逐层拆分ElasticSearch的概念
-
Cluster:集群,Es是一个可以横向扩展的检索引擎(部分时候当作存储数据库使用),一个Es集群由一个唯一的名字标识,默认为"elasticsearch"。在配置文件中指定相同的集群名,Es会将相同集群名的节点组成一个集群。
-
Node:节点,集群中的任意一个实例对象,是一个节点
-
Index:索引,存放相同类型数据的一个集合,索引有唯一的名字,相比于关系型数据库,可以理解为一个表(6.0.0废除type之后)
-
Shard:分片,物理存储单位,创建一个索引时可以指定分成多少个分片来存储。每个分片本身也是一个功能完善且独立的"索引",可以被放置在集群的任意节点上。
-
Replication:副本,对数据的备份,主要针对分片进行备份,即分片的备份
-
Document:文档,具体存储的数据(json结构)
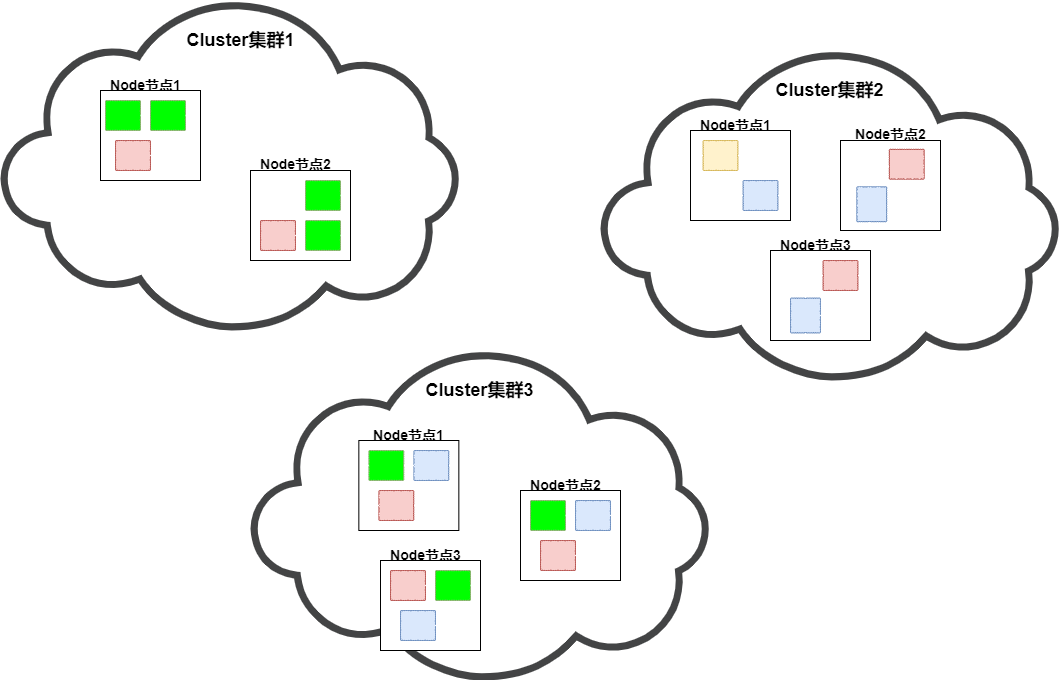
如上图,每个云朵代表一个Es集群Cluster,集群中由一个个的Es实例Node构成,每个Es实例中存放着一个个的彩色方块(Shard),同一个集群中相同颜色的方块(shard)构成一个索引(index)
索引和分片、副本
实际上,索引是一个抽象的逻辑概念,使用时,我们面向的是索引(Index ),只需要指定索引名即可。索引背后真正的实体是分片(Shard)。
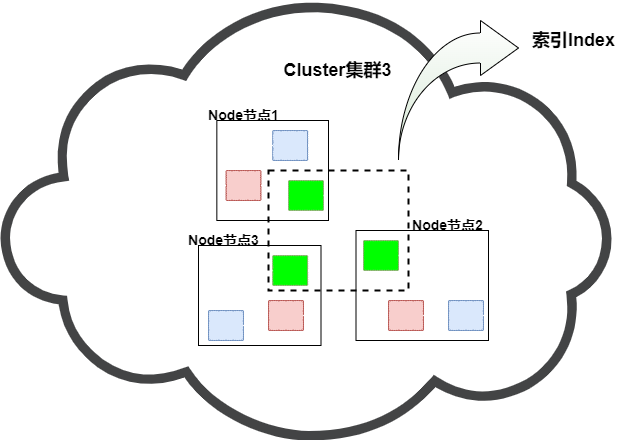
同一集群中,同一索引(Index )可能由多个分片(Shard )组成,这些Shard 会分布在不同的节点(Node )中;而副本(Replication)则可以理解为一种特殊的分片,实际上数据是在一个个的分片上的,而副本的主要职责是对分片进行备份,以满足Es的稳定性。当副本数设置为1时,则代表着每个分片都会有一个副本,且副本中的内容与分片一样,肩负数据备份以及维稳责任。
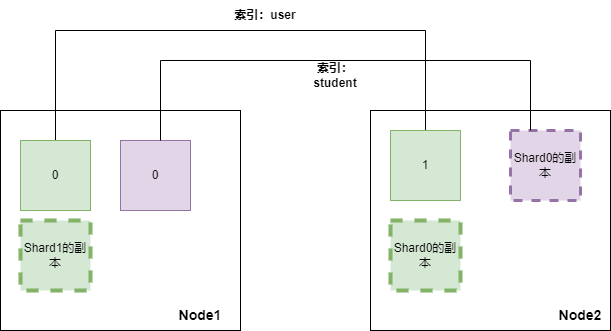
例如我们在2个节点的集群上创建一个名为user的索引和student索引,user索引设置2个分片1个副本,student索引设置1个分片1个副本;那么user索引的两个shard会各自得到一个副本,副本和shard的内容一致,且均匀的分布在两个节点上(Es会根据相应的策略来尽可能保证分片和相应的副本不在同一节点中,且保证每个节点的数据都是完整的)。这样如果当Node1节点崩坏,对于user索引的查询,会由节点2的 shard1和shard0的副本来承担,且shard1和shard0的副本的数据之和是一个完整user的数据(等同于shard0和shard1)。
Segment
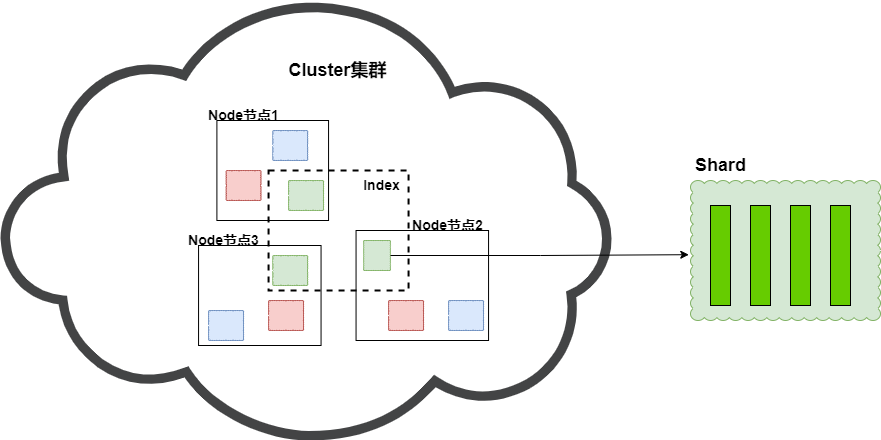
所以对于es来说,分片(shard )才是数据真正的载体,每一个Shard 本质上是一个Lucene的索引(Lucene Index)。
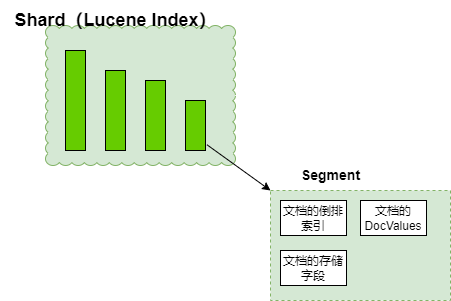
每个Lucene Index(Es的Shard) 是由多个Segment构成 ,Segement才是Lucene和Es查询性能的核心,Segment主要承载三部分内容:
-
Inverted Index
-
Stored Fields
-
Document Values
Inverted Index(倒排索引)
Segment中最重要的就是倒排索引,也是Es能够快速检索的根本,它是Segment基于存储的数据抽离出来的一个能够快速检索的数据结构,一个倒排索引的结构主要由一个有序的数据字典Dictionary(包括单词Term和它出现的频率)和 单词Term对应的Postings(文档的id或位置)组成:
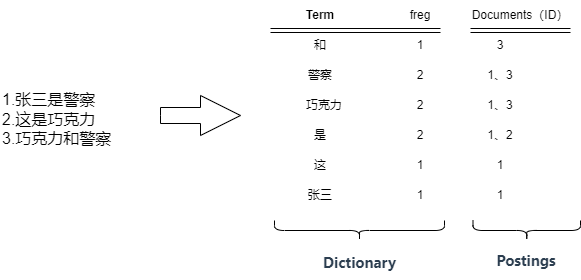
对于倒排索引,Es中是根据字段不同类型进行不同的策略:
-
Text 字段:
- 这些字段用于全文搜索。
- 它们会被分析(分词),并创建倒排索引。
- 可以包含多个词项,支持全文搜索和复杂查询。
-
Keyword 字段:
- 这些字段用于结构化搜索,如过滤、排序、聚合。
- 它们不会被分析,而是以整个字段的值存储。
- 每个不同的字段值都会在倒排索引中拥有一个独立的条目。
-
Numeric 字段(如 integer, float, double 等):
- 用于数值搜索,如范围查询或数值排序。
- 这些字段的值通常不会被倒排索引,除非明确设置为可搜索。
-
Date 字段:
- 用于日期和时间的搜索。
- 类似于数值字段,它们的值通常不会被倒排索引,除非明确设置为可搜索。
-
Boolean 字段 和 Binary 字段:
- 用于存储布尔值或二进制数据。
- 通常不会被倒排索引
构建倒排索引主要根据文档字段的类型主要为text,构建倒排索引的过程是:
- 文档分析:提取文档中的文本内容,通常包括标题和上下文。
- 词项提取:从文本中提取单词或词组(分词器)。
- 词项标准化:对提取的词项进行标准化处理,比如转小写、去除标点符号、去除停用词等(分词器)。
- 词项索引:为每个词项分配一个唯一的词项ID。
- 构建倒排表:为每个词项创建倒排表,记录词项在文档中的位置和频率。
在Elasticsearch中,每个字段的倒排索引是独立的,这意味着对于每个字段,Elasticsearch都会维护一个单独的倒排表,该倒排表包含了该字段中词项的文档映射信息。
Stored Fields(存储字段)
在索引文档时,Es是会保存原始内容的,原始文档内容在Es中表现为JSON, 而使用Es时,多是基于一个JSON中的某几个字段进行检索,大部分情况是不需要原始JSON内容的,但是若无特殊指定,Es每次检索是需要把完整的JSON在查询结果中通过_source进行携带:
{
"_index": "ariticle",
"_type": "_doc",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": { //不进行查询指定,默认所有字段通过_source返回
"user": "张三",
"title": "这是一个示例文章",
"context": "这是文章中的上下文以及具体的文章内容XXX"
}
}大批量的字段返回,除造成了额外的网络传输消耗外,在Es内部,也需要对整个文档进行序列化,造成资源浪费。
Stored Fields(存储字段)是一种特殊的字段类型,可以在文档中指定多个字段并将字段的原始内容进行额外存储,形成一个和_source平级的内容,检索时不需要序列化整个文档,直接读取额外的存储空间内容即可。
使用方法是在设计索引mapping 时通过store属性进行字段指定。
使用 store Fields后,可将指定的字段额外被Segment存储一份,检索时直接读取
//在索引创建时就固定常用哪些字段
{
"ariticle": {
"aliases": {
},
"mappings": {
"_doc": {
"properties": {
"title": { //默认没有store属性,默认值就是false
"type": "text",
},
"context": { //默认没有store属性,默认值就是false
"type": "text"
},
"user": { //明确指定store属性为true
"type": "keyword",
"store": true
}
}
}
}
}
//同样的查询
{
"query": {
"match_all": {}
},
"from":0,
"size":10
}
//返回结果
{
"_index": "ariticle",
"_type": "_doc",
"_id": "1",
"_version": 1,
"found": true,
"fields": { //此时多了名称为fields的字段,并且没有了_source
"user": [ //user的stroe属性设置为true,因此显示在结果中
"张三"
]
}
}事实上不论设不设置store属性为true,Elasticsearch都是会把原始文档进行存储的,当store为false时(默认配置),这些field只存储在"_source" field中,我们进行检索时,通过DSL来控制_source中返回的字段原文内容;但是当使用了store Fields时,会对相应字段的内容多存储一份,检索时针对使用了store Fields的字段,不需要序列化整个文档,相比通过指定返回字段查询效率会快很多,代价就是需要额外的存储一份内容,且内容在定义时就固定,不如在DSL中使用 _source 指定内容灵活。
Document Values
Document Values主要用于 排序、聚合、脚本索引中,Document Values对数据内容进行列式存储,便于快速进行 sort、aggs操作;
这里Docvalus是相当于倒排索引的正排索引,它作用于除Text类型之外的类型字段,倒排索引的优势 在于查找包含某个项的文档,而对于从另外一个方向的相反操作并不高效,即:确定哪些项是否存在单个文档里。这种场景下,就需要类似Mysql那种列式存储,构建一个正排索引
Doc Terms
-----------------------------------------------------------------
Doc_1 | brown, dog, fox, jumped, lazy, over, quick, the
Doc_2 | brown, dogs, foxes, in, lazy, leap, over, quick, summer
Doc_3 | dog, dogs, fox, jumped, over, quick, the
-----------------------------------------------------------------DocValues是在索引时与倒排索引同时生成的,并且是不可变的,需要持久化到磁盘中 。Doc values 是不支持对需要分词的字段进行列存储的(例如text),然而,这些字段仍然可以使用聚合,是因为使用了fielddata 的数据结构。与 doc values 不同,fielddata 构建和管理 100% 在内存中,常驻于 JVM 内存堆。
Fielddata默认是不启用的,因为text字段比较长,一般只做关键字分词和搜索,很少拿它来进行全文匹配和聚合还有排序,因为大多数这种情况是无意义的,一旦启用将会把text都加载到内存中,那将带来很大的内存压力,导致出现内存熔断现象(circuit breaker)。
它通过内部检查(字段的类型、基数、大小等等)来估算一个查询需要的内存。它然后检查要求加载的 fielddata 是否会导致 fielddata 的总量超过堆的配置比例。如果估算查询大小超出限制,就会触发熔断,查询会被中止并返回异常。
fielddata的内存配置在elasticsearch.yml中
cssindices.breaker.fielddata.limit fielddata级别限制,默认为堆的60% indices.breaker.request.limit request级别请求限制,默认为堆的40% indices.breaker.total.limit 保证上面两者组合起来的限制,默认堆的70%
Es的缓存
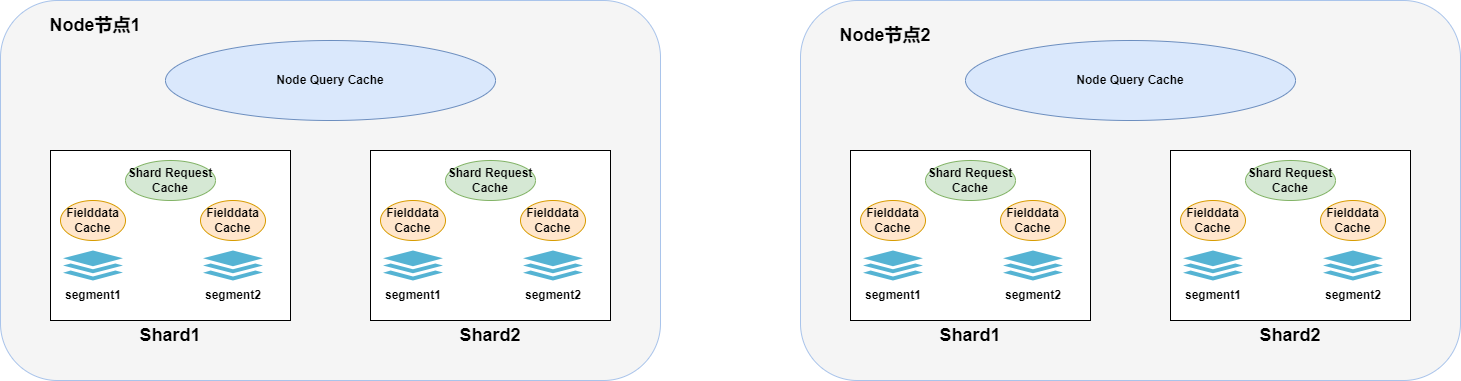
ElasticSearch在查询时涉及其自身JVM的缓存一共分为三类:
-
Node Query Cache:
- 节点级别的缓存,被所有分片共享。
- 主要用于缓存过滤器的执行结果,通常是压缩过的bitset,对应满足查询条件的文档ID列表。使用term精确查询某个值时或者bool配合filter查询时会触发
- Node Query Cache 会在底层的段(segment)发生变更时自动使缓存失效,以确保查询结果的准确性
- 通过elasticsearch.yml配置来控制:
indices.queries.cache.size: 控制查询缓存的内存大小,默认为节点堆内存的10%。indices.queries.cache.count: 控制缓存的总数量,默认值通常是10000。
-
Shard Request Cache :
- 分片级别的缓存。
- 多使用于聚合(aggs)时,只会缓存DSL查询中参数
size=0的请求,以完整DSL为缓存键,不会缓存hits,但会缓存hits.total以及聚合信息。 - 缓存的生命周期是一个
refresh_interval,即在默认情况下每1秒钟失效一次。 - 通过elasticsearch.yml配置来控制:
index.requests.cache.enable: 控制是否启用分片级别的缓存,默认为true。indices.requests.cache.size: 控制请求缓存在JVM堆中的百分比,默认为1%。indices.requests.cache.expire: 配置缓存过期时间,单位为分钟。
-
Fielddata Cache :
- 分段级别的缓存。
- 用于存储已分析字段(analyzed fields)的字段数据,如果该字段是
text类型或者没有为该字段设置doc_values,对于该字段聚合、排序或者脚本访问时会缓存。 - 一旦触发
Fielddata加载到内存中,它会保留在那里,直到相关段被删除或更新。 - 通过es配置文件指定:
indices.fielddata.cache.size: 控制字段数据缓存的大小,默认不限制。indices.breaker.fielddata.limit: 设置 Fielddata 断路器限制大小,默认为60%的JVM堆内存。
以上为查询时常用的缓存,多为Es本身JVM的内存进行划分和使用,另外Es在写入时还会使用一定的SystemCache,如Recycler Cache 、Warmer Cache等。
ElasticSearch的文档索引过程
集群视角索引文档
一次新增文档(索引文档),在集群视角的流程:
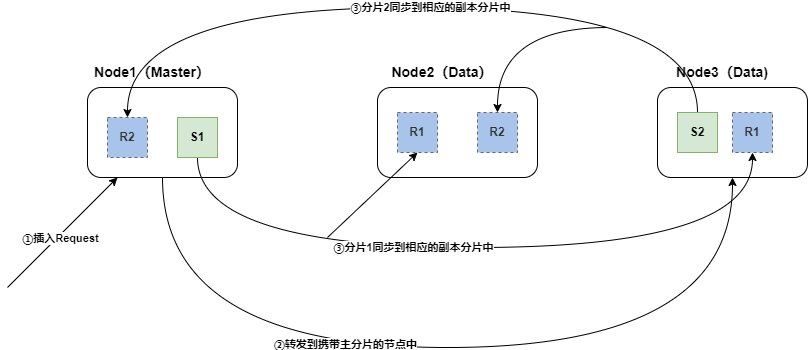
- 客户端向Es服务(集群)发送新增数据请求,请求首先到达Master节点
- Master节点为每个节点创建一个批量请求,并将这些请求并行转发到每个包含主分片的节点上。
- 每个节点上的主分片接收到插入请求,主分片进行数据索引并行转发新文档(或删除)到相应的副本分片(跨节点)。 一旦所有的副本分片报告所有操作成功,该节点将向Master节点报告成功,协调节点将这些响应收集整理并返回给客户端。
分片内部索引时具体在做什么
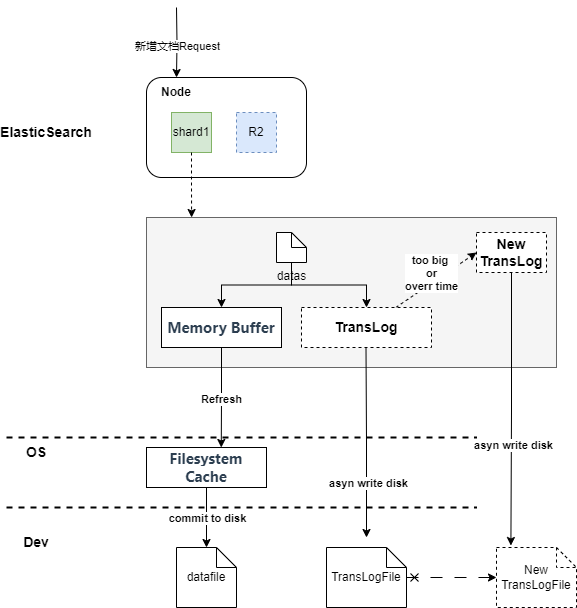
- 当分片所在的节点接收到数据新增请求后,在分片内部,首先会将数据请求写入到Memory Buffer ,然后定时(默认是每隔1秒,可在索引中设置)写入到Filesystem Cache (系统缓存),从Momery Buffer 到Filesystem Cache 的过程就是常说的refresh;这也是为什么对于Es的内存配置时不要过大,要预留给操作系统足够的内存空间的原因,因为这里十分依赖系统内存;
- 同时为保证数据的可靠性,防止数据在Momery Buffer 和Filesystem Cache 中丢失,Es额外追加了TransLog 机制,到达分片的新增请求,数据同时会异步写入 TransLog 一份(磁盘记录)。
- 当TransLog 增长过大(默认为512M)或到达配置的时间时(默认30分钟),FilesystemCache 中的内容被写入到磁盘中,然后旧的TransLog 将被删除并开始一个新的TransLog 。 这个过程被称作Flush
refresh过程中segment的活动
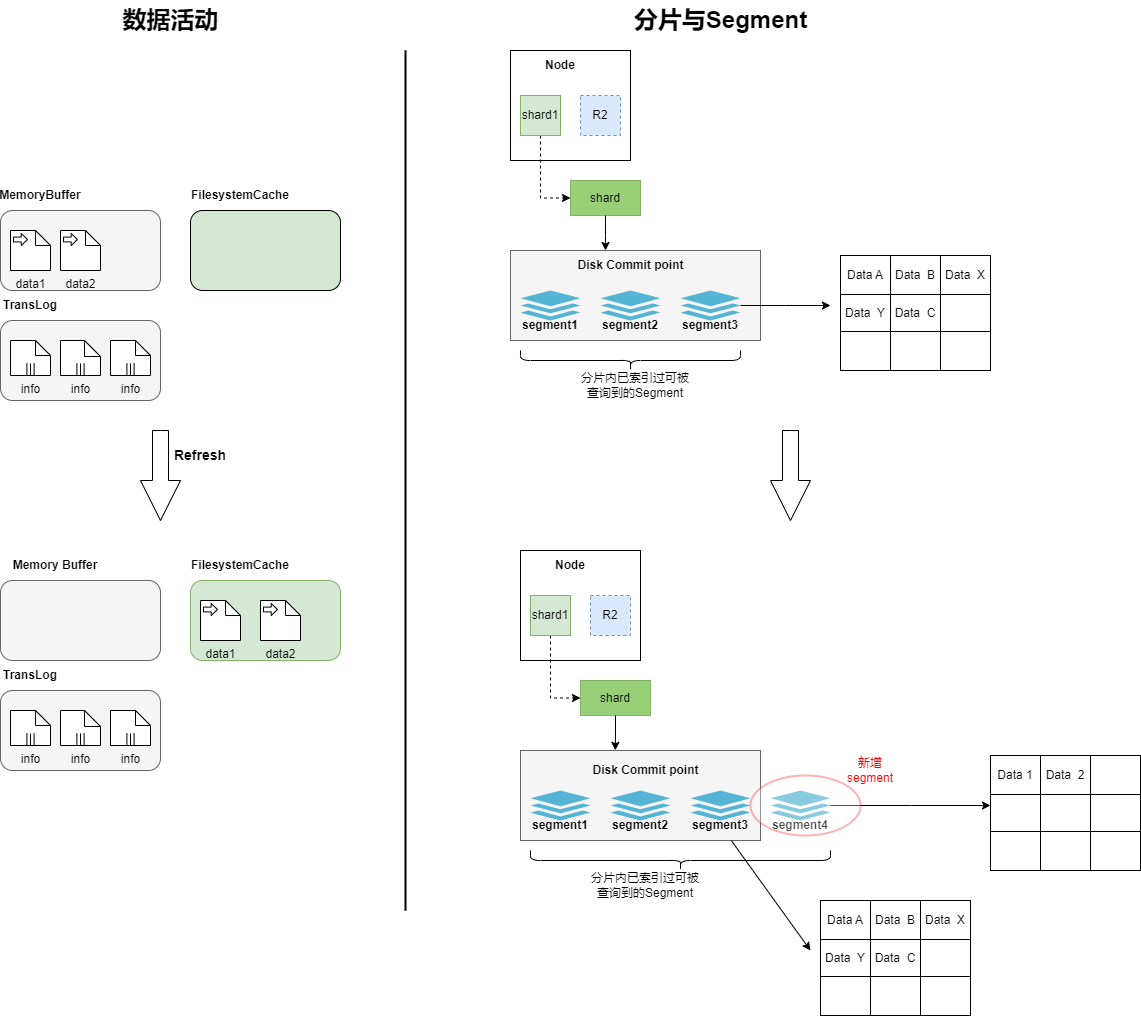
文档数据被写入后,首先进入到Memory Buffer 和TransLog 中,此时shard 中的Segment 还是之前已经稳定的数据,新写入的文档还没有形成Segment ,无法被Es查到。根据 index.refresh_interval 设置 的refresh (冲刷)间隔时间,数据开始进行refresh,Memory Buffer 中的文档被内容分析、分词,形成一个新的Segment ,然后Memory Buffer 开始清空,refresh后新生成的Segment是暂存在FilesystemCache 中的,所以从存储上看,新的文档从Memory Buffer 转移到了 Filesystem Cache,到此,新插入的文档数据才可以被Es查询到
flush过程中segment的活动
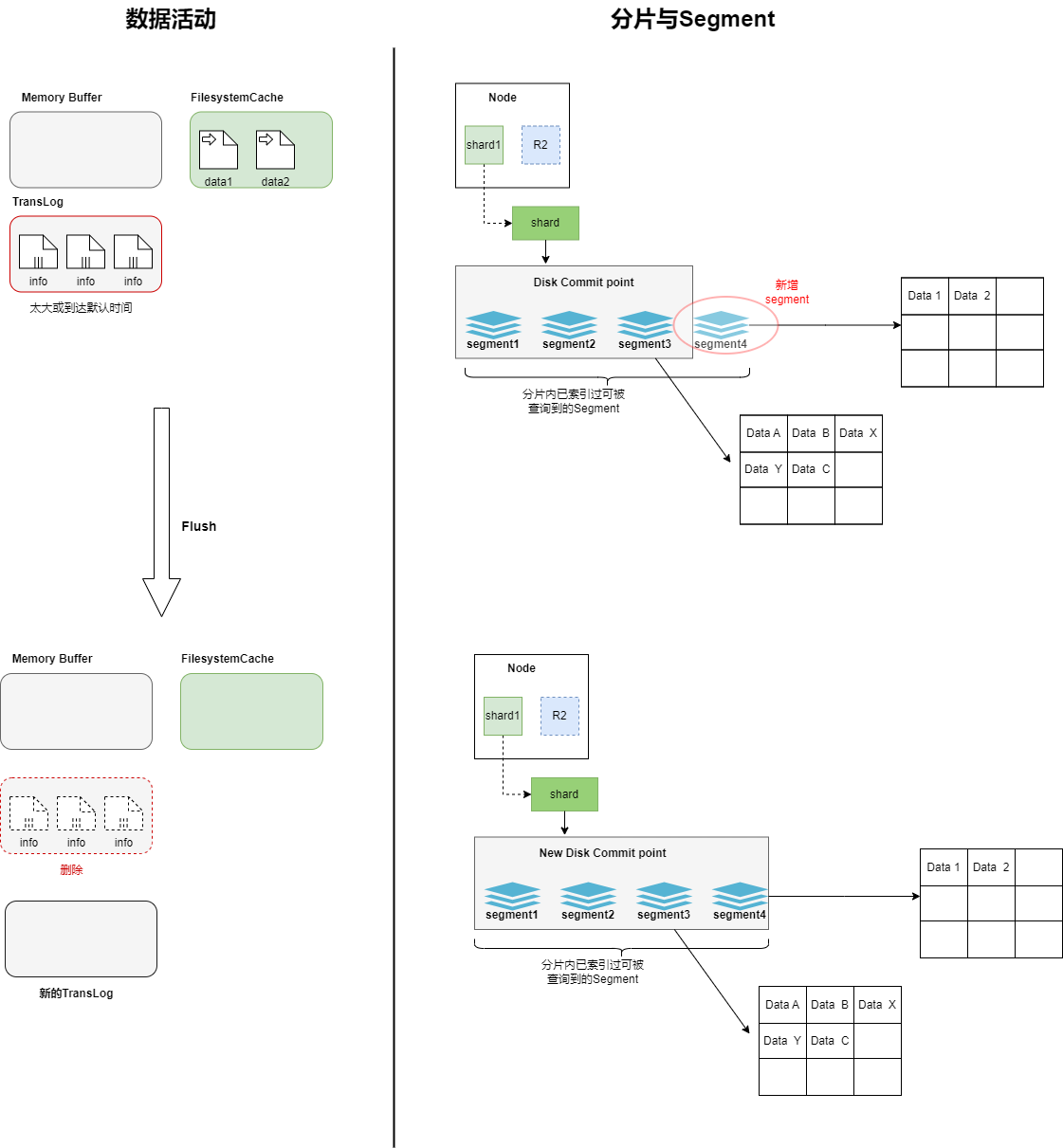
随着TransLog越来越大,会触发Flush过程,在这个过程中,FilesystemCache中的内容会被写入到磁盘中,段的fsync将创建一个new commit point,此时清空Filesystem Cache,然后删除TransLog,再生成一个新的TransLog,记录后续的内容
segement的 merge

由于refresh 流程每次都会创建一个新的段,refresh 的频繁会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。 每一个段都会消耗文件句柄、内存和cpu运行周期。而且每个搜索请求都必须轮流检查每个段,所以段越多,搜索也就越慢。于是Es在后他就需要不定期的合并Segment ,以减少Segment的数量。
合并进程选择一小部分大小相似的段,并且在后台将它们合并成为更大的段(过程中并不会中断索引和搜索)。合并后的新Segment 被Flush 到磁盘中,然后打开新的Segment的检索功能,同时删除磁盘上旧的Segment。
ElasticSearch的检索过程
elasticSearch中的检索一般分为两类,一类是Get查询 ,即通过_id查询具体的文档,一类是Search查询,即向Es发起DSL语句的查询。这里主要以Search查询为例
查询整体过程
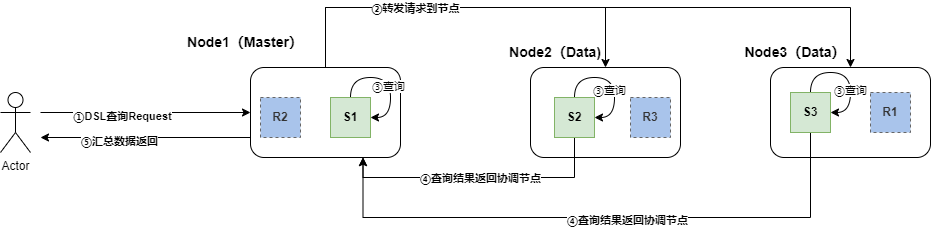
-
客户端向Es服务(集群)发送指定索引的查询请求,请求先到达主节点(协调节点)
-
协调节点根据集群部署,将请求转发到其他节点所对应的索引分片上(优先使用主节点)
- 此过程中Es内存机制会判定是否符合Node Cache的标准,进行Node Cache查询或缓存查询
-
各个节点上的分片在其内部进行数据检索,检索出符合条件的数据
-
此过程中会根据查询,判定是否符合Shard Cache标准,进行Cache查询或缓存内容
-
涉及聚合或分析字段的聚合操作,内部Segment会判定是否fielddata Cache标准,并启用该缓存
-
-
各分片将检索出的数据发回主节点,主节点进行汇总后返回给客户端
也就是说,Es是通过分片将同一索引的数据均匀的散布在集群中,每个分片依赖所处节点设备的硬件资源进行独立查询,通过网络传输,将结果返回。
查询时segment内部具体在做什么
说Segment 的查询之前补充一下上文Segment 的内容部分(注意,在Es或者Lucene中提及的Segment 是逻辑概念,不等价于磁盘上的段);Segment的组成部分和文档数据在磁盘上的对应关系:
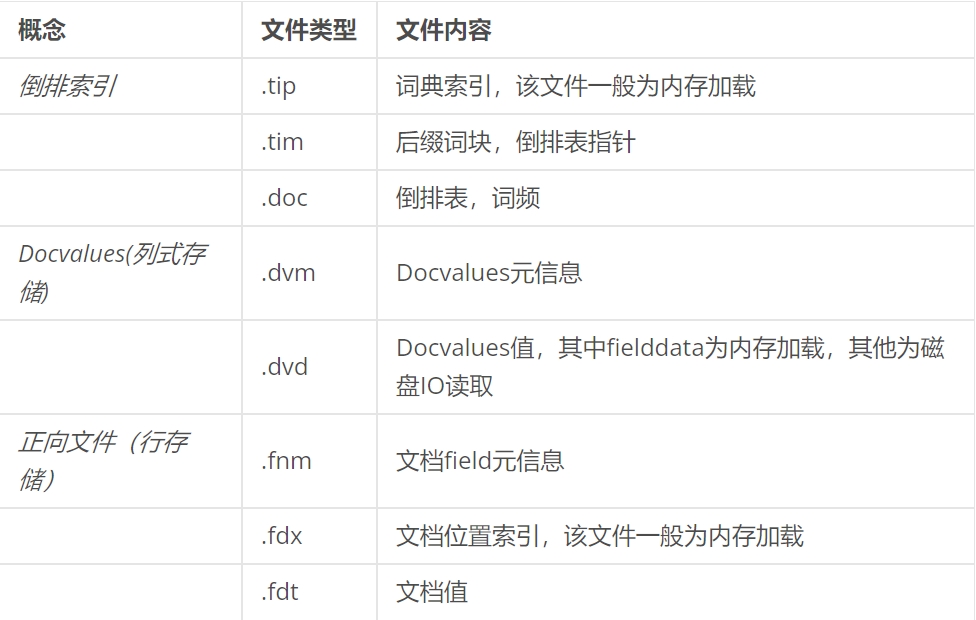
更多文档类型可以此处查看
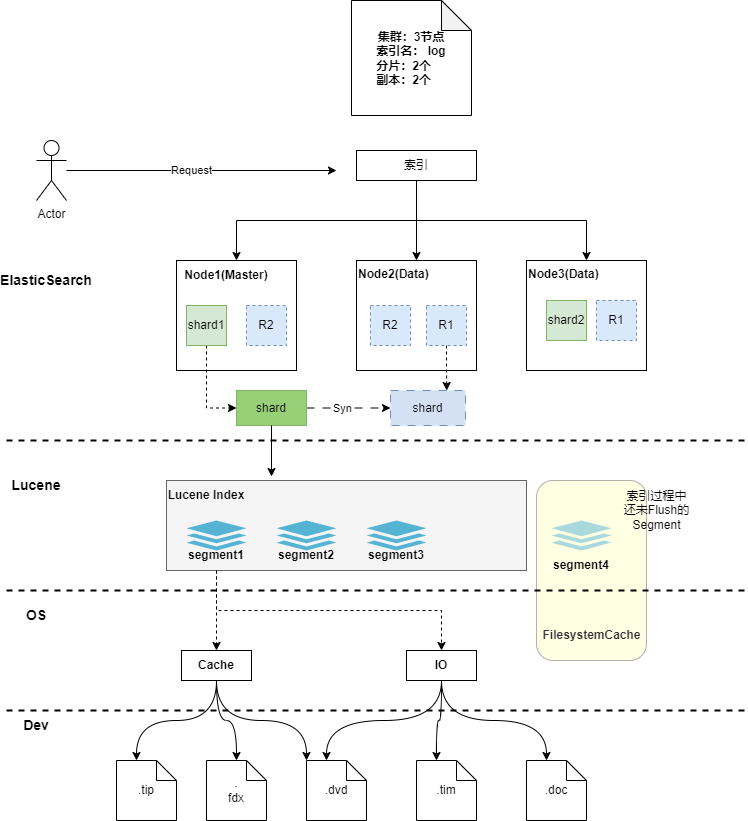
-
请求来的shard内部,解析出DSL,转译为Lucene的语法
-
通过 commit point记录分发到segments中,此时的segment分为两种,一种是经过flush和merge的,我称之为磁盘版segment(当然不那么准确);还有一种是处在索引过程中的,上文中存在于FilesystemCache中可被查询的,我称之为内存版segment。两者不同之处就在于,前者涉及磁盘IO读取部分数据来完成查询,后者不需要IO,直接内存进行查询
-
每个segment根据词法分析得出的词项,进行词典检索(词典的数据.tip文件一般加载在内存中,不需要磁盘IO,非常快),配合倒排表,快速找到相关文档(这个过程需要磁盘IO)
-
如果涉及数字类型的sum、max、min的聚合或者text的聚合操作,则segment会使用DocValues相关的文件,借助列式存储的优势快速运算;fielddata缓存机制也是在此时发挥作用。
-
segment完成检索后将内容返回到shard中(其他segment也是同理),由shard去进行合并、缓存等操作