HTML表格在网页上以网格格式显示数据。表格以行和列的形式组织表格数据,其中每个单元格可以包含文本、图像、链接或其他 HTML 元素。在这篇博文中,我们将学习如何用 Java 创建 HTML 表。
**Aspose.Html**是一种高级的HTML操作API,可让您直接在.NET应用程序中执行广泛的HTML操作任务,Aspose.Html for .NET允许创建,加载,编辑或转换(X)HTML文档,而无需额外的软件或工具。API还为固定布局格式(如PDF和XPS)以及许多光栅图像格式提供了高保真渲染引擎。
Aspose API支持流行文件格式处理,并允许将各类文档导出或转换为固定布局文件格式和最常用的图像/多媒体格式。
Aspose.Html 最新下载(qun:666790229)![]() https://www.evget.com/product/3983/download
https://www.evget.com/product/3983/download
这篇博文展示了Aspose.HTML for .NET提供的另一个突出功能。这个功能丰富的 .NET 库使您能够以C#编程方式从网页中提取文本。此外,此文本提取 API公开了多个用于从HTML页面中提取文本的类和方法。
因此,您可以轻松地为您的软件开发网站文本提取器,这将为您的业务带来竞争优势。因此,请仔细阅读本文,不要错过任何部分。此外,请确保您已在本地计算机上安装了 .NET 以实现该功能。
文本提取 API 安装
Aspose.HTML for .NET 提供了一种从网页中提取文本的无缝解决方案。作为 C# 程序员,您可以选择此文本提取 API来开发网页文本提取器以提高工作效率。此外,在多种情况下您都需要网站文本提取 API,因此Aspose.HTML for .NET可能是首选。不过,您可以通过下载DLL 文件或在NuGet包管理器 中运行以下命令来 安装它 :
PM> Install-Package Aspose.Html
您可以在此处查看完整的安装说明。
使用 C# 从网页中提取文本 - 代码示例
使用Aspose.HTML for .NET库既不复杂也不困难。因此,此文本提取 API是由我们顶尖的工程师精心设计的。那么,让我们开始编写代码片段吧。
您可以按照以下步骤操作:
- 定义目录地址。
- 初始化HTMLDocument类的构造函数来加载网页。
- 通过调用GetElementsByTagName方法收集所有 h2 标题。
- 循环遍历所有检索到的 h2 标题。
- 使用GetElementsByTagName方法获取粗体文本。
- 循环遍历从网页检索的所有粗体文本。
- 调用WriteAllText方法将文本保存到Txt文件中。
以下代码片段展示了如何以 C# 编程方式从网页中提取文本:
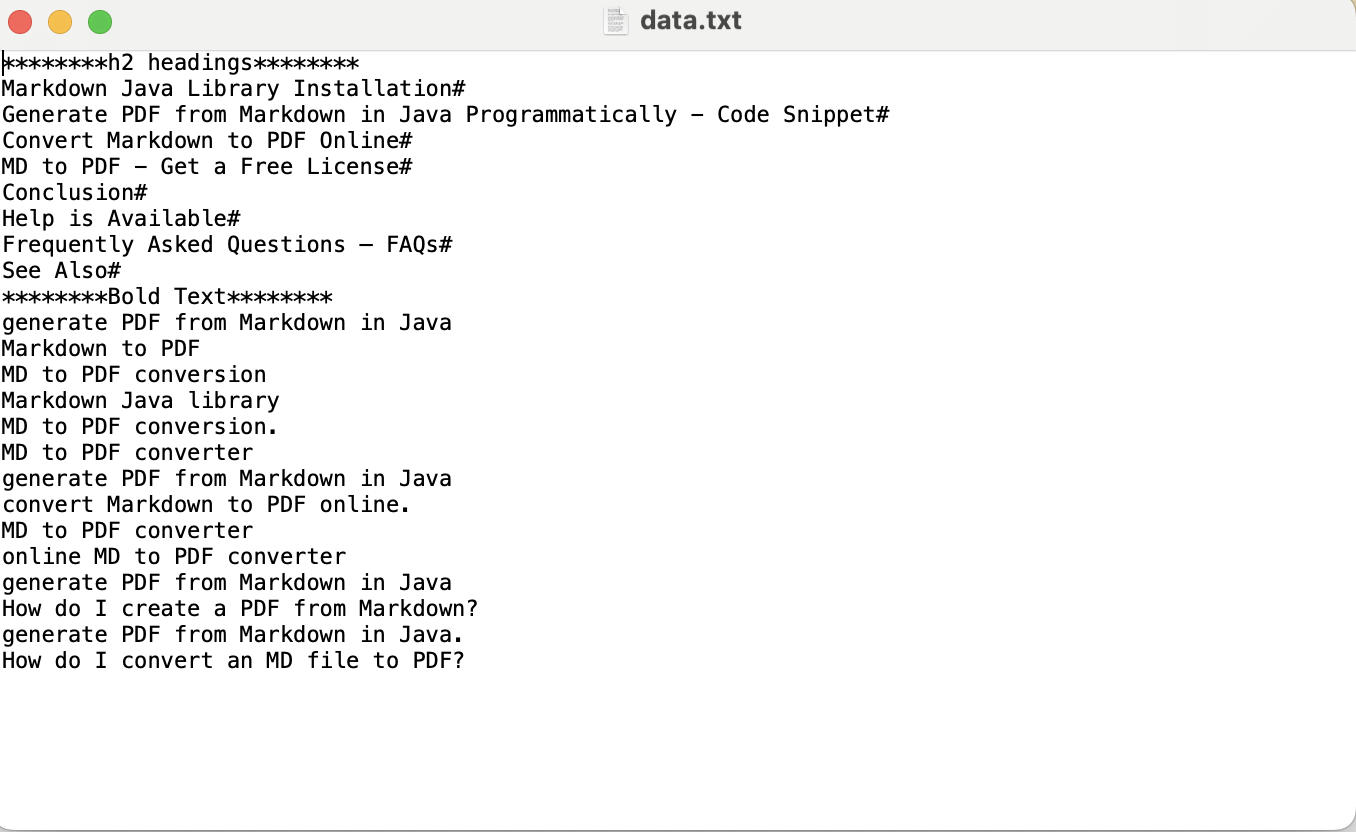
namespace Aspose.Html { class HTML { // Extract Text from Webpage in C# - Text Extraction API static void Main(string[] args) { // Define the directory address String dir = "/sample-files/"; // Initialize a constructor of HTMLDocument class to load a webpage. using (var document = new HTMLDocument("https://blog.aspose.com/html/generate-pdf-from-markdown-in-java-markdown-to-pdf/")) { // Collect all h2 headings by calling the GetElementsByTagName method. var headings = document.GetElementsByTagName("h2"); String data = "********h2 headings********" + System.Environment.NewLine; // loop through all the retrieved h2 headings. for (var i = 0; i < headings.Length; i++) { data += headings[i].TextContent+System.Environment.NewLine; } // Get the bold text using the GetElementsByTagName method. var boldTags = document.GetElementsByTagName("strong"); data += "********Bold Text********" + System.Environment.NewLine; // Loop through all the bold text retrieved from a webpage. for (var i = 0; i < boldTags.Length; i++) { data += boldTags[i].TextContent + System.Environment.NewLine; } // Call the WriteAllText method to save the text in a txt file. File.WriteAllText(Path.Combine(dir, "data.txt"), data); } } } }
上述代码示例的输出如下图所示:
在线文本提取器
此在线网页文本提取器是一款可以非编程方式执行数据提取任务的工具。它是一款基于 Web 的应用程序,在手机的 Web 浏览器中也能很好地运行。最重要的是,它是免费的,并且可以非常快速地从 HTML 页面中提取文本。将来,此在线文本提取器将配备更多功能。
结论
这篇博文到此结束。我们希望您已经学会了如何使用C# 以编程方式从网页中提取文本。此外,您还了解了从 HTML 页面中提取文本的实际实现。事实上,在快速应用程序开发方面,程序员总是倾向于使用可靠且强大的 API,幸运的是,Aspose.HTML for .NET几乎可以为您完成这项工作。因此,您可以通过访问文档和 API参考了解有关此文本提取 API 的更多信息。