文章目录
-
- 每日一句正能量
- 一、引言
- 二、LWIP协议栈分层架构与裁剪策略
-
- [2.1 完整协议栈 vs 工业裁剪](#2.1 完整协议栈 vs 工业裁剪)
- [2.2 核心裁剪配置](#2.2 核心裁剪配置)
- 三、内存池(MEMP)与PBUF管理机制
-
- [3.1 MEMP内存池机制](#3.1 MEMP内存池机制)
- [3.2 PBUF数据包缓冲区](#3.2 PBUF数据包缓冲区)
- [3.3 PBUF_POOL内存布局优化](#3.3 PBUF_POOL内存布局优化)
- [3.4 内存池初始化与监控](#3.4 内存池初始化与监控)
- 四、零拷贝(Zero-Copy)技术实现
-
- [4.1 传统拷贝 vs 零拷贝](#4.1 传统拷贝 vs 零拷贝)
- [4.2 零拷贝实现技术](#4.2 零拷贝实现技术)
-
- [4.2.1 DMA描述符直接指向PBUF](#4.2.1 DMA描述符直接指向PBUF)
- [4.2.2 RX中断零拷贝处理](#4.2.2 RX中断零拷贝处理)
- [4.2.3 PBUF_ROM/REF零拷贝发送](#4.2.3 PBUF_ROM/REF零拷贝发送)
- [4.3 pbuf_chain链表拼接](#4.3 pbuf_chain链表拼接)
- 五、中断处理架构与数据流优化
-
- [5.1 中断处理流程](#5.1 中断处理流程)
- [5.2 三种处理模式对比](#5.2 三种处理模式对比)
- [5.3 RTOS环境下的中断优化](#5.3 RTOS环境下的中断优化)
- [5.4 中断优先级配置](#5.4 中断优先级配置)
- 六、以太网DMA描述符与PBUF零拷贝映射
-
- [6.1 DMA描述符环结构](#6.1 DMA描述符环结构)
- [6.2 DMA-PBUF映射初始化流程](#6.2 DMA-PBUF映射初始化流程)
- [6.3 缓存一致性处理](#6.3 缓存一致性处理)
- 七、关键性能优化参数配置
-
- [7.1 内存参数优化](#7.1 内存参数优化)
- [7.2 定时器参数优化](#7.2 定时器参数优化)
- [7.3 硬件卸载优化](#7.3 硬件卸载优化)
- 八、嵌入式代码实现架构
-
- [8.1 硬件抽象层](#8.1 硬件抽象层)
- [8.2 协议栈核心层](#8.2 协议栈核心层)
- 九、完整代码实现示例
- 十、性能测试与调优
-
- [10.1 性能测试指标](#10.1 性能测试指标)
- [10.2 常见问题排查](#10.2 常见问题排查)
- 十一、总结与展望

每日一句正能量
筛选比改变更重要。
成年人的关系和时间都很珍贵。试图改变别人往往徒劳且消耗自己,而懂得筛选对的人、对的事,则是一种更高效、更清醒的生活策略。
一、引言
在工业4.0和智能制造的浪潮下,以太网已成为工业现场通信的核心基础设施。从PLC、运动控制器到工业机器人、智能传感器,几乎所有现代工业设备都配备了以太网接口。然而,工业场景对网络通信有着严苛的要求:低延迟、高确定性、强实时性、高可靠性。如何在资源受限的嵌入式MCU上实现高性能的TCP/IP通信,是每一位工业嵌入式开发者必须面对的挑战。
LWIP(Lightweight IP)协议栈由瑞典计算机科学院Adam Dunkels开发,专为嵌入式系统设计,其核心理念是在几十KB的RAM和ROM中实现完整的TCP/IP协议栈。本文将深入LWIP协议栈的内部实现,从协议裁剪、内存池管理、零拷贝技术、中断优化四个维度,提供一套完整的工业级性能优化方案。
二、LWIP协议栈分层架构与裁剪策略
LWIP协议栈采用模块化设计,各层之间通过清晰的接口解耦,使得裁剪和扩展变得异常灵活。
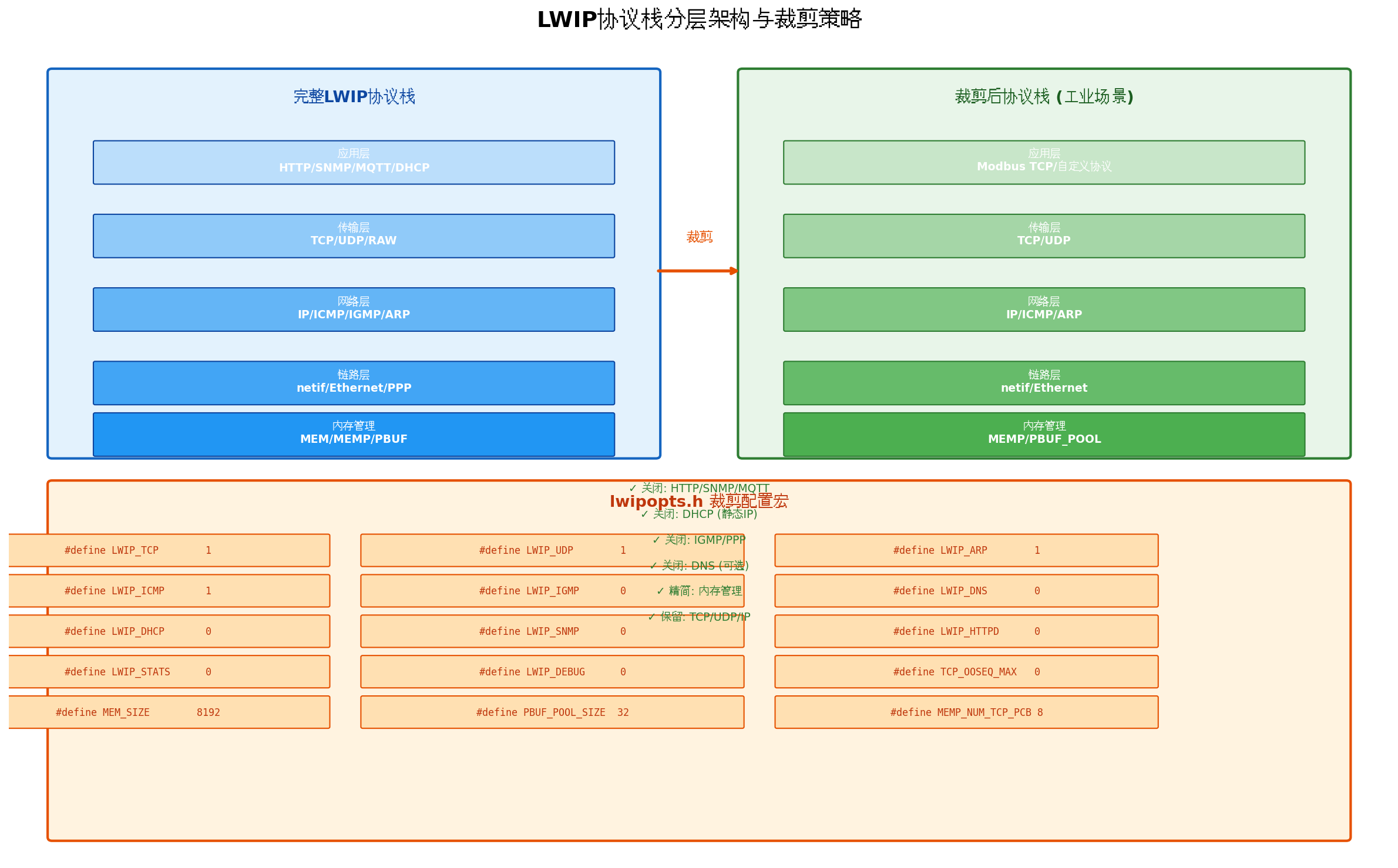
2.1 完整协议栈 vs 工业裁剪
完整的LWIP协议栈包含应用层(HTTP/SNMP/MQTT/DHCP)、传输层(TCP/UDP/RAW)、网络层(IP/ICMP/IGMP/ARP)、链路层(netif/Ethernet/PPP)以及内存管理层。但在典型的工业以太网应用中,许多功能并不需要:
工业场景裁剪策略:
| 功能模块 | 工业需求 | 裁剪建议 |
|---|---|---|
| HTTP服务器 | 通常不需要 | 关闭 LWIP_HTTPD |
| SNMP | 通常不需要 | 关闭 LWIP_SNMP |
| MQTT | 可选 | 若不用则关闭 |
| DHCP | 工业设备多用静态IP | 关闭 LWIP_DHCP |
| DNS | 通常不需要 | 关闭 LWIP_DNS |
| IGMP | 组播需求少 | 关闭 LWIP_IGMP |
| PPP | 串口拨号不适用 | 关闭 PPP_SUPPORT |
2.2 核心裁剪配置
c
/* lwipopts.h - 工业场景裁剪配置 */
#ifndef LWIPOPTS_H
#define LWIPOPTS_H
/* 协议功能裁剪 */
#define LWIP_TCP 1 // 保留TCP
#define LWIP_UDP 1 // 保留UDP
#define LWIP_ARP 1 // 保留ARP
#define LWIP_ICMP 1 // 保留ICMP
#define LWIP_IGMP 0 // 关闭IGMP
#define LWIP_DNS 0 // 关闭DNS
#define LWIP_DHCP 0 // 关闭DHCP
#define LWIP_SNMP 0 // 关闭SNMP
#define LWIP_AUTOIP 0 // 关闭AutoIP
#define LWIP_IGMP 0 // 关闭IGMP
/* 调试与统计裁剪 */
#define LWIP_STATS 0 // 关闭统计(生产环境)
#define LWIP_DEBUG 0 // 关闭调试
#define LWIP_STATS_DISPLAY 0
/* TCP优化 */
#define TCP_OOSEQ_MAX 0 // 禁用乱序缓存(工业场景追求确定性)
#define TCP_OOSEQ_MAX_BYTES 0
#define TCP_OOSEQ_MAX_PBUFS 0
#define LWIP_TCP_KEEPALIVE 0 // 关闭保活(工业用应用层心跳)
/* 内存优化 */
#define MEM_SIZE 8192 // 通用堆内存
#define PBUF_POOL_SIZE 32 // PBUF池数量
#define PBUF_POOL_BUFSIZE 1524 // PBUF池大小(MTU+头)
#define MEMP_NUM_TCP_PCB 8 // TCP控制块
#define MEMP_NUM_UDP_PCB 4 // UDP控制块
#define MEMP_NUM_TCP_SEG 16 // TCP段
#define MEMP_NUM_NETBUF 8 // NETBUF
#define MEMP_NUM_NETCONN 8 // 连接
/* 性能优化 */
#define TCP_SND_BUF 8192 // 发送缓冲区
#define TCP_WND 8192 // 接收窗口
#define TCP_MSS 1460 // 最大段大小
#define TCP_SNDQUEUELOWAT 2048 // 发送队列低水位
#define LWIP_NETIF_TX_SINGLE_PBUF 1 // 发送合并为单pbuf
#define CHECKSUM_BY_HARDWARE 1 // 硬件校验和
/* 定时器优化 */
#define TCP_TMR_INTERVAL 100 // TCP定时器间隔(ms)
#define TCP_FAST_INTERVAL 100 // 快速定时器
#define TCP_SLOW_INTERVAL 500 // 慢速定时器
/* 线程安全 */
#define LWIP_TCPIP_CORE_LOCKING 1 // 核心锁机制
#define LWIP_TCPIP_CORE_LOCKING_INPUT 1
#endif /* LWIPOPTS_H */三、内存池(MEMP)与PBUF管理机制
LWIP的内存管理采用混合策略:固定大小的内存池(MEMP)用于频繁分配的核心数据结构,通用堆(MEM)用于动态分配,PBUF则是承载网络数据包的基本容器。
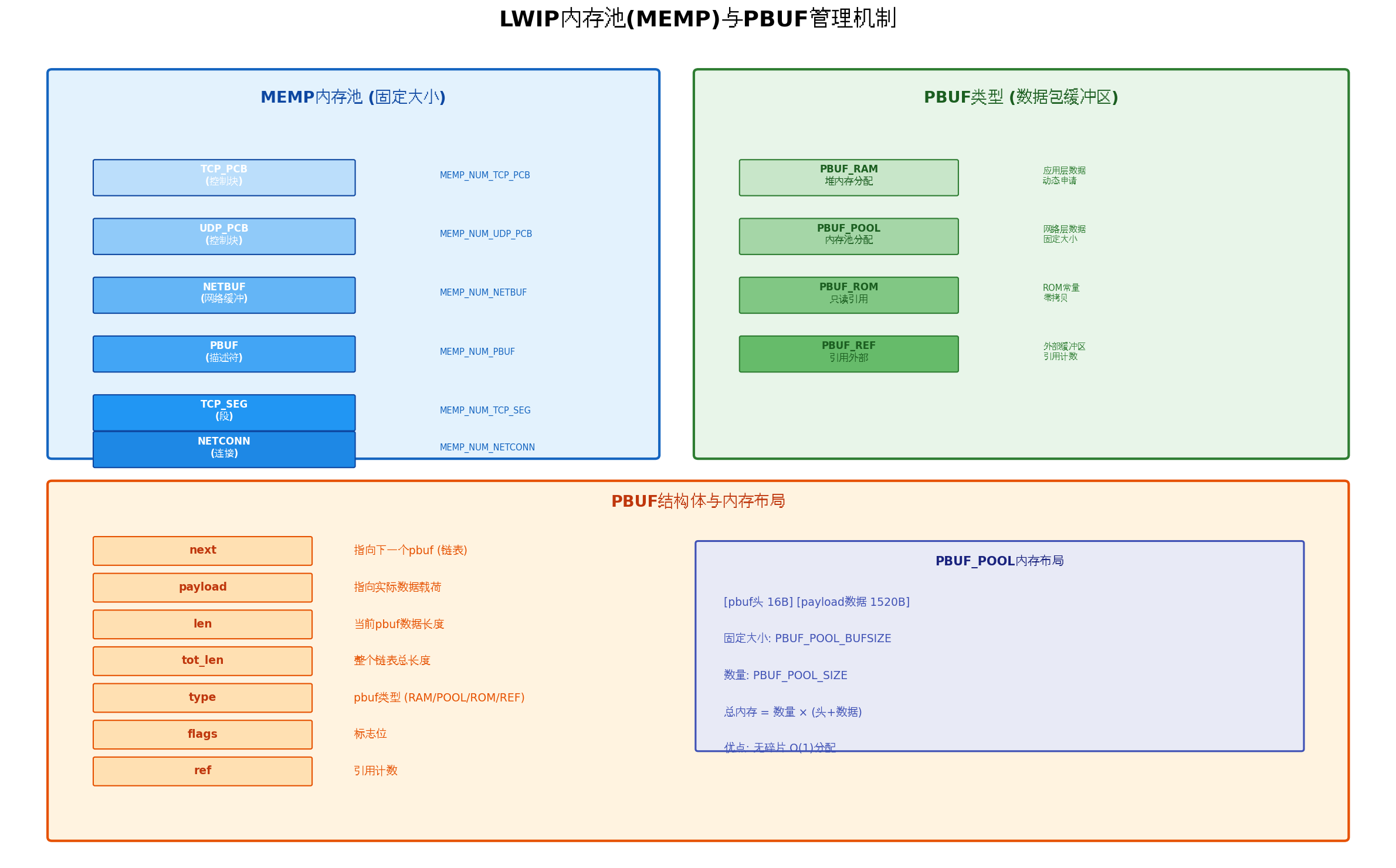
3.1 MEMP内存池机制
MEMP(Memory Pool)是LWIP的核心内存管理机制,采用预分配固定大小内存块的方式,避免了动态分配带来的碎片和不确定性。
c
/* MEMP内存池类型定义 */
typedef enum {
MEMP_RAW_PCB, // RAW协议控制块
MEMP_UDP_PCB, // UDP控制块
MEMP_TCP_PCB, // TCP控制块
MEMP_TCP_PCB_LISTEN,// TCP监听控制块
MEMP_TCP_SEG, // TCP段
MEMP_NETBUF, // 网络缓冲区
MEMP_NETCONN, // 网络连接
MEMP_TCPIP_MSG_API, // TCPIP消息API
MEMP_TCPIP_MSG_INPKT,// TCPIP输入包消息
MEMP_ARP_QUEUE, // ARP队列
MEMP_PBUF, // PBUF描述符
/* ... 更多类型 ... */
MEMP_MAX
} memp_t;MEMP的核心优势:
- O(1)分配/释放:通过链表管理空闲块,分配和释放都是常数时间
- 无内存碎片:固定大小块避免了碎片问题
- 确定性:内存使用量在编译期确定,适合实时系统
3.2 PBUF数据包缓冲区
PBUF是LWIP中承载网络数据的核心数据结构,支持四种类型:
| PBUF类型 | 内存来源 | 适用场景 | 特点 |
|---|---|---|---|
| PBUF_RAM | 堆内存(mem_malloc) | 应用层发送数据 | 动态分配,大小灵活 |
| PBUF_POOL | 内存池(memp) | 网络层接收数据 | 固定大小,快速分配 |
| PBUF_ROM | 外部ROM | 静态数据发送 | 零拷贝,只读引用 |
| PBUF_REF | 外部RAM | 应用层数据发送 | 零拷贝,引用计数 |
c
/* PBUF结构体定义 */
struct pbuf {
struct pbuf *next; // 指向下一个pbuf(链表)
void *payload; // 指向实际数据载荷
u16_t tot_len; // 整个链表总长度
u16_t len; // 当前pbuf数据长度
u8_t type; // pbuf类型
u8_t flags; // 标志位
u16_t ref; // 引用计数
};3.3 PBUF_POOL内存布局优化
PBUF_POOL是接收路径的首选,其内存布局需要精心设计:
c
/* PBUF_POOL配置 */
#define PBUF_POOL_SIZE 32 // 缓冲区数量
#define PBUF_POOL_BUFSIZE 1524 // 缓冲区大小
/* 计算验证 */
// 以太网帧头: 14字节
// IP头: 20字节
// TCP头: 20字节
// 数据: 1460字节 (MSS)
// 总计: 1514字节 < 1524字节 (安全余量10字节)PBUF_POOL的内存布局:
[PBUF头 16B] [payload数据 1508B] = 1524B/块
总内存 = 32 × 1524B = 48,768B ≈ 48KB3.4 内存池初始化与监控
c
/* 内存池初始化 */
void memp_init(void) {
memp_t pool;
for (pool = 0; pool < MEMP_MAX; pool++) {
memp_init_pool(pool);
}
}
/* 内存池使用监控(调试用) */
#if LWIP_STATS
void memp_stats_display(void) {
memp_t pool;
for (pool = 0; pool < MEMP_MAX; pool++) {
printf(\"Pool %d: used=%d, avail=%d, max=%d\\n\",
pool,
lwip_stats.memp[pool].used,
lwip_stats.memp[pool].avail,
lwip_stats.memp[pool].max);
}
}
#endif四、零拷贝(Zero-Copy)技术实现
零拷贝是提升网络性能的核心技术,其目标是减少数据在内存中的复制次数,降低CPU负载和延迟。
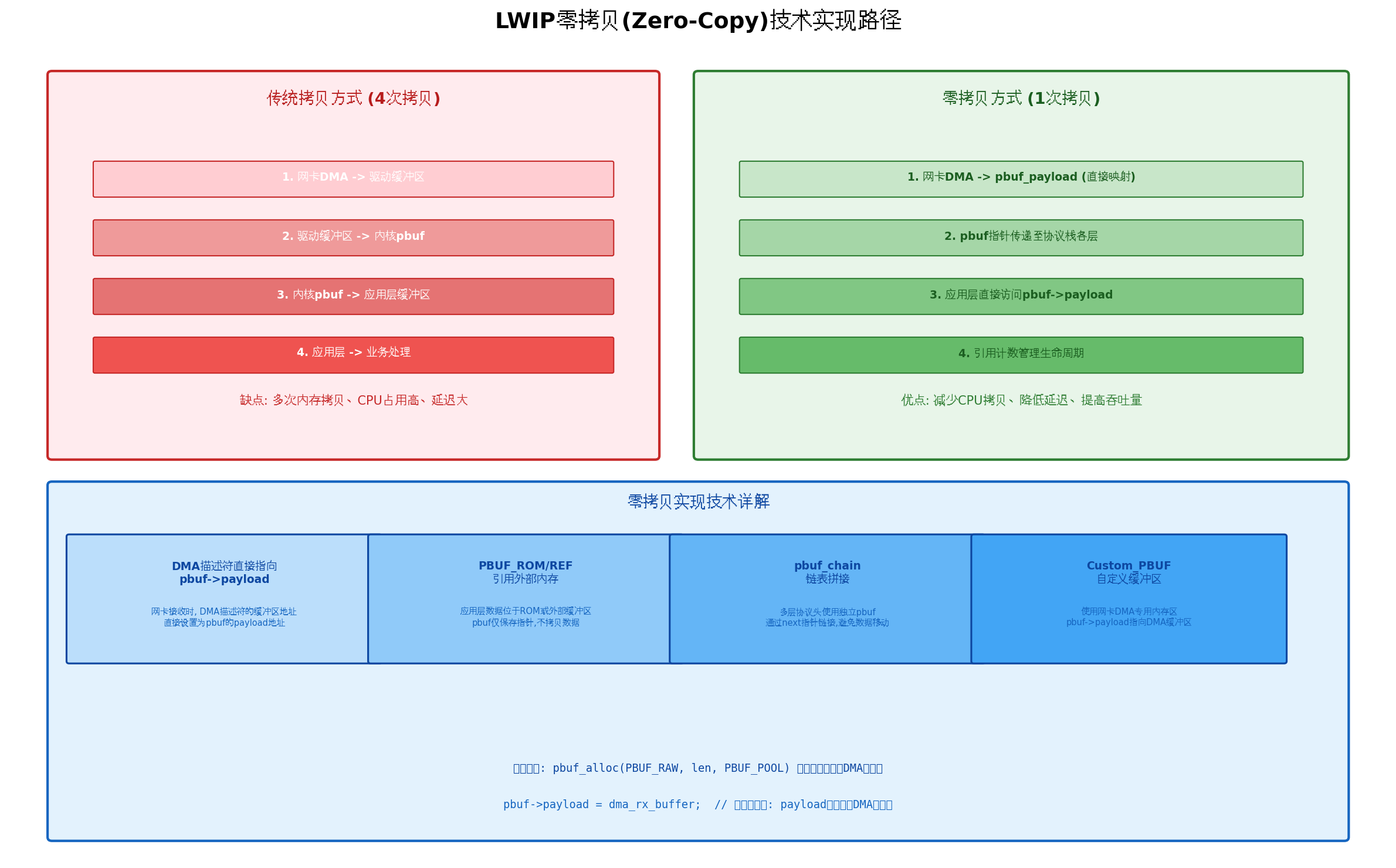
4.1 传统拷贝 vs 零拷贝
传统方式(4次拷贝):
- 网卡DMA → 驱动缓冲区
- 驱动缓冲区 → 内核pbuf
- 内核pbuf → 应用层缓冲区
- 应用层 → 业务处理
零拷贝方式(1次拷贝):
- 网卡DMA → pbuf->payload(直接映射)
- pbuf指针传递至协议栈各层
- 应用层直接访问pbuf->payload
- 引用计数管理生命周期
4.2 零拷贝实现技术
4.2.1 DMA描述符直接指向PBUF
c
/* 零拷贝核心: DMA描述符与PBUF映射 */
#define ETH_RX_DESC_CNT 8 // RX描述符数量
#define ETH_TX_DESC_CNT 8 // TX描述符数量
/* 全局映射表 */
static struct pbuf *g_rxPbuf[ETH_RX_DESC_CNT];
static ETH_DMADescTypeDef g_rxDmaDesc[ETH_RX_DESC_CNT];
/* 初始化DMA描述符与PBUF映射 */
void ETH_InitDescriptors(void) {
for (int i = 0; i < ETH_RX_DESC_CNT; i++) {
/* 分配PBUF_POOL缓冲区 */
g_rxPbuf[i] = pbuf_alloc(PBUF_RAW, PBUF_POOL_BUFSIZE, PBUF_POOL);
if (g_rxPbuf[i] == NULL) {
LWIP_ASSERT(\"PBUF alloc failed\", 0);
return;
}
/* 配置DMA描述符指向PBUF payload */
g_rxDmaDesc[i].Buffer1Addr = (uint32_t)g_rxPbuf[i]->payload;
g_rxDmaDesc[i].Control |= ETH_DMADESC_OWN; // 交给DMA
g_rxDmaDesc[i].Buffer2NextDescAddr = (uint32_t)&g_rxDmaDesc[(i+1)%ETH_RX_DESC_CNT];
}
/* 设置DMA描述符环 */
ETH->DMARDLAR = (uint32_t)&g_rxDmaDesc[0];
}4.2.2 RX中断零拷贝处理
c
/* RX中断处理 - 零拷贝 */
void ETH_IRQHandler(void) {
uint32_t dmaStatus = ETH->DMASR;
uint32_t rxIndex = 0;
if (dmaStatus & ETH_DMASR_RS) { // RX完成中断
while (!(g_rxDmaDesc[rxIndex].Status & ETH_DMADESC_OWN)) {
struct pbuf *p = g_rxPbuf[rxIndex];
/* 获取接收帧长度 */
uint32_t frameLen = (g_rxDmaDesc[rxIndex].Status & ETH_DMADESC_FL) >> 16;
p->len = frameLen;
p->tot_len = frameLen;
/* 关键: 增加引用计数,防止ISR释放 */
pbuf_ref(p);
/* 将pbuf传递给协议栈线程(零拷贝) */
if (sys_mbox_trypost(&g_rxMbox, p) != ERR_OK) {
/* 邮箱满,丢弃 */
pbuf_free(p);
}
/* 分配新的PBUF给DMA */
g_rxPbuf[rxIndex] = pbuf_alloc(PBUF_RAW, PBUF_POOL_BUFSIZE, PBUF_POOL);
if (g_rxPbuf[rxIndex] != NULL) {
g_rxDmaDesc[rxIndex].Buffer1Addr = (uint32_t)g_rxPbuf[rxIndex]->payload;
g_rxDmaDesc[rxIndex].Status = ETH_DMADESC_OWN; // 交回DMA
}
rxIndex = (rxIndex + 1) % ETH_RX_DESC_CNT;
}
}
ETH->DMASR = dmaStatus; // 清除中断标志
}4.2.3 PBUF_ROM/REF零拷贝发送
c
/* 使用PBUF_ROM发送静态数据(零拷贝) */
err_t send_static_data(struct tcp_pcb *tpcb, const char *data, u16_t len) {
struct pbuf *p;
err_t err;
/* PBUF_ROM: payload指向ROM中的数据,不拷贝 */
p = pbuf_alloc(PBUF_TRANSPORT, 0, PBUF_ROM);
if (p == NULL) return ERR_MEM;
p->payload = (void *)data; // 直接指向ROM数据
p->len = len;
p->tot_len = len;
err = tcp_write(tpcb, p->payload, len, TCP_WRITE_FLAG_COPY);
/* 注意: tcp_write默认会拷贝数据,需要配合TCP_WRITE_FLAG_COPY标志 */
pbuf_free(p);
return err;
}
/* 使用PBUF_REF发送应用层数据(零拷贝) */
err_t send_app_data(struct tcp_pcb *tpcb, uint8_t *appData, u16_t len) {
struct pbuf *p;
/* PBUF_REF: payload指向应用层缓冲区 */
p = pbuf_alloc(PBUF_TRANSPORT, 0, PBUF_REF);
if (p == NULL) return ERR_MEM;
p->payload = appData;
p->len = len;
p->tot_len = len;
/* 应用层数据在发送完成前不能释放 */
err_t err = tcp_write(tpcb, p->payload, len, 0); // 不拷贝
pbuf_free(p); // 减少引用计数,但数据不释放
return err;
}4.3 pbuf_chain链表拼接
多层协议头使用独立pbuf,通过next指针链接,避免数据移动:
c
/* 构建带协议头的数据包(零拷贝拼接) */
struct pbuf *build_packet_with_header(uint8_t *payload, u16_t payloadLen) {
struct pbuf *pHead, *pPayload;
/* 分配协议头pbuf */
pHead = pbuf_alloc(PBUF_TRANSPORT, 20, PBUF_RAM); // TCP头
if (pHead == NULL) return NULL;
/* 分配payload pbuf(引用外部数据) */
pPayload = pbuf_alloc(PBUF_RAW, 0, PBUF_REF);
if (pPayload == NULL) {
pbuf_free(pHead);
return NULL;
}
pPayload->payload = payload;
pPayload->len = payloadLen;
pPayload->tot_len = payloadLen;
/* 将payload链接到head后面 */
pbuf_chain(pHead, pPayload); // pHead->next = pPayload
return pHead; // 总长度 = 20 + payloadLen
}五、中断处理架构与数据流优化
中断处理是LWIP性能的关键瓶颈。设计良好的中断服务例程(ISR)应当短小精悍,避免执行复杂或耗时的操作。
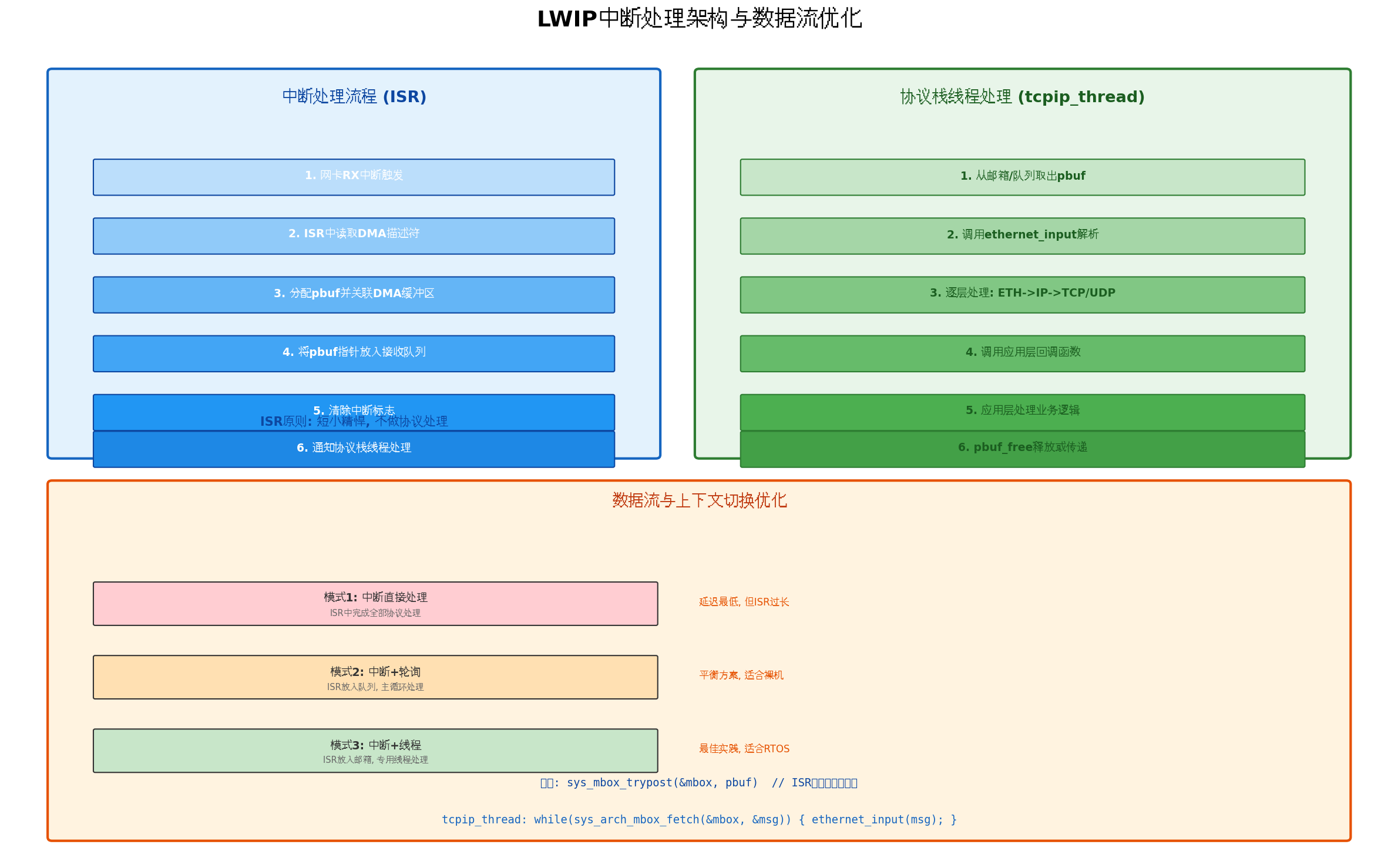
5.1 中断处理流程
ISR处理原则:
- 读取DMA描述符状态
- 分配/关联pbuf
- 将pbuf指针放入接收队列/邮箱
- 清除中断标志
- 通知协议栈线程
协议栈线程处理:
- 从邮箱/队列取出pbuf
- 调用ethernet_input解析
- 逐层处理: ETH→IP→TCP/UDP
- 调用应用层回调函数
- pbuf_free释放或传递
5.2 三种处理模式对比
| 模式 | 实现方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 模式1: 中断直接处理 | ISR中完成全部协议解析 | 延迟最低 | ISR过长,影响系统响应 | 简单裸机系统 |
| 模式2: 中断+轮询 | ISR放入队列,主循环处理 | 平衡方案 | 主循环需频繁检查 | 无RTOS的复杂系统 |
| 模式3: 中断+线程 | ISR放入邮箱,专用线程处理 | 最佳实践,线程安全 | 需要RTOS支持 | 多任务工业系统 |
5.3 RTOS环境下的中断优化
c
/* 基于FreeRTOS的LWIP中断优化 */
/* 接收邮箱 */
static sys_mbox_t g_rxMbox;
/* 初始化 */
void LWIP_Init(void) {
/* 创建接收邮箱 */
sys_mbox_new(&g_rxMbox, 16); // 队列深度16
/* 初始化LWIP */
tcpip_init(NULL, NULL);
/* 添加网络接口 */
netif_add(&g_netif, IP_ADDR_ANY, IP_ADDR_ANY, IP_ADDR_ANY, NULL,
ethernetif_init, tcpip_input);
netif_set_default(&g_netif);
netif_set_up(&g_netif);
}
/* 优化的ISR */
void ETH_IRQHandler(void) {
BaseType_t xHigherPriorityTaskWoken = pdFALSE;
uint32_t dmaStatus = ETH->DMASR;
if (dmaStatus & ETH_DMASR_RS) {
struct pbuf *p = process_rx_descriptor();
if (p != NULL) {
/* 使用FromISR版本入队 */
sys_mbox_trypost_fromisr(&g_rxMbox, p, &xHigherPriorityTaskWoken);
}
}
ETH->DMASR = dmaStatus;
/* 上下文切换 */
portYIELD_FROM_ISR(xHigherPriorityTaskWoken);
}
/* 协议栈线程 */
static void tcpip_thread(void *arg) {
struct pbuf *p;
while (1) {
/* 阻塞等待邮箱消息 */
sys_arch_mbox_fetch(&g_rxMbox, (void**)&p, 0);
if (p != NULL) {
ethernet_input(p, &g_netif); // 零拷贝传递
}
}
}5.4 中断优先级配置
c
/* NVIC中断优先级配置 */
void ETH_NVIC_Config(void) {
/* 以太网全局中断 */
NVIC_InitTypeDef NVIC_InitStruct;
NVIC_InitStruct.NVIC_IRQChannel = ETH_IRQn;
NVIC_InitStruct.NVIC_IRQChannelPreemptionPriority = 5; // 抢占优先级5
NVIC_InitStruct.NVIC_IRQChannelSubPriority = 0;
NVIC_InitStruct.NVIC_IRQChannelCmd = ENABLE;
NVIC_Init(&NVIC_InitStruct);
/* 注意: 优先级需低于FreeRTOS的configMAX_SYSCALL_INTERRUPT_PRIORITY */
/* 若configMAX_SYSCALL_INTERRUPT_PRIORITY = 5, 则ETH_IRQn优先级>=5 */
}六、以太网DMA描述符与PBUF零拷贝映射
DMA描述符环是网卡与CPU之间的桥梁,将DMA描述符与PBUF直接映射是实现零拷贝的核心。
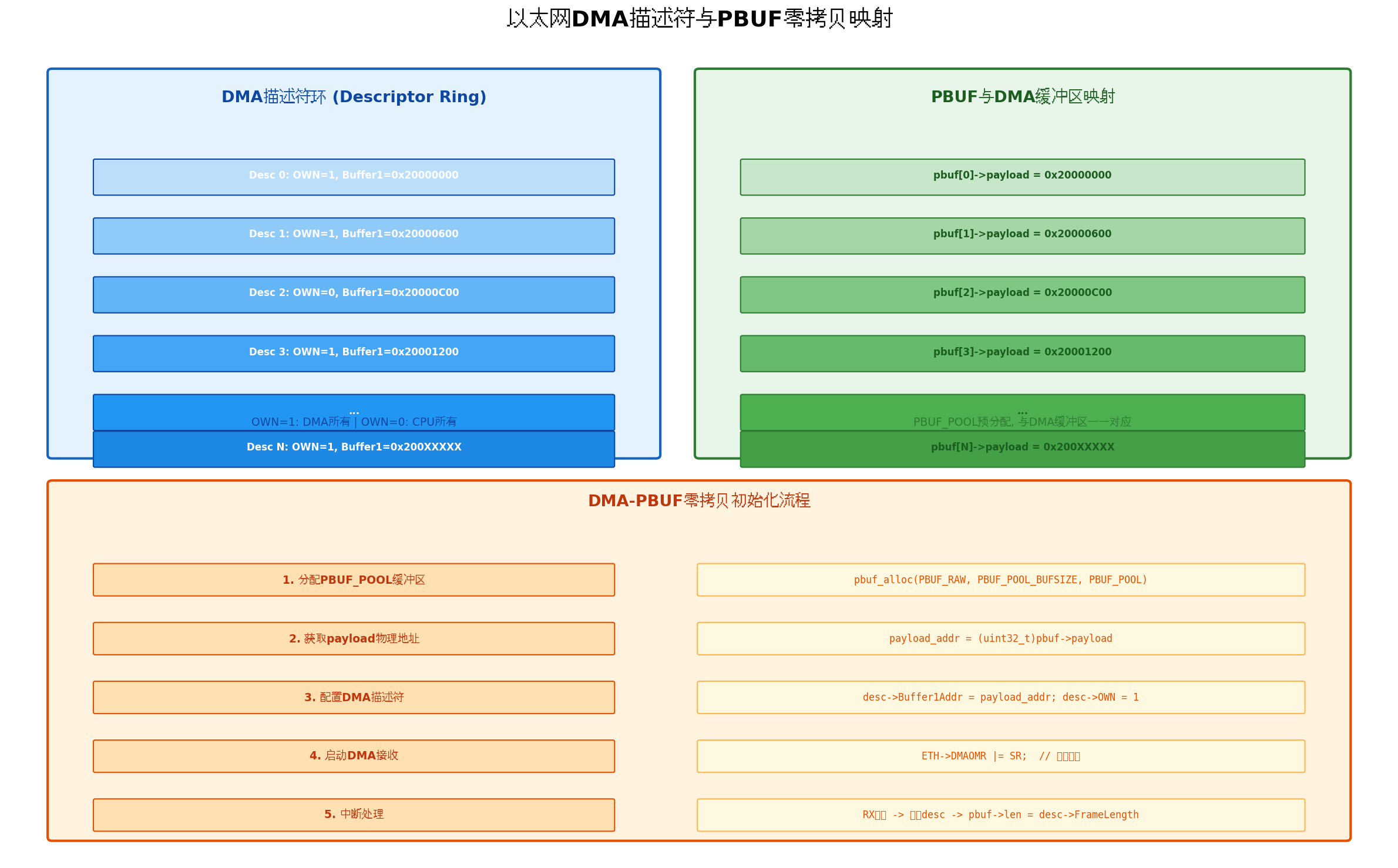
6.1 DMA描述符环结构
DMA描述符环(循环链表):
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Desc 0 │───→│ Desc 1 │───→│ Desc 2 │───→ ...
│ OWN=1 │ │ OWN=1 │ │ OWN=0 │
│ Buf=0x2000 │ │ Buf=0x2600 │ │ Buf=0x2C00 │
└─────────────┘ └─────────────┘ └─────────────┘
↑ │
└──────────────────────────────────────────┘6.2 DMA-PBUF映射初始化流程
c
/* DMA-PBUF零拷贝初始化 */
void ETH_DMADescInit(void) {
uint32_t i;
for (i = 0; i < ETH_RX_DESC_CNT; i++) {
/* 1. 分配PBUF_POOL */
g_rxPbuf[i] = pbuf_alloc(PBUF_RAW, PBUF_POOL_BUFSIZE, PBUF_POOL);
LWIP_ASSERT(\"pbuf_alloc failed\", g_rxPbuf[i] != NULL);
/* 2. 获取payload物理地址 */
uint32_t payloadAddr = (uint32_t)g_rxPbuf[i]->payload;
/* 3. 配置DMA描述符 */
g_rxDmaDesc[i].Status = 0;
g_rxDmaDesc[i].Control = ETH_DMADESC_OWN | // DMA所有
ETH_DMADESC_RCH; // 链接描述符
g_rxDmaDesc[i].Buffer1Addr = payloadAddr;
g_rxDmaDesc[i].Buffer2NextDescAddr = (uint32_t)&g_rxDmaDesc[(i+1)%ETH_RX_DESC_CNT];
}
/* 4. 设置DMA接收描述符列表地址 */
ETH->DMARDLAR = (uint32_t)&g_rxDmaDesc[0];
/* 5. 启动DMA接收 */
ETH->DMAOMR |= ETH_DMAOMR_SR; // Start Receive
}6.3 缓存一致性处理
对于带D-Cache的MCU(如STM32F7/H7),需要特别注意缓存一致性:
c
/* 缓存一致性维护 */
#include \"core_cm7.h\"
/* 接收路径: 无效化Cache(使CPU看到DMA写入的数据) */
void ETH_InvalidateDCache(uint32_t addr, uint32_t size) {
SCB_InvalidateDCache_by_Addr((uint32_t *)addr, size);
}
/* 发送路径: 清理Cache(使DMA看到CPU写入的数据) */
void ETH_CleanDCache(uint32_t addr, uint32_t size) {
SCB_CleanDCache_by_Addr((uint32_t *)addr, size);
}
/* 优化的RX处理 */
void ETH_RX_Process(void) {
uint32_t i = g_rxIndex;
while (!(g_rxDmaDesc[i].Status & ETH_DMADESC_OWN)) {
struct pbuf *p = g_rxPbuf[i];
uint32_t frameLen = (g_rxDmaDesc[i].Status & ETH_DMADESC_FL) >> 16;
/* 无效化D-Cache,确保CPU读取DMA最新数据 */
ETH_InvalidateDCache((uint32_t)p->payload, frameLen);
p->len = frameLen;
p->tot_len = frameLen;
/* 传递给协议栈 */
sys_mbox_trypost(&g_rxMbox, p);
/* 分配新PBUF */
g_rxPbuf[i] = pbuf_alloc(PBUF_RAW, PBUF_POOL_BUFSIZE, PBUF_POOL);
g_rxDmaDesc[i].Buffer1Addr = (uint32_t)g_rxPbuf[i]->payload;
g_rxDmaDesc[i].Status = ETH_DMADESC_OWN;
i = (i + 1) % ETH_RX_DESC_CNT;
}
g_rxIndex = i;
}七、关键性能优化参数配置
LWIP的性能高度依赖于配置参数的合理设置。以下是在工业场景中经过验证的推荐配置:
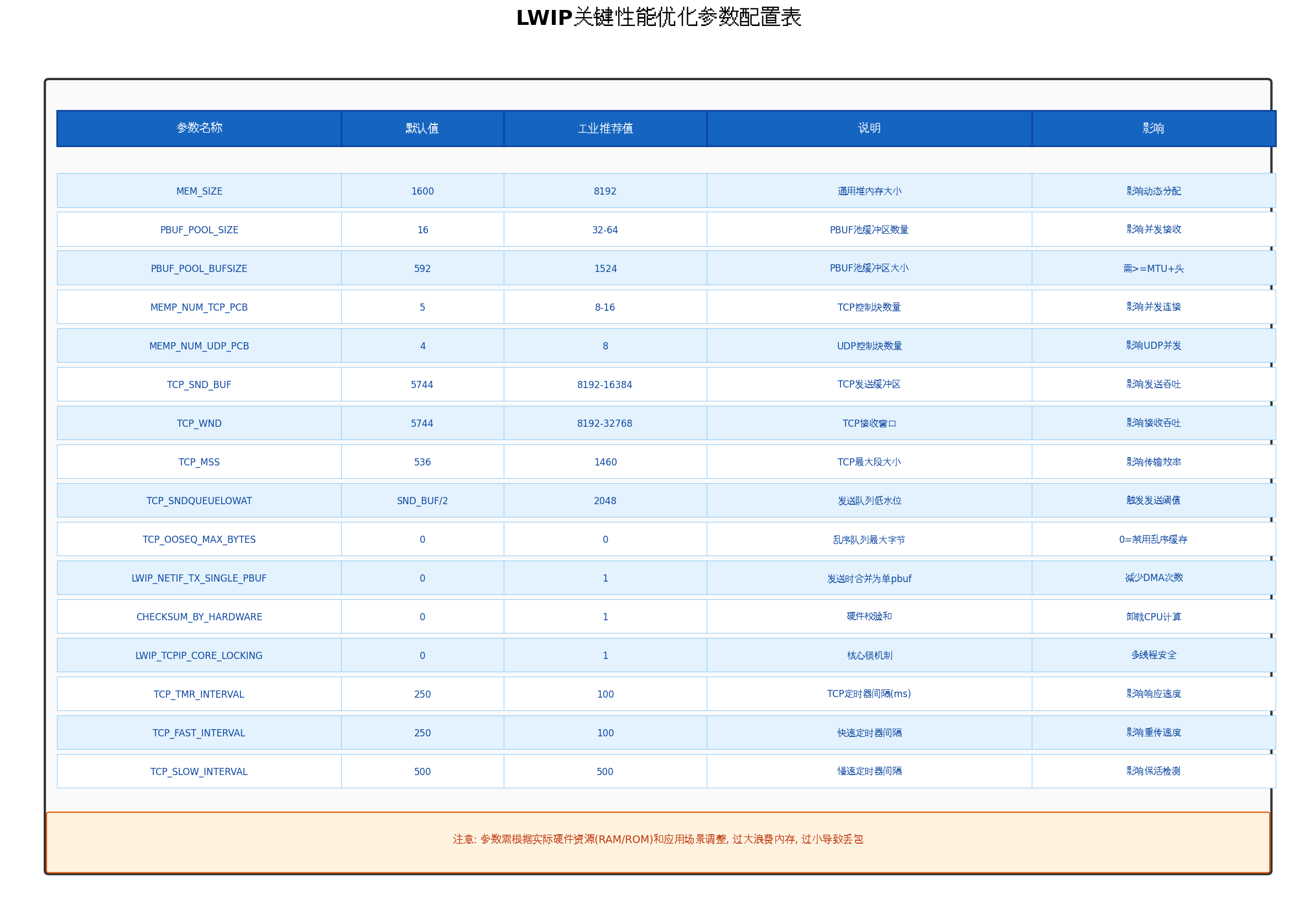
7.1 内存参数优化
c
/* 内存参数 - 工业推荐配置 */
#define MEM_SIZE 8192 // 通用堆: 8KB
#define PBUF_POOL_SIZE 32 // PBUF池: 32个
#define PBUF_POOL_BUFSIZE 1524 // PBUF大小: 1524B (MTU+头)
/* TCP参数 */
#define TCP_SND_BUF 8192 // 发送缓冲: 8KB
#define TCP_WND 8192 // 接收窗口: 8KB
#define TCP_MSS 1460 // 最大段: 1460B
#define MEMP_NUM_TCP_PCB 8 // TCP连接: 8个
#define MEMP_NUM_TCP_SEG 16 // TCP段: 16个
/* UDP参数 */
#define MEMP_NUM_UDP_PCB 4 // UDP连接: 4个7.2 定时器参数优化
c
/* 定时器参数 - 降低延迟 */
#define TCP_TMR_INTERVAL 100 // TCP定时器: 100ms (默认250ms)
#define TCP_FAST_INTERVAL 100 // 快速定时器: 100ms
#define TCP_SLOW_INTERVAL 500 // 慢速定时器: 500ms
/* 重传参数 */
#define TCP_RTO_TIME 1000 // 初始RTO: 1s
#define TCP_MAXRTX 12 // 最大重传: 12次
#define TCP_SYNMAXRTX 6 // SYN重传: 6次7.3 硬件卸载优化
c
/* 硬件校验和卸载 */
#define CHECKSUM_BY_HARDWARE 1
/* 网卡驱动中的校验和配置 */
void ETH_ChecksumOffloadConfig(void) {
/* 使能接收校验和卸载 */
ETH->MACCR |= ETH_MACCR_IPCO; // IPv4 Checksum Offload
/* 配置DMA描述符: 使能校验和插入 */
for (int i = 0; i < ETH_TX_DESC_CNT; i++) {
g_txDmaDesc[i].Status |= ETH_DMADESC_CIC_TCPUDPICMP_FULL;
}
}八、嵌入式代码实现架构
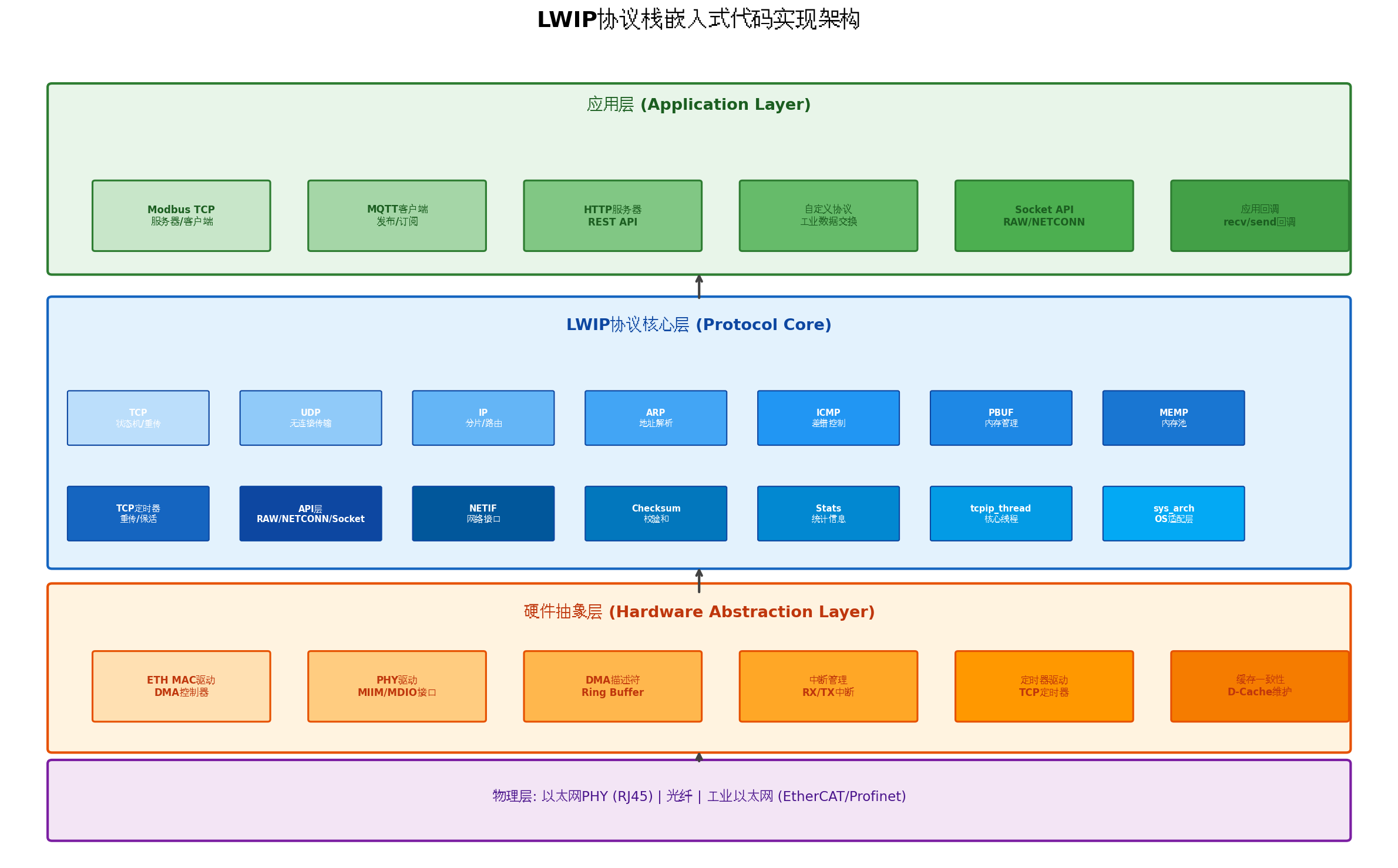
完整的LWIP嵌入式实现需要以下层次:
8.1 硬件抽象层
c
/* 网卡驱动接口 */
typedef struct {
int (*init)(struct netif *netif); // 初始化
int (*send)(struct netif *netif, struct pbuf *p); // 发送
void (*irq_handler)(void); // 中断处理
void (*poll)(struct netif *netif); // 轮询
} Eth_Driver_t;
/* PHY驱动接口 */
typedef struct {
uint32_t (*read_reg)(uint32_t regAddr); // 读寄存器
void (*write_reg)(uint32_t regAddr, uint32_t value); // 写寄存器
uint32_t (*get_link_status)(void); // 获取链路状态
uint32_t (*get_speed)(void); // 获取速率
uint32_t (*get_duplex)(void); // 获取双工模式
} Phy_Driver_t;8.2 协议栈核心层
c
/* 协议栈主循环 */
void lwip_poll(void) {
/* 处理定时器 */
sys_check_timeouts(); // TCP定时器、ARP老化等
/* 处理接收数据 */
struct pbuf *p;
while ((p = eth_driver.receive()) != NULL) {
ethernet_input(p, &g_netif);
}
/* 检查链路状态 */
static uint32_t lastLinkCheck = 0;
if (sys_now() - lastLinkCheck > 1000) { // 每秒检查一次
uint32_t linkStatus = phy_driver.get_link_status();
if (linkStatus != g_lastLinkStatus) {
netif_set_link_up(&g_netif); // 或 netif_set_link_down
g_lastLinkStatus = linkStatus;
}
lastLinkCheck = sys_now();
}
}九、完整代码实现示例
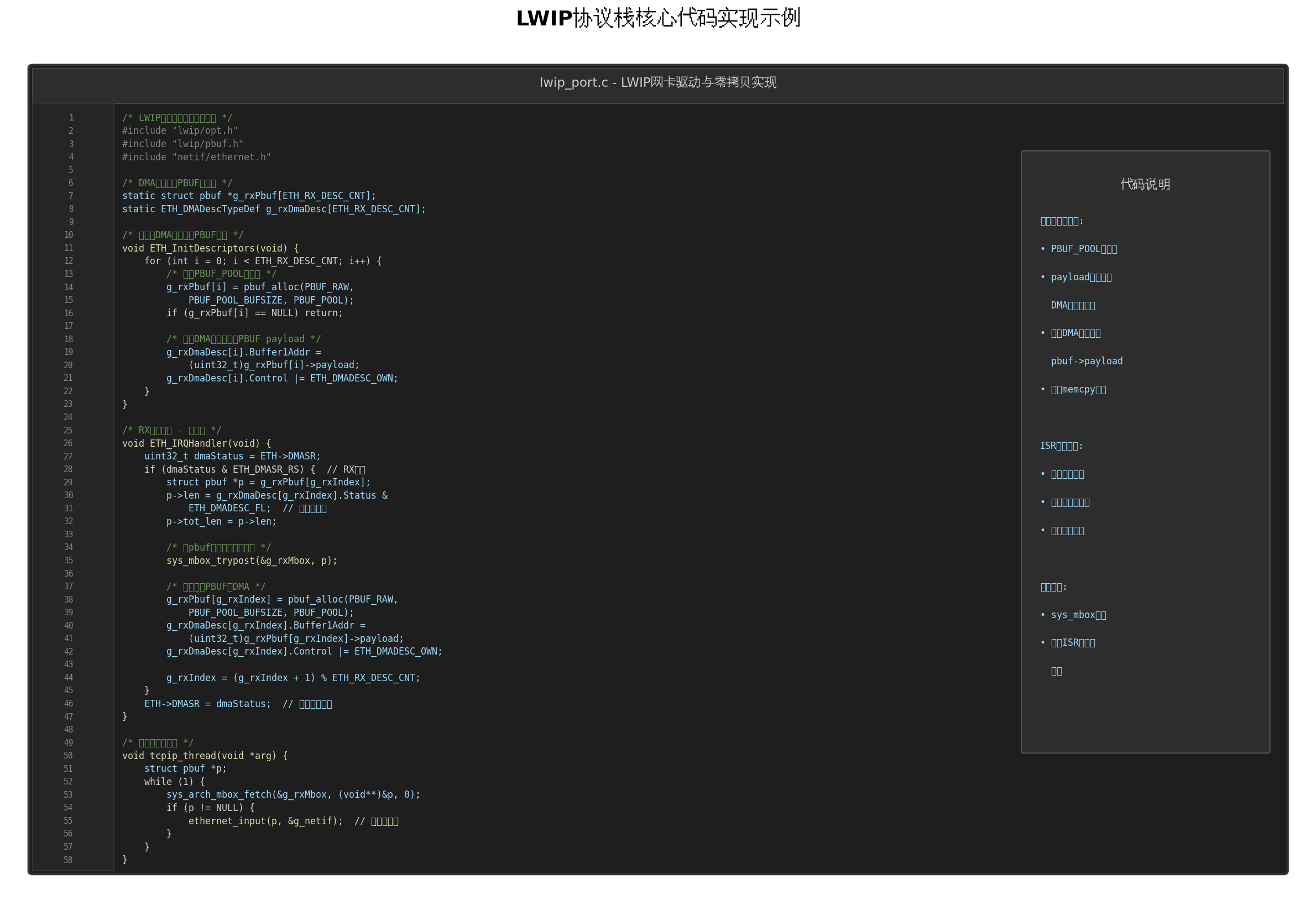
以下是完整的网卡驱动零拷贝实现:
c
/* lwip_port.c - LWIP网卡驱动与零拷贝实现 */
#include \"lwip/opt.h\"
#include \"lwip/pbuf.h\"
#include \"netif/ethernet.h\"
#include \"stm32h7xx_hal.h\"
/* DMA描述符与PBUF映射表 */
#define ETH_RX_DESC_CNT 8
#define ETH_TX_DESC_CNT 8
static struct pbuf *g_rxPbuf[ETH_RX_DESC_CNT];
static ETH_DMADescTypeDef g_rxDmaDesc[ETH_RX_DESC_CNT];
static volatile uint32_t g_rxIndex = 0;
/* 接收邮箱 */
static sys_mbox_t g_rxMbox;
static struct netif g_netif;
/* 初始化DMA描述符与PBUF映射 */
void ETH_InitDescriptors(void) {
for (int i = 0; i < ETH_RX_DESC_CNT; i++) {
/* 分配PBUF_POOL缓冲区 */
g_rxPbuf[i] = pbuf_alloc(PBUF_RAW, PBUF_POOL_BUFSIZE, PBUF_POOL);
if (g_rxPbuf[i] == NULL) {
LWIP_ASSERT(\"PBUF alloc failed\", 0);
return;
}
/* 配置DMA描述符指向PBUF payload */
g_rxDmaDesc[i].Buffer1Addr = (uint32_t)g_rxPbuf[i]->payload;
g_rxDmaDesc[i].Control |= ETH_DMADESC_OWN;
g_rxDmaDesc[i].Buffer2NextDescAddr = (uint32_t)&g_rxDmaDesc[(i+1)%ETH_RX_DESC_CNT];
}
/* 设置DMA接收描述符列表地址 */
ETH->DMARDLAR = (uint32_t)&g_rxDmaDesc[0];
}
/* RX中断处理 - 零拷贝 */
void ETH_IRQHandler(void) {
uint32_t dmaStatus = ETH->DMASR;
if (dmaStatus & ETH_DMASR_RS) { // RX完成
struct pbuf *p = g_rxPbuf[g_rxIndex];
/* 获取帧长度 */
p->len = g_rxDmaDesc[g_rxIndex].Status & ETH_DMADESC_FL;
p->tot_len = p->len;
/* 无效化D-Cache */
SCB_InvalidateDCache_by_Addr((uint32_t *)p->payload, p->len);
/* 将pbuf传递给协议栈线程 */
sys_mbox_trypost(&g_rxMbox, p);
/* 分配新的PBUF给DMA */
g_rxPbuf[g_rxIndex] = pbuf_alloc(PBUF_RAW, PBUF_POOL_BUFSIZE, PBUF_POOL);
g_rxDmaDesc[g_rxIndex].Buffer1Addr = (uint32_t)g_rxPbuf[g_rxIndex]->payload;
g_rxDmaDesc[g_rxIndex].Control |= ETH_DMADESC_OWN;
g_rxIndex = (g_rxIndex + 1) % ETH_RX_DESC_CNT;
}
ETH->DMASR = dmaStatus; // 清除中断标志
}
/* 协议栈线程处理 */
void tcpip_thread(void *arg) {
struct pbuf *p;
while (1) {
sys_arch_mbox_fetch(&g_rxMbox, (void**)&p, 0);
if (p != NULL) {
ethernet_input(p, &g_netif); // 零拷贝传递
}
}
}
/* 网卡发送函数 */
static err_t low_level_output(struct netif *netif, struct pbuf *p) {
struct pbuf *q;
uint8_t *buffer = (uint8_t *)g_txDmaDesc[g_txIndex].Buffer1Addr;
uint32_t framelength = 0;
/* 拷贝pbuf数据到DMA发送缓冲区 */
for (q = p; q != NULL; q = q->next) {
memcpy(buffer + framelength, q->payload, q->len);
framelength += q->len;
}
/* 清理D-Cache */
SCB_CleanDCache_by_Addr((uint32_t *)buffer, framelength);
/* 启动DMA发送 */
g_txDmaDesc[g_txIndex].Control = framelength | ETH_DMADESC_OWN | ETH_DMADESC_FS | ETH_DMADESC_LS;
ETH->DMAOMR |= ETH_DMAOMR_ST; // Start Transmission
g_txIndex = (g_txIndex + 1) % ETH_TX_DESC_CNT;
return ERR_OK;
}
/* 网卡初始化 */
err_t ethernetif_init(struct netif *netif) {
LWIP_ASSERT(\"netif != NULL\", (netif != NULL));
netif->linkoutput = low_level_output;
netif->output = etharp_output;
netif->mtu = 1500;
netif->flags = NETIF_FLAG_BROADCAST | NETIF_FLAG_ETHARP | NETIF_FLAG_LINK_UP;
/* 初始化MAC和DMA */
ETH_MACDMAConfig();
ETH_InitDescriptors();
/* 使能中断 */
HAL_NVIC_SetPriority(ETH_IRQn, 5, 0);
HAL_NVIC_EnableIRQ(ETH_IRQn);
return ERR_OK;
}十、性能测试与调优
10.1 性能测试指标
| 指标 | 测试方法 | 工业要求 | 优化目标 |
|---|---|---|---|
| 吞吐量 | iperf/自定义工具 | >90%线速 | 接近理论最大值 |
| 延迟 | ping/TCP RTT | <1ms(局域网) | 最小化 |
| CPU占用 | 统计idle时间 | <30% | 降低中断频率 |
| 丢包率 | 长时间压力测试 | <0.001% | 零丢包 |
| 内存使用 | 监控MEMP/MEM | <80%总量 | 预留余量 |
10.2 常见问题排查
| 现象 | 可能原因 | 解决方法 |
|---|---|---|
| 高丢包率 | PBUF_POOL不足 | 增加PBUF_POOL_SIZE |
| 高延迟 | TCP定时器间隔过大 | 减小TCP_TMR_INTERVAL |
| 连接不稳定 | 内存不足 | 增加MEM_SIZE/MEMP数量 |
| 吞吐量低 | TCP窗口太小 | 增大TCP_WND/TCP_SND_BUF |
| 缓存不一致 | D-Cache未维护 | 添加Cache无效化/清理 |
十一、总结与展望
本文从协议栈裁剪、内存池管理、零拷贝技术、中断优化四个核心维度,完整阐述了LWIP在工业以太网场景下的性能优化方案。关键技术要点包括:
- 协议裁剪是性能优化的第一步,关闭不需要的功能可显著减少ROM/RAM占用
- MEMP内存池提供确定性内存分配,O(1)的分配/释放适合实时系统
- PBUF_POOL是接收路径的首选,其大小需匹配MTU和并发需求
- 零拷贝通过DMA-PBUF直接映射,将数据拷贝从4次降至1次
- 中断处理遵循"短小精悍"原则,协议解析交给专用线程
- D-Cache一致性是高性能MCU的必选项,需正确维护Cache状态
在实际工业应用中,还需要考虑:
- TSN(时间敏感网络)的硬件时间戳支持
- EtherCAT/Profinet等工业以太网协议的共存
- 功能安全(SIL等级)对网络通信的要求
- 网络安全(TLS/IPSec)在工业场景的应用
通过本文的技术实现,开发者可以构建高性能、低延迟、高确定性的工业以太网通信系统,满足智能制造对网络通信的严苛要求。
转载自:https://blog.csdn.net/u014727709/article/details/162512692
欢迎 👍点赞✍评论⭐收藏,欢迎指正