
生产环境升级 Kubernetes,最容易出问题的地方通常不是"二进制能不能替换成功",而是升级后 kubelet 能不能继续通过 CRI 正常调用 containerd。
很多事故的现场都很像:节点重启后看起来还在,containerd 服务也显示 running,但 Pod 卡在 ContainerCreating,节点变成 NotReady,或者业务镜像突然拉不下来。这个时候再回头查 CRI endpoint、cgroup driver、pause 镜像、Harbor 证书,已经是在业务窗口里抢时间。
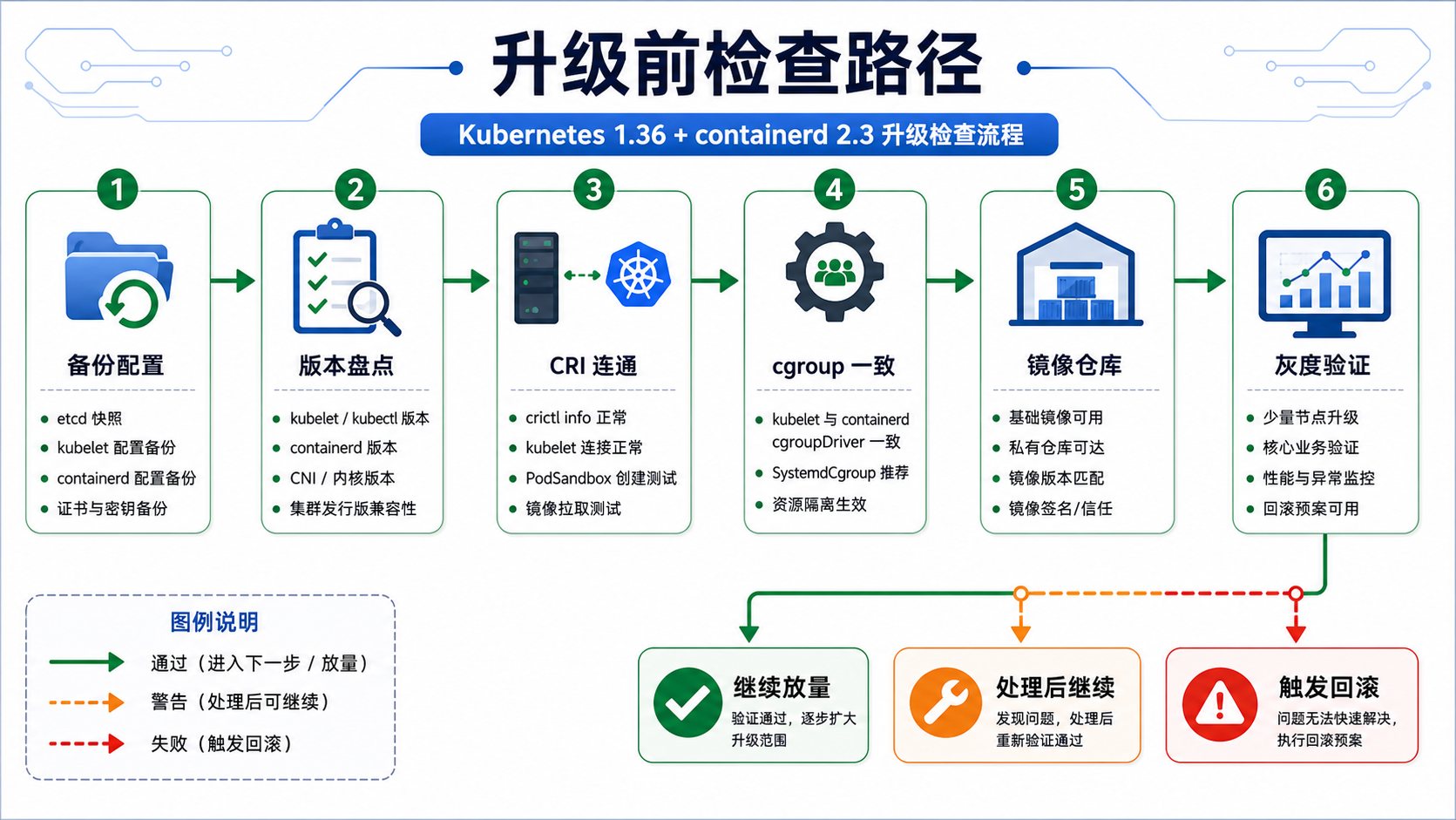
这篇按生产升级检查手册来写,不写新闻解读。目标是回答一个很具体的问题:升级 Kubernetes 1.36 + containerd 2.3 前,节点上到底要检查哪些文件、命令、字段和回滚条件?
版本边界:本文按 2026-07-01 写作时核对的官方信息讨论:Kubernetes 1.36 当前维护分支的最新补丁版本为 1.36.2,containerd 2.3 当前已有 2.3.2 补丁版本。生产操作前仍要以官方 release notes、版本偏差策略和发行版包源为准,不要只按文章里的版本号直接全量升级。
1. 升级风险从哪里来
Kubernetes 节点上的运行时链路可以简化成:
API Server -> kubelet -> CRI endpoint -> containerd -> runc -> Pod
升级 Kubernetes 或 containerd 时,真正要保护的是这条链路连续不断。
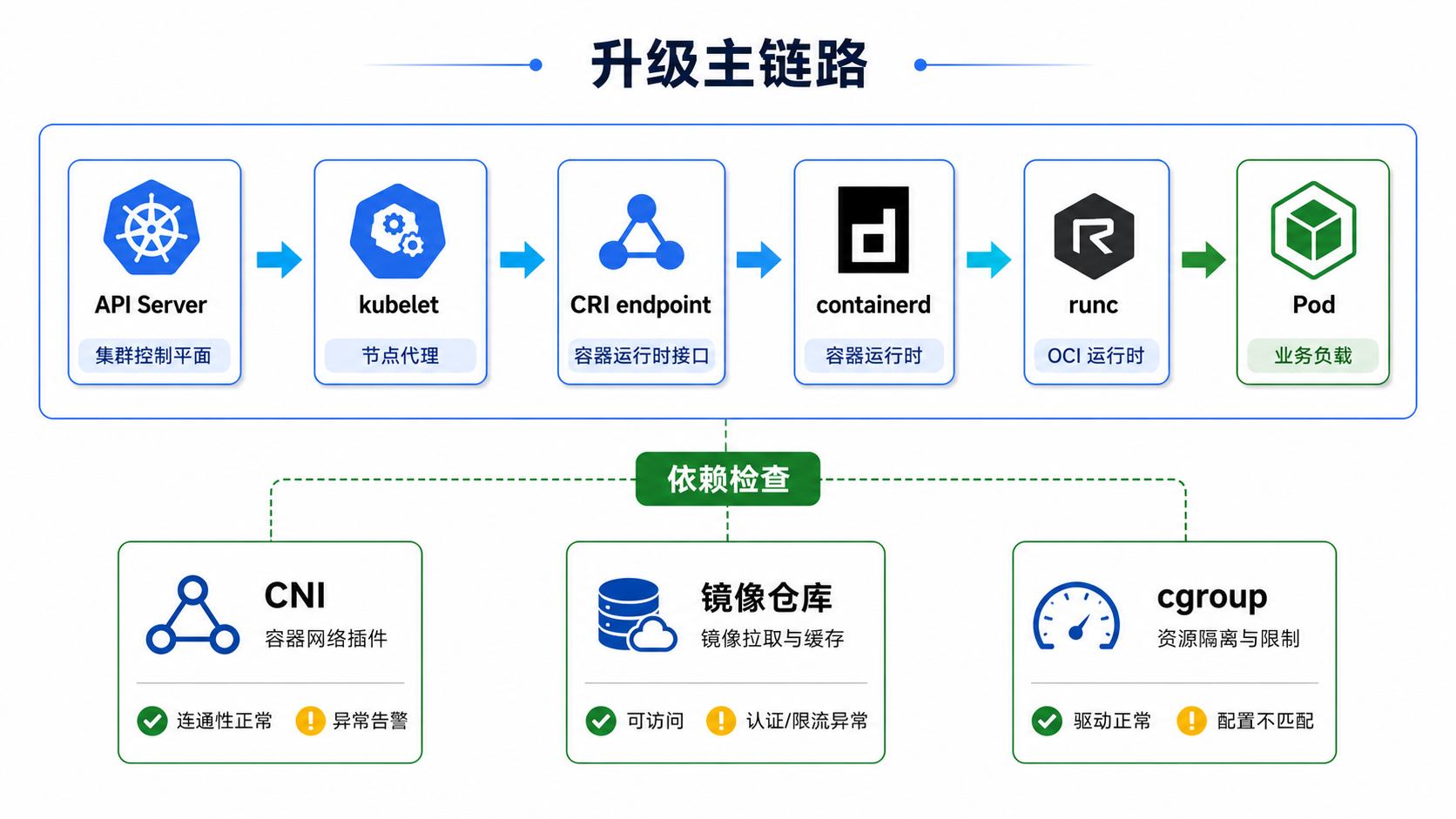
常见风险主要来自 5 类:
| 风险点 | 典型现象 | 先看哪里 |
|---|---|---|
| kubelet 与运行时断连 | 节点 NotReady,Pod 无法创建 |
crictl info、kubelet 日志 |
| CRI endpoint 配错 | crictl 报连接失败 |
/etc/crictl.yaml、kubelet 启动参数 |
| cgroup driver 不一致 | Pod 启动异常,资源统计异常 | /var/lib/kubelet/config.yaml、containerd config dump |
| pause 镜像或私有仓库不可达 | Pod 卡在 ContainerCreating 或 ImagePullBackOff |
sandbox_image、certs.d、Pod Events |
| 升级没有灰度和回滚 | 问题从单节点扩散到整组节点 | Drain、验证、回滚窗口 |
升级前先做一个判断:如果你现在不能解释节点上 kubelet 连到哪个 containerd socket,也不能说清 SystemdCgroup 和 sandbox_image 在哪里,那就先不要动生产批量升级。
2. 版本兼容关系:不要只看 Kubernetes 和 containerd 两个数字
生产升级至少要记录 5 个维度:Kubernetes 控制面、kubelet、containerd、CNI、操作系统内核。只看 kubeadm upgrade plan 不够,它不会替你判断私有仓库证书、节点 cgroup、containerd 配置是否都适合这次升级。
先把 Kubernetes 自身的版本偏差规则压实:
| 组件 | Kubernetes 1.36 升级时的关键限制 | 升级前判断 |
|---|---|---|
| kube-apiserver | HA 集群里新旧 apiserver 最多相差 1 个 minor | 控制面不要跨 minor 跳升 |
| kubelet | 不能比 kube-apiserver 新,最多可比 kube-apiserver 旧 3 个 minor | 目标 apiserver 为 1.36 时,kubelet 可为 1.36、1.35、1.34、1.33 |
| kube-proxy | 不能比 kube-apiserver 新,最多可旧 3 个 minor | 和节点 kubelet 版本一起看 |
| kubectl | 支持与 kube-apiserver 前后相差 1 个 minor | 运维机 kubectl 不要长期落后 |
这里的重点不是背规则,而是确定升级顺序:控制面先按规则进入 1.36,再逐批处理 kubelet 和节点运行时。对 kubelet 做 minor 版本升级前,应先 drain 对应节点,不要在承载业务 Pod 的节点上原地硬升。
建议先建一张盘点表:
| 节点 | 角色 | kubelet | containerd | CNI | OS / Kernel | 业务风险 |
|---|---|---|---|---|---|---|
| node-a | worker | 1.35.x | 2.2.x | Calico/Cilium 版本 | Ubuntu/RHEL + kernel | 低流量 |
| node-b | GPU worker | 1.35.x | 2.2.x | Calico/Cilium 版本 | GPU 驱动依赖内核 | 高风险 |
检查 kubelet 版本:
kubelet --version用途:确认节点实际运行的 kubelet 版本。 判断标准:输出版本要和升级计划一致;如果节点版本散乱,先把节点分组,不要混在一个批次升级。
检查 containerd 版本:
containerd --version用途:确认节点运行时版本。 判断标准:确认当前版本、目标版本、发行版包源是否匹配;如果生产节点来自不同 OS 镜像,必须逐类验证。
检查节点汇报的运行时版本:
kubectl get nodes -o wide用途:从控制面视角确认每个节点的 CONTAINER-RUNTIME。 判断标准:目标节点应显示预期运行时,例如 containerd://2.3.x;如果控制面看到的版本和节点本机不一致,先查 kubelet 汇报和服务重启状态。
3. 升级前先备份:配置文件比命令更值钱
升级涉及 /etc/containerd/config.toml、/var/lib/kubelet/config.yaml、systemd drop-in、registry 证书和认证配置时,必须先备份。不要相信"配置很简单,我记得住"。
建议在每台节点上执行:
sudo mkdir -p /root/k8s-runtime-backup/$(date +%F)用途:创建当天备份目录。 判断标准:目录创建成功,后续备份都放到同一个日期目录里。
sudo cp -a /etc/containerd /root/k8s-runtime-backup/$(date +%F)/containerd用途:备份 containerd 主配置、certs.d、registry hosts 配置。 判断标准:备份目录里能看到 config.toml 和证书、hosts 文件;如果目录不存在,记录当前节点是否使用默认配置。
sudo cp -a /var/lib/kubelet/config.yaml /root/k8s-runtime-backup/$(date +%F)/kubelet-config.yaml用途:备份 kubelet 配置。 判断标准:文件存在且可读,重点字段包括 cgroupDriver、clusterDNS、containerLogMaxSize 等。
sudo systemctl cat kubelet > /root/k8s-runtime-backup/$(date +%F)/kubelet-systemd.txt
sudo systemctl cat containerd > /root/k8s-runtime-backup/$(date +%F)/containerd-systemd.txt用途:备份 systemd unit 和 drop-in。 判断标准:能看到 kubelet 的启动参数来源;如果这里有 --container-runtime-endpoint,后面要和 /etc/crictl.yaml 对齐。
4. CRI 插件与 endpoint 检查
升级 containerd 后,kubelet 能不能正常工作,关键是 CRI service 是否可用、endpoint 是否一致。
检查 crictl 配置:
cat /etc/crictl.yaml用途:确认 crictl 连接哪个 runtime endpoint。 判断标准:生产 containerd 节点通常应看到类似:
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false如果 endpoint 指向旧 Docker socket、CRI-O socket 或不存在的路径,crictl info 会误导你。
检查 socket 是否存在:
ls -l /run/containerd/containerd.sock用途:确认 containerd socket 文件存在。 判断标准:文件存在且服务运行;如果不存在,先查 systemctl status containerd,不要继续看 Pod 业务日志。
检查 CRI 连通性:
sudo crictl info用途:验证 CRI service 能否正常响应。 判断标准:能输出 runtime、config、runtimes 等信息;如果报 connection refused、context deadline exceeded、unknown service runtime.v1.RuntimeService,优先查 endpoint、CRI 插件和 containerd 日志。
检查 containerd 配置中的 CRI 插件:
sudo containerd config dump | grep -n "io.containerd" -A 120用途:查看 CRI 插件配置段。 判断标准:CRI 插件不能被禁用;如果 /etc/containerd/config.toml 的 disabled_plugins 里出现 cri,kubelet 无法通过 CRI 管理 Pod。containerd 1.x 常见路径是 plugins."io.containerd.grpc.v1.cri",containerd 2.x 会出现 plugins.'io.containerd.cri.v1.runtime' 等新路径,排查时不要只 grep 旧路径。
5. kubelet、cgroup 与 containerd runtime 配置
cgroup 配置不一致,是升级后很容易变成"节点偶发异常"的坑。新集群通常建议 kubelet 使用 systemd cgroup driver,containerd 的 runc options 里也要对应启用 SystemdCgroup。
检查 kubelet cgroup driver:
grep -n "cgroupDriver" /var/lib/kubelet/config.yaml用途:确认 kubelet 使用哪个 cgroup driver。 判断标准:如果输出 cgroupDriver: systemd,containerd 侧也应使用 systemd cgroup;如果为空,要结合 kubelet 版本和启动参数确认默认行为。
检查 containerd 的 SystemdCgroup:
sudo containerd config dump | grep -n "SystemdCgroup" -A 5 -B 5用途:确认 runc runtime options。 判断标准:生产 Kubernetes 节点常见目标是 SystemdCgroup = true;如果 kubelet 是 systemd,containerd 却是 false,升级前先评估并灰度修正。containerd 2.x 的 runc 配置路径通常在:
[plugins.'io.containerd.cri.v1.runtime'.containerd.runtimes.runc]
runtime_type = "io.containerd.runc.v2"
[plugins.'io.containerd.cri.v1.runtime'.containerd.runtimes.runc.options]
SystemdCgroup = true如果你的配置仍是 1.x 风格路径,先确认发行版是否做了兼容迁移,不要直接复制线上旧配置覆盖新版本默认配置。
检查系统是 cgroup v1 还是 v2:
stat -fc %T /sys/fs/cgroup用途:确认系统 cgroup 文件系统类型。 判断标准:cgroup2fs 表示 cgroup v2;tmpfs 常见于 cgroup v1。OS 升级或内核变更时,这个结果可能影响 kubelet 和运行时行为。
6. 镜像仓库、pause 镜像和 sandbox_image
很多升级事故不是 containerd 起不来,而是升级后新 Pod 的 sandbox 或业务镜像拉不下来。
检查 pause 镜像:
sudo containerd config dump | grep -n "sandbox_image"用途:确认 Pod sandbox 使用的 pause 镜像。 判断标准:镜像地址应在当前网络环境可拉取;国内环境、离线环境、私有仓库环境尤其要提前验证。旧配置里常见 plugins."io.containerd.grpc.v1.cri".sandbox_image,升级到 containerd 2.x 时要结合 containerd config dump 的实际输出确认字段是否仍然生效。
验证 sandbox 镜像能拉取:
sudo crictl pull <pause-image>用途:从 CRI 视角验证镜像拉取。 判断标准:能成功 pull;如果失败,看错误是 x509、401、403、not found 还是 timeout,不要只写"网络问题"。
检查 registry 配置目录:
sudo find /etc/containerd/certs.d -maxdepth 3 -type f -name "hosts.toml" -print用途:确认 containerd 是否使用 certs.d/<registry>/hosts.toml 管理 mirror、TLS、认证入口。 判断标准:私有仓库域名应有对应目录;如果 Harbor 使用自签证书,还要确认 CA 文件路径和域名 SAN。
7. 关键命令速查

正文仍保留准确命令,避免图片压缩影响阅读:
| 检查目标 | 命令 | 看什么 | 异常时下一步 |
|---|---|---|---|
| kubelet 版本 | kubelet --version |
是否符合升级批次 | 先分组,不要混升 |
| containerd 版本 | containerd --version |
当前和目标版本 | 核对包源和回滚包 |
| 节点运行时 | kubectl get nodes -o wide |
CONTAINER-RUNTIME |
查 kubelet 汇报状态 |
| CRI 连通 | crictl info |
是否能输出 runtime 信息 | 查 endpoint 和 containerd 日志 |
| crictl endpoint | cat /etc/crictl.yaml |
runtime-endpoint |
改成正确 socket 后重测 |
| containerd 配置 | containerd config dump |
CRI、sandbox、runtime、registry | 先备份再调整 |
| kubelet 服务 | systemctl status kubelet |
active、失败原因 | 查 journalctl -u kubelet |
| containerd 服务 | systemctl status containerd |
active、启动错误 | 查 journalctl -u containerd |
| kubelet 日志 | journalctl -u kubelet -n 200 --no-pager |
runtime、PLEG、cgroup、image 关键词 | 顺着关键词下钻 |
| containerd 日志 | journalctl -u containerd -n 200 --no-pager |
CRI、registry、snapshot、sandbox 错误 | 对应查配置和镜像仓库 |
8. 灰度升级流程和回滚条件
不要直接滚全量节点。推荐顺序:
-
选 1 台非核心 worker 节点;
-
cordon防止新 Pod 调度; -
drain迁移可迁移工作负载; -
备份配置;
-
升级 kubelet/containerd;
-
重启服务;
-
验证 CRI、Pod sandbox、业务镜像、DaemonSet;
-
放开少量业务;
-
观察 30-60 分钟后再进入下一批。
节点灰度命令:
kubectl cordon <node-name>用途:暂停新 Pod 调度到该节点。 判断标准:kubectl get nodes 中节点出现 SchedulingDisabled。
kubectl drain <node-name> --ignore-daemonsets --delete-emptydir-data用途:迁移普通 Pod,为节点升级腾出窗口。 判断标准:业务 Pod 能在其他节点恢复;如果有 PDB 阻塞,不要强拆核心业务,先调整升级批次。
升级后验证:
sudo systemctl restart containerd kubelet
sudo crictl info
kubectl describe node <node-name>
kubectl get pods -A -o wide --field-selector spec.nodeName=<node-name>用途:确认服务、CRI、节点状态和 Pod 状态连续恢复。 判断标准:crictl info 正常、节点 Ready、核心 DaemonSet 正常、新建测试 Pod 能拉镜像并进入 Running。
回滚条件建议写死,不要临场争论:
| 条件 | 处理 |
|---|---|
| containerd 启动失败 | 还原 /etc/containerd 备份,回滚包版本,重启服务 |
crictl info 无法连接 |
回滚 endpoint/config,检查 CRI 插件和 socket |
| 节点持续 NotReady | 暂停批次,查 kubelet 日志和 Node Conditions |
| DaemonSet 无法恢复 | 暂停放量,确认 CNI、日志采集、监控 agent |
| 核心业务 Pod 无法 Running | 立即停止升级,按业务回滚预案处理 |
解除调度:
kubectl uncordon <node-name>用途:验证通过后允许新 Pod 调度。 判断标准:节点不再显示 SchedulingDisabled,新 Pod 可以正常落到该节点。
9. 常见故障与判断路径
故障一:升级后节点 NotReady
先看 Node Conditions:
kubectl describe node <node-name>关注 Ready、MemoryPressure、DiskPressure、PIDPressure、NetworkUnavailable。如果 Ready 是 False 或 Unknown,继续看 kubelet 日志:
journalctl -u kubelet -n 200 --no-pager重点搜:container runtime、PLEG、cgroup、failed to run Kubelet、node not found。
故障二:Pod 卡在 ContainerCreating
先看 Pod Events:
kubectl describe pod <pod-name> -n <namespace>如果看到 FailedCreatePodSandBox,优先查 pause 镜像、CNI、CRI。继续执行:
sudo crictl pods
sudo crictl ps -a
sudo journalctl -u containerd -n 200 --no-pager判断标准:如果 sandbox 没创建出来,问题还没到业务容器;不要先查应用日志。
故障三:镜像拉取失败
先区分错误类型:
| 错误关键词 | 常见原因 | 下一步 |
|---|---|---|
x509 |
CA、证书链、域名 SAN | 查 /etc/containerd/certs.d/<registry>/hosts.toml 和 CA 文件 |
401 |
未认证 | 查 imagePullSecret 或节点侧认证 |
403 |
认证成功但无权限 | 查 Harbor project 权限 |
not found |
镜像名、tag、项目路径错误 | 核对镜像完整地址 |
timeout |
网络、DNS、mirror 不通 | 查 DNS、代理、mirror endpoint |
10. 一页式 checklist
| 阶段 | 检查项 | 通过标准 |
|---|---|---|
| 版本 | kubelet/containerd/CNI/OS 已盘点 | 每类节点有清单和升级批次 |
| 备份 | containerd、kubelet、systemd drop-in 已备份 | 可以从备份恢复原配置 |
| CRI | crictl info 正常 |
endpoint 指向 containerd socket |
| cgroup | kubelet 与 containerd 配置一致 | cgroupDriver 与 SystemdCgroup 不冲突 |
| 镜像 | pause 镜像和业务仓库可拉取 | crictl pull 验证通过 |
| 服务 | kubelet/containerd 重启后正常 | systemd active,无关键错误 |
| 灰度 | 先非核心节点 | Drain、验证、观察完成 |
| 回滚 | 包版本、配置、业务窗口明确 | 达到条件立即停止放量 |
11. 总结
Kubernetes + containerd 的生产升级,核心不是"把版本升上去",而是升级前把节点运行时链路查清楚:
kubelet -> CRI endpoint -> containerd -> runtime -> Pod sandbox -> 镜像仓库
只要这条链路里有一个点没确认,升级就可能从计划内维护变成现场排障。我的建议是:先做版本盘点和配置备份,再检查 CRI、cgroup、镜像仓库,最后只从低风险节点灰度开始。
下一篇会继续落到工具层:crictl 实战指南:没有 docker 命令后,Kubernetes 节点该怎么排障?
参考资料
-
Kubernetes Releases: Releases | Kubernetes
-
Kubernetes Version Skew Policy: Version Skew Policy | Kubernetes
-
Kubernetes Container Runtimes: Container Runtimes | Kubernetes
-
containerd GitHub Releases: Releases · containerd/containerd · GitHub
-
containerd CRI 配置文档: containerd/docs/cri/config.md at main · containerd/containerd · GitHub