1、文本 PDF 的解析
1.1、文本的提取
进行文本提取的 Python 库包括:pdfminer.six、PyMuPDF、PyPDF2 和 pdfplumber,效果最好的是 PyMuPDF,PyMuPDF 在进行文本提取时能够最大限度地保留 PDF 的阅读顺序,这对于双栏 PDF 文件的抽取非常有用。下面就以难度比较大的双栏 PDF 为例,来介绍使用 PyMuPDF 库进行文字抽取的效果。
我们以下面的 PDF 为例来看使用 PyMuPDF 进行文字提取的效果。

进行文本提取的代码如下:
csharp
import pymupdf
pages = pymupdf.open("./test_data/2022110404_pdf.pdf")
text = pages[0].get_text()
print(text)打印的结果如下:
csharp
局进行了首次 HTV-2 飞行试验,试验未取得成功,但验证了助推火箭与高超声速飞行器分离
的技术,为未来发展奠定了基础。美国国防高级研究计划局计划于 2011 年进行 HTV_2 的第
二次飞行试验。目前,美国还在开展 HCV 缩比技术验证机 HTV-3 的设计,以及 HCV 推进方案
的选型工作。
HTV-2 超高速飞行器
(2)"常规打击导弹"计划
"常规打击导弹"计划是美国空军正在研制的另外一种快速全球打击武器,以"猎鹰"
计划的"高超声速技术验证机"为基础进行研制。它也是一种无动力的高超声速滑翔飞行器,
在大气层内滑翔时间约 800 秒(后续型号将达到 3000 秒),最大飞行距离 11000 千米,可以
投送包括"小直径炸弹"、"联合直接攻击弹药"、情报/监视/侦察/毁伤评估无人机等多
种有效载荷。目前,"常规打击导弹"的研制已进入第二阶段,将开展载荷投送飞行器的实
际设计、研制和飞行试验。美空军计划在 2012 年初进行"常规打击导弹"投送载荷飞行器
的飞行试验,2017-2020 年在本土部署首个"常规打击导弹"系统。1.2、表格的提取
表格提取效果比较好的库有 camelot 和 tabula ,表格又可以分为有线表和少线表。下面就分别以有线表和少线表为例来介绍 camelot 和 tabula 的使用。
我们以下面的 PDF 为例来看使用 camelot 和 tabula 进行有线表格提取的效果。
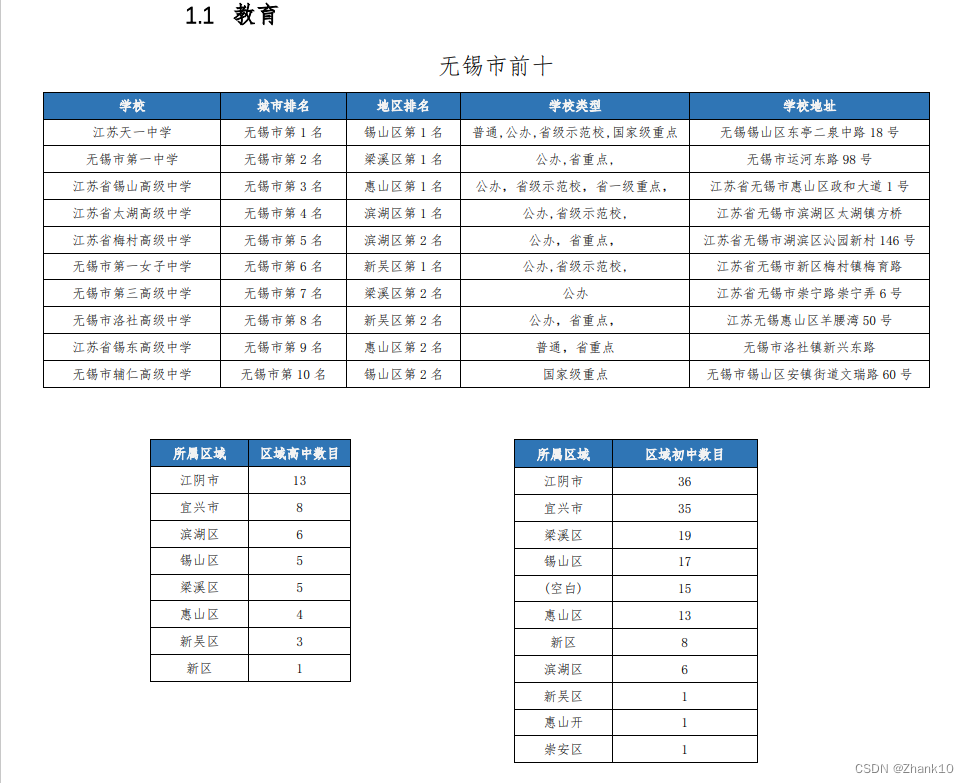
使用 camelot 进行表格提取的代码如下:
csharp
import camelot
tables = camelot.read_pdf('data.pdf')
print(tables[0].df)输出结果如下:
csharp
0 学校 城市排名 地区排名 学校类型 学校地址
1 江苏天一中学 无锡市第 1 名 锡山区第 1 名 普通,公办,省级示范校,国家级重点 无锡锡山区东亭二泉中路 18 号
2 无锡市第一中学 无锡市第 2 名 梁溪区第 1 名 公办,省重点, 无锡市运河东路 98 号
3 江苏省锡山高级中学 无锡市第 3 名 惠山区第 1 名 公办,省级示范校,省一级重点, 江苏省无锡市惠山区政和大道 1 号
4 江苏省太湖高级中学 无锡市第 4 名 滨湖区第 1 名 公办,省级示范校, 江苏省无锡市滨湖区太湖镇方桥
5 江苏省梅村高级中学 无锡市第 5 名 滨湖区第 2 名 公办,省重点, 江苏省无锡市湖滨区沁园新村 146 号
6 无锡市第一女子中学 无锡市第 6 名 新吴区第 1 名 公办,省级示范校, 江苏省无锡市新区梅村镇梅育路
7 无锡市第三高级中学 无锡市第 7 名 梁溪区第 2 名 公办 江苏省无锡市崇宁路崇宁弄 6 号
8 无锡市洛社高级中学 无锡市第 8 名 新吴区第 2 名 公办,省重点, 江苏无锡惠山区羊腰湾 50 号
9 江苏省锡东高级中学 无锡市第 9 名 惠山区第 2 名 普通,省重点 无锡市洛社镇新兴东路
10 无锡市辅仁高级中学 无锡市第 10 名 锡山区第 2 名 国家级重点 无锡市锡山区安镇街道文瑞路 60 号使用 tabula 进行表格提取的代码如下:
csharp
import tabula
dfs = tabula.read_pdf("data.pdf")
print(dfs[0])输出结果如下:
csharp
0 学校 城市排名 地区排名 学校类型 学校地址
1 江苏天一中学 无锡市第 1 名 锡山区第 1 名 普通,公办,省级示范校,国家级重点 无锡锡山区东亭二泉中路 18 号
2 无锡市第一中学 无锡市第 2 名 梁溪区第 1 名 公办,省重点, 无锡市运河东路 98 号
3 江苏省锡山高级中学 无锡市第 3 名 惠山区第 1 名 公办,省级示范校,省一级重点, 江苏省无锡市惠山区政和大道 1 号
4 江苏省太湖高级中学 无锡市第 4 名 滨湖区第 1 名 公办,省级示范校, 江苏省无锡市滨湖区太湖镇方桥
5 江苏省梅村高级中学 无锡市第 5 名 滨湖区第 2 名 公办,省重点, 江苏省无锡市湖滨区沁园新村 146 号
6 无锡市第一女子中学 无锡市第 6 名 新吴区第 1 名 公办,省级示范校, 江苏省无锡市新区梅村镇梅育路
7 无锡市第三高级中学 无锡市第 7 名 梁溪区第 2 名 公办 江苏省无锡市崇宁路崇宁弄 6 号
8 无锡市洛社高级中学 无锡市第 8 名 新吴区第 2 名 公办,省重点, 江苏无锡惠山区羊腰湾 50 号
9 江苏省锡东高级中学 无锡市第 9 名 惠山区第 2 名 普通,省重点 无锡市洛社镇新兴东路
10 无锡市辅仁高级中学 无锡市第 10 名 锡山区第 2 名 国家级重点 无锡市锡山区安镇街道文瑞路 60 号从结果可以看出,在提取有线表时,不管是 camelot 还是 tabula 都能很好地进行提取,而且不需要过多的参数设置。
1.3、扫描 PDF 的解析
1.3.1、文本的提取
在从扫描的 PDF 文件中提取文本时,使用开源的 PaddleOCR,并且用 PPStructure 做版面的分析。我们还是以下面的 PDF 文件为例,不过这是的 PDF 文件是扫描 PDF。

提取文本的代码如下:
csharp
import os
import cv2
from paddleocr import PPStructure, draw_structure_result, save_structure_res
from PIL import Image
img_path = "./bert-1.png"
table_engine = PPStructure(show_log=True)
save_folder = './output'
img = cv2.imread(img_path)
result = table_engine(img)
save_structure_res(result, save_folder, os.path.basename(img_path).split('.')[0])
font_path = './fonts/simfang.ttf'
image = Image.open(img_path).convert('RGB')
im_show = draw_structure_result(image, result, font_path=font_path)
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')提取结果如下:

图中的左边是根据给出的版面分析结果画出来的,可以看出对双栏 PDF 做了正确的解析。右边是根据识别出来的文本以及文本的坐标画出来的,可以看出基本上和左边的版面以及内容是一致的。
1.3.1、表格的提取
我们还是以下面的 PDF 文件为例,不过这是的 PDF 文件是扫描 PDF。
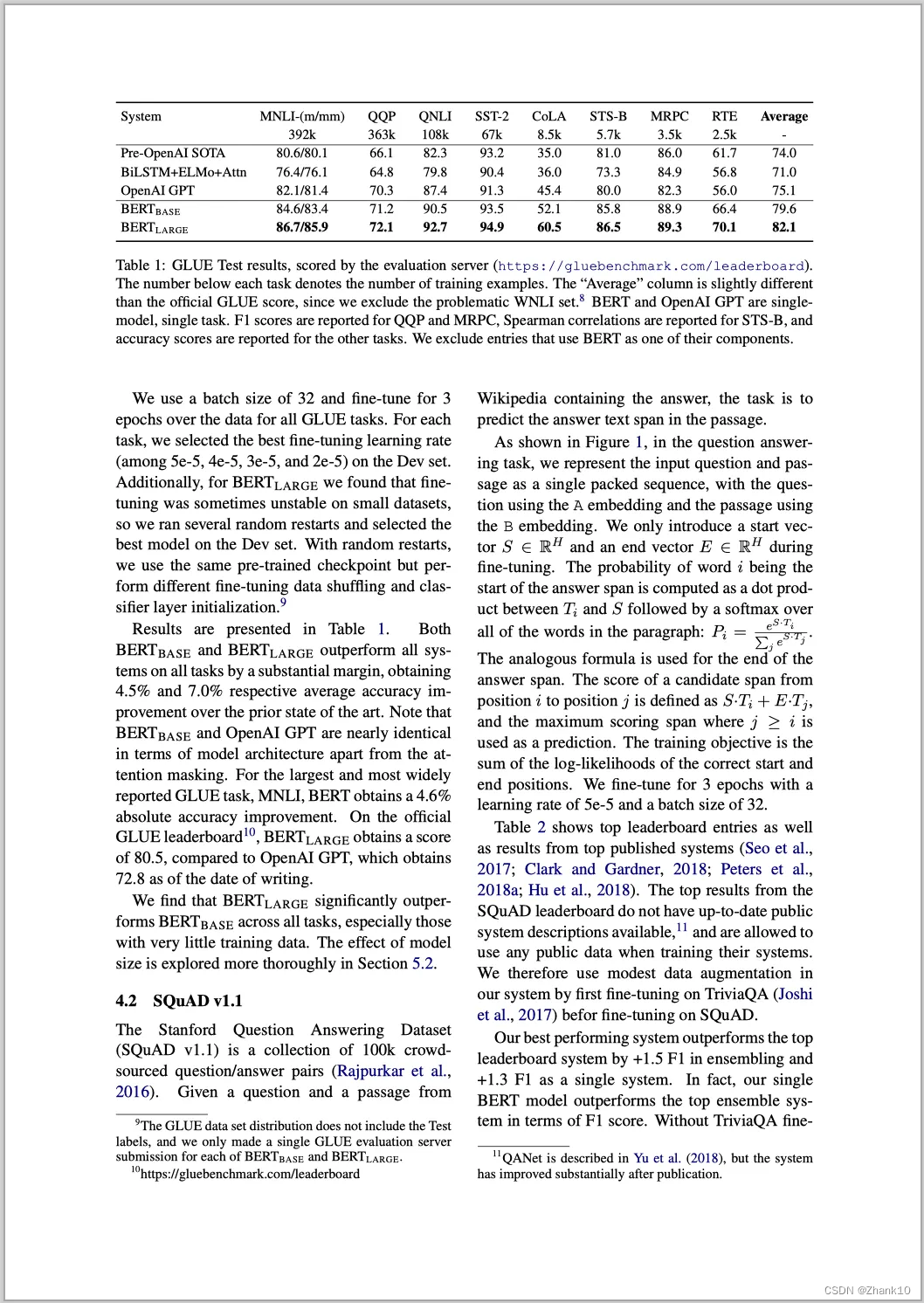
代码如下:
csharp
import os
import cv2
from paddleocr import PPStructure,draw_structure_result,save_structure_res
from PIL import Image
table_engine = PPStructure(show_log=True)
save_folder = './output'
img_path = './bert-6.png'
img = cv2.imread(img_path)
result = table_engine(img)
save_structure_res(result, save_folder,os.path.basename(img_path).split('.')[0])
for line in result:
line.pop('img')
print(line)在上面的输出结果中,有一行类型为 table 的输出,我们将这一行中 html 标签下的内容拷贝出来,放到一个 html 文件中,得到如下的表格:

可以看出在表头这一块还是有一些差异,但是其他的信息基本都是正确的,应该说效果还是不错的。