总结最优的两种方法:
方法1:
使用了【MyBatis-plus】saveBatch 但是数据入库效率依旧很慢,那可能是是因为JDBC没有配置,saveBatch 批量写入并没有生效哦!!!
详细配置如下:批量数据入库:rewriteBatchedStatements=true
java
# 数据源
master:
driver-class-name: org.postgresql.Driver
url: jdbc:postgresql://127.0.0.1:5444/mxpt_business_databases?useUnicode=true&characterEncoding=utf8¤tSchema=public&stringtype=unspecified&rewriteBatchedStatements=true
username: postgres
password: postgres
schema: public方法2:
使用【MyBatis】进行数据的批量入库:拼接sql语句,每1000条数据入库一次。
java
@Override
public String insertBoundValueListToDatabase(List<ResourceCalcSceneBoundValue> list)
{
//1.先删除原有场次和工程的数据,再进行导入
ResourceCalcSceneBoundValue gongkuangValue = list.get(0);
Long scprodId = gongkuangValue.getScprodId();
Long gongkuangId = gongkuangValue.getBoundId();
List<ResourceCalcSceneBoundValue> listValue = resourceCalcSceneBoundValueMapper.selectResourceCalcSceneBoundValueList(gongkuangValue);
if(listValue != null && listValue.size() > 0){
resourceCalcSceneBoundValueMapper.deleteBoundValueByScprodIdAndBoundId(scprodId, gongkuangId);
}
//2.将结果插入到数据库中
if (list.size() > 0) {
//条数为1
if(list.size() == 1){
resourceCalcSceneBoundValueMapper.insertResourceCalcSceneBoundValueList(list.subList(0, 1));
}
//由于数据库对于插入字段的限制,在这里对批量插入的数据进行分批处理
int batchCount = 120;//每批commit的个数
int batchLastIndex = batchCount - 1;// 每批最后一个的下标
for (int index = 0; index < list.size() - 1; ) {
if (batchLastIndex > list.size() - 1) {
batchLastIndex = list.size() - 1;
resourceCalcSceneBoundValueMapper.insertResourceCalcSceneBoundValueList(list.subList(index, batchLastIndex + 1));
break;// 数据插入完毕,退出循环
} else {
resourceCalcSceneBoundValueMapper.insertResourceCalcSceneBoundValueList(list.subList(index, batchLastIndex + 1));
index = batchLastIndex + 1;// 设置下一批下标
batchLastIndex = index + (batchCount - 1);
}
}
return "边界过程数据入库成功! 条数为:"+list.size()+"条。 ";
}
return "数据条数为0。";
}xml代码:
java
<insert id="insertResourceCalcSceneBoundValueList" parameterType="java.util.List" useGeneratedKeys="false">
INSERT INTO resource_calc_scene_bound_value
(scprod_id, bound_id, tm, flow, water, kurong, inq, stcd, remark, jp, kaidu, kgnum)
VALUES
<foreach collection="list" item="item" index="index" separator=",">
(#{item.scprodId,jdbcType=INTEGER}
,#{item.boundId,jdbcType=INTEGER}
,#{item.tm,jdbcType=TIMESTAMP}
,#{item.flow,jdbcType=NUMERIC}
,#{item.water,jdbcType=NUMERIC}
,#{item.kurong,jdbcType=NUMERIC}
,#{item.inq,jdbcType=NUMERIC}
,#{item.stcd,jdbcType=VARCHAR}
,#{item.remark,jdbcType=VARCHAR}
,#{item.jp,jdbcType=NUMERIC}
,#{item.kaidu,jdbcType=NUMERIC}
,#{item.kgnum,jdbcType=INTEGER})
</foreach>
</insert>参考博客:
https://www.cnblogs.com/natee/p/17428877.html
大神总结的超级详细!!!
一起学习!!!
发现接口处理速度慢的有点超出预期,感觉很奇怪,后面定位发现是数据库批量保存这块很慢。
这个项目用的是 mybatis-plus,批量保存直接用的是 mybatis-plus 提供的 saveBatch。 我点进去看了下源码,感觉有点不太对劲:
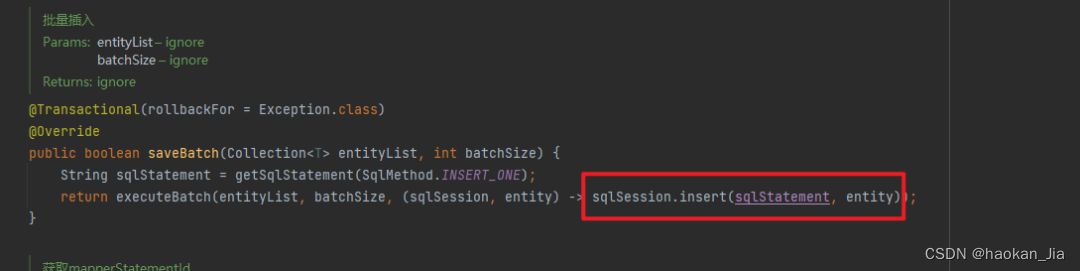
继续追踪了下,从这个代码来看,确实是 for 循环一条一条执行了 sqlSession.insert,下面的 consumer 执行的就是上面的 sqlSession.insert:
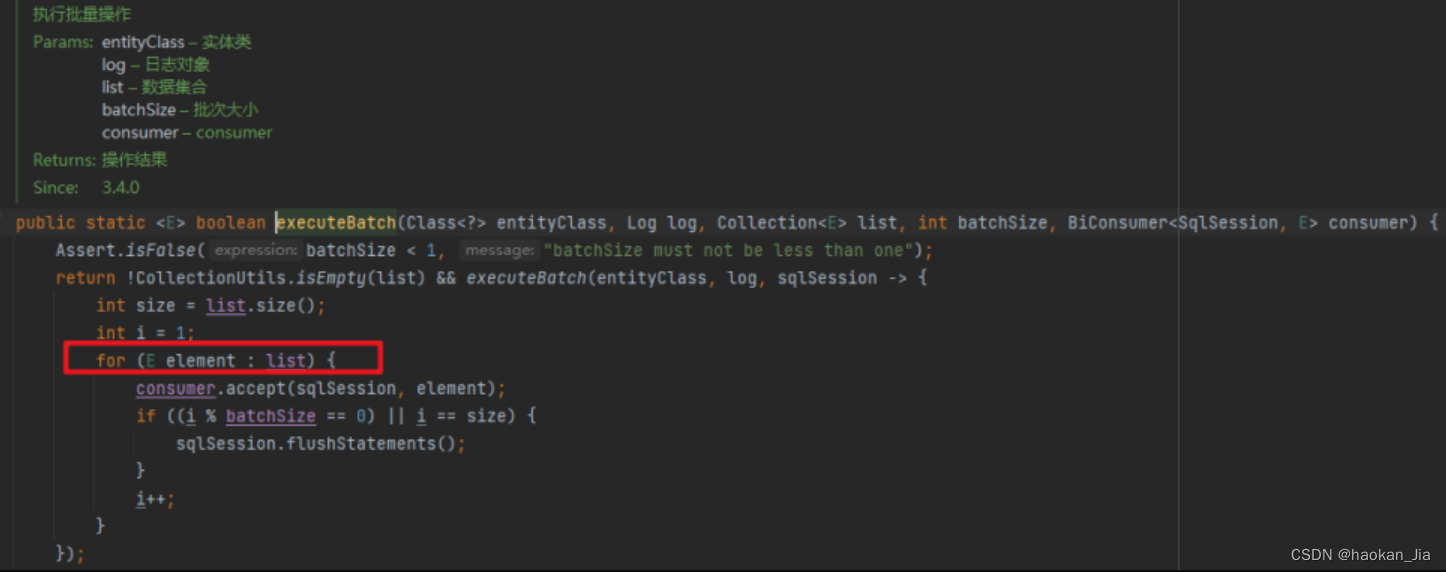
然后累计一定数量后,一批 flush。从这点来看,这个 saveBach 的性能肯定比直接一条一条 insert 快。
1、1000条数据,一条一条插入
java
@Test
void MybatisPlusSaveOne() {
SqlSession sqlSession = sqlSessionFactory.openSession();
try {
StopWatch stopWatch = new StopWatch();
stopWatch.start("mybatis plus save one");
for (int i = 0; i < 1000; i++) {
OpenTest openTest = new OpenTest();
openTest.setA("a" + i);
openTest.setB("b" + i);
openTest.setC("c" + i);
openTest.setD("d" + i);
openTest.setE("e" + i);
openTest.setF("f" + i);
openTest.setG("g" + i);
openTest.setH("h" + i);
openTest.setI("i" + i);
openTest.setJ("j" + i);
openTest.setK("k" + i);
//一条一条插入
openTestService.save(openTest);
}
sqlSession.commit();
stopWatch.stop();
log.info("mybatis plus save one:" + stopWatch.getTotalTimeMillis());
} finally {
sqlSession.close();
}
}
可以看到,执行一批 1000 条数的批量保存,耗费的时间是 121011 毫秒。
2、1000条数据用 mybatis-plus 自带的 saveBatch 插入
java
@Test
void MybatisPlusSaveBatch() {
SqlSession sqlSession = sqlSessionFactory.openSession();
try {
List<OpenTest> openTestList = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
OpenTest openTest = new OpenTest();
openTest.setA("a" + i);
openTest.setB("b" + i);
openTest.setC("c" + i);
openTest.setD("d" + i);
openTest.setE("e" + i);
openTest.setF("f" + i);
openTest.setG("g" + i);
openTest.setH("h" + i);
openTest.setI("i" + i);
openTest.setJ("j" + i);
openTest.setK("k" + i);
openTestList.add(openTest);
}
StopWatch stopWatch = new StopWatch();
stopWatch.start("mybatis plus save batch");
//批量插入
openTestService.saveBatch(openTestList);
sqlSession.commit();
stopWatch.stop();
log.info("mybatis plus save batch:" + stopWatch.getTotalTimeMillis());
} finally {
sqlSession.close();
}
}
耗费的时间是 59927 毫秒,比一条一条插入快了一倍,从这点来看,效率还是可以的。
然后常见的还有一种利用拼接 SQL 方式来实现批量插入,我们也来对比试试看性能如何。
3、1000 条数据用手动拼接 SQL 方式插入, 搞个手动拼接:

来跑跑下性能如何:
java
@Test
void MapperSaveBatch() {
SqlSession sqlSession = sqlSessionFactory.openSession();
try {
List<OpenTest> openTestList = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
OpenTest openTest = new OpenTest();
openTest.setA("a" + i);
openTest.setB("b" + i);
openTest.setC("c" + i);
openTest.setD("d" + i);
openTest.setE("e" + i);
openTest.setF("f" + i);
openTest.setG("g" + i);
openTest.setH("h" + i);
openTest.setI("i" + i);
openTest.setJ("j" + i);
openTest.setK("k" + i);
openTestList.add(openTest);
}
StopWatch stopWatch = new StopWatch();
stopWatch.start("mapper save batch");
//手动拼接批量插入
openTestMapper.saveBatch(openTestList);
sqlSession.commit();
stopWatch.stop();
log.info("mapper save batch:" + stopWatch.getTotalTimeMillis());
} finally {
sqlSession.close();
}
}
耗时只有 2275 毫秒,性能比 mybatis-plus 自带的 saveBatch 好了 26 倍!
这时,我又突然回想起以前直接用 JDBC 批量保存的接口,那都到这份上了,顺带也跑跑看!
4、1000 条数据用 JDBC executeBatch 插入
java
@Test
void JDBCSaveBatch() throws SQLException {
SqlSession sqlSession = sqlSessionFactory.openSession();
Connection connection = sqlSession.getConnection();
connection.setAutoCommit(false);
String sql = "insert into open_test(a,b,c,d,e,f,g,h,i,j,k) values(?,?,?,?,?,?,?,?,?,?,?)";
PreparedStatement statement = connection.prepareStatement(sql);
try {
for (int i = 0; i < 1000; i++) {
statement.setString(1,"a" + i);
statement.setString(2,"b" + i);
statement.setString(3, "c" + i);
statement.setString(4,"d" + i);
statement.setString(5,"e" + i);
statement.setString(6,"f" + i);
statement.setString(7,"g" + i);
statement.setString(8,"h" + i);
statement.setString(9,"i" + i);
statement.setString(10,"j" + i);
statement.setString(11,"k" + i);
statement.addBatch();
}
StopWatch stopWatch = new StopWatch();
stopWatch.start("JDBC save batch");
statement.executeBatch();
connection.commit();
stopWatch.stop();
log.info("JDBC save batch:" + stopWatch.getTotalTimeMillis());
} finally {
statement.close();
sqlSession.close();
}
}
耗时是 55663 毫秒,所以 JDBC executeBatch 的性能跟 mybatis-plus 的 saveBatch 一样(底层一样)。
综上所述,拼接 SQL 的方式实现批量保存效率最佳。
但是我又不太甘心,总感觉应该有什么别的法子,然后我就继续跟着 mybatis-plus 的源码 debug 了一下,跟到了 MySQL 的驱动,突然发现有个 if 里面的条件有点显眼: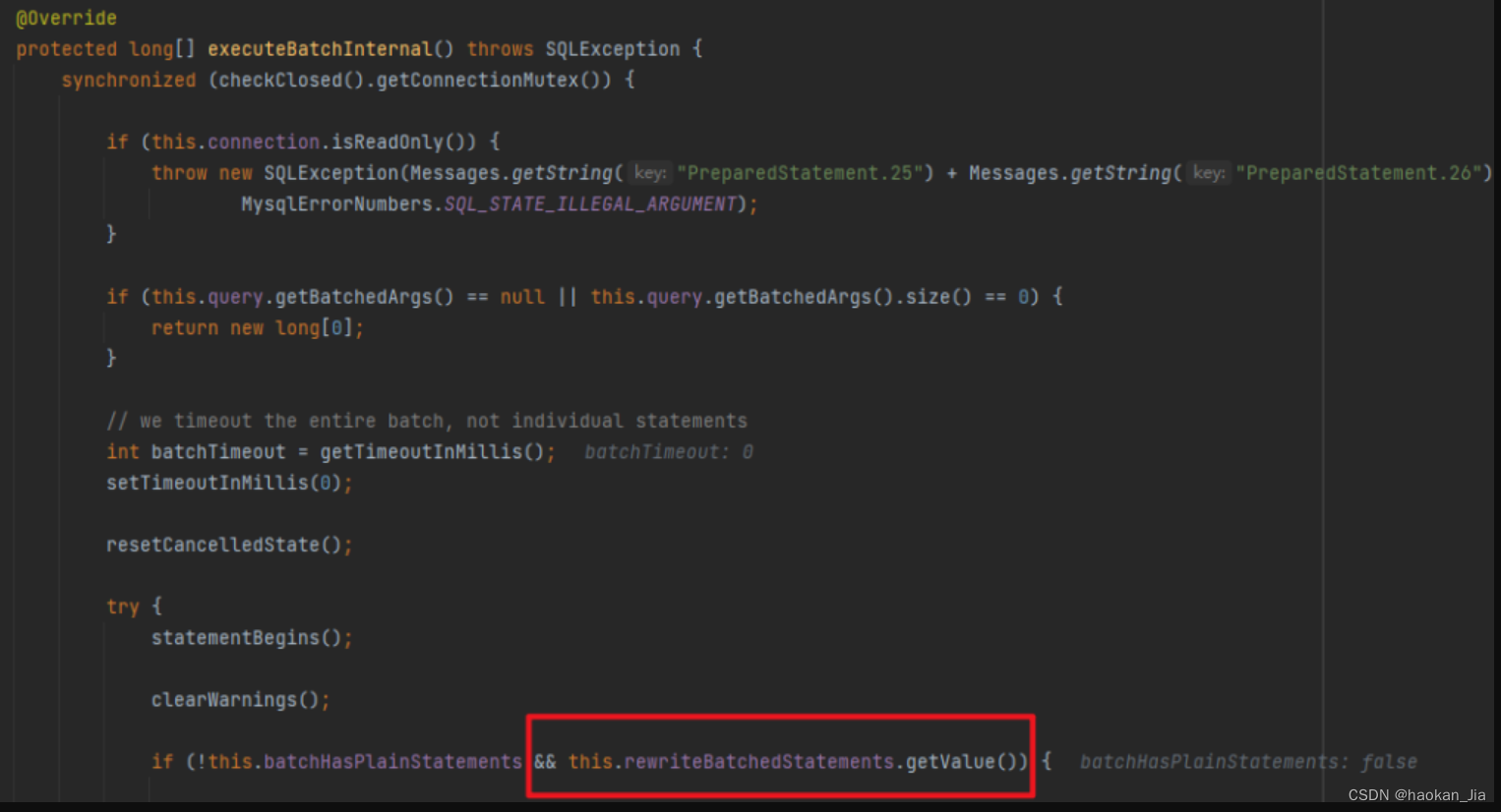
就是这个叫 rewriteBatchedStatements 的玩意,从名字来看是要重写批操作的 Statement,前面batchHasPlainStatements 已经是 false,取反肯定是 true,所以只要这参数是 true 就会进行一波操作。
我看了下默认是 false。
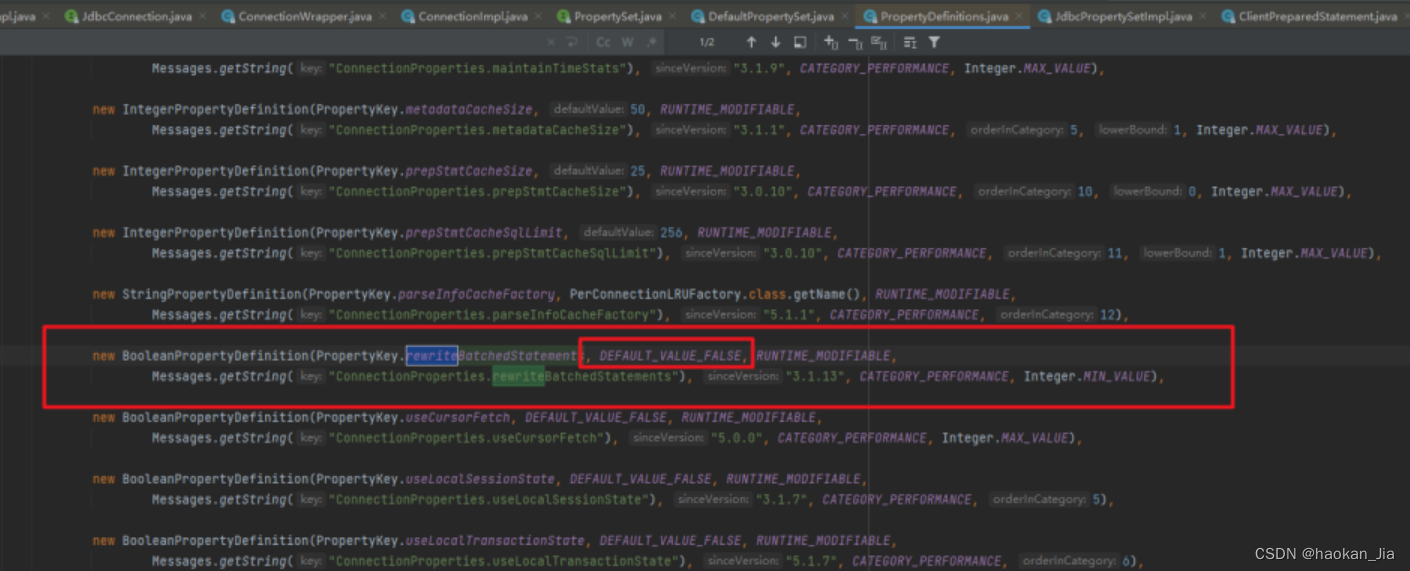
直接将 jdbcurl 加上了这个参数:

然后继续跑了下 mybatis-plus 自带的 saveBatch,果然性能大大提高,跟拼接 SQL 差不多!

然后我继续 debug ,来探探 rewriteBatchedStatements 究竟是怎么 rewrite 的! 如果这个参数是 true,则会执行下面的方法且直接返回:

看下 executeBatchedInserts 究竟干了什么:

看到上面我圈出来的代码没,好像已经有点感觉了,继续往下 debug。
果然!SQL 语句被 rewrite了:
对插入而言,所谓的 rewrite 其实就是将一批插入拼接成 insert into xxx values (a),(b),©...这样一条语句的形式然后执行,这样一来跟拼接 SQL 的效果是一样的。
那为什么默认不给这个参数设置为 true 呢?主要有以下两点:
如果批量语句中的某些语句失败,则默认重写会导致所有语句都失败。
批量语句的某些语句参数不一样,则默认重写会使得查询缓存未命中。
看起来影响不大,所以我给我的项目设置上了这个参数!
最后
稍微总结下我粗略的对比(虽然粗略,但实验结果符合原理层面的理解),如果你想更准确地做实验,可以使用 JMH,并且测试更多组数(如 5000,10000等)的情况。
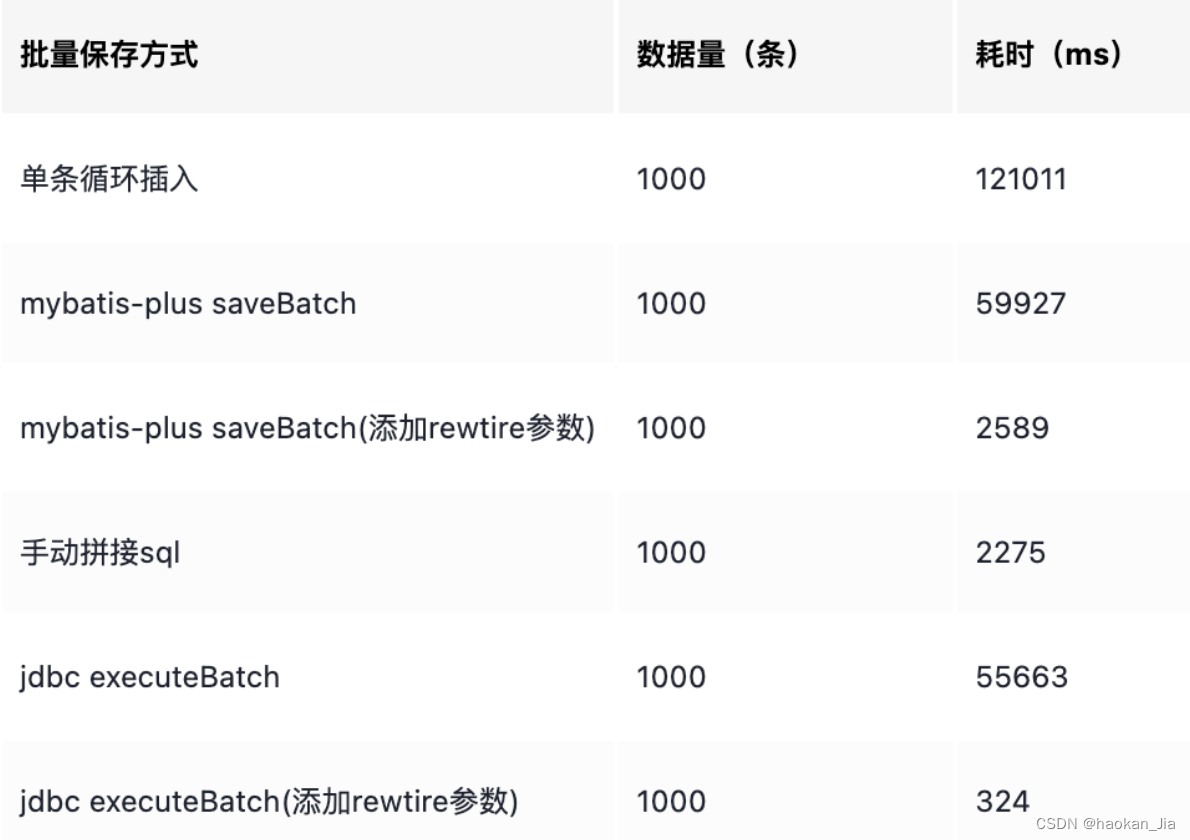
所以如果有使用 JDBC 的 Batch 性能方面的需求,要将 rewriteBatchedStatements 设置为 true,这样能提高很多性能。
然后如果喜欢手动拼接 SQL 要注意一次拼接的数量,分批处理。