哈喽大家好,我是咸鱼
今天分享一篇文章,是关于 TCP 拥塞控制对数据延迟产生的影响的。作者在服务延迟变高之后进行抓包分析,结果发现时间花在了 TCP 本身的机制上面:客户端并不是将请求一股脑发送给服务端,而是只发送了一部分,等到接收到服务端的 ACK,然后继续再发送,这就造成了额外的 RTT,这个额外的 RTT 是由 TCP 的拥塞控制导致的
原文链接:https://www.kawabangga.com/posts/5181
这是上周在项目上遇到的一个问题,在内网把问题用英文分析了一遍,觉得挺有用的,所以在博客上打算再写一次。
问题是这样的:我们在当前的环境中,网络延迟 <1ms,服务的延迟是 2ms,现在要迁移到一个新的环境,新的环境网络自身延迟(来回的延迟,RTT,本文中谈到延迟都指的是 RTT 延迟)是 100ms,那么请问,服务的延迟应该是多少?
我们的预期是 102ms 左右,但是现实中,发现实际的延迟涨了不止 100ms,P99 到了 300ms 左右。
从日志中,发现有请求的延迟的确很高,但是模式就是 200ms, 300ms 甚至 400ms 左右,看起来是多花了几个 RTT。
接下来就根据日志去抓包,最后发现,时间花在了 TCP 本身的机制上面,这些高延迟的请求都发生在 TCP 创建连接之后。
首先是 TCP 创建连接的时间,TCP 创建连接需要三次握手,需要额外增加一个 RTT。为什么不是两个 RTT?因为过程是这样的:
+0 A -> B SYN
+0.5RTT B -> A SYN+ACK
+1RTT A -> B ACK
+1RTT A -> B Data即第三个包,在 A 发给 B 之后,A 就继续发送下面的数据了,所以可以认为这第三个包不会占用额外的时间。
这样的话,延迟会额外增加一个 RTT,加上本身数据传输的一个 RTT,那么,我们能观察到的最高的 RTT 应该是 2 个 RTT,即 200ms,那么为什么会看到 400ms 的请求呢?
从抓包分析看,我发现在建立 TCP 连接之后,客户端并不是将请求一股脑发送给服务端,而是只发送了一部分,等到接收到服务端的 ACK,然后继续在发送,这就造成了额外的 RTT。看到这里我恍然大悟,原来是 cwnd 造成的。
cwnd 如何分析,之前的博文中也提到过。简单来说,这是 TCP 层面的一个机制,为了避免网络赛车,在建立 TCP 连接之后,发送端并不知道这个网络到底能承受多大的流量,所以发送端会发送一部分数据,如果 OK,满满加大发送数据的量。这就是 TCP 的慢启动。
那么慢启动从多少开始呢?
Linux 中默认是 10.
/usr/src/linux/include/net/tcp.h:
/* TCP initial congestion window as per draft-hkchu-tcpm-initcwnd-01 */
#define TCP_INIT_CWND 10也就是说,在小于 cwnd=10 * MSS=1448bytes = 14480bytes 数据的情况下,我们可以用 2 RTT 发送完毕数据。即 1 个 RTT 用于建立 TCP 连接,1个 RTT 用于发送数据。
下面这个抓包可以证明这一点,我在 100ms 的环境中,从一端发送了正好 14480 的数据,恰好是用了 200ms:
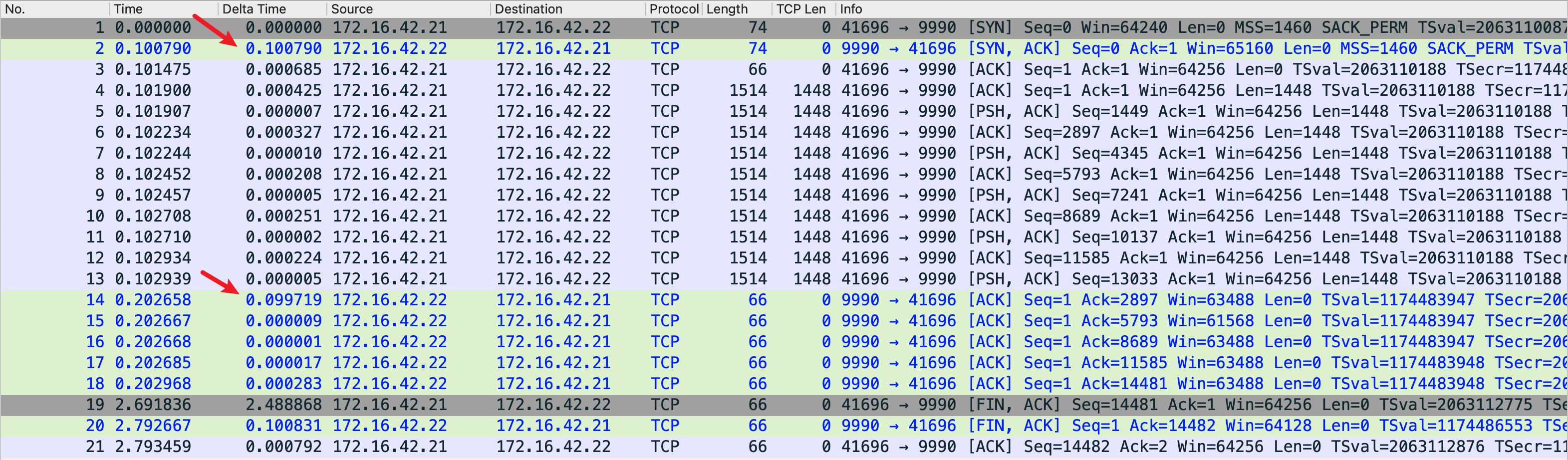 100ms 用于建立连接,100ms 用于发送数据
100ms 用于建立连接,100ms 用于发送数据
如果发送的数据小于 14480 bytes(大约是 14K),那么用的时间应该是一样的。
但是,如果多了即使 1 byte,延迟也会增加一个 RTT,即需要 300ms。下面是发送 14481 bytes 的抓包情况:
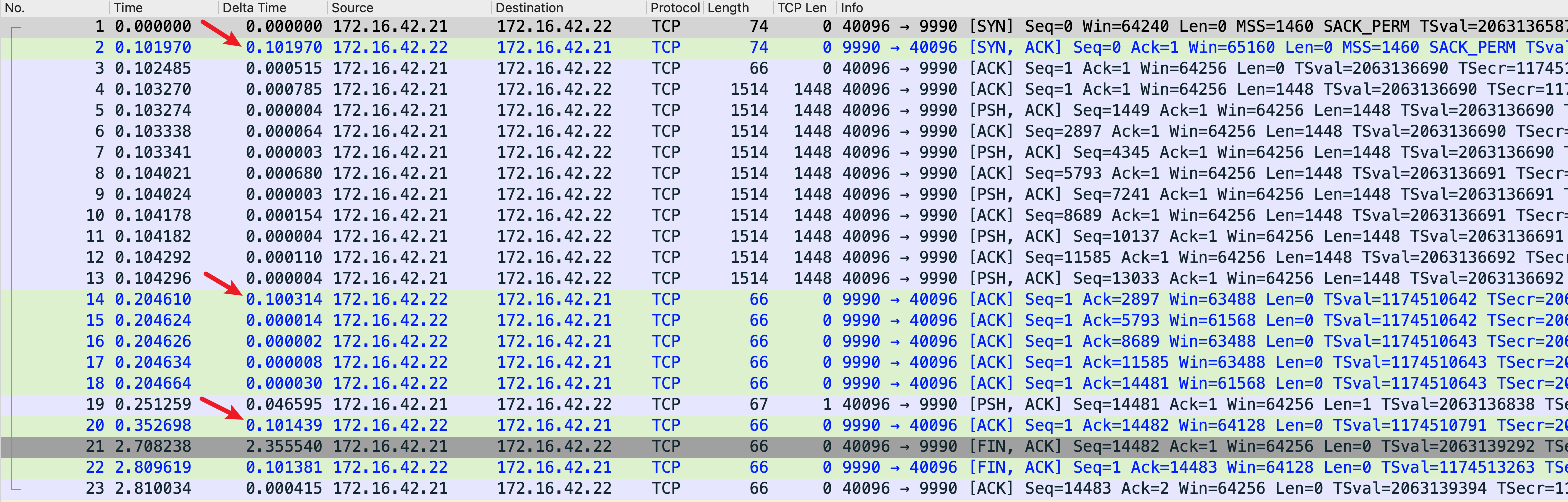 多出来一个 100ms 用于传输这个额外的 byte
多出来一个 100ms 用于传输这个额外的 byte
慢启动,顾名思义,只发生在启动阶段,如果第一波发出去的数据都能收到确认,那么证明网络的容量足够,可以一次性发送更多的数据,这时 cwnd 就会继续增大了(取决于具体拥塞控制的算法)。
这就是额外的延迟的来源了。回到我们的案例,这个用户的请求大约是 30K,响应也大约是 30K,而 cwnd 是双向的,即两端分别进行慢启动,所以,请求发送过来 +1 RTT,响应 +1 RTT,TCP 建立连接 +1 RTT,加上本身数据传输就有 1 RTT,总共 4RTT,就解释的通了。
解决办法也很简单,两个问题都可以使用 TCP 长连接来解决。
PS:其实,到这里读者应该发现,这个服务本身的延迟,在这种情况下,也是 4个 RTT,只不过网络环境 A 的延迟很小,在 1ms 左右,这样服务自己处理请求的延迟要远大于网络的延迟,1 个 RTT 和 4 个 RTT 从监控上几乎看不出区别。
PPS:其实,以上内容,比如 "慢启动,顾名思义,只发生在启动阶段",以及 "两个问题都可以使用 TCP 长连接来解决" 的表述是不准确的,详见我们后面又遇到的一个问题:TCP 长连接 CWND reset 的问题分析。
Initial CWND 如果修改的话也有办法。
这里的 thread 的讨论,有人提出了一种方法:大意是允许让应用程序通过 socket 参数来设置 CWND 的初始值:
setsockopt(fd, IPPROTO_TCP, TCP_CWND, &val, sizeof (val))------然后就被骂了个狗血淋头。
Stephen Hemminger 说 IETF TCP 的家伙已经觉得 Linux 里面的很多东西会允许不安全的应用了。这么做只会证明他们的想法。这个 patch 需要做很多 researech 才考虑。
如果 misuse,比如,应用将这个值设置的很大,那么假设一种情况:网络发生拥堵了,这时候应用不知道网络的情况,如果建立连接的话,还是使用一个很大的 initcwnd 来启动,会加剧拥堵,情况会原来越坏,永远不会自动恢复。
David Miller 的观点是,应用不可能知道链路 (Route) 上的特点:
initcwnd是一个路由链路上的特点,不是 by application 决定的;- 只有人才可能清楚整个链路的质量,所以这个选项只能由人 by route 设置。
所以现在只能 by route 设置。
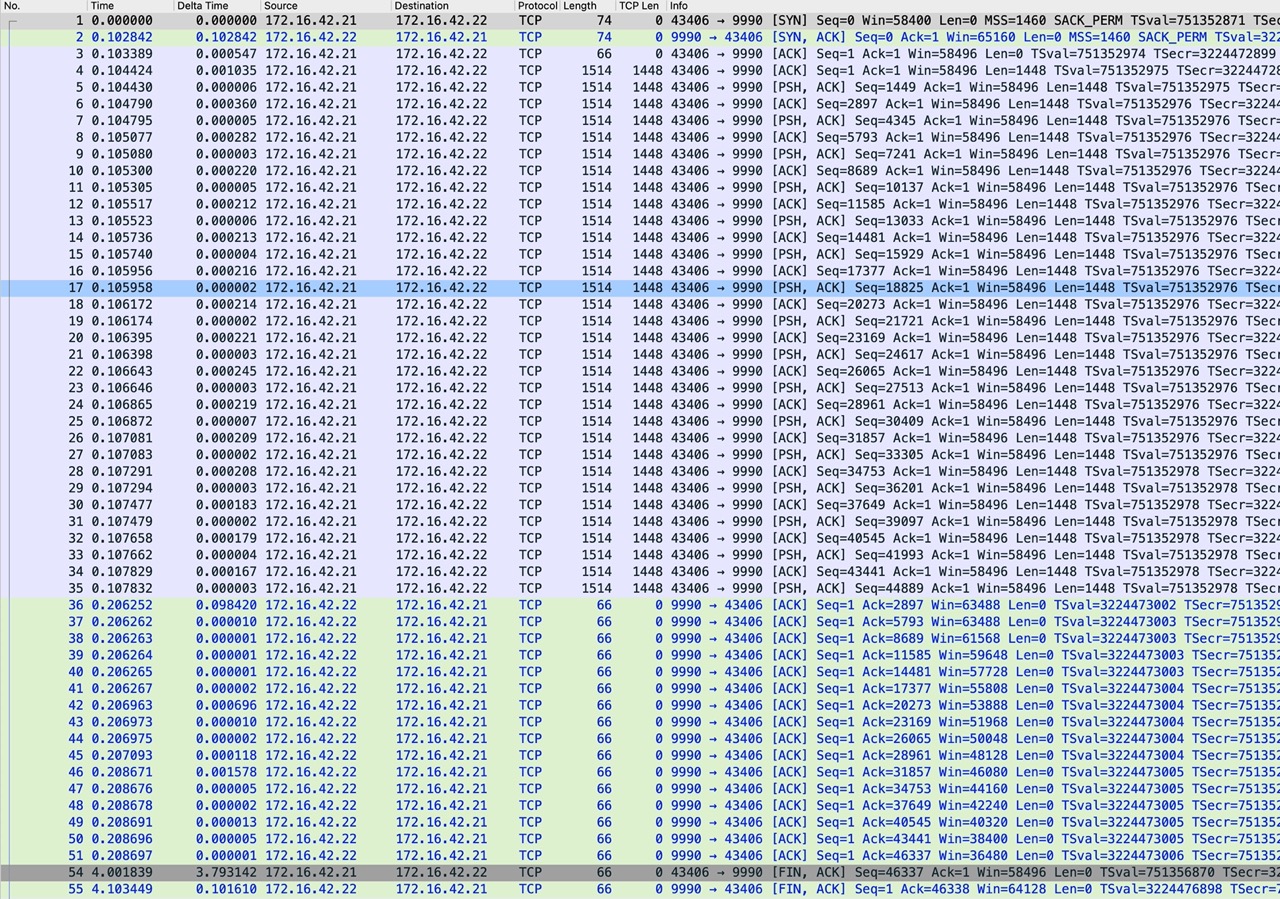
我实验了一下,将 cwnd 设置为 40:
 通过 ip route 命令修改
通过 ip route 命令修改
然后在实验,可以看到这时候,client 发送的时候,可以一次发送更多的数据了。
后记
现在看这个原因,如果懂一点 TCP,很快就明白其中的原理,很简单。
但是现实情况是,监控上只能看到 latency 升高了,但是看不出具体是哪一些请求造成的,只知道这个信息的话,那可能的原因就很多了。到这里,发现问题之后,一般就进入了扯皮的阶段:中间件的用户拿着监控(而不是具体的请求日志)去找平台,平台感觉是网络问题,将问题丢给网络团队,网络团队去检查他们自己的监控,说他们那边显示网络没有问题(网络层的延迟当然没有问题)。
如果要查到具体原因的话,需要:
- 先从日志中查找到具体的高延迟的请求。监控是用来发现问题的,而不是用来 debug 的;
- 从日志分析时间到底花在了哪一个阶段;
- 通过抓包,或者其他手段,验证步骤2 (这个过程略微复杂,因为要从众多连接和数据包中找到具体一个 TCP 的数据流)
我发现在大公司里面,这个问题往往牵扯了多个团队,大家在没有确认问题就出现在某一个团队负责的范围内的时候,就没有人去这么查。
我在排查的时候,还得到一些错误信息,比如开发者告诉我 TCP 连接的保持时间是 10min,然后我从日志看,1min 内连续的请求依然会有高延迟的请求,所以就觉得是 TCP 建立连接 overhead 之外的问题。最后抓包才发现明显的 SYN 阶段包,去和开发核对逻辑,才发现所谓的 10min 保持连接,只是在 Server 侧一段做的,Client 侧不关心这个时间会将 TCP 直接关掉。
幸好抓到的包不会骗人。