: 接收具体的数据库模型类(注意:这里传入的是类本身,而不是实例)。
# 将其保存在实例变量中,以便后续所有的增删改查操作都能知道当前操作的是哪张表。
def __init__(self, model: Type[ModelT]):
self.model = model
# 3. 根据主键查询单条记录
# db: Session: 接收外部传入的数据库会话(通过 FastAPI 的依赖注入获取)。
# obj_id: int: 主键 ID。
# 返回值 Optional[ModelT]: 如果找到则返回对应的 ORM 对象,找不到则返回 None。
def get(self, db: Session, obj_id: int) -> Optional[ModelT]:
# db.get() 是 SQLAlchemy/SQLModel 提供的快捷方法,专门用于按主键查询
return db.get(self.model, obj_id)
# 4. 分页查询
# 接收当前页码和每页条数,返回标准分页数据结构
def page(self, db: Session, page: int, page_size: int):
# 计算偏移量:(当前页码 - 1) * 每页条数
offset = (page - 1) * page_size
# 构建查询当前页数据的语句,跳过 offset 条记录,最多取 page_size 条
stmt = select(self.model).offset(offset).limit(page_size)
items = db.exec(stmt).all()
# 查询该表的总记录数,用于前端计算总页数
total = db.exec(select(func.count(self.model.id))).one()
# 返回封装好的分页字典
return {"page": page, "page_size": page_size, "total": total, "items": items}
# 5. 新增记录
# obj_in: CreateT: 接收前端传入的创建数据(通常是 Pydantic 模型)
def create(self, db: Session, obj_in: CreateT) -> ModelT:
# model_validate(): 将前端传入的数据模型安全地转换为数据库 ORM 对象
# 这一步会自动过滤掉前端恶意传入的多余字段,保证数据安全
db_obj = self.model.model_validate(obj_in)
# 将新对象加入数据库会话,并提交事务
db.add(db_obj)
db.commit()
# refresh(): 刷新对象状态。因为 id 和 create_time 等字段是由数据库生成的,
# 提交后必须刷新才能从数据库读取这些最新生成的值
db.refresh(db_obj)
return db_obj
# 6. 局部更新
# db_obj: Model: 需要更新的 ORM 对象实例。
# update_dict: dict: 包含需要更新字段的字典(通常由前端传入的 update 模型转换而来)
def update(self, db: Session, db_obj: Model, update_dict: dict):
# 遍历字典中的键值对
for k, v in update_dict.items():
# 安全检查:只有当 ORM 对象确实拥有该属性时,才进行赋值
# 这可以防止前端传入非法字段导致报错
if hasattr(db_obj, k):
# 正确的写法应该是 setattr(db_obj, k, v),即同时传入属性名和属性值
setattr(db_obj, k, v)
# 提交更新并刷新对象,确保返回最新状态
db.commit()
db.refresh(db_obj)
return db_obj
# 7. 删除记录
def delete(self, db: Session, obj_id: int):
# 先根据主键查询该对象是否存在
obj = self.get(db, obj_id)
if obj:
# 如果存在,则从会话中删除该对象并提交事务
db.delete(obj)
db.commit()
# 返回被删除的对象(如果不存在则返回 None)
return obj4.8.2 crud/user_crud.py
python
from crud.base import BaseCRUD
from models.user import User
from schemas.user_schema import UserCreate
from sqlmodel import select, Session
class UserCRUD(BaseCRUD[User, UserCreate]):
# 扩展自定义查询:根据用户名查找
def get_by_username(self, db: Session, username: str):
return db.exec(select(User).where(User.username == username)).first()
user_crud = UserCRUD(User)4.8.3 crud/address_crud.py
python
from crud.base import BaseCRUD
from models.address import Address
from schemas.address_schema import AddressCreate
# 实例化一个专门用于操作 Address 表的 CRUD 对象
address_crud = BaseCRUD[Address, AddressCreate](Address)4.9 routers 接口路由
4.9.1 routers/user_router.py
python
from fastapi import APIRouter, Depends, HTTPException, Query
from sqlalchemy import func
from sqlmodel import Session, select
from common.response import ApiResp, PageData, success_resp
from crud.user_crud import user_crud
from database.session import get_db
from models.user import User
from schemas.user_schema import UserCreate, UserUpdate, UserPublic
# 创建用户管理相关的 API 路由,统一设置路径前缀为 "/users",并在 Swagger 文档中归类为 "用户管理" 标签
router = APIRouter(prefix="/users", tags=["用户管理"])
# 创建用户接口
@router.post("/", response_model=ApiResp[UserPublic])
def create_user(user_in: UserCreate, db: Session = Depends(get_db)):
"""
接收用户创建请求,校验用户名唯一性后创建新用户
:param user_in: 用户创建请求体 (UserCreate 模型)
:param db: 数据库会话,通过依赖注入获取
"""
# 检查用户名是否已存在,防止重复创建
exist = user_crud.get_by_username(db, user_in.username)
if exist:
raise HTTPException(status_code=400, detail="用户名已存在")
# 调用 CRUD 层创建用户并返回成功响应
db_user = user_crud.create(db, user_in)
return success_resp(db_user)
# 用户分页列表接口
@router.get("/", response_model=ApiResp[PageData[UserPublic]])
def list_user(
page: int = Query(1, ge=1), # 当前页码,最小值为 1
page_size: int = Query(10, le=50), # 每页条数,最大值为 50
db: Session = Depends(get_db) # 数据库会话依赖注入
):
"""
获取用户分页列表,使用 selectinload 预加载关联的地址信息,有效解决 ORM 的 N+1 查询问题
"""
from sqlalchemy.orm import selectinload
# 构建查询语句,并预加载用户的 addresses 关联关系
stmt = select(User).options(selectinload(User.addresses))
# 根据页码和每页条数计算数据库偏移量 (offset)
offset = (page - 1) * page_size
# 执行分页查询获取当前页的用户列表
items = db.exec(stmt.offset(offset).limit(page_size)).all()
# 查询用户表总记录数,用于前端分页组件计算总页数
total = db.exec(select(func.count(User.id))).one()
# 封装分页数据对象
page_data = PageData(page=page, page_size=page_size, total=total, items=items)
return success_resp(page_data)
# 根据 ID 查询用户详情接口
@router.get("/{user_id}", response_model=ApiResp[UserPublic])
def get_user(user_id: int, db: Session = Depends(get_db)):
"""
根据用户 ID 获取单个用户详情,同样预加载地址信息
:param user_id: 路径参数,目标用户的 ID
"""
from sqlalchemy.orm import selectinload
# 构建带过滤条件和预加载的查询语句
stmt = select(User).where(User.id == user_id).options(selectinload(User.addresses))
user = db.exec(stmt).first()
# 若未找到对应用户,抛出 404 异常
if not user:
raise HTTPException(404, "用户不存在")
return success_resp(user)
# 更新用户接口
@router.put("/{user_id}", response_model=ApiResp[UserPublic])
def update_user(user_id: int, update_in: UserUpdate, db: Session = Depends(get_db)):
"""
根据用户 ID 更新用户信息,仅更新请求体中传入的字段
:param user_id: 路径参数,目标用户的 ID
:param update_in: 用户更新请求体 (UserUpdate 模型)
"""
# 查询目标用户是否存在
user = user_crud.get(db, user_id)
if not user:
raise HTTPException(404, "用户不存在")
# 将 Pydantic 模型转为字典,exclude_unset=True 表示只包含客户端实际传入的字段,避免将未传字段覆盖为 None
update_dict = update_in.model_dump(exclude_unset=True)
# 执行数据库更新操作
user = user_crud.update(db, user, update_dict)
return success_resp(user)
# 删除用户接口
@router.delete("/{user_id}", response_model=ApiResp)
def del_user(user_id: int, db: Session = Depends(get_db)):
"""
根据用户 ID 删除用户,底层已配置级联删除,会同步删除该用户关联的地址信息
:param user_id: 路径参数,目标用户的 ID
"""
# 执行删除操作,若用户不存在则返回 None
user = user_crud.delete(db, user_id)
if not user:
raise HTTPException(404, "用户不存在")
# 删除成功,返回无数据的成功响应
return success_resp(None)4.9.2 routers/init.py
python
# 创建 API 根路由,统一设置全局路径前缀为 "/api/v1",便于后续进行 API 版本控制
api = APIRouter(prefix="/api/v1")
# 将用户管理模块的路由注册到根路由中
# 注册后,该模块下的接口路径将自动拼接为 "/api/v1/users/..."
api.include_router(user_router)
# 将地址管理模块的路由注册到根路由中
# 注册后,该模块下的接口路径将自动拼接为 "/api/v1/addresses/..."
api.include_router(addr_router)4.10 main.py 项目入口
python
from fastapi import FastAPI
from database.session import engine
from sqlmodel import SQLModel
from routers import api
from common.exception import register_exception
from config.settings import settings
# 自动创建数据库表结构的方法
# 注意:生产环境严禁使用此方法,仅允许在本地开发环境 (dev) 中临时使用,生产环境应通过数据库迁移工具 (如 Alembic) 管理表结构
def create_tables():
if settings.app_env == "dev":
# 绑定数据库引擎,自动创建所有继承自 SQLModel 的表
SQLModel.metadata.create_all(bind=engine)
# 初始化 FastAPI 应用实例,设置项目的标题和版本号(会显示在 Swagger 文档中)
app = FastAPI(title="SQLModel-FastAPI综合实战", version="1.0")
# 注册应用启动事件
# 当应用启动时,会自动执行此函数,完成数据库表的自动创建等初始化工作
@app.on_event("startup")
def startup():
create_tables()
# 注册全局异常处理器,统一拦截和处理应用中抛出的异常,返回标准化的错误响应格式
register_exception(app)
# 将配置了 "/api/v1" 前缀的根路由挂载到 FastAPI 应用中,使所有子路由生效
app.include_router(api)
# 定义根路由 (健康检查接口),通常用于负载均衡器或容器探针检测服务是否存活
@app.get("/")
def index():
return {"msg": "项目启动成功,文档地址 /docs"}
# 脚本直接运行入口,方便在本地开发时快速启动服务
if __name__ == "__main__":
import uvicorn
# 使用 Uvicorn (ASGI 服务器) 启动应用
# reload=True: 开启热重载,修改代码后自动重启服务,仅限开发环境使用
# host: 监听本地回环地址
# port: 监听 8000 端口
uvicorn.run("main:app", reload=True, host="127.0.0.1", port=8000)五、项目运行与Alembic迁移规范
5.1 启动项目
bash
uvicorn main:app --reload访问接口文档:http://127.0.0.1:8000/docs
5.2 线上迁移流程(禁止create_all)
- 初始化alembic(第五阶段教程配置env.py绑定SQLModel.metadata)
bash
alembic init alembic- 生成迁移脚本
bash
alembic revision --autogenerate -m "init user address table"- 执行升级
bash
alembic upgrade head- 表结构修改后重复生成脚本+升级;出错使用
alembic downgrade -1回滚
六、实战覆盖全套知识点复盘
- Pydantic复用:DTO分层、@field_validator密码校验、EmailStr、序列化exclude隐藏密码
- SQLModel基础:BaseModel、Field约束、model_validate转换实体
- 一对多关联:ForeignKey外键、Relationship双向、cascade_delete级联删除
- N+1优化:selectinload预加载关联地址
- 工程封装:pydantic-settings、通用BaseCRUD、分层目录
- 事务:Session自动事务,commit/rollback由FastAPI依赖自动管理
- 高级查询:分页count统计、offset/limit分页
- FastAPI联动:Depends会话注入、全局异常、泛型统一返回、RESTful接口